
Vue设计思想
- Vue3.0更注重模块上的拆分,在2.0中无法单独使用部分模块。需要引入完整的Vuejs(例如只想使用响应式部分,但是需要引入完整的Vuejs), Vue3中的模块之间耦合度低,模块可以独立使用。 拆分模块
- Vue2中很多方法挂载到了实例中导致没有使用也会被打包(还有很多组件也是一样)。通过构建工具Tree-shaking机制实现按需引入,减少用户打包后体积。 重写API
- Vue3允许自定义渲染器,扩展能力强。不会发生以前的事情,改写Vue源码改造渲染方式。 扩展更方便
依然保留Vue2的特色
Vue3依旧是声明式的框架,用起来简单。
命令式和声明式区别
- 早在JQ的时代编写的代码都是命令式的,命令式框架重要特点就是关注过程
- 声明式框架更加关注结果。命令式的代码封装到了Vuejs中,过程靠vuejs来实现
- 命令式编程:
let numbers = [1,2,3,4,5]
let total = 0
for(let i = 0; i < numbers.length; i++) {
total += numbers[i] - 关注了过程
}
console.log(total)
- 声明式编程:
let total2 = numbers.reduce(function (memo,current) {
return memo + current
},0)
console.log(total2)
采用虚拟DOM
传统更新页面,拼接一个完整的字符串innerHTML全部重新渲染,添加虚拟DOM后,可以比较新旧虚拟节点,找到变化在进行更新。虚拟DOM就是一个对象,用来描述真实DOM的
const vnode = {
__v_isVNode: true,
__v_skip: true,
type,
props,
key: props && normalizeKey(props),
ref: props && normalizeRef(props),
children,
component: null,
el: null,
patchFlag,
dynamicProps,
dynamicChildren: null,
appContext: null
}
区分编译时和运行时
