
常考vue面试题(附答案)
Vue生命周期钩子是如何实现的
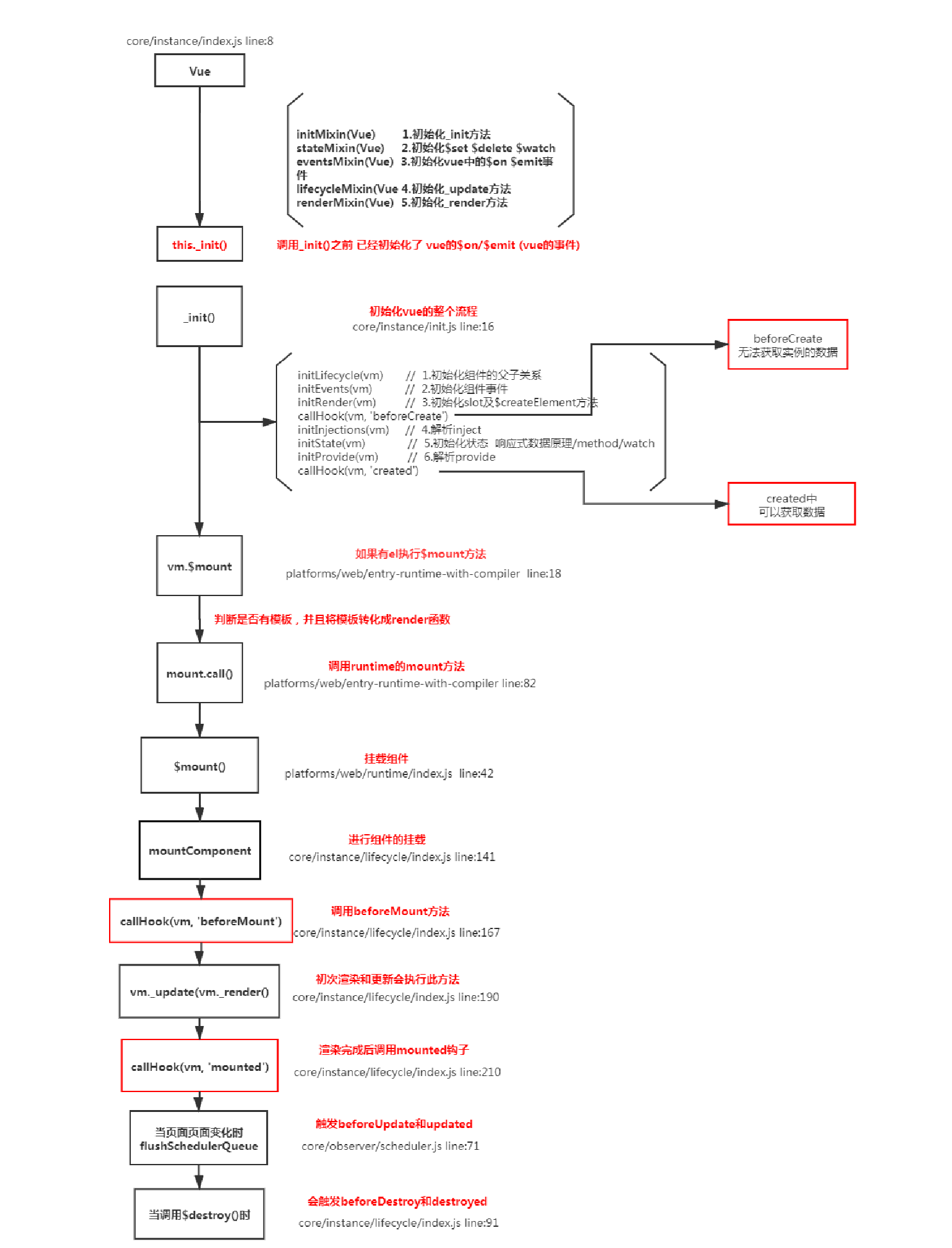
vue的生命周期钩子就是回调函数而已,当创建组件实例的过程中会调用对应的钩子方法- 内部会对钩子函数进行处理,将钩子函数维护成数组的形式
Vue的生命周期钩子核心实现是利用发布订阅模式先把用户传入的的生命周期钩子订阅好(内部采用数组的方式存储)然后在创建组件实例的过程中会一次执行对应的钩子方法(发布)
<script>
// Vue.options 中会存放所有全局属性
// 会用自身的 + Vue.options 中的属性进行合并
// Vue.mixin({
// beforeCreate() {
// console.log('before 0')
// },
// })
debugger;
const vm = new Vue({
el: '#app',
beforeCreate: [
function() {
console.log('before 1')
},
function() {
console.log('before 2')
}
]
});
console.log(vm);
</script>相关代码如下
export function callHook(vm, hook) {
// 依次执行生命周期对应的方法
const handlers = vm.$options[hook];
if (handlers) {
for (let i = 0; i < handlers.length; i++) {
handlers[i].call(vm); //生命周期里面的this指向当前实例
}
}
}
// 调用的时候
Vue.prototype._init = function (options) {
const vm = this;
vm.$options = mergeOptions(vm.constructor.options, options);
callHook(vm, "beforeCreate"); //初始化数据之前
// 初始化状态
initState(vm);
callHook(vm, "created"); //初始化数据之后
if (vm.$options.el) {
vm.$mount(vm.$options.el);
}
};
// 销毁实例实现
Vue.prototype.$destory = function() {
// 触发钩子
callHook(vm, 'beforeDestory')
// 自身及子节点
remove()
// 删除依赖
watcher.teardown()
// 删除监听
vm.$off()
// 触发钩子
callHook(vm, 'destoryed')
}原理流程图

Vue 子组件和父组件执行顺序
加载渲染过程:
- 父组件 beforeCreate
- 父组件 created
- 父组件 beforeMount
- 子组件 beforeCreate
- 子组件 created
- 子组件 beforeMount
- 子组件 mounted
- 父组件 mounted
更新过程:
- 父组件 beforeUpdate
- 子组件 beforeUpdate
- 子组件 updated
- 父组件 updated
销毁过程:
- 父组件 beforeDestroy
- 子组件 beforeDestroy
- 子组件 destroyed
- 父组件 destoryed
Vue的基本原理
当一个Vue实例创建时,Vue会遍历data中的属性,用 Object.defineProperty(vue3.0使用proxy )将它们转为 getter/setter,并且在内部追踪相关依赖,在属性被访问和修改时通知变化。 每个组件实例都有相应的 watcher 程序实例,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的setter被调用时,会通知watcher重新计算,从而致使它关联的组件得以更新。
