
啊哈,我也实现了大文件的断点续传
之前看到了几位大佬写的前端大文件上传的文章,感觉这个功能还挺有意思的,我也试了试,在大佬的代码上加了一些自己的想法。这篇文章算是一个自己的总结,也希望能给想做这个功能的同学一些帮助。
功能总结如下:
- 大文件的分片上传
- 文件的断点续传
- 并发控制
- 错误重试
参考文章(非常推荐大家阅读):
- 写给新手前端的各种文件上传攻略,从小图片到大文件断点续传
- 字节跳动面试官:请你实现一个大文件上传和断点续传
- 字节跳动面试官,我也实现了大文件上传和断点续传
项目地址:gitee
话不多说,下面开始
本文技术栈:
前端:vue,element-ui,webWorker,axios,spark-MD5以及一些文件上传api
后端:express+multiparty
需求整理
在正式开始之前,先来梳理一下要实现的功能:
- 由于要上传的文件比较大,因此我们不可能直接将整个文件直接上传,因此需要对文件进行切割,也就是分片,将多个分片依次上传,最终由服务端将切片进行合并,从而得到最终文件
- 大文件上传时间比较长,并且分片后请求较多,上传过程中,可能会遇到用户断网等问题,因此,我们的上传功能需要支持断点续传(参考迅雷的下载过程)
- 如果将每个分片设为1M,那么一个200M的文件就会有200个分片,也就是会有200个请求。这200个请求不可能同时发出去,因此,我们需要对并发的数量做一个控制。
- 前面说了,用户上传过程中可能会遇到断网的问题,或者某个切片会丢失,为了优化用户体验,应该对每个失败的请求进行重试。
确定好功能之后,下面来梳理一下整个流程以及一些技术细节
-
使用
<input type='file'>来承载上传的文件,当用户选择文件时,触发change事件,可以获取到文件的信息,并且给用户一个本地预览 -
当用户点击上传时,开始对文件进行切片,使用Blob.slice方法
-
使用文件的
hash作为后端存储时的文件名,因此在上传前应该先计算文件的hash。计算hash是一个比较费时的操作,因此我们使用Worker线程计算,防止页面假死。 -
考虑断点续传的情况:如果用户上传期间断开了链接,之后重新上传时,应该只上传还没有上传的部分。为了实现这个功能,我们有两种方案:
- 在客户端记录用户上传过哪些切片,比如
localStorage - 在上传之前向服务端发一个
verify请求,服务器查找用户上传文件的文件夹,获取用户已经上传的部分并返回给客户端
我们采用第二种方案。
- 在客户端记录用户上传过哪些切片,比如
-
过滤出还没有上传的部分,开始上传
-
用户点击暂停,这里我没有使用原生
xhr的abort,没有取消已经发出去的请求,而是暂停了后续的请求,也算是一个不一样的地方吧,后文会讲到我是怎么实现的。 -
用户点击恢复,恢复被暂停的请求
-
如果某些切片超出了重试的次数之后仍然失败,用户可以点击重试按钮,将失败的部分重新上传
-
当全部切片发送完成时,请求服务器合并切片
流程图如下:
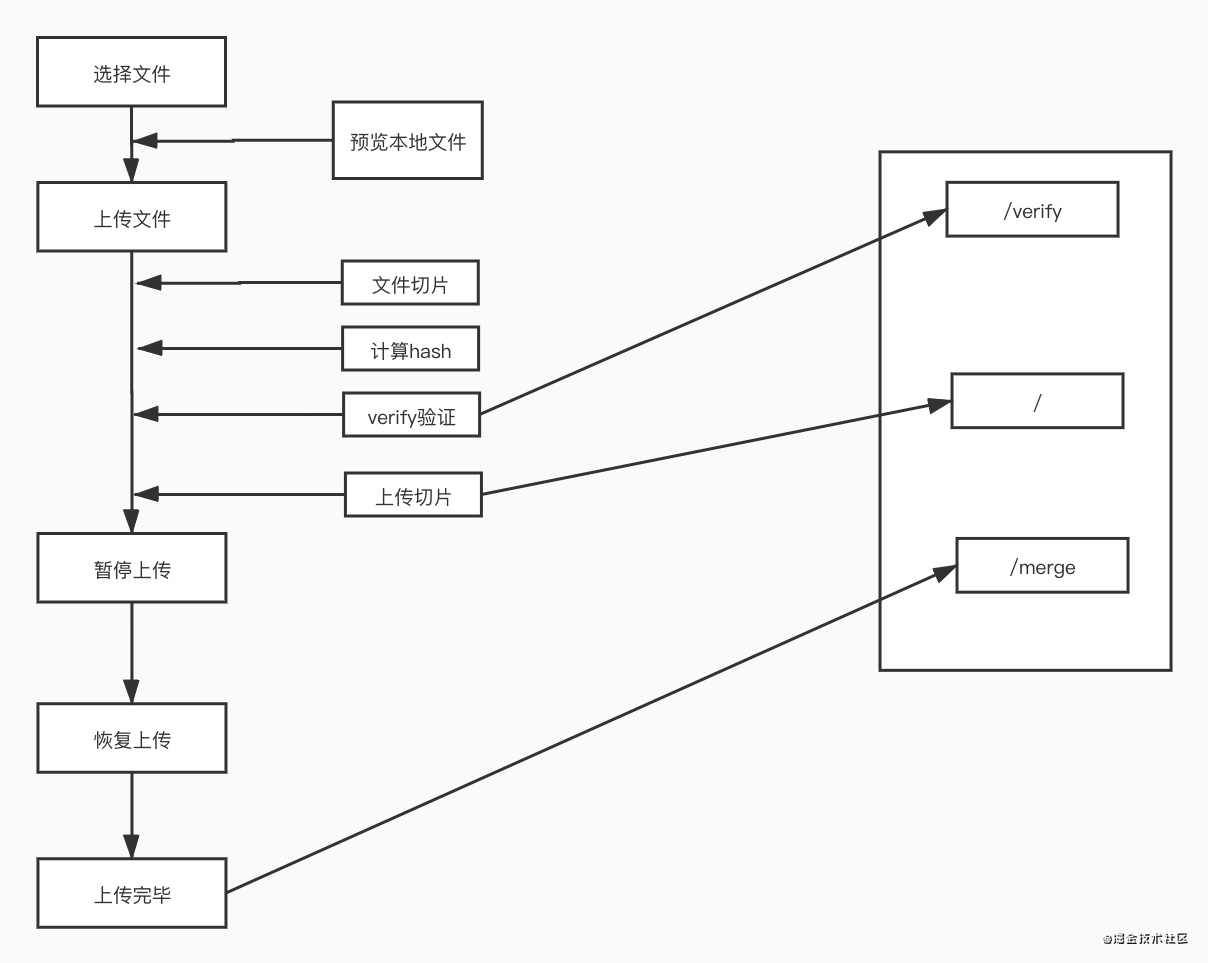

基本结构
两个配置项:
const CHUNK_SIZE = 1024 * 1024 * 0.5 // 每个切片大小,单位字节
const CONCURRENCY_LIMIT = 4 // 并发数量限制
定义上传的状态
const UPLOAD_STATUS = {
calculatingHash: "calculatingHash", // 正在计算hash
waiting: "waiting", // 等待用户开始上传
uploading: "uploading", // 正在上传
abort: "abort", // 暂停上传
success: "success", // 后端文件合并完毕,文件秒传时也应该是这个状态
fail: "fail" // 上传失败
}
data中的量:
data() {
return {
showPreview: false, // 本地文件预览加载完成时为true
file: null, // 文件
hash: "", // 文件hash
worker: null, // worker线程
hashPercent: 0, // hash计算进度,用于显示hash计算进度条
uploadedLen: 0, // 已经上传过的切片数量
chunksLen: 0, // 总切片数量
fileChunks: [], // 记录所有切片
