
「译」JavaScript 是如何计算 1+1 的 – Part 1 创建源码字符串
来源:medium.com/compilers/c…
我是一个编译器爱好者,一直在学习 V8 JavaScript 引擎的工作原理。当然,学习东西最好的方式就是写出来,所以这也是我在这里分享经验的原因。我希望这也能让其他人感兴趣。
译者注:
翻译已获得作者授权。
由于我对一部分名词、c++ 语法也不怎么了解,所以结合自己的理解以及上下文做了一些「译者注」,可以有取舍的参考

毫无疑问 1 + 1 = 2,但是 V8 JavaScript 的引擎是如何计算出来的呢?
题外话,我最喜欢的一个面试问题是:「从输入 URL 到页面加载发生了什么?」
_
这是一个很好的问题,因为它能展示一个人相关知识的深度和广度,能从回答这个问题的过程中,发现哪些部分是他最感兴趣的
这是一系列博文中的第一篇,将探讨 V8 在 1 + 1 被输入之后的一切。首先,我们将关注 V8 如何在其堆内存中存储 1 + 1 字符串。这听起来很简单,但它完全值得这一整篇的博文!
一、客户端应用(The Client Applicant)
要计算 1 + 1,你可能最先采取的方法是启动 NodeJS,或者打开 Chrome 开发者控制台,然后简单地输入 1 + 1。但为了展示 V8 的内部结构,我决定修改 hello-world.cc,这是 V8 源代码中的一个标准示例应用程序
我把原来打印 "Hello World" 的代码,用 1 + 1 的表达式代替
// 创建一个包含 JavaScript 源代码的字符串
Local<String> source = String::NewFromUtf8Literal(isolate, "1 + 1");
// 编译源代码
Local<Script> script =
Script::Compile(context, source).ToLocalChecked();
// 运行该脚本以获得结果
Local<Value> result = script->Run(context).ToLocalChecked();
// 将结果转换为Number并打印出来
Local<Number> number = Local<Number>::Cast(result);
printf("%f\n", number->Value());
译者注:为了便于不懂 C++ 的同学理解代码含义,提供一些变量的说明和一份 TS 形式的表达(仅用于辅助理解代码!不代表真实逻辑!)
- isolate(隔离)- 在 V8 中一个 isolate 是 V8 的一份实例。在 blink 中 isolate 和线程是 1 : 1 的关系。主线程与一个 isolate 相关联,一个工作线程与一个隔离相关联
- context(上下文)- context 是 V8 中全局变量范围的概念。简单的说,一个 Window 对象对应于一个context。例如 和 parent frame 的有不同的 Window 对象,所以不同的 frame 具有不同的context
- Literal (字面量) - value 代表值,literals 代表如何表达一个值。比如 15 是一个值,这个值是唯一的,但表达的方式有很多种:例如阿拉伯数字 15,用中文 十五,用英文 fifteen,用 16 进制 0xF。15 是 value,后面的种种都是 literal
- 双冒号
::可以当成为 js 里的.,String::NewFromUtf8Literal就是String.``NewFromUtf8Literal- 箭头函数
->可以当成为 js 里的.,script->Run(context)就是script.Run(context)
