
一、前言
浏览器的本质就是加载外部资源、解析外部资源、面向用户展示、面向用户交互,它是一个非常复杂的应用程序,每一个tab都是一个进程,每一个进程都有自己的GPU线程、js引擎线程、网络IO线程等等。
作为web前端开发者,必然会和浏览器经常打交道,可你是否好奇过,浏览器可以通过哪些方式请求资源呢?
作为一名老练的开发者,你可能脱口而出XHR,也就是我们常用的XMLHttpRequest对象,不过通常我们会使用axios或者其他类库对XMLHttpRequest的封装进行开发。
而本文尝试探讨浏览器尽可能多的请求资源的方式,并分析他们的异同,以及为什么分这么多请求方式,以及如何利用他们来做性能优化,增加我们的面试谈资。
需要提前说明的是,相对于浏览器来说,其实本地主机的资源也算是外部资源,而本文探讨的主题是性能优化,所以下面讲的外部资源,统一都是互联网上的资源。
好了,话不多说开始吧!
二、方式
document
我们要聊到的第一个请求资源的方式是通过地址栏向互联网发起请求,通过这种方式不会存在跨域问题,或者说根本就不会有跨域这个概念,因为跨域是必须要相对于当前站点而言的,而打开一个新的tab根本就不存在当前站点更别说跨域了。
只要是合法的URL,对方服务又没有禁用你的IP,理论上来说你就可以正常请求到你想要的资源,资源的处理方式有两种。
第一种:可被浏览器解析的 浏览器会直接包装一个html帮你展现在界面上
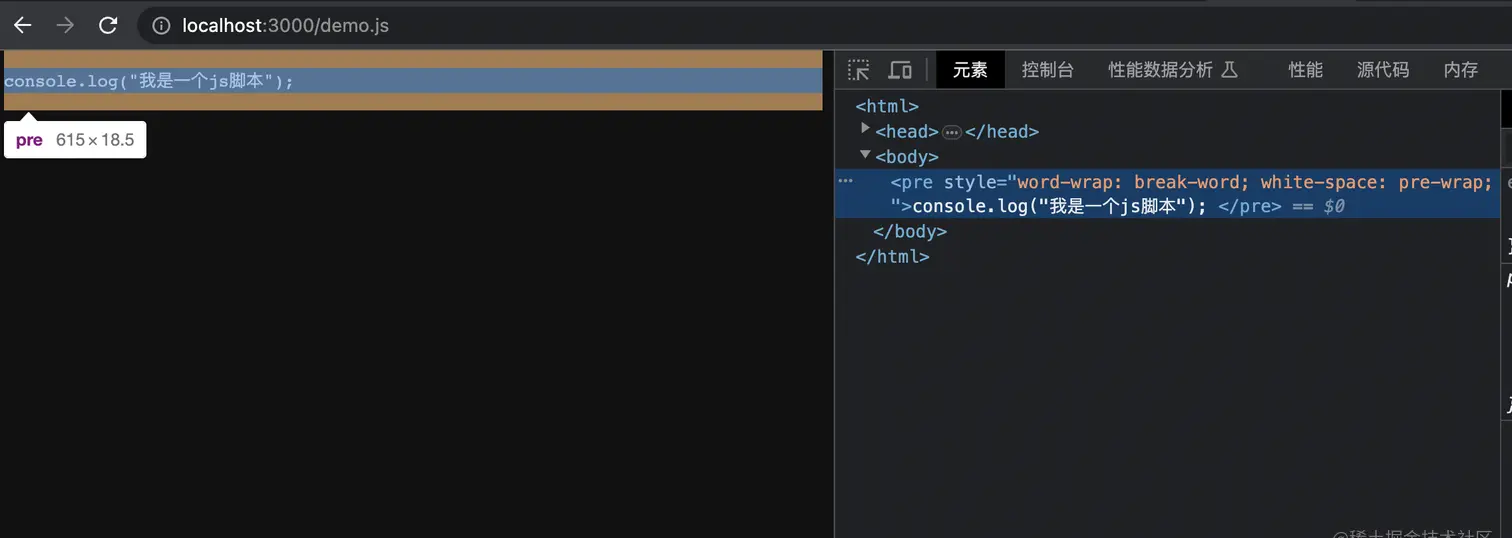

第二种:不可被浏览器解析的 浏览器会下载这个资源到本地磁盘中
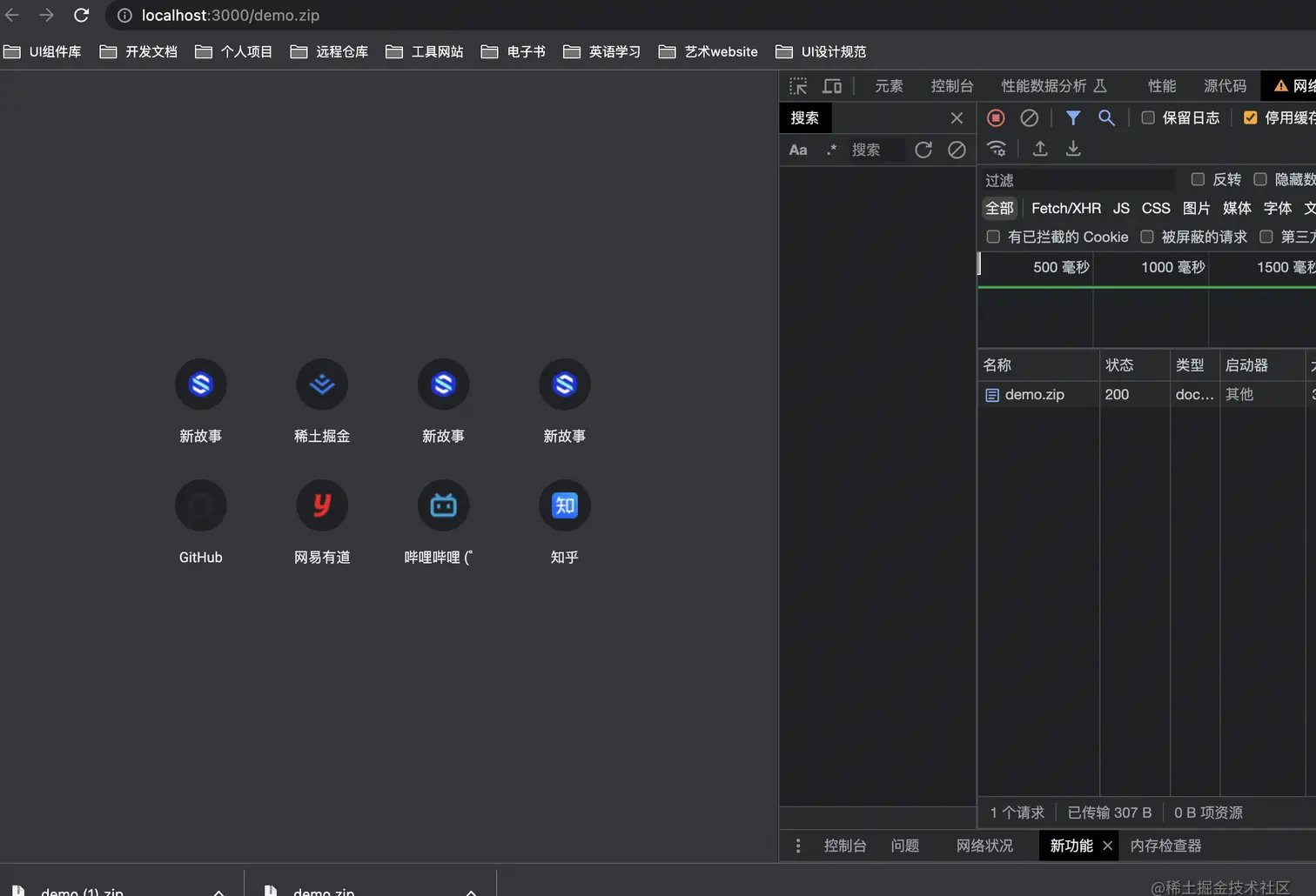
一般来说,文本类的资源都可以被查看和浏览,而特殊文件例如pdf,word、zip等都是被下载的。如果你是一个偏执狂想要查看到底哪些可以是被下载的,可以查看这篇文档,它记录了所有浏览器识别的媒体资源类型!
