
再读《编写可维护的JavaScript》
最近闲来无事,翻了翻放在书架上吃灰的书籍,有些书之前已经看了几遍,但仍然具有再次阅读的价值,而这两天重新阅读了一番《编写可维护的JavaScript》,这本书的核心内容是从前端工程师的角度出发展示的最佳编程实践,包括编码风格与技巧、自动化、测试等等。
整本书分为了三个部分:
- 编程风格
- 编程实践
- 自动化
接下来的内容是从这几个视角来看看现在的前端工程化是如何保障编码的可维护性和质量。
编程风格
编程风格的统一在团队中尤为重要,在前端工程化整个流程中属于规范化阶段,这个阶段是基石阶段,基石不牢靠,建立出来的应用自然也就不稳定。
编程风格的核心是基本的格式,良好编程风格使代码更具有可读性。这就像你的高考作文如果没有严格的断句格式,一个标点符号都没有,那批卷的老师不得火冒三丈吗?在 TA 眼里就是一团字符,不可能还在那有限的时间里给你去断句,猜测每一句的语气,就只能送你一首《凉凉》。
1、格式化
基本的格式化包括缩进、语句结尾、行长度、换行、空行、命名、直接量等等。对于基本的格式化,现在的 IDE 就自带格式化规则,对于团队中使用不同的 IDE,可以创建 .editorconfig文件来定义格式化的规则。传送门
# 官网的示例配置
# EditorConfig is awesome: https://EditorConfig.org
# top-most EditorConfig file
root = true
# Unix-style newlines with a newline ending every file
[*]
end_of_line = lf
insert_final_newline = true
# Matches multiple files with brace expansion notation
# Set default charset
[*.{js,py}]
charset = utf-8
# 4 space indentation
[*.py]
indent_style = space
indent_size = 4
# Tab indentation (no size specified)
[Makefile]
indent_style = tab
# Indentation override for all JS under lib directory
[lib/**.js]
indent_style = space
indent_size = 2
# Matches the exact files either package.json or .travis.yml
[{package.json,.travis.yml}]
indent_style = space
indent_size = 2
当然除了基本的 js、css、json、yml等文件格式,还有 react 的 .jsx,vue 中的 .vue,css-in-js 等等各种不同的文件或者代码块,这里就需要用到额外的一些插件,比如:
- stylelint
- prettier
- ...
2、代码块
在基本的格式化基础上就是规范语句、表达式、运算符等的编写风格,这里统称代码块。
对于代码块的编码风格就包括对齐风格、语句间隔、语句编写最佳实践、如何减少变量、函数、运算符的复杂度等。
举一些熟知的规范:
- 变量函数命名规范
- 严格相等 ===
- 禁止使用包装类型创建对象
- ...
那么语句的编写最佳实践呢?其实这个很多时候是为了优化代码的性能,举两个例子:
1、比如 switch 优化,case 连续执行:
switch(condition) {
case "first":
case "second":
break;
case ""
}
2、比如 for-in 对象遍历,通过 hasOwnProperty 去过滤实例属性:
for(let prop in obj) {
if(obj.hasOwnProperty(prop)){
console.log(`property name is ${prop}`);
}
}
而对于以上是可以通过 ESLint 这样的插件来避免,当代码中出现不符合规范规则的时候,就出抛出警告或者错误,对于这类插件的另一好处是可以根据团队的具体情况来客制化规则。
编程实践
1、代码的耦合
在 UI 层的松耦合这一章,强调 HTML、CSS、JavaScript 即结构、样式、行为三者分离,到了现在的组件化开发时代,也是需要从 UI 中拆分出来的一个结构单元,让其成为组件,一个组件单元包含了 HTML 模板、CSS 样式、JavaScript 逻辑,组件化能达到复用和分治的目的。
现在流行框架的组件化开发都没有浏览器原生支持,需要经过 Transform 才能运行,所以对于 Vue 或者 React 这样的组件就需要通过打包构建工具等来转换成以便得到浏览器原生支持。
虽然现在相比之前的编写方式变了,但其需要做到代码松耦合的中心思想一直没有变。
2、全局变量
相信很多人在进入前端工程化后,接触到全局变量的几率比之前小了很多,可能更多的就是涉及到应用和打包构建的标识信息(比如 version 与 buildID)放在了全局变量里,在组件化和模块化开发的潮流中,之前全局变量带来的问题已经极大的避免了。
模块化开发的方式让每一个模块都是一个单独的作用域,在该模块内所定义的变量、函数等都是私有的,无法被其他模块读取。