// 导入类 String、Script,导入类型集合 Local
import { String, Script, Number, Local } from 'v8'
const source: Local["String"] = String.NewFromUtf8Literal(isolate, "1 + 1");
const script: Local["Script"] = Script.Compile(context, source).ToLocalChecked();
const result: Local["Value"] = script.Run(context, source).ToLocalChecked();
const number: Local["Number"] = Number.Cast(result);
console.log(number.Value());
快速阅读这段代码并大概了解一下。这些 C++ 代码看起来难以理解,但注释会应该能帮到你。在这篇博文中,我们主要关注第一句代码,即在 V8 堆中分配一个新的 1 + 1 字符串
Local<String> source = String::NewFromUtf8Literal(isolate, "1 + 1");
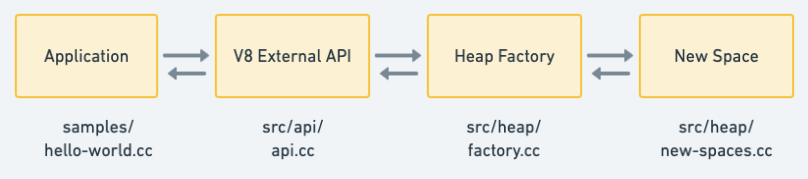
为了理解这段代码,我们先从所涉及的一系列 V8 模块开始。在此图中,执行流程是由左至右,返回值从右至左传回,插入到 soruce 变量中
-
应用程序 - 这代表了 V8 的客户端,在我们的例子中,它是
hello-world.cc程序。但通常情况下,它是整个 Chrome 浏览器、NodeJS 运行时系统或任何其他嵌入了 V8 JavaScript 引擎的软件 -
V8 外部 API - 这是一个面向客户端的 API,提供对 V8 功能的访问。虽然它是用 C++ 实现的,但 API 是围绕着各种 JavaScript 概念来塑造的,如数字、字符串、数组、函数和对象,允许以各种方式创建和操作它们
-
堆工厂 - V8 引擎内部(不通过 API 暴露)是一个在堆上创建各种数据对象的「工厂」。令人惊讶的是,可用的工厂方法集与外部 API 提供的方法有很大的不同,所以很多转换是在 API 层内部完成的
-
New Space - V8 的堆非常复杂,但新分配的对象通常存储在 New Space 中,通常被称为 新生代。我们在这里就不详细介绍了,但是 New Space 是使用 Cheney 算法来管理的,Cheney 算法是一种执行垃圾回收的著名算法
现在我们来详细了解一下这个流程,重点是:
- API 层如何决定创建什么类型的字符串,以及它在堆中的存储位置
- 字符串的内部内存布局是怎样的。这取决于字符串里字符的范围
- 如何从堆中分配空间。在我们的例子中,需要 20 个字节
- 最后,如何将指向字符串的指针返回给应用程序,用于未来进行垃圾回收
二、确定存储字符串的方式和位置
如上所述,在客户端应用程序和堆工厂(实际创建对象的地方)之间必须进行大量的转换工作。大部分的工作都在 src/api/api.cc 中进行
让我们从客户端应用程序的调用开始:
String::NewFromUtf8Literal(isolate, "1 + 1");
第一个参数是「Isolate(隔离)」,它是 V8 的主要内部数据结构,代表运行时系统的状态,与其他可能存在的 V8 实例隔离。要理解这一点,可以想象打开了多个浏览器窗口,每个窗口都有一个完全独立的 V8 实例在运行,每个实例都有自己的隔离堆。我们不会多谈 isolate 参数,只需要知道到很多 API 的调用都需要这个参数
