
前端领域的转译打包工具链(下):工程化闭环
这是我参与更文挑战的第7天,活动详情查看: 更文挑战。
这是前端领域的转译打包工具链的第二篇文章,上篇文章讲了前端领域的各种转译器,包括 babel、tsc、terser、eslint、postcss、posthtml、swc 等,介绍了他们各自的用途和通用的原理,还有在项目中使用的 3 种方式:git hooks、ide 插件、打包工具的 loader 和 plugin。
这一节我们继续探究工程化的工具链,包括打包工具、模块化、v8 引擎、跨端引擎、工程化的闭环等。
任务管理器和打包工具
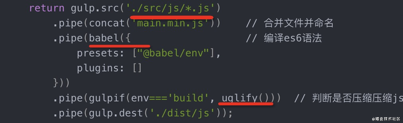
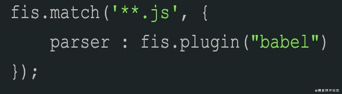
其实在打包工具流行之前,当时主要是各种任务管理器,比如 gulp、fis。它们通过匹配文件路径的方式来对不同文件应用不同的转译器。
比如 gulp:

和 fis:
当时的模块化方案大多是 amd、cmd 这种需要加载一个运行时库(require.js 和 sea.js)来支持的方案,不需要打包,只需要对文件做转译。
但是后来 commonjs 和 esm 的模块化方案流行开来,而这些模块化方案不再是通过加载一个运行时库的方式来支持,而是通过打包工具把他们转成浏览器支持的函数的形式。
这些打包工具中,最流行的是 webpack。它不再是通过正则来匹配文件路径来做转译了,而是从入口模块开始分析模块之间的依赖关系,遇到不同的后缀名的文件应用配置的不同 loader。还可以通过 plugin 在输出文件之前对所有内容做一次处理。
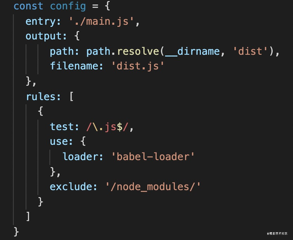
这种方式和任务管理器的匹配文件路径的方式相比更细致,能够做更多的优化,所以渐渐流行开来,而 gulp、fis 等方案也逐渐走向没落。
模块化规范
模块打包,都是基于模块规范的,我们来梳理下历史上的模块化的规范。
