
最近做一个前端导出图片的需求,本来以为是一个很简单的场景,结果接连踩了好几个坑,记录汇总一下遇到的几个问题。
前端常见的下载场景一般有两种,一种是文件存在于cdn或云端,接口返回下载文件的url;一种是接口返回二进制文件流。
先说返回url的场景,此种场景文件一般比较小。
- 最简洁的方案:iframe下载
- iframe下载只适用于浏览器不能直接预览的文件类型,图片或者pdf等不适用
const downByFrame = (data) => { var url = data // 文件地址 var iframe = document.createElement('iframe') iframe.src = url iframe.style.display = 'none' iframe.onload = function () { document.body.removeAttribute(iframe) } document.body.appendChild(iframe) } - 最常用的方案:a标签下载
- a标签下载需要借助download属性
const downByA = (imageData) => { const linkImg = document.createElement('a') linkImg.style.display = 'none' linkImg.href = imageData linkImg.download = 'test.png' document.body.appendChild(linkImg) linkImg.click() }- download属性有同域限制和兼容性问题
- 在chrome浏览器中同域的链接地址可以下载,非同域的会跳转链接地址
- 大部分web端浏览器已支持该属性,部分移动端浏览器不支持,可查看mdn文档
downloadonly works for [same-origin URLs], or theblob:anddata:schemes.故可以利用blob对象和dataUrl来实现非同域的下载。
- Blob + a标签下载
const downByABolb = (imageData) => { fetch(imageData) .then((res) => { return res.blob() }) .then((blob) => { return URL.createObjectURL(blob) }) .then((urlBolb) => { return downByA(urlBolb) }) }- 考虑到fetch的兼容性问题,使用XMLHttpRequest还是最常用的写法
const downByBlob = (imageData) => { const xhr = new XMLHttpRequest() xhr.open('get', imageData) // 设置responseType xhr.responseType = 'blob' xhr.send() xhr.onload = function () { if (this.status === 200 || this.status === 304) { // 或者xhr的请求不设置responseType,在返回结果后利用下面的代码转换成blob对象 // const blob = new Blob([this.response], { type: xhr.getResponseHeader('Content-Type') }); // const url = URL.createObjectURL(blob); const url = URL.createObjectURL(this.response) downByA(url) } } } - dataUrl + a标签下载
- 转换成dataUrl可以利用canvas.toDataUrl方法,适用于下载图片的场景,且不同的图片格式在不同的浏览器下会存在兼容性问题
- 另外在使用canvas转图片下载时会出现图片过大转换成的dataUrl长度超出a标签长度限制导致无法下载的情况,导出文件变成了空白的txt。
const downByData = (imageData) => { // type为png\jpg\jpeg时,其他格式支持性不好,chrome支持webp let type = 'image/png' let image = new Image() // 避免抛出安全错误,此处需设置允许跨域访问 image.setAttribute('crossOrigin', 'anonymous') image.onload = () => { let canvas = document.createElement('canvas') canvas.width = image.width canvas.height = image.height let ctx = canvas.getContext('2d') ctx?.drawImage(image, 0, 0, image.width, image.height) const url = canvas.toDataURL(type) downByA(url) } image.src = imageData } - 其他
- a标签的download属性与HTTP 头中的 Content-Disposition 属性都可以表示下载文件的文件名,HTTP 头属性优先于此属性。
- a标签中常使用a.click()来触发点击事件,但无法有效控制事件冒泡,在微前端架构中也可能存在一些其他问题。此时可以使用new mouseEvent()来创建一个鼠标事件来控制是否冒泡、是否可以取消等,再通过dispatchevent触发。
var $a = document.createElement('a') $a.download = 'test.png' $a.target = '_blank' $a.href = imageData var evt = new MouseEvent('click', { // some micro front-end framework, window maybe is a Proxy view: document.defaultView, bubbles: true, cancelable: false, }) $a.dispatchEvent(evt)
再说返回二进制文件流的情况
在遇到大文件下载的情形,直接返回文件存储的url给前端下载,虽然可以使用webworker开辟一个下载进程,但仍然存在下载时间过长导致下载中途失败的情况。这时候一般会选择后端返回二进制文件流,前端再根据文件大小选择下载方式。
-
非分片下载
- 无需分片下载的文件流,可以参考blob+a标签的方式,只需要设置xhr/fetch返回的数据类型为arraybuffer。
