
前言
讨论问题于前,我们首先要理解可读流的机制:
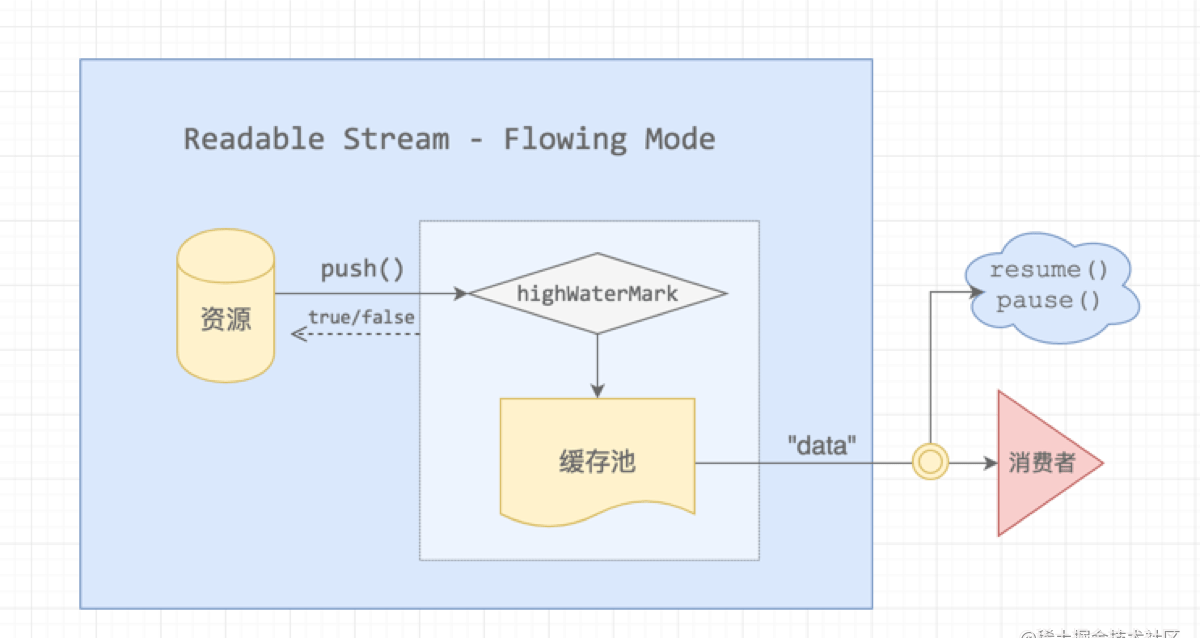

可以看到可读流是通过内部的this.push方法把数据放到缓存池,然后给data事件的回调函数用的。举个例子,我们自定义一个可读流:
const { Readable } = require('stream');
const data = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
const readableStream = new Readable({
highWaterMark: 3,
read() {
const chunk = data.shift();
this.push(chunk)
},
});
readableStream.on('data',(data)=>{
console.log('data: ', data);
})
当readableStream注册data事件的时候,流就会源源不断的调用read方法,把数据拿来。
好了,我们接着看pipe方法。
我一直不明白,pipe方法为什么不去限制读取速度,为什么这么说呢,我们从pipe方法的简单实现开始讨论,如下:
pipe(ws){
// pipe的时候就已经开始读数据了,读数据的同时还会写数据
// 如果读的太快
this.on('data',(chunk)=>{
let flag = ws.write(chunk);
if(!flag){
this.pause();
}
});
ws.on('drain',()=>{
this.resume();
})
}
代码中的 pipe 方法会自动将可读流中的数据传递给可写流,并在数据传递过程中自动处理流的状态变化、数据流量控制等问题。
在这个过程中,如果可写流的缓冲区已满,无法写入更多的数据,此时可读流会暂停(pause())读取数据,等待可写流处理完缓冲区中的数据后再继续读取数据;
而当可写流的缓冲区变为空时,会触发 drain 事件,此时可读流会继续读取数据(resume())。
疑问
看似没有问题,但是我的疑问是,pipe函数只限制了写入的速度,也就是写入ws.write(chunk),写入到可写流缓存区时,如果缓存区数据过多,就暂停上游可读流。
为什么没有可读流读数据过快,可读流缓存区数据过多,就暂停往可写流缓存区写数据的逻辑呢?
