
作者介绍
赵翔,2021年7月加入去哪儿旅行,前端开发工程师,目前主要负责酒店相关业务以及Serverless平台的基建与日常维护
一、去哪儿旅行 Serverless 现状
在 Qunar 技术沙龙之前的文章我们讲到,为了更高效的完成前后端之间数据的裁剪聚合、更快速的上线一个服务功能,我们决定以 Serverless 的思想,建设一个 FAAS 云平台。依据平台提供的能力,开发人员可以通过编写云函数的方式来快速的实现服务功能。
自基于 Serverless 实现的云平台上线并在业务中接入以来,前端开发效率大大提升,以门票业务的接入为例,在代码层面,开发人员更专注于展示,代码量从 2 万多行降低至 6500 多行;迭代效率方面,UI 逻辑的改动实现从原本的平均 1pd 降低到了 0.1pd 。
对于 Serverless 平台而言,我们的目标是其在为开发人员开发提效赋能的同时,能够兼顾性能与稳定性上的保障,但是随着业务的不断接入,一些性能相关的问题渐渐暴露出来,最突出的是下面的两个问题:
- NodeJs 在计算上单线程的特性使得其在运算能力较薄弱,无法应对计算量大的场景
- 缓存内容散乱,没有进行统一的管理
针对这些问题,我们进行了专项优化,以此来提升 Serverless 服务的性能和稳定性,我们以一个实际的优化案例来展开描述:
二、实际场景分析
由一个例子来了解下上面的问题,neeko 系统是由去哪儿网自主研发的组件配置系统,经由它我们可以通过配置的方式进行页面组件的调整,如某酒店详情页的标签展示:


以标签组件的配置为例,其包含标签内容、标签UI、展示位置、展示条件等属性,我们会依据这些属性,结合酒店的信息来为其不同房型展示不同的标签。
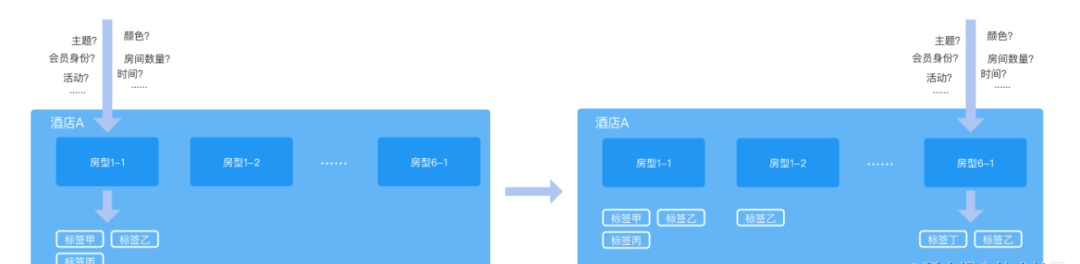
从整体来看,要展示一个酒店内所有的标签信息,需要经过房型数目* 标签配置 * 酒店信息的匹配计算,线上数据的监控显示,其整体响应的计算时长 P99 均值达到 400ms 左右,速度较慢。
为什么这里标签的展示计算会这么耗时呢?
回归到问题本身,标签展示的计算本质上是一个数组的遍历,对每一个房型进行串行的运算,整体下来的时间与其遍历的数组长度相关,且对于每个房型的运算来说,标签配置和酒店信息的运算中嵌套着多层的循环匹配,其本身的计算量就比较大,在房型数目较多的情况,整体耗时就会比较长。
那有没有什么办法能够让我们的云函数能够提高对这种大计算量场景的运算效率呢?
让我们分析一下,对于各个房型之间,其标签的计算其实是互不影响的,相比一个一个的串行的进行运算,如果我们能够实现让这些计算在云函数中并行同时完成,最终再去汇总结果,那么计算效率就能够大大提高了。
三、计算能力提升
提到 NodeJS 的并行计算,就不得不提到 worker_threads 模块, worker_threads 是 NodeJs 团队开发的多线程模块,可用于处理密集型计算,通过它,我们可以创建多个独立于主线程的工作线程,把任务分发给工作线程,让他们来并行的执行计算。结合我们云函数的使用场景,我们设计了如下的落地方案。
(一)并行计算的探索
线程池配置
对于线程池的配置,主要从两方面进行考虑:
- 线程的数量问题
- 线程创建与销毁时机
让我们结合 worker_threads 模块以及 v8 引擎的底层支持来进行分析,我们的 javascript 运行在 v8 实例(Isolate)当中, 通过对 Isolate 的注释描述,我们能够得到这样的信息:

v8 isolates have completely separate states …… The embedder can create multiple isolates and use them in parallel in multiple threads. An isolate can be entered by at most one thread at any given time.
