
强大的人不是征服什么而是能承受什么
大家好,我是柒八九。
今天,我们继续Rust学习笔记的探索。我们来谈谈关于Rust学习笔记之智能指针的相关知识点。
如果,想了解该系列的文章,可以参考我们已经发布的文章。如下是往期文章。
文章list
- Rust学习笔记之Rust环境配置和入门指南
- Rust学习笔记之基础概念
- Rust学习笔记之所有权
- Rust学习笔记之结构体
- Rust学习笔记之枚举和匹配模式
- Rust学习笔记之包、Crate和模块
- Rust学习笔记之集合
- Rust学习笔记之错误处理
- Rust学习笔记之泛型、trait 与生命周期
- Rust学习笔记之闭包和迭代器
你能所学到的知识点
- 何为指针 推荐阅读指数 ⭐️⭐️⭐️⭐️⭐️
- 使用
Box<T>指向堆上的数据 推荐阅读指数 ⭐️⭐️⭐️⭐️- 使用
Drop Trait运行清理代码 推荐阅读指数 ⭐️⭐️⭐️⭐️Rc<T>引用计数智能指针 推荐阅读指数 ⭐️⭐️⭐️⭐️RefCell<T>和内部可变性模式 推荐阅读指数 ⭐️⭐️⭐️⭐️
好了,天不早了,干点正事哇。

何为指针
{指针|pointer}是一个变量,它存储了一个值的内存地址。
常见编程语言的显式指针
在编程中,指针通常用来指向另一个变量或对象的内存地址,以便可以直接访问或修改该变量或对象的值。指针概念通常存在于低级编程语言中,比如C和C++,但是其他编程语言如Java和Python也支持指针。
以下是一个简单的C++代码示例,展示如何声明和使用指针:
#include <iostream>
int main() {
int num = 10; // 声明一个整型变量
int* p; // 声明一个整型指针
p = # // 将指针指向num的内存地址
std::cout << "num的值是: " << num << std::endl;
std::cout << "p所指向的值是: " << *p << std::endl; // 输出p指向的值
std::cout << "num的地址是: " << &num << std::endl;
std::cout << "p指向的地址是: " << p << std::endl; // 输出p所指向的地址
*p = 20; // 修改p指向的值
std::cout << "num的值是: " << num << std::endl; // 输出修改后的num值
std::cout << "p所指向的值是: " << *p << std::endl; // 输出修改后的p指向的值
return 0;
}
在这个例子中,我们声明了一个整型变量num,并将其初始化为10。然后我们声明了一个指向整型的指针p,并将其指向num的内存地址。我们使用*p访问指针所指向的值,并使用&num获取num的内存地址。我们还可以通过修改指针所指向的值来间接修改num的值,即通过*p = 20将num的值修改为20。
JS中引用
JavaScript中没有像C++和其他低级语言中的指针那样的显式指针。相反,JavaScript使用{引用|Reference}来管理对象和函数的访问和使用。
在JavaScript中,对象和函数都是通过引用来访问的,而不是通过复制其值。引用是一个指向内存地址的值,它允许我们在代码中访问或修改对象或函数。在JavaScript中,我们使用变量来存储引用,而不是直接使用指针。
下面是一个简单的JavaScript代码示例,展示如何声明和使用引用:
let obj = {name: '北宸南蓁', age: 25}; // 声明一个对象
let ref = obj; // 声明一个指向对象的引用
console.log(obj.name); // 输出对象的属性值
console.log(ref.name); // 输出引用所指向的对象的属性值
obj.age = 30; // 修改对象的属性值
console.log(ref.age); // 输出引用所指向的对象的修改后的属性值
在这个例子中,我们声明了一个名为obj的对象,其中包含名为name和age的属性。我们还声明了一个指向该对象的引用ref。我们可以通过obj和ref访问和修改对象的属性值,因为它们都引用了同一个对象。
总之,虽然JavaScript中没有显式的指针,但引用概念可以用来达到类似指针的目的。通过引用,JavaScript可以管理对象和函数的访问和使用,而不需要开发人员手动管理内存。
总之,
指针/引用是一种非常有用的编程概念,它允许我们直接访问和修改内存中的数据。但是,在使用指针时需要小心,因为指针也可能导致一些常见的编程错误,如空指针引用和内存泄漏。
Rust中的指针
Rust 中最常见的指针是 {引用|reference}。引用以 & 符号为标志并借用了它们所指向的值。除了引用数据没有任何其他特殊功能。它们也没有任何额外开销,所以应用得最多。
另一方面,{智能指针|smart pointers}是一类数据结构,它们的表现类似指针,但是也拥有额外的元数据和功能。Rust 标准库中不同的智能指针提供了多于引用的额外功能。