Vue complier 实现
- 模板解析这种事,本质是将数据转化为一段
html,最开始出现在后端,经过各种处理吐给前端。随着各种mv*的兴起,模板解析交由前端处理。 - 总的来说,
Vue complier是将template转化成一个render字符串。
可以简单理解成以下步骤:
parse过程,将template利用正则转化成AST抽象语法树。optimize过程,标记静态节点,后diff过程跳过静态节点,提升性能。generate过程,生成render字符串
MVVM、MVC、MVP的区别
MVC、MVP 和 MVVM 是三种常见的软件架构设计模式,主要通过分离关注点的方式来组织代码结构,优化开发效率。
在开发单页面应用时,往往一个路由页面对应了一个脚本文件,所有的页面逻辑都在一个脚本文件里。页面的渲染、数据的获取,对用户事件的响应所有的应用逻辑都混合在一起,这样在开发简单项目时,可能看不出什么问题,如果项目变得复杂,那么整个文件就会变得冗长、混乱,这样对项目开发和后期的项目维护是非常不利的。
(1)MVC
MVC 通过分离 Model、View 和 Controller 的方式来组织代码结构。其中 View 负责页面的显示逻辑,Model 负责存储页面的业务数据,以及对相应数据的操作。并且 View 和 Model 应用了观察者模式,当 Model 层发生改变的时候它会通知有关 View 层更新页面。Controller 层是 View 层和 Model 层的纽带,它主要负责用户与应用的响应操作,当用户与页面产生交互的时候,Controller 中的事件触发器就开始工作了,通过调用 Model 层,来完成对 Model 的修改,然后 Model 层再去通知 View 层更新。
(2)MVVM
MVVM 分为 Model、View、ViewModel:
- Model代表数据模型,数据和业务逻辑都在Model层中定义;
- View代表UI视图,负责数据的展示;
- ViewModel负责监听Model中数据的改变并且控制视图的更新,处理用户交互操作;
Model和View并无直接关联,而是通过ViewModel来进行联系的,Model和ViewModel之间有着双向数据绑定的联系。因此当Model中的数据改变时会触发View层的刷新,View中由于用户交互操作而改变的数据也会在Model中同步。
这种模式实现了 Model和View的数据自动同步,因此开发者只需要专注于数据的维护操作即可,而不需要自己操作DOM。
(3)MVP
MVP 模式与 MVC 唯一不同的在于 Presenter 和 Controller。在 MVC 模式中使用观察者模式,来实现当 Model 层数据发生变化的时候,通知 View 层的更新。这样 View 层和 Model 层耦合在一起,当项目逻辑变得复杂的时候,可能会造成代码的混乱,并且可能会对代码的复用性造成一些问题。MVP 的模式通过使用 Presenter 来实现对 View 层和 Model 层的解耦。MVC 中的Controller 只知道 Model 的接口,因此它没有办法控制 View 层的更新,MVP 模式中,View 层的接口暴露给了 Presenter 因此可以在 Presenter 中将 Model 的变化和 View 的变化绑定在一起,以此来实现 View 和 Model 的同步更新。这样就实现了对 View 和 Model 的解耦,Presenter 还包含了其他的响应逻辑。
Vue 3.0 中的 Vue Composition API?