我看了很多网上的文章,包括源码分析,感觉还是没有解决这个问题,索性就自己调试一下源码了。以下是调试方法和调试记录
分析完这个问题后,自己顺便也搞定了另外两个疑问:
- 自定义可写流,如果不调用next函数,流会停止吗,源码如何实现导致这样的情况?
- transform流的实现原理是什么,它内部做了背压处理吗?
调试方法
我用的是chrome浏览器来协助看源码的方式(js代码,如果要看c++的话不太适合)
node --inspect-brk index.js
然后在chrome://inspect/#devices中,能看到一个Remote Target的一个列表,点击inspect即可进入调试页面。
然后进去
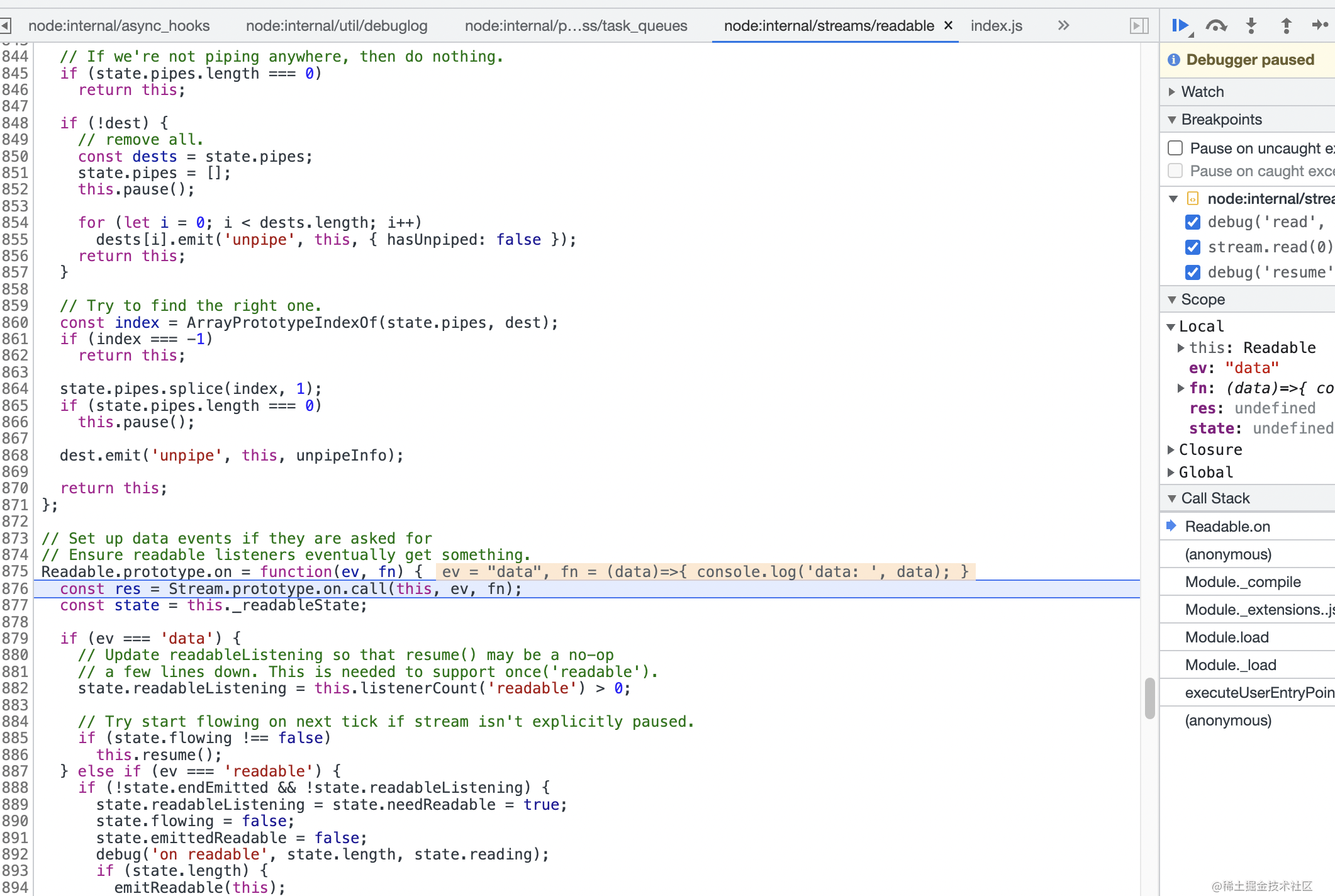
点击右上角的调试按钮即可一步一步的看代码了,走到readableStream.on这里,我们进入函数,就可以看到node源码了

readable的js源码如下:
正式调试
我们用的案例如下
const { Readable } = require('stream');
const data = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
const readableStream = new Readable({
highWaterMark: 3,
read() {
const chunk = data.shift();
this.push(chunk)
},
});
readableStream.on('data',(data)=>{
console.log('data: ', data);
})
重点是highWaterMark为3,我们每次往里面放一个字节。后面我们还会举例,如果一次性放5个字节,超过highWaterMark又会怎么样。
首先进入了on方法,注册data事件,一旦注册data事件,就会调用resume方法(开启流动模式)
// Ensure readable listeners eventually get something.
Readable.prototype.on = function(ev, fn) {
const res = Stream.prototype.on.call(this, ev, fn);
const state = this._readableState;
if (ev === 'data') {
// Update readableListening so that resume() may be a no-op
// a few lines down. This is needed to support once('readable').
state.readableListening = this.listenerCount('readable') > 0;
// Try start flowing on next tick if stream isn't explicitly paused.
if (state.flowing !== false)
this.resume();
} else if (ev === 'readable') {
if (!state.endEmitted && !state.readableListening) {
state.readableListening = state.needReadable = true;
state.flowing = false;
state.emittedReadable = false;
debug('on readable', state.length, state.reading);
if (state.length) {
emitReadable(this);
} else if (!state.reading) {
process.nextTick(nReadingNextTick, this);
}
}
}
return res;
};