3、事件处理
对于事件处理,书中强调了两个规则:
- 隔离应用逻辑
- 不分发事件对象
将应用逻辑所所有的事件处理程序中抽离出来是一种最佳实践,而且处理出来的逻辑部分可以进行单独测试,而不用去制造事件的触发。
不要分发事件对象则是为了让应用逻辑部分的代码不依赖事件对象,事件对象上包含很多和事件相关的额外信息,如果把事件对象无节制地分发,会让代码不够清晰而且在进行测试的时候还需要创建事件对象并作为参数传入,最佳的方式就是在事件处理程序中使用事件对象来处理事件,拿到所需要的数据传入给应用逻辑。
// bad
var application = {
handleClick: function(event) {
this.showPopup(event);
},
showPopup: function(event) {
var popup = document.getElementById('popup');
popup.style.top = event.clientY + 'px';
popup.style.left = event.clientX + 'px';
popup.className = 'reveal';
}
}
addEventListener(element, 'click', function(event) {
application.handleClick(event);
})
// good
var application = {
handleClick: function(event) {
this.showPopup(event.clientX, event.clientY);
},
showPopup: function(x, y) {
var popup = document.getElementById('popup');
popup.style.top = y + 'px';
popup.style.left = x + 'px';
popup.className = 'reveal';
}
}
addEventListener(element, 'click', function(event) {
application.handleClick(event);
})
这一部分同样适用于现代前端框架中的事件处理,尽管那些框架都是自己内部实现了一套事件机制,但应用逻辑部分的代码并不影响我们做抽离,应让每个应用逻辑函数表现得更为清晰。
好的 API 一定是对于期望和依赖都是透明的。
4、数据类型的判断
数据类型的判断检测主要是原始值、引用值以及属性的检测方法,这一部分内容经常出现在一些公司的面试中。
1、检测原始值
typeof 'str' // "string"
typeof 123 // "number"
typeof true // "boolean"
typeof undefined // "undefined"
typeof Symbol('123') // "symbol"
typeof 1n // "bigint"
原始值中对于 null 的判断比较特殊一些,如果需要判断是否是 null,则直接使用 === 或者 !== 来判断。
2、检测引用值
引用类型值的检测方法,可能有人一来就想到使用 instanceof 方法,但这方法用来判断对象是否属于某个特定类型的做法并非最佳。因为它不仅仅检测构造器,还检测原型链。
var now = new Date();
now instanceof Date // true
now instanceof Object // true
检测内置对象时使用 toString:
var arr = [];
Object.prototype.toString.call(arr); // "[object Array]"
function myFunc() {};
Object.prototype.toString.call(myFunc); // "[object Function]"
对于检测函数时也可以使用 typeof :
function myFunc() {};
typeof myFunc // "function"
3、检测属性
判断属性是否存在的最好的方法就是使用 in 运算符,in 运算符仅仅会简单地判断指定的属性是否存在,而不是读取属性值。如果判断属性值的话,很有可能因为属性值为假值而导致判断错误:
if(object[propertyName]) {
// code...
}
if(object[propertyName] != null) {
// code...
}
if(object[propertyName] != undefined) {
// code...
}
而现在有了 TypeScript 加持,不仅仅通过类型注解来提供编译时的静态类型检查,大大的降低了 JavaScript 本身的不确定性,还提升了代码的阅读性和维护性。
比如低级检查:
const books = [{
name: 'JavaScript',
price: 20
}, {
name: 'Java',
price: 15
}];
const sortedBooks = books.sort((a, b) => a.name.localCompare(b.name));
// error TS2339: Property 'localCompare' does not exist on type 'string'.