在 Vue2 中,代码是 Options API 风格的,也就是通过填充 (option) data、methods、computed 等属性来完成一个 Vue 组件。这种风格使得 Vue 相对于 React极为容易上手,同时也造成了几个问题:
- 由于 Options API 不够灵活的开发方式,使得Vue开发缺乏优雅的方法来在组件间共用代码。
- Vue 组件过于依赖
this上下文,Vue 背后的一些小技巧使得 Vue 组件的开发看起来与 JavaScript 的开发原则相悖,比如在methods中的this竟然指向组件实例来不指向methods所在的对象。这也使得 TypeScript 在Vue2 中很不好用。
于是在 Vue3 中,舍弃了 Options API,转而投向 Composition API。Composition API本质上是将 Options API 背后的机制暴露给用户直接使用,这样用户就拥有了更多的灵活性,也使得 Vue3 更适合于 TypeScript 结合。
如下,是一个使用了 Vue Composition API 的 Vue3 组件:
<template>
<button @click="increment">
Count: {{ count }} </button>
</template>
<script>
// Composition API 将组件属性暴露为函数,因此第一步是导入所需的函数
import { ref, computed, onMounted } from 'vue'
export default { setup() {
// 使用 ref 函数声明了称为 count 的响应属性,对应于Vue2中的data函数
const count = ref(0)
// Vue2中需要在methods option中声明的函数,现在直接声明
function increment() { count.value++ } // 对应于Vue2中的mounted声明周期
onMounted(() => console.log('component mounted!')) return { count, increment } }}
</script>显而易见,Vue Composition API 使得 Vue3 的开发风格更接近于原生 JavaScript,带给开发者更多地灵活性
参考 前端进阶面试题详细解答
Vue中diff算法原理
DOM操作是非常昂贵的,因此我们需要尽量地减少DOM操作。这就需要找出本次DOM必须更新的节点来更新,其他的不更新,这个找出的过程,就需要应用diff算法
vue的diff算法是平级比较,不考虑跨级比较的情况。内部采用深度递归的方式+双指针(头尾都加指针)的方式进行比较。
简单来说,Diff算法有以下过程
- 同级比较,再比较子节点(根据
key和tag标签名判断) - 先判断一方有子节点和一方没有子节点的情况(如果新的
children没有子节点,将旧的子节点移除) - 比较都有子节点的情况(核心
diff) - 递归比较子节点
- 正常
Diff两个树的时间复杂度是O(n^3),但实际情况下我们很少会进行跨层级的移动DOM,所以Vue将Diff进行了优化,从O(n^3) -> O(n),只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。 Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅- 在创建
VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升
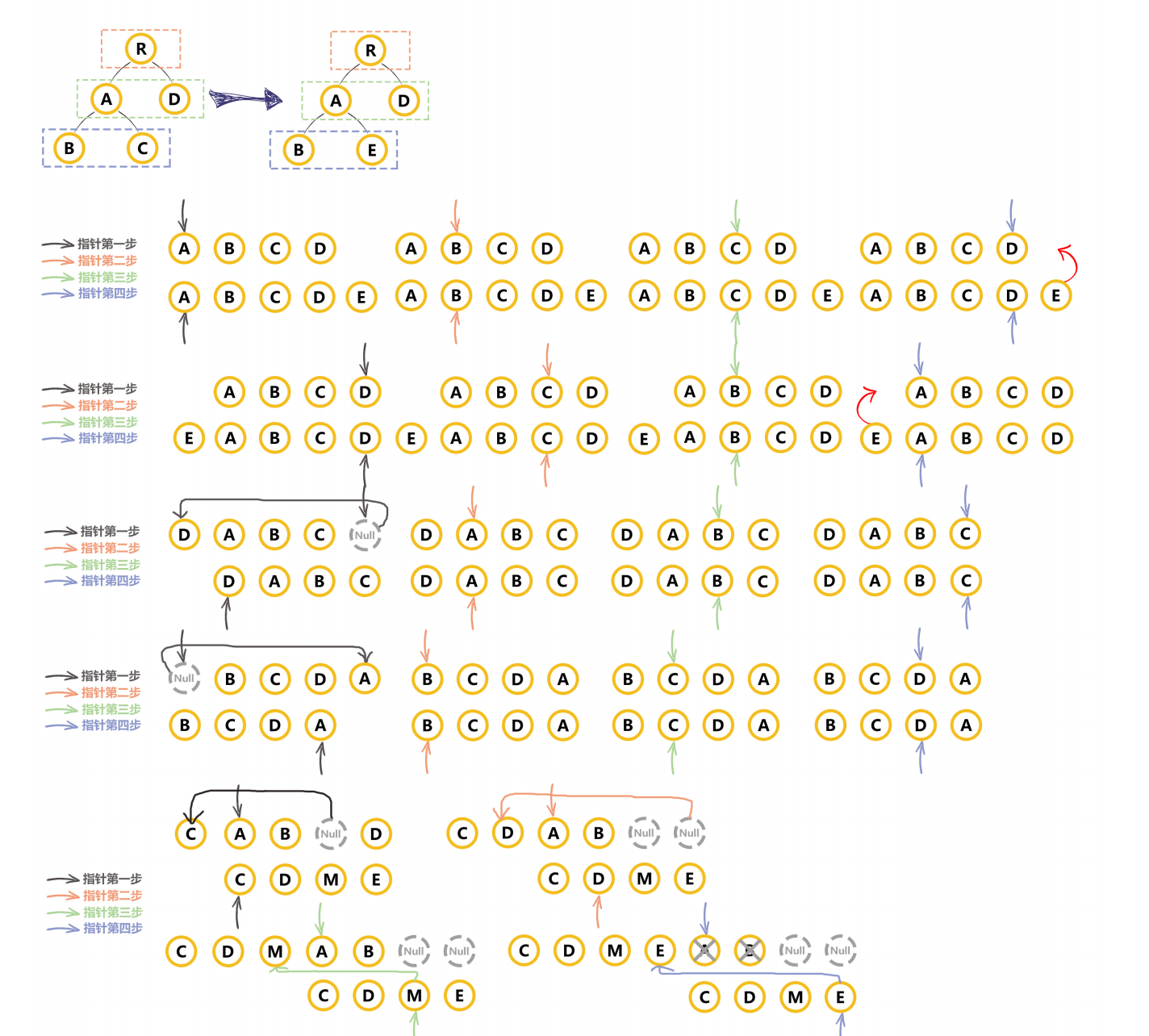
vue3中采用最长递增子序列来实现
diff优化
回答范例
思路
diff算法是干什么的- 它的必要性
- 它何时执行
- 具体执行方式
- 拔高:说一下
vue3中的优化
回答范例
Vue中的diff算法称为patching算法,它由Snabbdom修改而来,虚拟DOM要想转化为真实DOM就需要通过patch方法转换- 最初
Vue1.x视图中每个依赖均有更新函数对应,可以做到精准更新,因此并不需要虚拟DOM和patching算法支持,但是这样粒度过细导致Vue1.x无法承载较大应用;Vue 2.x中为了降低Watcher粒度,每个组件只有一个Watcher与之对应,此时就需要引入patching算法才能精确找到发生变化的地方并高效更新 vue中diff执行的时刻是组件内响应式数据变更触发实例执行其更新函数时,更新函数会再次执行render函数获得最新的虚拟DOM,然后执行patch函数,并传入新旧两次虚拟DOM,通过比对两者找到变化的地方,最后将其转化为对应的DOM操作patch过程是一个递归过程,遵循深度优先、同层比较的策略;以vue3的patch为例- 首先判断两个节点是否为相同同类节点,不同则删除重新创建
- 如果双方都是文本则更新文本内容
- 如果双方都是元素节点则递归更新子元素,同时更新元素属性
- 更新子节点时又分了几种情况