其实最早 js 是没有模块化规范的,当时都是通过 window 上的 namespace 来避免命名冲突的,比如 jquery 提供了 $.confict 方法,ts 也有 namespace 的语法。
后来有了 amd、cmd 的方案,
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
})
// AMD
define(['./a'], function(a) {
a.doSomething()
})
这两种分别由 sea.js 和 require.js 实现,需要运行时先加载这两个库。
再后来 nodejs 的模块化规范 commonjs 流行开来,开发时使用 commonjs 规范,然后通过打包工具转成浏览器支持的模块化方案。
const a = require('a');
a.doSomething();
es2015 之后,js 语言级别支持了模块化,就是 es module。
import a from 'a';
a.doSomething();
esm 有兼容问题,生产环境下同样需要打包工具转成其他模块实现。
webpack
打包工具中最流行的是 webpack。
webpack 是通过模块之间依赖关系的分析来构建依赖图,通过不同的后缀对应的 loader 来对不同内容做转换,所以支持 css、js、png 等各种模块。

weback 的打包流程
webpack 并不是把模块处理完就直接输出的,而是做了一次分组(chunk),按照一定的分组规则,把一些模块合并到同个 chunk 中,之后再输出成文件。
我们知道,浏览器对一个域名并行加载的资源数也就是 5 个左右,所以合并成 chunk 有利于网页加载速度的优化。
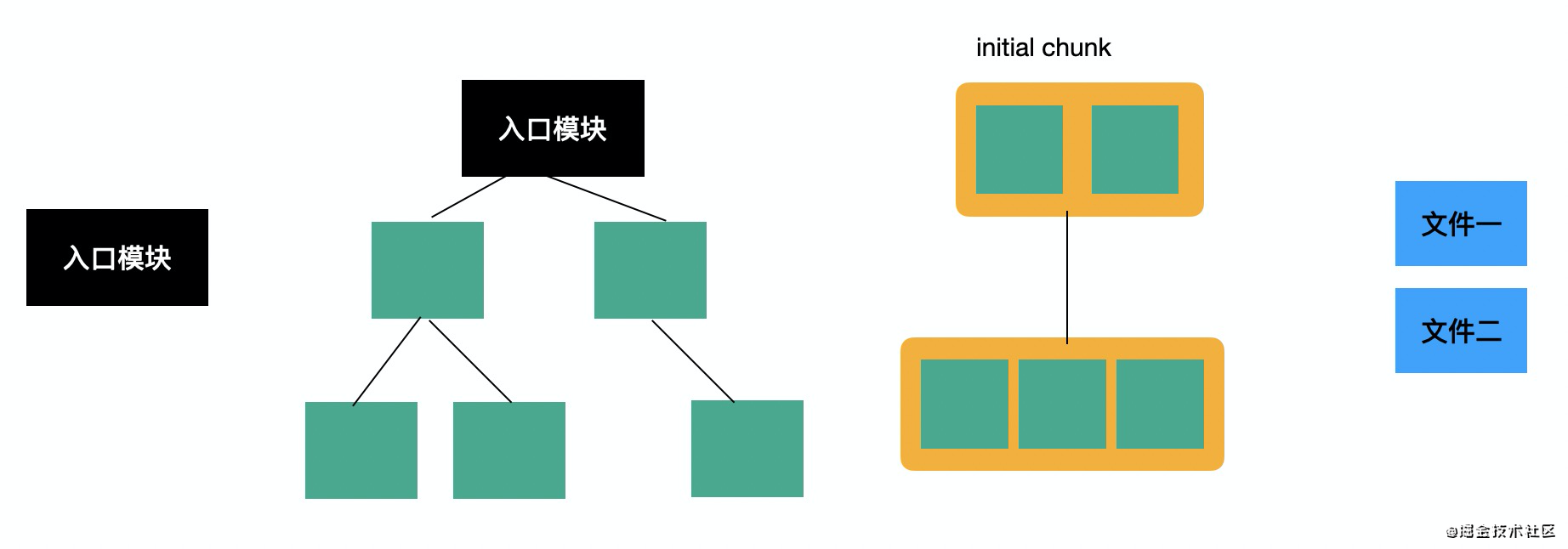
模块是一个图(一个模块可以被多个模块依赖),分组之后仍然会有依赖关系。从 module graph 到 chunk graph 的转换是 webpack 逻辑最复杂的地方之一。