我们会讨论{引用计数|reference counting} 智能指针类型,其允许数据有多个所有者。引用计数智能指针记录总共有多少个所有者,并当没有任何所有者时负责清理数据。
在
Rust中,普通引用和智能指针的一个额外的区别是引用是一类只借用数据的指针;相反,在大部分情况下,智能指针拥有它们指向的数据。
智能指针通常使用结构体实现。智能指针区别于常规结构体的显著特性在于其实现了 Deref 和 Drop trait。
Deref trait允许智能指针结构体实例表现的像引用一样,这样就可以编写既用于引用、又用于智能指针的代码。Drop trait允许我们自定义当智能指针离开作用域时运行的代码。
这里将会讲到的是来自标准库中最常用的一些:
Box<T>,用于在堆上分配值Rc<T>,一个引用计数类型,其数据可以有多个所有者Ref<T>和RefMut<T>,通过RefCell<T>访问(RefCell<T>是一个在运行时而不是在编译时执行借用规则的类型)
使用 Box<T> 指向堆上的数据
最简单智能指针是 box,其类型是 Box<T>。
box允许你将一个值放在堆上而不是栈上。留在栈上的则是指向堆数据的指针。
除了数据被储存在堆上而不是栈上之外,box 没有性能损失。不过也没有很多额外的功能。它们多用于如下场景:
- 当有一个在编译时未知大小的类型,而又想要在需要确切大小的上下文中使用这个类型值的时候
- 当有
大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候- 转移大量数据的所有权可能会花费很长的时间,因为数据在栈上进行了拷贝。为了改善这种情况下的性能,可以通过
box将这些数据储存在堆上。
- 转移大量数据的所有权可能会花费很长的时间,因为数据在栈上进行了拷贝。为了改善这种情况下的性能,可以通过
- 当希望拥有一个值并只关心它的类型是否实现了特定
trait而不是其具体类型的时候
使用 Box<T> 在堆上储存数据
如下 展示了如何使用 box 在堆上储存一个 i32:
fn main() {
let b = Box::new(5);
println!("b = {}", b);
}
这里定义了变量 b,其值是一个指向被分配在堆上的值 5 的 Box。这个程序会打印出 b = 5;。正如任何拥有数据所有权的值那样,当像 b 这样的 box 在 main 的末尾离开作用域时,它将被释放。这个释放过程作用于 box 本身(位于栈上)和它所指向的数据(位于堆上)。
Box 允许创建递归类型
Rust 需要在编译时知道类型占用多少空间。一种无法在编译时知道大小的类型是{递归类型|recursive type} ,其值的一部分可以是相同类型的另一个值。这种值的嵌套理论上可以无限的进行下去,所以 Rust 不知道递归类型需要多少空间。不过 box 有一个已知的大小,所以通过在循环类型定义中插入 box,就可以创建递归类型了。
cons list
cons list,一个函数式编程语言中的常见类型。cons list 是一个来源于 Lisp 编程语言的数据结构。在 Lisp 中,cons 函数(“construct function” 的缩写)利用两个参数来构造一个新的列表,他们通常是一个单独的值和另一个列表。
cons list 的每一项都包含两个元素:
- 当前项的值
- 下一项
- 其最后一项值包含一个叫做
Nil的值且没有下一项。
- 其最后一项值包含一个叫做
cons list 通过递归调用 cons 函数产生。代表递归的终止条件(base case)的规范名称是 Nil,它宣布列表的终止。
定义一个 cons list 的枚举定义。
enum List {
Cons(i32, List),
Nil,
}
使用这个 cons list 来储存列表 1, 2, 3 将看起来如下所示:
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}
第一个 Cons 储存了 1 和另一个 List 值。这个 List 是另一个包含 2 的 Cons 值和下一个 List 值。接着又有另一个存放了 3 的 Cons 值和最后一个值为 Nil 的 List,非递归成员代表了列表的结尾。
如果尝试编译上面的代码,会得到下面的错误
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ recursive type has infinite size
2 | Cons(i32, List),
| ----- recursive without indirection
这个错误表明这个类型 “有无限的大小”。其原因是 List 的一个成员被定义为是递归的:它直接存放了另一个相同类型的值。这意味着 Rust 无法计算为了存放 List 值到底需要多少空间。
计算非递归类型的大小
存在如下代码
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
当 Rust 需要知道要为 Message 值分配多少空间时,它可以检查每一个成员并发现 Message::Quit 并不需要任何空间,Message::Move 需要足够储存两个 i32 值的空间,依此类推。因为只会使用一个成员,所以 Message 值需要的最大空间是存储其最大成员所需的空间大小。
