
第 63 届早早聊大会将于 2023 年 4 月 15 日(本周六)举办 – 低代码无代码|无码有码 全靠拖拉,6 位讲师全天直播,关键词:低代码/组件物料/游戏实践/ A/B Test /React 玩转。跟早早聊一起,玩转低代码,上车链接:www.zaozao.run/conf/c63


本文是 2021 年 12 月 26 日,第三十五届 – 前端早早聊【前端搞 Node.js】专场,来自蚂蚁金服 语雀前端团队 —— 小珲的分享。感谢 AI 的发展,借助 GPT 的能力,最近我们终于可以非常高效地将各位讲师的精彩分享文本化后,分享给大家。(完整版含演示请看录播视频和 PPT):www.zaozao.run/video/c35
正文如下
大家好,我是来自语雀的小珲,是一名全栈开发工程师。
在本次分享的内容如下,
- 第一,解释什么是 ORM,以及它在Node.js web 应用中的使用和优缺点。
- 第二,大致介绍目前比较常见的两种 ORM 模式 – Active Record 和 Data Mapper,并对它们进行简单对比。
- 第三,用架构图和伪代码来详细介绍 ORM 的结构,包括其中的重要部分和相关实现。
- 第四,使用 ORM 时可能遇到的问题以及相应的优化措施。

