

Node.js 的事件循环是其核心特性之一,它对于 Node.js 的性能、并发处理能力和整体设计都有着深远的影响,它决定了如何调度任务、何时执行回调以及如何管理并发。因此对事件循环的深入了解可以帮助我们避免常见的陷阱,更好地利用 Node.js 的异步特性。本文着重介绍 Node.js 中的事件循环机制、process.nextTick()和微任务等。
什么是事件循环
事件循环机制允许 Node.js 执行非阻塞 I/O 操作,它通过将操作转移给操作系统来实现 I/O 处理。现代内核大多数是多线程的,因此可以在后台处理多个操作。当其中一个操作完成时,内核会告诉 Node.js 操作已完成,这时对应的回调函数就可以被添加到轮询队列中,最终回调会被执行。
默认情况下,Node.js 在主线程上执行所有代码,主线程持续运行事件循环来执行 JavaScript 代码块。每个块都是一个回调,这可以被看作是一个协作调度的任务。其中第一个任务包含启动 Node.js 的代码(例如可能来自模块或者标准输入),其他任务则在随后的运行中被添加进来。整个事件循环可以粗略的概括成下面这样:
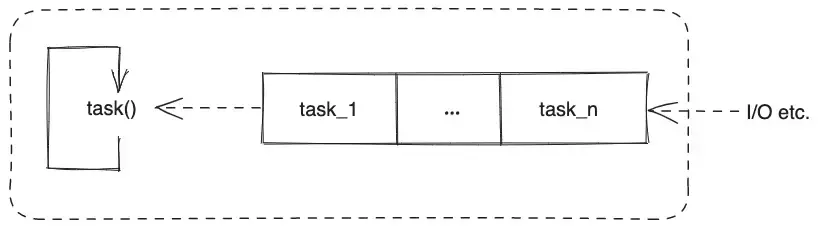

主线程运行的代码看起来像是这样:
while (true) { // event loop
const task = taskQueue.dequeue(); // blocks
task();
}
事件循环从任务队列中取出回调并在主线程执行该回调,当任务队列为空时 taskQueue.dequeue() 阻塞。
添加任务到队列
可能将回调添加到任务队列的情况如下:
- JS 代码执行:JavaScript 代码可以将任务添加到队列中,以便后续执行。
- 事件触发:当事件触发器(也就是事件的来源)触发事件,事件监听的调用会被添加到任务队列。
- Node.js API 中基于回调的操作:
- 我们请求某些东西(例如网络资源、文件内容),并给 Node.js 一个回调,该回调可以告诉我们最终的执行结果;
- 该操作要么在主线程中进行,要么在外部线程运行;
- 当执行完成,回调的调用添加到任务队列中。
下面是一个在 Node.js 中读文件的例子:
import { readFile } from 'node:fs';
readFile('/etc/passwd', 'utf8',(err, data) => {
if (err) {
throw err;
}
console.log(data);
});
readFile 操作会在另一个线程中读文件,当文件读取成功后,回调会被添加到任务队列中。
为什么是主线程而不是主进程?
在解释之前我们先回顾一下线程和进程的关系和区别:
进程(Process)
- 定义:进程是一个独立的执行实体,它拥有自己的私有地址空间。每个进程都有自己的一组完整的资源,如内存、CPU 时间片、I/O 等。
- 资源共享:进程之间不共享内存空间和资源,这为它们提供了隔离。这意味着一个进程崩溃不会影响其他进程。
- 创建和终止:创建或终止进程通常比线程更为耗时和资源密集。
- 通信:进程之间的通信 (IPC) 相对复杂,常用的方法有管道、消息队列、共享内存等。
- 独立性:进程是完全独立的,它们不依赖于其他进程。
- 上下文切换:进程之间的上下文切换通常比线程之间的上下文切换更为耗时。
线程(Thread)
- 定义:线程是进程内的一个执行单元。一个进程可以有一个或多个线程。所有线程共享该进程的地址空间和资源。
- 资源共享:同一进程内的所有线程共享相同的内存空间和资源。这使得线程之间的通信更为高效,但也意味着一个线程的错误可能会影响同一进程中的其他线程。
- 创建和终止:创建或终止线程相对更为快速和轻量。
- 通信:线程之间的通信更为简单,因为它们共享相同的地址空间。
- 独立性:线程是进程的一部分,它们的执行依赖于所属的进程。
- 上下文切换:线程之间的上下文切换通常更为快速。
我们知道 Node.js 运行 JavaScript 保持了在浏览器中单线程的特点。Node.js 本身运行在一个进程中,当我们说 Node.js 是单线程时,是指它在这个进程中只使用一个线程来执行 JavaScript 代码,这就是我们上面提到的“主线程”,而 Node.js 的非阻塞特性及事件循环机制也是在这个单一线程实现的。
虽说 Node.js 运行 JavaScript 是单线程的,但是并不是说 Node.js 只能运行单线程,如果想要创建新的线程,可以使用 Node.js 内置的 Worker threads 模块。而如果想要创建新的进程,可以使用 Node.js 内置的 Cluster 、Child process 模块。