一般我们需要在某个站点下载某个文件的时候,就可以使用这种方式,针对某些特别的资源类型,比如.zip、.doc等就可以直接将资源URL赋值给url,利用浏览器自己的能力就可以下载该资源,如果下所示:
window.open(url, "_blank")
link – 外部资源链接元素
link标签我们都很熟悉,我们常用它来加载外部的样式,就像下面这个样子:
<link rel="stylesheet" href="/path/index.css"></link>
当我们谈论加载资源的方式的时候,可以从两个角度思考,这种方式是否可以加载所有的资源,我们是否可以对获取到的资源进行操作。
对于link标签而言它的名字叫做外部资源链接元素,它最重要的两个属性就是rel 和 href,前者指定这个外部资源和本文档的关系,后者指定外部资源的地址。其中不指定rel或者href属性这个link标签就是没有意义的,对于rel属性的取值只能取这些指定的值,我摘取了我们主要需要了解的几个属性值:
| rel | 作用 |
|---|---|
icon |
代表当前文档的图标。 |
stylesheet |
导入样式表 |
preload |
指定用户代理必须根据 as 属性给出的潜在目的地(以及与相应目的地相关的优先级),为当前导航预先获取和缓存目标资源。 |
prefetch |
指定用户代理应预先获取并缓存目标资源,因为后续的导航可能需要它。 |
接下来我们结合上面提到两个角度来看一下这个link标签。
