

实现并查集数据结构的技术指南
并查集(Disjoint Set Union,简称并查集)是一种常用的数据结构,用于管理元素之间的等价关系。它主要支持两种操作:合并(Union)和查找(Find)。并查集通常用于解决各种问题,如图论中的连通性问题、最小生成树算法中的边的选择等。
基本思想
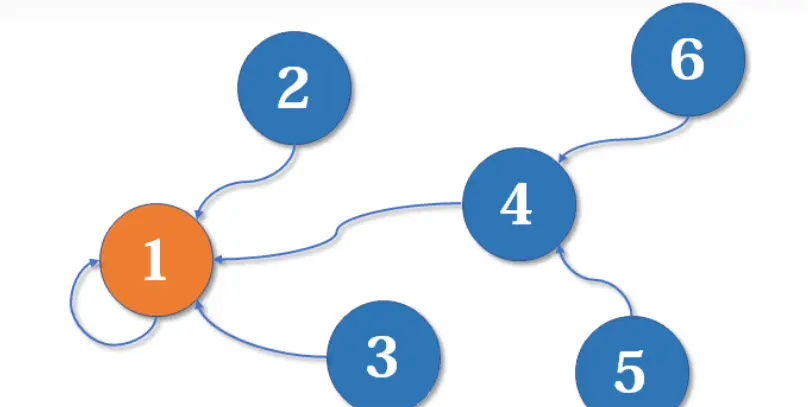
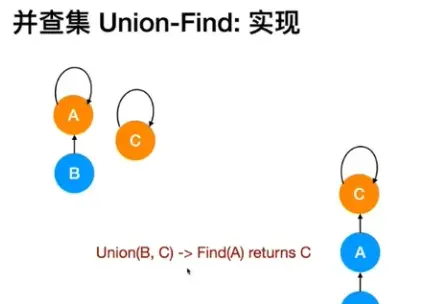
并查集通过维护一棵树来表示集合,其中每个节点都指向其父节点,根节点指向自身。在实际实现中,可以使用数组来表示这棵树,数组的索引表示元素,数组的值表示指向的父节点。
实现步骤
- 初始化: 初始化时,每个元素都是独立的集合,即每个元素都是一个单独的树,且每个元素的父节点指向自身。
- 查找(Find): 查找操作用于确定元素所属的集合。通过不断向上查找父节点,直到找到根节点,即自身指向自身的节点,确定元素所在的集合。
- 合并(Union): 合并操作用于将两个集合合并为一个集合。通过找到两个元素所在集合的根节点,将其中一个根节点的父节点指向另一个根节点,从而实现集合的合并。