什么是 ORM
为了照顾纯前端的同学,我将先展示一个简单的 demo 来演示 ORM 的使用。我们假定有三张表,用户表、文章表和评论表,它们之间的关系可以用图表现出来。每篇文章只能有一个作者,每个文章可以有多条评论,每一条评论只能属于某一篇文章。接下来我们来看看 ORM 在使用时,如何表达数据库中的关系,并使用它进行业务查询和展示。
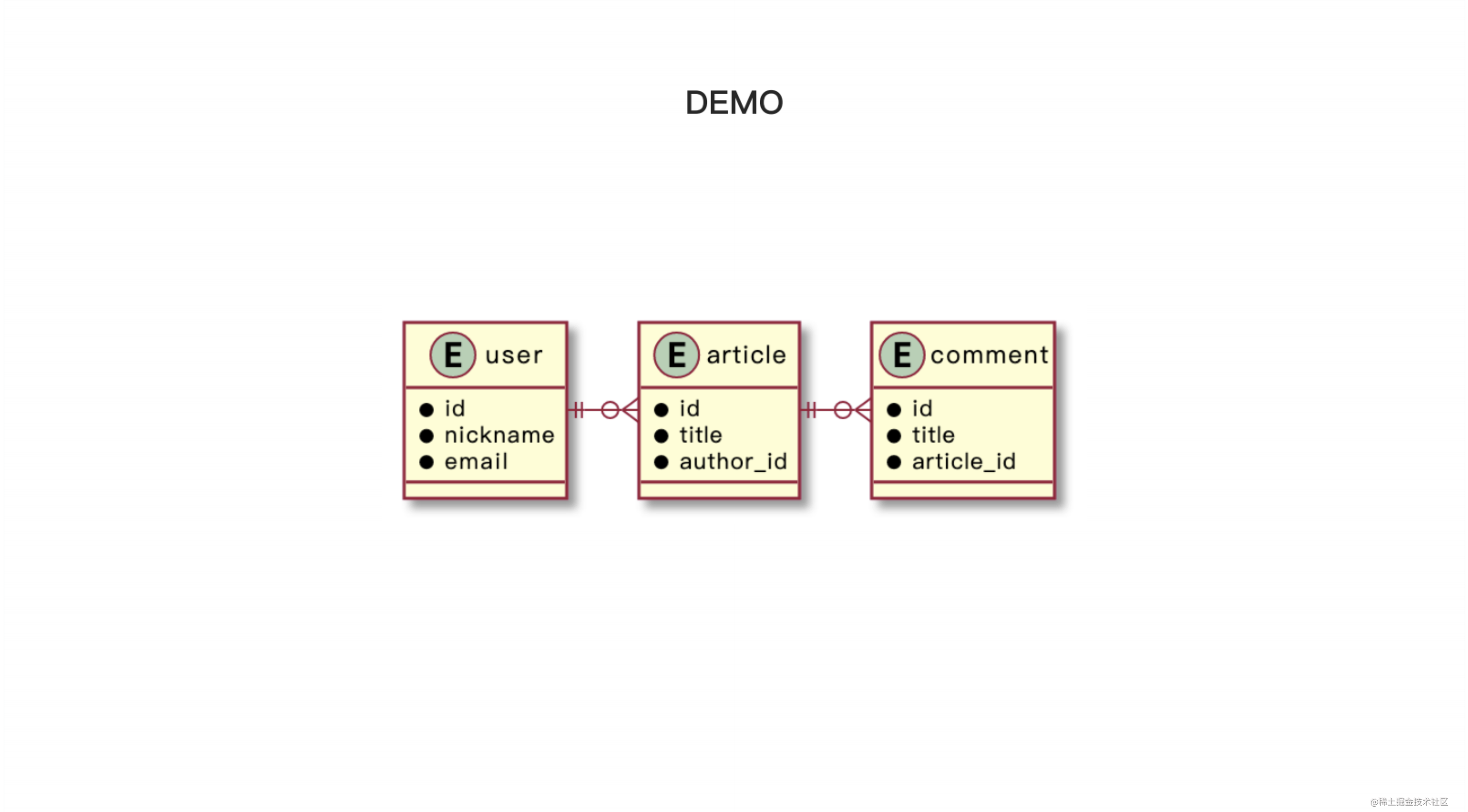
首先,我们会使用 ORM 来描述三个实体,包括用户、文章和评论。我们将使用 user 类来对应用户实体,使用 comment 类对应评论实体,使用 article 类对应文章实体。在 article 类中,我们将描述刚刚提到的两个关系,即每篇文章有一个作者,每篇文章有多条评论。我们将根据本地数据库的设置,连接到数据库,进行初始化操作。在初始化函数中,我们会首先连接到数据库,然后对这三张表进行数据清理。接下来,我们将演示如何使用 ORM 进行增删改查操作。
我们将先创建一个用户,并使用 ORM 功能查询出该用户,然后对其进行简单修改,并重新查询结果。接着,我们将创建一个文章,并添加两个评论。然后,我们将使用三种不同的方式来查询文章以及与之相关的作者和评论。在执行结果中,我们可以看到每个操作所对应的 SQL 语句和调用,以及查询到的结果。在下面的三个不同的 API 调用方式中,生成的 SQL 语句都是相似的。最终,我们将得到一篇文章及其相关的作者、评论以及其他信息。通过这个 demo,我们可以看到如何在 Node.js 中使用 ORM 进行增删改查操作。
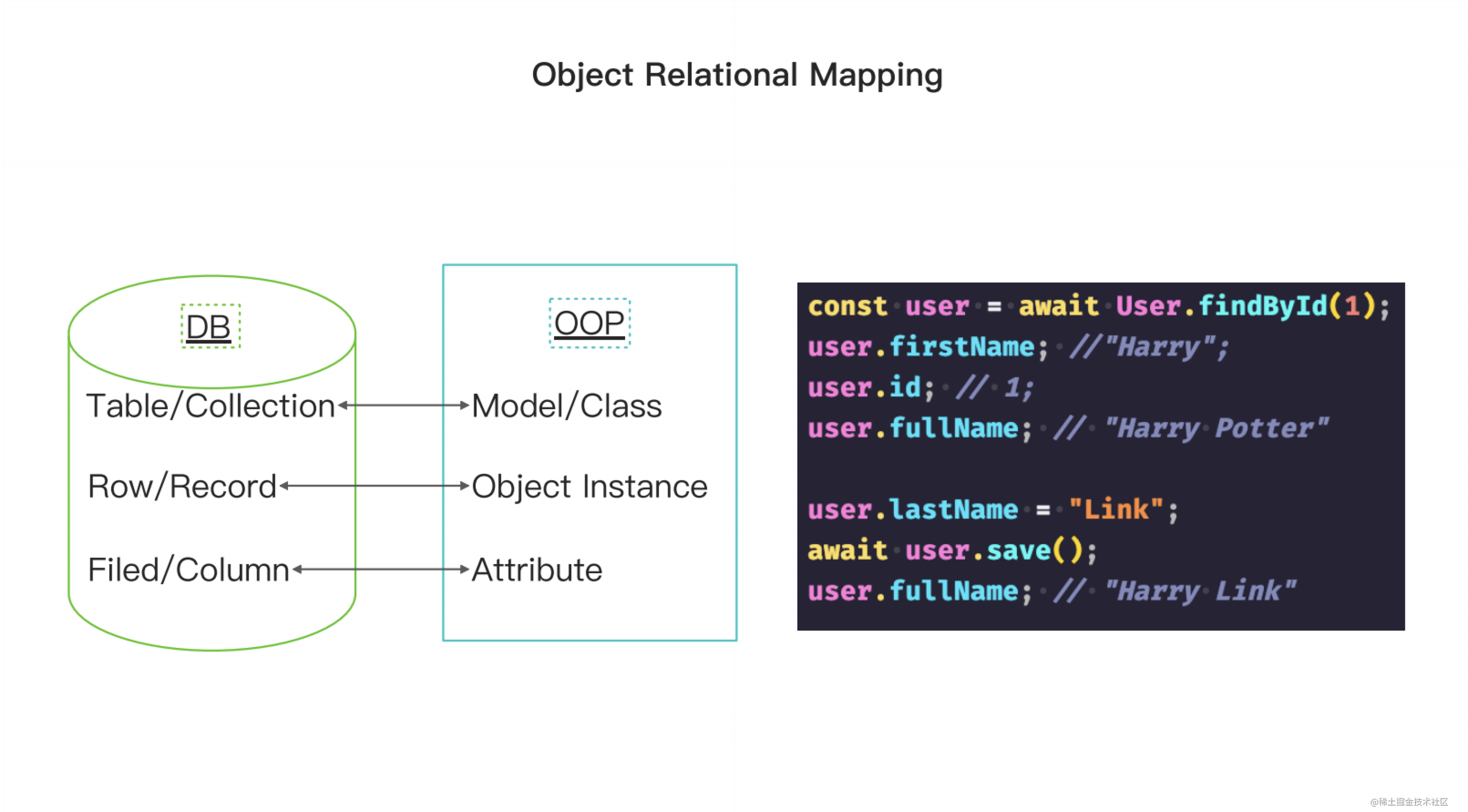
回到主题什么是 ORM ?ORM 是对象关系映射(Object Relation Mapping)的缩写,它将数据中表对应着的开发代码或内存中的 model 类与数据库中的某一张表对应。数据表中的每一条数据对应着 model 类的一个实例,数据表中的某个字段对应着 model 类的一个成员变量。使用 ORM 可以将数据库中的数据映射到开发代码中,从而方便地操作数据库的增删改查。
使用 ORM 有很多优点,例如 ORM 会对查询和更新操作进行数据预处理,从而防止 SQL 注入的风险。另外,ORM 屏蔽了直接编写 SQL 的细节,使得开发人员不必自己写 SQL,这对于 SQL 不熟练的人来说是一个好处。此外,由于 ORM 以模型为基础,因此支持 MVC 的开发架构,并且可以映射所有数据库表到内存的 model 中,这有助于组织和复用代码,避免了到处写 SQL 的尴尬处境。
然而,使用 ORM 也存在一些缺点。例如,由于组合 API 生成的 SQL 的特性,有时自动生成的 SQL 可能不是最优的方案,这可能会导致性能问题。此外,为了处理各种复杂的逻辑,model 也会变得很复杂,处理查询结果可能会有不必要的对象深拷贝,这会影响应用的性能。同时,ORM 为了适配 SQL 满足的各种业务场景,有很多 API 需要学习,这也是一种成本。另外,对于一些奇怪的查询需求,ORM 可能无法满足,此时只能手写 SQL。这些是我总结 ORM 的一些优点和缺点。