- 我们需要有一个虚拟DOM,调用渲染方法将虚拟DOM渲染成真实DOM (缺点就是虚拟DOM编写麻烦)
- 专门写个编译时可以将模板编译成虚拟DOM (在构建的时候进行编译性能更高,不需要再运行的时候进行编译,而且vue3在编译中做了很多优化)
Monorepo 管理项目
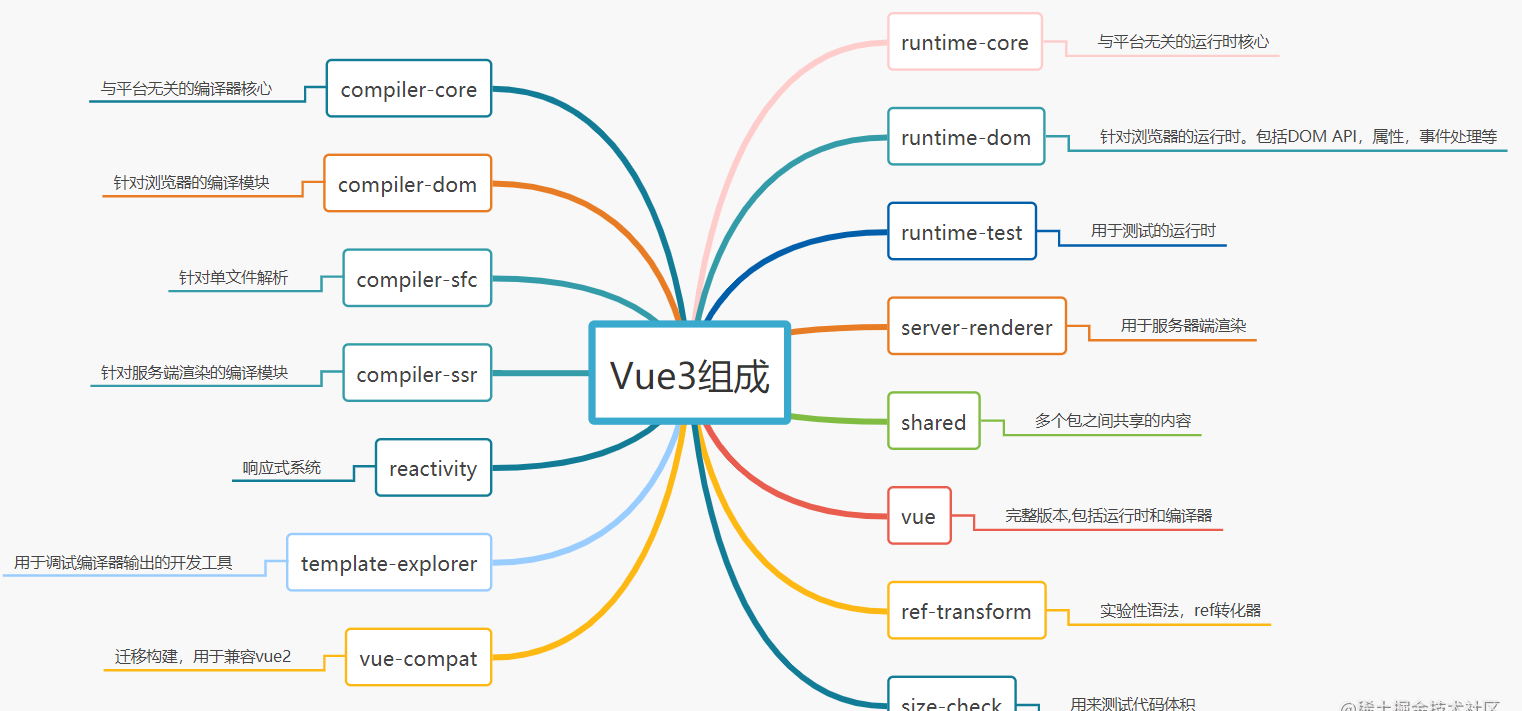
Monorepo 是管理项目代码的一个方式,指在一个项目仓库(repo)中管理多个模块/包(package)。 Vue3源码采用 monorepo 方式进行管理,将模块拆分到package目录中。

- 一个仓库可维护多个模块,不用到处找仓库
- 方便版本管理和依赖管理,模块之间的引用,调用都非常方便
Vue3项目结构
Vue3采用Typescript
Vue2 采用Flow来进行类型检测 (Vue2中对TS支持并不友好), Vue3源码采用Typescript来进行重写 , 对Ts的支持更加友好。
搭建Monorepo环境
Vue3中使用pnpm workspace来实现monorepo (pnpm是快速、节省磁盘空间的包管理器,同时,也较好地支持了worspace和monorepos。主要采用符号链接的方式管理模块)
认识pnpm
pnpm 是 performant npm(高性能的 npm),它是一款快速的,节省磁盘空间的包管理工具,同时,它也较好地支持了 workspace 和 monorepos,简化开发者在多包组件开发下的复杂度和开发流程。
pnpm优势
包安装速度极快
比传统方案安装包的速度快了两倍,以下是官方给出的benchmarks(对比了npm, pnpm, Yarn Classic, and Yarn PnP),在多种常见情况下,执行install的速度比较
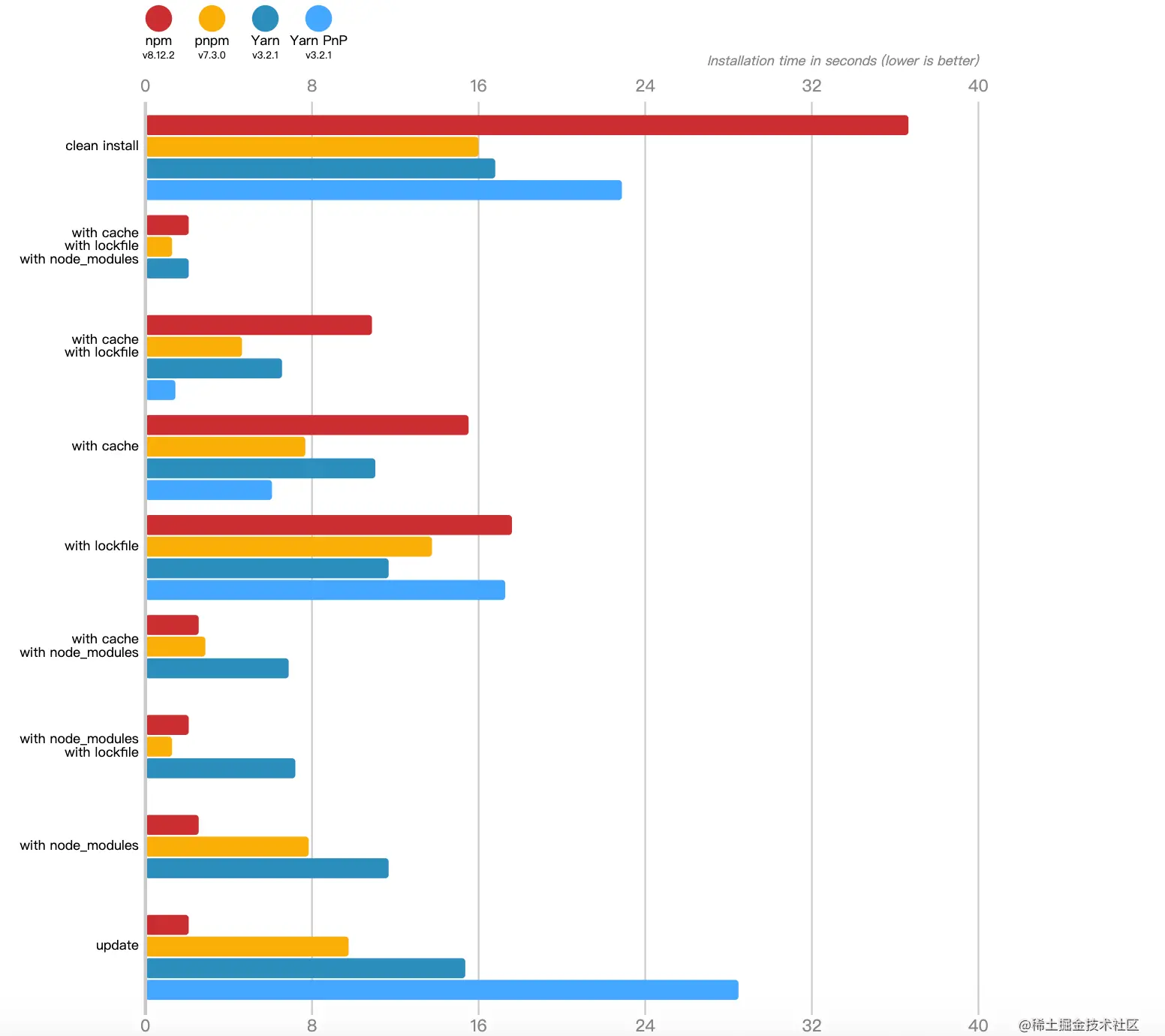
为啥pnpm会比其他的包管理器快呢?这得益于包管理机制,节约了磁盘空间提升安装速度
pnpm依赖包扁平化管理原理
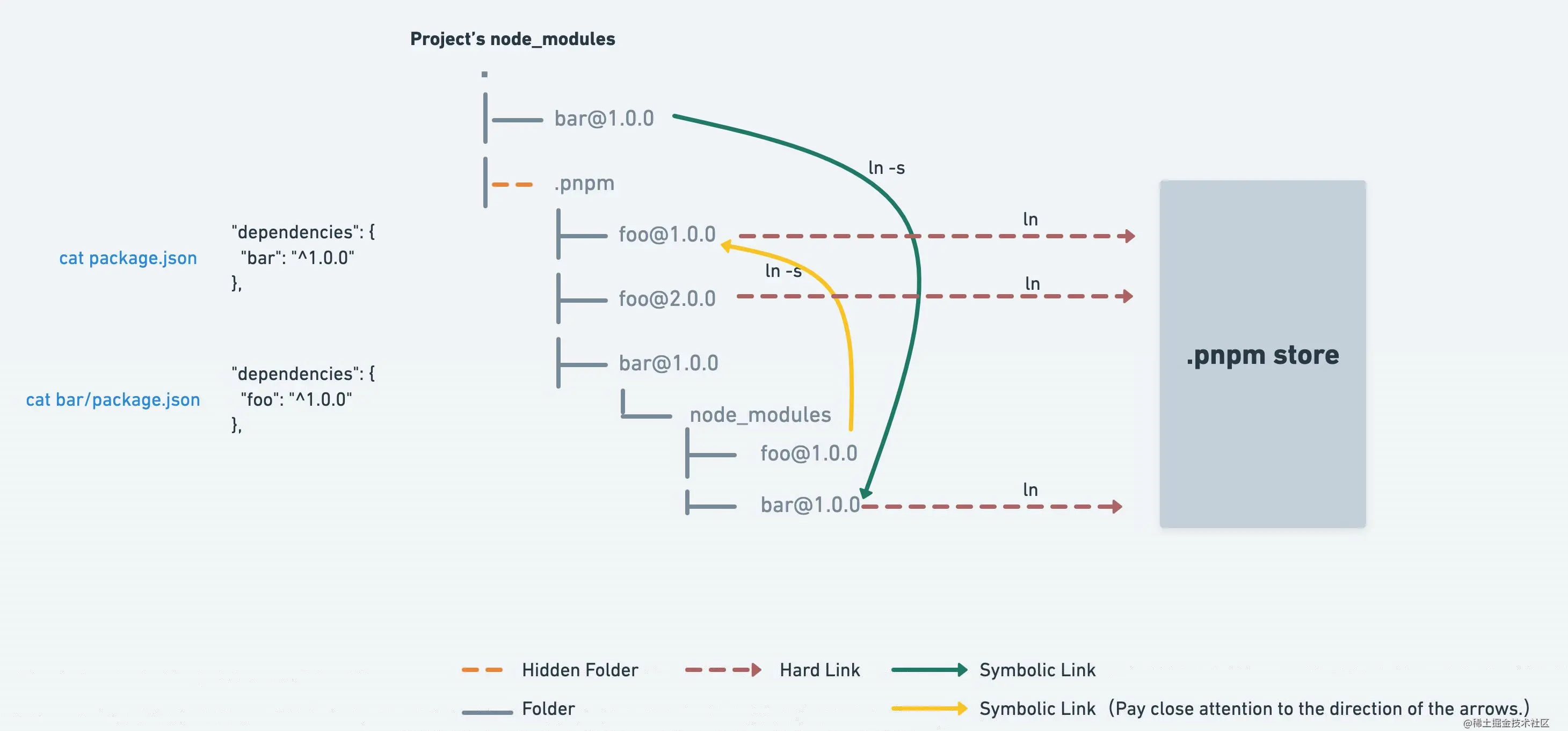
pnpm之所以如此高效,最核心的思想就是:全局store + hard link管理。
