



想获取更多原创好文,请搜索公众号关注我们吧~ 本文首发于政采云前端博客:初识 Rust —冉冉升起的新星
简介
Rust 是一种兼顾内存安全、高并发和稳定运行的编程语言。它有着惊人的运行速度(有些领域甚至超过 C/C++),能够防止运行时错误,并保证线程安全。Rust 语言使每个人都能够构建可靠、高效的软件。在过去七年的 stackoverflow 的最受喜爱的编程语言中,连续得到榜首的位置。Mozilla 创造了 Rust,Meta、Apple、Amazon、Microsoft、 Google 和华为都使用 Rust 去开发系统基础设施、加密、虚拟化以及其他的底层应用。
理念与优势
曾经世界上只有两种语言,一种需要手动管理内存(c,c++),另一种拥有GC(Java,Python,JS),而 Rust 创造了第三种可能性。
Rust 中不存在 GC ,它希望开发者自己去管理内存,使开发者对于内存有更大的控制权,管理过程却不会向 C 和 C++ 一样繁琐,少了许多痛苦。可以说,一旦你的程序通过编译成功的运行了起来,运行时便不再会出现任何内存 Bug。
之所以能做到这一点,原因在于Rust 使用了一种非常独特的内存管理手段,其核心理念基于 “所有权”(owernership)。基本上,Rust 会追踪“谁”在读和写具体的一块内存。Rust 知道一块内存是谁在使用,也知道这块内存是否已经没人使用,这时可以立即释放这块内存。Rust 在编译时强制内存规则,这个机制让内存 Bug 几乎不会存在于运行时(runtime)。你不需要手动追踪内存,编译器会帮你处理好。
除此以外,Rust 还有很出色的配套工具。Rust 的文档写得很详细,有着一流的包管理器和构建工具,直接集成了单元测试。
生态
SWC
SWC 是一个可扩展的基于 Rust 的平台,用于下一代快速开发工具。Next.js、Parcel 等工具都在使用它。
Deno
Deno 是一个简单、先进且安全的 JavaScript 和 TypeScript 运行时环境。Deno 的创始人是 Node.js 的创始人,他企图替换 Node.js。
Ripgrep
Ripgrep 是一个面向行的搜索工具,它是所有同类工具中性能最为出色的,并且在 Windows、macOS 和 Linux 上都具有一流的支持。顺带一提,VSCode 所使用的全局搜索就是基于该插件。
语法初步介绍
安装 & Hello World
推荐使用 VSCode 和 Rust Analyzer 进行开发来获得最佳体验
安装 Rust 的主要方式是通过 Rustup 这一工具,它既是一个 Rust 安装器又是一个版本管理工具。
要下载 Rustup 并安装 Rust,请在终端中运行以下命令,然后遵循屏幕上的指示
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
要检查是否正确安装了 Rust,打开命令行并输入:
$ rustc --version
你应该可以看到按照以下格式显示的最新稳定版本的版本号、对应的 Commit Hash 和 Commit 日期:
rustc x.y.z (abcabcabc yyyy-mm-dd)
如果看到了这样的信息,就说明 Rust 已经安装成功了!