Active Record & Data Mapper
接下来介绍两种常见的 ORM 模式:Active Record 和 Data Mapper。Active Record 翻译成中文就是主动记录模式,是一种架构模式。之前展示的 ORM 是 Active Record 模式的。

Active Record 的简单总结是一个对象,同时包含了数据库对应的属性字段和相应的业务的增删改查操作,也就是说 model 打包了这一个域该有的所有功能。比如,用户有了 user model 就可以直接使用它,并对它以及 user model 实例进行一些业务的编码。这种类型的 ORM 几乎都有一个特点,就是所有 CRUD 操作都打包在一个 model 中。业务中只需要根据自己的项目和数据库设计去派生出对应的 base model 的子类。user model 继承了 base model 所有的 API,同时也会包含自己特有的业务 API,比如查询某个性别的用户、某个年龄段用户等等。

Active Record 类型的 ORM 使用上更加符合我们的直觉,使用起来更方便。数据库有多少张表,就对应多少个 model,每个 model 有哪些操作,都在这个派生出来的 model 中实现。它代表的是我们的数据结构与模型对象高度耦合,因此可能更适合一些业务逻辑比较简单的中小型应用。
我们之前已经展示了一个属于 Active Record 类型的 ORM demo,因此在这里就不再多作解释。接下来,我们将介绍另一种 ORM 类型,即 Data Mapper类型。我们将通过一个 demo 来说明这种类型的 ORM,其中涉及到的模型包括 user、article 和 comment。回顾一下它们之间的关系:每篇文章有一个作者,每个用户可以有多篇文章,每篇文章有多条评论,每条评论只能归属于一篇文章。虽然 Data Mapper 类型的 ORM 在 JavaScript 中并不是很流行,但我们将使用一个名为 TypeORM 的常用 ORM 来进行演示。