全局store好理解,说白了就是在项目的node_modules下创建一个.pnpm名称的目录,把项目中所有的依赖都安装到里面,形成一个包名 + 内部依赖 + 版本信息的序列目录列表,- 而且不会重复安装同一个包。使用npm/yarn的时候,如果100个包依赖express,那么就可能安装了100次express,磁盘中就有100个地方写入了这部分代码。但是pnpm会只在一个地方写入这部分代码,后面使用会直接使用硬链接
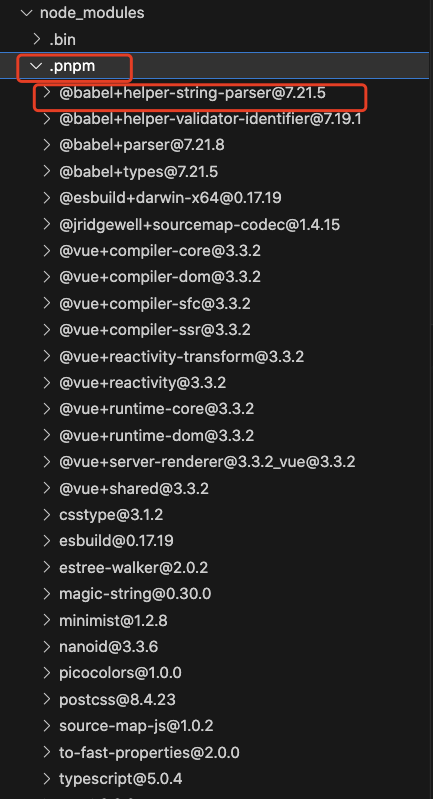
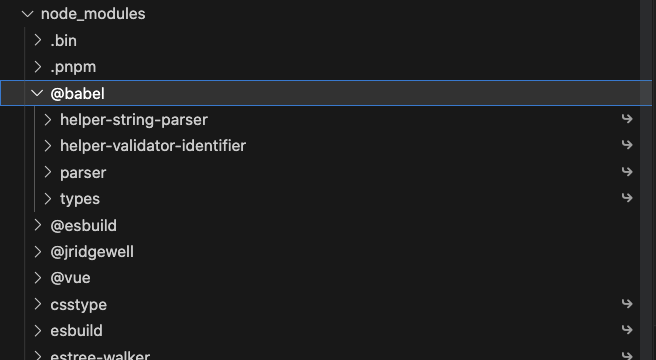
hard link管理指的是外面的依赖包不再以实体文件的形式存在,而是创建了一个链接(有点像windows系统的快捷方式)指向store里面的指定依赖,用到该依赖包时去store里面取,如下图,@babel里面的依赖全部是hard link,真正的实体文件在.pnpm目录中。
pnpm monorepos模式优势
优势一:快
由于有了hard link和全局store的加持,在开发环境中编码,热更新的开发服务响应是非常快的,给开发者有良好的体验环境。
优势二:管理方便
多个组件间的调用依赖简单,举个例子:在1个pnpm monorepos工程里面有3个组件,其中a只提供给开发者本地调试用,b和c作为发布包,并且b依赖c。
我们只需要把3个包在pnpm workspace注册,便能像引用远程组件那样去引入,而且支持实时本地调试。这个功能像是pnpm自动帮我们做好了npm link。
优势三:解决monorepos的结构性依赖痛点
Phantom dependencies (幽灵依赖)
常见于yarn体系下,例如依赖里面有个包名叫 foo,foo 里面依赖了 bar,经过 yarn 的扁平化处理,会把依赖foo和bar在 node_modules 同一层级目录下。那么根据 nodejs 的寻径原理,用户能 require 到 foo,同样也能 require 到 bar。
这样的bar就是一个幽灵依赖,它有什么问题呢?直到某一天随着foo包升级,导致它不再依赖bar,那么在项目引用bar就会直接报错,因为根本没安装过这个包。