String::NewFromUtf8Literal 方法 (见 src/api/api.cc) 首先进行基本的字符串长度检查,同时也决定如何在内存中存储字符串。 考虑到我们只提供了两个参数,第三个 type 参数默认为NewStringType::kNormal,表示字符串应该作为常规对象在堆上分配。另一种方法是传递NewStringType::kInternalized,表示需要对字符串进行去重复处理。这个特性对于避免存储同一个常量字符串的多个副本非常有用
内部会接着调用 NewString 方法(见 [src/api/api.cc](https://github.com/v8/v8/blob/8.8.276/src/api/api.cc)),它调用 factory->NewStringFromUtf8(string)。请注意,这里的 string 已经被映射到一个内部的 Vector 数据结构中,而不是一个普通的 C++ 字符串,因为堆工厂有一套与外部 API 完全不同的方法。当返回值传回客户端应用程序时,这种差异将在后面变得更加明显
在 NewStringFromUtf8 内部(见 src/heap/factory.cc),决定了字符串的最佳存储格式。当然,UTF-8 是一种方便的格式,可以存储广泛的 Unicode 字符,但是当只使用基本的 ASCII 字符时 (例如 1 + 1) V8 会以 「1 个字节」的格式存储字符串。为了做出这个决定,字符串的字符被传递到 Utf8Decoder decoder(utf8_data) 中(在 src/strings/unicode-decoder.h 中声明)
现在我们已经决定分配一个 1 字节的字符串,使用普通的(不是内部化的)方法,下一步是调用NewRawOneByteString(见 src/heap/factory-base.cc),在这里,堆内存被分配,字符串的内容被写入该内存
三、字符串的内存结构
在 V8 内部,我们的 1 + 1 字符串被表示为 v8::Internal::SeqOneByteString 类的一个实例 (见 src/objects/string.h)。如果你像大多数面向对象的开发者一样,你会期望 SeqOneByteString 有许多公共方法,以及一些私有属性,比如一个字符数组或一个存储字符串长度的整数。然而,事实并非如此! 相反,所有内部对象类实际上只是指向堆中存储这些数据地址的指针
译者注:对象类 - 定义属性的命名集合,并将它们分类为必需属性集和可选属性集
从 src/objects/objects.h 中的代码注释可以看出,大约有 150 个内部类的父类是 v8::Internal::Object。这些类中都只包含了一个 8 字节的值(在 64 位机器上),指向了堆中对象所在的地址
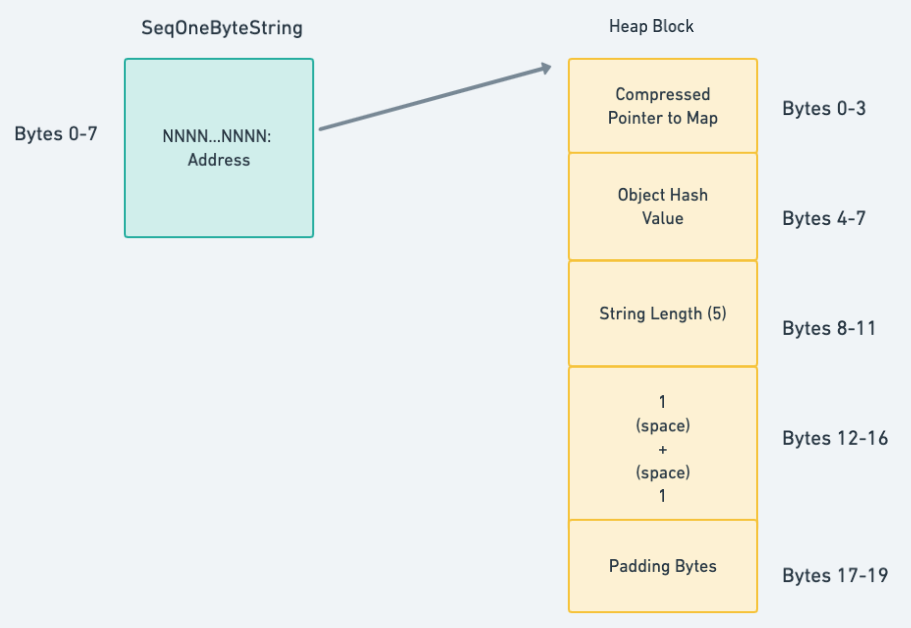
其中有趣的部分是:
SeqOneByteString 对象
如前所述,这不是一个功能完善的字符串类,而是一个指向堆中字符串实际内容地址的指针。在 64 位的机器上,这个「指针」将是一个 8 字节的 unsigned long (无符号长整形),其类型别名为 Address。请注意,堆上的数据(在图的右边)实际上并不是一个真正的 C++ 对象,所以没有必要把这个 Address 当作一个指向强类型的东西(如 String *)的指针来处理
但是,你可能想知道为什么要先有一个间接层,而不直接访问 Heap Block 呢?当你考虑到垃圾收集会导致对象在堆中移动时,会知道这种方法是有意义的。重要的是,数据可以移动,而不会让客户端应用程序感到困惑
译者注:Heap Block - 内存块