res其实就是继承的Event模块,所以返回的res可以调用on方法来注册data事件
state返回的是Readable,标记的是当前可读流的一些属性,例如初始化时:
- buffer: 这是缓冲区的对象,是一个链表结构,BufferList {head: null, tail: null, length: 0}
- flowing: null,表示是否是流动状态,因为我们这里只看流动模式,这个变量比较重要
- highWaterMark: 3,表示缓冲区大小,单位为字节
- reading: false,是否正在读数据
- sync: true,是否是同步读取数据
这里可以看到,因为state.flowing !== false,所以直接进入了 this.resume();
我们接着看resume
Readable.prototype.resume = function() {
const state = this._readableState;
if (!state.flowing) {
debug('resume');
// We flow only if there is no one listening
// for readable, but we still have to call
// resume().
state.flowing = !state.readableListening;
resume(this, state);
}
state[kPaused] = false;
return this;
};
因为state.flowing是null,所以 state.flowing = ture(state.readableListening初始化为false),继续调用resume
function resume(stream, state) {
if (!state.resumeScheduled) {
state.resumeScheduled = true;
process.nextTick(resume_, stream, state);
}
}
state.resumeScheduled初始化也是false,调用了process.nextTick,在本轮事件循环末尾执行resume_。我们接着等待执行process.nextTick。
function resume_(stream, state) {
debug('resume', state.reading);
if (!state.reading) {
stream.read(0);
}
state.resumeScheduled = false;
stream.emit('resume');
flow(stream);
if (state.flowing && !state.reading)
stream.read(0);
}
因为state.reading初始化是false,所以走到 stream.read(0);我们接着看read方法
Readable.prototype.read = function(n) {
n = howMuchToRead(n, state);
let doRead = state.needReadable;
if (state.length === 0 || state.length - n < state.highWaterMark) {
doRead = true;
}
if (state.ended || state.reading || state.destroyed || state.errored ||
!state.constructed) {
doRead = false;
debug('reading, ended or constructing', doRead);
} else if (doRead) {
debug('do read');
state.reading = true;
state.sync = true;
// If the length is currently zero, then we *need* a readable event.