但这种情况不会发生在pnpm中。上面讲过pnpm中node_modules的结构是包名 + 内部依赖 + 版本信息的序列目录列表,在项目也根本没法直接require bar。
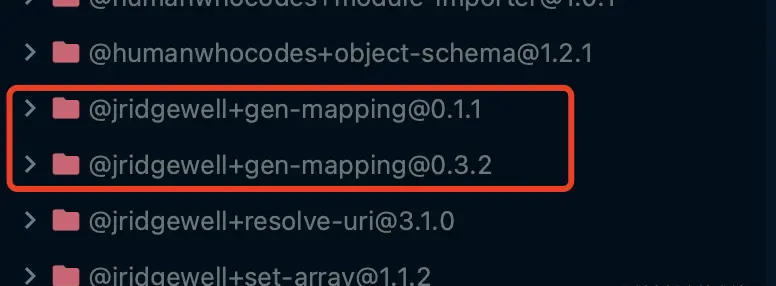
依赖分身
就是说不同依赖中的子依赖同一个包,而且这个包版本还不一致,导致项目重复安装子依赖包,致增加依赖的维护成本。
在pnpm体系下,由于所有依赖都打平到全局store里面了,所以不同版本的依赖只会安装一次,足以被整个项目所用。
当然,假如子依赖的版本不一致,pnpm还是会安装多次的,但是所有父依赖包的引用地址只会指向一处,这也弥补性能和空间上的性能缺陷。
全局安装pnpm
npm install pnpm -g # 全局安装pnpm
创建.npmrc文件
shamefully-hoist = true
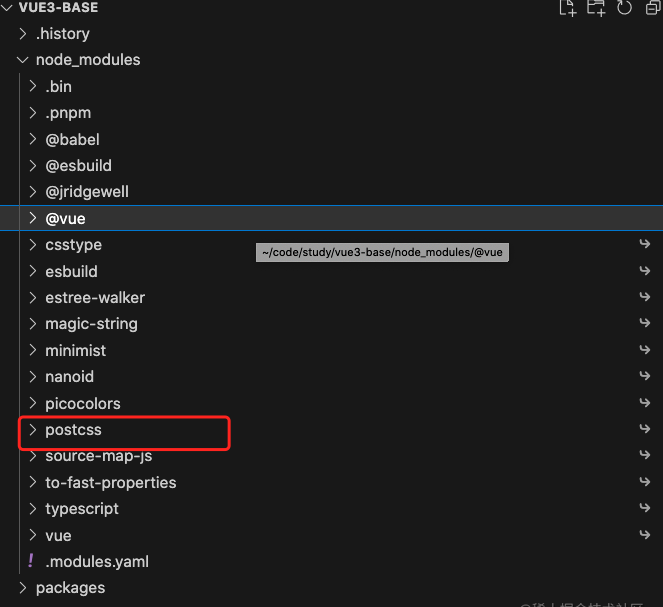
这里您可以尝试一下安装Vue3, pnpm install vue@next此时默认情况下vue3中依赖的模块不会被提升到node_modules下。 添加羞耻的提升可以将Vue3,所依赖的模块提升到node_modules中
配置workspace
新建 pnpm-workspace.yaml
packages:
- 'packages/*'
将packages下所有的目录都作为包进行管理。这样我们的Monorepo就搭建好了。确实比lerna + yarn workspace更快捷
环境搭建
打包项目Vue3采用rollup进行打包代码,安装打包所需要的依赖
pnpm install typescript rollup rollup-plugin-typescript2 @rollup/plugin-json @rollup/plugin-node-resolve @rollup/plugin-commonjs minimist execa@4 esbuild -D -w
初始化TS
pnpm tsc --init
先添加些常用的ts-config配置,后续需要其他的在继续增加
{
"compilerOptions": {
"outDir": "dist", // 输出的目录