- 新的子节点是文本,老的子节点是数组则清空,并设置文本;
- 新的子节点是文本,老的子节点是文本则直接更新文本;
- 新的子节点是数组,老的子节点是文本则清空文本,并创建新子节点数组中的子元素;
- 新的子节点是数组,老的子节点也是数组,那么比较两组子节点,更新细节blabla
vue3中引入的更新策略:静态节点标记等
vdom中diff算法的简易实现
以下代码只是帮助大家理解diff算法的原理和流程
- 将
vdom转化为真实dom:
const createElement = (vnode) => {
let tag = vnode.tag;
let attrs = vnode.attrs || {};
let children = vnode.children || [];
if(!tag) {
return null;
}
//创建元素
let elem = document.createElement(tag);
//属性
let attrName;
for (attrName in attrs) {
if(attrs.hasOwnProperty(attrName)) {
elem.setAttribute(attrName, attrs[attrName]);
}
}
//子元素
children.forEach(childVnode => {
//给elem添加子元素
elem.appendChild(createElement(childVnode));
})
//返回真实的dom元素
return elem;
}- 用简易
diff算法做更新操作
function updateChildren(vnode, newVnode) {
let children = vnode.children || [];
let newChildren = newVnode.children || [];
children.forEach((childVnode, index) => {
let newChildVNode = newChildren[index];
if(childVnode.tag === newChildVNode.tag) {
//深层次对比, 递归过程
updateChildren(childVnode, newChildVNode);
} else {
//替换
replaceNode(childVnode, newChildVNode);
}
})
}</details>
什么是递归组件?举个例子说明下?
分析
递归组件我们用的比较少,但是在Tree、Menu这类组件中会被用到。
体验
组件通过组件名称引用它自己,这种情况就是递归组件
<template>
<li>
<div> {{ model.name }}</div>
<ul v-show="isOpen" v-if="isFolder">
<!-- 注意这里:组件递归渲染了它自己 -->
<TreeItem
class="item"
v-for="model in model.children"
:model="model">
</TreeItem>
</ul>
</li>
<script>
export default {
name: 'TreeItem',
// ...
}
</script>回答范例
- 如果某个组件通过组件名称引用它自己,这种情况就是递归组件。
- 实际开发中类似
Tree、Menu这类组件,它们的节点往往包含子节点,子节点结构和父节点往往是相同的。这类组件的数据往往也是树形结构,这种都是使用递归组件的典型场景。 - 使用递归组件时,由于我们并未也不能在组件内部导入它自己,所以设置组件
name属性,用来查找组件定义,如果使用SFC,则可以通过SFC文件名推断。组件内部通常也要有递归结束条件,比如model.children这样的判断。 - 查看生成渲染函数可知,递归组件查找时会传递一个布尔值给
resolveComponent,这样实际获取的组件就是当前组件本身
原理
递归组件编译结果中,获取组件时会传递一个标识符 _resolveComponent("Comp", true)
const _component_Comp = _resolveComponent("Comp", true)就是在传递maybeSelfReference
export function resolveComponent(
name: string,
maybeSelfReference?: boolean
): ConcreteComponent | string {
return resolveAsset(COMPONENTS, name, true, maybeSelfReference) || name
}resolveAsset中最终返回的是组件自身:
if (!res && maybeSelfReference) {
// fallback to implicit self-reference
return Component
}对keep-alive的理解,它是如何实现的,具体缓存的是什么?