要说明的是,在 Generational Garbage Collection(代际垃圾收集)中,对象首先在 新生代(New Space)中分配,如果它们存活的时间足够长,就会被移到 老生代(Old Space)中。为了实现这一目的,垃圾收集器会将Heap Block 复制到新的堆空间,然后更新 Address 值指向新的内存地址。鉴于 SeqOneByteString 对象本身的内存地址仍然和之前完全相同,客户端软件不会注意到这个变化。
Compressed Pointer To Map (Heap Block 的第 0-3 个字节)(指向 Map 的压缩指针)
JavaScript 是一种动态类型的语言,这意味着 _变量 _没有类型,然而 _存储在变量中的值 _却有类型。「map 」是 V8 将堆中的每个对象与其数据类型描述关联起来的方式。毕竟,如果对象没有被标记上它的类型,Heap Block 就会变成一个串无意义的字节
除了提到 maps 也是存储在 _只读空间 _中的一种堆对象之外,我们不会对 1 + 1 字符串的 map 进行更多的详细介绍。 Maps(也被称为形状或隐藏类)可以变得非常复杂,尽管我们的常量字符串通过调用read_only_roots().one_byte_string_map()(见 src/heap/factory-base.cc)使用了一个预先定义的 map
译者注:heap object - 堆对象。是在程序运行时根据需要随时可以被创建或删除的对象,在虚拟的程序空间中存在一些空闲存储单元,这些空闲存储单元组成的所谓的堆
有趣的是,虽然这个 map 字段是指向另一个堆对象的指针,但它巧妙地使用了指针压缩,在一个 32 位的字段中存储了一个 64 位的指针值
Object Hash Value (Heap Block 的第 4-7 个字节)(对象哈希值)
每个对象都有一个内部的哈希值,但在这个例子中,它默认为 kEmptyHashField(值为3),表示哈希值还没有计算出来
String Length (Heap Block 的第 8-11 个字节)(字符串长度)
这是字符串中的字节数(5)(两个 1,两个 ,一个 +)
The Characters and the Padding (Heap Block 的第 12-19 个字节)(字符和填充物)
正如你所期望的那样,接下来存储的是 5 个单字节字符。此外,为了确保未来的堆对象根据 CPU 的架构要求进行对齐,还额外增加了 3 个字节的填充(将对象对齐到 4 字节的边界)。
四、从堆中分配内存
我们简单地提到,工厂类从堆中分配一块内存(在我们的例子中是 20 个字节),然后用对象的数据填充该块。剩下的一个问题是这 20 个字节是 _如何 _分配的
在 Cheney 的垃圾收集算法中,新生代(New Space)被分为两个半空间。为了在堆中分配一个内存块,分配器确定在当前半空间的 Limit,和该半空间的当前 Top 之间是否有足够的可用字节。如果有足够的空间,算法返回下一个块的地址,然后按请求的字节数递增 Top 指针
这里展示了这种基本情况,显示了当前半空间的前后状态: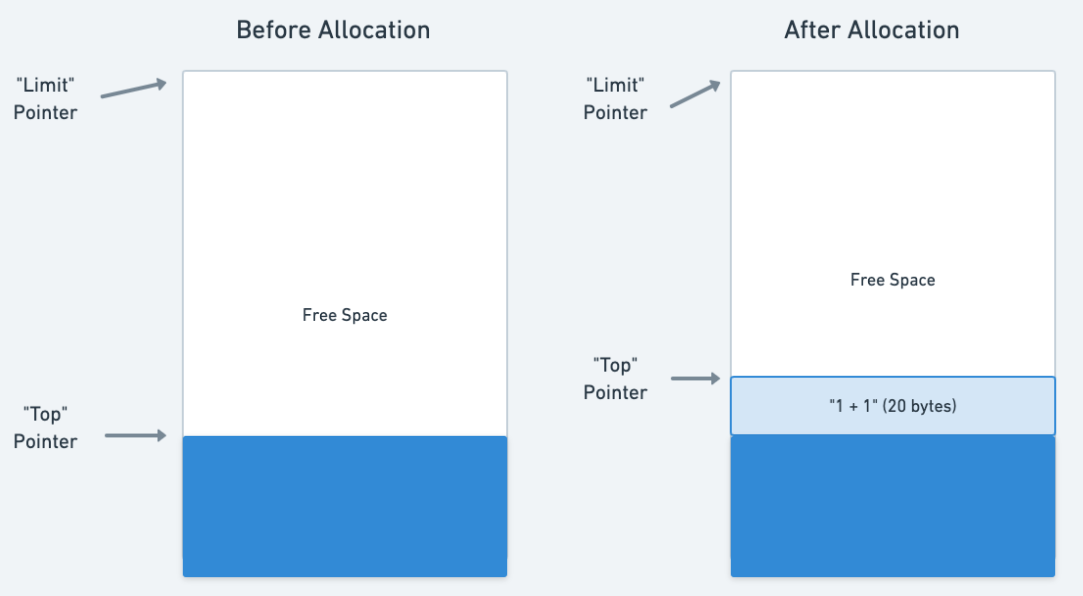
如果当前的半空间用完了可用内存(Top 和 Limit 太接近),那么 Cheney 算法的收集部分就会开始。一旦收集完成,所有的 _活 _对象将被复制到第二个半空间的开始,而所有的 _死 _对象(残留在第一个半空间中)将被丢弃。无论怎样,一个半空间都能保证其所有 _使用过 _的空间都在底部,而所有的 _空闲的 _空间都在顶部,所以它总是会像上图一样