if (state.length === 0)
state.needReadable = true;
// Call internal read method
this._read(state.highWaterMark);
state.sync = false;
// If _read pushed data synchronously, then `reading` will be false,
// and we need to re-evaluate how much data we can return to the user.
if (!state.reading)
n = howMuchToRead(nOrig, state);
}
let ret;
if (n > 0)
ret = fromList(n, state);
else
ret = null;
if (ret === null) {
state.needReadable = state.length <= state.highWaterMark;
n = 0;
} else {
state.length -= n;
if (state.multiAwaitDrain) {
state.awaitDrainWriters.clear();
} else {
state.awaitDrainWriters = null;
}
}
if (state.length === 0) {
// If we have nothing in the buffer, then we want to know
// as soon as we *do* get something into the buffer.
if (!state.ended)
state.needReadable = true;
// If we tried to read() past the EOF, then emit end on the next tick.
if (nOrig !== n && state.ended)
endReadable(this);
}
if (ret !== null) {
state.dataEmitted = true;
this.emit('data', ret);
}
前
return ret;
};
因为刚开始,我们的缓存区肯定是没有数据的,所以state.length === 0 是true, 首先会走到
if (state.length === 0 || state.length - n < state.highWaterMark) {
doRead = true;
}
然后走到
if(doRead) {
state.reading = true;
state.sync = true;
// If the length is currently zero, then we *need* a readable event.
if (state.length === 0)
state.needReadable = true;
// Call internal read method
this._read(state.highWaterMark);
}
也就是触发我们之前在readableStream上自定义的read方法,
read() {
const chunk = data.shift();
this.push(chunk)
},
也就是最终调用了push方法,push方法最终调用了addChunk方法,因为判断条件是:
if(chunk && chunk.length > 0){
addChunk...
}
addChunk方法最终在这里判断是否是直接把数据给data事件的回调函数,还是写入到buffer缓冲区里(在初始化的时候,顺便把state.reading改为了false)
state.flowing && state.length === 0 && !state.sync &&
stream.listenerCount('data') > 0
因为之前state.sync已经被改为true,也就是同步读取代码,所以上面的表达式为false,如果是false就会把数据放到缓存区,也就是buffer上,如果是true就会把数据直接给data事件的回调函数。
然后调用maybeReadMore函数,会一直重复调用stream.read(0),直到缓冲区的大小大于等于highWaterMark。
但是这个任务是放在process.nextTick中执行的,我们接着看之前resume_函数没有执行完的地方(主要是掉了flow方法,源码如下)
function flow(stream) {
const state = stream._readableState;
debug('flow', state.flowing);
while (state.flowing && stream.read() !== null);
}
会一直调stream.read(),我们看看如此调用read方法有啥用,它会继续调this.push,push又开始调addChunk,此时因为state.length不等于0了,因为之前已经给缓存区push了数据,所以还会继续往缓存区push数据。
read(0) —> read()方法,然后读取howMuchToRead计算的数据量,然后通过emit方法返回给data事件的回调函数。
因为之前flow函数有个while循环一直调用stream.read(),就会把数据源源不断的给data事件。
结论1
如果push的数据小于highwaterMark则会读一点就马上给data,不存在我说的pipe会把缓存区撑爆的可能。所以pipe方法的处理是没有问题的。
换一个案例:如果push比highWaterMark大的数据会怎样
我们换一个上来就push比highWaterMark大的数据
const { Readable } = require('stream');
const readableStream = new Readable({
highWaterMark: 3,
read() {
const chunk = 'abcdefg';
this.push(chunk)
},
});
readableStream.on('data',(data)=>{
console.log('data: ', data);
})
最开始肯定是调用read(0)开启流动模式,跟上面是一样的,也会走到flow方法调用read函数,关键就在于此时read函数如何处理。
首先,read()方法没有传参
if (n === undefined) {
n = NaN;
} else if (!NumberIsInteger(n)) {
n = NumberParseInt(n, 10);
}
const nOrig = n;
导致n等于NaN,并赋值给nOrig。
然后调用
n = howMuchToRead(n, state);
计算最新的n的值,howMuchToRead中这样解决:
if (NumberIsNaN(n)) {
// Only flow one buffer at a time.