"sourceMap": true, // 采用sourcemap
"target": "es2016", // 目标语法
"module": "esnext", // 模块格式
"moduleResolution": "node", // 模块解析方式
"strict": false, // 严格模式
"resolveJsonModule": true, // 解析json模块
"esModuleInterop": true, // 允许通过es6语法引入commonjs模块
"jsx": "preserve", // jsx 不转义
"lib": ["esnext", "dom"], // 支持的类库 esnext及dom
}
}
创建模块
我们现在packages目录下新建两个package,用于手写响应式原理做准备
- reactivity 响应式模块
- shared 共享模块
所有包的入口均为src/index.ts 这样可以实现统一打包
- reactivity/package.json
{
"name": "@vue/reactivity",
"version": "1.0.0",
"main": "index.js",
"module":"dist/reactivity.esm-bundler.js",
"unpkg": "dist/reactivity.global.js",
"buildOptions": {
"name": "VueReactivity",
"formats": [
"esm-bundler",
"cjs",
"global"
]
}
}
- shared/package.json
{
"name": "@vue/shared",
"version": "1.0.0",
"main": "index.js",
"module": "dist/shared.esm-bundler.js",
"buildOptions": {
"formats": [
"esm-bundler",
"cjs"
]
}
}
formats为自定义的打包格式,有esm-bundler在构建工具中使用的格式、esm-browser在浏览器中使用的格式、cjs在node中使用的格式、global立即执行函数的格式