对于link标签,只要上面的4个属性,是可以加载所有类型的资源的,不行我们将rel指定为stylesheet,我们甚至可以加载后缀为.exe类型的资源。
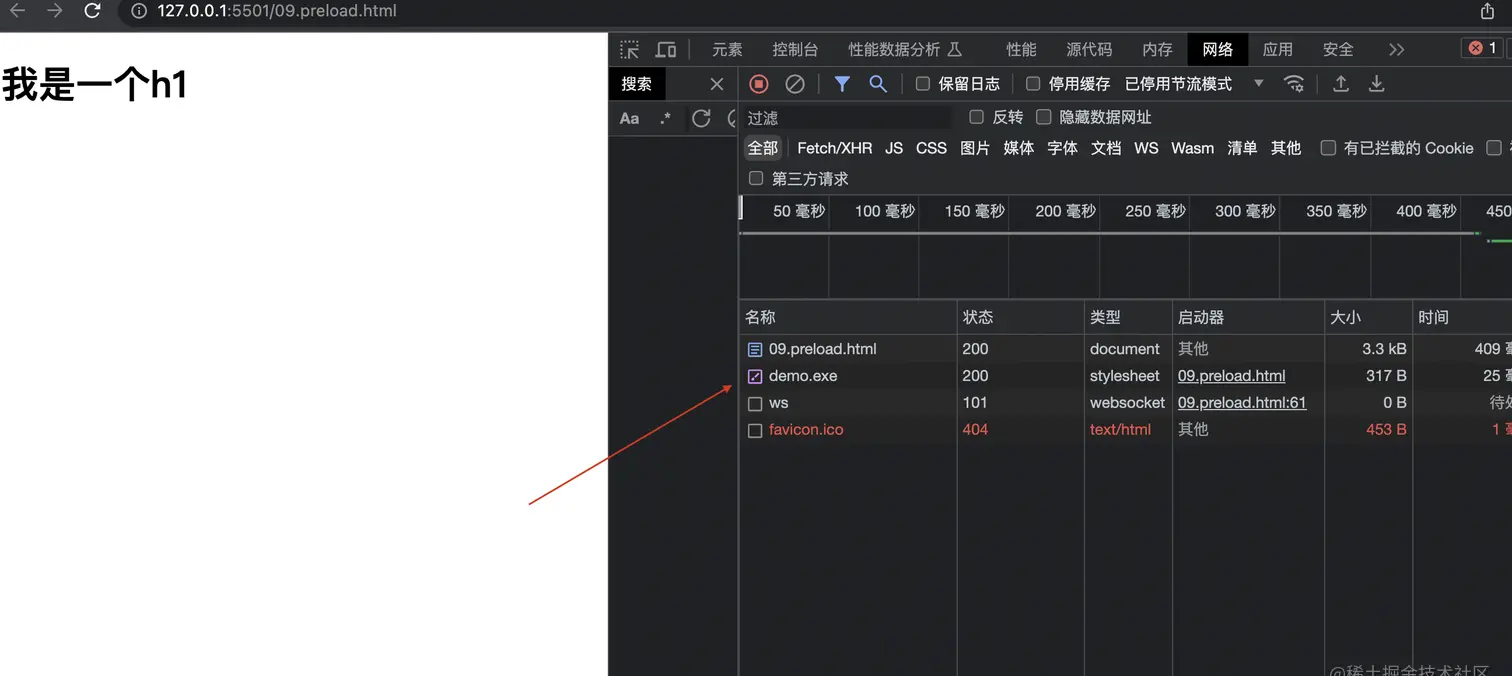
但是因为我们指定的是stylesheet类型的,所以浏览器只会识别Content-Type为text/css类型的资源,其他资源一律都会静默失败。
对于link标签而言,我们不可以对获取到的资源进行操作。加载的元数据不会暴露给用户,所以用户只能知道资源被加载了,但是无法操作。
当我们把rel指定为preload的时候,那么意味着这个资源会被以最高的优先级进行下载,在html预解析的时候就会进行下载了,但是不会立马执行,等到用到这个资源的时候直接从下载好的资源中拿就好了,而不用在这个时候才开始下载,所以一般我们可以使用这个进行性能优化。
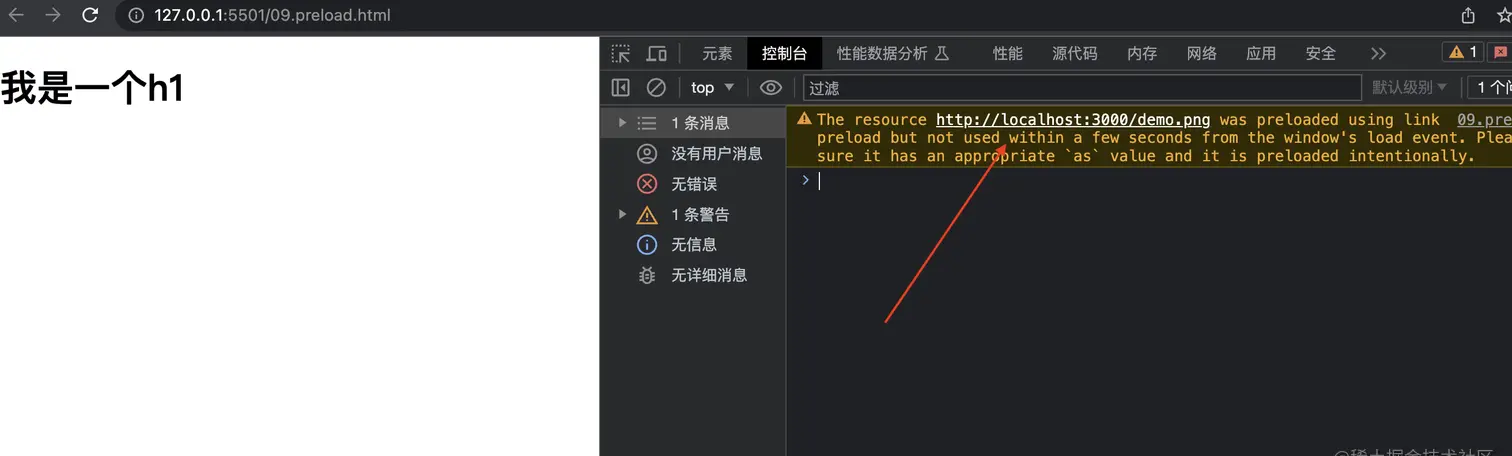
当我们把rel指定为prefetch的时候,意味着浏览器会在空闲的时候下载这个资源,等将来有一天用到这个资源的时候,则直接在缓存中拿取,它和preload的区别就是,preload的资源是在当前页面会用到的,而prefetch在将来的某一个才会被用到。如果一个资源被preload了,但是却没有在当前页面用到的话,浏览器会这样提示我们:
script
这个标签对于大多数开发者来说是再熟悉不过了,它也是一种请求资源的方式,不过仅限于加载javascript的资源。区别就是script加载资源过后会帮我们把这个资源交给js引擎去执行,从而实现相应的逻辑。