Scheduler: null, // 并发任务调度器,所有的请求会通过该调度器来完成,并且实现了错误重试功能
uploadStatus: UPLOAD_STATUS,
curStatus: UPLOAD_STATUS.waiting // 当前的上传状态
}
}
定义的方法:
// 当input触发change事件时触发,用于获取文件
handleFileChange(e) {}
// 用于预览文件
preview() {}
// 用户点击上传时触发,此方法中需要调用文件分片方法,计算hash方法,verify验证方法,上传切片方法
async handleUpload() {}
// 上传失败时,用户点击重试按钮时触发
async handleRetry() {}
// 文件切片的方法
createFileChunks() {}
// 计算文件hash的方法
getFileHash() {}
// 请求服务器哪些切片已经上传过
async verifyUpload(filename, fileHash) {}
// 上传切片
async uploadChunks(chunksNeedUpload) {}
// 请求服务器合并切片
async mergeRequest() {}
// 用户点击暂停时触发
handlePause() {}
// 用户点击继续按钮时触发
handleResume() {}
html结构如下,主要就是几个按钮,hash计算进度条,上传进度条和用于预览的video标签
<input type="file" @change="handleFileChange" />
<el-button
type="primary"
@click="handleUpload"
v-show="curStatus === uploadStatus.waiting"
>上传</el-button
>
<el-button
type="primary"
@click="handleRetry"
v-show="curStatus === uploadStatus.fail"
>重试</el-button
>
<el-button
type="warning"
@click="handlePause"
v-show="curStatus === uploadStatus.uploading"
>暂停</el-button
>
<el-button
type="primary"
@click="handleResume"
v-show="curStatus === uploadStatus.abort"
>继续</el-button
>
<br />
<el-progress
type="circle"
:percentage="hashPercent"
class="hash-progress"
:status="hashProgressStatus"
></el-progress>
<el-progress
:text-inside="true"
:stroke-width="20"
:percentage="uploadPercent"
:status="uploadProgressStatus"
class="file-progress"
></el-progress>
<div class="preview-container" v-show="showPreview">
<video ref="preview" controls></video>
</div>
用于进度条的几个计算属性:
// hash计算进度条状态,用于区分颜色
hashProgressStatus({ hashPercent }) {
return hashPercent >= 100 ? "success" : null
},
// 上传进度条状态,用于区分颜色
uploadProgressStatus({ curStatus, uploadStatus, uploadPercent }) {
if (curStatus === uploadStatus.fail) return "exception"
return uploadPercent >= 100 ? "success" : null
},
// 上传进度
uploadPercent({ uploadedLen, chunksLen, curStatus, uploadStatus }) {
if (curStatus === uploadStatus.waiting) return 0