Cargo 是 Rust 的构建系统和包管理器,它可以为你处理很多任务,比如构建代码、下载依赖库并编译这些库
我们使用 Cargo 创建一个新项目,运行以下命令:
$ cargo new hello_cargo
$ cd hello_cargo
第一行命令新建了名为 hello_cargo 的目录和项目。我们将项目命名为 hello_cargo
使用 cargo run 在一个命令中同时编译并运行生成的可执行文件
Cargo 还提供了一个叫 cargo check 的命令。该命令快速检查代码确保其可以编译,但并不产生可执行文件
通常 cargo check 要比 cargo build 快得多,因为它省略了生成可执行文件的步骤。如果你在编写代码时持续地进行检查,cargo check 可以让你快速了解现在的代码能不能正常通过编译!为此很多 Rustaceans 编写代码时定期运行 cargo check 确保它们可以编译。当准备好使用可执行文件时才运行 cargo build。
变量与可变性
在 Rust 中,变量默认是不可改变的(immutable),这意味着一旦我们给变量赋值,这个值就不再可以修改了
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}
保存并使用 cargo run 运行程序。应该会看到一条与不可变性有关的错误信息,如下输出所示:
error[E0384]: cannot assign twice to immutable variable `x`
Rust 编译器保证,如果声明一个值不会变,它就真的不会变,所以你不必自己跟踪它。这意味着你的代码更易于推导。
不过可变性也是非常有用的,可以用来更方便地编写代码。尽管变量默认是不可变的,你仍然可以在变量名前添加 mut 来使其可变
例如,让我们将 src/main.rs 修改为如下代码:
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}
现在运行这个程序,将不再报错
数据类型
在 Rust 中,每一个值都属于某一个 数据类型(data type),这告诉 Rust 它被指定为何种数据,以便明确数据处理方式。我们将看到两类数据类型子集:标量(scalar)和复合(compound)。标量(scalar)类型代表一个单独的值,包含四种类型:整型、浮点型、布尔类型和字符类型。复合类型(Compound types)可以将多个值组合成一个类型。Rust 有两个原生的复合类型:元组(tuple)和数组(array)。
元组类型
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。元组长度固定:一旦声明,其长度不会增大或缩小。
我们使用包含在圆括号中的逗号分隔的值列表来创建一个元组。元组中的每一个位置都有一个类型,而且这些不同值的类型也不必是相同的。这个例子中使用了可选的类型注解:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}
tup 变量绑定到整个元组上,因为元组是一个单独的复合元素。为了从元组中获取单个值,可以使用模式匹配(pattern matching)来解构(destructure)元组值,像这样:
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}
我们也可以使用点号(.)后跟值的索引来直接访问它们。例如:
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}
这个程序创建了一个元组,x,然后使用其各自的索引访问元组中的每个元素。跟大多数编程语言一样,元组的第一个索引值是 0。
元组非常适合在成员的语义不明确的情况下使用,比起使用结构体费尽心思起一些并不直观的字段名,直接使用元组则更为省力,以下是一个使用元组和枚举定义 IP 地址的例子:
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
数组类型
另一个包含多个值的方式是 数组(array)。与元组不同,数组中的每个元素的类型必须相同。Rust 中的数组与一些其他语言中的数组不同,Rust 中的数组长度是固定的。
我们将数组的值写成在方括号内,用逗号分隔:
fn main() {
let a = [1, 2, 3, 4, 5];
}
当你想要确保总是有固定数量的元素时,数组非常有用。但是数组并不如 vector 类型灵活。vector 类型是标准库提供的一个 允许 增长和缩小长度的类似数组的集合类型。
可以像这样编写数组的类型:在方括号中包含每个元素的类型,后跟分号,再后跟数组元素的数量。
let a: [i32; 5] = [1, 2, 3, 4, 5];
这里,i32 是每个元素的类型。分号之后,数字 5 表明该数组包含五个元素。
你还可以通过在方括号中指定初始值加分号再加元素个数的方式来创建一个每个元素都为相同值的数组:
let a = [3; 5];
变量名为 a 的数组将包含 5 个元素,这些元素的值最初都将被设置为 3。这种写法与 let a = [3, 3, 3, 3, 3]; 效果相同,但更简洁。
当尝试用索引访问一个元素时,Rust 会检查指定的索引是否小于数组的长度。如果索引超出了数组长度,Rust 会 panic,这是 Rust 术语,它用于程序因为错误而退出的情况。在很多底层语言中,并没有进行这类检查,这样当提供了一个不正确的索引时,就会访问无效的内存。通过立即退出而不是允许内存访问并继续执行,Rust 让你避开此类错误。
函数
Rust 代码中的函数和变量名使用 snake case 规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。这是一个包含函数定义示例的程序:
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}
在函数签名中,必须 声明每个参数的类型。当定义多个参数时,使用逗号分隔,像这样:
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("The measurement is: {value}{unit_label}");
}
函数可以向调用它的代码返回值。我们并不对返回值命名,但要在箭头(->)后声明它的类型。在 Rust 中,函数的返回值等同于函数体最后一个表达式的值。使用 return 关键字和指定值,可从函数中提前返回;但大部分函数隐式的返回最后的表达式。这是一个有返回值的函数的例子:
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}
所有权
所有权(系统)是 Rust 最为与众不同的特性,对语言的其他部分有着深刻含义。它让 Rust 无需垃圾回收(garbage collector)即可保障内存安全,因此理解 Rust 中所有权如何工作是十分重要的。本章,我们将讲到所有权,受限于篇幅,就不涉及相关功能:借用(borrowing)、slice 。
所有权规则
首先,让我们看一下所有权的规则。当我们通过举例说明时,请谨记这些规则:
Rust 中的每一个值都有一个 所有者(owner)。
值在任一时刻有且只有一个所有者。
当所有者(变量)离开作用域,这个值将被丢弃。
变量作用域
在所有权的第一个例子中,我们看看一些变量的 作用域(scope)。作用域是一个项(item)在程序中有效的范围。假设有这样一个变量:
let s = "hello";
变量 s 绑定到了一个字符串字面值,这个字符串值是硬编码进程序代码中的。这个变量从声明的点开始直到当前 作用域 结束时都是有效的。示例中的注释标明了变量 s 在何处是有效的。
{ // s 在这里无效,它尚未声明
let s = "hello"; // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,s 不再有效
第一个堆上数据类型-String
为了演示所有权的规则,我们需要一个比 数据类型 章节中讲到的都要复杂的数据类型。前面介绍的类型都是已知大小的,可以存储在栈中,并且当离开作用域时被移出栈,如果代码的另一部分需要在不同的作用域中使用相同的值,可以快速简单地复制它们来创建一个新的独立实例。不过我们需要寻找一个存储在堆上的数据来探索 Rust 是如何知道该在何时清理数据的。
我们已经见过字符串字面值,即被硬编码进程序里的字符串值。字符串字面值是很方便的,不过它们并不适合使用文本的每一种场景。原因之一就是它们是不可变的。另一个原因是并非所有字符串的值都能在编写代码时就知道。
可以使用 from 函数基于字符串字面值来创建 String,如下:
let s = String::from("hello");
这两个冒号 :: 是运算符,允许将特定的 from 函数置于 String 类型的命名空间(namespace)下,而不需要使用类似 string_from 这样的名字。
可以修改此类字符串:
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() 在字符串后追加字面值
println!("{}", s); // 将打印 `hello, world!`
在大部分没有 GC 的语言中,识别出不再使用的内存并调用代码显式释放就是我们的责任了,跟请求内存的时候一样。从历史的角度上说正确处理内存回收曾经是一个困难的编程问题。如果忘记回收了会浪费内存。如果过早回收了,将会出现无效变量。如果重复回收,这也是个 bug。我们需要精确地为一个 allocate 配对一个 free。
Rust 采取了一个不同的策略:内存在拥有它的变量离开作用域后就被自动释放。下面是示例中作用域例子的一个使用 String 而不是字符串字面值的版本:
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效
这是一个将 String 需要的内存返回给分配器的很自然的位置:当 s 离开作用域的时候。当变量离开作用域,Rust 为我们调用一个特殊的函数。这个函数叫做 drop,在这里 String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop。
移动
在 Rust 中,多个变量可以采取不同的方式与同一数据进行交互。让我们看看示例中一个使用整型的例子。
let x = 5;
let y = x;
我们大致可以猜到这在干什么:“将 5 绑定到 x;接着生成一个值 x 的拷贝并绑定到 y”。现在有了两个变量,x 和 y,都等于 5。这也正是事实上发生了的,因为整数是有已知固定大小的简单值,所以这两个 5 被放入了栈中。
现在看看这个 String 版本:
let s1 = String::from("hello");
let s2 = s1;
这看起来与上面的代码非常类似,所以我们可能会假设他们的运行方式也是类似的:也就是说,第二行可能会生成一个 s1 的拷贝并绑定到 s2 上。不过,事实上并不完全是这样。
看看图 1-1 以了解 String 的底层会发生什么。String 由三部分组成,如图左侧所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。这一组数据存储在栈上。右侧则是堆上存放内容的内存部分。
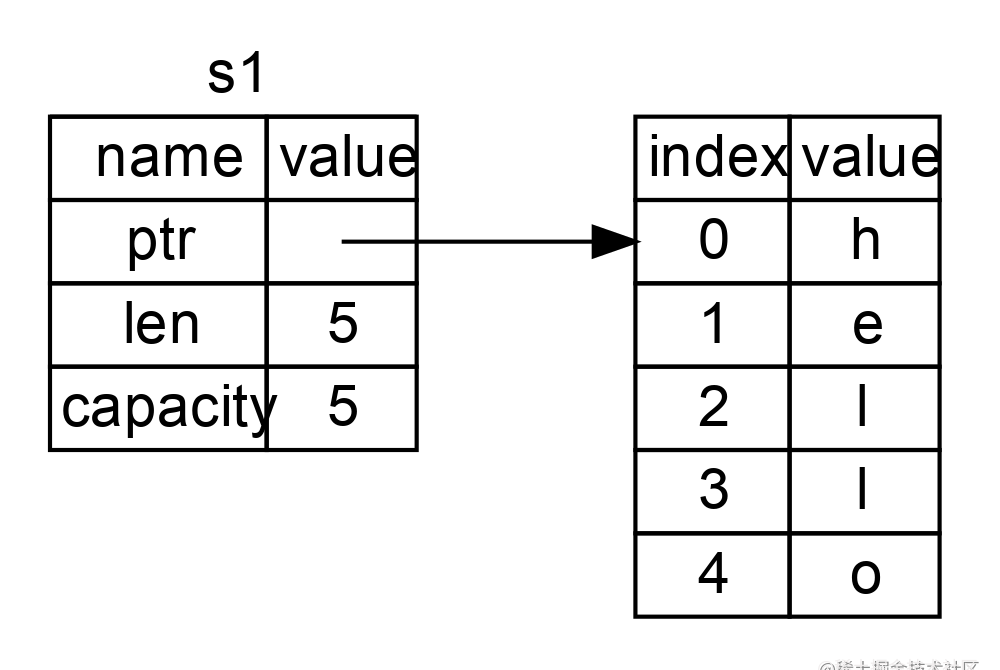
图 1-1:将值 "hello" 绑定给 s1 的 String 在内存中的表现形式
长度表示 String 的内容当前使用了多少字节的内存。容量是 String 从分配器总共获取了多少字节的内存。长度与容量的区别是很重要的,不过在当前上下文中并不重要,所以现在可以忽略容量。
当我们将 s1 赋值给 s2,String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据。换句话说,内存中数据的表现如图 1-2 所示。
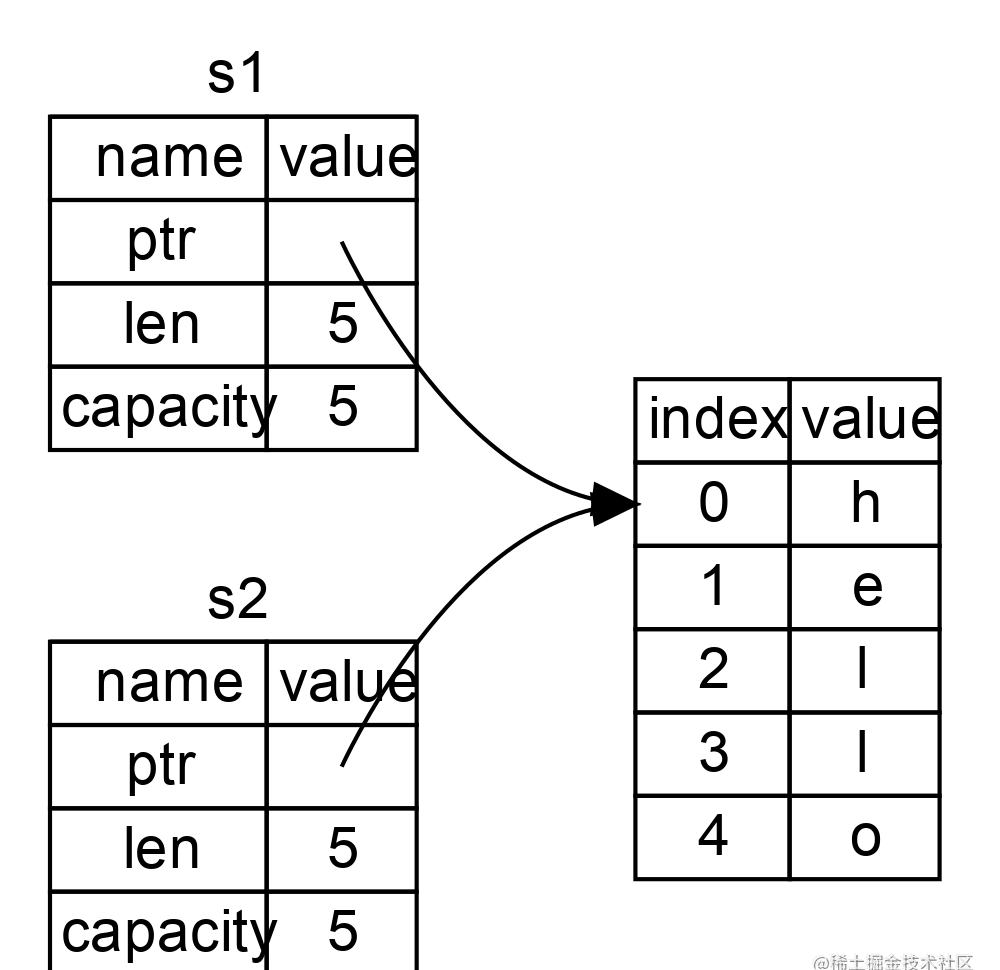
图 1-2:变量 s2 的内存表现,它有一份 s1 指针、长度和容量的拷贝
这个表现形式看起来 并不像 图 1-3 中的那样,如果 Rust 也拷贝了堆上的数据,那么内存看起来就是这样的。如果 Rust 这么做了,那么操作 s2 = s1 在堆上数据比较大的时候会对运行时性能造成非常大的影响。
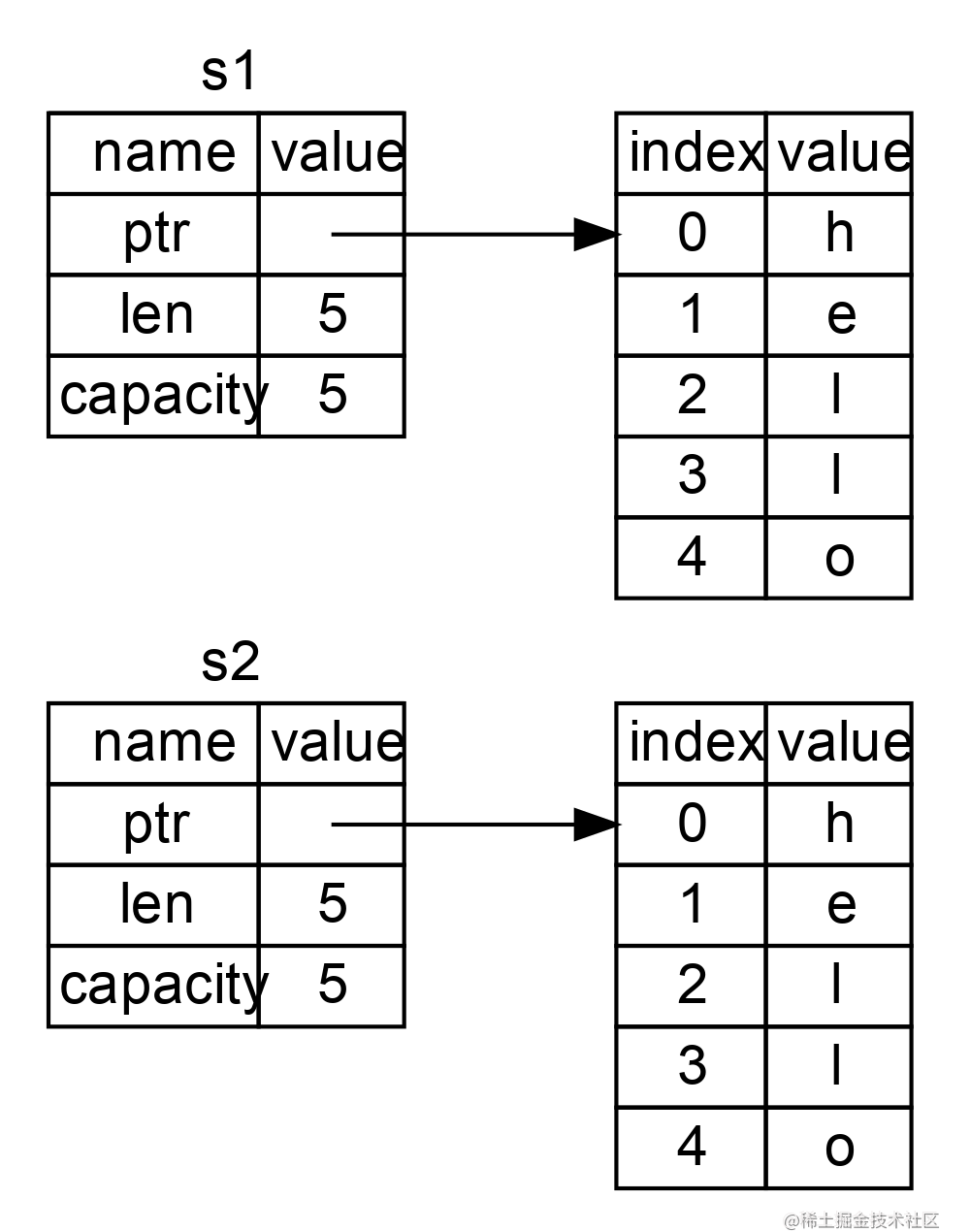
图 1-3:另一个 s2 = s1 时可能的内存表现,如果 Rust 同时也拷贝了堆上的数据的话
之前我们提到过当变量离开作用域后,Rust 自动调用 drop 函数并清理变量的堆内存。不过图 1-2 展示了两个数据指针指向了同一位置。这就有了一个问题:当 s2 和 s1 离开作用域,他们都会尝试释放相同的内存。这是一个叫做 二次释放(double free)的错误,也是之前提到过的内存安全性 bug 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
为了确保内存安全,在 let s2 = s1; 之后,Rust 认为 s1 不再有效,因此 Rust 不需要在 s1 离开作用域后清理任何东西。看看在 s2 被创建之后尝试使用 s1 会发生什么;这段代码不能运行:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
你会得到一个类似如下的错误,因为 Rust 禁止你使用无效的引用。
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
如果你在其他语言中听说过术语 浅拷贝(shallow copy)和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据可能听起来像浅拷贝。不过因为 Rust 同时使第一个变量无效了,这个操作被称为 移动(move),而不是叫做浅拷贝。上面的例子可以解读为 s1 被 移动 到了 s2 中。那么具体发生了什么,如图 1-4 所示。
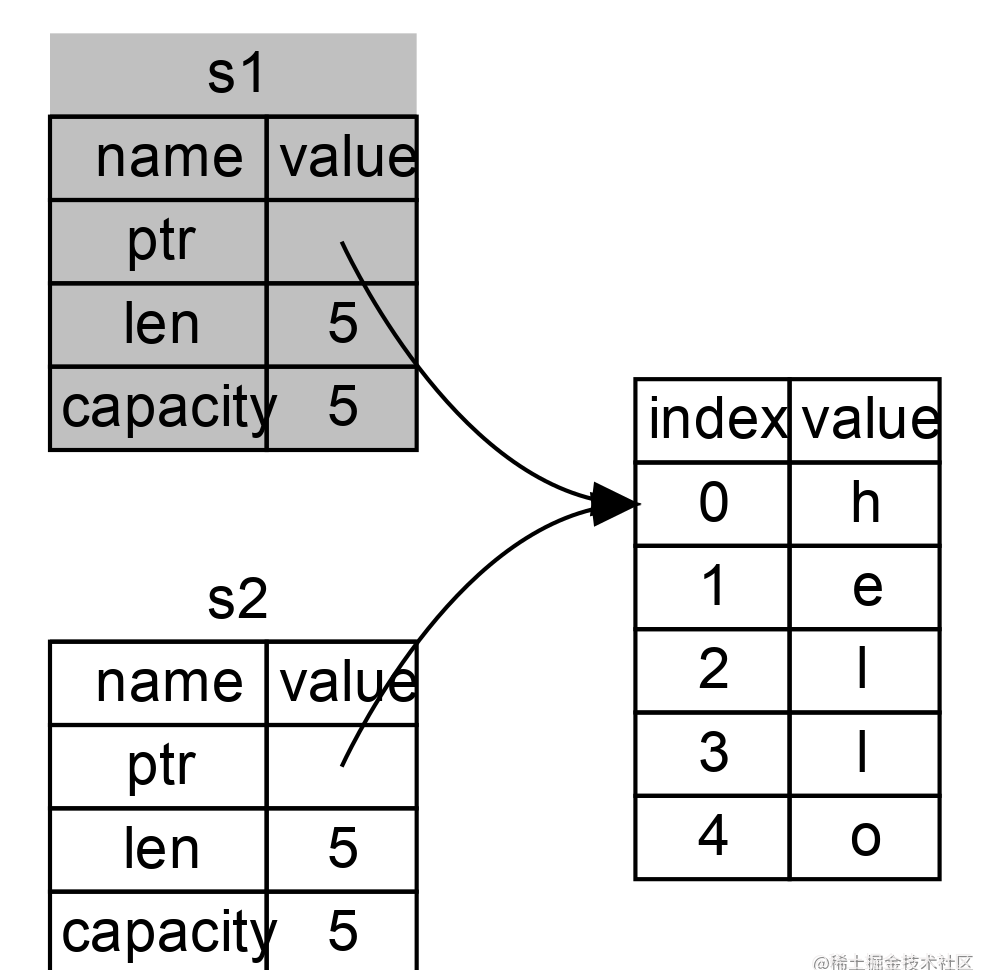
图 1-4:s1 无效之后的内存表现
这样就解决了我们的问题!因为只有 s2 是有效的,当其离开作用域,它就释放自己的内存,完毕。
另外,这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何 自动 的复制可以被认为对运行时性能影响较小。
克隆
如果我们 确实 需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的通用函数。
这是一个实际使用 clone 方法的例子:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
这段代码能正常运行,并且明确产生图 1-3 中行为,这里堆上的数据 确实 被复制了。
当出现 clone 调用时,你知道一些特定的代码被执行而且这些代码可能相当消耗资源。你很容易察觉到一些不寻常的事情正在发生。
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过 x 依然有效且没有被移动到 y 中。
原因是像整型这样的在编译时已知大小的类型被整个存储在栈上,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效。换句话说,这里没有深浅拷贝的区别,所以这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它。
Rust 有一个叫做 Copy trait 的特殊注解,可以用在类似整型这样的存储在栈上的类型上。如果一个类型实现了 Copy trait,那么一个旧的变量在将其赋值给其他变量后仍然可用。
所有权与函数
将值传递给函数与给变量赋值的原理相似。向函数传递值可能会移动或者复制,就像赋值语句一样。以下示例使用注释展示变量何时进入和离开作用域:
fn main() {
let s = String::from("hello"); // s 进入作用域
takes_ownership(s); // s 的值移动到函数里 ...
