
——「高性能MYSQL」读书笔记(第十一章)
《高性能****MYSQL》
MYSQL经典书籍,常读常新。
什么是可扩展?
- 性能 vs 容量 vs 可扩展性
性能 = 响应时间
系统真实容量=在保证可接受的性能的情况下,能够达到的吞吐量。
容量和可扩展性并不依赖于性能;即使系统性能不是很高也可以具备可扩展性。
- 可扩展性的定义
能够通过增加资源来提升容量(处理负载)的能力;负载有多个角度:数据量,用户量,用户活跃度,相关数据集大小。
当增加资源以处理负载和增加容量时,系统能够获得的投资产出率(ROI)。
-
通常,系统增长无法带来等同的收益(非线性扩展)—- USL扩展理论
-
构建高可扩展性系统的重要原则:在系统内尽量避免串行化和交互。
扩展MYSQL
规划可扩展性
-
估算需要承担的负载,尤其是最大负载峰值
-
了解计划日程表,根据实际情况选择合适的方案
-
如果系统某个部分失效,对分摊负载的其他部分有什么影响,是否预留额外的系统容量
-
在选择可扩展方案前,优先进行性能优化和硬件升级
垂直扩展(向上扩展)
购买更多性能强悍的硬件
水平扩展(向外扩展)
复制、拆分、分片sharding
复制
将数据复制到多个服务器,使用备库处理读查询。
适用于读为主的应用;有重复缓存的问题 – Ch10
拆分
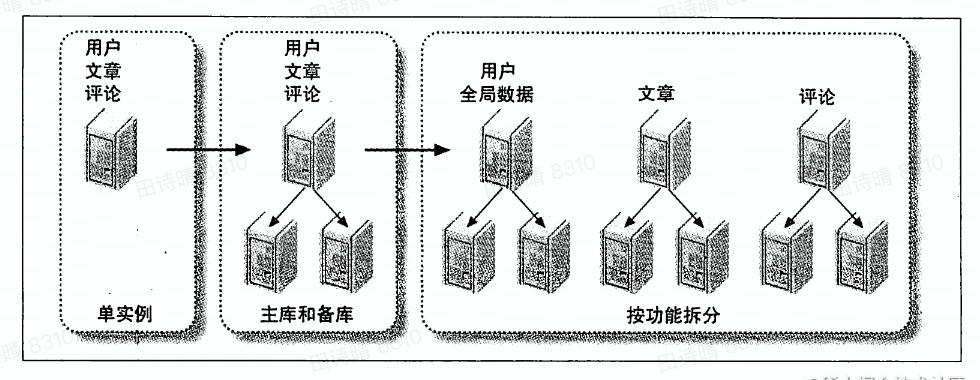
将工作负载分布到多个”节点” –> 垂直分库
节点(node): 在MYSQL架构中,指一个功能部件,ie 一台服务器。对于能够故障转移的冗余系统,一个节点有多个服务器:一个主一主复制双机结构、一个主库和多个备库等,一个节点内的所有服务器拥有相同的数据
按功能拆分:将应用内彼此不关联的功能分离,将节点分配给不同的功能区域,每个节点只包含特定功能区域的数据
不能通过功能划分来无限的进行扩展。
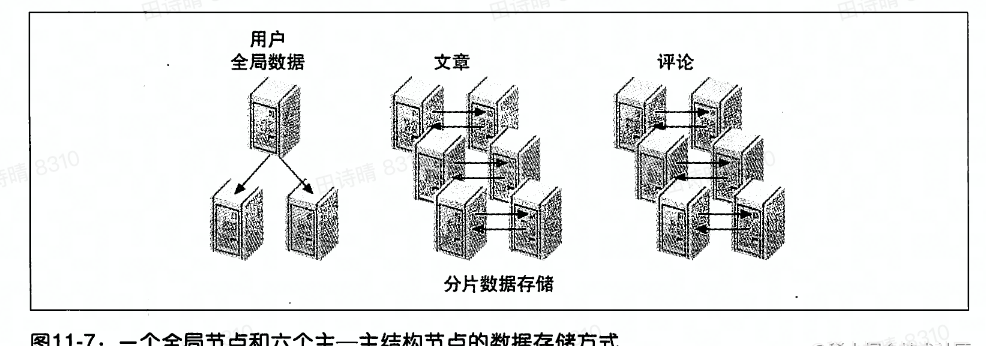
分片
将数据分割,并存储到不同节点。–> 水平分库
-
扩展大型mysql应用最通用和成功的方法;
-
某些全局数据不分片,单独存储;对将会增长到十分庞大的数据进行分片;
-
在应用设计初期进行必要的分片设计
-
通过数据库访问抽象层,降低应用和分片数据存储之间通信的复杂度
复制 -> 按功能划分 -> 分片

如非必要,尽量不分片。尝试性能调优、更好的应用或数据库设计(应用拆分、增加缓存)、更好的服务器、升级MYSQL、读写分离来提升系统负载瓶颈。
分片
选择分区键
分区键决定了每一行分配到哪一个分片中;通常使用数据库中一个非常重要的实体的主键作为分区键,比如用户ID。
(Mysql NDB Cluster 使用每个表的主键哈希来分片,这样可以简化判断数据存储在何处的操作,但却可能增加获取数据的难度,具体取决于需要什么数据以及是否知道主键)
使用实体一关系图确定分区键;尽量避免跨分片查询,分片足够小,数据划分尽量均匀。

复杂的应用存在多个不同维度的查询,可以有多个分区健,并设计数据冗余存储—冗余全量或冗余关系表。
跨分片查询
有一些场景需要查询多个分片并进行聚合或关联操作,性能与分片内查相比会下降很多,可以借助汇总表。