开发人员可以通过创建多个 v8 实例来去并行的运行多个线程,而一个v8实例在同一时间段内只能被一个线程所使用,每一个 V8 实例都有着完全独立的状态。
也就是说,由于每个 v8 实例的状态独立,每个线程都需要单独的 cpu 内核去支撑实例的运作,而又因为,v8 实例同一时间段只能被一个线程所使用,故而要想实现最大程度的并行,线程数量与所能提供的计算核数应当是一一对应的。
而对于线程的创建和销毁,我们从需并行执行的云函数调用量级来进行考量,其调用是连续不间断的,且量级较大。

由于线程的创建开销较高,随量级的的变化动态调整线程数目显然是不适合的,我们希望在维持线程常驻的情况下,尽量减少线程数目的变化频率。
我们以一个最大并行任务量为 3 (即最多同时执行三个任务)的云函数为例,在一台4核的容器上运行该云函数,通过调整线程池中线程的数量,来对线程中函数的执行时间、cpu 利用率等指标进行观察验证:
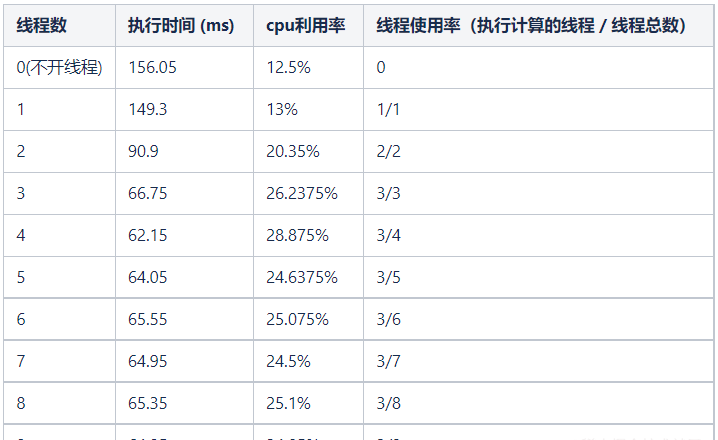
可以看到,云函数的执行时间起初随着线程数的增加而减少,而到了线程数增加到超过了最大并行任务量3时,执行时间开始微涨,处于 64-65ms 的区间内;cpu 使用率起初随着线程数增加而增加,同样,当线程数增加到超过最大并行任务量时,cpu 利用率有所降低,处于 24%-25% 的区间内;最佳的执行时间以及 cpu 利用率比在线程数与核数满足线程数 = 核数 – 1 时达成。
综合之前的结论和实验数据,我们的线程池,初始化创建线程,维持线程常驻,线程数目上取当前容器核数 – 1(预留一核给主线程),只在线程异常时执行线程的销毁和新增补齐,并始终维持固定的线程数目。
(二)线程通信
在线程通信方面,要考虑的主要是两方面的因素:线程同步和线程互斥,同步是说线程间的数据依赖是有顺序的,甲依赖于乙的数据,那甲就应当在乙之后,互斥是说数据的修改是排它的,同一资源的修改访问不能同时进行,甲和乙不能同时修改同一数据,否则会造成数据的覆盖丢失,甲不能在乙读取数据的时候修改数据,否则会使得甲拿不到原本的数据。
worker_threads 模块有 sharedBuffer 和 postMessage 两种线程间数据交互的方式,我们来逐一分析两种方式下实现线程通信的可行性:
sharedBuffer
sharedBuffer 通过在线程间共享内存的方式实现数据共享,首先我们会创建一个 sharedArrayBuffer 实例,通过 Int32Array 作为 View 来承接它的修改,在创建子线程时,主线程将这个 buffer 实例作为初始数据传给子线程,这样,主线程和子线程操作同一个 buffer 实例,便可以共用同一数据了,但想要实现以共用数据的方式做到通信,我们该如何做到线程同步和线程互斥呢?Node Atomics 模块为我们提供了对 sharedArrayBuffer 的原子化操作,什么是原子化操作?简单来说,就是 buffer 中某一位上的操作,一定会在上一个操作结束后才会开始,并且操作过程不会中断,保证操作的互斥,且依据 Atomics,我们可以实现对线程的阻塞和唤醒,通过在 sharedArrayBuffer 上设置互斥量,来实现线程的同步调度。
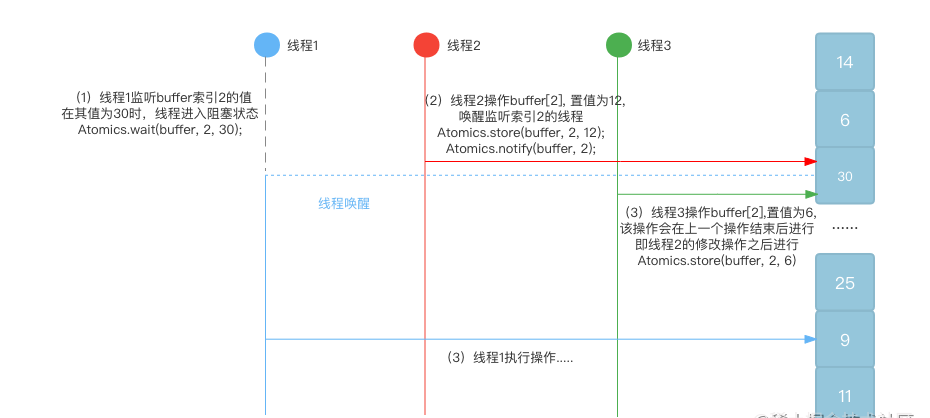
现在有了线程间共享数据逻辑同步和操作互斥的方法,想要将其用在具体的实现上,还需要对sharedArrayBuffer进行结构位的调整。
我们把整个buffer分为五部分的结构位:
- 数据长度位:表示当前要修改的数据内容的长度,置于 buffer 0 位
- buffer 修改 mutex 位:表示当前 buffer 是否正在被操作,置于buffer 1 位
- 线程数目位:表示当前线程池中的线程数目,置于 buffer 2 位
- 线程状态位:表示当前各个线程的工作状态,置于 buffer 3 位 ~ (3+线程数目) 位
- 线程数据位:表示当前要修改的内容,置于 buffer (3 + 线程数目 + 1) 位 ~ (3 + 线程数目 + 1 + 数据长度) 位
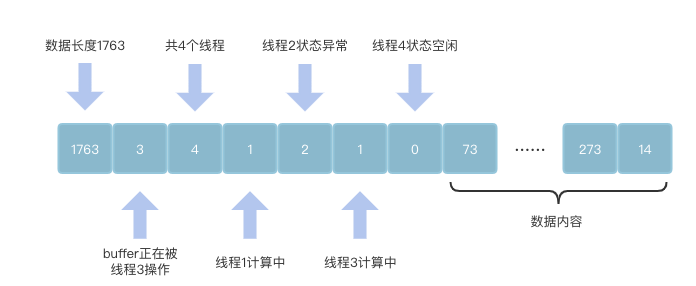
依据划分好的 buffer,我们便可以清楚的知道各个线程的执行状态,结合 Atomics 将任务序列化后写入 buffer 数据部分,并告知当前空闲的线程去执行任务,线程间也可以根据 mutex 位,互斥的操作数据内容。
postMessage
postMessage 以收发消息的形式来进行线程间的消息通信,工作线程的执行通过消息触发,天然的支持线程同步线程互斥,它以 v8 自带的序列化方法操作要发送的数据,以消息的形式发送给其他线程,数据传递即发即用。在使用上,我们可以通过发送消息轮询各个线程,来找到空闲线程,并将任务给到空闲的线程,待到所有任务结束后,由主线程做结果的聚合。
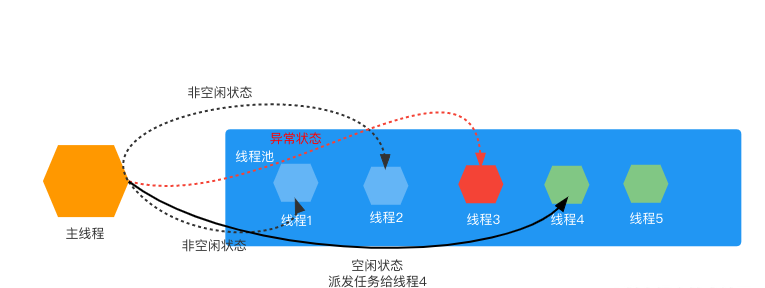
方式比较
我们对两种方式进行了初步的实现,以一条线上的数据为参照,来做两种方式进行线程通信耗时的比对:
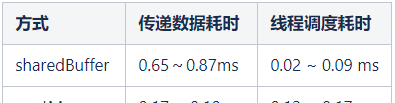
可以看到,在线程调度方面,由于 sharedBuffer 方案中通过记录各个线程的状态,可以很明确的知道要调度的空闲线程,相比 postMessage 去轮询,它的耗时非常小。
而在数据传递方面,sharedBuffer 由于要传递的数据包含对象等类型,从 buffer 中对其存取需要一些列的转换,相比 postMessage 要慢不少。
再从数据传递、数据操作和异常处理方面进行分析:

sharedBuffer 由于数据的操作都是 buffer 上进行的,读取buffer转为可用数据的操作时间较长, 且直接操作和截取buffer的过程对于我们是不可知,有风险的,相比于 postMessage 的消息即用,我们并不能确保截取操作后的buffer经过转换后依然是可用的数据对象。
在异常处理方面,postMessage 可以将异常消息主动发送给主线程,而 sharedBuffer 由于存在 Atomics.wait 的使用让某些线程阻塞的情况,如果因为其他线程异常而不去唤醒该线程,则该线程可能会是一直阻塞的状态。
(三)方案设计
综合考虑两种方式,我们决定将两种方式进行结合,取 sharedBuffer 直接感知各线程的优势和 postMessage 消息即用的特点,设计了以下方案:
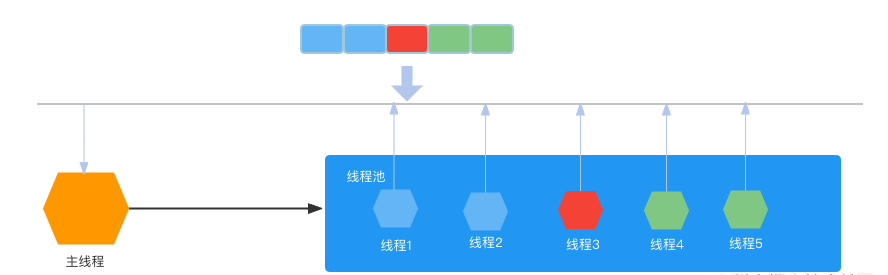
在主线程和子线程间,维护一个表示线程工作状态的 buffer 内容,这块内容由子线程维护更新,每个子线程更新 buffer 中自己对应位的值,这样,主线程便能直接知道各个工作线程的工作状态,将计算任务派发给空闲的线程,同时也能知道哪些线程出现了问题,做销毁和重启线程的处理。
函数处理
有了线程间通信的方法,我们该如何去运行具体的函数去做逻辑处理呢? worker_threads 模块将要放在多线程运算的函数以文件或是eval的形式导入,结合我们的云平台,要做到 FasS 形式的使用,这个函数需要提供一个能够运行外部代码的环境。因此我们可以将函数体也作为参数带入环境,并将函数体进行实例化缓存,这样,线程中便能运行外部传来的代码了,即 worker 参数 = 函数参数 + 函数体。
那么问题来了,如何去保障外部来的代码不会对系统造成影响呢?如何去相对安全、相对可靠的运行这些代码呢?