和模块一样,chunk 也有入口 chunk,叫做 intial chunk,其中保存了 webpack 用于支持模块加载的一些运行时的 api,当然这部分 runtime 代码也可以抽离出来。
module.exports = {
optimization: {
runtimeChunk: true
},
};
webpack 设计的模块分组机制(chunk 机制)有两个好处:
- 减少请求数量,把模块合并到若干个 chunk 能够并行加载
- 把公共模块划分到同个 chunk,更好的利用缓存
webpack 整体的编译流程是:从入口模块开始构建模块依赖图,之后转换为 chunk 依赖图,然后使用不同的 chunk 模版打印成 assets,输出成文件。
webpack 做的优化
webpack 的优化大体可以分为基于 runtime 的优化和基于编译的优化两种
基于 runtime 的优化
webpack 有自己的 runtime,也基于 runtime 做了很多优化。
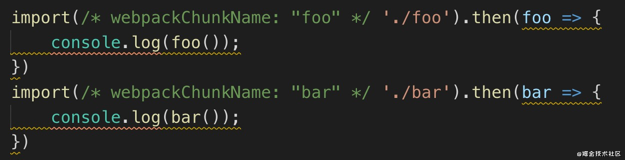
- 不需要马上加载模块可以懒加载,通过 require.ensure、import 等 api 来延后加载。这功能叫
code spliting。
-
通过 window 共享变量的方式来复用其他模块,可以把之前打包后的模块挂在 window 上,通过 window 在运行时获取该模块。这个是 dll plugin 的功能,用于减少一些不经常变动的模块的编译。
-
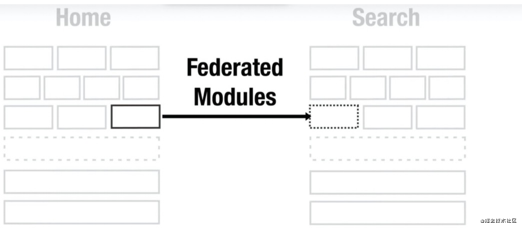
通过 window 共享变量的方式,共享其他 bundle 的模块,这个和 dll plugin 的思路一样,但是 webpack5 给他设计了一套 api,用于 bundle 间共享模块,叫做模块联邦(module fedaration)。
基于编译的优化
基于编译的优化主要是 tree shaking,可以在打包的时候把没用到的 export 给删掉,其实就是跨文件的死代码删除(dead code elimation)
treeshking 的实现有两种思路:
-
合并成一个文件,通过声明提升,变成单文件的 DCE,让 terser 来处理
-
自己做多文件的 import 和 export 的引用计数,删掉没有被用到的 export
rollup 基于第一种做 treeshking,而 webpack 主要是基于第二种,当然也可以通过一些做作用域提升的插件来触发第一种 treeshking。
tree shking 基于对 es module 的静态分析,因为 import 的 source 只能是字符串,不会是动态生成的内容,所以可以分析。而 commonjs 的依赖就没法分析,也就没法 treeshking。
bundleless
我们打包是因为浏览器不支持 es module,但是现代浏览器已经有部分能够支持 esmodule 了,所以出现了 bundless 的思路,比如 vite。

不需要进行模块依赖图的分析,只需要根据请求的路径使用服务端的 middleware 来处理请求的资源即可,在中间件里面调用转译器对文件内容做转换。
开发环境下极大提升了构建速度。
但是生产环境因为兼容问题,还是需要打包。
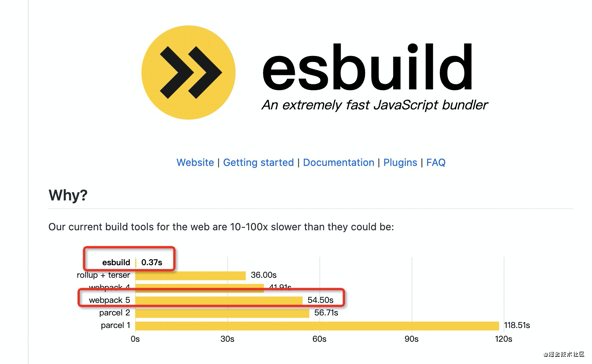
esbuild
就像转译器有用 rust 写的 swc,打包工具也有了 go 写的 esbuild,利用 go 的协程来处理并发编译,速度上相比 webpack 有极大提升。
所以 vite 在生产环境的打包使用了 esbuild。
js 引擎
转译打包后的代码怎么跑起来呢?
就需要 JS 解释器,比如 V8、SpiderMonkey、hermes ...
解释器和转译器的区别
转译器是把源码 parse 成 AST 之后,进行 AST 转换,之后再打印成目标代码,并生成 sourcemap。
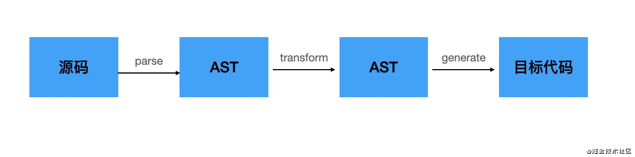
而解释器是把源码 parse 成 AST 之后解释执行 AST,或者转成字节码之后解释执行字节码。而且还可以把字节码编译成机器码直接执行,这种叫做 JIT 编译。