const handleBufferDownload = () => { axios({ method: 'post', url: url, responseType: 'arraybuffer', }).then((res) => { let blob = new Blob([res.data]) const blobUrl = URL.createObjectURL(blob) downByA(blobUrl) }) } -
分片下载
- 分片下载主要依赖HTTP 响应头
Accept-Ranges。相关的http头及含义可见下图。
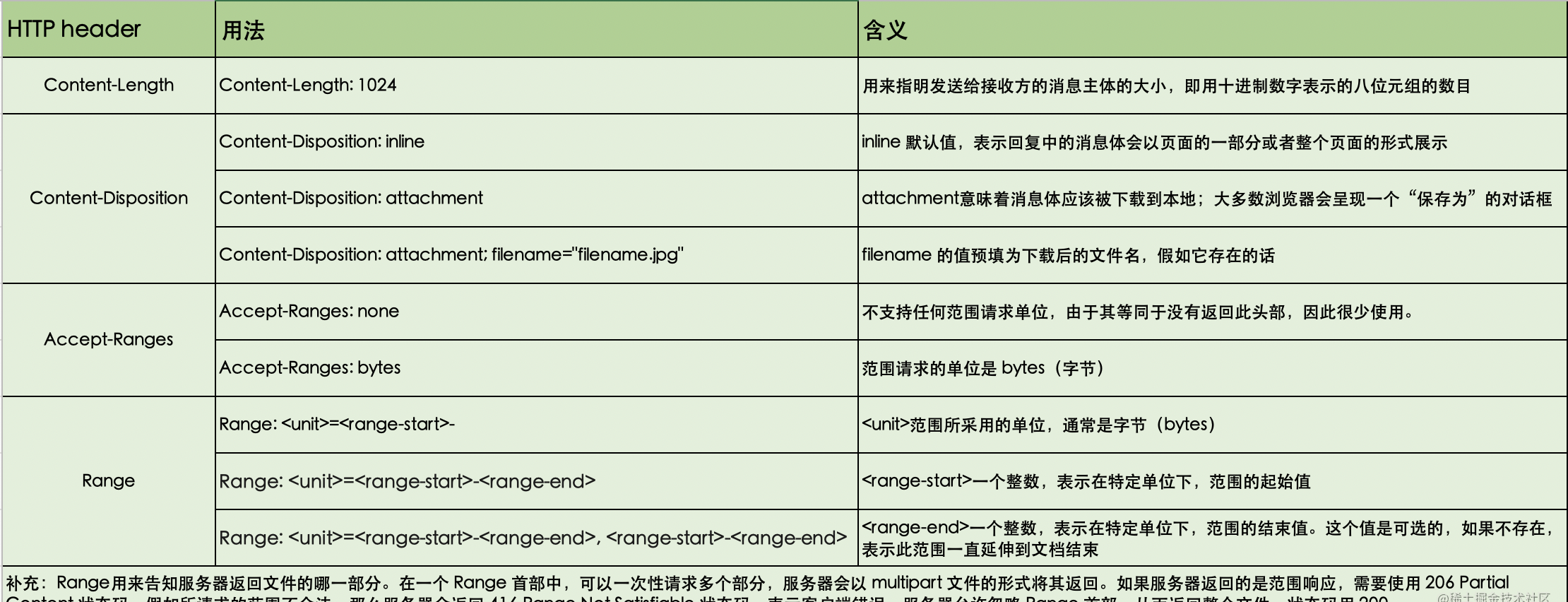

- 大文件分片下载主要可以分为4步:根据下载文件大小进行切片请求,下载任务多线程并行操作,所有切片下载完成后进行拼装,拼装完成后下载。
- 切片请求
- 先根据文件大小对文件进行分割
// Node.js代码 async getfileSize() { const { ctx } = this; const { url } = ctx.request; const filepath = url.split('filepath')[1].slice(1); const pathname = path.resolve(this.app.config.static.dir, filepath); const statObj = fs.statSync(pathname); ctx.set('Access-Control-Allow-Origin', '*'); ctx.set('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, OPTIONS'); ctx.set('Content-Disposition', `attachment;filename=${encodeURIComponent(filepath)}`); // 返回文件大小,前端可根据header中的filename获取文件名称 ctx.body = { data: 'success', size: statObj.size }; } // 前端一个普通的get/post请求即可,获取到文件大小后按照一定的规则进行分割 const handleSplitDown = (filepath, fileSize) => { const CHUNK_SIZE = 1024 * 10 * 10 const chunkCount = Math.ceil(fileSize / CHUNK_SIZE) let initList = [] const resultList = [] for (let i = 0; i < chunkCount; i++) { initList.push(i) } return new Promise((resolve, reject) => { return downList(initList, resultList, resolve, reject) }) } - 多线程下载
- 将大文件按照一定规则分割后,利用promise.allSettled并发多个下载请求,要有重试机制来应对下载失败的情况
async function downList(arr, resultList, resolve?, reject?) { const fileList = [] for (let i = 0; i < arr.length; i++) { fileList.push(downloadWithByte(filepath, arr[i] * CHUNK_SIZE, (arr[i] + 1) * CHUNK_SIZE - 1)) } const failList = [] Promise.allSettled(fileList).then((res) => { res.forEach((item, index) => { // 注意可能存在请求失败的情况,要有重试机制 if (item.status === 'fulfilled') { resultList[index] = item } else { failList.push(index) } if (failList.length === 0) { resolve(resultList) } else { return downList(failList, resultList, resolve, reject) } }) }) }- 此时的后端代码要注意http header的处理
// Node.js代码 async downfileSplit() { const { ctx } = this; const { url } = ctx.request; const { range } = ctx.request.headers; const filepath = url.split('filepath')[1].slice(1); const pathname = path.resolve(this.app.config.static.dir, filepath); const statObj = fs.statSync(pathname); const total = statObj.size; let [ , start, end ] = range.match(/(\d*)-(\d*)/); console.log(ctx.request, total, start, end); ctx.set('Access-Control-Allow-Origin', '*'); ctx.set('Access-Control-Allow-Methods', 'PUT, POST, GET, DELETE, OPTIONS'); ctx.set('Content-Disposition', `attachment;filename=${encodeURIComponent(filepath)}`); start = start ? parseInt(start) : 0; end = end ? parseInt(end) : total - 1; ctx.status = 206; ctx.set('Accept-Ranges', 'bytes'); ctx.set('Content-Range', `bytes=${start}-${end}/${total}`); ctx.body = fs .createReadStream(pathname, { start, end }) .pipe(stream.PassThrough()); } - 拼装切片
- 所有分片都下载完成后,按照顺序拼接成blob
handleSplitDown(filepath, fileSize).then((res) => { let blob = new Blob(res.map((r) => r.value.data)) const blobUrl = URL.createObjectURL(blob) downByA(blobUrl) }) - 下载
- 获取到blob之后,利用a标签即可实现下载
- 切片请求
- 分片下载主要依赖HTTP 响应头
参考链接
原文链接:https://juejin.cn/post/7231095643572420668 作者:Ambber