与此相对当 Rust 编译器检查像 List 这样的递归类型时会发生什么呢。编译器尝试计算出储存一个 List 枚举需要多少内存,并开始检查 Cons 成员,那么 Cons 需要的空间等于 i32 的大小加上 List 的大小。为了计算 List 需要多少内存,它检查其成员,从 Cons 成员开始。Cons 成员储存了一个 i32 值和一个 List 值,这样的计算将无限进行下去。

使用 Box<T> 给递归类型一个已知的大小
Rust 无法计算出要为定义为递归的类型分配多少空间。
Box<T> 是一个指针,我们总是知道它需要多少空间:指针的大小并不会根据其指向的数据量而改变。这意味着可以将 Box 放入 Cons 成员中而不是直接存放另一个 List 值。Box 会指向另一个位于堆上的 List 值,而不是存放在 Cons 成员中。
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1,
Box::new(Cons(2,
Box::new(Cons(3,
Box::new(Nil))))));
}
Cons 成员将会需要一个 i32 的大小加上储存 box 指针数据的空间。Nil 成员不储存值,所以它比 Cons 成员需要更少的空间。通过使用 box ,打破了这无限递归的连锁,这样编译器就能够计算出储存 List 值需要的大小了。
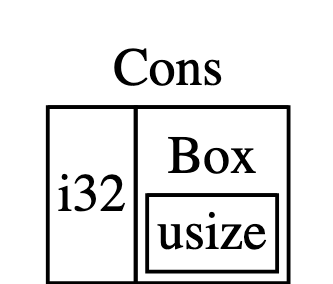
box 只提供了间接存储和堆分配;他们并没有任何其他特殊的功能。
Box<T> 类型是一个智能指针,因为它实现了 Deref trait,它允许 Box<T> 值被当作引用对待。当 Box<T> 值离开作用域时,由于 Box<T> 类型 Drop trait 的实现,box 所指向的堆数据也会被清除。
通过 Deref trait 将智能指针当作常规引用处理
实现 Deref trait 允许我们重载 {解引用运算符|dereference operator} *。通过这种方式实现 Deref trait 的智能指针可以被当作常规引用来对待,可以编写操作引用的代码并用于智能指针。
通过解引用运算符追踪指针的值
常规引用是一种指针类型,一种理解指针的方式是将其看成指向储存在其他某处值的箭头。
创建了一个 i32 值的引用,接着使用解引用运算符解出所引用的值:
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}
变量 x 存放了一个 i32 值 5。y 等于 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是 解引用)。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
必须使用解引用运算符解出引用所指向的值
像引用一样使用 Box<T>
可以使用 Box<T> 代替引用来重写上面的代码,解引用运算符也一样能工作。
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
它们唯一不同的地方就是将 y 设置为一个指向 x 值的 box 实例,而不是指向 x 值的引用。
自定义智能指针
创建一个类似于标准库提供的 Box<T> 类型的智能指针。
从根本上说,
Box<T>被定义为包含一个元素的元组结构体。
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
这里定义了一个结构体 MyBox 并声明了一个泛型参数 T,因为我们希望其可以存放任何类型的值。MyBox 是一个包含 T 类型元素的元组结构体。MyBox::new 函数获取一个 T 类型的参数并返回一个存放传入值的 MyBox 实例。
修改 main 使用我们定义的 MyBox<T> 类型代替 Box<T>
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}
代码不能编译,因为 Rust 不知道如何解引用 MyBox。得到的编译错误是:
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
MyBox<T> 类型不能解引用,因为我们尚未在该类型实现这个功能。为了启用 * 运算符的解引用功能,需要实现 Deref trait。
通过实现 Deref trait 将某类型像引用一样处理
Deref trait,由标准库提供,要求实现名为 deref 的方法,其借用 self 并返回一个内部数据的引用。
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
type Target = T; 语法定义了用于此 trait 的关联类型。
deref 方法体中写入了 &self.0,这样 deref 返回了我希望通过 * 运算符访问的值的引用。
