
让你的浏览器变成Siri一样的语音助手
最近业余时间浏览技术文章的时候,看到了一篇关于语音朗读的文章:Use JavaScript to Make Your Browser Speak(用Javascript让你的浏览器说话),文章中提到可以通过speechSynthesis实现让现代浏览器语音朗读指定的内容,这激发了我的好奇心去探索了一番,于是便有了下文。
本文提及的代码片段执行需要音频输出设备(如音响、耳机)和音频输入设备(如麦克风)等硬件设备的支持。
语音朗读 speechSynthesis
严格意义来上,实现语音朗读的功能需要speechSynthesis和SpeechSynthesisUtterance两个方法共同协作完成。SpeechSynthesisUtterance告诉浏览器需要语音朗读的内容,而speechSynthesis将需要朗读的内容合成为音频内容,由音响等一类的音频输出设备进行播放。
支持朗读的语言
speechSynthesis的实现是通过浏览器底层调用了操作系统的相关接口实现的语音朗读。因此语言的支持度可能因为浏览器和操作系统的不同而不同,可以通过speechSynthesis.getVoices()获取当前设备支持的朗读语言。
不过,多数支持speechSynthesis方法的浏览器一般都支持中文内容的朗读。而且这样也带来了一个好处:可以离线使用,也可以通过SpeechSynthesisVoice.localService方法替换成自己的音源。
代码示例
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<button type="button" onclick="speak('你好,李焕英')">说话</button>
<script type="text/javascript">
// 语音朗读功能
function speak(sentence) {
// 生成需要语音朗读的内容
const utterance = new SpeechSynthesisUtterance(sentence)
// 由浏览器发起语音朗读的请求
window.speechSynthesis.speak(utterance)
}
</script>
</body>
</html>
兼容性


排除已不再维护的IE浏览器,PC几个主流的浏览器和IOS均已支持,安卓支持性有好有坏,需要做好兼容处理。
M71提案
不过值得注意的一点是,当Chrome上线相关功能之后,发现语音朗读的功能被一些网站滥用,于是Chrome在M71提案(提案链接)之后,将触发机制变更成:需要用户自行触发事件才能进行语音朗读。
我个人测试了Chrome、Edge两款浏览器,Chrome无法通过直接调用和通过创建DOM节点触发click事件间接调用,而Edge在写文时(2021-03-13)两种方法都可以调用;因此如果有相关业务需求时,建议做好相应的兼容准备。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<script type="text/javascript">
function speak(sentence) {
const utterance = new SpeechSynthesisUtterance(sentence);
window.speechSynthesis.speak(utterance);
};
// 在M71提案后,Chrome禁止了自动调用语言朗读的机制
// Edge在2021-03-13时可以直接调用,其他浏览器跟进程度未知
speak('直接调用');
const button = document.createElement('button');
button.onclick = () => speak('创建节点调用');
document.body.appendChild(button);
button.click();
setTimeout(() => document.body.removeChild(button), 50);
</script>
</body>
</html>
测试完这些代码的时候,脑海中忽然闪过一个想法:既然都有语音朗读了,那有没有语音识别的方法呢?于是我查了MDN及一些相关的资料,发现还真有语音识别的方法:SpeechRecognition(文档链接)。
语音识别 SpeechRecognition
跟语音朗读speechSynthesis本地朗读不同,SpeechRecognition在MDN文档(点击此处)中明确提出了是基于服务器的语音识别,也就是说必须联网才能识别。
On some browsers, like Chrome, using Speech Recognition on a web page involves a server-based recognition engine. Your audio is sent to a web service for recognition processing, so it won't work offline.
在某些浏览器(例如Chrome)上,网页上使用的语音识别基于服务器的识别引擎。您的音频将发送到网络服务以进行识别处理,因此它将无法离线工作。
如果你使用的浏览器是Chrome,语音识别的服务端则是由谷歌提供的,如果不用梯子的话会直接提示结束。不过好在提供了SpeechRecognition.serviceURI用来自定义语音识别的提供商,算是一种权宜之计吧。
代码示例
<!DOCTYPE html>
<head lang="zh-CN">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音朗读</title>
</head>
<body>
<button type="button" onclick="recognition.start()">点击识别语音</button>
<button type="button" onclick="recognition.stop()">结束语音识别</button>
<p id="status"></p>
<p id="output"></p>
<script type="text/javascript">
// 目前只有Chrome和Edge支持该特性,在使用时需要加私有化前缀
const SpeechRecognition = window.webkitSpeechRecognition
const recognition = new SpeechRecognition()
const output = document.getElementById("output")
const status = document.getElementById("status")
// 语音识别开始的钩子
recognition.onstart = function() {
output.innerText = ''
status.innerText = '语音识别开始'
}
// 如果没有声音则结束的钩子
recognition.onspeechend = function() {
status.innerText = "语音识别结束"
recognition.stop()
}
// 识别错误的钩子
recognition.onerror = function({ error }) {
const errorMessage = {
'not-speech': '未检测到声源',
'not-allowed': '未检测到麦克风设备或未允许浏览器使用麦克风'
}
status.innerText = errorMessage[ error ] || '语音识别错误'
}
// 识别结果的钩子,
// 可通过interimResults控制是否实时识别,maxAlternatives设置识别结果的返回数量
recognition.onresult = function({ results }) {
const { transcript, confidence } = results[0][0]
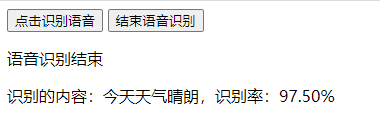
output.innerText = `识别的内容:${ transcript },识别率:${ (confidence * 100).toFixed(2) }%`
}
</script>
</body>
</html>
识别准确度
我个人拿Chrome浏览器尝试了一下午,当识别率低于90%的时候,基本就会出现丢字的情况,比如我用较快的语气说了一句“今天天气怎么样”,最后识别的结果是“怎么样”。当环境比较嘈杂的时候,基本识别率就没有高于70%的时候,说一句“你好”,得到的结果要么直接报错要么不搭边,对长难句的识别率也不怎么高。