非空判断:
const data = {
list: null,
success: true
};
const value = data.list.length;
基于类型检查的特点来编写测试用例也会更好的去缩小出错的边界。
4、配置分离
将配置数据抽离出来,意味着任何人都可以修改它们,而不会导致应用逻辑出错,还可以将配置数据放到单独的文件,将配置数据和代码隔离开来,而配置分离也是 12-factor APP(12 要素应用程序)之一,传送门。
配置数据一般分为私密配置和可暴露配置,私密配置通常是服务器凭证、数据库连接信息等等,而可暴露配置通常是 API 接口地址、域名、Appkey 等等,这些最后都会出现在代码中。
在前端工程化之前如果要进行配置分离,基本上是使用 JSON 文件或者从服务器端获取的方式来进行抽离管理配置数据,自从有了 Node.js 和构建工具加持后,对于私密配置可以把使用 .env 文件配置存储在环境变量中,在不同的环境下,比如 development 、 staging 、 production 都有不同的配置信息。而对于可暴露配置就使用模块化的方式引入或者利用构建工具注入到代码中。
5、抛出自定义错误
抛出有价值的错误,不管在什么环境或者使用什么编程语言下都很重要,抛出错误不是为了防止错误,而是在错误发生时能更容易地进行调试。
错误是开发者的朋友,而不是敌人。
那么如何何时需要抛出错误呢?
- 一旦修复了一个很难调试的错误,尝试增加一俩个自定义错误。当再次发生错误时,这将有助于更容易地解决问题;
- 正在编写代码,思考一下,希望当前的那些代码发生了情况就会一团糟;
- 如果正在编写的代码别人(不知道是谁)也会使用,思考一下他们的使用方式,在特定的情况下抛出错误;
对于现在的前端框架和库来说,其内部都有值得学习的错误抛出方式,因为作为开发者是这些框架和库的使用者,而作者埋在框架中的错误抛出就是为了让开发者更好的定位到问题所在,能快速的解决问题。
浏览器兼容
芜湖...,随着微软宣布从 2022 年 6 月 15 日起,某些版本的 Windows 软件将不再支持当前版本的 IE 11 桌面应用程序,前端工程师的噩梦也随着这个消息终结,但主流浏览器的兼容还是需要背负。
在工程化时代,利用构建工具可以将 JavaScript polyfill 、各种 loader 以及 autoprefixer 去做到兼容性的处理,而现代前端框架也都对主流浏览器提供了支持,甚至还有 browserslist 这样的神器来帮助你更方便的在不同工具之间对目标浏览器特性支持的配置。
文件和目录结构
对于前面提到的代码拆分抽离其实也与目录结构相关,因为拆分会增加项目的文件数量,数量增加了,目录结构复杂度也会增加,每个文件的功能也会更加独立,就降低了与其他文件的耦合。