如果需要在组件切换的时候,保存一些组件的状态防止多次渲染,就可以使用 keep-alive 组件包裹需要保存的组件。
(1)keep-alive
keep-alive有以下三个属性:
- include 字符串或正则表达式,只有名称匹配的组件会被匹配;
- exclude 字符串或正则表达式,任何名称匹配的组件都不会被缓存;
- max 数字,最多可以缓存多少组件实例。
注意:keep-alive 包裹动态组件时,会缓存不活动的组件实例。
主要流程
- 判断组件 name ,不在 include 或者在 exclude 中,直接返回 vnode,说明该组件不被缓存。
- 获取组件实例 key ,如果有获取实例的 key,否则重新生成。
- key生成规则,cid +"∶∶"+ tag ,仅靠cid是不够的,因为相同的构造函数可以注册为不同的本地组件。
- 如果缓存对象内存在,则直接从缓存对象中获取组件实例给 vnode ,不存在则添加到缓存对象中。 5.最大缓存数量,当缓存组件数量超过 max 值时,清除 keys 数组内第一个组件。
(2)keep-alive 的实现
const patternTypes: Array<Function> = [String, RegExp, Array] // 接收:字符串,正则,数组
export default {
name: 'keep-alive',
abstract: true, // 抽象组件,是一个抽象组件:它自身不会渲染一个 DOM 元素,也不会出现在父组件链中。
props: {
include: patternTypes, // 匹配的组件,缓存
exclude: patternTypes, // 不去匹配的组件,不缓存
max: [String, Number], // 缓存组件的最大实例数量, 由于缓存的是组件实例(vnode),数量过多的时候,会占用过多的内存,可以用max指定上限
},
created() {
// 用于初始化缓存虚拟DOM数组和vnode的key
this.cache = Object.create(null)
this.keys = []
},
destroyed() {
// 销毁缓存cache的组件实例
for (const key in this.cache) {
pruneCacheEntry(this.cache, key, this.keys)
}
},
mounted() {
// prune 削减精简[v.]
// 去监控include和exclude的改变,根据最新的include和exclude的内容,来实时削减缓存的组件的内容
this.$watch('include', (val) => {
pruneCache(this, (name) => matches(val, name))
})
this.$watch('exclude', (val) => {
pruneCache(this, (name) => !matches(val, name))
})
},
}render函数:
- 会在 keep-alive 组件内部去写自己的内容,所以可以去获取默认 slot 的内容,然后根据这个去获取组件
- keep-alive 只对第一个组件有效,所以获取第一个子组件。
- 和 keep-alive 搭配使用的一般有:动态组件 和router-view
render () {
//
function getFirstComponentChild (children: ?Array<VNode>): ?VNode {
if (Array.isArray(children)) {
for (let i = 0; i < children.length; i++) {
const c = children[i]
if (isDef(c) && (isDef(c.componentOptions) || isAsyncPlaceholder(c))) {
return c
}
}
}
}
const slot = this.$slots.default // 获取默认插槽
const vnode: VNode = getFirstComponentChild(slot)// 获取第一个子组件
const componentOptions: ?VNodeComponentOptions = vnode && vnode.componentOptions // 组件参数
if (componentOptions) { // 是否有组件参数
// check pattern
const name: ?string = getComponentName(componentOptions) // 获取组件名
const { include, exclude } = this
if (
// not included
(include && (!name || !matches(include, name))) ||
// excluded
(exclude && name && matches(exclude, name))
) {
// 如果不匹配当前组件的名字和include以及exclude
// 那么直接返回组件的实例
return vnode
}
const { cache, keys } = this
// 获取这个组件的key
const key: ?string = vnode.key == null
// same constructor may get registered as different local components
// so cid alone is not enough (#3269)
? componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '')
: vnode.key
if (cache[key]) {
// LRU缓存策略执行
vnode.componentInstance = cache[key].componentInstance // 组件初次渲染的时候componentInstance为undefined
// make current key freshest
remove(keys, key)
keys.push(key)
// 根据LRU缓存策略执行,将key从原来的位置移除,然后将这个key值放到最后面
} else {
// 在缓存列表里面没有的话,则加入,同时判断当前加入之后,是否超过了max所设定的范围,如果是,则去除
// 使用时间间隔最长的一个
cache[key] = vnode
keys.push(key)
// prune oldest entry
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode)
}
}
// 将组件的keepAlive属性设置为true
vnode.data.keepAlive = true // 作用:判断是否要执行组件的created、mounted生命周期函数
}
return vnode || (slot && slot[0])
}keep-alive 具体是通过 cache 数组缓存所有组件的 vnode 实例。当 cache 内原有组件被使用时会将该组件 key 从 keys 数组中删除,然后 push 到 keys数组最后,以便清除最不常用组件。
实现步骤:
- 获取 keep-alive 下第一个子组件的实例对象,通过他去获取这个组件的组件名
- 通过当前组件名去匹配原来 include 和 exclude,判断当前组件是否需要缓存,不需要缓存,直接返回当前组件的实例vNode
- 需要缓存,判断他当前是否在缓存数组里面:
- 存在,则将他原来位置上的 key 给移除,同时将这个组件的 key 放到数组最后面(LRU)
- 不存在,将组件 key 放入数组,然后判断当前 key数组是否超过 max 所设置的范围,超过,那么削减未使用时间最长的一个组件的 key
- 最后将这个组件的 keepAlive 设置为 true
(3)keep-alive 本身的创建过程和 patch 过程
缓存渲染的时候,会根据 vnode.componentInstance(首次渲染 vnode.componentInstance 为 undefined) 和 keepAlive 属性判断不会执行组件的 created、mounted 等钩子函数,而是对缓存的组件执行 patch 过程∶ 直接把缓存的 DOM 对象直接插入到目标元素中,完成了数据更新的情况下的渲染过程。
首次渲染
- 组件的首次渲染∶判断组件的 abstract 属性,才往父组件里面挂载 DOM
// core/instance/lifecycle
function initLifecycle (vm: Component) {
const options = vm.$options
// locate first non-abstract parent
let parent = options.parent
if (parent && !options.abstract) { // 判断组件的abstract属性,才往父组件里面挂载DOM
while (parent.$options.abstract && parent.$parent) {
parent = parent.$parent
}
parent.$children.push(vm)
}
vm.$parent = parent
vm.$root = parent ? parent.$root : vm
vm.$children = []
vm.$refs = {}
vm._watcher = null
vm._inactive = null
vm._directInactive = false
vm._isMounted = false
vm._isDestroyed = false
vm._isBeingDestroyed = false
}- 判断当前 keepAlive 和 componentInstance 是否存在来判断是否要执行组件 prepatch 还是执行创建 componentlnstance
// core/vdom/create-component
init (vnode: VNodeWithData, hydrating: boolean): ?boolean {
if (
vnode.componentInstance &&
!vnode.componentInstance._isDestroyed &&
vnode.data.keepAlive
) { // componentInstance在初次是undefined!!!