可以将全部数据冗余存储至ES,由ES处理复杂的查询。(基于流程实例id分片后,查询用户任务列表需要遍历所有分片;由任务中心处理列表查询,解决的跨分片查询问题)
部署分片
-
分片的库名表名都一样
-
分片的库名一样表名不一样,每个表名都包含分片号
-
分片的库名不一样表名一样,每个库名都包含分片号
-
分片的库名表名都不一样,库名表名都包含分片号 –> 推荐做法
分配数据
分片足够小但不过小,在单个节点上存储多个分片,这样数据备份/恢复、更改表结构、平衡节点的分片会更容易。
| 固定分配 | 动态分配 | 显式分配 | |
|---|---|---|---|
| 分区函数 | 仅依赖分区健值,eg 哈希函数、取模 | 数据分片映射表 | 新数据写入时,选择目标分片,把分片号写到ID中 |
| 优点 | 简单,开销低 | 更细致地控制数据存储位置、便于分配均衡可以建立多层次分片策略,并利用分片亲和性,减少跨分片查询问题 | ID包含分区健信息 |
| 缺点 | 难以平衡不同分片的负载无法自定义数据分配位置,不能进行热点数据转移难以修改分片策略 | 开销大,通常要使用分布式缓存 | 已有的数据难以实现分片方式是固定的,难以平衡分片间的负载 |
| 可以混合使用两种分配方法,eg 通过哈希函数将数据分配到桶中,再将桶动态映射到分片上 | 正常情况下不推荐 | ||
均衡分片数据
可以在分片间移动数据来实现负载均衡,但应尽量避免。
一个比较好的方式是使用动态分配策略,并将新数据随机分配到分片中,通过分片的标志位控制是否将数据写入分片。
生成全局唯一ID
分片数据存储需要在多台机器上生成全局唯一ID,可以采取以下方法:
-
使用auto_increment_increment和auto_increment_offset
-
使用全局节点中创建的有自增ID的表;可以请求一批数字,用完再申请。有单点问题。
-
使用缓存的incr方法。缓存服务重启时,需要确定所有分片中的最大值并初始化缓存值
-
使用分片号+自增数的复合值
-
使用GUID
分片工具
将数据源隐藏数据库抽象层中
-
连接到正确的分片并执行查询。
-
分布式一致性校验。
-
跨分片的结果集聚合
-
跨分片关联操作
-
锁和事务管理
-
创建新的数据分片并重新平衡分片
向内扩展
- 归档/清理不需要的数据,减少数据量
需要注意:
对应用不造成影响:使用索引,一次删除适量的数据,必要时让步于事务处理;
保证数据一致性:设计相关联的表的归档顺序
避免数据丢失:确保在存储目标上保存成功后再从源表中删除
- 隔离活跃数据与非活跃数据,高效利用缓存。(分表、表分区、动态分片)
负载均衡
基本思路:在一个服务器集群中尽可能地平均负载量。
目的:
可扩展性:帮助实现读写分离扩展策略
高效性:高效利用资源
可用性:保证系统持续可用
透明性:对客户端透明
一致性:对于数据库事务、网站会话,将相关的查询指向同一个服务器,防止状态丢失
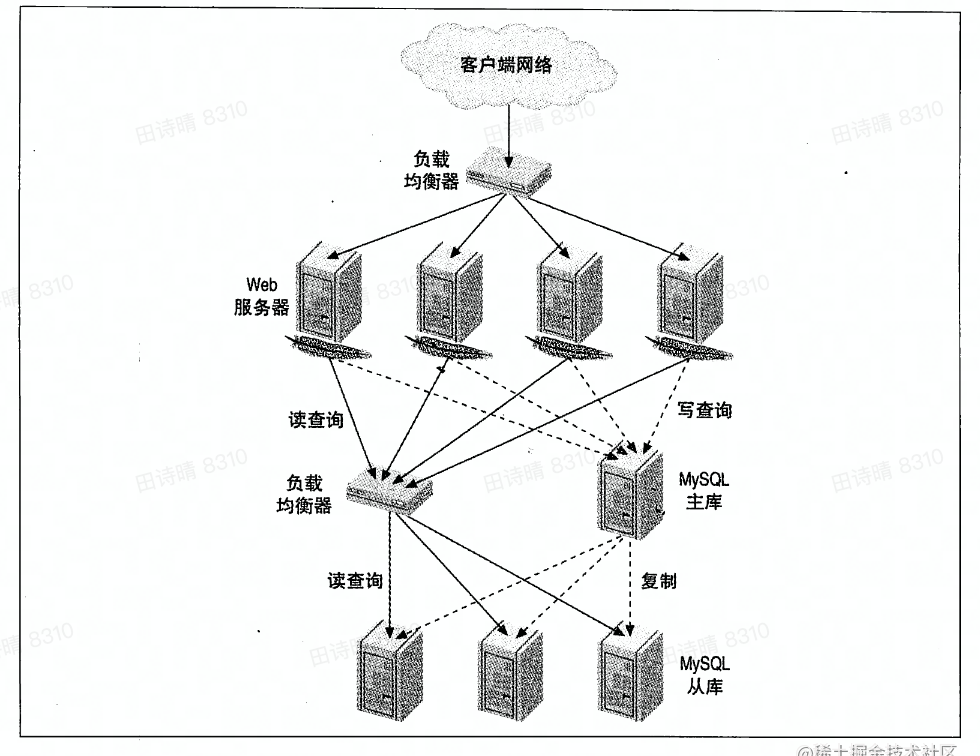
直接连接Mysql