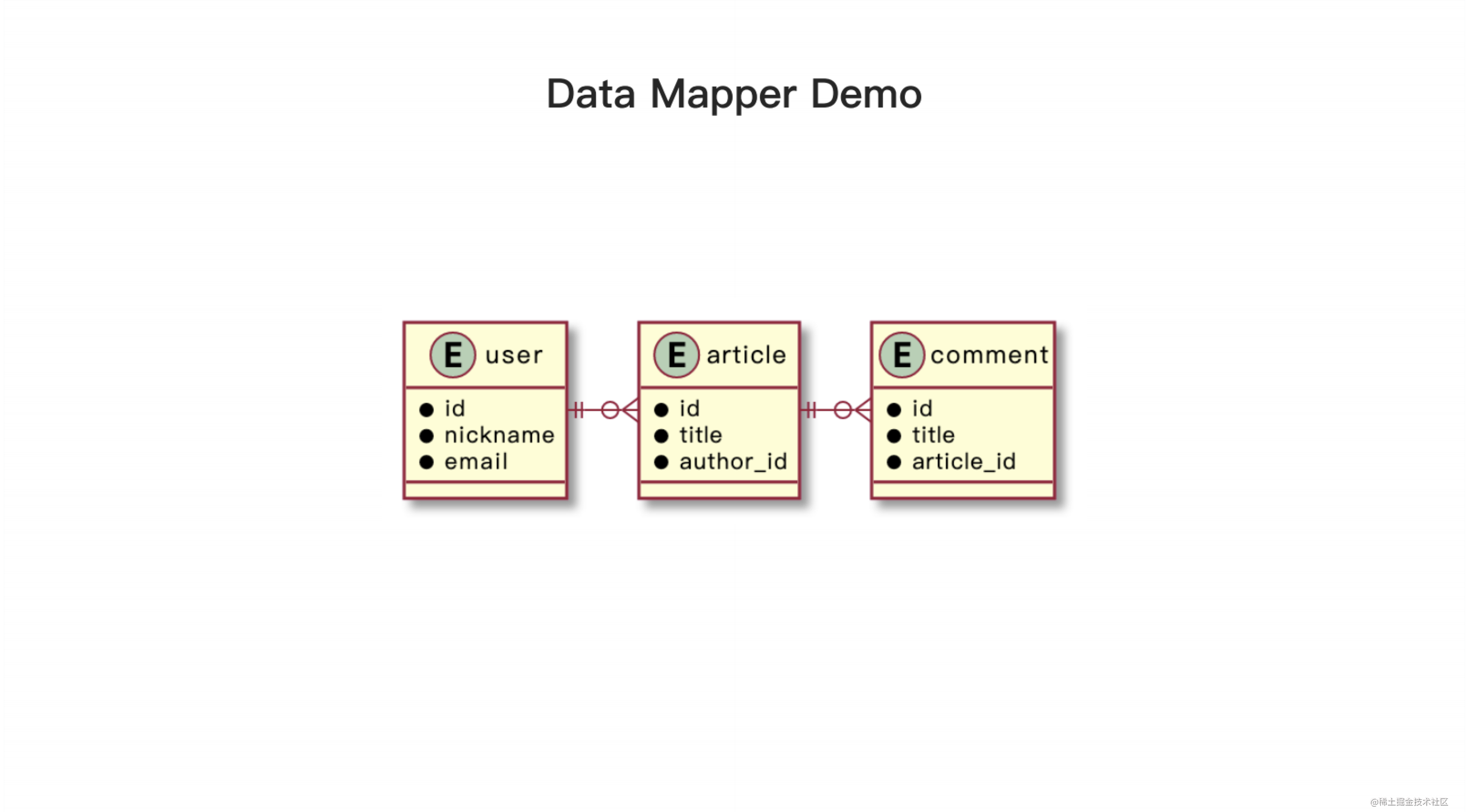
首先,我们需要声明实体,分别是用户(user)、文章(article)和评论(comment)。在每个实体中,我们声明可能用到的属性和实体之间的关系。例如,用户可能会有多篇文章,而一篇文章只能有一个作者和多个评论,每个评论只能属于一篇文章。这与之前讲过的 Active Record ORM 类似,但有一个不同点是这些模型不再包含基础的数据操作(例如增删改查),而只用于展示数据,例如名字的展示可能需要加上大写等特殊的展示。
Data Mapper 的实现主要是为了适配某个实体或几个实体的一些基础业务操作。我们以文章(article)为例,实现一个 Data Mapper,里面会有一个 API,用于根据当前文章的 ID 获取其作者(article)和评论(comment)。在 API 中,我们使用 Data Mapper 提供的基础 API 去做一个简单的查询。由于数据库中已经有了数据,我们直接去查询,然后生成一个circle并查找到想要的文章,其中包含作者和两个评论。
Data Mapper 模式与 Active Record 模式的不同点在于,它将数据存储层与领域层解耦,模型不再承担增删改操作的功能。Data Mapper 可以同时处理一个或多个实体类的应用,例如连表查询和统一的数据插入操作等业务操作。如果某个业务需要对数据一致性有较强的要求,并涉及多个实体,Data Mapper 可以直接在其中进行操作。
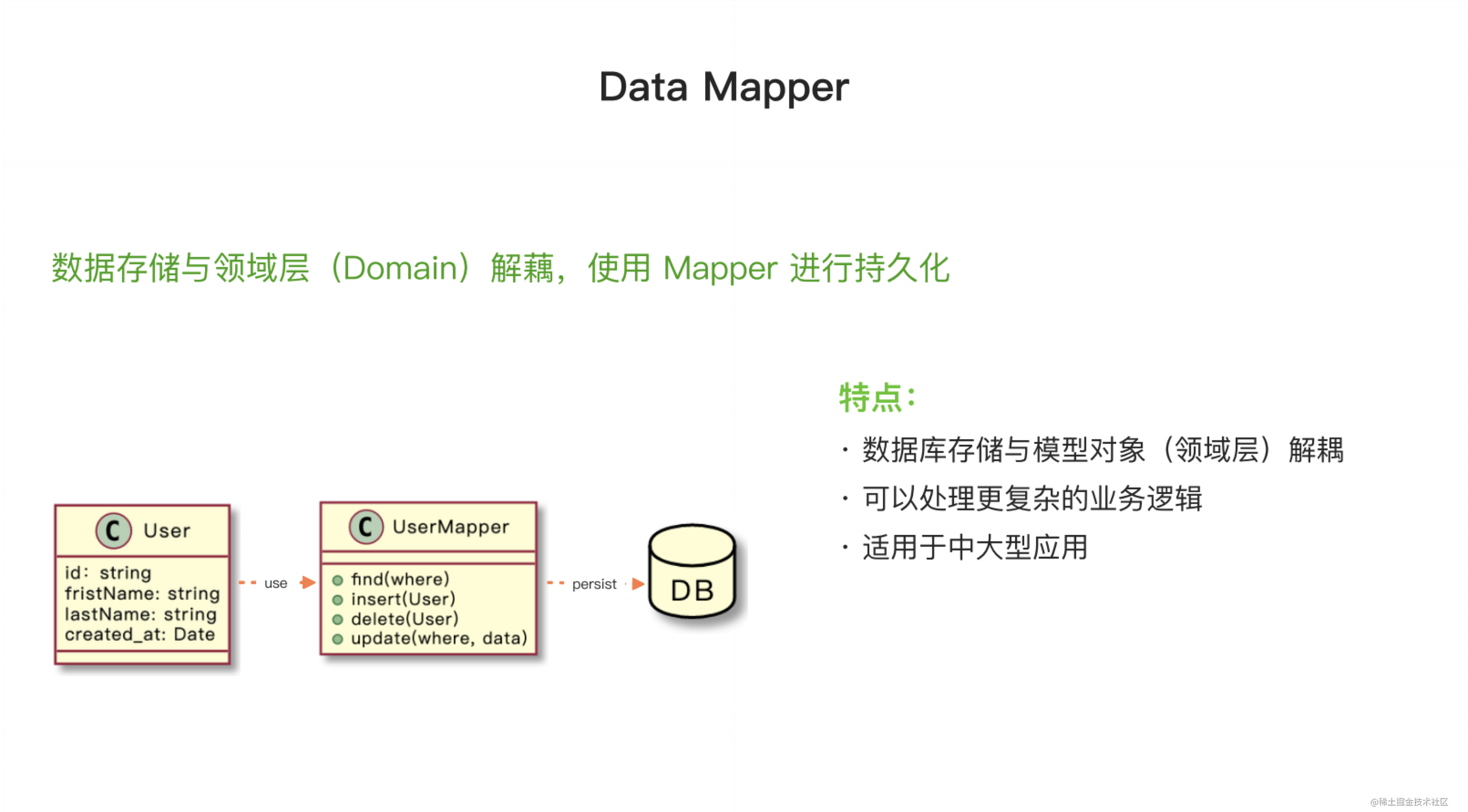
与之前的 Active Record ORM 不同,如果涉及多个模型,我们可能需要单独使用一个服务(Service)将这些模型结合起来进行处理。因此,Data Mapper ORM 更适合处理多实体类的应用。

无码有码,全靠拖拉。跟早早聊一起,玩转低代码,上车链接:www.zaozao.run/conf/c63
ORM 的构成
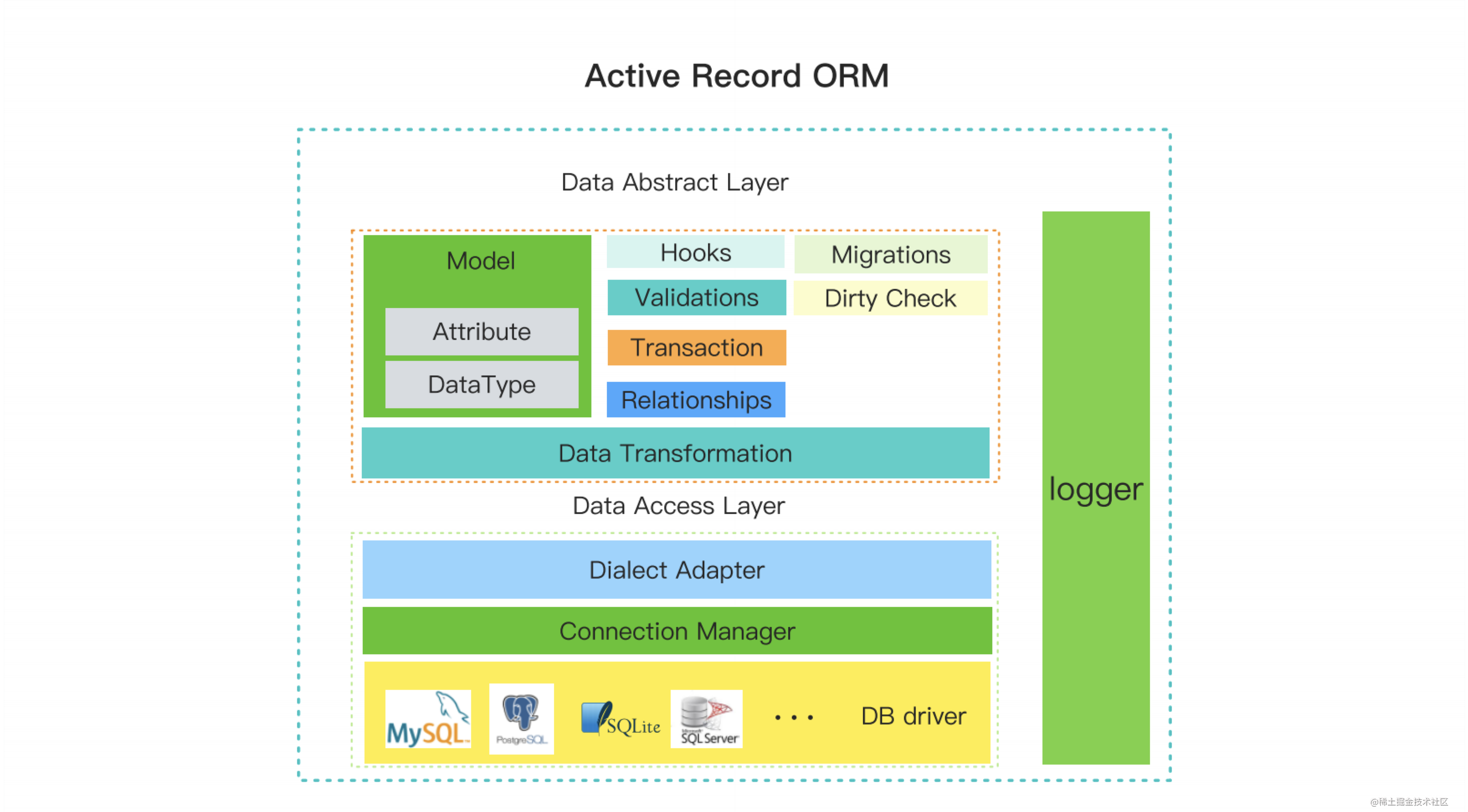
我们接下来将讲解 ORM 的构成,其中我们将重点讲解 Active Record ORM,这是我们常用的一种类型。这些例子都是伪代码。
我将 Active Record ORM 的结构分为两层,第一层为数据抽象层,包含常用的 Base Model,通过继承 Base Model 来创建业务 model。
- API 都通过 Base Model 进行调用,其他基础功能依附于 Base Model。
- Hooks 是插入到 API 执行过程中的钩子函数,可以对特定 model 的字段在执行某个操作时进行通用处理。
- Validations 是 ORM 进行数据预处理的必要部分,使用它可以提高应用的安全性和降低数据库执行 SQL 时的数据类型转换压力。
- Transaction 是对数据事务的抽象和实现,对于一些数据一致性要求高的业务很有必要。
- Relationships 是关系型数据库的核心,每个 model 与 model 之间的关系对应数据库的 ERD。
- Migrations 是 ORM 的一个工具类型的功能,用于同步数据表结构以及数据订正。
- Dirty Check 是检查数据是否更新的功能,在 Hooks 中使用较多。
- Data Transformation 是将查询结果转换为 model 实例,或将查询条件转换为数据库能够识别的数据类型的功能。
第二层为数据访问层。
- Dialect Adopter 是核心功能,将 model 的 API 调用转换成对应的 SQL,并在转换过程中抹平 ORM 会适配的不同数据库之间的方言差异。
- Connection Manager用于管理ORM在应用中的数据库连接。
- DB Driver是数据工具,用于与数据库进行交互。
日志模块是开发和运维中必须的,贯穿整个架构。
数据抽象层
在 Base Model 中,数据表中的某个字段对应着 model 类的成员变量,这是对象关系映射中的重要关系映射。
DataType(数据类型)主要用于表现数据类型,作为 JS 基础类型与数据库数据类型的桥梁,记录了数据库类型和对应的 JS 数据类型,并能在两种语言之间转换数据类型。它还需要表达该类型的 SQL,例如,如果数据类型是 integer,在 MySQL 中表现是什么样子的,在 post Grace 或 circulate 中表现又是什么样子的类型。这样,最小的 ORM 最小单位类就成型了。
Attribute (属性)用于表达数据表中的数据字段,它能够与数据表中的字段设置大致一致,包括是否允许为空、是否有默认值、数据类型等。在 ORM 中,Attribute 还有一个重要的功能,就是数据验证,可以设置一些预置的规则或用户自定义的规则来验证数据的合法性。

在 Active Record ORM 中,Base Model 是其核心组成部分之一。它包含了 CRUD 在内的所有基础 API,同时还要能够读取用户派生的 model。在 Base Model 中,还有针对数据库与应用开发语言之间的不同命名习惯的 name 和 column 成员变量。初始化 model 时,还会有用户设置的 Hooks 和 Validation,用户可以自定义 set/get 方法来对某个字段做一些自定义的操作,在设置字段值的时候自动执行相应操作,比如用 text 类型数据库的字段来存储 JSON 字符串。此外,base model 还会记录各个 model 之间的关系,如 has_one、has_many 等关系。