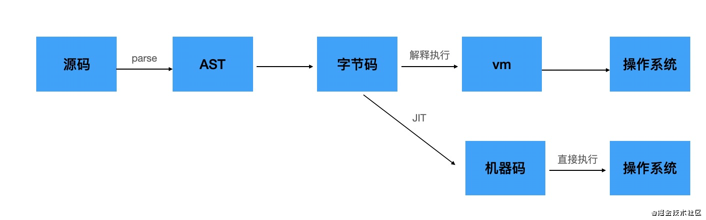
v8 就是这样的编译流程:
- ignation 是解释器,会把 AST 转成 bytecode 并解释执行
- turbofan 是 JIT 编译器,可以把字节码编译成机器码,直接执行
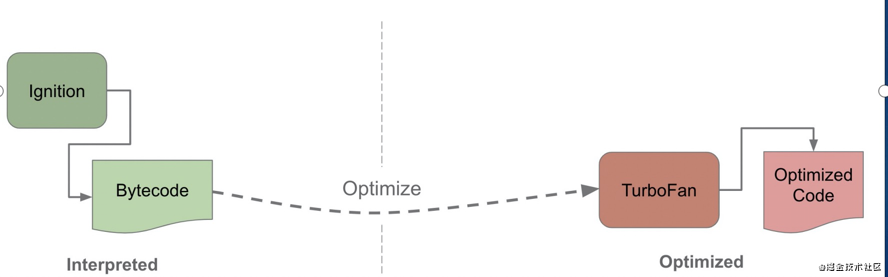
上面说的这些都是从源码开始 parse,然后解释执行的,其实 js 也完全可以做到像 java 一样,先把源码编译成字节码,然后直接执行字节码的思路。这样可以提升运行速度。
react native 的 js 引擎 hermes 就是这么做的:
提前进行 parse 和 compile,之后就可以直接从字节码开始解释或者直接从机器码执行。
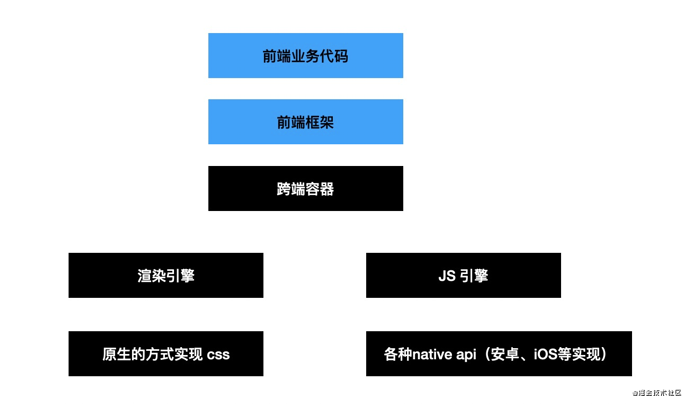
跨端引擎
js 引擎除了在浏览器里面跑以外,也会用在跨端引擎中,跨端引擎会给它注入各种 native 能力的 api,而且会注入自己实现的 dom api。
跨端引擎是为了让前端代码渲染到原生,实现了一套 css 渲染引擎和 dom api,提供了前端代码运行的容器,可以对接各种前端框架。
工程化闭环
我们聊了转译器、模块化、打包工具、bundleless、js 引擎、跨端引擎等,这些串联起来就是前端领域的工具链。
在开发环境下和生产环境下的工具链不同,形成了两种工程化的闭环。
开发环境的工程化闭环
开发环境下,源码经过转译打包生成目标代码(不压缩),目标代码会放到开发服务器,浏览器请求开发服务器下载代码来运行和调试,支持 sourcemap,根据运行情况进行修改代码,这是开发时的闭环。
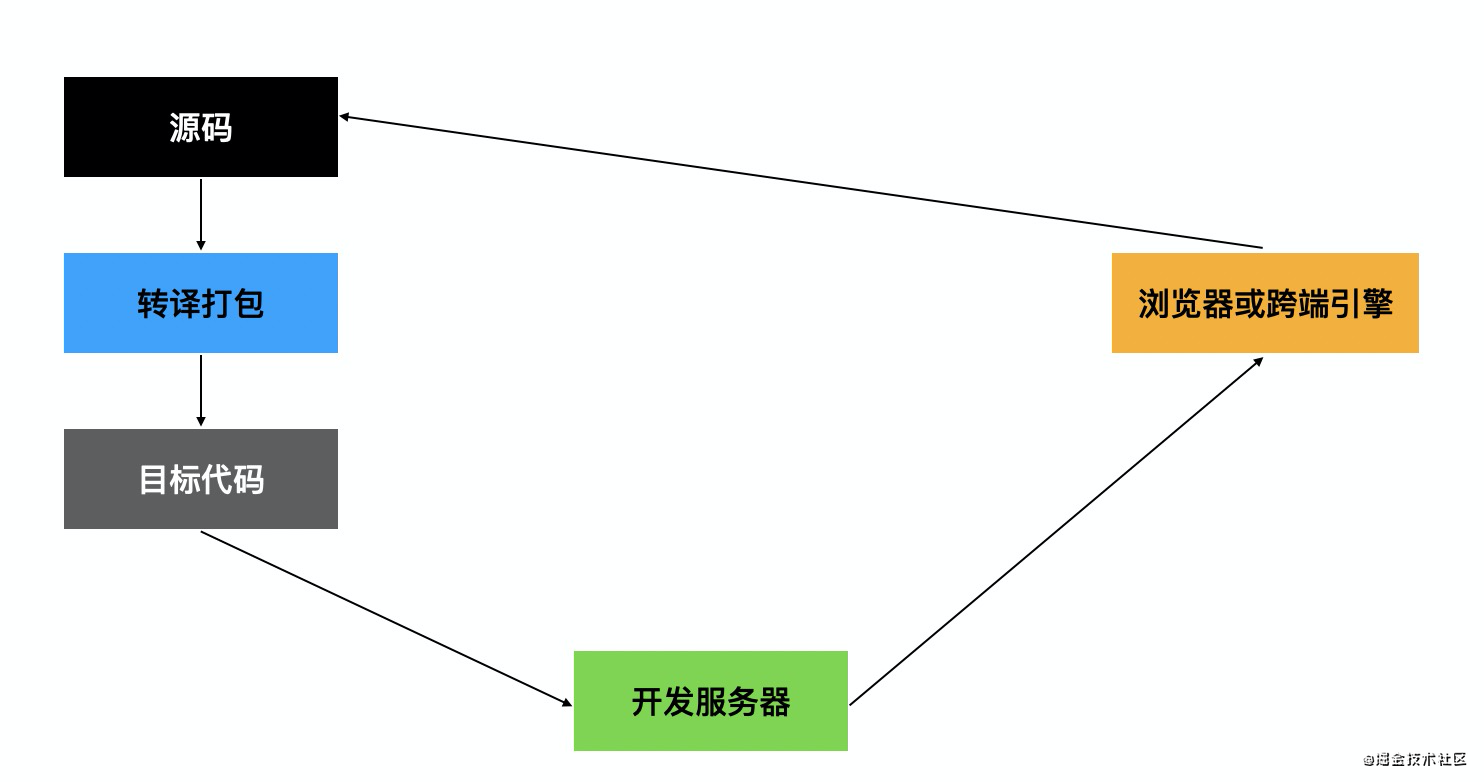
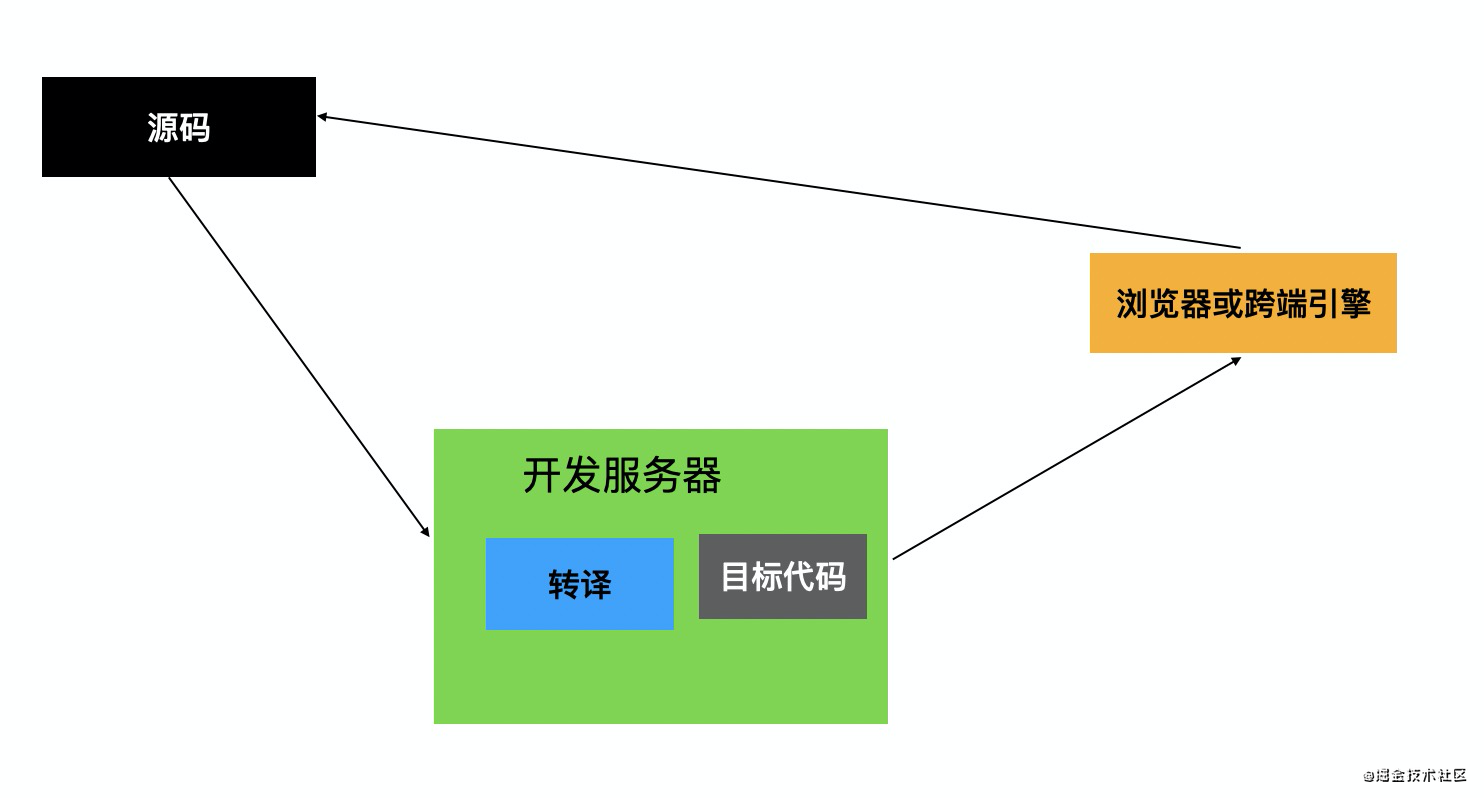
当然,如果是 bundleless 的话,转译直接在开发服务器上完成了,不需要打包:
生产环境的工程化闭环
