
webpack源码解析
前言:
webpack作为一个打包工具,它的入参是各种静态文件和配置参数,可以实现灵活的可扩展性的插件配置和loaders加载,最后输出打包后的bundle文件。下图是官网中的webpack打包示意图,webpack可以打包全世界!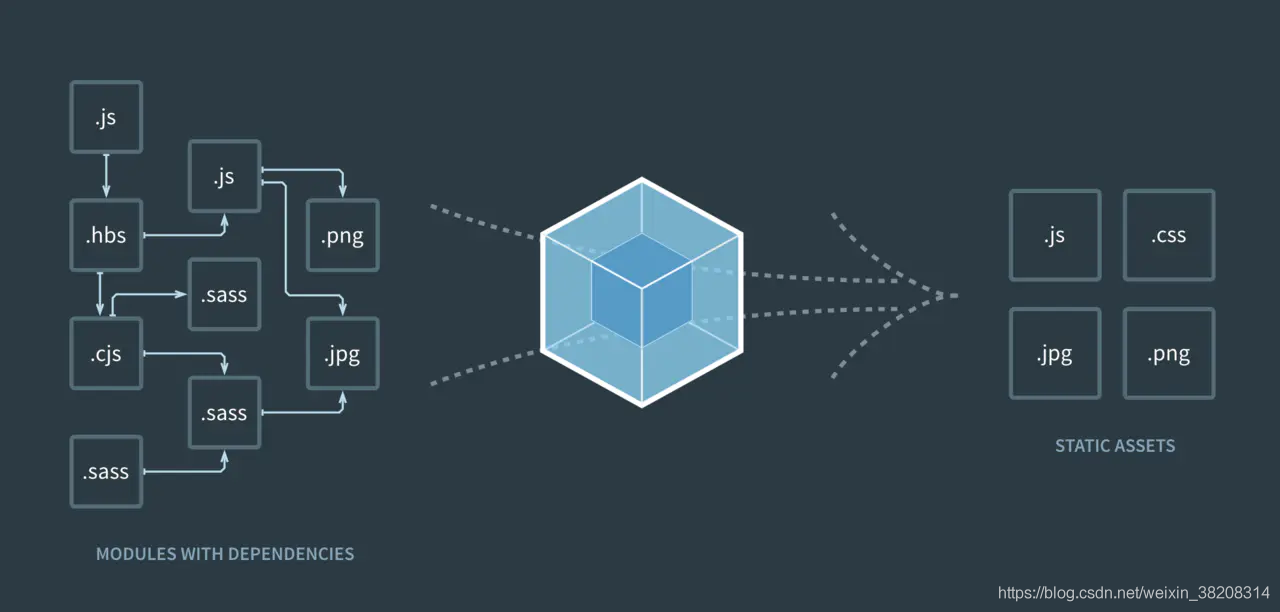

在使用webpack的过程中,一直有几个疑问萦绕脑海:
- webpack中间的处理流程究竟做了些什么?
- 我们平时配置的loaders、plugins都在哪个阶段起作用?
- webpack是如何支持如此复杂的配置而又不影响性能的?
在分析源码之前,我们必须要先了解一下Tapable这个东西(第3个问题的答案)。
Webpack本质上是事件驱动的,从一个事件,走向下一个事件。它的整个编译过程中暴露出来大量的 Hook 供内部/外部插件使用,而实现这一切的核心就是Tapable。Tapable 类似于发布订阅模式,但是它提供了更加复杂的钩子类型,我们可以理解为webpack打包流程是由打包阶段的各个事件组成的,而插件的实现就是在这些事件钩子上绑定属于自己的回调函数,这样就实现了webpack的可扩展性。
可参考这篇文章:
webpack tapable啥玩意?
我们一起来看一下吧,首先举个?说明webpack在做什么?
一.举例说明webpack在做什么?
// a.js (webpack config 入口文件)
import add from './b.js'
add(1, 2)
import('./c').then(del => del(1, 2))
-----
// b.js
import mod from './d.js'
export default function add(n1, n2) {
return n1 + n2
}
mod(100, 11)
-----
// c.js
import mod from './d.js'
mod(100, 11)
import('./b.js').then(add => add(1, 2))
export default function del(n1, n2) {
return n1 - n2
}
-----
// d.js
export default function mod(n1, n2) {
return n1 % n2
}
各个文件的依赖关系如下: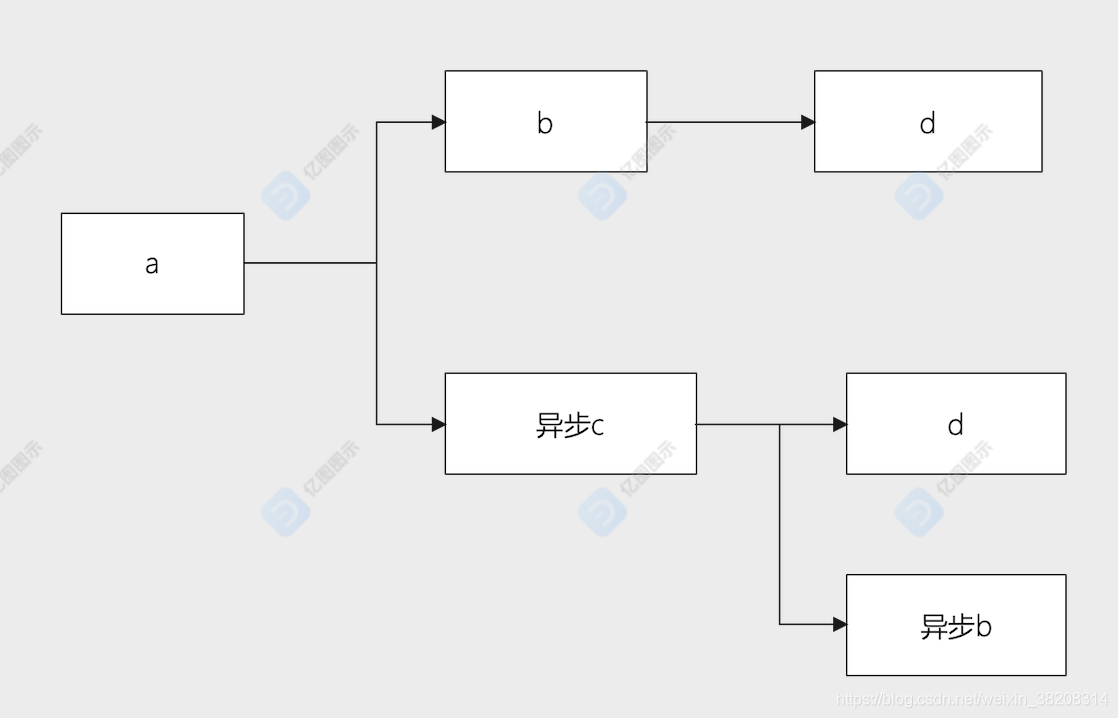
// webpack.config.js
module.exports = {
entry: {
app: 'a.js'
},
output: {
filename: '[name].[hash:8].js',
chunkFilename: '[name].bundle.[chunkhash:8].js',
publicPath: '/'
},
}
上述代码经过webpack打包之后,最终会输出2个打包文件:
- app.js - 包含了 a.j、b.js、d.js 的代码
- 0.bundle.js - 包含了 c.js 的代码
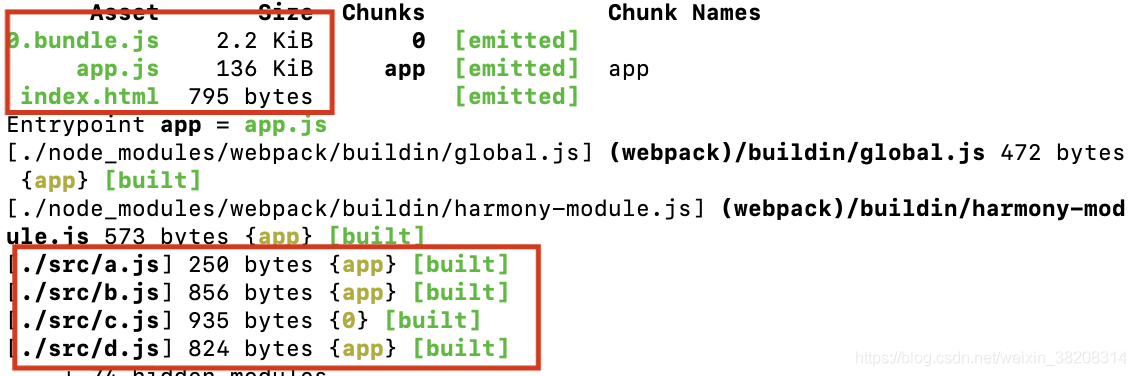
看到这里,我们看到webpack将我们的文件按照某种规则进行打包输出(当然目前为止我们还没有用到插件和loaders),如果不知道这两个包是如何输出的也没关系,后面会再解释。
webpack到底怎么做到的?我们开始进入正题吧,本文只解析部分核心webpack源码,抛砖引玉,让大家对webpack的运行流程有一个大致的了解。
在打包的时候我们会在命令行执行以下打包命令:
webpack --config webpack.config.js
该命令在webpack-cli中相当于执行以下代码:
// 使用,这里模仿webpack-cli中的代码,相当于在命令行里输入webpack。
const options = require("./webpack.config.js");
const compiler = webpack(options);
compiler.run();
简单解释:加载webpack配置文件,传给webpack文件,返回一个编译器compiler,运行编译器。
so,我们先来看看webpack入口---webpack.js做了什么?
一 .webpack.js
下面这段代码是webpack.js的主要部分:
const webpack = (options, callback) => {
...
// 用我们自定义的配置覆盖webpack默认的配置 返回综合配置
options = new WebpackOptionsDefaulter().process(options);
// 将代码入口传入编译器,实例化编译器
compiler = new Compiler(options.context);
// Node环境插件 挂载在编译器的钩子上
new NodeEnvironmentPlugin({...}).apply(compiler);
// 自定义插件 挂载在编译器的钩子上
options.plugin.apply(compiler);
...
// 将webpack配置的其他属性所用到的插件,都挂载在compiler上
compiler.options = new WebpackOptionsApply().process(options, compiler);
...
return compiler;
}
在这里解释几件事情:
- webpack4.0可以实现零配置,没有用户配置的情况下,它会采用默认的配置将src文件夹下的index.js打包到dist文件夹下的main.js中(其他很多默认配置不赘述)。
- new Compiler(options.context)这句代码的意思是将当前文件夹的绝对路径传给编译器。
举例:
class NodeEnvironmentPlugin {
apply(compiler) {
compiler.inputFileSystem = new CachedInputFileSystem(
new NodeJsInputFileSystem(),
60000
);
//....
compiler.hooks.beforeRun.tap("NodeEnvironmentPlugin", compiler => {
if (compiler.inputFileSystem === inputFileSystem) inputFileSystem.purge();
});
}
}
module.exports = NodeEnvironmentPlugin;
上图中,是node环境下的一个插件的代码核心。比如我们在解析文件(resolver)的时候,需要用到的文件系统,这个插件就是在compiler的beforeRun钩子上挂载了自己的事件,将文件读取系统挂载在compiler上,使得compiler中的其他插件可以使用文件读取系统。
webpack.js主要做了几件事:
1.整合配置参数(用户配置和默认配置)
2.将node环境的插件和用户配置的插件挂载在compiler各个钩子上,使得各个插件可以在编译的不同阶段执行自己的逻辑。
3.返回compiler
开始执行compiler.run();操作:
二. compiler.js
compiler.js是用来控制编译流程的文件。run方法逻辑如下:
beforeRun钩子-->run钩子-->编译compile方法-->编译结束回调onCompiled
run方法核心代码如下:
run(callback) {
const onCompiled = (err, compilation) => {
// 编译结束后的回调函数
// 文件输出
}
...
// 触发beforeRun钩子,增加文件存取的功能
this.hooks.beforeRun.callAsync(this, err => {
// 触发run钩子,处理缓存的模块 减少编译的模块 加快编译速度
this.hooks.run.callAsync(this, err => {
...
this.compile(onCompiled);
});
}
虽然这里各种钩子嵌套执行,并没有添加任何功能,但其实插件已经在各种钩子上绑定了自己的事件,webpack实现了功能与实现的解耦,代码逻辑清晰。
compile(callback) {
this.hooks.beforeCompile.callAsync(params, err => {
// 编译
this.hooks.compile.call(params);
// newCompilation是webpack使用的编译器
const compilation = this.newCompilation(params);
// 正式启动编译
this.hooks.make.callAsync(compilation, err => {
...
// 编译结束
compilation.finish(err => {
...
// 封装 执行优化的钩子 chunk构建和打包优化
compilation.seal(err => {
...
this.hooks.afterCompile.callAsync(compilation, err => {
...
return callback(null, compilation);
});
});
});
});
});
}
}
compile函数的逻辑如下:
beforeCompile钩子-->compile钩子-->实例化编译器compilation对象-->make钩子(转换模块)-->编译结束-->seal封装-->afterCompile钩子-->执行compile回调函数
compiler.js文件做的几件事:
- 启动编译。通过实例化编译对象并执行make钩子,编译开始,真正的核心编译工作是由compilation对象做的。
- 管理输出。编译结束后会执行onCompiled这个回调函数,整理输出数据。
- 通过钩子控制整个编译流程。
下方表格中,分别是compiler的几个钩子,插件就是挂载在编译的不同阶段,在不同的阶段执行不同的插件。
| 关键钩子 | 钩子类型 | 钩子参数 | 作用 |
|---|---|---|---|
| beforeRun | AsyncSeriesHook | Compiler | 运行前的准备活动,主要启用了文件读取的功能。 |
| run | AsyncSeriesHook | Compiler | “机器”已经跑起来了,在编译之前有缓存,则启用缓存,这样可以提高效率。 |
| beforeCompile | AsyncSeriesHook | params | 开始编译前的准备,创建的ModuleFactory,创建Compilation,并绑定ModuleFactory到Compilation上。 |
| compile | SyncHook | params | 编译了 |
| make | AsyncParallelHook | compilation | 从Compilation的addEntry函数,开始构建模块 |
| afterCompile | AsyncSeriesHook | compilation | 编译结束了 |
| shouldEmit | SyncBailHook | compilation | 获取compilation发来的电报,确定编译时候成功,是否可以开始输出了。 |
| emit | AsyncSeriesHook | compilation | 输出文件了 |
| afterEmit | AsyncSeriesHook | compilation | 输出完毕 |
| done | AsyncSeriesHook | Status | 无论成功与否,一切已尘埃落定。 |
编译回调函数:
const onCompiled = (err, compilation) => {
if (this.hooks.shouldEmit.call(compilation) === false) {
...
this.hooks.done.callAsync(stats, err => {
...
}
return
}
this.emitAssets(compilation, err => {
...
if (compilation.hooks.needAdditionalPass.call()) {
...
this.hooks.done.callAsync(stats, err => {});
};
})
}
这个函数的作用就是将编译后的内容生成文件。先调用shouldEmit判断是否编译成功,成功之后就调用Compiler.emitAssets方法打包文件。我们可以看到compiler文件通过各种钩子控制了整个编译流程。但是真正的编译是在compilation.js文件中。
so?我们来看一下最核心的编译函数:compilation
三. compilation.js
// 正式启动编译
this.hooks.make.callAsync(compilation, err => {
// 编译结束
compilation.finish(err => {
在compiler.js中,我们发现,在执行了make钩子之后,并没有执行任何的compilation对象的方法,而是在它的回调函数中直接执行了compilation.finish方法。那编译到底是如何做到的?其实,在关于入口的插件中,在make这个钩子上绑定了事件,其中执行了addEntry这个添加入口的操作,从这里就开始了真正的编译过程。
插播:在执行添加入口addEntry操作之前,入口插件做了哪些准备工作呢?
// WebpackOptionsApply.js
new EntryOptionPlugin().apply(compiler);
compiler.hooks.entryOption.call(options.context, options.entry);
上面代码中,在EntryOptionsPlugin中注册了compiler.hooks.entryOption钩子的事件处理函数,它会根据入口值entry的类型不同,区分单入口/多入口,实例化不同的插件类型。(SingleEntryPlugin,MultiEntryPlugin等)
插播结束!
//SingleEntryPlugin.js
class SingleEntryPlugin {
...
apply(compiler) {
compiler.hooks.compilation.tap(
"SingleEntryPlugin",
(compilation, { normalModuleFactory }) => {
// 存储键值对 将 SingleEntryDependency 和 normalModuleFactory关联起来
compilation.dependencyFactories.set(
SingleEntryDependency,
normalModuleFactory
);
}
);
compiler.hooks.make.tapAsync(
"SingleEntryPlugin",
(compilation, callback) => {
...
compilation.addEntry(context, dep, name, callback);
}
);
}
...
}
我们以单入口为例,看一下SingleEntryPlugin做了些什么事情?
- 注册了 compilation 事件回调。
- 注册了 make 事件回调。
- compilation事件是在实例化编译器的时候触发的,在make动作执行之前,绑定这个钩子的插件可以获得两个参数,一个是编译器本身,一个是模块工厂。该回调函数的作用是将SingleEntryDependency和normalModuleFactory关联起来。
- 在make阶段的时候调用addEntry 方法,然后进入 _addModuleChain 进入正式的编译阶段。
// compiler.js
addEntry(context, entry, name, callback) {
this.hooks.addEntry.call(entry, name);
...
this._addModuleChain(
...
return callback(null, module);
);
}
addEntry方法做了两件事:
1.调用addEntry钩子
2.调用_addModuleChain方法,执行结束后,将执行make钩子携带过来的回调函数,告知compiler编译结束。
_addModuleChain做了几件事(重点):
_addModuleChain(context, dependency, onModule, callback) {
...
// 获取模块工厂类型
const moduleFactory = this.dependencyFactories.get(Dep);
...
this.semaphore.acquire(() => {
// 创建新模块 module
moduleFactory.create(
...
// 将模块加入到compilation.modules中
const addModuleResult = this.addModule(module);
module = addModuleResult.module;
// 入口模块加入compilation.entries
onModule(module);
// 处理模块的依赖 再转换依赖 组成模块链
const afterBuild = () => {
if (addModuleResult.dependencies) {
this.processModuleDependencies(module, err => {
...
});
}
};
if (addModuleResult.build) {
// 构建 转换模块代码(parse loader generate)
this.buildModule(module, false, null, null, err => {
...
// 判断依赖
afterBuild();
});
});
}
_addModuleChain流程分析:
1)获取入口对应的模块工厂类型
根据不同 dependency 类型,获取 multiModuleFactory(多入口模块的生产工厂) 或者normalModuleFacotry(单入口模块的工厂)
2) 调用moduleFactory.create创建入口模块
对于单入口来说,moduleFactory.create调用的是normalModuleFacotry的create方法。该方法主要作用就是获取文件和loaders对应的绝对路径,并实例化模块工厂创建模块。
插播:moduleFactory.create做了什么?
create(data, callback) {
//...省略部分逻辑
this.hooks.beforeResolve.callAsync(
{
contextInfo,
resolveOptions,
context,
request,
dependencies
},
(err, result) => {
//...
// 触发 normalModuleFactory 中的 factory 事件。
const factory = this.hooks.factory.call(null);
// Ignored
if (!factory) return callback();
factory(result, (err, module) => {
//...
callback(null, module);
});
}
);
}
- 触发 beforeResolve 事件
- 触发 NormalModuleFactory 中的 factory 事件。在 NormalModuleFactory 的 constructor 中有一段注册 factory 事件的逻辑。
- 执行 factory 方法,主要流程如下:

factory 方法做了两件事情:获取文件的绝对路径及其对应的loaders的绝对路径,生成normalModule实例,并将文件路径和loaders路径存放到该实例中。
插播结束
3)addModule
得到模块实例之后,将其存放于全局的 Compilation.modules 数组中和 _modules 对象中。
这个阶段可以看成add阶段,他会将module的所有信息都存于Compilation 中,以便于在最后打包成 chunk 的时候使用。
4)调用buildModule解析模块,输出依赖列表
该阶段做了以下几件事情:
- 运行Loader
- Parser解析出AST
- walkStatements解析出依赖
插播:buildModule做了什么事情?
moduleNormalModule 的实例,Compilation.buildModule实际上调用的是NormalModule.build 方法:build方法逻辑如下:
// NormalModule.build 方法
build(options, compilation, resolver, fs, callback) {
//...
return this.doBuild(options, compilation, resolver, fs, err => {
//...
try {
// 这里会将 source 转为 AST,分析出所有的依赖
const result = this.parser.parse(/*参数*/);
if (result !== undefined) {
// parse is sync
handleParseResult(result);
}
} catch (e) {
handleParseError(e);
}
})
}
// NormalModule.doBuild 方法
doBuild(options, compilation, resolver, fs, callback) {
//...
// 执行各种 loader
runLoaders(
{
resource: this.resource,
loaders: this.loaders,
context: loaderContext,
readResource: fs.readFile.bind(fs)
},
(err, result) => {
//...
// createSource 会将 runLoader 得到的结果转为字符串以便后续处理
this._source = this.createSource(
this.binary ? asBuffer(source) : asString(source),
resourceBuffer,
sourceMap
);
//...
}
);
}
分为两部分:
- doBuild函数:对源文件执行loaders,doBuild方法才是真正取到了文件的内容,并用loaders对其进行处理。
- doBuild函数回调:使用acorn将代码转换为ast抽象语法树,遍历ast找出该文件的所有依赖,为该module增加依赖(dependency 实例),每一个dependency 实例都有一个template方法,template中保存着源代码中该依赖的字符位置range,在最后生成文件的时候,会将该range替换成依赖文件的内容。
4)执行buildModule的回调函数afterBuild
const afterBuild = () => {
...
// 如果有依赖,则进入 processModuleDependencies
if (addModuleResult.dependencies) {
this.processModuleDependencies(module, err => {
if (err) return callback(err);
callback(null, module);
});
} else {
return callback(null, module);
}
};
- 执行processModuleDependencies方法,处理模块依赖
- 处理依赖的方式与主文件类似,会重复执行reate-->build-->add-->processDep整个流程,构建完整的模块链。
完成编译过程生成模块链之后,执行make事件的回调函数,告知compiler编译完毕。开始执行seall封装操作。
四.seal封装
this.hooks.make.callAsync(compilation, err => {
...
compilation.seal(err => {
...
this.hooks.afterCompile.callAsync(compilation, err
...
});
});
});
});
make编译过程结束后,开始执行compilation的seal钩子,开始chunk的构建和优化打包过程。
此过程会根据入口文件、配置中关于优化分包的参数去合并生成多个chunk。
因为这部分代码过于冗长,且嵌套很多,这里就不粘贴代码进行解析了,接下来,我们以文章开头的代码为例说明chunk形成的过程,便于理解:
首先,webpack会为所有的module生成module graph(模块图谱,如上图)。模块图谱的形成过程就是从入口文件开始,分析每一个模块的同步依赖modules和异步依赖blocks,对于同步依赖,再执行以上步骤。对于异步依赖,会单独拿出来进行分析,便于后面将异步依赖单独进行打包。
其次,上图是根据module graph 生成basic chunk graph的结果,生成了3个chunkGroup。basic chunk graph的生成过程是:入口文件和异步文件,webpack会为它们单独生成一个chunk,从入口文件开始,遍历它的同步依赖modules以及依赖modules的依赖...,同时将该模块与入口文件的chunk相关联,直到没有找到同步依赖为止(得到上图第一个chunkGroup)。在遍历的过程中,如果遇到异步依赖,就单独创建一个chunk,再执行以上过程,关联modules和chunk,这样就完成了最后两个chunkGroup的形成。
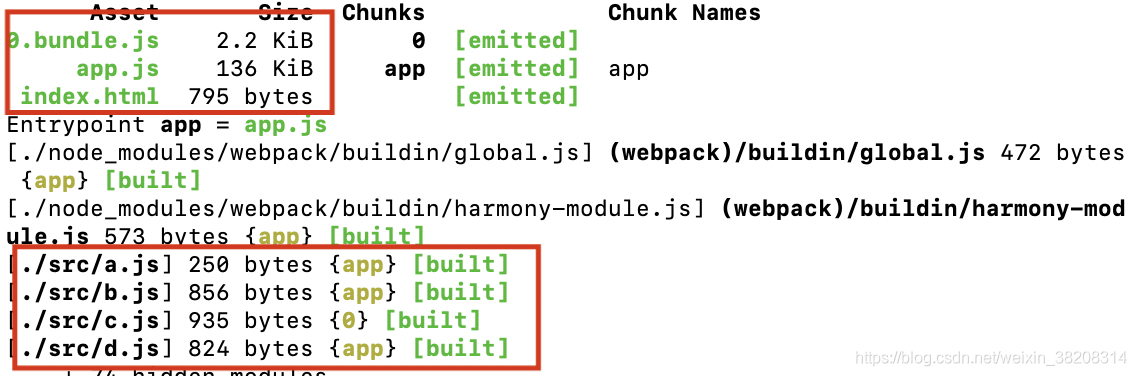
最后一步,得到优化chunk graph。观察basic chunk graph的结果:发现三个包中都有d.js,这样打包之后会造成重复打包。后两个异步加载的包中需要的d.js已经在入口包中进行了同步加载,同步加载的优先级大于异步加载,所以后两个chunkGroup需要的d.js可以去掉。再看第三个包中需要的b.js,也已经在入口包中以同步的形式加载过了,所以也不需要,将第三个包删掉,就得到了最终的chunk。
五.输出打包文件
整合chunk完毕之后,最后要输出打包文件。我们得到的module、chunk文件都是通过require进行聚合的代码,不可以在浏览器中运行,webpack会提供template模版产生带有_webpack_require()格式的代码(实质上是webpack实现了简单的require函数),这样打包之后的代码就可以在浏览器中运行了。
关于webpack模块化可参考这篇文章
最后,通过emitAssets将最终的js输出到output的path中。
附上一张webpack打包流程图。
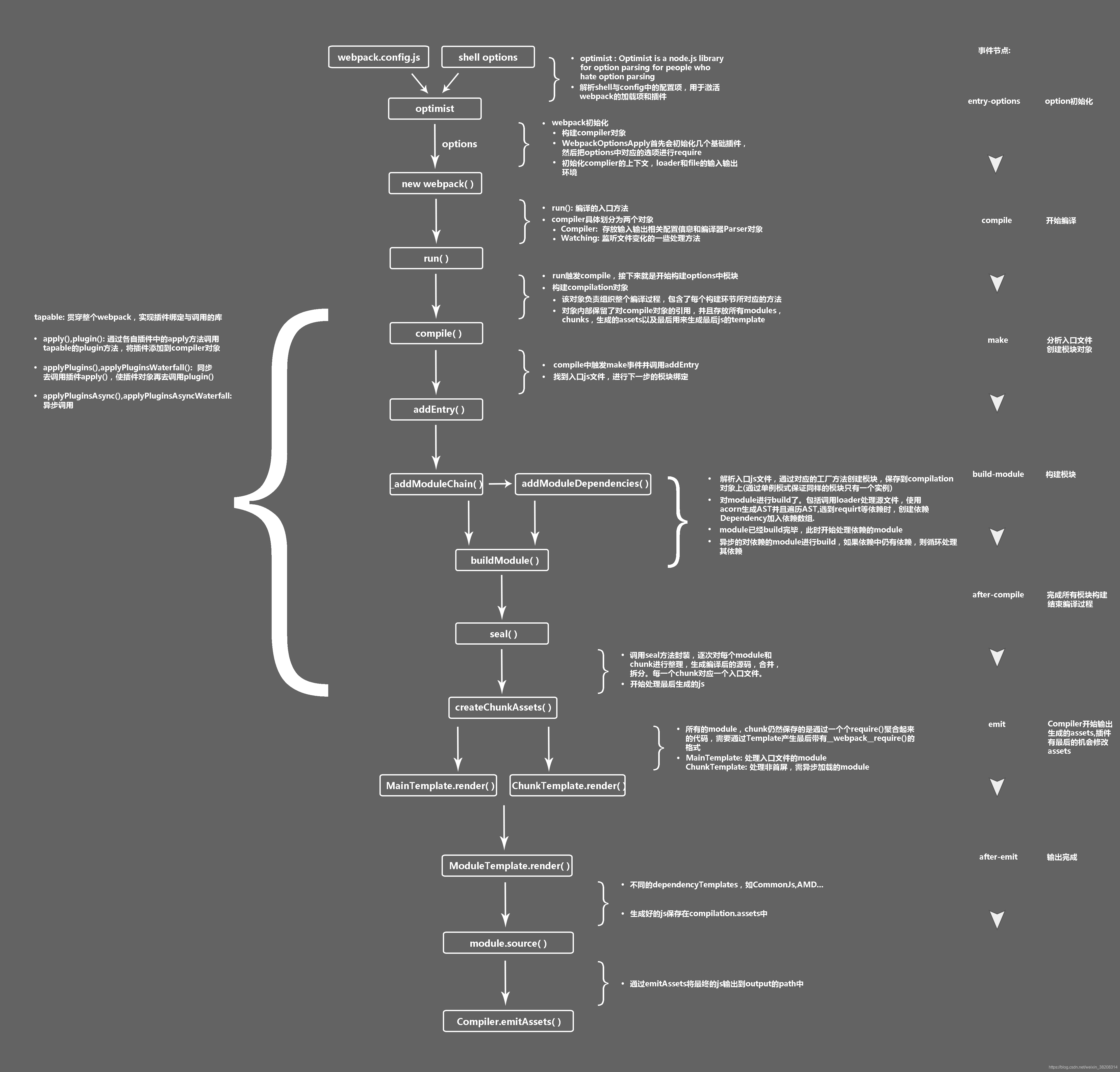
参考博客:
juejin.cn/post/684490…
juejin.cn/post/684490…
juejin.cn/post/684490…