

前言
以前听后端的同事说,用网页爬虫可以抓取到许多电影下载资源。当时就跃跃欲试,想学习一下。无奈当时太懒,也经受不住生活中各种能获得即时快乐感事情的诱惑。时间都没有用到正经事情上。把这件事情耽搁了好几年。前段时间在掘金看到一篇有关爬虫的文章,勾起了我的回忆,我当时就暗下决心,这次一定要把爬虫程序写出来,把存储在心里的后台任务释放掉。了却我的心结,除去一个心智负担。
效果演示
爬虫配置数据都写在config.js中,启动爬虫程序后,每隔一分钟,会创建一个json文件,里面的内容是爬取出来的目标网站数据。

思路
看网上说,随便爬取别人家网站的内容是侵权和违法的,那我找个不会违法的网站,比如说爬一爬程序员的大本营稀土掘金的综合文章排行榜数据(排行榜上每篇文章的排名,标题,链接),练练手。万事开头难,那么该从何处下手呢。分三步实现:
- 第一步 分析目标网站,观察如何获取想要的数据
- 第二步 爬取数据,把爬下来的数据存储到本地文件中
- 第三步 定时爬取,定期去爬取目标网站内容
分析目标网站
首先,掘金文章榜-综合栏页面渲染完成之后长这样,再查看一下网页源代码,得出页面排行榜数据是动态获取渲染出来的。

这一点决定了不能使用在网上盛传的node-https.get+cheerio组合方案, 因为node-https.get只能获取静态网页内容,而cheerio是基于获取到网页的静态内容之后做的数据提取操作。本文选择的目标页面数据是动态渲染出来的,用node-https.get爬取像豆瓣电影这样的网站,一点问题都没有。如果想爬取像掘金文章排行榜这种内容是用动态数据渲染出来的页面,显得就力不从心。那是不是就做不下去了?这次岂能这么容易放弃,经过一番查找和尝试,终于找到了救世主,用的是什么方法呢? 这里先卖个关子,后面会讲。

其次, 如果想爬取文章排行榜每篇文章的排名,标题,链接信息,就需要观察页面的dom结构,找到抓手。根据下图所圈出来的几个页面元素的样式名,就能从dom树中解析出文章排行榜中每一篇文章的这三项内容。
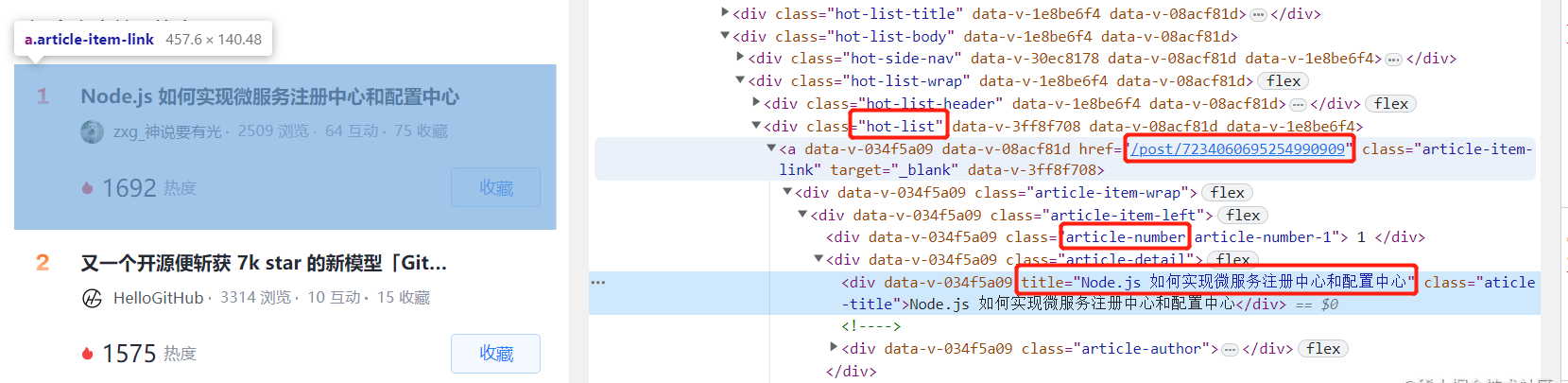
在调试控制台, 执行一下document.querySelector(".hot-list > .article-item-link > .article-item-wrap > .article-item-left >.article-number"),验证一下,获取的内容是否正确。没错,是我们要的东西。另外发现,文章链接缺少网站域名,我们自己把文章链接补充完整。解析页面数据完整的代码如下:
// 操作dom, 获取文章列表页面的内容
function getData(pageOrigin) {
const list = [];
const itemSelector = ".hot-list >.article-item-link";
const commonSelector = ".article-item-wrap > .article-item-left";
const rankSelector = [commonSelector, ".article-number"].join(">");
const titleSelector = [commonSelector, ".article-detail > .aticle-title"].join(">");
document.querySelectorAll(itemSelector).forEach((ele) => {
// const rank = ele.querySelector(rankSelector).innerText.replace(/[\n\s]/g, "");
const rank = ele.querySelector(rankSelector).innerText;
const title = ele.querySelector(titleSelector).getAttribute("title");
const link = `${pageOrigin}${ele.getAttribute("href")}`;
list.push({
排名: rank,
标题: title,
链接: link,
});
});
return list;
}
爬取数据
有请我们的Puppeteer大神闪亮登场,要不是他救场,我这次又得被打脸了。先做一下简要介绍。Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。再做一下详细介绍。
Puppeteer 是什么 ?
- Puppeteer 默认情况下是以 headless 启动 Chrome 的,也可以通过参数控制启动有界面的 Chrome
- Puppeteer 提供了一系列 API,通过 Chrome DevTools Protocol 协议控制 Chromium/Chrome 浏览器的行为;
- Puppeteer 默认绑定最新的 Chromium 版本,也可以设置绑定别的版本
上面又引出来一个概念,什么是Headless(无头浏览器) ?无头浏览器是指浏览器运行在无界面的环境中,通过命令行或者程序语言操作浏览器, 无需人的干预,运行更稳定。
Puppeteer 能做什么?
- 爬取 SPA 或 SSR 网站
- 网页截图或者生成 PDF文件
- UI 自动化测试,模拟表单提交,键盘输入,点击等行为
- 捕获网站的时间线,帮助诊断性能问题
- 创建一个最新的自动化测试环境,使用最新的 js 和最新的 Chrome 浏览器运行测试用例
- 测试 Chrome 扩展程序
- …
我们需要的就是Puppeteer能够爬取动态数据渲染完成之后的页面功能。那具体要怎么做?限于篇幅,我重点介绍一下本文用到的一些Puppeteer API,想要了解完整API的话请参考官方文档。
用到的Puppeteer API简介
先看看如何创建一个Puppeteer实例,我们围绕这个实例的创建,把相关的API都讲一下。
const puppeteer = require("puppeteer");
// 使用 puppeteer.launch 启动 Chrome
(async () => {
const browser = await puppeteer.launch({
headless: false, // 有浏览器界面启动
slowMo: 100, // 放慢浏览器执行速度,方便测试观察
args: [
// 启动 Chrome 的参数,详见上文中的介绍
"–no-sandbox",
"--window-size=1280,960",
],
});
const page = await browser.newPage();
await page.goto("https://www.baidu.com");
const articleList = await page.evaluate((pageOrigin) => {
return getData();
// 操作dom, 获取文章列表页面的内容
function getData() {}
}, crawlPageOrigin);
await page.close();
await browser.close();
})();
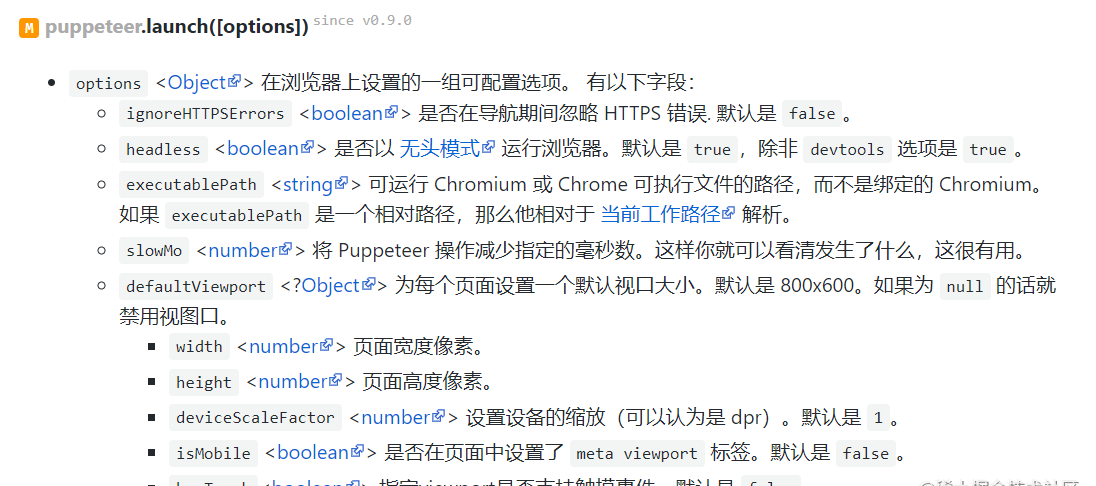
- puppeteer.launch: puppeteer 提供了两种方法用于创建一个 Browser 实例:puppeteer.launch每次都启动一个 Chrome 实例,puppeteer.connect 可以实现对于同一个 Chrome 实例的共用,减少启动关闭浏览器的时间消耗,puppeteer.launch的配置参数很多(如下图),比较重要的是headless这一项, 设置成false的话,会启动一个有界面的浏览器,可供调试使用,一般都使用默认值true或’new'(新版本使用的是’new’)。
- Browser: 对应一个浏览器实例,一个 Browser 可以包含多个 BrowserContext
- Page:表示一个 Tab 页面,通过 browserContext.newPage()或browser.newPage() 创建,browser.newPage() 创建页面时会使用默认的 BrowserContext。
- page.goto:打开新页面,提供了两个参数 waitUtil 和 timeout,waitUtil 表示直到什么出现就算执行完毕,timeout 表示如果超过这个时间还没有结束就抛出异常。
await page.goto('https://www.baidu.com', {
timeout: 30 * 1000,
waitUntil: [
'load', // 等待 “load” 事件触发
'domcontentloaded', // 等待 “domcontentloaded” 事件触发
'networkidle0', // 在 500ms 内没有任何网络连接
'networkidle2' // 在 500ms 内网络连接个数不超过 2 个
]
});
- page.evaluate(pageFunction[, …args])
在浏览器环境中执行函数。这个方法专坑新手。首先要明白一个重要的概念两个独立的环境,使用 Puppeteer 时我们几乎一定会遇到在这两个环境之间交换数据:运行 Puppeteer 的 Node.js 环境和 Puppeteer 操作页面的 Page DOM环境,理解这两个环境很重要。
// 外面是node环境,不能操作dom
const articleList = await page.evaluate((pageOrigin) => {
// 里面是无头浏览器环境,可以操作dom
return getData();
}, crawlPageOrigin);
page.evaluate里外环境是不直接相通的, 可以通过向 page.evaluate方法传参,把node环境中的变量传进去。参数只能为变量,不能传函数,函数传进去会变成null。传递函数的办法是通过page.exposeFunction("函数名", 函数);, 把node环境定义的函数传递到Page Dom环境,但传递进去的这个node函数也无法接收Page Dom环境传递的dom参数。不过可以将Page Dom环境处理的结果,返回给外部node环境。实现node环境和Page Dom环境的数据流通。
实现爬虫程序
有了上面的知识做铺垫, 现在让我们用puppeteer写一段爬取页面数据的程序。
// 无头浏览器模块
const puppeteer = require("puppeteer");
// 目标页面
const crawlPage="https://juejin.cn/hot/articles/1";
// 网页爬虫
async function crawler() {
//创建实例
const browser = await puppeteer.launch({
//无浏览器界面启动
headless: "new",
});
// 新开一个tab页面
const page = await browser.newPage();
// 加载目标页,在 500ms 内没有任何网络请求才算加载完
await page.goto(crawlPage, { waitUntil: "networkidle0" });
// 在无头浏览器页面dom环境,获取页面数据
const articleList = await page.evaluate(() => {
return getData();
// 操作dom, 获取文章列表页面的内容
function getData() {
// ...
return list;
}
});
// 关闭tab页
await page.close();
// 关闭实例
await browser.close();
}
定时爬取
爬虫程序一般都是定时爬取目标页面内容,那么如何实现定时执行爬取网页的动作呢?node 有一个工具包叫node-schedule,可以定期执行任务。
安装
pnpm add node-schedule
调用
const schedule = require("node-schedule");
// 创建任务,任务名称必须唯一
schedule.scheduleJob(`任务名称`, `时间`, () => {
});
// 删除任务
schedule.scheduledJobs[`任务名称`].cancel();
时间格式
| 格式 | 含义 |
|---|---|
| 10 * * * * * | 每分钟的第10秒触发 |
| 10 20 * * * * | 每小时的20分10秒触发 |
| 10 20 1 * * * | 每天的凌晨1点20分10秒触发 |
| 10 20 1 2 * * | 每月的2日1点20分10秒触发 |
| 10 20 20 5 2023 * | 2023年的5月20日1点20分10秒触发 |
| 10 20 1 * * 1 | 每周一的1点20分10秒触发 |
现在我们来实现定时调用网页爬虫的功能,我们对node-schedule做一下封装, 封装两个方法,任务创建和删除。这里将定时任务的定时时间设置成0 \* \* \* \* \*, 是为了更快的看到结果,实际爬取网页内容时,不一定需要这么高的频次。
定时爬取实现
// 定时任务模块
const Alarm = require("./alarm");
// 爬虫模块
const crawler = require("./crawler");
main();
function main() {
new Alarm({
// 定时任务名称
alarmName: "自动爬虫任务-20230520",
// 定时任务计划
alarmTime: "0 * * * * *",