那么合理的目录结构带来的好处仅仅是看起来赏心悦目吗?不是的,还有以下几个方面的体现:
- 让目录结构清晰、更容易理解(比如 src:源文件,build:最终构建目录,tests:测试文件)
- 避免多人维护一个文件的情况
- 降低合并冲突的可能性
好的结构可以缩短构建的时间,而且不会让开发人员在新建文件的时候还纠结放在哪里,对新入职的成员也更为友好。

现在很多框架的 cli 或者优秀的开源项目都提供了一个很好的示例,可以参考参考他们的做法。
文档化
很多开发者都只喜欢写代码,不喜欢写文档,针对于 JavaScript 的文档生成工具是很多的,比如 JSDoc、YUIDoc 等,可以根据 Javascript 文件中注释信息,生成 JavaScript 库、模块的 API 文档,可以使用它记录如:命名空间、类、方法、方法参数等。
但是由于组件化开发 + TypeScript 的出现,对于代码内的注释来生成文档这一现象已渐渐弱化,更多是架设项目组件开发的文档站点,比如利用 StyleGuidist、StoryBook、dumi 等等这样工具,对于一些逻辑不是复杂或者工具类的函数,通过编写阅读性强的代码(好的编码规范和风格)和强大的 Static Analyzer 就能很清楚为什么要这么写的具体细节,但是对于逻辑复杂的代码还是需要加上注释。
除此之外,随着团队规模的增加,文档的沉淀也变得愈发重要,比如业务文档、技术文档、分享沉淀文档、新人文档等等,这些不仅仅可以降低沟通成本,还能让团队的成员得到成长。
自动化
任何简单机械的重复劳动都应该让机器去完成,自动化是前端工程化的一部分,自动化包括:
- 自动化测试
- 自动化构建
- 自动化部署
现在的自动化主要是针对作业自动化,提升开发效率和体验,一系列动作都是在代码提交后,通过 Git Hook 来进行触发。
1、自动化测试
自动化测试是指把以人为驱动的测试行为转化为机器执行的过程,最大优势就是可以快速而且反复的进行测试,进一步提升测试效率。实际上自动化测试往往通过一些测试工具或框架,编写自动化测试用例,来模拟手工测试过程。
对于前端来说,测试一般分为三种类型:单元测试(Unit Test)、集成测试(Integration Test)、UI 测试(UI Test),这三种测试类型的测试占比在理想状态下形成了一个金字塔模型。
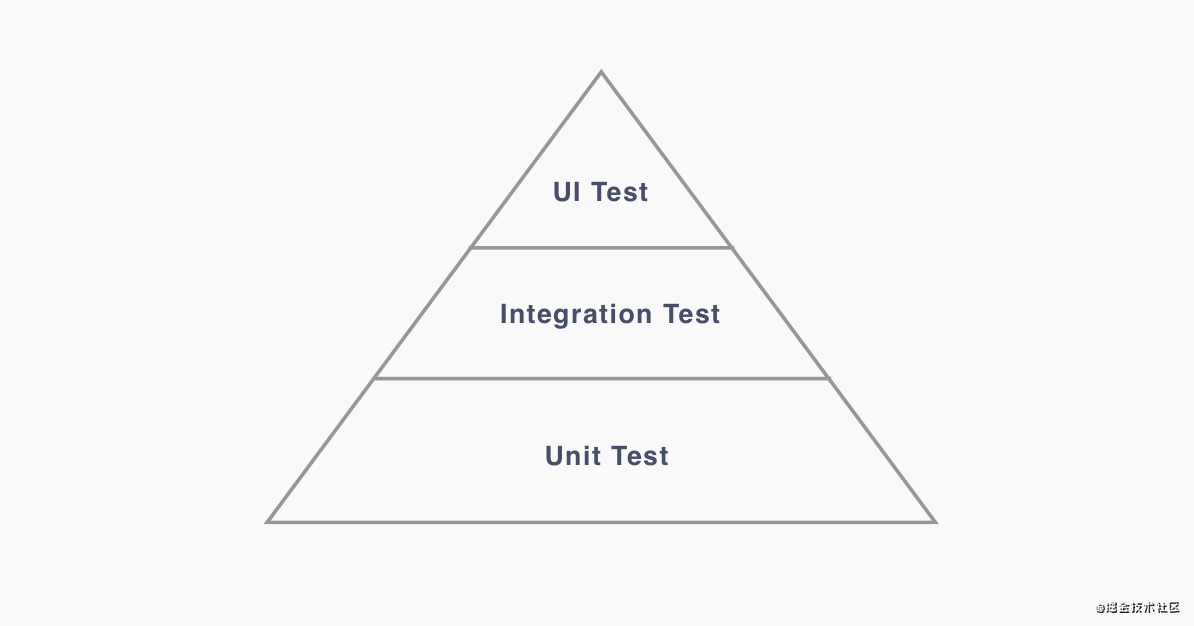
在引入自动化测试之前需要思考当前项目、人员的配置情况、生命周期等要素,不然引入的成本就会变得更高或者说意义并不大,自动化测试更多的适用于这些类型的项目:
- 公共库的开发维护
- 中长期的项目的迭代和重构
- 不可控的三方依赖