if (state.flowing && state.length)
return state.buffer.first().length;
return state.length;
}
判断n是NaN的话 return state.buffer.first().length;
因为read(0)的时候,已经把push的数据放到了state.buffer上的链表第一个位置上,所以这时候返回了这个buffer数据的长度,我们传了’abced’,所以这里的长度是5。也就是n会赋值为5。
然后因为
if (state.length === 0 || state.length - n < state.highWaterMark) {
doRead = true;
debug('length less than watermark', doRead);
}
state.length – n < state.highWaterMark为true(state.length 在最开read(0)的时候就已经是5了,现在调用read,结果n的值还是5)所以这里为true
但是也有可能第二次读的数据是1,那么 state.length – n < state.highWaterMark就为false了,这种情况下会直接把这1个数据给data事件,而不用去调_read方法。
这样的话也会有问题,比如每次读100MB的数据,虽然没有撑爆内存,但是会一直保持每次push(100MB)的内存使用,所以在push数据的时候,一定不要数据量过大。
最后触发data事件,把那5个字符传给data的回调函数。
结论
pipe函数的处理方式没有大问题,原因是一般情况下,我们的每次push的数据都会小于highwaterMark,所以会出现我们第一个案例的情况
就是每次读一次数据,触发一次data事件,直到push数据结束。
但是第二个案例也告诉我们,如果每次push的数据大小过大,内存会维持一个较大的使用量,不建议这样做,所以如果你要自定义可读流,一定要把每次push的数据限制大小。这样应用的性能会更好!
所以说pipe虽然处理了背压,但使用者自己也要注意可读流的每次的大小。
自定义可写流,如果不调用next函数,流会停止吗,源码如何实现导致这样的情况?
有的同学可能不清楚自定义可写流如何实现,我们先简单了解下:
const Stream = require('stream');
const writableStream = Stream.Writable();
writableStream._write = function (data, encoding, next) {
setInterval(() => {
next();
}, 1000);
}
writableStream.on('finish', () => console.log('done~'));
writableStream.write('写入数据,');
writableStream.end();
如上,只要write方法会调用_write,_write接收写入的数据。
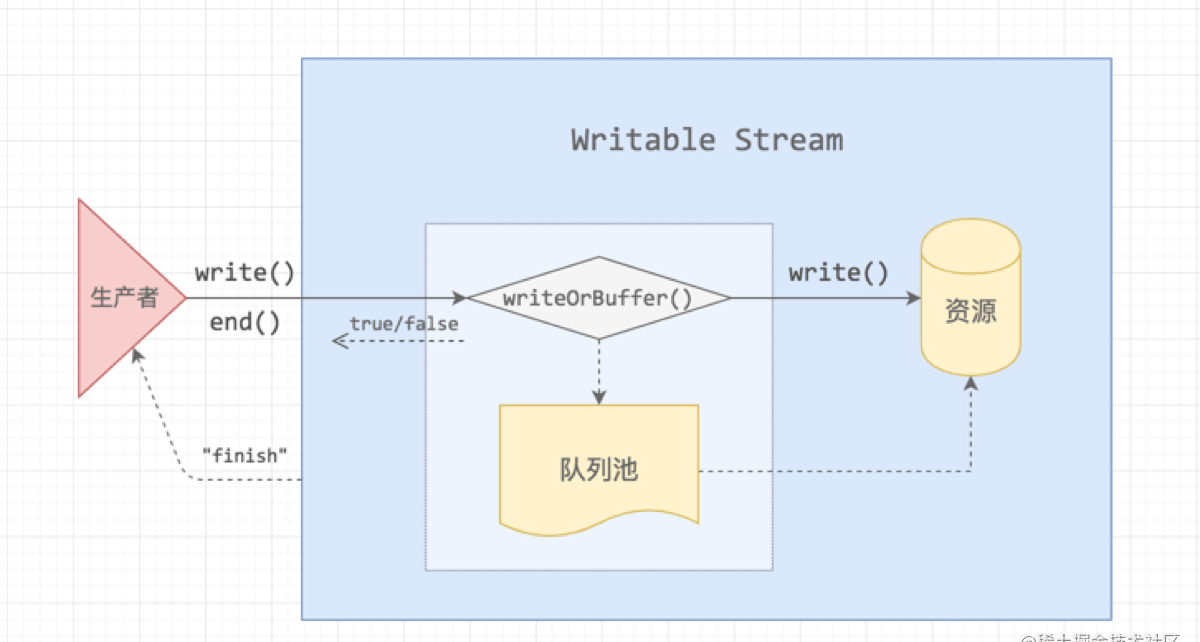
我们打断点进入到write方法中,案例就上面的ritableStream.write('写入数据,');。
Writable.prototype.write = function(chunk, encoding, cb) {
return _write(this, chunk, encoding, cb) === true;
};
此时只有chunk是有数据,encoding为undefined(会帮我们默认设为utf8,highwatermark会置为16384,cb为空)
我们看一下_write函数,主要就是初始化writeable的state,比如encoding, 然后调用了
return writeOrBuffer(stream, state, chunk, encoding, cb);
这里的stream就是writeable实例对象,writeOrBuffer源码如下:
function writeOrBuffer(stream, state, chunk, encoding, callback) {
// 我们这里的数据length是15
const len = state.objectMode ? 1 : chunk.length;
// 写缓存大小加上15
state.length += len;
// 此时因为highWaterMark是16384,所以ret是true,而且一般情况下都是true
const ret = state.length < state.highWaterMark;
// We must ensure that previous needDrain will not be reset to false.
if (!ret)
state.needDrain = true;
// 把当前状态writing设为true
// stream._write就是我们外部写的_write函数
state.writelen = len;
state.writecb = callback;
state.writing = true;
state.sync = true;
stream._write(chunk, encoding, state.onwrite);
state.sync = false;
return ret && !state.errored && !state.destroyed;
}
stream._write就是我们外部写的_write函数,也就是把chunk(15字节),encoding是’buffer’,原因是state.decodeStrings默认是true,所以。
我们外部调用next函数实际上是state.onwrite函数,我们看下是onwrite源码:
state.writing = false;
state.writecb = null;
state.length -= state.writelen;
state.writelen = 0;
process.nextTick(afterWriteTick, state.afterWriteTickInfo);
然后在afterWriteTick执行afterWriteTick方法,这个方法对于我们探讨next函数的调用对可写流产生什么。
所以我们可以看到,产生的数据是直接送给下游的,没有经过缓冲区?这是不是跟我们的图片上展示的流程冲突了呢?
什么时候写入缓冲区
我们把例子改一下:
const Stream = require('stream');
const writableStream = Stream.Writable({ highWaterMark: 3, encoding: 'utf8' });
writableStream._write = function (data, encoding, next) {
console.log('data: ', data.toString());
}
writableStream.on('finish', () => console.log('done~'));
writableStream.write('123456');
writableStream.write('2123456');
writableStream.end();
第一次读入数据123456跟之前没啥区别,区别就在第二次读数据,请看以下关键代码:
if (state.writing || state.corked || state.errored || !state.constructed) {
state.buffered.push({ chunk, encoding, callback });
if (state.allBuffers && encoding !== 'buffer') {
state.allBuffers = false;
}
if (state.allNoop && callback !== nop) {
state.allNoop = false;
}
} else {
state.writelen = len;
state.writecb = callback;
state.writing = true;
state.sync = true;
stream._write(chunk, encoding, state.onwrite);
state.sync = false;
}
在读取123456的时候虽然调用stream._write(chunk, encoding, state.onwrite);,但是因为next函数没有,所以state.writing 还是等于true(next函数的调用会让state.writing = false)
这就导致第二次读数据的时候,上面的if语句走的是第一个条件。把数据写到了缓冲区里,但是没有调用stream._write,所以就这么结束了。。。
但是,但是,如果你再改一下案例
const Stream = require('stream');
const writableStream = Stream.Writable({ highWaterMark: 3, encoding: 'utf8' });
writableStream._write = function (data, encoding, next) {
console.log('data: ', data.toString());
setTimeout(()=>{
next();
},2000)
}
writableStream.on('finish', () => console.log('done~'));
writableStream.write('123456');
writableStream.write('2123456');
writableStream.end();
在两秒后,又会输出2123456,这是因为2秒后调用next函数,此时会把缓冲区里的数据取出来。
此时的逻辑就变为,一边把数据存入缓冲区,一边把之前已经在缓冲区的数据拿出来给下游!