不过在我们的情况下,当前的半空间有很多空闲的内存,所以我们切掉 20 个字节,然后增加 Top 指针。不需要进行垃圾收集,也不涉及第二个半空间。在 V8 代码中,有许多特殊情况需要考虑,但最后 20 个字节的分配是由 src/heap/new-spaces-inl.h 中的 NewSpace::AllocateFastUnaligned 方法处理的
五、返回一个句柄
句柄(Handle)是 C++ 程序设计中经常提及的一个术语。它并不是一种具体的、固定不变的数据类型或实体,而是代表了程序设计中的一个广义的概念。
句柄一般是指获取另一个对象的方法 - 一个广义的指针,它的具体形式可能是一个整数、一个对象或就是一个真实的指针,而它的目的就是建立起访问与被访问对象之间的唯一的联系
现在我们有了一个指针,指向完全填充了字符串的内容(包括长度、哈希值和映射)的 Heap Block,这个指针必须返回给客户端应用程序。如果你还记得,客户端调用了这行代码
Local<String> source = String::NewFromUtf8Literal(isolate, "1 + 1");
但是,source 的类型到底是什么,Local<String> 到底是什么意思?这里有两个关键的观察点:
将内部类转换为外部类
首先,我们先回顾一下, V8 使用 v8::internal::SeqOneByteString 类存储了我们的字符串对象,有趣的是它只是一个指向堆上数据的指针。然而,客户端应用程序期望数据的类型是 v8::String,这是 V8 API 的一部分
你可能会感到惊讶,v8::internal::SeqOneByteString(v8::internal::String 的一个子类)与v8::String 处于一个完全不同的类层次结构。事实上,所有的内部类都是在 src/objects 目录下使用v8::internal 命名空间定义的,而外部类则是在 include/v8.h 中使用 v8 命名空间定义的
重温我们之前讨论过的 NewFromUtf8Literal 方法(见 src/api/api.cc),在将对象指针返回给客户端应用程序之前的最后一步是将结果从 v8::internal::String 转化为 v8::String
return Utils::ToLocal(handle_result);
这个转换是通过定义在 src/api/api-inl.h 中的宏来完成的
译者注:宏(Macro)本质上就是代码片段,通过别名来使用。在编译前的预处理中,宏会被替换为真实所指代的代码片段
管理好垃圾回收的「根」
其次,我们来讨论一下 Local<String> 的含义(顺便说一下,它是 v8::Local<v8::String> 的缩写)。Local 的概念是当字符串对象不再被需要时,我们如何处理它的垃圾回收
任何 JavaScript 开发人员都知道,当对象没有剩余的引用时,就会进行垃圾回收。回收算法从「根」开始,然后遍历整个堆,找到所有可到达的对象。根是一个非堆(non-heap)引用,比如一个全局变量,或者仍然在作用域中的基于堆栈(stack-based)的局部变量。如果这些变量被分配了新的值,或者它们离开了作用域(它们的封装函数结束),它们曾经指向的数据现在有可能是垃圾
译者注:堆栈就是栈,这个「堆」并不是数据结构意义上的堆(Heap),而是动态内存分配意义上的堆 - 用于管理动态生命周期的内存区域
在 hello-world.cc 程序的情况下,我们在 C++ 栈中也有指针,可以引用堆对象。这些指针没有对应的JavaScript 变量名,因为它们只存在于 C++ 程序的上下文中(比如 hello-world.cc,或者 Chrome,或者NodeJS)。例如:
Local<String> source = ...