// kept-alive components, treat as a patch
const mountedNode: any = vnode // work around flow
componentVNodeHooks.prepatch(mountedNode, mountedNode) // prepatch函数执行的是组件更新的过程
} else {
const child = vnode.componentInstance = createComponentInstanceForVnode(
vnode,
activeInstance
)
child.$mount(hydrating ? vnode.elm : undefined, hydrating)
}
},prepatch 操作就不会在执行组件的 mounted 和 created 生命周期函数,而是直接将 DOM 插入
(4)LRU (least recently used)缓存策略
LRU 缓存策略∶ 从内存中找出最久未使用的数据并置换新的数据。
LRU(Least rencently used)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是 "如果数据最近被访问过,那么将来被访问的几率也更高"。 最常见的实现是使用一个链表保存缓存数据,详细算法实现如下∶
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 链表满的时候,将链表尾部的数据丢弃。
mixin 和 mixins 区别
mixin 用于全局混入,会影响到每个组件实例,通常插件都是这样做初始化的。
Vue.mixin({
beforeCreate() {
// ...逻辑 // 这种方式会影响到每个组件的 beforeCreate 钩子函数
},
});虽然文档不建议在应用中直接使用 mixin,但是如果不滥用的话也是很有帮助的,比如可以全局混入封装好的 ajax 或者一些工具函数等等。
mixins 应该是最常使用的扩展组件的方式了。如果多个组件中有相同的业务逻辑,就可以将这些逻辑剥离出来,通过 mixins 混入代码,比如上拉下拉加载数据这种逻辑等等。
另外需要注意的是 mixins 混入的钩子函数会先于组件内的钩子函数执行,并且在遇到同名选项的时候也会有选择性的进行合并。
extend 有什么作用
这个 API 很少用到,作用是扩展组件生成一个构造器,通常会与 $mount 一起使用。
// 创建组件构造器
let Component = Vue.extend({ template: "<div>test</div>" });
// 挂载到 #app 上new Component().$mount('#app')
// 除了上面的方式,还可以用来扩展已有的组件
let SuperComponent = Vue.extend(Component);
new SuperComponent({
created() {
console.log(1);
},
});
new SuperComponent().$mount("#app");Vue的性能优化有哪些
(1)编码阶段
- 尽量减少data中的数据,data中的数据都会增加getter和setter,会收集对应的watcher
- v-if和v-for不能连用
- 如果需要使用v-for给每项元素绑定事件时使用事件代理
- SPA 页面采用keep-alive缓存组件
- 在更多的情况下,使用v-if替代v-show
- key保证唯一
- 使用路由懒加载、异步组件
- 防抖、节流
- 第三方模块按需导入
- 长列表滚动到可视区域动态加载
- 图片懒加载
(2)SEO优化
- 预渲染
- 服务端渲染SSR
(3)打包优化
- 压缩代码
- Tree Shaking/Scope Hoisting
- 使用cdn加载第三方模块
- 多线程打包happypack
- splitChunks抽离公共文件
- sourceMap优化
(4)用户体验
- 骨架屏
- PWA
- 还可以使用缓存(客户端缓存、服务端缓存)优化、服务端开启gzip压缩等。
了解nextTick吗?