Hooks 是指一些在函数执行前或执行后需要执行的操作,Hooks 的使用则可以降低业务代码的复杂度,减少工作量,它需要注意一下几点。
- Hooks 需要能够叠加某个操作,以便处理多种逻辑,这些逻辑不会相互影响。
- Hooks 需要有一个原函数,它的入参和返回值类型不能被修改。Hooks 的实现方式有很多种,其中比较直观的一种方式是面向切面编程。在 ORM 的 API 中,一些 API 可以配置或需要配置 hooks,例如 create、update、destroy 等。
- Hooks 的实现需要注意不同的 API 入参和返回值可能不同。
- 实现 Hooks 时需要注意静态成员方法和成员方法、函数执行上下文等问题。
- 在使用 AOP 实现 Hooks 时,我们还需要考虑如何跳过 Hooks 的执行。

接着我们来看一下 Transaction 的简单实现。在 SQL 语法中实现事务并不复杂,一般使用 begin 开始事务,执行业务 SQL,然后使用 commit 提交或 rollback 回滚事务。在代码中实现事务,我们可以提供一些基础的 API,如 begin、commit 和 rollback。在事务开始时,可能需要设置事务的隔离级别。通过这些 API,我们可以保持业务代码的数据一致性。然而,在实现事务时,我们需要考虑如何自动 commit 和 rollback,而不需要手动调用 commit 和 rollback。

数据访问层
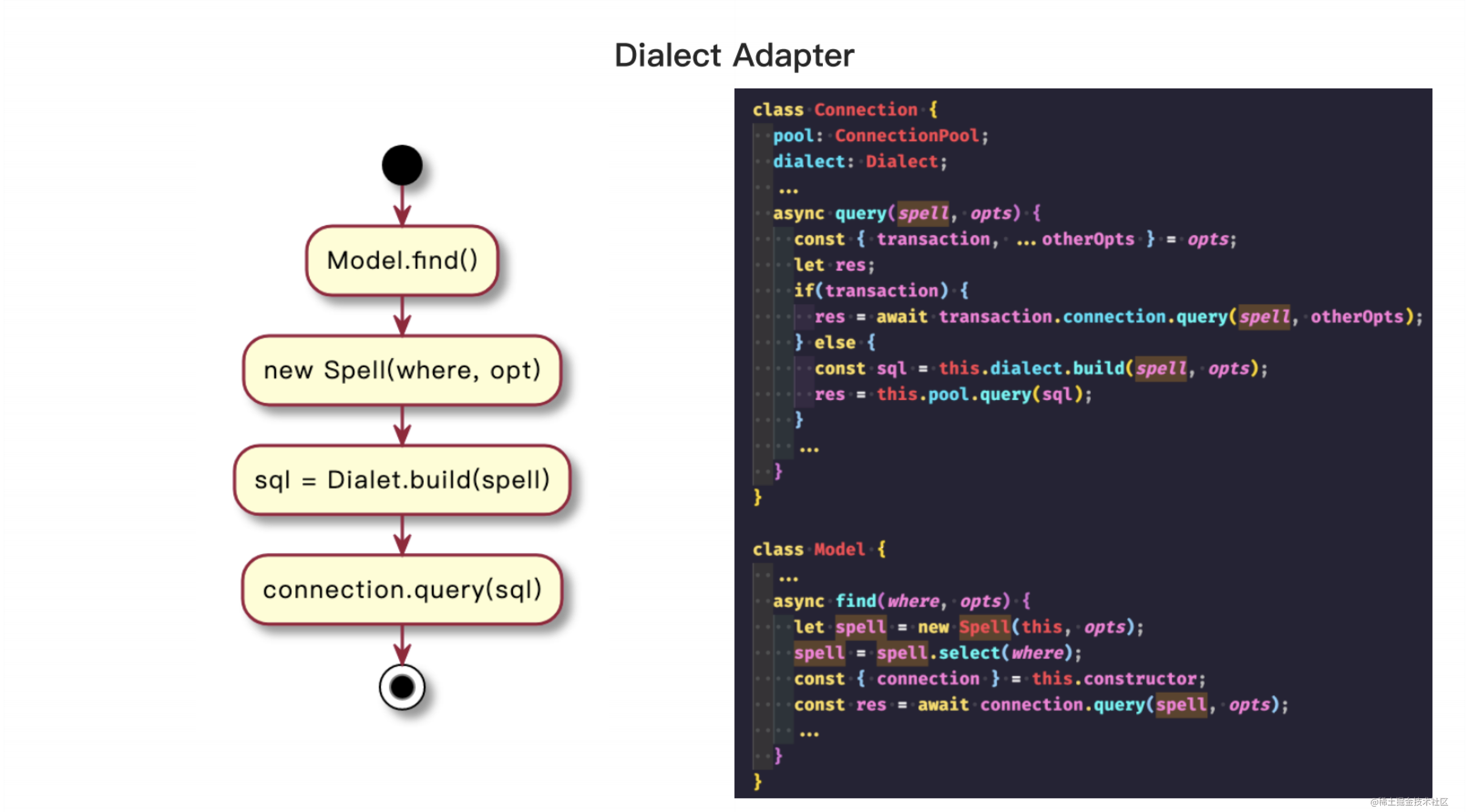
在数据抽象层中,为了适配常用的数据库类型,需要一个中间态去表达 ORM API,这个中间态被称为 Spell。它可以表达实际的 SQL 命令,根据模型的类型去判断操作的数据表,表达查询所需的字段以及常用的 SQL 关键词表达式。