没有 Deref trait 的话,编译器只会解引用 & 引用类型。deref 方法向编译器提供了获取任何实现了 Deref trait 的类型的值,并且调用这个类型的 deref 方法来获取一个它知道如何解引用的 & 引用的能力。
当我们输入 *y 时,Rust 事实上在底层运行了如下代码:
*(y.deref())
Rust 将 * 运算符替换为先调用 deref 方法再进行普通解引用的操作,如此我们便不用担心是否还需手动调用 deref 方法了。Rust 的这个特性可以让我们写出行为一致的代码,无论是面对的是常规引用还是实现了 Deref 的类型。
deref 方法返回了一个值的引用,而 *(y.deref()) 括号外边的普通解引用仍然必须存在的原因是因为所有权。如果 deref 方法直接返回值而不是值的引用,其值(的所有权)将被移出 self。
函数和方法的隐式解引用强制转换
{解引用强制转换|deref coercions}是 Rust 在函数或方法传参上的一种便利。解引用强制转换只能工作在实现了 Deref trait 的类型上。解引用强制转换将一种类型(A)隐式转换为另外一种类型(B)的引用,因为 A 类型实现了 Deref trait,并且其关联类型是 B 类型。比如,解引用强制转换可以将 &String 转换为 &str,因为类型 String 实现了 Deref trait 并且其关联类型是 str。
impl ops::Deref for String {
type Target = str;
#[inline]
fn deref(&self) -> &str {
unsafe { str::from_utf8_unchecked(&self.vec) }
}
}
当我们将特定类型的值的引用作为参数传递给函数或方法,但是被传递的值的引用与函数或方法中定义的参数类型不匹配时,会发生解引用强制转换。这时会有一系列的 deref 方法被调用,把我们提供的参数类型转换成函数或方法需要的参数类型。
解引用强制转换的加入使得 Rust 开发者编写函数和方法调用时无需增加过多显式使用 & 和 * 的引用和解引用。这个功能也使得我们可以编写更多同时作用于引用或智能指针的代码。
解引用强制转换如何与可变性交互
类似于使用 Deref trait 重载不可变引用的 * 运算符,Rust 提供了 DerefMut trait 用于重载可变引用的 * 运算符。
Rust 在发现类型和 trait 实现满足三种情况时会进行解引用强制转换:
- 当
T: Deref<Target=U>时从&T到&U。 - 当
T: DerefMut<Target=U>时从&mut T到&mut U。 - 当
T: Deref<Target=U>时从&mut T到&U。
头两个情况除了可变性之外是相同的:第一种情况表明如果有一个 &T,而 T 实现了返回 U 类型的 Deref,则可以直接得到 &U。第二种情况表明对于可变引用也有着相同的行为。
使用 Drop Trait 运行清理代码
对于智能指针模式来说第二个重要的
trait是Drop,其允许我们在值要离开作用域时执行一些代码。可以为任何类型提供Drop trait的实现,同时所指定的代码被用于释放类似于文件或网络连接的资源。
例如,可以在Box<T> 自定义了 Drop 用来释放 box 所指向的堆空间。
在 Rust 中,可以指定每当值离开作用域时被执行的代码,编译器会自动插入这些代码。于是我们就不需要在程序中到处编写在实例结束时清理这些变量的代码 —— 而且还不会泄漏资源。
指定在值离开作用域时应该执行的代码的方式是实现 Drop trait。Drop trait 要求实现一个叫做 drop 的方法,它获取一个 self 的可变引用。
展示了唯一定制功能就是当其实例离开作用域时,打印出 处理垃圾数据! 的结构体 CustomSmartPointer。
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("处理垃圾数据`{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer { data: String::from("my stuff") };
let d = CustomSmartPointer { data: String::from("other stuff") };
println!("CustomSmartPointers created.");
}
Drop trait包含在prelude中,所以无需导入它。
我们在 CustomSmartPointer 上实现了 Drop trait,并提供了一个调用 println! 的 drop 方法实现。drop 函数体是放置任何当类型实例离开作用域时期望运行的逻辑的地方。
在 main 中,我们新建了两个 CustomSmartPointer 实例并打印出了 CustomSmartPointer created.。在 main 的结尾,CustomSmartPointer 的实例会离开作用域,而 Rust 会调用放置于 drop 方法中的代码,打印出最后的信息。注意无需显式调用 drop 方法:
CustomSmartPointers created.