pnpm install @vue/shared@workspace --filter @vue/reactivity
配置ts引用关系
"baseUrl": ".",
"paths": {
"@vue/*": ["packages/*/src"]
}
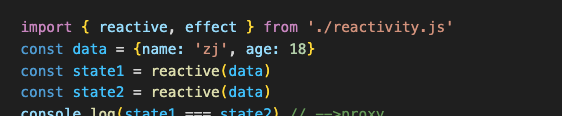
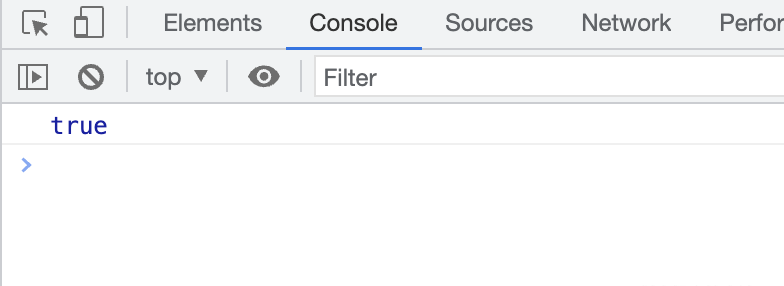
项目搭建好了,我们来看下效果,首先我们引入Vue中的reactive、effect看下运行效果
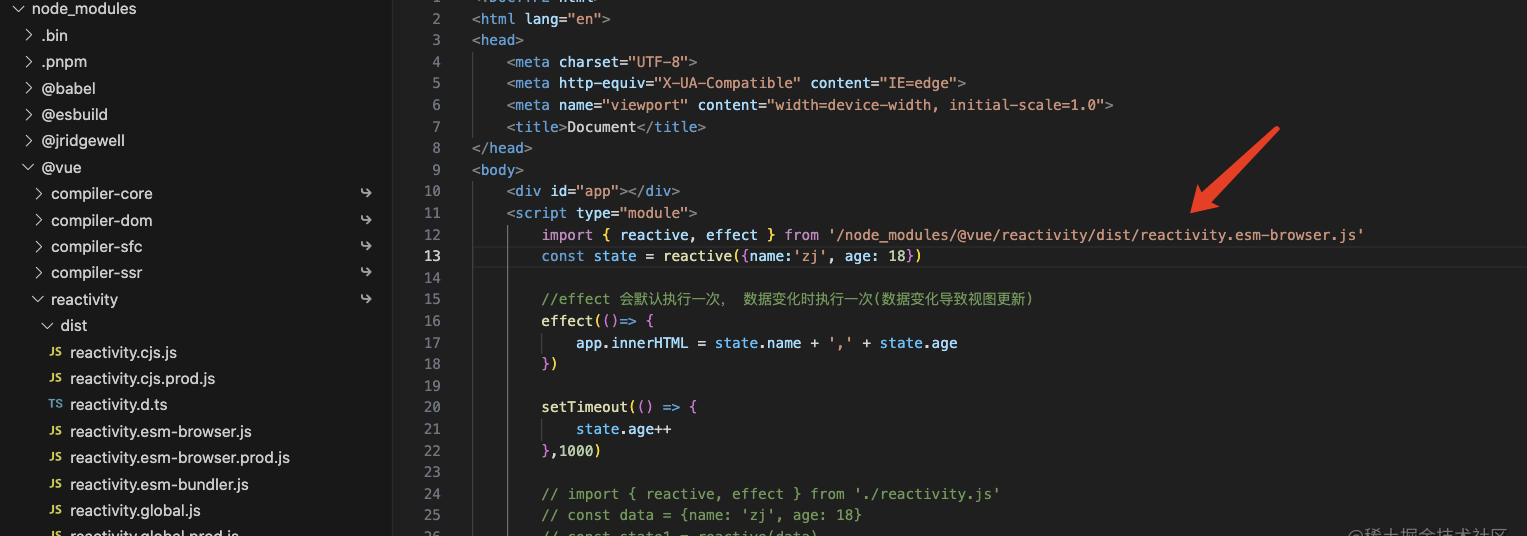


依赖收集
Vue3对比Vue2的响应式变化
- 在Vue2的时候使用defineProperty来进行数据的劫持, 需要对属性进行重写添加
getter及setter性能差。 - 当新增属性和删除属性时无法监控变化。需要通过
$set、$delete实现 - 数组不采用defineProperty来进行劫持 (浪费性能,对所有索引进行劫持会造成性能浪费)需要对数组单独进行处理
Vue3中使用Proxy来实现响应式数据变化。从而解决了上述问题。
CompositionAPI
- 在Vue2中采用的是OptionsAPI, 用户提供的data,props,methods,computed,watch等属性 (用户编写复杂业务逻辑会出现反复横跳问题)
- Vue2中所有的属性都是通过
this访问,this存在指向明确问题 - Vue2中很多未使用方法或属性依旧会被打包,并且所有全局API都在Vue对象上公开。Composition API对 tree-shaking 更加友好,代码也更容易压缩。
- 组件逻辑共享问题, Vue2 采用mixins 实现组件之间的逻辑共享; 但是会有数据来源不明确,命名冲突等问题。 Vue3采用CompositionAPI 提取公共逻辑非常方便
简单的组件仍然可以采用OptionsAPI进行编写,compositionAPI在复杂的逻辑中有着明显的优势~。
reactivity模块中就包含了很多我们经常使用到的API例如:computed、reactive、ref、effect等