代码实现
下面是并查集的简单实现,使用了路径压缩和按秩合并的优化:
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.rank = [0] * n
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # 路径压缩
return self.parent[x]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
示例
# 创建并查集对象,包含5个元素
uf = UnionFind(5)
# 合并元素1和元素2所在的集合
uf.union(1, 2)
# 合并元素3和元素4所在的集合
uf.union(3, 4)
# 检查元素1和元素2是否属于同一个集合
print(uf.find(1) == uf.find(2)) # 输出:True
# 检查元素1和元素3是否属于同一个集合
print(uf.find(1) == uf.find(3)) # 输出:False
进一步优化与应用
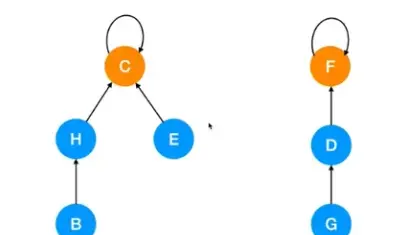
路径压缩
在查找操作中,路径压缩可以进一步提高并查集的效率。路径压缩的核心思想是在查找过程中,将节点直接连接到根节点,以减少后续查找的时间复杂度。路径压缩可以通过递归或迭代实现。
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.rank = [0] * n
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # 路径压缩
return self.parent[x]
按秩合并
按秩合并的思想是,始终将较小的树合并到较大的树中,以减少树的深度,进而降低查找操作的复杂度。在合并操作中,需要比较两个根节点的秩(即树的高度),并将秩较小的根节点连接到秩较大的根节点上。
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.rank = [0] * n
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
应用示例:判断图中连通分量的数量
并查集常用于图论中的连通性问题。下面是一个示例,通过并查集来判断无向图中连通分量的数量:
def count_components(n, edges):
uf = UnionFind(n)
for edge in edges:
uf.union(edge[0], edge[1])
components = set()
for i in range(n):
components.add(uf.find(i))
return len(components)
用并查集解决区域填充问题。假设有一个二维网格,其中包含了若干个岛屿(由’1’表示)和海洋(由’0’表示),岛屿被海洋包围。现在需要对每个岛屿进行区域填充,使得每个岛屿都被水域包围。以下是代码示例:
class UnionFind:
def __init__(self, n):
self.parent = [i for i in range(n)]
self.rank = [0] * n
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # 路径压缩
return self.parent[x]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] < self.rank[root_y]:
self.parent[root_x] = root_y
elif self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_y] = root_x
self.rank[root_x] += 1
def fill_surrounded_regions(grid):
if not grid:
return grid
m, n = len(grid), len(grid[0])
uf = UnionFind(m * n + 1) # 最后一个节点表示海洋
for i in range(m):
for j in range(n):
if grid[i][j] == '0':
uf.union(i * n + j, m * n) # 将海洋连接到一个虚拟节点
else:
if i > 0 and grid[i - 1][j] == '1':
uf.union(i * n + j, (i - 1) * n + j)
if i < m - 1 and grid[i + 1][j] == '1':
uf.union(i * n + j, (i + 1) * n + j)
if j > 0 and grid[i][j - 1] == '1':
uf.union(i * n + j, i * n + j - 1)
if j < n - 1 and grid[i][j + 1] == '1':
uf.union(i * n + j, i * n + j + 1)
for i in range(m):
for j in range(n):
if uf.find(i * n + j) != uf.find(m * n):
grid[i][j] = 'X'
return grid
# 示例
grid = [
["1", "1", "1", "1", "0"],
["1", "1", "0", "1", "0"],
["1", "1", "0", "0", "0"],
["0", "0", "0", "0", "0"]
]
filled_grid = fill_surrounded_regions(grid)
for row in filled_grid:
print(" ".join(row))
这个代码示例演示了如何使用并查集来解决区域填充问题。通过判断岛屿之间的连通性,并将与海洋相连的岛屿合并到一起,然后将不与海洋相连的岛屿标记为水域。
并查集的应用领域
除了在图论中的连通性问题之外,并查集还在各种领域得到广泛应用,其中包括但不限于:
1. 算法竞赛
在算法竞赛中,例如ACM/ICPC、Codeforces等比赛中,并查集常被用来解决一些关于连通性的问题,比如判断图的连通性、求解最小生成树、最短路径等。并查集的高效实现可以帮助竞赛选手在有限的时间内解决问题。
2. 图像处理
在图像处理中,像素的连通性是一个重要的概念。并查集可以用来判断图像中的像素是否连通,从而进行图像分割、边缘检测等操作。例如,可以利用并查集来合并相邻的像素,将它们视为同一连通分量。
3. 社交网络分析
在社交网络分析中,常常需要判断社交网络中的用户之间是否存在关系,以及他们之间的关系强度。并查集可以用来管理用户之间的关系,快速判断两个用户是否属于同一社交圈子,进而进行社交网络分析和推荐系统的优化。
4. 数据库系统
在数据库系统中,常常需要处理大量的数据并对其进行关联。并查集可以用来管理数据之间的关系,例如在数据库中实现集合操作、聚类分析等。并查集的高效实现可以加速数据库查询和数据处理的速度。

5. 任务调度与资源分配
在任务调度和资源分配领域,经常需要解决资源之间的依赖关系和任务之间的调度顺序。并查集可以用来管理任务和资源之间的关系,快速判断任务之间的依赖关系,进而进行任务调度和资源分配的优化。
总结
本文介绍了并查集数据结构的基本原理、实现方法以及优化技巧,并提供了代码示例展示了其在实际问题中的应用。首先,我们了解了并查集的基本操作:合并(Union)和查找(Find),以及如何使用数组来表示并查集中的树结构。随后,我们介绍了路径压缩和按秩合并两种优化技巧,用于提高并查集的效率。通过路径压缩,我们可以减少查找操作的时间复杂度;而按秩合并则可以降低树的深度,进而减少查找和合并操作的时间复杂度。
在代码示例部分,我们展示了如何实现一个简单的并查集类,并给出了一个应用示例:使用并查集解决区域填充问题。在这个示例中,我们通过并查集来判断岛屿之间的连通性,然后对每个岛屿进行区域填充,确保每个岛屿都被水域包围。这个示例展示了并查集在图论和图像处理等领域的应用。
综上所述,虽然并查集是一种简单的数据结构,但它在解决各种实际问题中具有广泛的应用。通过合并和查找操作,可以高效地管理元素之间的关系,解决连通性、区域填充等问题。希望本文能够帮助读者更深入地理解并查集,并在实际工作和学习中发挥作用。
原文链接:https://juejin.cn/post/7359077652445921330 作者:申公豹本豹