处理垃圾数据 `other stuff`!
处理垃圾数据 `my stuff`!
当实例离开作用域 Rust 会自动调用 drop,并调用我们指定的代码。变量以被创建时相反的顺序被丢弃,所以 d 在 c 之前被丢弃。
通过 std::mem::drop 提早丢弃值
整个 Drop trait 存在的意义在于其是自动处理的。然而,有时你可能需要提早清理某个值。当我们希望在作用域结束之前就强制释放变量的话,我们应该使用的是由标准库提供的 std::mem::drop。
fn main() {
let c = CustomSmartPointer { data: String::from("some data") };
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer 在main结束之前被处理了");
}
尝试编译代码会得到如下错误
error[E0040]: explicit use of destructor method
--> src/main.rs:14:7
|
14 | c.drop();
| ^^^^ explicit destructor calls not allowed
错误信息表明不允许显式调用 drop。错误信息使用了术语{析构函数|destructor},这是一个清理实例的函数的通用编程概念。析构函数 对应创建实例的 构造函数。Rust 中的 drop 函数就是这么一个析构函数。
Rust 不允许我们显式调用 drop 因为 Rust 仍然会在 main 的结尾对值自动调用 drop,这会导致一个 double free 错误,因为 Rust 会尝试清理相同的值两次。
因为不能禁用当值离开作用域时自动插入的 drop,并且不能显式调用 drop,如果我们需要强制提早清理值,可以使用 std::mem::drop 函数。
std::mem::drop 函数不同于 Drop trait 中的 drop 方法。可以通过传递希望提早强制丢弃的值作为参数。std::mem::drop 位于 prelude,我们可以直接使用。
fn main() {
let c = CustomSmartPointer { data: String::from("some data") };
println!("CustomSmartPointer created.");
drop(c);
println!("CustomSmartPointer 在main结束之前被处理了");
}
运行这段代码会打印出如下:
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer 在main结束之前被处理了"
Rc<T> 引用计数智能指针
大部分情况下所有权是非常明确的:可以准确地知道哪个变量拥有某个值。然而,有些情况单个值可能会有多个所有者。
例如,在图数据结构中,多个边可能指向相同的节点,而这个节点从概念上讲为所有指向它的边所拥有。节点直到没有任何边指向它之前都不应该被清理。
为了启用多所有权,Rust 有一个叫做 Rc<T> 的类型。其名称为 {引用计数|reference counting}的缩写。引用计数意味着记录一个值引用的数量来知晓这个值是否仍在被使用。如果某个值有零个引用,就代表没有任何有效引用并可以被清理。
Rc<T> 用于当我们希望在堆上分配一些内存供程序的多个部分读取,而且无法在编译时确定程序的哪一部分会最后结束使用它的时候。如果确实知道哪部分是最后一个结束使用的话,就可以令其成为数据的所有者,正常的所有权规则就可以在编译时生效。
使用 Rc<T> 共享数据
创建两个共享第三个列表所有权的列表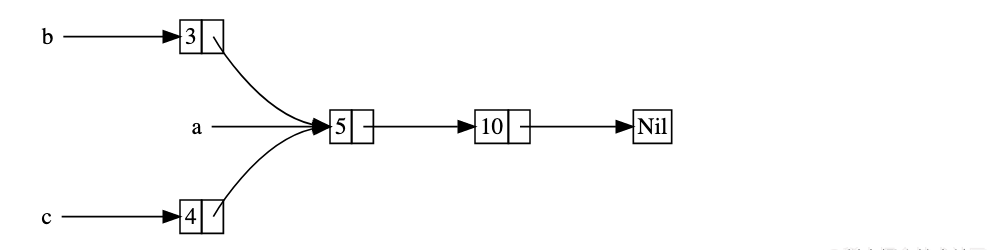
列表 a 包含 5 之后是 10,之后是另两个列表:b 从 3 开始而 c 从 4 开始。b 和 c 会接上包含 5 和 10 的列表 a。换句话说,这两个列表会尝试共享第一个列表所包含的 5 和 10。
尝试使用 Box<T> 定义的 List 实现并不能工作
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5,
Box::new(Cons(10,
Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}
编译会得出如下错误:
error[E0382]: use of moved value: `a`
--> src/main.rs:13:30
|
12 | let b = Cons(3, Box::new(a));
| - value moved here
13 | let c = Cons(4, Box::new(a));
| ^ value used here after move
Cons 成员拥有其储存的数据,所以当创建 b 列表时,a 被移动进了 b 这样 b 就拥有了 a。接着当再次尝试使用 a 创建 c 时,这不被允许,因为 a 的所有权已经被移动。
修改 List 的定义为使用 Rc<T> 代替 Box<T>。现在每一个 Cons 变量都包含一个值和一个指向 List 的 Rc<T>。
- 当创建
b时,不同于获取a的所有权,这里会克隆a所包含的Rc<List>,这会将引用计数从1增加到2并允许a和b共享Rc<List>中数据的所有权。 - 创建
c时也会克隆a,这会将引用计数从2增加为3。每次调用Rc::clone,Rc<List>中数据的引用计数都会增加,直到有零个引用之前其数据都不会被清理
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}
需要使用
use语句将Rc<T>引入作用域,因为它不在prelude中。
在 main 中创建了存放 5 和 10 的列表并将其存放在 a 的新的 Rc<List> 中。接着当创建 b 和 c 时,调用 Rc::clone 函数并传递 a 中 Rc<List> 的引用作为参数。
克隆 Rc<T> 会增加引用计数
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}
在程序中每个引用计数变化的点,会打印出引用计数,其值可以通过调用 Rc::strong_count 函数获得。
这段代码会打印出:
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
a 中 Rc<List> 的初始引用计数为1,接着每次调用 clone,计数会增加1。当 c 离开作用域时,计数减1。不必像调用 Rc::clone 增加引用计数那样调用一个函数来减少计数;Drop trait 的实现当 Rc<T> 值离开作用域时自动减少引用计数。
RefCell<T> 和内部可变性模式
{内部可变性|Interior mutability}是 Rust 中的一个设计模式,它允许你即使在有不可变引用时也可以改变数据,这通常是借用规则所不允许的。为了改变数据,该模式在数据结构中使用 unsafe 代码来模糊 Rust 通常的可变性和借用规则。
通过 RefCell<T> 在运行时检查借用规则
不同于
Rc<T>,RefCell<T>代表其数据的唯一的所有权。
对于引用和 Box<T>,借用规则的不可变性作用于编译时。对于 RefCell<T>,这些不可变性作用于运行时。
- 对于引用,如果违反这些规则,会得到一个编译错误。
- 而对于
RefCell<T>,如果违反这些规则程序会panic并退出。
在编译时检查借用规则的优势是这些错误将在开发过程的早期被捕获,同时对运行时没有性能影响,因为所有的分析都提前完成了。为此,在编译时检查借用规则是大部分情况的最佳选择,这也正是其为何是 Rust 的默认行为。
相反在运行时检查借用规则的好处则是允许出现特定内存安全的场景,而它们在编译时检查中是不允许的。静态分析,正如 Rust 编译器,是天生保守的。但代码的一些属性不可能通过分析代码发现。
类似于 Rc<T>,RefCell<T> 只能用于单线程场景。如果尝试在多线程上下文中使用RefCell<T>,会得到一个编译错误。
如下为选择 Box<T>,Rc<T> 或 RefCell<T> 的理由:
Rc<T>允许相同数据有多个所有者;Box<T>和RefCell<T>有单一所有者。Box<T>允许在编译时执行不可变或可变借用检查;Rc<T>仅允许在编译时执行不可变借用检查;RefCell<T>允许在运行时执行不可变或可变借用检查。- 因为
RefCell<T>允许在运行时执行可变借用检查,所以我们可以在即便RefCell<T>自身是不可变的情况下修改其内部的值。
内部可变性:不可变值的可变借用
借用规则的一个推论是当有一个不可变值时,不能可变地借用它。
fn main() {
