
阅读本文你可能获得:
1.掌握 Node 常用模块的常用 API
2.掌握开发基于业务的脚手架的流程
3.了解 npm 包开发中你可能忽略的细节
4.渗透式 create-vant-cli-app 源码解读
5.更多…
起因
昨天两周前一位同事要改某个旧的功能模块,我看内容很少又是用Vue3写的,迁移到我搭建好了的monorepo项目里刚好合适。于是就让他来试水。
然后就是一顿操作。。各种小问题,幸好都得以解决。
虽然解决了,但集成进来的项目会越来越多,就算我不当“客服”,而是直接把初始化步骤写好了,同事也可能怨声载道,毕竟要手动改很多东西。如下图所示。
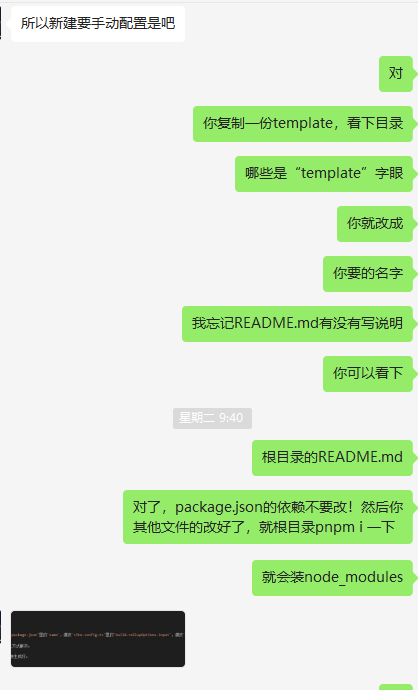

只是截取了一部分,我最后的结论是这个配置的事情必须搞成自动化。
因此,还是得把这几个月拖拖拉拉依然没搞出来的“快速初始化项目”的任务给完成。
但是怎么写呢?你让我手写一个 CLI 真写不出来。除非我平时就是不停地造这类轮子。
我一直比较喜欢Vant,这次会一边学习源码,一边开发一个基于我们业务的脚手架。
准备
我们来根据 Vant文档说明 看看怎么运行脚手架的:通过yarn create vant-cli-app快速创建项目,同时又支持手动安装,例如pnpm add @vant/cli -D。
方式不唯一,而且很陌生,不行,开始晕了。
“简单点,搭建的方式简单点!”
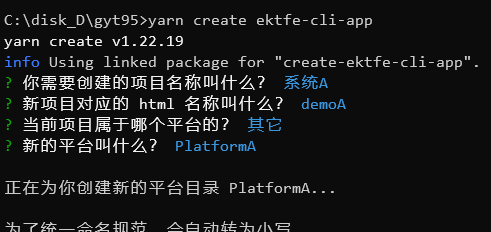
定下第一个小目标:能通过yarn create ektfe-cli-app命令安装依赖并运行。
第一个小目标:本地运行 CLI
yarn create 是什么?原理是什么?
先从命令入手,yarn create是什么?原理是什么?
根据Yarn 中文文档可知命令格式:
yarn create <starter-kit-package> [<args>]
这个命令其实是简写! 主要帮助你同时做两件事:
- 全局安装
create-<starter-kit-package>(如果存在就将其更新到最新版) - 运行
package.json的bin字段下的可执行文件。并且还会将任何<args>转发给它
也就是说,yarn create react-app my-app等价于
$ yarn global add create-react-app
$ create-react-app my-app
注意1:<starter-kit-package>就是以create-开头的 npm 包。
(所以create-cli-app的create-是固定的,必须要加!)
注意2:npm init也是一样用法,例如:npm init react-app my-app
package.json 参数解读
npm 英文官方文档(但不全,有部分在 TS 文档、 Node 文档里都有提及)
看开源项目可先看package.json(明明是README.md!)。
所以我们来看vant-cli的package.json。
后记:是的,当时先看vant-cli。我以为我要开发的是这个。。
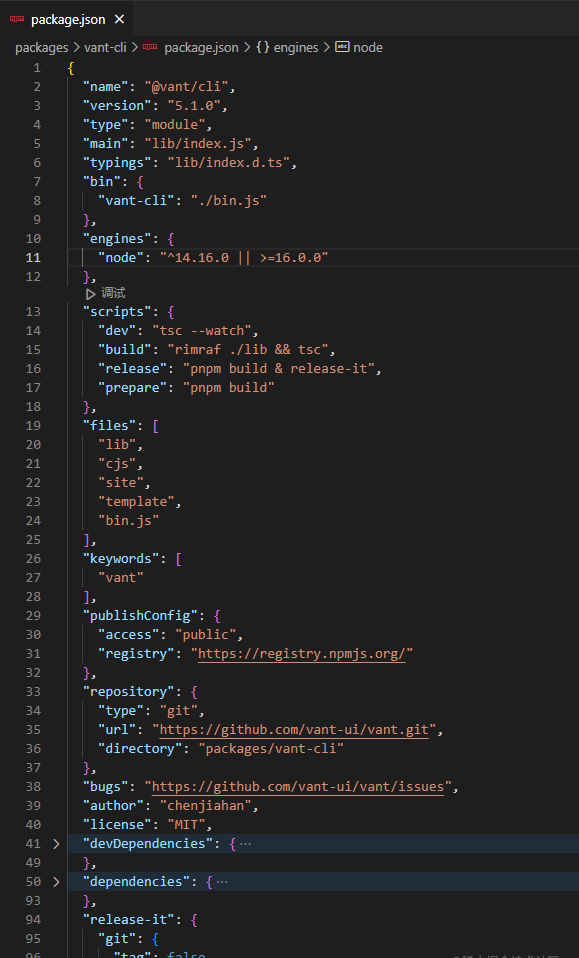
有些字段很关键,有些字段不关键。但还是整体了解一下吧。
黑体字是经常忘记但很重要的字段。
name:包名称,发布 npm 包的时候也是这个名称
version:版本号
type: package下的.js被Node以cjs或esm加载。
main:加载这个 npm 包时的入口文件。
官方文档称:main字段是一个模块ID,是程序的主要入口点。即如果你的 npm 包名为foo,并且用户安装了它,然后在项目里导入例如require("foo"),那么main模块里export的对象将被返回。
路径是相对于 npm 包根目录的模块。例如这里lib/index.ts就是执行打包后生成的lib目录中的index.ts。当加载这个 npm 包的时候,会执行index.ts。如果没有指定,默认是根目录的index.js。
typings: 起初根本查不到这个字段,只看到 types 字段。于是灵机一动把光标移动到 typings 字段上面👇意思是“typings”字段与“types”同一个意思,使用哪个都行。

它们都是用于指定TypeScript项目中导入该 npm 包时使用的类型声明文件(.d.ts 文件)的位置。这个字段可以帮助TypeScript编译器在导入 npm 包时正确地处理类型检查。
在早期版本的
TypeScript中,类型声明文件的扩展名是.d.ts,而typings字段用于指定该文件的位置。后来,TypeScript 2.0引入了types字段,作为typings字段的替代品。因此,如果你在使用较新版本的TypeScript(2.0 及以上),应该使用types字段。
bin: 命令名到本地文件名的一种映射。它允许在安装 npm 包后将脚本添加到系统的 PATH 路径中。这些脚本可以是命令行工具或其他可执行文件。
当例如vant-cli被全局安装,该文件会被链接到全局bin目录,或者创建一个cmd去执行bin字段里的指定文件,因此它可以按名称运行。
另外,你必须确保bin字段引用的文件,以#!/usr/bin/env node开头,否则脚本不会被视为可执行文件。
简单来说,会自动直接执行这个文件,例如 vant-cli 本地安装可以用pnpm add @vant/cli -D ,指的是在当前工程目录的命令行可以执行bin.js这个文件。
(在安装时,如果是全局安装,npm 将会使用符号链接把这些文件链接到 prefix/bin ,如果是本地安装,会链接到./node_modules/.bin/)
注意:yarn create vant-cli-app对应的不是vant-cli这个包的name字段(@vant/cli)或者bin字段(vant-cli)。而是create-vant-cli-app这个 npm 包里的bin字段,也就是说yarn create对应的是create-vant-cli-app项目。
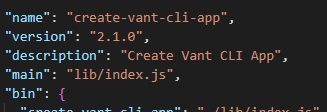
区分 yarn create 和 yarn add
首先, yarn create和yarn add是两回事!