在生产环境下,源码经过转译打包生成目标代码,通过 ci cd 上传文件到 cdn 服务器,用户请求 cdn 获取代码运行,根据性能和报错监控以及产品经理反馈来进行 bug 修改和后续迭代。这是生产时的闭环。

总结
这两篇文章的内容就是我去华为分享的全部了,主要是讲了前端领域的转译器、打包工具、js 引擎、跨端引擎,以及串联起了整个工程化的工具链闭环。
我们总结下这两节的内容:
因为前端 html、css、js 直接从源码解释的特点,所以需要转译器,不同转译器(babel、tsc、terser、eslint、postcss、posthtml、swc)目的不同,但原理差不多,流程都是:把源码 parse 成 AST,对 AST 进行分析和转换,之后生成目标代码和 sourcemap。
转译器用在项目里需要配合打包工具,或者通过 ide 插件、git hooks 的方式使用。
转译器大多是对单个文件进行处理,打包工具用于整个项目的处理。
多个文件通过模块的方式组合在一起,比如 esm、commonjs 等模块规范,打包工具通过分析模块依赖关系的方式,递归处理每一个模块。
基于模块依赖分析的打包工具比如 webpack 是现在的主流,通过划分 chunk 来控制文件数量,编译时会做 tree shking,运行时提供了 code spliting、dll plugin、module federation 等机制来优化性能。
部分浏览器支持了 es module,开发时可以使用 bundleless 方案,不分析模块依赖图,直接对请求的文件对转译,比如 vite。
esbuild 使用 go 来写,速度相比 webpack 有比较大的提升。
跨端引擎有自己定制的 JS 引擎和渲染引擎,可以做很多针对性的优化。
源码经过转译打包后,部署到开发服务器(开发环境)或者通过 ci、cd 上传 cdn(生产环境),然后下发到用户的浏览器(或跨端引擎)解释执行,根据监控或者自己发现的问题进行修改。这是前端工程化的闭环。
这两节内容比较多,主要是把工具链各个环节串讲了一遍,希望能帮你理清前端工程化的脉络。