
JS运行过程详解
在开篇之前,先看几个常见的JS题目:
// part1
console.log(a); // undefined
var a;
// part2
function demo() {
setTimeout(() => {
console.log('1')
}, 0);
console.log('2');
}
demo(); // 2, 1;
part1中我们在执行console.log(a)之前并没有设置a这个变量,我们都知道JS是不同于Java这种编译性语言的,JS属于解释性语言,边执行边解析。因此在执行console.log(a)的时候,应该会报错才对(因为声明变量是在下面一句,此时还没对var a 进行解析)。但是为啥会是undefined呢?这是非常著名的变量提升的问题。
变量提升的原因
在JS执行的过程中,当遇到一段可执行的代码块的时候,就会创建并初始化这段可执行的代码块的执行上下文。
可执行的代码块有:全局代码块,函数代码块,eval代码块(很少涉及到,本文不做具体描述)。


上下文的定义是:上下文就是程序需要执行时所需要的环境,具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
从以上的概念中可以看出,上下文无非就是存储一些信息,包括变量,内存信息等。也就是说在函数还没有真正运行的时候,就已经将这些变量创建出来了。这也就是变量提升的原因。
上下文共分为两个阶段:创建阶段,执行阶段。
在创建并初始化的时候,做了以下几件事情(此时此刻还只是初始化,并没有压入栈中执行):
- 创建变量对象
- 绑定作用域链
- 确定this指向
我们先一步一步看:创建变量对象阶段这个小阶段有做了啥:
创建变量对象:
创建变量对象VO(Variable object)分为以下几个步骤:
- 先向内存申请一片地址,用存储当前的变量对象信息。
- 对于函数形参,首先他会将形参的具体的值,添加到VO中的arguments中去,key为形参在函数括号中的顺序。然后在将
形参的名称:形参的具体的值存储到VO中去。(如果可执行的代码块是函数的话,会执行这一步操作,否则不会执行) - 对于函数声明,他会以
函数名:function-object存储到VO中。(假如函数名与VO中所储存的key值冲突,那么直接替换) - 对于变量声明,假如键名没有与函数声明的名称或形参的名称冲突的话,它就会被添加到VO中。否则直接忽略。
// 示例:
function demo(arg1) {
function test() {};
var test = 12;
}
demo(123);
//对应的VO是:
VO: {
arguments: {
0: 123,
}
arg1: 123, // 执行步骤2
test: reference to function test(){}, // 执行步骤3 以及步骤4,因为var test = 2 在VO中有相同的键名,并且这个键名对应的是个函数声明。所以直接忽略。
}
绑定作用域链
函数内部有个[[scope]]属性,在函数被**创建**的时候,就会保存父类的的所有变量到其中。注意着并不是完整的作用域链,因为完整的作用域链还要包含他自身。
那么在函数创建并创建其上下文的时候,就会把当前的函数的[[scope]]上的变量保存到这个上下文中的scope中。那么当函数执行的时候,会将当前自身的活跃对象AO假如到当前的scope中去。这个才是完整的作用于链。(函数入栈执行的时候,变量对象VO就会被激活成AO)。
function demo1() {
function demo2() {}
demo2();
}
demo1()
// demo2在函数demo1创建并初始化其执行上下文的时候,这个时候函数就会被创建,那么久会保存demo1的变量到demo2这个函数的[[scope]]中,因此:
demo2.[[scope]] = {
demo1.VO
}
// 当demo2被压入栈中执行的时候,demo2的变量对象VO会激活成活跃对象AO,这个时候在吧这个AO添加到scope的顶部,一个完整的作用域链就完成了。
demo2.context = {
AO: {...},
scope: {AO, demo1.VO}
}
这也就是闭包的原理。闭包指的是能够访问自由变量的函数。自由变量指的是这这个变量既不是我这个函数创建的,也不是我这个函数的参数。
function demo1() {
var a = 123;
function demo2() {
console.log(a);
}
return demo2;
}
demo1()();
// demo2在函数demo1创建并初始化其执行上下文的时候,这个时候函数就会被创建,那么久会保存demo1的变量到demo2这个函数的[[scope]]中,因此:
demo2.[[scope]] = {
demo1.VO
}
// 当demo2被压入栈中执行的时候,demo2的变量对象VO会激活成活跃对象AO,这个时候在吧这个AO添加到scope的顶部,一个完整的作用域链就完成了。
demo2.context = {
AO: {...},
scope: {AO, demo1.VO}
}
确定this指向
太过复杂,另开辟一片讲解。
入栈执行
前面我们已经讲了准备工作,在准备工作做完之后,就会压入栈中执行,将变量对象VO激活成AO。当整个函数执行完毕之后,就会出栈。这个栈就被称为执行栈,因为JS是单线程的,也就是有且仅有这么一个执行栈。那么如果全部都顺序的在栈上执行的话,可能会造成阻塞情况。例如:
function asyncFun() {
setTimeout(() => {
console.log('123');
}, 10000000000000000000000000000);
console.log('456');
}
asyncFun();
假如全部在栈上顺序执行的话,那么console.log('456')需要等到10000000000000000000000000000秒后执行,那么这段时间,相当于执行栈上啥都不做了,就等时间到了在继续。显然这样是不合理的。所以在JS入栈执行的时候,又会有事件循环机制来辅佐代码运行
事件循环机制
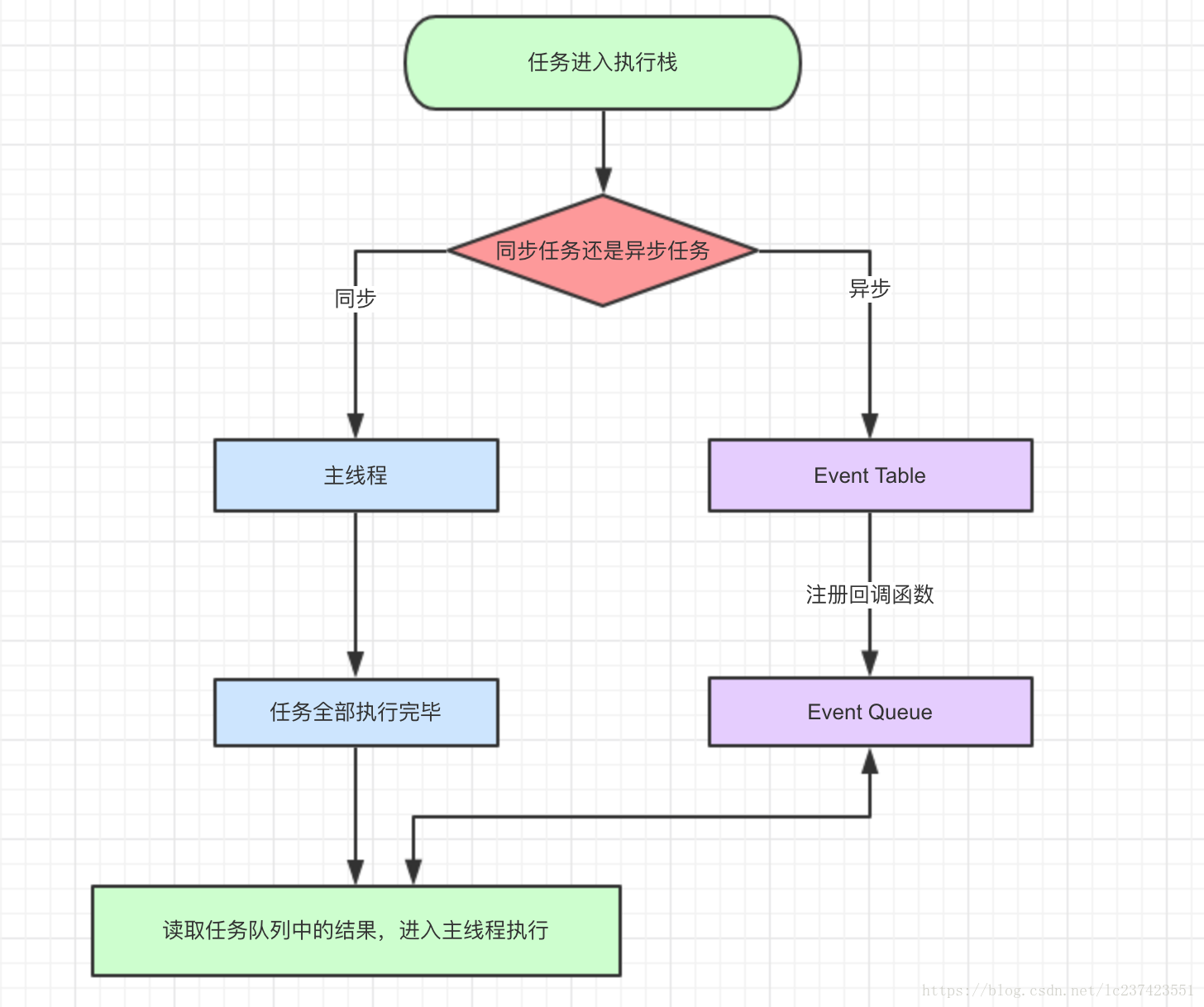
在JS中,当一个代码块进入到执行栈上执行的时候,会经历以下几个步骤:
- 当前这个代码片段是同步代码片(任务)或者是异步代码片(任务)
- 如果是同步的话,那么直接就在主线程上运行
- 如果是异步的话,把他加入到Event Table里面去,并且注册函数。
- 当异步任务执行完毕的时候,Event Table会将当前这个函数移到Event Queue中去。
- 当主线程上的任务都执行完毕的时候,就回去查找Event Queue里面有没有需要执行的,如果有,那么继续重复1,2,3,4,5步骤,直到没有需要执行的。
图例:
那么在异步任务队列里,又分为了两大类:分别是宏任务,以及微任务。
宏任务包括: script(主程序代码), setTimeOut, setInterVal, setImmediate, I/O操作, UI渲染, requestAnimationFrame。
微任务包括:promise(原生) MutationObserver process.nextTick() mutation Object.observe
那么我们在之前说过,当主线程上同步任务已经执行完毕了,他这个时候,会去任务队列里去取任务出来执行。在这一块,他首先会取微任务,直到当前已经没有微任务可以执行了,他才会去取宏任务执行。