Dialect 需要解析 Spell 表达式,根据方言类型生成特定的 SQL。例如,ORM 需要官方提供支持的MySQL、Postgres、SQL Server和 SQLite 的 Dialect。因此,需要为每种数据库类型编写一个dialect。我们可以将 Spell 表达式的解析抽象成标准的接口,这样开发者就可以实现自己的方言,甚至不仅限于 SQL,还可以是其他类型的查询语言。这样我们就可以使用 ORM 的 API 进行各种类型的查询。

整个查询的执行过程是这样的:假设我们使用 user model 去查询某个用户数据,我们在 user model 中使用 find 方法并根据传参生成对应的 Spell 对象。然后我们在 Connection 类中管理数据库连接池和方言(即 Dialect),实现一个 query 方法,在其中调用 Dialect 生成 SQL,使用 SQL Driver 执行 SQL,最后通过进行数据转换并返回结果。
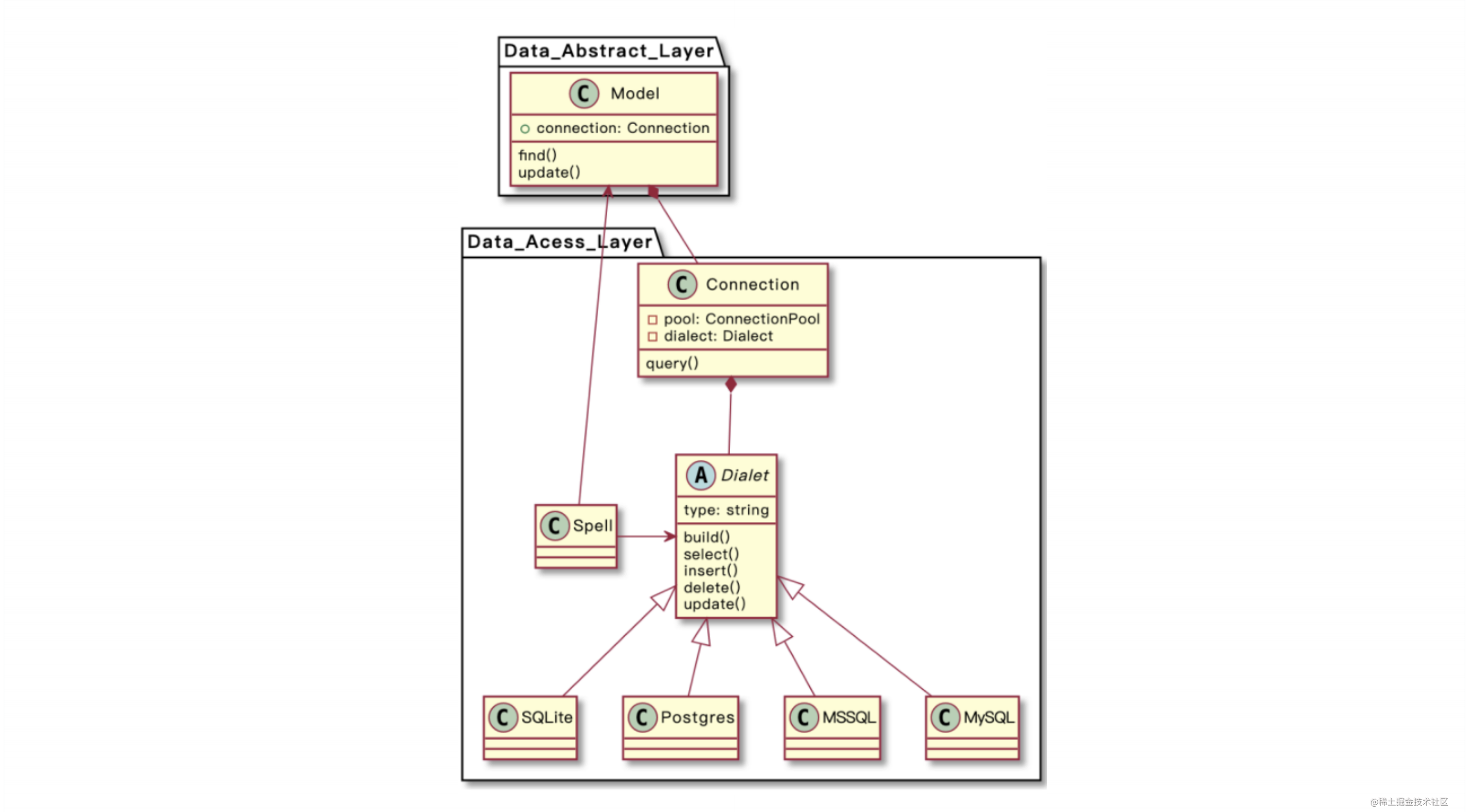
模块之间的关系
让我们再深入了解各个模块之间的关系。首先,数据层面上最主要的实体是 Model。在执行查询操作时, Spell 作为一个中间态,它连接了数据抽象层和数据访问层。同时,Dialect 负责适配数据库方言和生成特定的 SQL。这个结构还可以扩展出更多的功能,不仅限于 SQL 查询。
else
我们思考一下一个相对成熟的 ORM 还需要哪些改进?

欢迎报名第 63 届早早聊大会 – 低代码无代码,了解如何通过低代码平台提高生产力,玩转低代码。上车戳:www.zaozao.run/conf/c63
ORM 问题 / 优化
缓存查询
通过适当的操作来降低数据库的 QPS,例如在多个 service 方法中重复调用某个 Model 的查询时可以使用缓存技术,多次调用时只使用一次结果。
为了避免多次查询,可以通过缓存来保存查询结果,多次调用同一个查询时就可以直接使用缓存结果,从而降低数据库的 QPS。使用这种方法的时候,还需要考虑到缓存的刷新问题,例如,在更新数据时,可以在 update 中添加一个 Hooks,更新时自动刷新缓存。