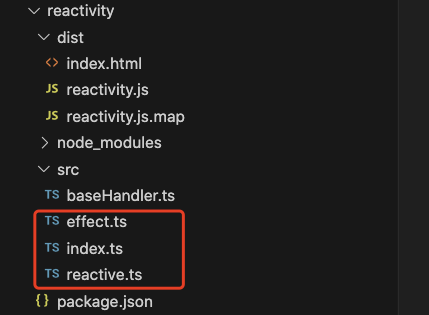
那现在我们不用Vue里面的api,我们自己写,看下里面的实现逻辑,在reactivity中实现两个api:effect和reactive

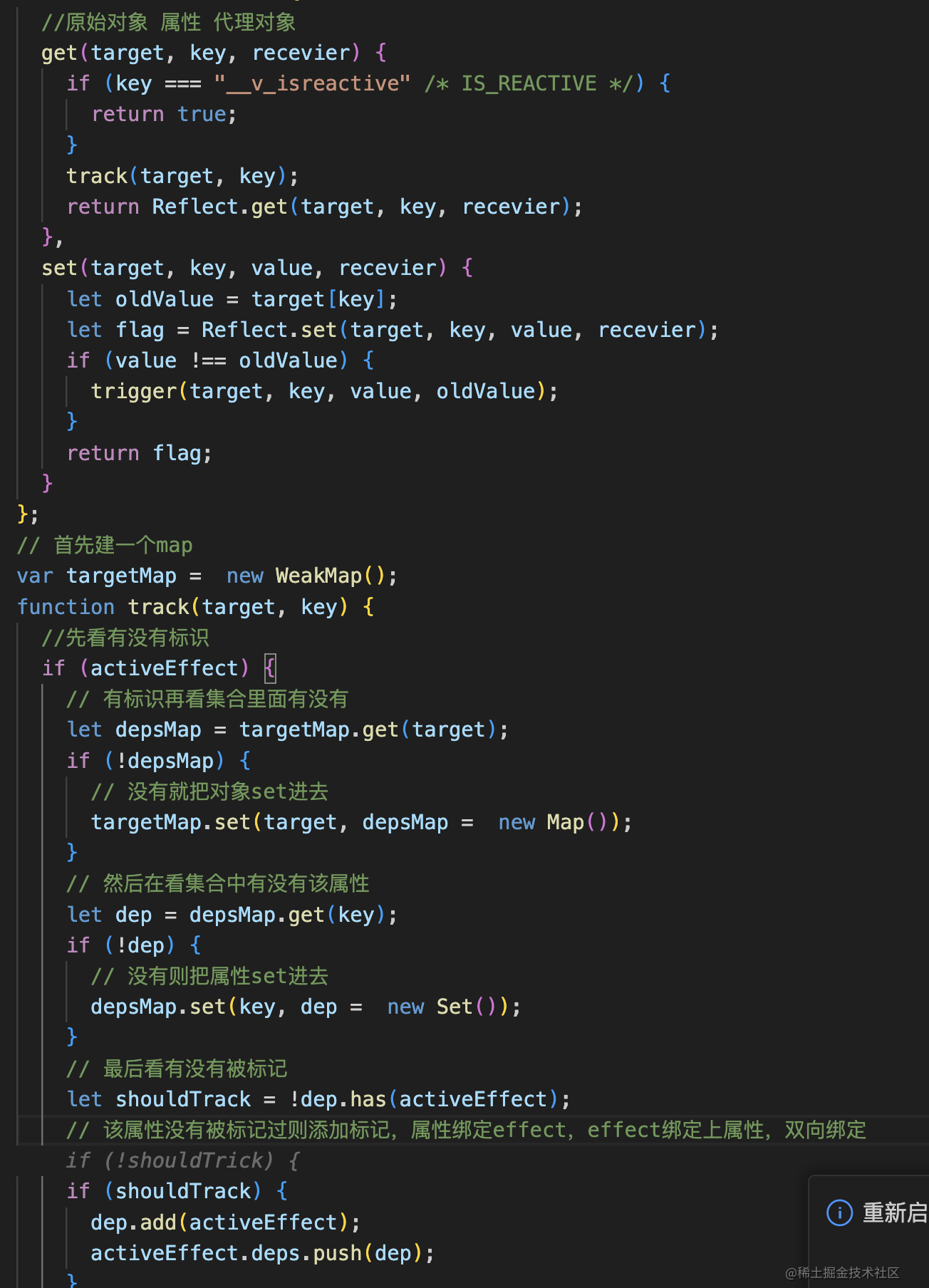
reactive接受的必须是对象,reactive传进来的对象利用Proxy进行劫持在内部进行依赖收集与通知更新操作然后最终返回一个代理对象
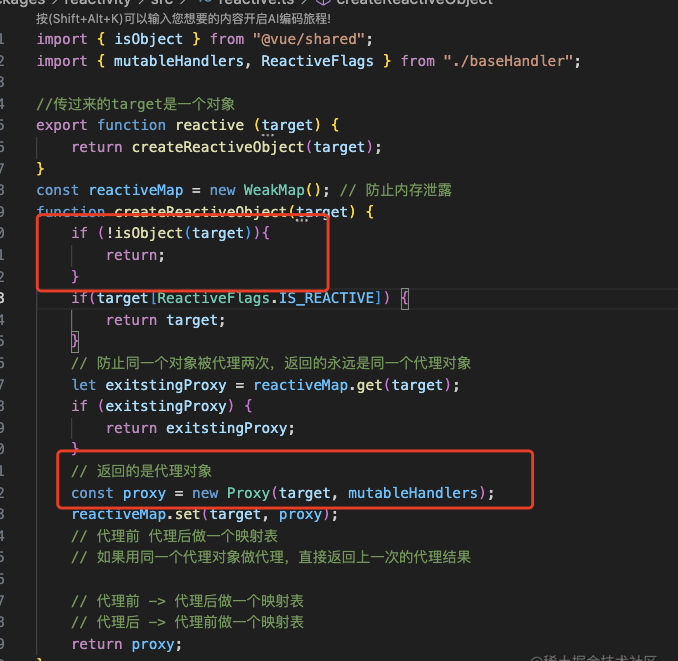
响应式的核心逻辑在mutableHandlers中,取值的时候要知道在哪个effect中使用了,赋值的时候要知道在哪个effect中重新执行

我们在get中取值的时候为了保证this指向是proxy,这里我们要借助reflect

effect函数
vue包虽然是所有模块的整合,但是在vue中我们是拿不到effect这个方法的。也就是说,reactivity中虽然有effect方法,但是它并没有暴露给vue,所以我们只能通过响应式reactivity拿到effect函数
effect接收的是函数,函数叫执行,默认情况下让函数先运行起来,我们采用类的方式创建,将用户的函数拿到变成响应式的函数
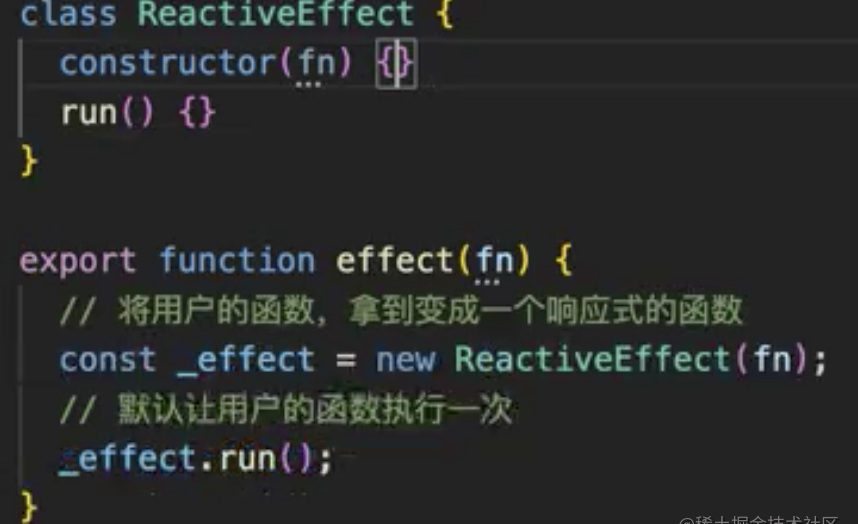
effect中存在的一些问题
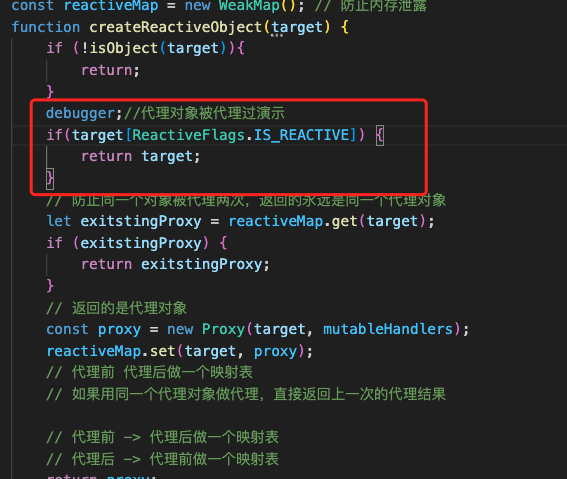
如果同一个对象被代理多次怎么办?应该返回同一个代理对象
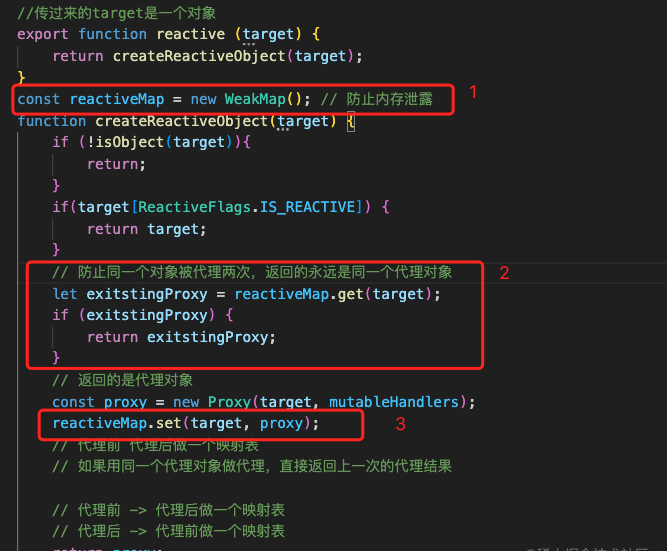
代理对象再次被代理应该怎么处理呢?
state1被代理过了 一定被增添了get和set方法,我们可以加一些标识
在取值的时候判断有标识就直接返回,然后去代理的时候发现有标识直接return当前的target

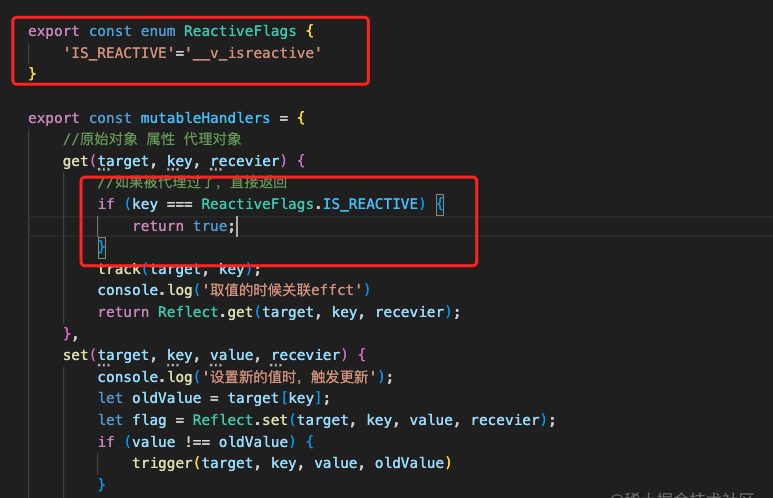
那我们怎么知道调用的是哪个effect呢?
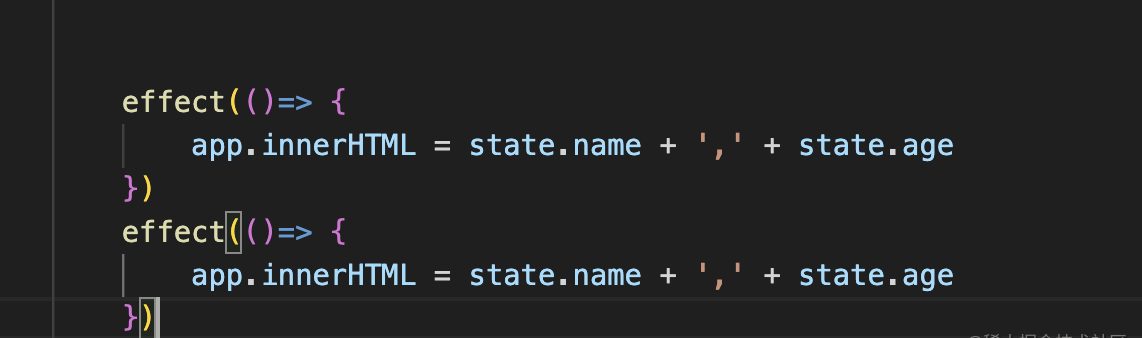
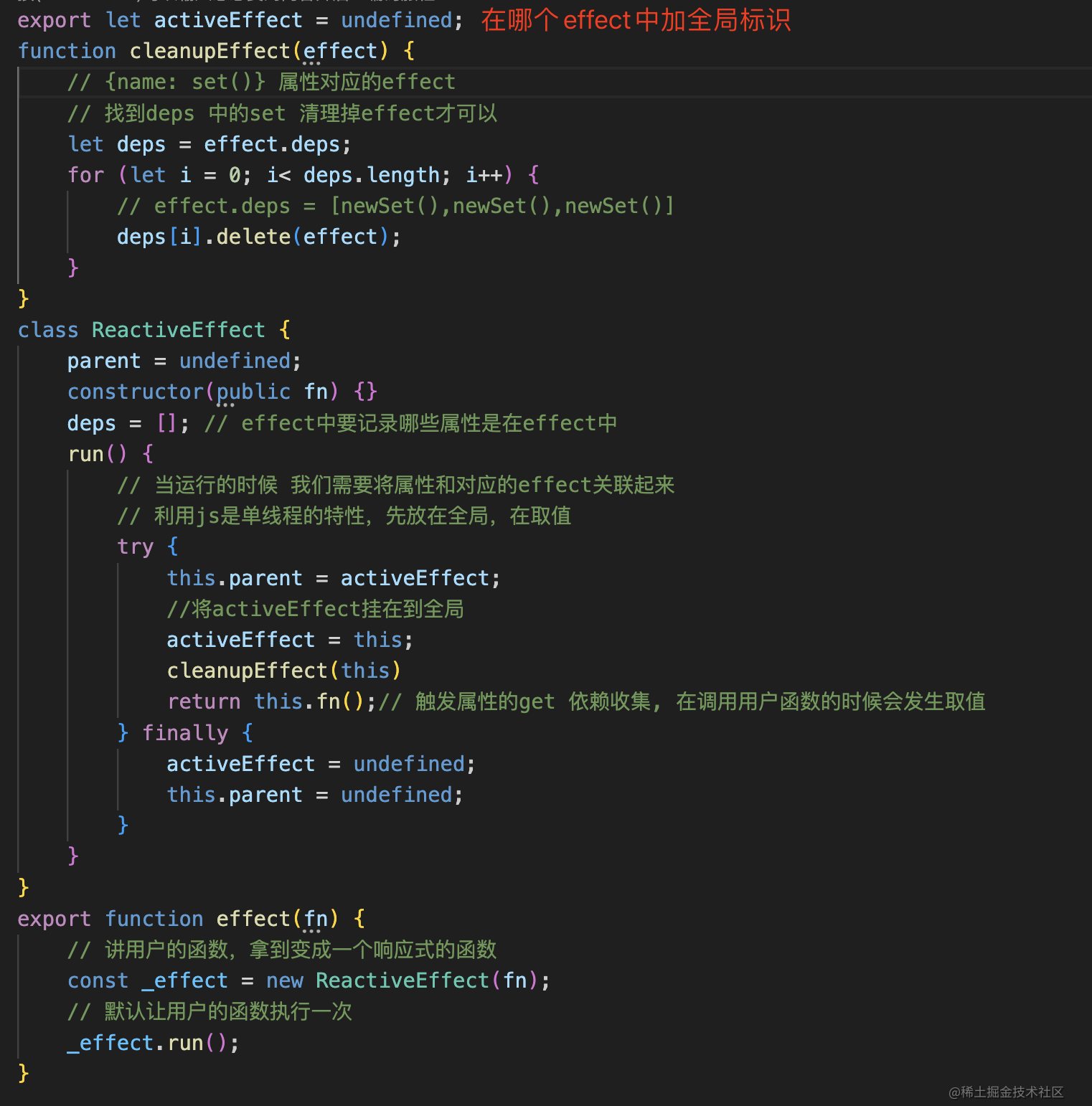