异步方法,异步渲染最后一步,与JS事件循环联系紧密。主要使用了宏任务微任务(setTimeout、promise那些),定义了一个异步方法,多次调用nextTick会将方法存入队列,通过异步方法清空当前队列。
谈谈你对MVVM的理解
为什么要有这些模式,目的:职责划分、分层(将Model层、View层进行分类)借鉴后端思想,对于前端而已,就是如何将数据同步到页面上
MVC模式 代表:Backbone + underscore + jquery

- 传统的
MVC指的是,用户操作会请求服务端路由,路由会调用对应的控制器来处理,控制器会获取数据。将结果返回给前端,页面重新渲染 MVVM:传统的前端会将数据手动渲染到页面上,MVVM模式不需要用户收到操作dom元素,将数据绑定到viewModel层上,会自动将数据渲染到页面中,视图变化会通知viewModel层 更新数据。ViewModel就是我们MVVM模式中的桥梁
MVVM模式 映射关系的简化,隐藏了controller
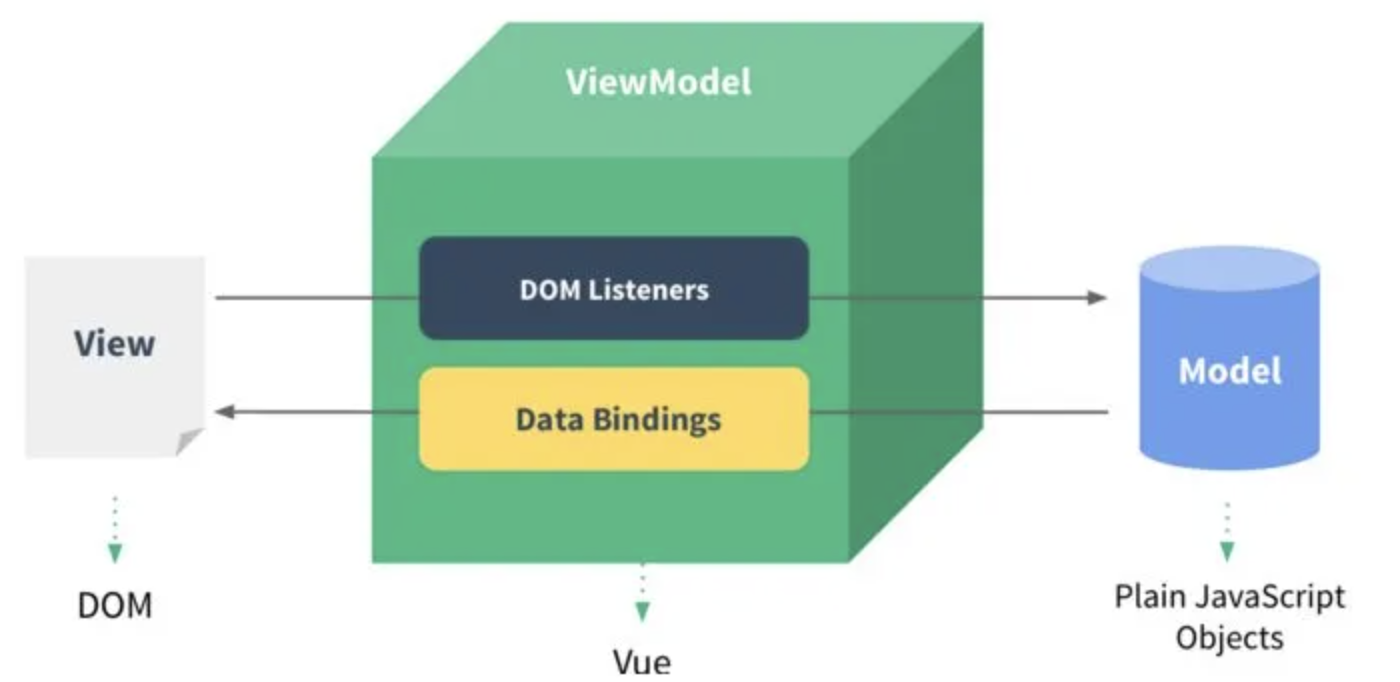
MVVM是Model-View-ViewModel缩写,也就是把MVC中的Controller演变成ViewModel。Model层代表数据模型,View代表UI组件,ViewModel是View和Model层的桥梁,数据会绑定到viewModel层并自动将数据渲染到页面中,视图变化的时候会通知viewModel层更新数据。
Model: 代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑。我们可以把Model称为数据层,因为它仅仅关注数据本身,不关心任何行为View: 用户操作界面。当ViewModel对Model进行更新的时候,会通过数据绑定更新到ViewViewModel: 业务逻辑层,View需要什么数据,ViewModel要提供这个数据;View有某些操作,ViewModel就要响应这些操作,所以可以说它是Model for View.
总结 : MVVM模式简化了界面与业务的依赖,解决了数据频繁更新。MVVM 在使用当中,利用双向绑定技术,使得 Model 变化时,ViewModel 会自动更新,而 ViewModel 变化时,View 也会自动变化。
我们以下通过一个 Vue 实例来说明 MVVM 的具体实现
<!-- View 层 -->
<div id="app">
<p>{{message}}</p>
<button v-on:click="showMessage()">Click me</button>
</div>// ViewModel 层
var app = new Vue({
el: '#app',
data: { // 用于描述视图状态
message: 'Hello Vue!',
},
methods: { // 用于描述视图行为
showMessage(){
let vm = this;
alert(vm.message);
}
},
created(){
let vm = this;
// Ajax 获取 Model 层的数据
ajax({
url: '/your/server/data/api',
success(res){
vm.message = res;
}
});
}
})// Model 层
{
"url": "/your/server/data/api",
"res": {
"success": true,
"name": "test",
"domain": "www.baidu.com"
}
}watch 原理
watch 本质上是为每个监听属性 setter 创建了一个 watcher,当被监听的属性更新时,调用传入的回调函数。常见的配置选项有 deep 和 immediate,对应原理如下
deep:深度监听对象,为对象的每一个属性创建一个watcher,从而确保对象的每一个属性更新时都会触发传入的回调函数。主要原因在于对象属于引用类型,单个属性的更新并不会触发对象setter,因此引入deep能够很好地解决监听对象的问题。同时也会引入判断机制,确保在多个属性更新时回调函数仅触发一次,避免性能浪费。immediate:在初始化时直接调用回调函数,可以通过在created阶段手动调用回调函数实现相同的效果
Vue-router 除了 router-link 怎么实现跳转
声明式导航
<router-link to="/about">Go to About</router-link>编程式导航
// literal string path
router.push('/users/1')
// object with path
router.push({ path: '/users/1' })
// named route with params to let the router build the url
router.push({ name: 'user', params: { username: 'test' } })回答范例
vue-router导航有两种方式:声明式导航和编程方式导航- 声明式导航方式使用
router-link组件,添加to属性导航;编程方式导航更加灵活,可传递调用router.push(),并传递path字符串或者RouteLocationRaw对象,指定path、name、params等信息 - 如果页面中简单表示跳转链接,使用
router-link最快捷,会渲染一个a标签;如果页面是个复杂的内容,比如商品信息,可以添加点击事件,使用编程式导航 - 实际上内部两者调用的导航函数是一样的
Vue实例挂载的过程中发生了什么
简单
TIP
分析
挂载过程完成了最重要的两件事:
- 初始化
- 建立更新机制
把这两件事说清楚即可!