它有几个核心的属性:
async:
这个属性是可以使得js资源可以并行的进行下载,也就是说如果我们不加上这个资源,那么在下载的这段时间,其实也会阻塞余下DOM的解析和渲染,但是加上这个属性之后,在下载的这段时间和DOM渲染是并行的,不会阻塞DOM的渲染。口说无凭,我们来个例子证明一下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<h1>script之前的DOM</h1>
<script src="http://localhost:3000/demo.js"></script>
<!-- <script async src="http://localhost:3000/demo.js"></script> -->
<h1>script之后的DOM</h1>
</body>
</html>
然后我开启浏览器的节流模式使得网络问题更明显:
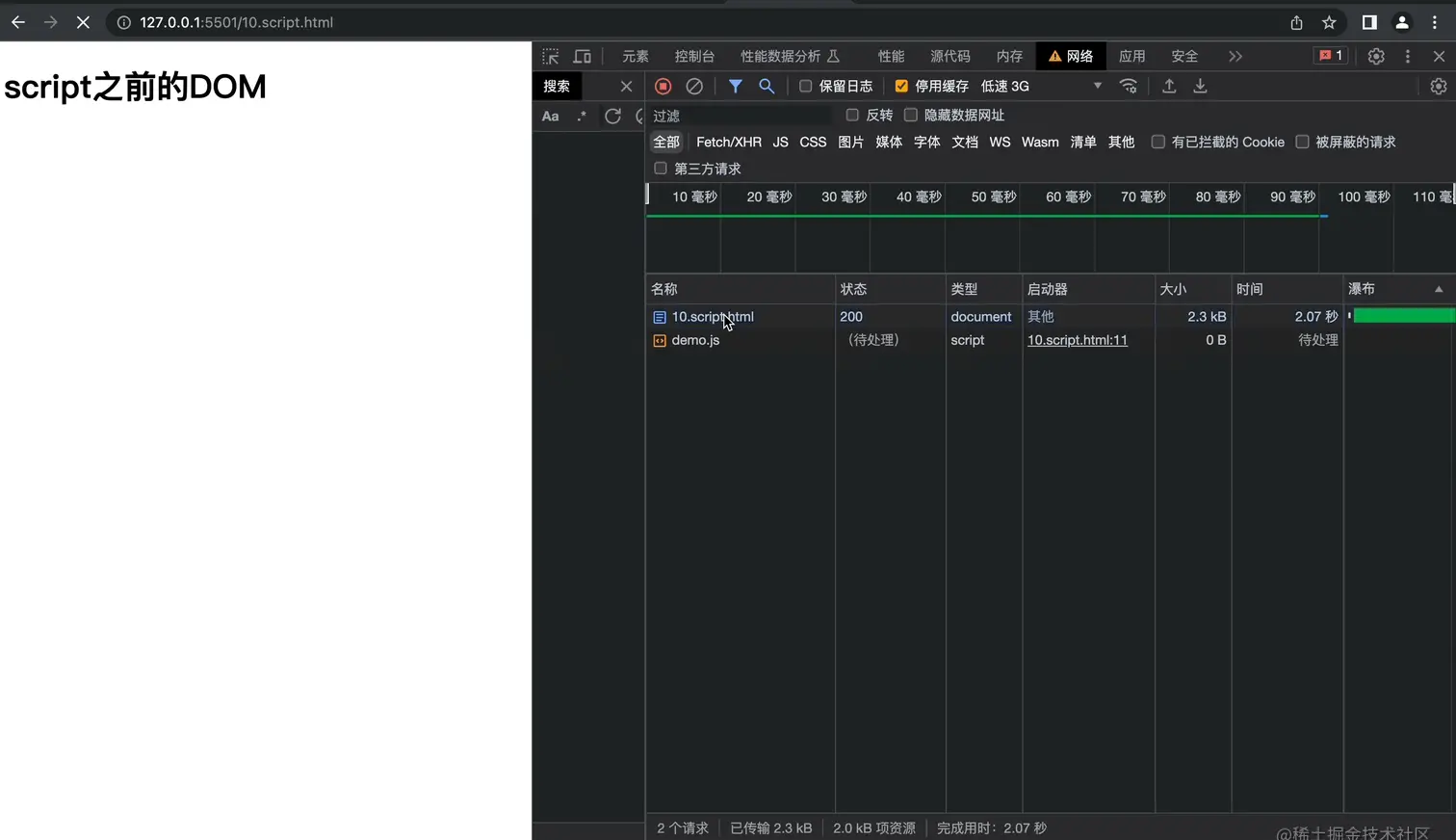
开启async之后的效果看一下:
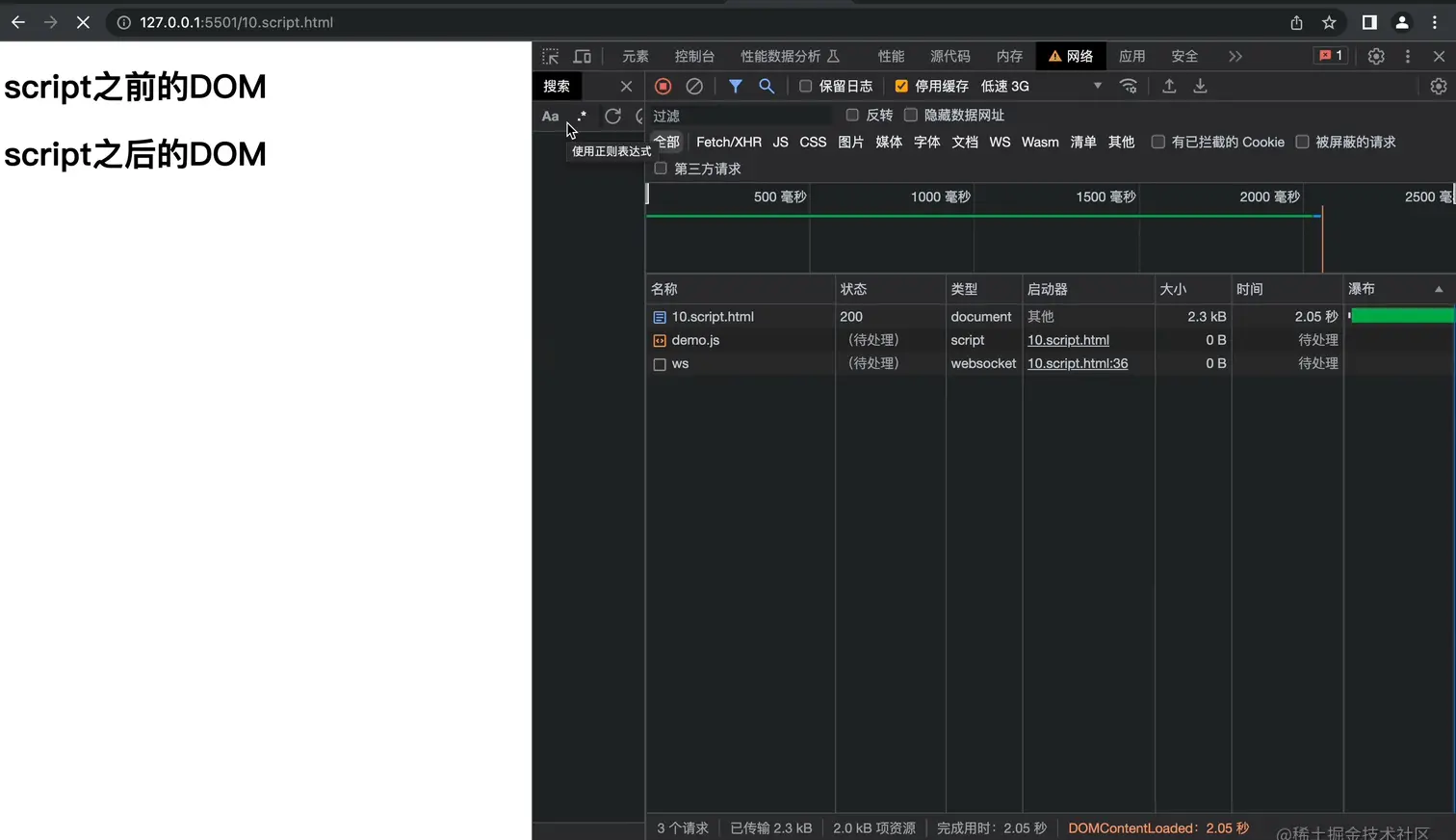
可以在下载资源的过程不会阻塞DOM的解析和渲染,如果我们js脚本不会改变DOM只是做一些计算任务,那么使用async就会特别划算。
defer:
这个布尔属性的设置是为了向浏览器表明,该脚本是要在文档被解析后,但在触发 DOMContentLoaded 事件之前执行的。
包含 defer 属性的脚本将阻塞 DOMContentLoaded 事件触发,直到脚本完成加载并执行。