现在前端的测试工具或框架有很多: Mocha、Jest、Jasmine、Enzyme、Cypress 等等,要说谁最好用,就没有,根据项目和团队的情况选择适合的才是最好的。
2、自动化构建
自动化构建是对目标源项目文件或者资源进行处理成需要的最佳输出结构和形式,比如语法校验、编译、代码合并和压缩、代码拆分、图片处理等等。这样可以解决很多需要手动完成的事情,构建阶段主要体现的是优化、提神效率和流程联动等。
常见的构建工具有 webpack、gulp、rollup 等 还有最新热门的 vite。
3、CI/CD
软件开发交付流程从最初的瀑布模型,到敏捷开发,再到现在的 DevOps。
敏捷开发是关于软件开发的过程与模式,而 DevOps 则通过消除资源浪费和简化部署等方式很好的补充了敏捷开发,从而实现更快,更持续的生产部署,更多是关于软件部署和运维管理。
随着 DevOps 的兴起,出现了 CI/CD。什么是 CI/CD 呢?CI(Continuous Integration)被称为持续集成,属于开发人员的自动化流程,而 CD(Continuous Delivery/Deployment)是持续交付和持续部署。
持续集成(CI)
持续集成可以帮助开发人员更加频繁地将代码更改合并到开发分支或主分支中(通常通过 Git 或 SVN 这样的工具)。一旦开发人员对应用所做的更改被合并,系统就会通过自动构建应用并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。
持续交付(CD)
持续交付通常是指开发人员对应用的更改会自动进行测试并上传到存储库(如 GitHub 或容器注册表),然后由运维团队将其部署到实时生产环境中。目的是解决开发团队和运维团队的可见性和沟通效率低的问题,确保尽可能的减少部署新代码时所需要的成本。
持续部署(CD)
持续部署是自动将开发人员的更改从存储库发布到生成环境,主要是为了解决因手动流程降低应用的交付速率,持续部署以持续交付的优势为根基,实现了管道后续阶段的自动化。
在之前很多公司会每月,或者每季度,甚至每年发布自己的产品,但现在每天、每周进行发布已经是常态,所以持续快速性的进行交付也是在顺应的时代的发展。
下面这张图很好的诠释了 CI/CD 整个闭环的流程:
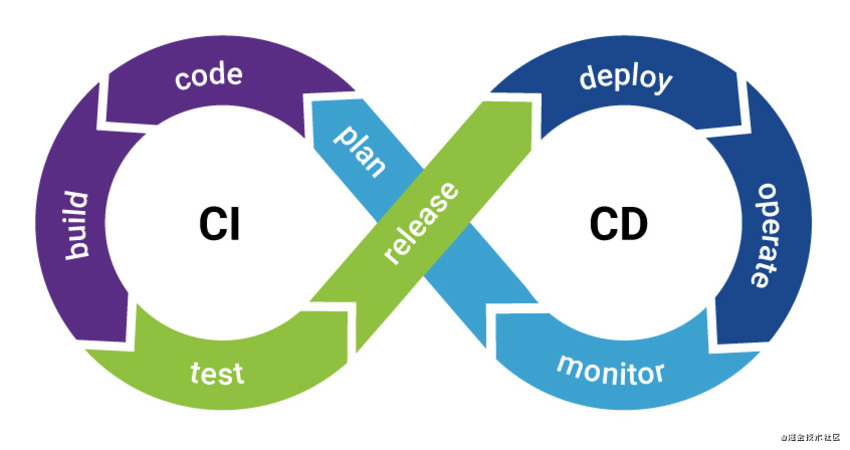
从计划 -> 编码 -> 自动化构建 -> 自动化测试 -> 版本发布 -> 生产部署 -> 产品运营 -> 数据监控 -> 计划,整个流程再次循环,直到产品生命周期的结束。
最后
以上就是重读这本书以及结合前端工程化的一些重新认识和总结,感谢各位看官,如喜欢,麻烦来个三连,如疑问,欢迎在评论区留言。