如果希望达到一个比较高的识别率,则需要安静的环境,简单的语句,说话清晰响亮缓慢(类似于播音腔)。
兼容性
这算是一个相当新的api,新到什么程度呢?
新到MDN文档创建SpeechRecognition相关词条的时间在2020年9月15日,截止我写文的2021年03月13日刚好半年的时间。
虽然新意味着兼容性差,但这也从某种层次上说明,未来Web前端的发展方向也许真的可能替代原生应用。

从兼容性来看,PC只有Chrome和Edge(仅限Chromium核心)这两款浏览器支持,移动端几乎全军覆没,只有少数几个比较新的版本支持,但不确定对整体的兼容性如何。
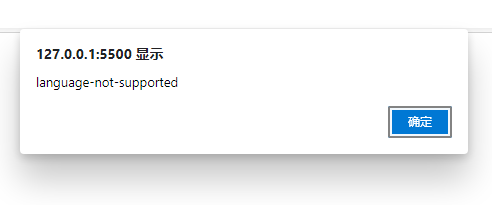
经过实际的测试,Chrome支持英文和中文的语音识别,而Edge会提示language-not-supported的错误,更改html上的语言仍然报错,怀疑需要更改电脑的系统语言才能解决(未确定)。
语音识别 + 语音朗读 = 语音助手
市面上比较常见的各类语音助手(比如Siri),在前端的逻辑都比较简单,一般情况下如果只处理本地化的配置,如设置闹钟、询问日期等功能,核心功能主要分为语音识别和语音朗读两部分,当浏览器提供了这两项能力的时候,便已满足了语音助手的条件。
于是我尝试写了一个很简单的DEMO,将两者合二为一实现了一个语音助手。
代码示例
<!DOCTYPE html>
<head lang="zh-CN">
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<title>语音助手</title>
</head>
<body>
<button type="button" onclick="recognition.start()">点击识别语音</button>
<p id="status"></p>
<p id="output"></p>
<script type="text/javascript">
function speak(sentence) {
const utterance = new SpeechSynthesisUtterance(sentence)
window.speechSynthesis.speak(utterance)
}
// 目前只有Chrome和Edge支持该特性,在使用时需要加私有化前缀
const SpeechRecognition = window.webkitSpeechRecognition
const recognition = new SpeechRecognition()
const output = document.getElementById("output")
const status = document.getElementById("status")
// 语音识别开始的钩子
recognition.onstart = function() {
output.innerText = ''
status.innerText = '语音识别开始'
}
// 如果没有声音则结束的钩子
recognition.onspeechend = function() {
recognition.stop()
}
// 识别错误的钩子
recognition.onerror = function({ error }) {
const errorMessage = {
'not-speech': '未检测到声源',
'not-allowed': '未检测到麦克风设备或未允许浏览器使用麦克风'
}
status.innerText = errorMessage[ error ] || '语音识别错误'
}
// 识别结果的钩子
recognition.onresult = function({ results }) {
// 设置一些比较简单的回复
const answers = {
'今天是星期几': '今天是星期六',
'今天天气怎么样': '今天天气晴朗'
}
const { transcript, confidence } = results[0][0]
// 设置一个阈值分别处理
if( confidence * 100 >= 90 ) {
speak(answers[transcript] || '这件事我还不知道,换个问题吧')
status.innerText = `语音回复的内容:${ answers[transcript] || '这件事我还不知道,换个问题吧' }`
} else {
speak('我好像没听明白')
status.innerText = `我好像没听明白`
}
}
</script>
</body>
</html>
总结
目前大部分的浏览器都还没兼容语音识别的特性,但在可预见的未来,不仅主流浏览器会支持语音识别的特性,也会有一些第三方服务商通过浏览器原生的方法提供类似的服务,同时会有更多类似的能力出现在Web平台上。