在这种情况下,source 是对堆对象的引用,尽管现在多了一层间接性。这张图将解释: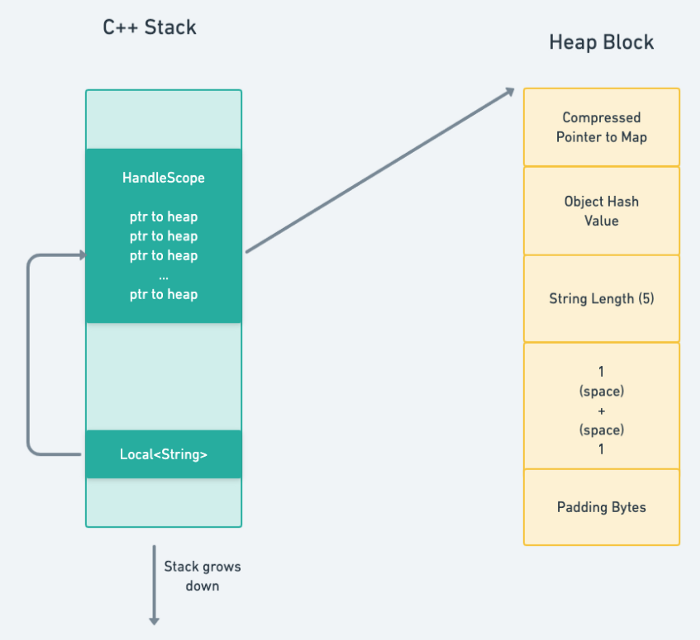
译者注:
ptr to heap = pointer to heap 指向内存块的指针
直觉上的指向:source 指向
1 + 1
实际上的指向:source 指向 ptr to heap 指向 Heap Block(其中包含了1 + 1)
左边是 C++ 堆栈,随着程序的执行,堆栈从上往下增长,右边是我们前面看到的内存块。当客户端程序执行时,它会将一个 HandleScope 对象推送到本地 C++ 栈上(见 src/samples/hello-world.cc)。接下来,调用 String::NewFromUtf8Literal() 的返回值作为一个 Local<String> 对象存储在 C++ 栈上
看起来我们又增加了一层间接性,但这样做是有好处的
-
寻根更容易 -
HandleScope对象是一个存储堆对象的「句柄」(也就是指针)的地方。你还记得,这正是我们的SeqOneByteString对象,一个指向底层堆数据的 8 字节指针。当垃圾收集启动时,V8 会迅速扫描HandleScope对象,找到所有的根指针。然后,如果底层堆数据被移动,它可以更新这些指针。 -
**本地指针易于管理 - **与相当大的
HandleScope相比,Local<String>对象是 C++ 堆栈上的一个 8 字节的值,它可以和其他任何 8 字节的值(如指针或整数)在相同的上下文中使用。特别是,它可以存储在CPU 寄存器中,传递给函数,或者作为返回值提供。值得注意的是,当垃圾回收发生时,垃圾回收器不需要定位或更新这些值 -
**消除作用域很容易 - **最后,当客户端应用程序中的 C++ 函数完成后,C++ 堆栈上的
HandleScope和Local对象会被删除,但只有在它们 C++ 对象析构函数被调用后才会被删除。这些析构函数从垃圾收集器的根列表中删除了所有的句柄。它们不再在作用域中,所以底层堆对象可能已经成为垃圾
译者附:析构函数(destructor)与构造函数相反,当对象结束其生命周期,如对象所在的函数已调用完毕时,系统自动执行析构函数。析构函数往往用来做“清理善后” 的工作(例如在建立对象时用 new 开辟了一片内存空间,delete 会自动调用析构函数后释放内存)
最后,引用我们的 1 + 1 字符串的 source 变量,现在已经准备好在我们的客户端应用程序中传递到下一行
Local<Script> script =
Script::Compile(context, source).ToLocalChecked();
下一节……
在堆上分配 1 + 1 的字符串显然有很多工作要做。希望它能说明 V8 内部架构的一些部分,以及在系统的不同部分如何表示数据。在未来的博文中,我会更多地研究我们的简单表达式是如何被解析和执行的,这将暴露出更多关于 V8 的运作方式
在本系列博文的第 2 部分,我将深入研究 _编译缓存 _是如何工作的,以避免编译代码超过必要的时间
附录:
第一次翻译文章,感谢 deepL、百度翻译、谷歌翻译
作者授权: