
虚拟DOM和Diff算法
1. React中的虚拟DOM
我们知道虚拟DOM在数据驱动视图更新中有着至关重要的作用,但是我们如果直接理解虚拟DOM可能有有点费劲,我们现在来思考一个问题,来逐步思考虚拟DOM到底怎么来的又解决了什么问题。我们现在思考如果是你,实现一个数据更新驱动视图更新的功能,怎么做?
① 完整替换
state数据JSX模板- 数据 + 模板 结合,生成真实的
DOM,来显示 state发生改变- 数据 + 模板 结合,生成真实的
DOM,替换原始的DOM
缺陷:
- 第一次生成了完整的
DOM片段 - 第二次生成了完整的
DOM片段 - 第二次的
DOM替换第一次的DOM,非常耗性能
② 寻找差异
state数据JSX模板- 数据 + 模板 结合,生成真实的
DOM,来显示 state发生改变- 数据 + 模板 结合,生成真实的
DOM,并不直接替换原始的DOM - 新的
DOM(DocumentFragment)和原始的DOM做比对,找差异 - 找出变化的
DOM节点 - 只用新的
DOM中的变化的元素替换老的DOM中的变化的元素
缺陷:
- 由于虽然减少了部分无变化的
DOM的替换,但是也增加了新旧DOM比对的过程,性能提升并不明显
③ react的做法
state数据JSX模板- 数据 + 模板 结合生成虚拟
DOM(虚拟DOM就是一个JS对象,用它来描述真实DOM的结构)- (比如虚拟
DOM是['div',{id: 'abc'},['span', {}, 'hello world']])
- (比如虚拟
- 用虚拟
DOM的结构来生成真实的DOM来显示- (比如真实的
DOM是<div id='abc'><span>hello world</span></div>)
- (比如真实的
state发生改变- 数据 + 模板 结合生成新的虚拟
DOM- (比如虚拟
DOM是['div',{id: 'abc'},['span', {}, 'bye bye']])
- (比如虚拟
- 比较新旧虚拟
DOM,找到存在区别的元素内容 - 直接操作
DOM,修改变化的部分
通过了解react中组做法你就能够明白,react使用虚拟DOM能提升性能的两个地方在于
- 数据发生变化,不再生成新的DOM,而是虚拟DOM这种js对象,用js生成DOM远比用js生成js对象代价高的多
- 不再是新旧DOM之间的比对,而是虚拟DOM之间的比对,使用js比对DOM消耗性能远比用js比对js对象要高的多,
总结两点就是:生成DOM变生成JS对象 和 DOM比对变成JS对象比对
2. 深入理解虚拟DOM
现在我们需要搞清楚一个问题就是,我们使用JSX语法来书写代码,最终生成了真实的DOM,那么这个过程是怎么样的?
- JSX语法会通过Babel编译成为React.createElement方法
- React.createElement方法执行返回的就是一个JS对象,俗称虚拟DOM
- 虚拟DOM描述了真实DOM的结构,通过React中的ReactDOM.render()函数再生成真实的DOM并挂载到浏览器中
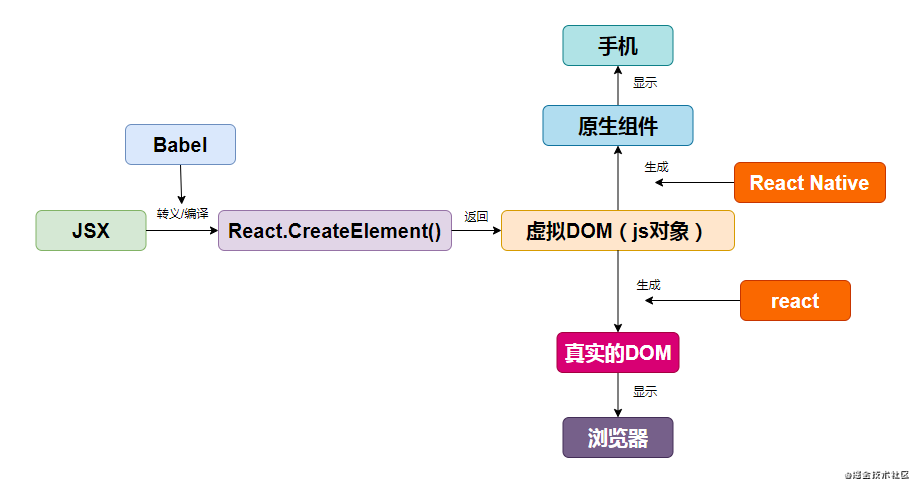

通过上面这张流程图,你知道了React使用虚拟DOM的流程,但是React为什么要使用虚拟DOM,使用它有什么好处呢?
- 性能提升(两个性能提升的点上面已说明)
- 使得跨端应用得以实现,比如React Native,虚拟DOM在浏览器通过React被转化成为了真实的DOM,但是在移动端虚拟DOM也可以通过其他东西被转化成为原生的组件,如上图所示
3. Diff算法
关于Diff算法,我们肯定不会深入讲其中的原理,我们只是来简单的介绍一下:Diff算法是用来帮助我们比对两个虚拟DOM区别的算法,因为Diff的全程就是Diffrence,找不同的意思。
① setState为什么是异步的
我们思考一下,两个虚拟DOM之间产生不同的原因归咎于数据发生了变化,无论是单个组件中数据变化,还是父子组件中的prop发生了变化,都是调用了setState方法修改了state,而setState这个方法是异步的,我们来想一下,为什么setState是异步的:
- 异步的原因肯定是为了提高性能,如果setState是同步的,连续多次调用这个方法,就会产生多个虚拟DOM ,从而造成多次新旧虚拟DOM之间的比对
- 但如果是异步的,按照异步事件循环的规则,多次异步方法会在下一次循环中执行,那么就可以将其何并,只做一次最后一次虚拟DOM的比对,提高性能
② Diff比较的方式
Diff算法中两个虚拟DOM的比对方式是同级比对,而且某一级如果不同,就不会再继续比对下去,也就是说如果第一层都不一样,就不会比比较第二层,第三层,哪怕后面的所有都一样,也会全部重新替换,虽然同层比对可能会造成一些性能的损耗,但是这样的方式速度最快
③ Key的终极解析
知道了Diff是同层比对之后,现在再来彻底说明为什么在循环中要带key,并且key为什么不能用index
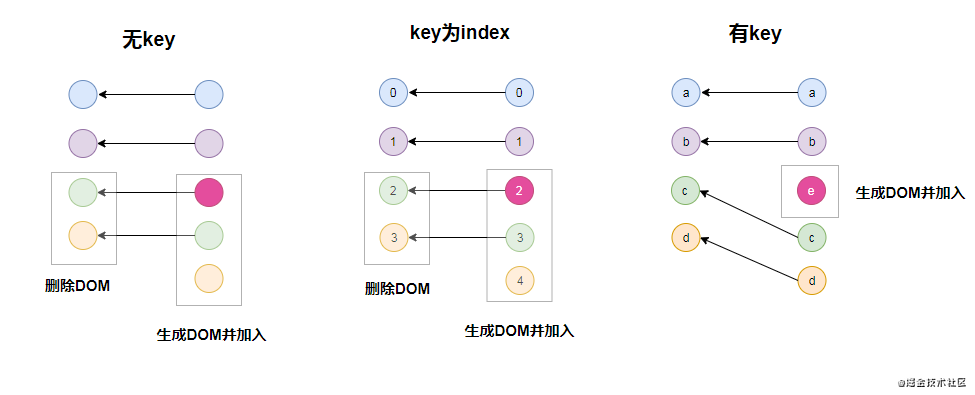
如上图,假如在一个循环中旧的虚拟DOM有4个节点,数据更新后,在数组的最中间插入另一个节点:
- 在无key或者key为index的时候,因为Diff算法是同层比对,一样的会复用,所以导致的结果就是在真实操作DOM的时候,它认为旧23变成了新234,所以就会先把旧的23的DOM删掉,然后生成新的234,再添加到DOM中。包含了删除2个节点的真实DOM操作,生成3个节点的真实DOM操作,将3个节点加入文档的真实DOM操作
- 但是在有key的情况下,因为有key做标志,新的虚拟DOM中c和d通过key知道自己和旧的虚拟DOM中的c和d描述的是真实DOM中同一段位置的东西,比对之后发现并无变化,所以在真实的DOM操作中只需要生成新的e节点并加入DOM中。只包含了生成1个节点的真实DOM操作和将1个节点加入文档的真实DOM操作
所以对比一下,你就能看出,在循环中,每个节点有固定且唯一的key能省略点多少真实的DOM操作,所以这就是设置正确的key是真的能提高性能的原因,而且数组中循环的元素越多,性能提升的越明显。