前者是全局安装,会包含两个步骤。后者是本地安装,即安装到当前工程目录里。
由于yarn create后面参数<starter-kit-package>是以“create-”开头的 npm 包。所以yarn create vant-cli-app命令之所以能创建项目,实际上是全局安装一个“create-”开头的 npm 包。即这里的create-vant-cli-app!所以你就能在windows的C盘的Yarn安装路径里的bin目录找到了create-vant-cli-app和create-vant-cli-app.cmd两个文件了!
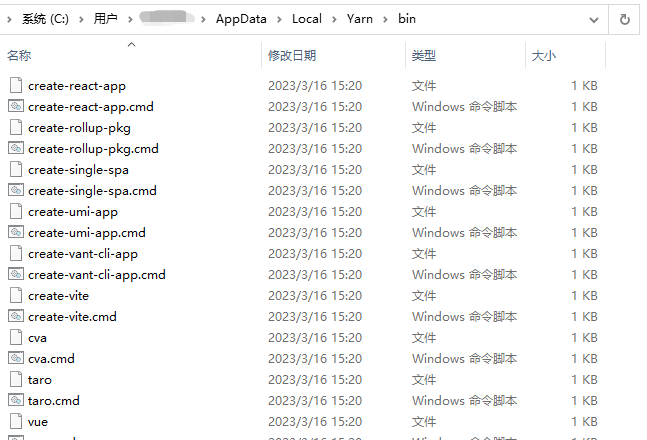
然后就会自动执行这个create-vant-cli-app的入口文件,最后在你执行yarn create vant-cli-app命令的目录下帮你初始化一个项目。
为什么会自动执行?上文提到过, yarn create包含两个步骤嘛,第一步全局安装,第二步就是执行 bin !
那yarn add @vant/cli -D又是怎么回事呢?
其实上面一大段都没提及vant的另一个 npm 包即vant-cli。@vant/cli就是vant-cli的name。我们之前也提到这个就是 npm 包的名称。而bin是当你执行这个 npm 包时会执行对应的文件。
咦,刚刚好像说main是入口文件呀,那执行的不就是从main开始的吗?那现在又说bin也是执行的字段。
那到底bin和main本质区别是什么?
区分 main 和 bin 字段
再次回顾main和bin字段:(当你抱怨“这两个字段刚刚不是说了吗”时,恭喜你,你掌握得很牢固)
main:当用户install某个 npm 包后并在代码里引入时,此时会进入main字段所指定的文件。
bin:当全局安装某个 npm 包时,会链接到全局bin目录,像xxx.cmd就会创建一个cmd然后里面就执行这个bin字段对应的文件。
因此!! bin所对应的文件,执行时机是在全局安装或本地安装的时候。而main字段所对应的文件,执行时机是在代码中导入的时候。这就是两者最大区别,两者看起来都在执行着什么,但执行的位置、时机都不同。
总算是理清了,个人觉得以上几个字段是最重要的。一定要区分清楚。希望不只有我是今天才分清的。
其它参数解读
engines:指定运行你这个包的 Node 版本(有可能有的功能是 Node 的某个版本之后才支持)(如果不指定,就是任何 Node 版本都可以)(也支持指定 npm 版本)
scripts:脚本命令
files:定义发布到npm仓库中的包时,应该包含哪些文件和目录。这个字段的作用是告诉npm在发布包的时候只包含指定的文件和目录,避免将不必要的文件或目录发布到npm上。同时,也会作为依赖项安装到项目工程里
keywords:关键字集合。一个字符串数组。好处:有助于别人通过 npm 搜索到你的包。(description同理)
publishConfig:发布npm包的访问权限(public)、发布地址
repository:项目地址
bugs:bug反馈地址
author:作者。只有一个人。另,contributors 是数组
devDependencies:开发环境会用到的依赖
dependencies:生产环境会用到的依赖
有的组件库还会有 module 字段,是打包生成一个 esm 语法的目录,module 字段就指向对应的入口文件。
至此,我(们)终于明白:发布 npm 包时如何指定文件/目录,安装 npm 包时执行 npm 包里的哪个文件,导入到项目工程后又会执行哪个文件。
如何本地开发 CLI ?
执行一下vant-cli的dev脚本命令,它实际上是执行tsc -w。
已知tsc是用来编译.ts文件的。默认从当前目录开始编译,而这个也取决于tsconfig.json。
为什么要用 tsconfig.json ?
因为实际开发的项目,很少是只有单个文件,当我们需要编译整个项目时,就可以使用tsconfig.json文件,将需要使用到的配置都写进tsconfig.json文件,这样就不用每次编译都手动输入配置,另外也方便团队协作开发。
然后可以看到create-vant-cli-app的tsconfig.json是这样写的👇
{
"extends": "../../tsconfig",
"compilerOptions": {
"target": "ES2019",
"outDir": "./lib",
"module": "commonjs",
"declaration": true
},
"include": ["src/**/*"]
}
可以看出outDir目录是./lib。所以当执行dev命令时,tsc -w就会监听include字段里所有.ts文件,一旦有文件变化,就编译输出到./lib目录。
include 属性作用:指定编译需要编译的文件或目录。
ok,开始初始化项目。
初始化自己的 CLI
补充一下,最终生成的模板长这样:
配置 package.json
通过pnpm init等命令就能初始化了,再进行一些修改。
结合前文知识,我们知道:
main:项目里导入时,会进入的入口文件。
bin:执行yarn create ektfe-cli-app时,全局安装后,会执行的文件对应路径。
{
"name": "create-ektfe-cli-app",
"version": "0.0.1",
"description": "Create CLI App",
"main": "lib/index.js",
"bin": {
"create-ektfe-cli-app": "./lib/index.js"
},
"scripts": {
"dev": "tsc --watch"
},
"author": "gyt95",
"license": "MIT"
}
而scripts的dev:运行项目,并watch变化,一旦变化就重新编译、输出。输出到哪里呢?这里就要配合tsconfig.json了。
{
"extends": "../../tsconfig.json",
"compilerOptions": {
"target": "ES2019",
"outDir": "./lib",
"module": "commonjs",
"declaration": true,
},
"include": ["src/**/*"]
}
然后创建src目录,创建index.ts,输入👇
#!/usr/bin/env node
function init(){
console.log(666)
}
init()
报错:无法在 –isolatedModules 下编译 “index.ts”,因为它被视为全局脚本文件。请添加导入、导出或空的 “export {}” 语句来使它成为模块。ts(1208)
为什么会报错?
当我们的tsconfig.json中的isolatedModules设置为true时,如果某个.ts文件中没有import或者export时,ts则认为这个模块不是一个ES Module模块,它被认为是一个全局的脚本,这个时候在文件中添加任意一个import或者export都可以解决这个问题。
所以这里加上export {}就不会报错了。
#!/usr/bin/env node
function init(){
console.log(666)
}
init()
export {}
为什么要设置 isolatedModules 为 true?
假设有如下两个ts文件,我们在a.ts中导出了Test接口,在b.ts中引入了a.ts中的Test接口。
然后又在b.ts将Test给导出。
export interface Test {}
import { Test } from './a';
export { Test };
这会造成一个什么问题呢?
如Babel对ts转义时,它会先将ts的类型给擦除,也就是a.ts空了。但是当碰到b.ts文件时,Babel并不能分析出export { Test }它到底导出的是一个类型还是一个实实在在的js方法或者变量,这时候Babel选择保留export。
但是a.ts文件在转换时可以很容易的判定它就导出了一个类型,在转换为js时,a.ts中的内容将被清空,而b.ts中导出的Test实际上是从a.ts中引入的,这时候就会产生报错。
如何解决上述问题?
ts提供了import type或export type,用来明确表示我引入/导出的是一个类型,而不是一个变量或者方法,使用import type引入的类型,将在转换为js时被擦除掉。
import { Test } from './a';
export type { Test };
其实就是基于“TS的导入省略能力会检测如果导入类型就会在编译后被擦除”这一特性上,擦除后导致JS找不到这个类型了,于是报错。所以,假如设置为true就不会在非tsc编译器有这个情况,假如是false,就要你自己加import type才行(3.8 新出的特性)
之前其实有了解过这个知识点。TypeScript 5.0 新特性--verbatimModuleSyntax要求你明确写类型导入,才会保留。否则,就会擦除。任何没有type修饰符的导入或导出,都会被保留。而任何使用type修饰符的内容,都会被删除。
即:“所有非仅类型导入/导出都会被保留,而仅类型导入/导出都会被移除。”
以前还有其它属性:
--importsNotUsedAsValues:用于确认类型导入的使用(仅类型导入需要被显式标记,而未被使用的值导入仍然将会保留)
--preserveValueImports:用于显式避免部分导入语句的移除(所有值导入都将被完整保留,避免 TypeScript 无法检测其使用方式的情况)
由于以前当同时开启preserveValueImports和isolatedModules配置时,isolatedModules会让引入的类型必须是type-only。所以来自同一个文件的数据必须得分两条import引入。
import { someFunc, BaseType } from "./some-module.js";
// ^^^^^^^^
// Error: 'BaseType' is a type and must be imported using a type-only import
// 除非
import type { BaseType } from "./some-module.js";
import { someFunc } from "./some-module.js"
而TypeScript 4.5允许一个type修饰词在import语句中👇
import { someFunc, type BaseType } from "./some-module.js";
isolatedModules是为了避免非tsc的编译器编译时出现类型被擦除但import的类型仍存在导致报错的问题。所以开启这个就为了安全编译,必须是模块隔离的。模块隔离,指的是导入和导出都是确定的,不是模棱两可的。是类型就必须声明是类型。
但很多开源库都不开启这个,不太理解。。就正如我暂时不理解为什么有tsc还需要用Babel编译ts代码?
小结:如果设置isolatedModules为true ,那么新建的 .ts文件一定要包含一个import或者export 。
执行 dev 命令运行 CLI
执行dev脚本后,tsc --watch后生成lib目录
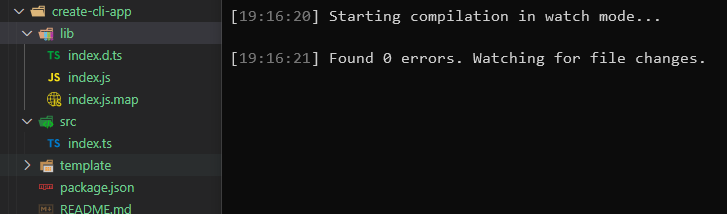
如何本地调试?
以前一般我们都用npm link来调试组件库。现在用yarn应该也一样,看了下 Yarn官方文档 。是用的yarn link。注意如果yarn unlink就失去了全局链接,此时再yarn create就会去线上yarnpkg查找。
pnpm 也有pnpm link,具体可见 Pnpm官方文档 。
pnpm link <dir>
从执行此命令的路径或通过 <dir> 指定的文件夹,链接package到node_modules中。
pnpm link --global
从执行此命令的路径或通过 <dir> 选项指定的文件夹,链接package到全局的node_modules中,所以使其可以被另一个使用pnpm link --global <pkg> 的package引用。
pnpm link --global <pkg>
将指定的包(<pkg>)从全局 node_modules 链接到 package 的 node_modules,从该 package 中执行或通过 --dir 选项指定。
由于我没有把 pnpm 加入到 PATH ,所以使用 全局link 就报错了👇
The configured global bin directory "C:\Users\xxxx\AppData\Local\pnpm" is not in PATH
有yarn create就行,目前为止,我们终于实现了第一个小目标!
第二个小目标:增加询问
内置一个模板 & 围绕业务提供几个问题。
主要用到的库
已知从index.ts执行。看看create-vant-cli-app的代码
#!/usr/bin/env node
import consola from 'consola';
import { prompt } from 'inquirer';
import { ensureDir } from 'fs-extra';
import { VanGenerator } from './generator';
const PROMPTS = [
{
type: 'input',
name: 'name',
message: 'Your package name',
},
];
async function run() {
const { name } = await prompt(PROMPTS);
try {
await ensureDir(name);
const generator = new VanGenerator(name);
await generator.run();
} catch (e) {
consola.error(e);
}
}
run();
看到consola,这看起来就是用于控制台打印输出的。
consola
官方描述:用于Node.js和浏览器的优雅控制台记录器。
pnpm add consola,用起来很简单。
const consola = require('consola')
// See types section for all available types
consola.success('Built!')
consola.info('Reporter: Some info')
consola.error(new Error('Foo'))
控制台展示:

下一个是inquirer。
inquirer
pnpm add inquirer
基本用法:传入一个“问题”数组给inquirer的prompt函数。并异步获取结果。获取到的结果就是用户选择的选项。
代码如下:
import { prompt } from 'inquirer';
const PROMPTS = [
{
type: 'input',
name: 'name',
message: 'Your package name',
},
];
async function run() {
const { name } = await prompt(PROMPTS);
}
run();
当调用prompt函数后,如果正常调用,则会再调用ensureDir函数。这个函数来自另一个库fs-extra。
fs-extra
官方描述:fs-extra添加了原生fs模块中未包含的文件系统的方法,并为fs方法添加了promise支持。它还使用graceful-fs来防止EMFILE错误。应该是fs的替代品。
那么create-vant-cli-app源码中的await ensureDir(name) 意思是确保 name 这个目录存在。如果目录结构不存在,则创建它。然后通过new Template(name)创建一个模板实例。并通过run()执行。
写了个简单逻辑:
#!/usr/bin/env node
import consola from 'consola'
import inquirer from 'inquirer'
const PROMPTS = [
{
type: 'input',
name: 'name',
message: '你需要创建的项目名称叫什么?'
},
{
type: 'list',
name: 'type',
choices: ['nsft', 'say', '其它'],
message: '当前项目属于哪个平台的?'
},
]
async function run (){
const result1 = await inquirer.prompt(PROMPTS)
console.log(result1);
try {
} catch (e) {
consola.error(e)
}
}
run()
然后执行dev命令再yarn link命令。
然后到目标项目中执行yarn create ektfe-cli-app。结果报错。
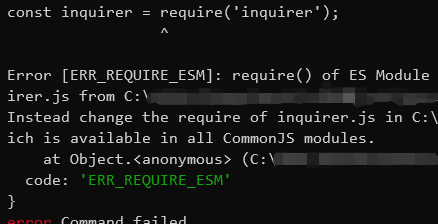
报错:Instead change the require of inquirer.js in C:\xxxx\xxx\xxx\index.js to a dynamic import() which is available in all CommonJS modules.
意思是inquirer.js的require要更改为在所有cjs模块中都可用的动态import()
代码明明写的是import。那一定是因为tsconfig.json。于是把"module": "commonjs"注释掉。
但又提示:

不能在模块外使用 import 语句?
查资料找到相应解决办法:bobbyhadz.com/blog/javasc…
即要在package.json中添加type: "module"。回顾上文可知,字段意思是当前package下的.js被Node.js以cjs或esm加载。
当前流程:
1.我们写的.ts文件会通过tsc编译输出到lib目录,例如index.ts会编译为./lib/index.js,然后通过yarn link进行全局链接。
2.在另一个项目里我们通过yarn create ektfe-cli-app全局安装和执行 CLI 。此时所执行的是bin字段对应的文件./lib/index.js。
3.由于是在Node环境执行的,但此时我们用的语法是esm的import,所以我们必须通过type: "module"告诉Node当前 npm 包里的.js都会作为es模块加载。
你也可以把鼠标移动到 package.json 的 type 字段上,会有以下提示:
当设置为“module”时,type 字段允许包指定所有 .js 文件都是 ES 模块。如果“类型”字段被省略或设置为“commonjs”,则所有 .js 文件都被视为 CommonJS。
而最尴尬的是一开始我就是想直接用默认的cjs模块规范。结果inquirer又要我用esm语法import。
怎么会这样?!
打开inquirer的 npm 包网址(Github也行),全局搜索“commonjs”。
Inquirer v9 and higher are native esm modules, this mean you cannot use the commonjs syntax require(‘inquirer’) anymore. If you want to learn more about using native esm in Node, I’d recommend reading the following guide. Alternatively, you can rely on an older version until you’re ready to upgrade your environment:
npm install --save inquirer@^8.0.0
意思是inquirer版本如果是 9 或以上,那么就是原生esm模块。意味着你不能再用cjs语法require('inquirer')。如果你想学习更多关于在 Node 中使用原生 esm 的知识,我将推荐阅读这个指南,或者你可以用旧版本,直到你准备好升级你环境为止。
那怎么create-vant-cli-app又没问题?
去看它的package.json,inquirer版本是 8+。
(因为我之前拉取Vant的源码到本地,也没同步后续代码,所以还是用的inquirer。后来我又到Github再看,发现已经改为enquirer了。基本上就是对inquier的重新实现)
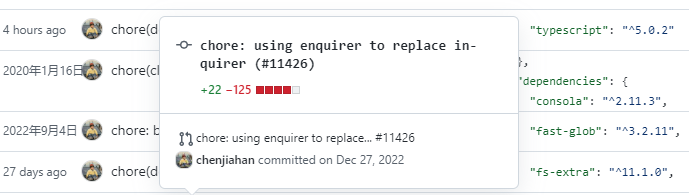
也就是说,当前我用的inquirer版本是 9 ,只能是package.json指定type为module 。

构建询问流程,生成模板项目
制定一个基本流程👇(属于草稿版,开发过程中不断完善,所以有出入)
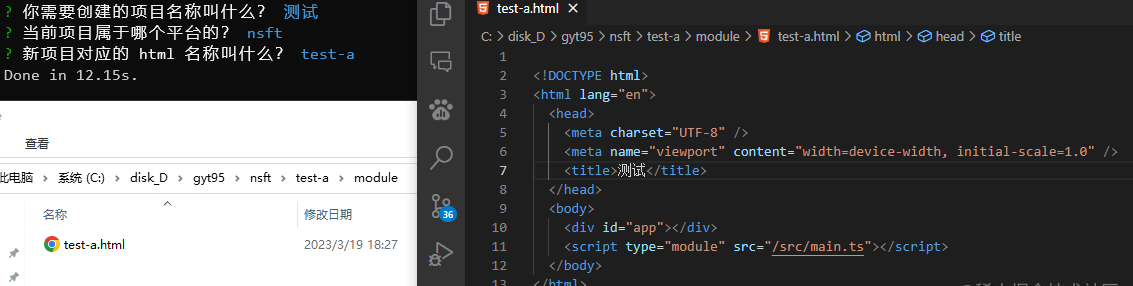
输入项目名称? > 数据图表
输入html名称? > data-charts
选择:所属平台? > nsft
其它:输入具体名称?
(如果输入非a-zA-Z则提示要输入英文单词)
(默认全转小写,而且不能和上面的同名,否则警告)
内部自动分配端口号,要改data.json
内部自动创建module目录,创建data-charts.html,内部title添加“数据图表”
内部自动创建src目录,对于App.vue要进行修改
内部创建package.json,修改对应的name
…
阶段1:询问后创建目录
我希望用户选择了问题3的“其它”时,会提供一个输入框让用户输入。
实现方式比较简单粗暴。代码如下:
#!/usr/bin/env node
import consola from 'consola'
import inquirer from 'inquirer'
import fs from 'fs-extra'
async function run() {
const { name, htmlName } = await inquirer.prompt([
{
type: 'input',
name: 'name',
message: '你需要创建的项目名称叫什么?'
},
{
type: 'input',
name: 'htmlName',
message: '新项目对应的 html 名称叫什么?'
}])
if (!name || !htmlName) return;
const { type } = await inquirer.prompt([
{
type: 'list',
name: 'type',
choices: [
{ name: 'nsft', value: 'nsft' },
{ name: 'SAY', value: 'say' },
{ name: '其它', value: 'others' },
],
message: '当前项目属于哪个平台的?'
}])
if (!type) return;
if (type === 'others') {
const { newPlatformName } = await inquirer.prompt([
{
type: 'input',
name: 'newPlatformName',
message: '新的平台叫什么?'
}])
if (!newPlatformName) return;
console.log(`\n正在为你创建新的平台 ${newPlatformName} 目录...`)
fs.ensureDir(newPlatformName)
}
}
run().catch(e => {
consola.error(e)
})
来看看效果:
对应目录下成功创建了平台。
这只是第一步。
优化1:当前用户如果选择的是已有平台,那么即将创建的目录会到对应平台。否则,会让用户自己输入一个,然后自动创建。
优化2:判断当前根目录的 data.json 中的 PORT 列表,是否包含这个htmlName ,如果是,则提示有重名,需要用户重新输入。否,则继续。
因此,针对优化1,流程要做修改。应该是先选择平台,检测后,再输入htmlName值。
然后就出现一些细节问题。
如何检测重名?
通过require('./data.json')拿到json数据,再通过PORT[type][htmlName]检测对应系统中是否包含同名的版块,是,则创建失败。否,则开始生成项目。
if(type !== 'others'){
try {
let json = fs.readFileSync('data.json', 'utf-8') // 直接用 fs.readFileSync
const { PORT } = JSON.parse(json);
if(PORT[type][htmlName]){
consola.error(`创建失败!当前所选择的 ${type} 平台存在同名的 html 名称`)
}
} catch (error) {
consola.error('当前目录下找不到data.json')
}
}
// 开始生成项目
// ...
注意:fs.readFileSync方法获取的值默认是buffer类型,所以传第二个参数utf-8才能返回我们要的数据。
针对优化2,又有细节问题。
因为不同平台属于不同工作区。那当前PORT是没有划分工作区,即所有平台的子项目的端口号都混淆在一个对象里。后期维护管理都不方便。所以这里我把PORT再次做了细分。
除了细分,还添加了一段逻辑:遍历PORT所有key,找到符合当前用户选择的平台,如果不存在,直接创建,并且端口号按照规则自增1000。如果已存在,则找到对应的key的最后一个子的key,拿到对应的端口号,并再按规则自增。这里涉及到fs模块的readFile和writeFile。
注意:最后writeFile时,要用JSON.stringify转换成字符串形式。
阶段2:内部自动生成html
难点:html 是自动生成、名字取决于用户输入的htmlName值,内部模板固定,但要嵌入用户输入的项目名称。
__dirname
直接使用发现报错:__dirname is not defined in ES module scope 。
以前 __dirname 在Node脚本中十分常用,因为可以获取当前JavaScript文件所在文件夹的路径。
但是如今! 如果在es模块下就无法直接使用__dirname了。(上文提到package.json里因为inquirer.js9.x 的原因而被迫写"type": "module",即采用esm语法。
解决办法:需要从原生Node模块url模块导入Node的url和fileURLToPath函数,然后可以通过以下方式自己搞一个和__dirname作用一样的值。
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
参考:fix-dirname-not-defined-es-module-scope – flaviocopes.com
虽然知道可以这么做,但我不知道这两个函数有什么用啊!赶紧去官方文档看一下。
fileURLToPath
作用:把 文件url 转换为 本地文件路径 。
像import.meta.url是当前vant-cli-app的bin/index.js这个文件的绝对路径。
console.log(import.meta.url);
const __filename = fileURLToPath(import.meta.url)
console.log(__filename);
// file:///C:/disk_D/packages/create-ektfe-cli-app/lib/index.js
// C:\disk_D\packages\create-ektfe-cli-app\lib\index.js
奇怪,怎么就会有 file:///呢?
file:/// 是什么?
file:///是一个 URL 协议,用于表示本地文件系统上的文件路径。在Node.js中,当我们读取本地文件时,文件路径通常是以file:///开头的 URL。
file:// 和 file:/// 有什么区别?
file://和file:///都是用于表示本地文件路径的 URL 协议,其中file:///是file://协议的扩展,用于更严格地表示文件路径。
file://是一种通用的文件 URL 协议,可以用于表示不同操作系统上的文件路径。例如:
- 在
Windows中,文件路径可能是file:///C:/path/to/file; - 在
macOS中,文件路径可能是file:///Users/user/Documents/example.txt。
在这种情况下,我们可以使用file://URL协议来表示文件路径,它在不同操作系统上都可以使用。
但是,在某些情况下,file://协议可能会有一些问题。例如,当文件路径中包含空格或非 ASCII 字符时,file://协议可能无法正确地解析文件路径。为了解决这个问题,file:///协议引入了更严格的语法来表示文件路径,以确保它们可以被正确地解析。
具体来说,file:///协议要求文件路径必须满足以下要求:
- 文件路径必须是绝对路径。
- 文件路径中的空格和非 ASCII 字符必须进行 URL 编码,例如空格应该被编码为
%20。
因此,当我们使用file:///协议来表示文件路径时,可以更加严格地保证文件路径的正确性。
但我仍然无法理解像file:///Users/user/Documents/example.txt这样的URL,它的三道杠 /// 是怎么解析的?
解析 file:/// 开头的文件路径
在Node.js中,可以使用内置的url模块来解析 URL。针对file:///Users/user/Documents/example.txt这个 URL,可以使用url模块的parse函数来解析该 URL,并获取其中的各个部分。具体代码如下:
const url = require('url');
const fileUrl = 'file:///Users/user/Documents/example.txt';
const parsedUrl = url.parse(fileUrl);
console.log(parsedUrl.protocol); // 'file:'
console.log(parsedUrl.pathname); // '/Users/user/Documents/example.txt'
在上面的代码中,我们首先引入了url模块,并定义了一个fileUrl变量,它包含要解析的 URL。然后,我们使用url.parse函数将fileUrl解析为一个 URL 对象。解析后,我们可以通过访问protocol和pathname属性来获取 URL 的协议和路径信息。
注意:在解析file:///协议的 URL 时,url.parse函数会将file:///协议解析为file:,并将/视为路径的一部分。因此,在解析后的 URL 对象中,路径信息存储在pathname属性中,且路径前会自动添加一个/符号。
即file:后的///会拆分为//和/, /会变成路径的一部分。所以在pathname里前缀添加/符号。
解析 file:// 开头的文件路径
与file:///协议不同,file://协议不要求文件路径必须是绝对路径,并且不需要对空格和非 ASCII 字符进行 URL 编码。因此,在解析file://协议的 URL 时,我们需要针对具体的 URL 规范进行解析。
一种常见的解析方法是,使用正则表达式来匹配 URL 中的各个部分。
const fileUrl = 'file://Users/user/Documents/example.txt';
const parsedUrl = fileUrl.match(/^file://([^/]+)(/.*)?$/);
console.log(parsedUrl[1]); // 'Users'
console.log(parsedUrl[2]); // '/user/Documents/example.txt'
正则表达式包括两个分组,分别用于匹配主机名和文件路径。
^表示字符串开始。
file://表示file://字符串。
([^/]+),^指的是“非”,+指的是至少1个。所以这里表示多个非/的字符。括号表示一个捕获组。
(/.*)?,/指的是/,结合起来就是/.* ,例如上面的example.txt。一个可选的捕获组,匹配一个以 / 开头,后面跟着任意字符的字符串,括号表示一个捕获组,?表示该组为可选,即字符串中可能不存在该部分
在正则表达式中,.表示匹配任何单个字符,而*表示匹配前一个字符0次或多次。所以,.*组合在一起表示匹配任意数量的任何字符(包括0个字符),直到遇到下一个匹配规则或者字符串的结尾。
那么问题来了:fileURLToPath(import.meta.url)中的import.meta.url是啥?
import.meta.url
首先,import.meta是一个在es模块内部可直接使用的对象。它包含的是关于模块运行环境的信息。运行环境可以是浏览器,也可以是Node。
其次,import.meta对象是可扩展的,宿主(浏览器/Node)可以把任何有用的信息写进去。
因此,浏览器和Node都给import.meta写入url。
所以import.meta.url就是你运行那个文件的绝对路径,但是只是个url 。
一般会通过fileURLToPath这个函数,进行转换。
file:///C:/xxx/xxx/bin/index.js👉C:\xxx\xxx\bin\index.js
然后像vite源码的create-vite中,src/index.ts里有一行path.resolve(filename, '../..', template-${template}),要拿到某个template模板目录进行拼接。(src和template-xx是同级的)
通过fs.readdirSync(templateDir)读取目录。得到的files,遍历,通过write函数写入。
write函数内部,会通过path.join拼接root和file。root是path.join(cwd, targetDir),而cwd就是process.cwd()。
process.cwd()
官方文档描述:返回 Node.js 进程的当前工作目录。
就是你执行yarn create vant-cli-app的当前目录的绝对路径。
啊!这个才是我想要的!就是想要获取当前所在的目录。
奇怪!那上文的 __dirname 是?
它是当前正在执行的文件的目录的绝对路径。也就是说,当前我执行的yarn create vant-cli-app,对应执行的是bin字段指向的文件,而这个文件的绝对路径,才是__dirname的值!
这里的__dirname是通过path.dirname接收__filename来得到的。
path.dirname
官方描述:获取传入的文件的父目录。
结合下图应该更明白了!

区分 process.cwd 和 __dirname
process.cwd:当前你执行命令所在的目录的绝对路径
__dirname:当前正在执行的文件所在目录的绝对路径
ok!回到上面create-vite的path.join(cwd, targetDir)。
那targetDir是啥?
在create-vite/src/index.ts的 init 函数里有个getProjectName函数,内容是判断targetDir是否为 ‘.’,是,path.basename(path.resolve()),否,直接用
首先,我尝试在当前路径C:\disk_D\gyt95执行命令输出看看
console.log(path.resolve()); // C:\disk_D\gyt95
console.log(path.basename(path.resolve())); // gyt95
找官方文档看看描述。
path.basename()
官方描述:返回路径的最后一部分,类似于Unix的basename命令。忽略尾随目录分隔符。而且区分大小写。
path.win32.basename('C:\foo.html', '.html');
// Returns: 'foo'
path.win32.basename('C:\foo.HTML', '.html');
// Returns: 'foo.HTML'
所以,上面的path.basename(path.resolve())就返回最后一部分,即gyt95。
那么,path.resolve()是什么?
path.resolve()
官方描述:将一系列路径或路径段解析为绝对路径。如果没有传递路径段,path.resolve()将返回当前工作目录的绝对路径。
因此,path.resolve()返回的就是当前工作目录的绝对路径,即C:\disk_D\gyt95。
知道了获取当前目录路径后,就要进入对应平台名称的目录里创建htmlName ,但不需要真的进行“进入”的操作,因为write本身就有 “进入然后把数据写进去”的意思。(刚开始还一直找有什么函数可以进入某个目录)
但执行报错,因为不能用cjs格式的require,我写的是require('data.json')
解决办法:用Node的fs模块读取当前是否存在这个文件。
根据经验,是有fs.exist的。查了下文档,发现原来Node的v16.19.1已经弃用,建议改用fs.stat或者fs.access。
当前,我们要在htmlName的目录下创建一个module空目录,已知mkdir创建目录。如何实现?
其实超级简单!!你直接判断这个路径,fs.ensureDir方法能直接判断你这个路径是否存在,如果不存在,能直接帮你创建这整个路径下的目录。。
创建完毕后,我直接利用fs.writeFile创建 html 文件!
完成 template 动态生成!
const moduleTemplate = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>${name}</title>
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.ts"></script>
</body>
</html>
`
// ensureDir 可以判断当前平台是否存在 htmlName 是否存在 module 目录
const modulePath = `${platformName}/${htmlName}/module`
try {
await fs.ensureDir(modulePath)
await fs.writeFile(`${modulePath}/${htmlName}.html`, moduleTemplate, 'utf-8')
} catch (error) {
console.log(error)
}
看看效果
进阶1:动态生成平台选项
目前,提供的平台选项是写死的。
我们希望:平台选项是根据当前目录所有非packages等特殊目录而自动生成的。用一个数组存起来。
如果数组为空,就提示找不到任何平台,请输入一个。
如果数组不为空,就展示给用户进行选择。
此时用户觉得都不是以上的平台,那么就选择最后一个选项“以上都不是”,就会提示请自行输入一个。
首先,如何获取当前执行 node 的路径下所有目录的名称?
可以通过fs.readdirSync()方法读取当前路径下的所有目录和文件,然后使用path模块中的path.join()方法来将当前路径和目录名称拼接成一个完整的路径,最后使用fs.stat()方法判断这个路径是否是一个目录。如果是目录,就将它的名称存储到一个数组中。
fs.readdirSync
官方描述:同步方式读取指定目录下所有文件和子目录名称。
但以上的思路有个问题:如果遇到.开头的文件,就会报错。可以通过给fs.readdirSync设置withFileType:true获取所有目录和文件的信息,以下是代码和区别
const currentNoInfoDirFiles = fs.readdirSync(cwd)
console.log(currentNoInfoDirFiles);
const currentDirFiles = fs.readdirSync(cwd,{ withFileTypes: true })
currentDirFiles.forEach(v => console.log(v, v.isDirectory()));
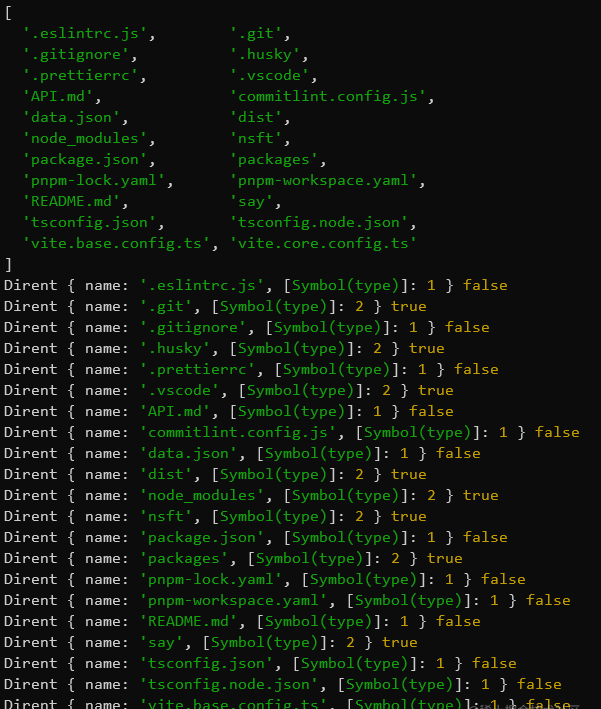
可以看到尽管能通过fs.isDirectory()判断是否为目录,但仍然有一些.开头的目录,需要过滤。并且,还有些特殊项目要过滤。综上,代码最后如下:
const BAN = ['packages', 'dist', 'node_modules'] // 这里看你需要自行添加,我的特殊目录就这些
currentDirFiles.forEach(file => {
if(file.isDirectory() && !file.name.startsWith('.') && !BAN.includes(file.name)){
currentPlatforms.push({
name: file.name,
value: file.name
})
}
})
currentPlatforms.push({ name: '其它', value: 'others' })
const { type } = await inquirer.prompt([
{
type: 'list',
name: 'type',
choices: currentPlatforms,
message: '当前项目属于哪个平台的?',
},
])
当输入新的名字时,我们再做一些处理,避免用户故意写特殊目录的名字。
if (type === 'others') {
const { newType } = await inquirer.prompt([
{
type: 'input',
name: 'newType',
message: '新平台的英文名称叫什么?',
},
])
if (!newType) return
fs.ensureDir(newType.toLowerCase())
if(BAN.includes(newType)){
consola.error('不能填写以下名称:packages, dist, node_modules')
return;
}else if(currentPlatforms.includes(newType)){
consola.error('这个名字已经存在!重来!')
return;
}
consola.info(`正在为你创建新的平台目录 ${newType}...`)
consola.info(`为了统一命名规范,会自动转为小写...`)
platformName = newType
} else {
platformName = type
}
进阶2:提取 template
上文看到我们直接定义变量moduleTemplate。但是更好的办法可以写template.html.tpl。
原本我也想过这个办法,但是不明白怎么去自定义template的 html 名称,不知道怎么改。
(不明白就对了,不明白就去了解它!)
直到后来我看了下Vant的实现方式,因为create-vant-cli-app里的模板包含package.json.tpl。
因此,我们要从create-vite回来,看回create-vant-cli-app的实现思路。过程中涉及一系列Node的模块的API,会逐一描述。
主要是writing函数和copyTpl函数,实现原理是这样的:
- 首先拿到 templatePath ,具体实现:
// this.inputs.vueVersion 的值是用户选择选项 Vue2/Vue3 传入的,对应的值为 vue2/vue3
const __filename = fileURLToPath(import.meta.url)
const __dirname = path.dirname(__filename)
GENERATOR_DIR = path.join(__dirname, '../generators');
const templatePath = path.join(GENERATOR_DIR, this.inputs.vueVersion).replace(
/\/g,
'/'
);
path.join
作用就是用特定于平台的分隔符将所有传入的路径段落拼接在一起。
(纯粹拼接。如果参数1是 .., 拼接../generators就变成 ....\generators ,如果是 __dirname 即执行文件的目录的绝对路径例如 C:\disk_D,拼接../generators后就会变成C:\disk_D\generators)
这里还有个关键点! 虽然我们在代码里写的是 /,但实际上Windows上打印出来的是Windows自己的分隔符“,也就是说,会自动转义。那上文能不能不使用replace转义呢?
本来以为不行,但其实是可以的。因为path.join会用对应平台特定的分隔符来拼接。但像create-vant-cli-app这里添加了replace是因为之前有 issue 说 Windows10 系统下执行yarn create vant-cli-app 后只出现一个node_modules。所以还是建议replace一下。
根据上文提到的 __dirname 作用可知,实际上对应的是 lib/index.js ,那么 ../generators ,刚好就是和 lib 目录同级的 generators 。
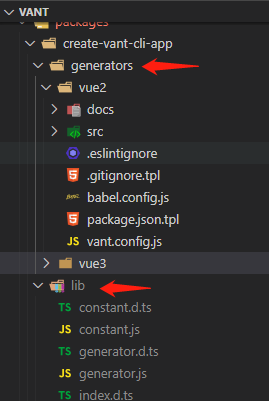
这里用replace方法把\都改为/。(注意:这里\\第一个\是JS的转义字符,下文立刻会说)
因此,用户选择Vue3时,获取路径是to/path/generators/vue3 。而 to/path 是绝对路径。
可以用fileURLToPath解决。
路径分隔符 \ 和 / 的区别?
都是路径分隔符。
在 Windows 操作系统中,路径分隔符通常是反斜杠(\),而在 Unix和类 Unix 操作系统(如 Linux 和 macOS)中,路径分隔符通常是正斜杠(/)。
在JavaScript中,反斜杠也可以用作转义字符。因此,如果你在 Windows 操作系统上编写JavaScript 代码并使用反斜杠作为路径分隔符,那么在某些情况下可能需要将路径中的反斜杠字符替换为斜杠字符,以确保正确解析路径。
- 接着拿到 templateFiles ,具体实现:
const templateFiles = glob.sync(
join(templatePath, '**', '*').replace(/\/g, '/'),
{
dot: true,
}
);
刚才得到了 vue3 模板的绝对路径,现在通过 path.join 拼接出 to/path/generators/vue3/**/* 路径(是的,path.join 会自动加分隔符)
这里提到了 glob 。用的是 fast-glob 这个库,那么 glob 是什么?
glob
通过星号等 shell 所用的模式匹配文件。它一般被用来查找指定目录下的所有文件和子目录glob.sync只是同步方式。
早期Unix(第 1-6 版,1969-1975)的命令行解释器依赖独立程序/etc/glob展开参数中的通配符。这个程序会展开通配符并把展开后的文件列表传给命令。它的名字是 “global command” 的简称。后来这个功能由工具函数 glob() 提供,被shell 等程序使用。(译自 WikiPedia)
(再次和Unix相关的知识点联系上)
其实就像这样的模式:用在命令行中的ls *.js,用在 .gitignore 文件中的 build/*。
所有用到 * 的路径可以用 glob 进行匹配。
这里有个参数{ dot: true },它是glob库中的一个选项,用于匹配隐藏文件(以 . 开头的文件)。如果将 dot 设置为 true,则glob.sync()将会匹配隐藏文件,否则将会忽略这些文件。(而这里因为create-vant-cli-app的vue2/vue3模板里都有.gitignore .eslintignore这样的以点号.开头的文件,所以要带上这个属性)
在上面的代码中,dot: true 表示匹配所有文件,包括隐藏文件。
- 遍历 templateFiles
templateFiles.forEach((filePath) => {
const outputPath = filePath
.replace('.tpl', '')
.replace(templatePath, this.outputDir);
this.copyTpl(filePath, outputPath, this.inputs);
});
每个路径都把.tpl字眼replace为空字符,再替换templatePath为输出目录。然后调用copyTpl方法,传入3个值: filePath每个模板文件路径,outputPath输出路径,this.inputs用户输入的所有信息集合。最后这个this.inputs是copyTpl方法要根据用户输入的信息,对.tpl文件进行内容动态修改。
为什么要替换为输出路径?
目的是将模板文件的路径替换为在新项目中的相应路径。这是为了确保生成的文件被正确地放置在新项目的相应位置上,并避免任何文件名冲突。
看下注释版
// 已知: outputDir 是 C:\aaa\username\projectName
// 已知: templatePath 是 C:\xxx\vant\create-vant-cli-app\generators\vue3
templateFiles.forEach((filePath) => {
// filePath 是 C:\xxx\vant\create-vant-cli-app\generators\vue3\package.json.tpl
const outputPath = filePath
.replace('.tpl', '')
// 变成:C:\xxx\vant\create-vant-cli-app\generators\vue3\package.json
.replace(templatePath, this.outputDir);
// 变成:C:\aaa\username\projectName\package.json'
this.copyTpl(filePath, outputPath, this.inputs);
});
- 执行 copyTpl 方法
已知,每个模板文件都会调用一次这个方法。那么以create-vant-cli-app为例,看看内部实现:
- 通过
fs.copySync把源路径文件,复制到,目标路径。即输出的目录里 - 通过
fs.readFileSync读取输出路径下文件内容 - 遍历用户输入的集合
this.inputs,通过正则表达式,查找是否有对应的模板语法 <%= ${key} %> ,有,替换为 key为name 所对应的 value - 遍历完毕就通过 fs.writeFileSync 把新的内容写入到输出文件里
function copyTpl(from: string, to: string, outputDir: string, args: Inputs) {
// 4-5-1 复制文件
fs.copySync(from, to)
// 4-5-2 读取文件
let content = fs.readFileSync(from, 'utf-8') // utf-8 是为了获取非 buffer 类型数据
// 4-5-2 遍历,替换掉模板语法
Object.keys(args).forEach(key => {
// 在正则表达式中,'g'代表全局匹配模式,表示匹配字符串中所有符合条件的子串
const reg = new RegExp(`<%= ${key} %>`, 'g')
content = content.replace(reg, args[key as keyof Inputs])
})
// 4-5-3 写回输出目录的对应文件
fs.writeFileSync(to, content)
// 4-5-4 动态改名
if (path.basename(to) === 'template.html') {
const newToPath = to.replace('template.html', `${args.htmlName}.html`)
fs.renameSync(to, newToPath)
}
// 4-5-5 提示成功