接着看transform流
transform源码
下图是transform流的数据走向: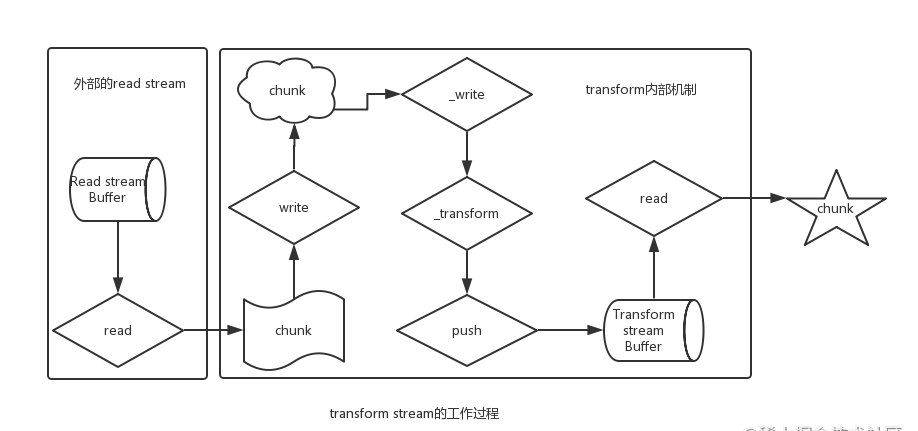
我们以下面的代码打断点调试:
const Stream = require('stream');
class TransformReverse extends Stream.Transform {
constructor() {
super()
}
_transform(buf, encoding, next) {
const res = buf.toString().split('').reverse().join('');
this.push(res)
next()
}
}
var transformStream = new TransformReverse();
transformStream.on('data', data => console.log(data.toString()))
transformStream.on('end', data => console.log('read done~'));
transformStream.write('写数据了!');
transformStream.end()
transformStream.on('finish', data => console.log('write done~'));
下面的_write,其实就是可写流里自定义的write方法,所以Transform流自己内部实现了自定义可写流。
Transform.prototype._write = function(chunk, encoding, callback) {
const rState = this._readableState;
const wState = this._writableState;
const length = rState.length;
this._transform(chunk, encoding, (err, val) => {
if (err) {
callback(err);
return;
}
if (val != null) {
this.push(val);
}
if (
wState.ended || // Backwards compat.
length === rState.length || // Backwards compat.
rState.length < rState.highWaterMark
) {
callback();
} else {
this[kCallback] = callback;
}
});
};
Transform.prototype._read = function() {
if (this[kCallback]) {
const callback = this[kCallback];
this[kCallback] = null;
callback();
}
};
然后上面调用了this._transform,就是我们之前案例里的我们自己实现的_transform方法,this.push其实就是可写流之前的push方法,就是往读缓冲区写数据。next函数就是上面_write方法最后一个回调函数。
也即是调用了callback();这个函数的意思是可写流马上把数据返回给下游。
所以transform流没有什么神奇之处,简单来说,首先调用write方法,这个是transform流继承可写流的方法,然后write方法调用内部的writeOrBuffer方法(就跟之前自定义write流是一样的流程)
然后writeOrBuffer方法中调用了自定义的_write方法,这个方法因为被transform流重写了,所以执行的transform流上的_write方法
这个方法里直接调用了自定义的_tranform流,此时可以对流里的数据进行处理,最后处理的数据交给了this.push,也就是写入到可写流的缓存里,最后write流执行callback();也就是之前我们提的next函数。
最终让可写流不断的写入新数据给this._transform,然后this._transform又把转换后的数据给可读流,这样循环往复。
原文链接:https://juejin.cn/post/7218163893915238458 作者:孟祥_成都