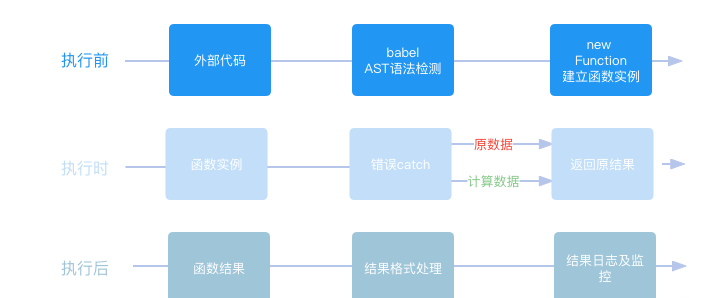
在前面 ServerLess 的文章我们有讲到,云函数的创建与更新是在平台上进行的,在云平台上,我们提供了基于 Monaco Editor 做的代码编辑器,其给用户代码提示和代码高亮等功能,并且,我们在云函数的保存接口上,置入了语法检测的功能,来保证云函数不会出现操作全局变量、引入外部依赖等影响服务稳定性的问题,为了灵活的自定义语法规范,这里我们选择使用通过 babel 遍历语法树做规则限定来实现语法检测。
有了执行前的语法检测,我们要着重考虑的则是在函数执行时的错误处理,当出现执行错误时,我们认为当前所处理的数据是有问题的数据,会返回未经云函数处理的原数据,用于做一些兜底逻辑的适配。而当出现处理超时时,这种情况,会返回当前已经计算了的数据,保证结果可用,Node 执行外部代码有eval、new Function 和使用 v m 三种方法,由于云函数触发频繁,vm 在每次执行时创建context的时间较长,所以 vm 并不适用。比较 eval 和 new Function,云函数的实例需要常驻,由于 eval 只是对代码的整体编译,而 new Function 在使用时可以很清晰的规范出一个函数实例并带入外部参数,因此我们最终选择了以 new Function 为基础,来执行云函数。
在函数执行后,我们会对结果进行格式的处理,包装状态码等信息,供调用方做逻辑适配,并对这次的调用记录日志和监控,保证云函数调用可追溯,异常可告警。
数据处理
在我们的设计中,工作线程需要计算的数据资源由主线程统一派发,结合线程通信来取保证资源互斥,但这也造成一个问题:当多个线程在同一资源的基础上进行计算修改时,主线程如何去合并它们的计算结果,该以怎样的原则去合并数据的修改?
考虑两种情况:数据内容的修改和数据结构的修改。
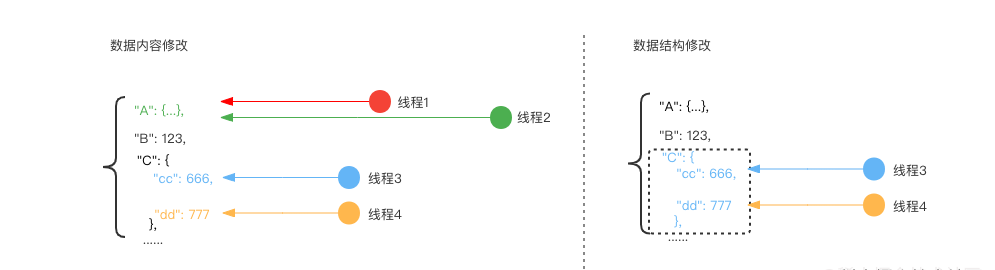
数据内容修改
进行数据内容修改时,以一个对象为例,操作的数据节点可能是该对象上的一级节点,如线程 1 与线程 2 都同时操作节点 A 整个大节点,这种情况下,以并行逻辑考虑,这里是会有数据覆盖的,至于谁覆盖谁,则由两个线程返回处理结果的时间顺序相关,若线程 2 先返回处理结果,则最终数据便是线程2处理的数据,线程 1 处理的数据被覆盖,这种覆盖逻辑在并行直接操作同一数据节点的情况下也是符合逻辑的。
还有一种情况是,操作同一个对象下不同的节点,如线程 3 与线程 4 各操作节点 C 下的 cc 节点和 dd 节点,这种情况下各自操作的数据不会互相影响,则在合并时不用考虑主线程收到它们返回结果的顺序。
数据结构修改
进行数据结构修改时,如线程 3 在结果中已经删去节点 C ,线程 4 在结果中对节点 C 进行修改,在与原结果进行合并时,与修改数据内容的现象是一样的,即谁先返回结果给主线程谁被覆盖,同样这样也符合并行逻辑。
总结下合并原则:对于基础类型的数据修改,如数字、字符串数据等,比对修改即可,对于结构化数据的整体修改,同一节点的修改直接覆盖即可。
(四)方案实践
在多线程计算能力的支持下,Neeko 标签处理函数时长成功降了下来, 但是,观察云函数的执行监控我们发现,在服务启动,函数实例初次创建的时候,函数的执行时间较长,经过一段时间后才会回落:

为什么会出现这种现象呢?
经过分析,这里是因为服务初次启动和函数实例初次创建的时候,一些配置、可枚举结果等冷数据并不在缓存中,只能通过外部 I/O 获取这部分数据,待获取到数据后,再将其存入缓存,这也就导致其执行一开始的时间较长,随着缓存的装载,运行时间才慢慢降低并保持平稳。服务初次启动导致的响应波动是非常影响服务的可用性的,在服务量级较大的情况下,即使拉长发布次数和发布间隔,也依然会对线上造成不小的影响。因此我们需要对服务进行缓存的统一治理,来去解决因缓存命中导致的请求超时问题。
四、缓存治理
函数缓存
我们当前的数据以 mysql、redis 缓存以及本地缓存分成三级进行存储,读取以及写入都按照本地缓存、redis 缓存、mysql 的顺序进行操作,因而在纯函数调用未命中本地缓存时,大部分情况函数内容都能从 redis 缓存中取得。
尽管和从 mysql 读取相比,redis 的读取速度较快,但还是和命中本地缓存直接调用有着一定的差距,尤其是在服务初次启动,函数被调用的时候,这个时候容器本地缓存还没有函数实例,需要先从 redis 中取得函数内容,装载在本地缓存和实例化后才能完成调用,造成 “一开始调用时间长,后续调用时间短” 的参差,如果可以让缓存一开始便已经装载 ready ,那么这个问题也就迎刃而解了。
因此我们选择,在服务正式启动前便进行缓存的装载,完成缓存的预热,尽管这一过程会增加服务启动的时间,但是对调用方来说,可以在一开始调用便有着不错的请求响应时间。

冷数据缓存
前面说到,在一些函数实例本地缓存未命中,需要 I/O 取数据的场合,其执行时长表现上往往波动较大,这一问题,在进行了函数缓存的预热后得到了缓解,但从监控数据来看,随着函数的执行调用,其执行时间仍呈下降后再趋平稳的状态,前后达到 30ms 的波动。除了函数缓存的读取,是否还会有其它的缓存读取造成时长波动的影响呢?
这里依然以 neeko 标签函数为例,总结下函数中可能会用到的缓存:
- 配置类数据缓存
- 可枚举计算结果的缓存
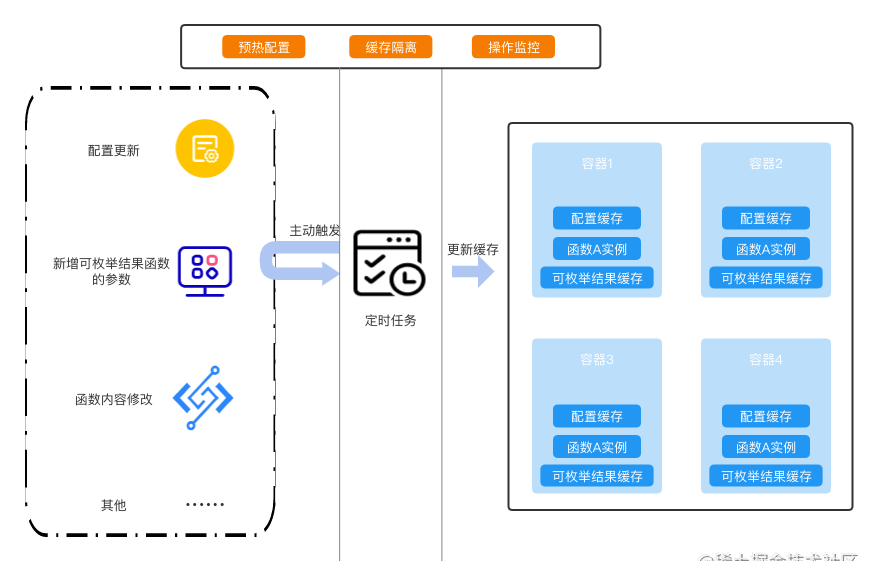
如果能进行一些冷数据的缓存,就能很好的减少运行时的数据获取所造成的影响,基于之前的函数缓存,我们做了一个统一的数据缓存层,进行数据缓存的处理:
这一层处于冷数据源和容器缓存之间,它会以定时任务的形式去拉取冷数据源的数据,检查更新,来更新容器上的缓存。
在这一层上,我们设置了一些缓存策略,来去调整缓存的更新:
- 预热配置:
不同缓存更新的频率不一样,在这里,我们针对不同的缓存进行不同的预热配置,如要拉去预热的数据源范围,获取数据失败的兜底配置等。
- 缓存隔离:
主要是针对业务数据的分离以及便于缓存淘汰等机制的设立,便于缓存的管理。
- 操作监控:
对每次的缓存更新,定时任务做监控记录,观测缓存的更新状态,设立相关告警。
方案实践
通过对函数的缓存增加服务初次启动时函数实例的命中率,对冷数据缓存增加函数在初次执行时对缓存数据的命中率,执行时间的波动成功降下来了,当前波动从原来的 30ms 到现在保持在 10ms 以内。
通过数据缓存层,我们成功使得函数的调度响应平稳下来,实现了数据接收和缓存配置的可拓展性,减少了因缓存未命中的时间波动。数据缓存层通过定时任务主动触发缓存数据的更新,未来还会加入由 qunar 自主研发的 qmq 消息队列以被动接收更新的形式获取要更新的缓存数据进行拓展。
五、接入效果
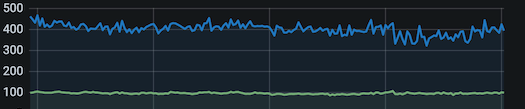
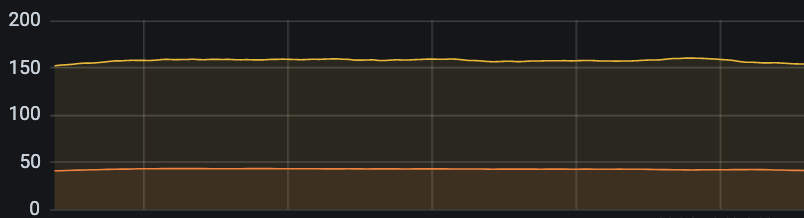
在国庆高流量下,Neeko 标签函数整体耗时下降,P99 从 400ms 降低到152ms 降低 72% ,响应时间无波动:
调用量级:

优化前:
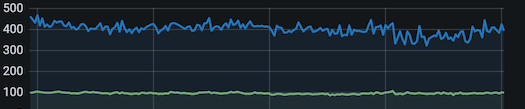
优化后:
六、未来规划
接入推广
在当前的业务接入中,Serverless 云函数的运用覆盖了多种场景,如数据的裁剪、接口的聚合处理、定时任务的创建以及提供配置能力等,我们希望能够在这些场景下进行 Serverless 云平台的推广,基于当前的平台能力接入更多的业务,从业务中的反馈来不断丰富和健壮平台能力。
服务分离
当前的云平台,对于云函数的修改和执行是在同一服务中的,这就导致,一些平台上展示的,界面化的东西,有时会需要对整体服务作出发布改动。为了做到服务功能分离,减少服务的管理复杂度,我们希望能对当前服务进行拆分,提高服务的稳定性。
自动化扩缩容治理
通过配置容器的自动化扩缩容,结合系统级、函数级的监控数据,进行容器的自动化扩缩容的阈值配置,做到资源的合理分配。
数据容灾
当前的云平台,函数的内容是保存在库中的,尽管我们会在服务初始化时缓存函数实例,但对于一些新的函数,一旦库出现问题了,它的执行是一定会受到影响的,基于此,我们希望通过数据库的存储转发、定时复制等方法来去做数据的容灾,保障原有的数据不会丢失。
原文链接:https://juejin.cn/post/7213252349559685176 作者:去哪儿技术沙龙