应用为负载均衡做决策,确定数据查询分配到哪个服务器
读写分离:写操作 -> 主库,读操作 -> 主库/从库
读写分离的方法:
-
基于查询分离:将不能容忍脏数据的读全部分配到主库;对从库的利用率可能较低
-
基于脏数据分离:检查复制延迟以确定备库数据是否太旧
-
基于会话分离:在会话上设置标记位记录数据是否有更新,有更新则查主库;如果数据更新早且主从延迟低,可以查询从库
-
基于版本分离:跟踪对象的版本号/时间戳判断是否需要从主库读取最新数据
-
基于全局版本/会话分离:
-
提交事务后,show master status,缓存主库日志坐标作为对象/会话的版本号
-
连接从库查询时,show slave status,获取从库日志坐标与缓存比对
-
如果从库坐标更新,则读取从库数据
-
Tips: show slave status -> seconds_behind_master 并不能准确地用于监控延迟
修改应用配置
配置连接从库的服务器,处理没有写操作的请求。例如wfcapi read集群
修改DNS名 — 不推荐
将只读服务器的DNS名指定给从库;如果主从延迟高,将只读DNS名指定给主库。
转移IP地址
使用虚拟IP
中间件
使用中间件作为网络通信代理,将请求转发到指定的数据库服务器。
负载均衡****器
mysql 连接是TCP/IP连接,可以在mysql上使用多用途负载均衡器,但是有一些缺陷:
-
负载均衡器不知道mysql的真实负载,对所有的请求都一视同仁,以至于在分发请求时无法做到“负载均衡”
-
负载均衡器并不能把单个http会话发送的请求固定到一个mysql服务器上,所以缓存的作用非常有限
-
连接池和长连接可能会阻塞负载均衡器分发连接请求
-
负载均衡器不能够直接对MYSQL进行负载和健康检查
负载均衡****算法
随机、轮询、最少连接数、最快响应、哈希、权重。根据实际情况选择合适的算法。
加减服务器
在增加新服务器时,为避免由于没有缓存影响性能,先在新服务器上进行重放
确保每个服务器都保留高于“足够”的容量。
一主多备架构的负载均衡
对读进行分区来提高缓存效率
分解写查询,让从库执行一部分
全同步复制 vs 半同步复制
场景分析
除了第一章节外,每个小组同学根据阅读内容,分析当前系统中存在的一些不合理的问题,分析并提出对应升级方案。
流程引擎解决Mysql性能问题的过程与本书的推荐思路基本一致。迁移RDS前,通过拆解SQL和优化索引消除了大部分慢查询,并按照服务划分把相对独立的表拆分到独立的数据库 – 消息、社交套件数据库;将流程图加载到缓存中,并进行批量读写。目前通过读写分离来解决数据库瓶颈问题,并预先设计了分库分表方案。总而言之,在分库分表前,务必评估是否是更合适的方案。
如何评估是否需要分片库:site.bytedance.net/docs/5431/r…
读写分离方案
流程引擎分库分表方案
分区键选择:不分区、tenantId、processInstanceId
跨分片查询:用户任务列表查询切换到任务中心
原文链接:https://juejin.cn/post/7182920965213388856 作者:严厚宗