if (curStatus === uploadStatus.success) return 100
return Math.floor((100 * uploadedLen) / chunksLen)
}
文件预览
首先是用户选择文件,触发change事件,处理函数为handleFileChange
handleFileChange(e) {
this.file = e.target.files[0] // 获取文件
this.preview() // 预览文件
}
preview() {
// URL.createObjectURL方法创建一个对于本地文件的引用url
const URLobj = window.URL.createObjectURL(this.file)
const preview = this.$refs.preview
preview.src = URLobj
preview.oncanplay = () => {
this.showPreview = true
}
}
这里需要注意,对于视频文件,我们不能用URL.revokeObjectURL()来销毁这个引用,否则视频就不能播放了。对于图片可以用该方法销毁引用。
上传前的准备
文件分片
通过前面的流程图可以看到,我们首先要对文件进行切片
async handleUpload() {
if (!this.file) {
this.$message({
type: "error",
message: "请选择要上传的文件"
})
return
}
// 文件切片
this.createFileChunks()
}
切片的方法比较简单,只需要用slice方法切分即可
function createFileChunks() {
const chunkList = []
let cur = 0
const file = this.file
const size = file.size
while (cur < size) {
chunkList.push(file.slice(cur, cur + CHUNK_SIZE))
cur += CHUNK_SIZE
}
this.chunksLen = chunkList.length
this.fileChunks = chunkList
}
计算hash
计算文件hash用到了worker线程,因此在/public下新建hash.js,worker线程接受文件切片作为参数,计算文件hash
// hash.js
importScript('./spark-md5.min.js')
self.onmessage = function(e) {
const { fileChunks } = e.data
const spark = new SparkMD5.ArrayBuffer()
const fileReader = new FileReader()
const len = fileChunks.length
let curChunk = 0
// 注意要用箭头函数,否则self指向错误
fileReader.onload = (e) => {
spark.append(e.target.result)
curChunk++
if (curChunk >= len) {
const hash = spark.end()
self.postMessage({ hash, percent: 100 }) // 当解析完毕时,将hash传递出去
self.close()
} else {
fileReader.readAsArrayBuffer(fileChunks[curChunk])
self.postMessage({ percent: 100 * curChunk / len }) // 没有解析完毕时,只传递解析进度
}
}
fileReader.readAsArrayBuffer(fileChunks[curChunk])
}
Spark-md5文档中提到,使用增量计算性能更好,这部分代码见官方文档即可
Incremental md5 performs a lot better for hashing large amounts of data, such as files. One could read files in chunks, using the FileReader & Blob's, and append each chunk for md5 hashing while keeping memory usage low.