回答范例
- 挂载过程指的是
app.mount()过程,这个过程中整体上做了两件事:初始化和建立更新机制 - 初始化会创建组件实例、初始化组件状态,创建各种响应式数据
- 建立更新机制这一步会立即执行一次组件更新函数,这会首次执行组件渲染函数并执行
patch将前面获得vnode转换为dom;同时首次执行渲染函数会创建它内部响应式数据之间和组件更新函数之间的依赖关系,这使得以后数据变化时会执行对应的更新函数
来看一下源码,在src/core/instance/index.js 中
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}可以看到 Vue 只能通过 new 关键字初始化,然后会调用 this._init 方法, 该方法在 src/core/instance/init.js 中定义
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// a uid
vm._uid = uid++
let startTag, endTag
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
startTag = `vue-perf-start:${vm._uid}`
endTag = `vue-perf-end:${vm._uid}`
mark(startTag)
}
// a flag to avoid this being observed
vm._isVue = true
// merge options
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor),
options || {},
vm
)
}
/* istanbul ignore else */
if (process.env.NODE_ENV !== 'production') {
initProxy(vm)
} else {
vm._renderProxy = vm
}
// expose real self
vm._self = vm
initLifecycle(vm)
initEvents(vm)
initRender(vm)
callHook(vm, 'beforeCreate')
initInjections(vm) // resolve injections before data/props
initState(vm)
initProvide(vm) // resolve provide after data/props
callHook(vm, 'created')
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
vm._name = formatComponentName(vm, false)
mark(endTag)
measure(`vue ${vm._name} init`, startTag, endTag)
}
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}
Vue初始化主要就干了几件事情,合并配置,初始化生命周期,初始化事件中心,初始化渲染,初始化 data、props、computed、watcher等
子组件可以直接改变父组件的数据吗?
子组件不可以直接改变父组件的数据。这样做主要是为了维护父子组件的单向数据流。每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值。如果这样做了,Vue 会在浏览器的控制台中发出警告。
Vue提倡单向数据流,即父级 props 的更新会流向子组件,但是反过来则不行。这是为了防止意外的改变父组件状态,使得应用的数据流变得难以理解,导致数据流混乱。如果破坏了单向数据流,当应用复杂时,debug 的成本会非常高。
只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件修改。
computed 和 watch 的区别和运用的场景?
computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值;
watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
运用场景:
- 当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;
- 当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
子组件可以直接改变父组件的数据么,说明原因
这是一个实践知识点,组件化开发过程中有个单项数据流原则,不在子组件中修改父组件是个常识问题
思路
- 讲讲单项数据流原则,表明为何不能这么做
- 举几个常见场景的例子说说解决方案
- 结合实践讲讲如果需要修改父组件状态应该如何做
回答范例
- 所有的
prop都使得其父子之间形成了一个单向下行绑定:父级prop的更新会向下流动到子组件中,但是反过来则不行。这样会防止从子组件意外变更父级组件的状态,从而导致你的应用的数据流向难以理解。另外,每次父级组件发生变更时,子组件中所有的prop都将会刷新为最新的值。这意味着你不应该在一个子组件内部改变prop。如果你这样做了,Vue会在浏览器控制台中发出警告
const props = defineProps(['foo'])
// ❌ 下面行为会被警告, props是只读的!
props.foo = 'bar'- 实际开发过程中有两个场景会想要修改一个属性:
这个 prop 用来传递一个初始值;这个子组件接下来希望将其作为一个本地的 prop 数据来使用。 在这种情况下,最好定义一个本地的 data,并将这个 prop 用作其初始值:
const props = defineProps(['initialCounter'])
const counter = ref(props.initialCounter)这个 prop 以一种原始的值传入且需要进行转换。 在这种情况下,最好使用这个 prop 的值来定义一个计算属性:
const props = defineProps(['size'])
// prop变化,计算属性自动更新
const normalizedSize = computed(() => props.size.trim().toLowerCase())- 实践中如果确实想要改变父组件属性应该
emit一个事件让父组件去做这个变更。注意虽然我们不能直接修改一个传入的对象或者数组类型的prop,但是我们还是能够直接改内嵌的对象或属性