// 把目标路径的前面部分和平台分隔符去掉,剩下的就是文件名了
const name = to.replace(outputDir + path.sep, '')
consola.success(`${color.green('创建')} ${name}`)
}
注意:第11行有一个g,不要误以为是字符了。。这在正则表达式里表示开启全局匹配模式。
fs.writeFileSync
当 file 是文件名时,同步将数据写入文件,如果文件已存在则替换该文件。数据可以是字符串或缓冲区。
当 file 是文件描述符时,其行为类似于直接调用 fs.write()(推荐)
参数介绍:
- path:要写入的文件的路径(必需参数)。
- data:要写入到文件中的数据(必需参数)。
- options:一个可选的选项对象,用于指定文件的编码、文件模式、文件权限等(可选参数)。
- encoding:一个可选的编码字符串,用于指定写入文件时使用的编码格式(可选参数)。如果省略此参数,则默认使用UTF-8编码。
这里包含动态修改 template.html.tpl 名称。 (create-vant-cli-app没有这一步)
由于模板的名称叫template.html.tpl,但具体项目的 html 应该是对应projectName的。
这里可以用fs模块的一个方法renameSync。
fs.renameSync
官方描述:将文件从 oldPath 重命名为 newPath。返回 undefined 。
if(path.basename(to) === 'template.html'){
const newToPath = to.replace('template.html', `${htmlName}.html`)
fs.renameSync(to, newToPath)
}
到了这里,才完成读取-遍历-写入,3个步骤。
- 附加写入成功提示,这里用到了 path.sep
path.sep
官方描述:提供特定于平台的路径段分隔符。例如Windows下是这样的:
'foo\bar\baz'.split(path.sep);
// Returns: ['foo', 'bar', 'baz']
在Windows上,正斜杠 (/) 和反斜杠 () 都被接受为路径段分隔符;但是,路径方法只添加反斜杠 ()。
以下是具体代码👇
copyTpl(from: string, to: string, args: Record<string, any>) {
fs.copySync(from, to);
let content = fs.readFileSync(to, 'utf-8');
Object.keys(args).forEach((key) => {
const regexp = new RegExp(`<%= ${key} %>`, 'g');
content = content.replace(regexp, args[key]);
});
fs.writeFileSync(to, content);
const name = to.replace(this.outputDir + sep, '');
consola.success(`${color.green('create')} ${name}`);
}
小结:copyTpl方法作用是复制模板里的文件到指定目录。其中包含类似于模板引擎的语法替换。把.tpl文件里的<$= key $>替换为对应的值。
有了上面的步骤,直接就生成剩下的文件了,包括package.json。
阶段3:内部自动生成目录及文件
其实就是上面的源码解析实现一次。
第三个小目标:制作欢迎界面
这部分没有点创意是不行的。让 ChatGPT 帮我想办法,结果做出来的欢迎界面至少我个人挺喜欢的。
import color from 'picocolors'
import boxen, { Options } from 'boxen'
import gradientString from 'gradient-string'
// 终极版
const welcomeMessage = gradientString('cyan', 'magenta').multiline(
['Hello! 欢迎使用EKTFE脚手架~', '😀🎉🚀'].join('')
)
const boxenOptions: Options = {
padding: 1,
margin: 1,
borderStyle: 'round',
borderColor: 'cyan',
backgroundColor: '#000',
}
console.log(boxen(welcomeMessage, boxenOptions))
具体的话,去GitHub搜下对应的库就好。
效果如图:
第四个小目标:发布并用于实践
是否要发布 npm 包?
我们公司是没有私有服务器的。如果要发布,就只能发布到外网 npm 上。那假如不发布到 npm ,其实也不是不行。就只要让对方在create-cli-app执行yarn link,然后在根目录执行yarn create xxx即可。这种做法,对于网络不好的时候,这是个好办法。
最后我选择发布到外网,反正也不是什么商业机密。像之前提到的“平台选项”,不写死,没啥问题。可以说是通用的了。
而且发布到外网,使用起来比本地使用要方便,至少少了一步yarn link。
主要的发布流程:(估计都被说烂了。但其实开发脚手架也是被说烂了,但我还是写了)
你只要注册 npm 账号,再通过yarn login和yarn publish就可以发布了。(或者用npm login和npm publish)
后续优化
1.当出现多个模版时,需要创建多个template,并提供给用户进行选择。
2.某些项目可能从一开始就要安装一些库,例如echarts。后期可以增加一个列表选项进行多选添加,这里估计又是知识盲区了。前期其实基于根目录的依赖项就行。
3.目前containers目录下的子目录名称等还没有变成自动化,不过方式和前文提到的template类似。可以后期再写。
4.代码层面的优化。
其它问题
.eslintrc.js 继承外部导致路径错误?
module.exports = {
extends: ['../../.eslintrc.js'],
}
原本打算通过lint-staged .eslintignore这类方式来跳过对template的eslint检测。但发现不行。
最后想了个办法,直接把.eslintrc.js更名为.eslintrc.js.tpl就失去了它原本的作用了,复制文件时会去掉.tpl的后缀,就又恢复了。
打包构建之前如何清理 lib 目录?
直接用rimarf不行。
rimraf 是什么?
一个用于递归删除文件和文件夹的 npm 包。在Windows上,由于文件夹路径的斜杠方向与Unix系统不同,因此rimraf会出现一些问题。
可以使用cross-env这个库,可以跨平台地设置环境变量。
"build": "cross-env rimraf lib && tsc"
也可以使用del这个库。
"build": "del lib && tsc"
如何用命令行创建LICENSE?
发现还没有许可证,发现网上大多数是可视化创建,我想用命令行,license-generator这个库可以解决。
小结
这篇文章是随着我阅读源码到开发脚手架整个过程一直写下来的,过程中看过Vant的源码、Node文档、Yarn 文档,以及各种库的文档,后来因为开始用 ChatGPT ,就决定试试在为我的日常工作学习提供一些帮助。
每天花一些时间开发脚手架、涉及的各种细节还要做笔记(因为几乎全是本人知识盲区)。不得不说涉及的知识点还是挺多。用了一周时间终于完成。再用近一周的时间基于业务进行优化,并且要重新整理文章。整理文章这个过程耗时很久,一是因为一直做笔记下来,后面的理解有时推翻前面的,所以前面可能存在错误的认知还有一些多余的推测,所以需要重看自己之前写的内容,很多不需要的就去掉,还有很多排版等问题。另外,为了可读性补上行内代码的样式,体力活,我还是喜欢直接空格多一些,写起来舒服,但不利于阅读。
原标题其实是“关于我编写一个脚手架顺便看完几个开源库源码的事”,但无奈就以上这点内容搞了很久,所以只能后续再研究。
收获
- 对
yarn的一些命令、package的安装和执行、package.json各种字段、脚手架的基本实现原理,都有较深刻的认识; - 把
create-vant-cli-app项目源码读完,虽然代码量超级少。但细节还是有的,主要是复习了不少Node常用的知识点(同理,可以把create-vite等等也尝试拿下); - 输出了一个基于业务的定制化脚手架。通用脚手架多的是,基于业务才是重点;
- 有趣的是,因为是定制化,所以提示语可以写直白点。如果是开源的通用脚手架,就要正式口吻;
- 后期使用了 ChatGPT 解决了一小部分问题,它的好处是对于一些不太难但找起来比较麻烦的知识点可以很快给出一个思路。如果遇到一些问题卡住了,去询问它比你查资料要快,然后比如说它抛出了一个 API ,我就会去文档里找,确实快了不少。部分代码优化也可以借助它。不过它也经常会一本正经胡说八道,所以如果没训练到位的话,注意不要被它忽悠了。
NEXT
先看下create-vite和create-vue等源码。然后开始看vant-cli和vite。
原文链接:https://juejin.cn/post/7214314627520282661 作者:gyt95