activeEffect作为全局标识,用完清理掉
函数栈执行存在的问题
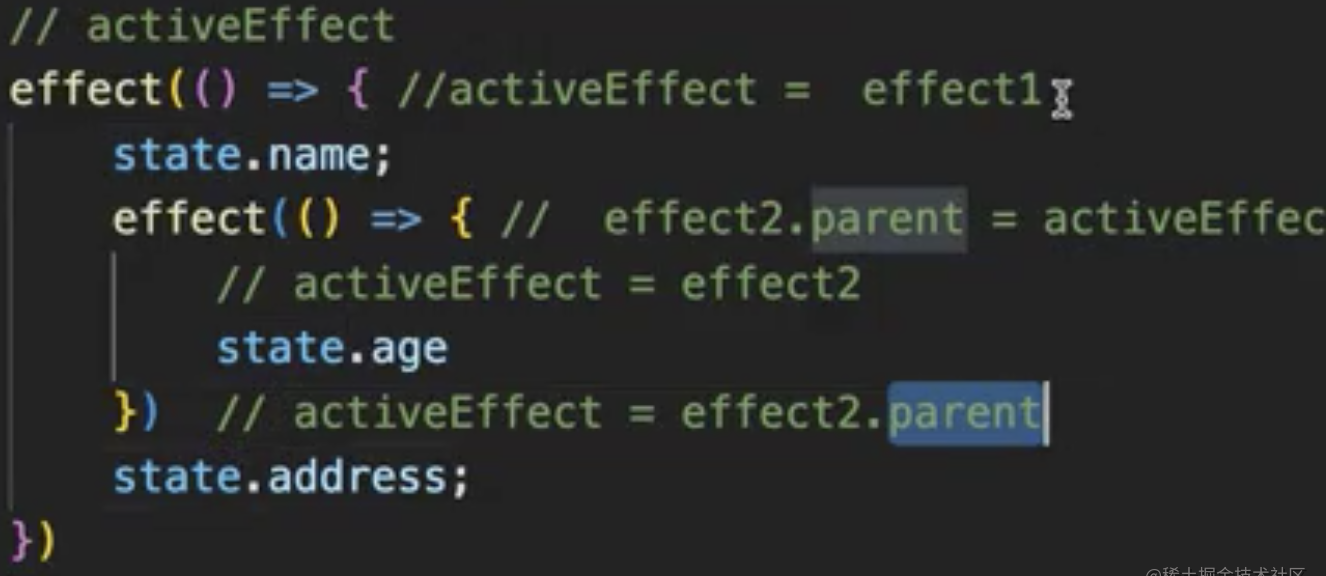
我们看下图state.address收集的标识是谁?effect1还是effect2,先执行effet1,后执行effect2,根据栈的原理最后一次执行的是effect2,不过我们用完就做了清空的处理,state.address最后是undefined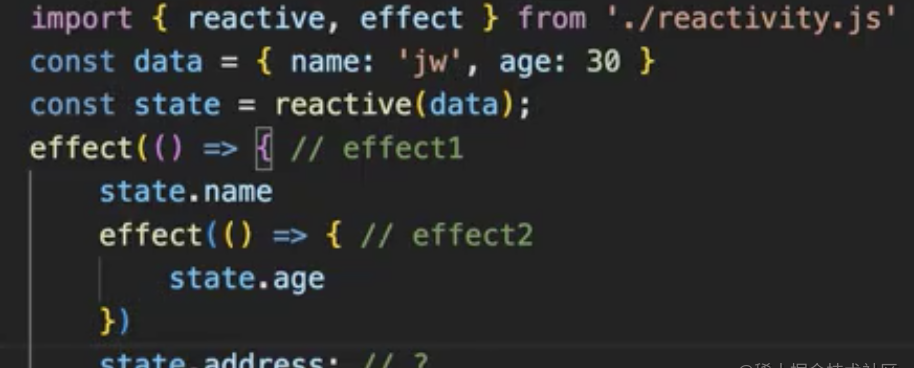
为了避免这种情况我们采用树状结构找父亲的形式,跟作用域很像,执行state.name 标识为effect1,
state.age 当前effect标识effect2,执行完之后还原成父亲,effect2.parent=>effect1 所以state.address 标识为effect1
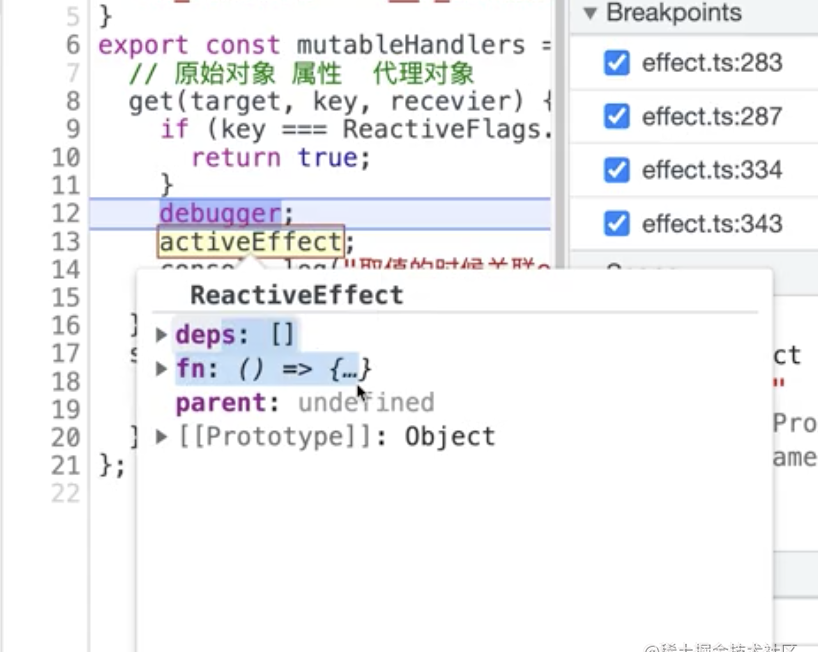
track函数的实现
我们先思考一个问题:属性和effect之间是什么关系呢?属性和effect之间是多对多的关系,effect中可以有多个属性,一个属性也可以对应多个effect,属性和effect之间的关联就叫依赖收集,当执行函数之前fn之前,已经将标识变量放在全局上了,那取值的时候就要拿到这个标识变量activeEffecttrack 让某个对象中的属性,收集当前它对应的 effect 函数,在get中收集依赖
我们先来分析一下,{name: ‘zj’, age: 18}这个对象上的name属性对应的effect是谁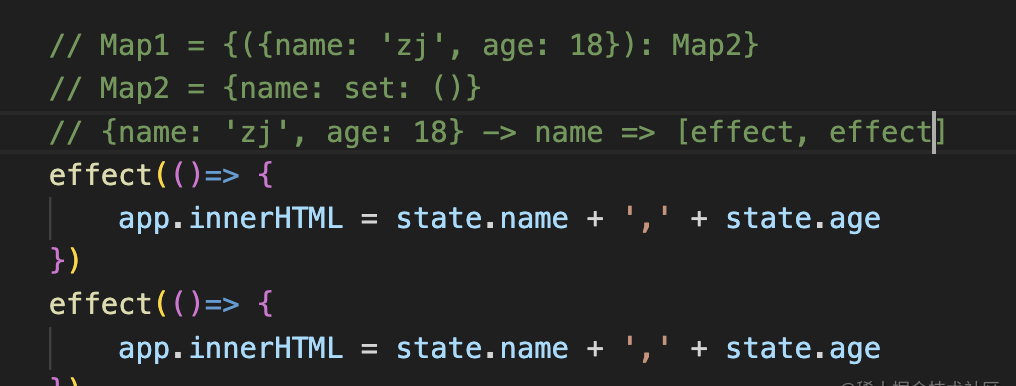
一个对象对应一个map,map里面属性对应当前的effect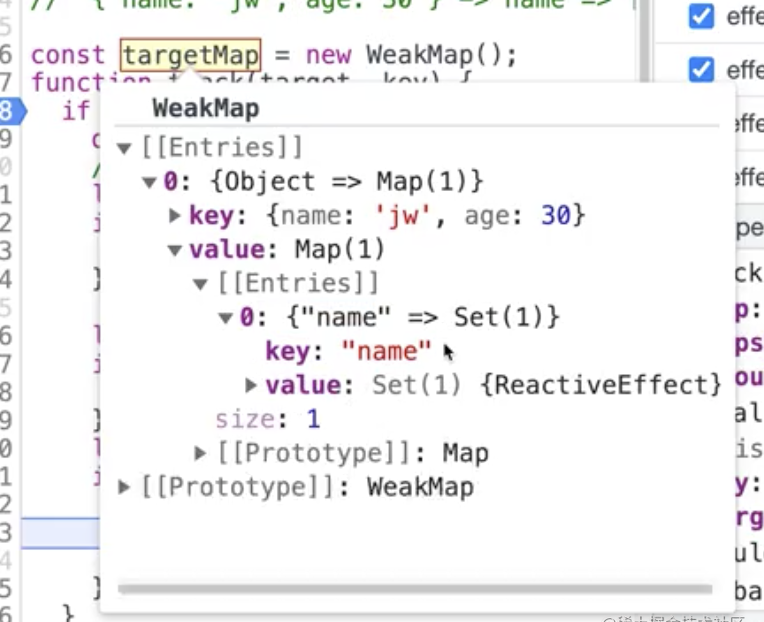
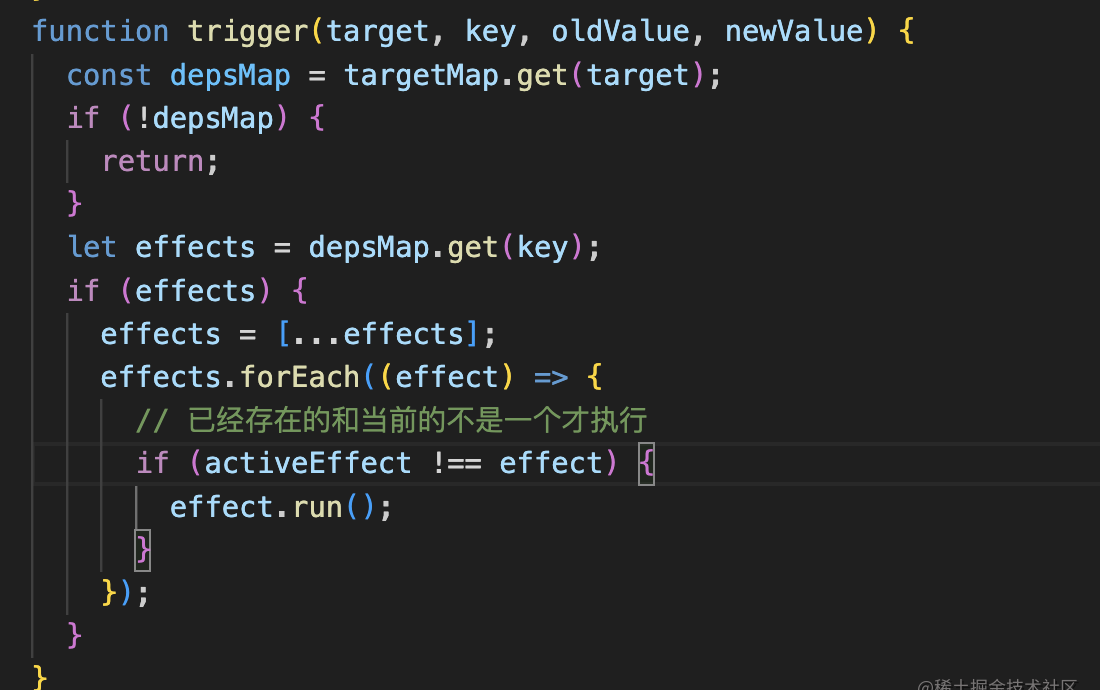
trigger 触发更新
trigger 找属性对应的 effect 让其执行 (数组,对象)
原文链接:https://juejin.cn/post/7239882475965759546 作者:会敲代码的柠檬