合理使用 Hooks
使用 Hooks 是在使用 ORM 时常见的问题。Hooks 可以大大简化代码,例如我们可以根据文档内容是否更改来更新其更新时间等字段。在某些复杂情况下,我们可能需要在一个 Model 中的 Hooks 中调用另一个 Model 的增删改操作,例如创建文档后可能需要更新 Book 的操作并触发相应字段的更新,这时我们需要考虑它们之间的关联关系和更新顺序。
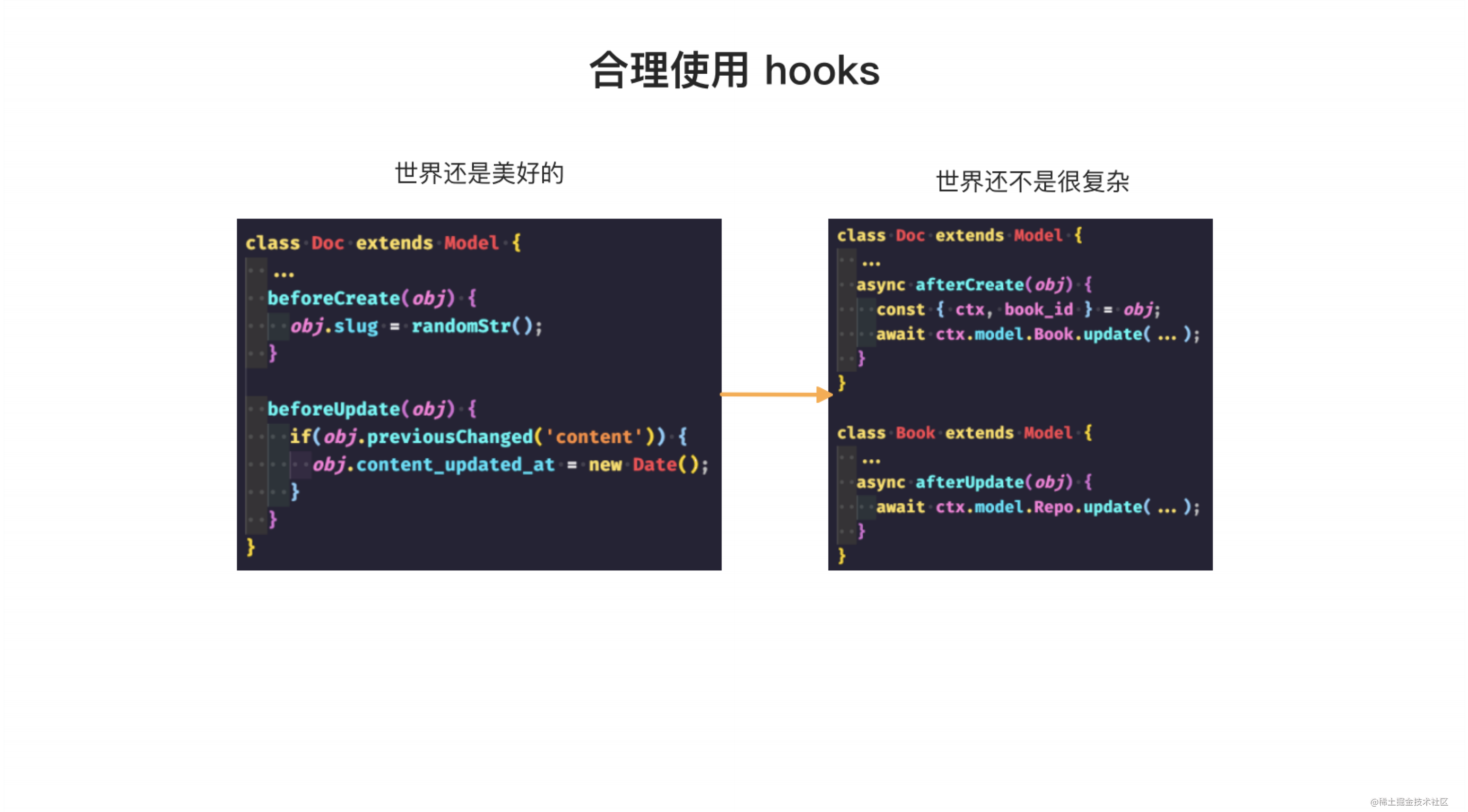
当我们的业务越来越复杂时,例如在更新 Repo 的时候可能需要触发一些 service 方法,而这些 service 方法可能会在 Hooks 方法中直接调用,导致调用链越来越长,越来越复杂。这种不规范的写法会使得代码的复杂度非常难以控制,甚至可能出现循环调用等问题,给新手带来极大的困扰。因此,在使用 Hooks 时需要非常谨慎,避免出现类似的问题。使用 Hooks 需要谨慎,虽然在平时使用时会感觉很方便,但是当需要重构或进行技术重构时,就可能会遇到困难,甚至引起灾难级事故。

查询优化
此外,在使用 ORM 工具时,需要进行查询优化,因为 ORM 只能根据输入参数做一些简单的优化处理,而对于一些极限情况,需要开发人员自己去注意。例如,在进行 SQL 查询用 in 时,由于条件长度较长,可能会因为数据库引擎的原因导致 SQL 无法执行或执行效率较低,此时需要将查询条件进行分组,利用 Node.js 进行分批查询,并在内存中组装结果。
在 ORM 的使用中,需要注意不正确使用 ORM 的 API 调用可能会导致生成子查询,从而降低查询性能。

最后
最后,推荐大家阅读 ORM 的源码(leoric.js.org/)和《企业应用架构模式》(martinfowler.com/eaaCatalog/…),尤其是其中介绍的两种架构模式。
低代码是当今最热门的技术之一,如果你对低代码感兴趣,或者正在研究低代码,欢迎报名第 63 届早早聊大会 – 低代码无代码,跟早早聊一起,玩转低代码。
- 举办时间:2023 年 4 月 15 日 10:00 ~ 17:00
- 截至时间:2023 年 4 月 15 日 19:00
- 举办方式:微信群 PPT 推送 + 线上视频实时直播 + 会后资料推送
- 报名方式:www.zaozao.run/conf/c63
- 大会主办方:前端早早聊

原文链接:https://juejin.cn/post/7220396447464259640 作者:前端早早聊