}).create(() =>{
crawler();
});
}
alarm.js代码如下:
const schedule = require("node-schedule");
class Alarm {
constructor({ alarmName, alarmTime }) {
this.alarmName = alarmName; // 定时任务名称
this.alarmTime = alarmTime; // 定时任务时间
}
// 创建定时任务
async create(callback) {
schedule.scheduleJob(`${this.alarmName}`, `${this.alarmTime}`, callback);
}
// 删除定时任务
delete() {
if (schedule.scheduledJobs[this.alarmName]) {
schedule.scheduledJobs[this.alarmName].cancel();
return true;
}
return false;
}
}
module.exports = Alarm;
另外,感觉做node开发,最好安装一下nodemon这个node工具包, 可以做到修改文件热启动,和开发页面修改代码之后页面自动刷新一样方便。
pnpm install -g nodemon
定时任务运行效果如下: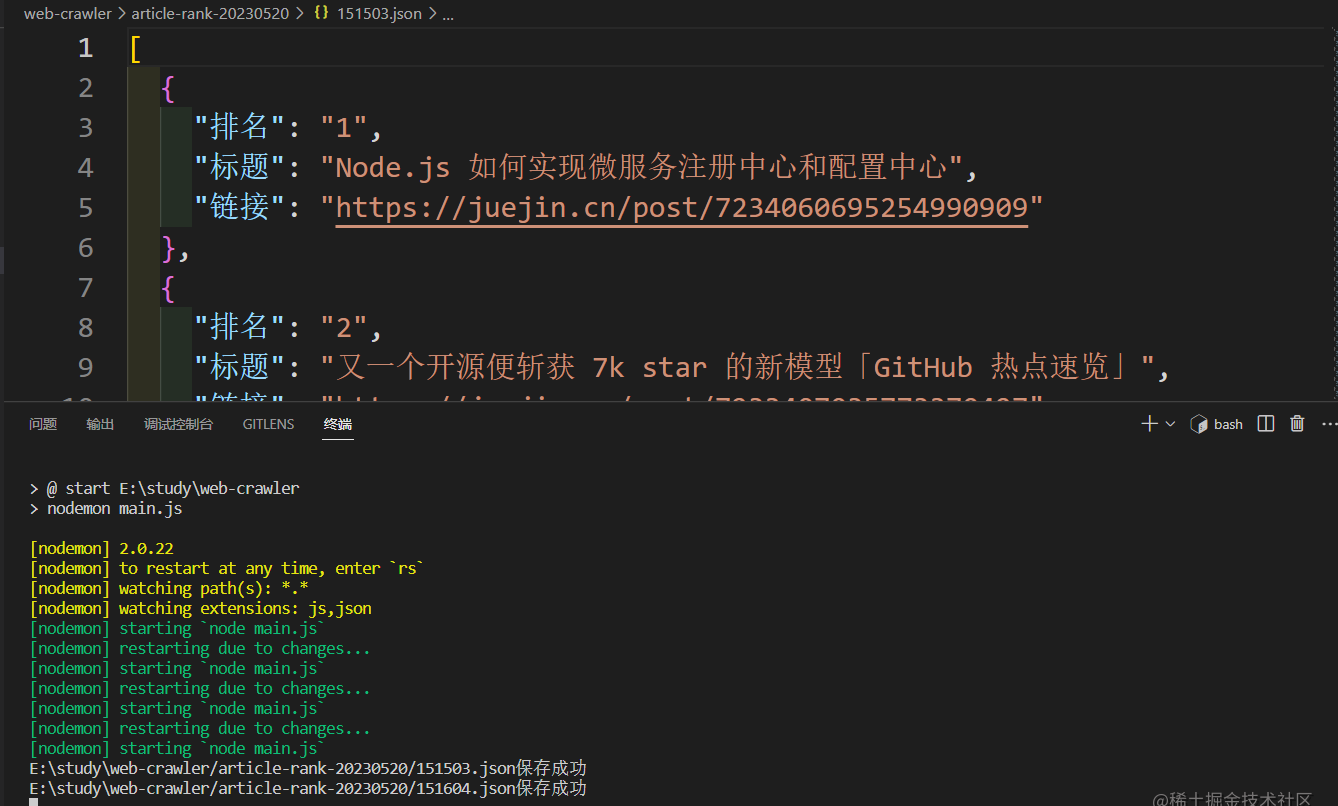
结语
一直对爬虫这一块比较感兴趣,也很想亲自实现一下,今天终于把这个曾经的Flag完成了。另外我写完爬虫功能后,审视了一下这个爬虫程序,感觉还有完善的空间。比如说把数据写入到数据库,这样查询数据更高效与方便; 再比如说做一个可视化页面,以更友好的方式展示数据等等。迫于时间精力有限,以后有空再完善。本文写的爬虫应用,实用价值不高,纯粹是为了练手学习新知识。如果你也对网页爬虫感兴趣,可以点击这个地址下载练习,有问题一起探讨。
原文链接:https://juejin.cn/post/7235137314401157180 作者:去伪存真