温馨提示:本属性不应在缺少
src属性的情况下使用(也就是内联脚本的情况下),这种情况下将不会生效。
defer 属性对模块脚本也不会生效——它们默认是 defer 的。
包含 defer 属性的脚本会按照它们出现在文档中的顺序执行。
这个属性能够消除阻塞解析的 JavaScript,在这种情况下,浏览器必须在继续解析之前加载和执行脚本。async 在这种情况下也有类似的效果。
iframe
如果说link是用来获取css资源,script标签用来获取js资源,那么iframe标签就是专门用来获取html资源的,而前端的基石就是html文件,html中又可以存在属于自己的js和css,这样嵌套下去就可以构成繁杂的前端界面。
iframe标签最重要的属性就是src,我们可以指定同源的或者非同源的。
iframe为我们提供了天然的隔离环境,一个父域的iframe和子域的iframe的样式和脚本互不影响。这就为微前端的实现提供了一种新的思路。因为我们完全使用任意的前端框架开发子应用然后嵌入主应用就可以,只需要维护子应用和主应用之间的通信就可以。
通信
如果我们的嵌套的iframe和主站点是同源的,那么其实可以共享本地存储和会话存储空间,这样即可实现通信。
如果是非同源的,那么可以借助postMessage这个api进行通信
由于本篇主要是介绍浏览器获取资源的方式,通信可以参考这篇文章,或者这篇文章。
虽然iframe为我们提供了天然的隔离环境,但是实际上他们的线程还是共用同一个GUI线程以及JS执行线程。我们可以通过一个实验验证一下!