真实的事件循环
真实的事件循环拥有多个任务队列,它在多个阶段中从这些队列中读取任务。其中比较重要的几个阶段如下:
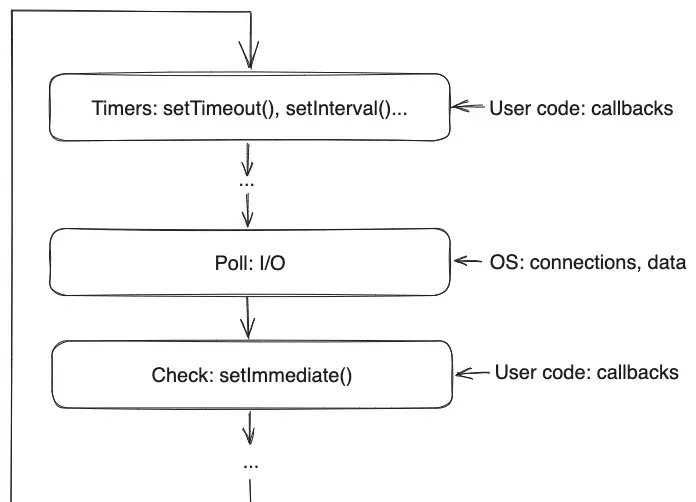
- Timers:调用已添加到队列中的定时任务:
setTimeout(task, delay = 1)在延迟 1 毫秒后运行回调任务setInterval(task, delay = 1)每隔 1 毫秒运行一次回调任务
- Poll:检索和处理 I/O 事件,并从队列中运行 I/O 相关的任务
- Check:立即执行阶段,执行通过以下方式安排的任务:
setImmediate(task)尽快运行回调任务(在 poll 之后立即执行)
每个阶段在满足以下两个条件之一就可以结束:
- 当前阶段的队列为空
- 当前阶段处理的任务数量等于最大数量
**注意:**每个阶段运行期间新添加的任务都会等到下一轮再执行,但是 “Poll” 阶段除外。
对于 “Poll” 阶段,需要注意以下几点:
- 如果 Poll 队列不为空,则轮询阶段运行它的任务;
- 如果 Poll 队列为空:
- 如果有
setImmediate()任务,事件循环将结束 “Poll” 阶段并进入 “Check” 阶段; - 如果没有
setImmediate()任务,事件循环将检查被添加到队列的计时器任务,如果一个或多个计时器准备就绪,事件循环将回到 “Timer” 阶段,执行这些计时器的回调。
- 如果有
- 如果此阶段耗费的时间超过操作系统的时间限制,则它结束并运行到下一个阶段。
注意:定时任务(如
setTimeout、setInterval)中指定的时间其实是任务最早的运行时间,这个时间并不精准,当遇到长时间运行的任务时,可能会导致 time task 运行延迟。
Next-tick 任务和微任务
在每次任务处理之后,会运行一个”子循环“,这个”子循环“包含两个阶段:
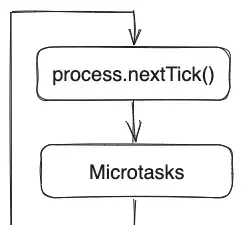
其中 Next-tick 任务是 Node.js 独有的,也就是 process.nextTick(),而 Microtasks 是跨平台的 Web 标准,包含 Promise、queueMicrotask() 等。这里简单说明一下:queueMicrotask() 是一个方法,它允许你直接将一个任务添加到 microtask 队列中,详细的使用可以参考:queueMicrotask() global function – Web APIs | MDN 。
子循环会一直运行直到队列为空。在运行期间添加的任务会立即处理,不会像上面主循环流程那样等到下一轮再处理。
综上所述,事件循环整体看来是这样的:

根据以上执行规则,我们很容易看到下面这段代码的执行结果如下:
function enqueueTasks() {
Promise.resolve().then(() => console.log('Promise reaction 1'));
queueMicrotask(() => console.log('queueMicrotask 1'));
process.nextTick(() => console.log('nextTick 1'));
setImmediate(() => console.log('setImmediate 1')); // (A)
setTimeout(() => console.log('setTimeout 1'), 0);
Promise.resolve().then(() => console.log('Promise reaction 2'));
queueMicrotask(() => console.log('queueMicrotask 2'));
process.nextTick(() => console.log('nextTick 2'));
setImmediate(() => console.log('setImmediate 2')); // (B)
setTimeout(() => console.log('setTimeout 2'), 0);
}
console.log('----setImmediate task result---\n')
setImmediate(enqueueTasks);
console.log('----setTimeout task result---\n')
setTimeout(enqueueTasks, 0);
## setImmediate task result
nextTick 1
nextTick 2
Promise reaction 1