主线程与worker线程的通信的逻辑如下
function getFileHash() {
this.curStatus = this.uploadStatus.calculatingHash
return new Promise((resolve) => {
this.worker = new Worker('/hash.js')
this.worker.postMessage({ fileChunks: this.fileChunks })
this.woker.onMessage = (e) => {
const { hash, percent } = e.data
this.hashPercent = Math.ceil(percent)
if (hash) {
this.hash = hash
resolve()
}
}
})
}
验证是否需要上传
下一步就是向服务器发送请求,得到已经上传的切片列表,这样就能够过滤出还需要上传哪些切片
现在讲一下服务器的逻辑:服务器会以文件hash为名字建立一个临时文件夹,改文件夹内放了所有切片,当服务器收到merge请求时,说明所有切片上传完毕,服务器就会将该文件夹内所有切片合并,放到存储文件的地址下,然后删除临时文件夹。
服务器会根据用户上传的文件名(用于提取文件后缀)和文件hash进行查找,如果存在该文件(注意不是临时文件夹),说明该文件不需要再上传了,也就是实现了文件秒传。如果不存在,服务器会找到该临时文件夹,然后得到该文件夹内已经存在的切片,并将已经上传过的切片列表返回。
async handleUpload() {
if (!this.file) {
this.$message({
type: "error",
message: "请选择要上传的文件"
})
return
}
// 文件切片
this.createFileChunks()
const { shouldUpload, uploadedList }await this.verifyUplaod() // 增加
// 说明文件已经上传过了
if (!shouldUpload) {
this.$message({
type: "success",
message: "文件秒传"
})
this.curStatus = this.uploadStatus.success
return
}
}
async verifyUplaod() {
const { data } = await axios({
url: '/verify',
method: 'post',
data: { filename: this.file.name, fileHash: this.hash }
})
return data
}
文件上传
添加任务
接下来过滤掉已经上传过的切片,将未上传过的切片上传即可
async handleUpload() {
// ...
const chunksNeedUpload = this.fileChunks
.map((chunk, index) => ({
chunk,
fileHash: this.hash, // 整个文件的hash
hash: `${this.hash}_${index}` // 每个切片的hash,这里用下划线分割,后端应该与之一致
}))
.filter(hash => !uploadedList.includes(hash))
this.uploadedLen = uploadedList.length
this.uploadChunks(chunksNeedUpload)
}
接下来的uploadChunks方法就是核心内容了,首先,我们上传文件时用的MIME类型是mutipart/form-data,因此,我们用FormData来构建请求体
async uploadChunks(chunksNeedUpload) {
this.curStatus = this.uploadStatus.uploading
chunksNeedUpload
.map({chunk, fileHash, hash} => {
const formData = new FormData()
formData.append('chunk', chunk)
formData.append('hash', hash) // 文件hash
formData.append('fileHash', fileHash) // 切片hash
})
}
接下来构建请求列表,将所有请求用一个函数封装,用并发调度器来执行
async uploadChunks(chunksNeedUpload) {
this.curStatus = this.uploadStatus.uploading
this.Scheduler = new Scheduler(CONCURRENCY_LIMIT) // 增加
chunksNeedUpload
.map({chunk, fileHash, hash} => {
const formData = new FormData()
formData.append('chunk', chunk)
formData.append('hash', hash) // 文件hash
formData.append('fileHash', fileHash) // 切片hash
})
.forEach((formData, index) => {
const taskFn = () => {
axios({
url: '/',
method: 'post',
headers: { 'Content-Type': 'multipart/form-data' },
data: formData
}).then(() => this.uploadedLen++) // 用于显示进度条
}
this.Scheduler.append(taskFn, index) // 增加
})
const { status } = await this.Scheduler.done() // 增加
if (status === 'success') {
this.mergeRequest()
} else {
this.$message({
type: 'error',
message: '文件上传失败,请重试'
})
}
}
这里的重点就是Scheduler类,通过调用append方法添加任务,执行done方法,会返回一个promise,promise返回两个值:status表示所有任务的调度状态,success为成功,即所有任务成功,fail为失败,即有些任务超过了重试次数仍然失败;第二个值是一个结果数组,与Promise.allSettled的返回值相同。
任务调度之并发控制与错误重试
接下来是讲解异步任务调度器是如何实现的,见/utils/scheduler.js
该任务调度器的功能如下:保证异步任务的并发数量,并且每个任务失败时可以重试,重试次数过多后彻底失败,并且可以暂停和恢复任务的执行。
首先定义了每个任务的状态:
const STATUS = {
waiting: 'waiting', // 正在等待执行
running: 'running', // 正在执行
error: 'error', // 失败,但是还可以重试
fail: 'fail', // 超出重试次数后仍然失败
success: 'success' // 成功
}
整个任务调度的结果
const PENDING = 'pending'
const SUCCESS = 'success' // 所有任务成功
const FIAL = 'fail' // 某些任务多次重试后仍然失败
接下来看构造方法
constructor(max = 4, retryTime = 3) {
this.status = PENDING
this.max = max // 最大并发量
this.tasks = [] // 任务数组
this.promises = [] // 任务结果promise数组,顺序与任务添加顺序对应
this.settledCount = 0 // 已经有结果的任务数量,成功或者重试多次后彻底失败
this.abort = false // 是否暂停执行
this.retryTime = retryTime // 重试次数
}
append方法用于添加任务,比较简单
append(handler, index) {
// 任务数组中添加了处理函数,任务状态,已经重试了几次,索引
this.tasks.push({ handler, status: STATUS.waiting, retryTime: 0, index })
}
外部会执行done方法来启动
done() {
// run方法来开始调度任务
return this.run().then(() =>
// 这里用this.promises保存了每个task返回的promise,用于返回每个任务的结果
// 对于本demo来说是多余的,但是这样更有通用性
Promise.allSettled(this.promises).then((res) => ({
status: this.status,
res
}))
)
}
接下来就是核心的run方法
run() {
return new Promise((resolve) => {
const start = async () => {}
for (let i = 0; i < this.max; i++) {
start()
}
})
}
初始时一次性启动this.max个任务,在start方法中,一个任务结束后会递归调用start,接下来是start方法
const start = async () => {
const index = this.tasks.findIndex(
{ status } => status === STATUS.waiting || status === STATUS.error
)
if (index === -1) return // 注意,这里有个大坑
const task = tasks[index]
task.status = STATUS.running
const promise = task.handler()
this.promises[task.index] = promise
promise
.then(() => {
task.status = STATUS.success
this.settledCount += 1
if (this.settledCount >= this.tasks.length) {
if (this.status === PENDING) {
this.status = SUCCESS
}
resolve()
} else {
start()
}
})
.catch(() => {
// 如果超出了重试次数,该任务彻底失败
if (task.retryTime >= this.retryTime) {
task.status = STATUS.fail
this.settledCount += 1
this.status = FAIL // 有一个任务彻底失败,整个任务调度就失败
} else {
task.status = STATUS.error
task.retryTime += 1
}
if (this.settledCount >= this.tasks.length) {
resolve()
} else {
start()
}
})
}
这部分实现了两个功能:并发控制和错误重试。可以看到,start函数的递归调用只有在then和回调catch回调中存在,因此保证了一个任务结束后才能执行下一个任务,而初始状态时,一口气执行了this.max个任务,因此实现了并发数量的控制。接下来是错误重试,原理在于
const index = this.tasks.findIndex(
{ status } => status === STATUS.waiting || status === STATUS.error
)
这一行代码是用来寻找下一个需要执行的任务,目标是状态为waiting和error的任务。在then回调中,我们把任务的状态置为了success,失败回调中,还可以继续重试的任务状态为error,彻底失败,不能继续重试的任务状态为fail,这样,下次寻找任务时就能找到失败的任务,从而完成重试。
if (index === -1) return // 注意,这里有个大坑
这里的坑在于,比如并发数量设置为4,当最后4个任务执行时,任务A率先执行成功,进入then回调,此时还有三个任务还没有结果,因此settledCount<this.tasks.length,会递归执行start方法,因此会寻找状态为waiting和error的任务,但是此时,任务的状态只有可能三种:success, running, fail,因此index为-1,那么task就是undefined,后续代码就会报错。所有任务都有结果后,将外层的promise来resolve掉。
这里的
then和catch回调函数都形成了闭包,所以能够得到对应的task对象
任务调度之暂停与恢复
下一个功能是任务的暂停与恢复。之所以没有使用原生xhr的abort,是想把这个功能实现地更有通用性,对于非网络请求的并发控制可以使用。
任务的暂停也很简单,外部控制promise的状态即可(貌似是promise/defer模式?),手写过promise的同学应该比较熟悉,在promiseA+测试时会用到这个方法。原理就是将promise的resolve和reject方法保存到外部,从而在外部控制promise的状态。
setDeferred() {
let deferred, resolveFn
deferred = new Promise((resolve) => {
resolveFn = resolve
})
this.deferred = deferred
this.resolve = resolveFn
}
在构造函数中执行该方法
constructor() {
// ...
this.setDeferred()
}
当执行this.resolve时,this.deferred就被resolve了。
start函数中加上一个判断:
const start = async () => {
if (this.abort) await this.deferred
// ...
}
初始状态,this.abort为false,当需要暂停时,调用pause方法
pause() {
this.abort = true
}
由于this.deferred一直是pending状态,后面的任务需要等待该promise被resolve,从而实现了任务暂停。
至于继续任务也很简单
resume() {
this.abort = false
this.resolve() // 放行
this.setDeferred() // 重置deferred
}
这样,一个异步任务调度器就算完成了。当用户点击暂停和继续按钮时,分别触发handlePause和handleResume方法,这两个方法分别调用Scheduler.pause和Scheduler.resume方法即可
handlePause() {
this.Scheduler.pause()
this.curStatus = this.uploadStatus.abort
}
handleResume() {
this.Scheduler.resume()
this.curStatus = this.uploadStatus.uploading
}
后台接口说明
熟悉nodejs的同学可以直接跳过这部分
后端是基于@yeyan1996的代码(作为一个0年前端,确实不会node),稍微改造了一下,用了express,看起来更简单一点,现在来介绍一下后端接口,主要是帮助和我一样不懂node的同学。
作者确实是不会nodejs,因此传的参数比较乱,会的同学可以自己改造
请求地址:/verify,请求方式post
| 字段 | 是否必须 | 说明 |
|---|---|---|
| fileHash | 是 | 整个文件的hash |
| filename | 是 | 原本的文件名 |
返回数据类型:json
| 字段 | 说明 |
|---|---|
| shouldUpload | 如果该文件已经存在,为false,否则为true |
| uoloadedList | 已经上传过的切片列表,当shouldUpload为false时为空 |
请求地址:/,请求方式post,数据类型:form-data
| fomrData字段 | 是否必须 | 说明 |
|---|---|---|
| chunk | 是 | 文件切片 |
| hash | 是 | 文件hash_切片索引 |
| fileHash | 是 | 整个文件的hash |
| filename | 是 | 原本的文件名 |
在这个接口中用随机数模拟了上传错误
请求地址:/merge,请求方式post
| 字段 | 是否必须 | 说明 |
|---|---|---|
| hash | 是 | 整个文件的hash |
| suffix | 是 | 文件后缀 |
返回数据类型:json
| 字段 | 说明 |
|---|---|
| code | 0 |
总结
一个大文件的断点续传分为以下几个步骤
- 获取文件,将文件分片
- 根据切片获取文件hash
- 验证该文件是否已经上传过
- 上传切片
- 通知服务器合并切片
这些基本流程,在很多文章中都已经讲到了,本文的demo则是在这些的基础上,增加了断点续传,并发控制,报错重传的功能,个人认为这些才是大文件上传的核心内容。本文中实现的Scheduler类是一个更具通用性的异步任务调度器,不仅仅局限在ajax请求上。
源码
gitee
不足与展望
本文只是实现了一个提供基本功能的大文件断点续传,其实能够扩展的地方还有很多,比如:
- 使用
websocket,由服务器主动推送进度 - 用户选择文件,但还没有点击上传之前,实现一个类似预计算的功能
- 文件分片大小和并发数量是固定的,可以根据用户网速进行调整,比如当用户网速较快时,可以将多个切片通过可写流合并为一个切片上传,提高速度
- 上传前的类型校验等等
大家可以结合以上的不足,或者根据自身的需求进行扩展,希望本文能够帮到大家!!!
如果感觉文章不错的话,就请点个赞吧?? !!!