一个主站点:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
@keyframes ani1 {
50% {
transform: rotate(360deg);
transform-origin: 60px;
}
}
.title {
animation: ani1 5s infinite;
}
</style>
</head>
<body>
<div>
<h1 class="title">我是father</h1>
<iframe
src="http://127.0.0.1:3000/demo.html"
frameborder="0"
allowfullscreen
></iframe>
</div>
</body>
</html>
一个子站点:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
@keyframes ani1 {
50% {
transform: rotate(360deg);
transform-origin: 60px;
}
}
.title {
animation: ani1 5s infinite;
}
</style>
</head>
<body>
<div>
<h1 class="title">我是son</h1>
<button onclick="block()">阻塞</button>
<script>
const block = () => {
const now = new Date().getTime();
while (Date.now() - now < 5000) {}
};
</script>
</div>
</body>
</html>
他们是不同源的,当我们点击子域的阻塞按钮时,它一定会阻塞子域的css动画,因为js线程和GUI线程是互斥的,但是否会阻塞父域的动画呢?如果阻塞说明他们的GUI线程是共用的,否则就不是,我们一起来看一下吧!
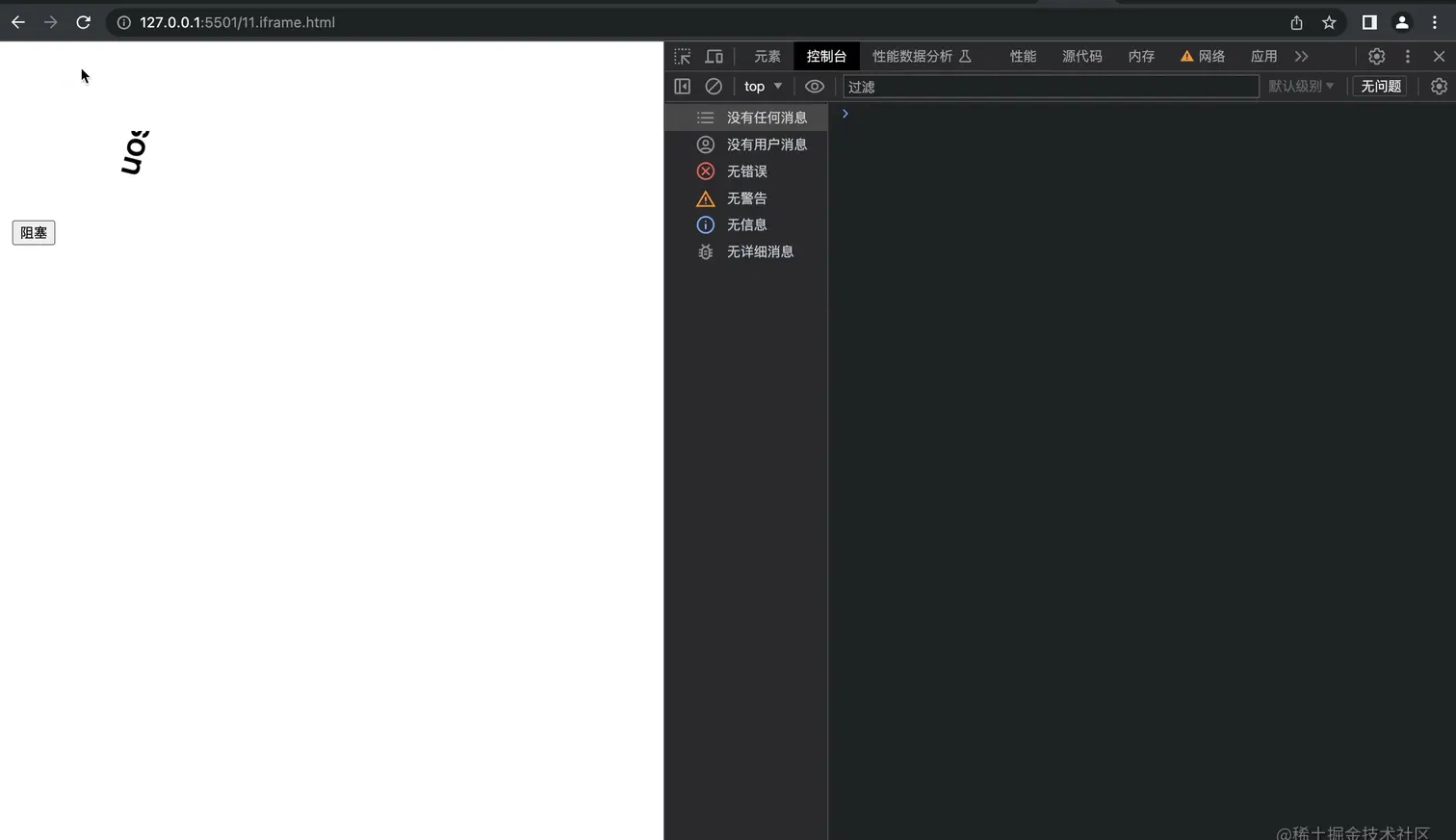
这恰恰说明了如果希望将iframe作为webWorker的平替方案是不现实的。
img/audio/video
进入媒体时代之后,我们在web上呈现的内容可以说是五花八门,因此浏览器也为我们提供了诸多可以解析媒体资源的标签,他们分别就是图片/音频/视频,对应的标签就是img/audio/video。
本篇文章主要谈论img标签的处理方式,因为它是我们使用可能最广泛的。
Web 最常用的图像格式是:
- APNG(动态可移植网络图形)——无损动画序列的不错选择(GIF 性能较差)。
- AVIF(AV1 图像文件格式)——静态图像或动画的不错选择,其性能较好。
- GIF(图像互换格式)——简单图像和动画的不错选择。
- JPEG(联合图像专家组)——有损压缩静态图像的不错选择(目前最流行的格式)。
- PNG(便携式网络图形)——对于无损压缩静态图像而言是不错的选择(质量略好于 JPEG)。
- SVG(可缩放矢量图形)——矢量图像格式。用于必须以不同尺寸准确描绘的图像。