// ... 所以到这里不再有效
let x = 5; // x 进入作用域
makes_copy(x); // x 应该移动函数里,
// 但 i32 是 Copy 的,
// 所以在后面可继续使用 x
} // 这里,x 先移出了作用域,然后是 s。但因为 s 的值已被移走,
// 没有特殊之处
fn takes_ownership(some_string: String) { // some_string 进入作用域
println!("{}", some_string);
} // 这里,some_string 移出作用域并调用 `drop` 方法。
// 占用的内存被释放
fn makes_copy(some_integer: i32) { // some_integer 进入作用域
println!("{}", some_integer);
} // 这里,some_integer 移出作用域。没有特殊之处
当尝试在调用 takes_ownership 后使用 s 时,Rust 会抛出一个编译错误。
返回值与作用域
返回值也可以转移所有权。示例展示了一个返回了某些值的示例,与上述示例一样带有类似的注释。
fn main() {
let s1 = gives_ownership(); // gives_ownership 将返回值
// 转移给 s1
let s2 = String::from("hello"); // s2 进入作用域
let s3 = takes_and_gives_back(s2); // s2 被移动到
// takes_and_gives_back 中,
// 它也将返回值移给 s3
} // 这里,s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,
// 所以什么也不会发生。s1 离开作用域并被丢弃
fn gives_ownership() -> String { // gives_ownership 会将
// 返回值移动给
// 调用它的函数
let some_string = String::from("yours"); // some_string 进入作用域。
some_string // 返回 some_string
// 并移出给调用的函数
}
// takes_and_gives_back 将传入字符串并返回该值
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // 返回 a_string 并移出给调用的函数
}
变量的所有权总是遵循相同的模式:将值赋给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。
虽然这样是可以的,但是在每一个函数中都获取所有权并接着返回所有权有些啰嗦。幸运的是,Rust 对此提供了一个不用获取所有权就可以使用值的功能,叫做 引用(references)。
我们初步地了解了 Rust 的所有权机制,但这仅仅是 Rust 的一小部分。除此以外还有许多重要的机制,包括 引用、切片,结构体,枚举与模式匹配、模块、常见集合、泛型、特征、生命周期、迭代器、智能指针等等。因为时间原因,就不展开继续讲了,如果感兴趣可以自行查阅文档学习。