let x = 5;
let y = &mut x;
}
如果尝试编译,会得到如下错误:
error[E0596]: cannot borrow immutable local variable `x` as mutable
--> src/main.rs:3:18
|
2 | let x = 5;
| - consider changing this to `mut x`
3 | let y = &mut x;
| ^ cannot borrow mutably
RefCell<T> 是一个获得内部可变性的方法。RefCell<T> 并没有完全绕开借用规则,编译器中的借用检查器允许内部可变性并相应地在运行时检查借用规则。如果违反了这些规则,会出现 panic 而不是编译错误。
RefCell<T> 在运行时记录借用
当创建不可变和可变引用时,我们分别使用 & 和 &mut 语法。对于 RefCell<T> 来说,则是 borrow 和 borrow_mut 方法。
borrow方法返回Ref<T>类型的智能指针,borrow_mut方法返回RefMut类型的智能指针。
这两个类型都实现了 Deref,所以可以当作常规引用对待。
RefCell<T> 记录当前有多少个活动的 Ref<T> 和 RefMut<T> 智能指针。每次调用 borrow,RefCell<T> 将活动的不可变借用计数加一。当 Ref<T> 值离开作用域时,不可变借用计数减一。就像编译时借用规则一样,RefCell<T> 在任何时候只允许有多个不可变借用或一个可变借用。
结合 Rc<T> 和 RefCell<T> 来拥有多个可变数据所有者
RefCell<T> 的一个常见用法是与 Rc<T> 结合。Rc<T> 允许对相同数据有多个所有者,不过只能提供数据的不可变访问。如果有一个储存了 RefCell<T> 的 Rc<T> 的话,就可以得到有多个所有者并且可以修改的值了!
cons list 的例子中使用 Rc<T> 使得多个列表共享另一个列表的所有权。因为 Rc<T> 只存放不可变值,所以一旦创建了这些列表值后就不能修改。让我们加入 RefCell<T> 来获得修改列表中值的能力。下面展示了通过在 Cons 定义中使用 RefCell<T>,我们就允许修改所有列表中的值了:
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
use std::cell::RefCell;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(10)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}
创建了一个 Rc<RefCell<i32>> 实例并储存在变量 value 中以便之后直接访问。接着在 a 中用包含 value 的 Cons 成员创建了一个 List。需要克隆 value 以便 a 和 value 都能拥有其内部值 5 的所有权,而不是将所有权从 value 移动到 a 或者让 a 借用 value。
打印出 a、b 和 c 时,可以看到他们都拥有修改后的值 15 而不是 5:
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 6 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 10 }, Cons(RefCell { value: 15 }, Nil))
引用循环与内存泄漏
Rust 的内存安全性保证使其难以意外地制造永远也不会被清理的内存(被称为 {内存泄漏|memory leak}),但并不是不可能。与在编译时拒绝数据竞争不同, Rust 并不保证完全地避免内存泄漏,这意味着内存泄漏在 Rust 被认为是内存安全的。这一点可以通过 Rc<T> 和 RefCell<T> 看出:创建引用循环的可能性是存在的。这会造成内存泄漏,因为每一项的引用计数永远也到不了 0,其值也永远不会被丢弃。
后记
分享是一种态度。
参考资料:《Rust权威指南》
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。

本文正在参加「金石计划」
原文链接:https://juejin.cn/post/7218948376166432825 作者:前端小魔女