- WebP(网络图片格式)——图像和动画的绝佳选择
以上的图片资源格式都可以被img标签所识别解析在浏览器上供用户观看,我们还是从两个角度去理解img标签。
它是否可以加载所有的资源,答案是否定的,它只能加载图片类型的资源,或者是带有图片信息的base64的字符串信息。其他则不能被img标签解析。
那么该如何将一个url转为base64呢,可以参看我的这一篇文章。另外一个角度就是我们是否可以操作图片数据资源呢!
其实是可以的,但是有个条件,我们必须使用CORS策略来请求img资源,只有我们保证资源的安全的我们才可以操作这些数据。
XMLHttpRequest/Fetch
以上我们讲述了浏览器可以通过多种标签的形式请求外部资源,但是发现没有!所有的形式都是浏览器针对不同资源类型而定义的标签,比如img来服务图片资源,script专门来服务js资源等等…这些标签也内置了处理资源的方式,比如img标签拿到图片资源后一定需要一点点去计算这些像素信息,调用GUI线程将其绘制到页面上,而script标签一定是加载好js脚本之后,判断是否为js脚本,如果是则调用js引擎线程执行脚本。
以上的方式都遵循一个范式:
加载资源(可以跨域) -> 以指定的方式进行处理
而接下来我们要讲到的就是虽然不能跨域的,但是却留给了开发者极大自由度的一种方式来请求资源。
他们就是XMLHttpRequest/Fetch。他们的用法都是大同小异,但是核心理念其实都是一样的。
那就是提供了一个开放的接口,这个接口可以帮助开发者使用js脚本,发送一个同源的请求,同源是为了保证数据的安全,然后将请求的数据暴露给开发者,开发者可以自己定义处理的方式。
我们举个简单的例子:
同样是请求一段js脚本,如果我们如果通过script标签的方式,我们没办法在这之间做任何事情,script标签加载之后,就直接执行了。
但是我们可以通过请求的方式拿到相应的字符串,然后判断这个字符串,甚至修改逻辑都是可以的。对于图片来说我们可以拿到数据流,甚至修改像素信息,这些就是数据的可见性和不可见性的区别。而作为开发者,我们始终重视是否可以得到数据可见性的数据是很重要的,这种有更强的控制能力。对于暴露出去的接口,我们尽可能的降低数据可见性是很有必要的,因为这样更加的安全。
三、最后的话
其实我们会发现浏览器的设计原则其实是比较理性的,如果我们选择跨域,则处理的方式则必须固定,这样可以保证浏览器将处理的方式限定,提高系统安全性。如果我们选择不跨域,浏览器则会给我们留更多的空间去窥探数据,只要符合CROS那么浏览器就认为这个是安全的内容,这怎么不是一种平衡的哲学呢!
shell、bash、zsh、powershell、gitbash、cmd这些到底都是啥?
从0到1开发一个浏览器插件(通俗易懂)
用零碎时间个人建站(200+赞)
更多精彩内容请访问我的个人网站 new-story.cn
创作不易,如果您觉得文章有任何帮助到您的地方,或者触碰到了自己的知识盲区,请帮我点赞收藏一下,或者关注我,我会产出更多高质量文章,最后感谢您的阅读,祝愿大家越来越好。
原文链接:https://juejin.cn/post/7244818841502777401 作者:Story