Rust的缺点
Rust 有非常陡峭的学习曲线。Rust 的抽象层级要比绝大部分 Web 语言低。
Rust 让你思考你的代码的方方面面,这对于系统开发是极为重要的。Rust 强制你思考内存是如何共享和拷贝的。Rust 强制你思考少见但是真实的边缘场景,以确保这些边缘场景也被控制住了。
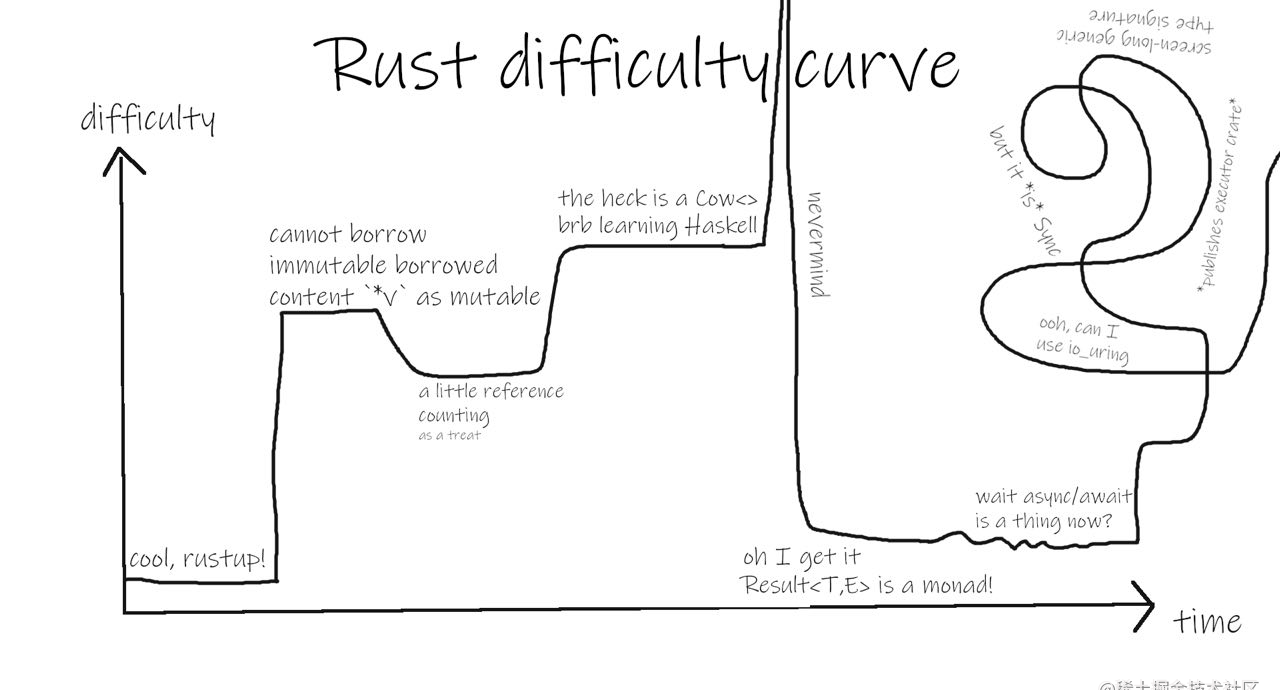
图 1-5:Rust 的难度曲线
总结
Rust 的所有权、生命周期是一种比较新奇的概念,但是,它本质上就是提供了一种对内存的控制方式,仅此而已。而这种访问方式,给了我们一种内存安全的可能,它需要我们编写程序的时候付出更多,但是这种 trade off 是有价值的。
Rust 对 wasm 有着一流的支持。在编译、打包等对性能苛刻的领域,基于 Rust 的工具也开始逐渐开花。在区块链和智能合约领域,Rust 则是有许多杀手级应用,将来很有可能一统江湖。总而言之,如果你需要一个稳定且高性能的基础设施或系统应用,Rust 就是不二之选。
我们可以看到集表达力、高性能、内存安全于一身的Rust,在很多场景里都能大施拳脚。因此,推荐大家学习下 Rust,掌握了Rust,就相当于掌握了很多其他语言的精髓,把Rust引入你的技术栈,也会让自己职业生涯多一门面向未来的利器。
推荐阅读
开源作品
- 政采云前端小报
开源地址 www.zoo.team/openweekly/ (小报官网首页有微信交流群)
- 商品选择 sku 插件
招贤纳士
政采云技术团队(Zero),包含前端(ZooTeam)、后端、测试、UED 等,Base 在风景如画的杭州,一个富有激情和技术匠心精神的成长型团队。政采云前端,隶属于政采云研发部。团队现有 90 余个前端小伙伴,平均年龄 27 岁,近 3 成是全栈工程师,妥妥的青年风暴团。成员构成既有来自于阿里、网易的“老”兵,也有浙大、中科大、杭电等校的应届新人。团队在日常的业务对接之外,还在物料体系、工程平台、搭建平台、性能体验、云端应用、数据分析及可视化等方向进行技术探索和实战,推动并落地了一系列的内部技术产品,持续探索前端技术体系的新边界。
如果你想改变一直被事折腾,希望开始能折腾事;如果你想改变一直被告诫需要多些想法,却无从破局;如果你想改变你有能力去做成那个结果,却不需要你;如果你想改变你想做成的事需要一个团队去支撑,但没你带人的位置;如果你想改变既定的节奏,将会是“5 年工作时间 3 年工作经验”;如果你想改变本来悟性不错,但总是有那一层窗户纸的模糊… 如果你相信相信的力量,相信平凡人能成就非凡事,相信能遇到更好的自己。如果你希望参与到随着业务腾飞的过程,亲手推动一个有着深入的业务理解、完善的技术体系、技术创造价值、影响力外溢的前端团队的成长历程,我觉得我们该聊聊。任何时间,等着你写点什么,发给 ZooTeam@cai-inc.com

原文链接:https://juejin.cn/post/7223415381788213304 作者:政采云技术