queueMicrotask 1
Promise reaction 2
queueMicrotask 2
## 注意这里的顺序区别
setTimeout 1
setTimeout 2
setImmediate 1
setImmediate 2
## setTimeout task result
nextTick 1
nextTick 2
Promise reaction 1
queueMicrotask 1
Promise reaction 2
queueMicrotask 2
## 注意这里的顺序区别
setImmediate 1
setImmediate 2
setTimeout 1
setTimeout 2
可以看到,不同的启动方式输出的 setTimeout 和 setImmediate 顺序不同。这里解释一下:
setImmediate(enqueueTasks)启动程序后的执行顺讯如下:- 事件循环首先进入
timers阶段,没有任务,进入下一阶段; - 往下走直到
check阶段,调用enqueueTasks,完成后进入下一轮; - 在新一轮事件循环中首先执行子循环,输出
nextTick、Promise、queueMicrotask; - 进入
timers阶段执行setTimeout,输出setTimeout 1、setTimeout 2; - 最后进入
check阶段,执行setImmedate,输出setImmediate 1和setImmediate 2。
setTimeout(enqueueTasks, 0)启动程序后的执行顺序:
- 事件循环首先进入
timers阶段,执行setTimeout(enqueueTasks, 0)的回调enqueueTasks,执行完该阶段后在进入下一阶段; - 执行子循环,输出
nextTick、Promise、queueMicrotask; - 进入主循环
check阶段,执行setImmediate,输出setImmediate 1、setImmediate 2,至此完成一次循环,进入下一个事件循环; - 开始新的事件循环,进入
timers阶段,执行setTimeout,输出setTimeout 1、setTimeout 2。
- 事件循环首先进入
饿死事件循环
基于上面对 next-tick 和微任务的理解,我们可以看到递归调用它们可能导致事件循环饿死,使后续无法执行。看下面这段代码:
import * as fs from 'node:fs/promises';
function timers() { // OK
setTimeout(() => timers(), 0);
}
function immediate() { // OK
setImmediate(() => immediate());
}
function nextTick() { // starves I/O
process.nextTick(() => nextTick());
}
function microtasks() { // starves I/O
queueMicrotask(() => microtasks());
}
timers();
console.log('AFTER'); // always logged
console.log(await fs.readFile('./file.txt', 'utf-8'));
- 代码中
timers()和immediate()不会饿死fs.readFile()(fs.readFile()在 “Poll” 阶段调用返回),因为在 “timers” 阶段和 “check” 阶段只是将对应的任务入队,并不执行。 - 由于 next-tick 任务和微任务的调度方式,
nextTick()和microtasks()都会阻止最后一行的输出,导致fs.readFile()饿死。
理解 process.nextTick()
process.nextTick(callback[, ...args])
process.nextTick() 将回调添加到 “next tick 队列”,严格从技术上来说,process.nextTick() 不属于事件循环,因为无论当前事件循环处于哪个阶段,“next tick 队列”都会在当前 JavaScript 堆栈上的操作完全执行结束后、事件循环继续之前被完全清空。
使用 process.nextTcik() 的原因如下:
- 允许用户处理 error,清除任何不需要的资源,或者在事件循环之前重试请求;
- 保证代码行为的一致性,API 始终被异步调用,这也是 Node.js 的设计哲学之一:API 应该始终是异步的,即使它不一定是异步的;
- 在某些情况下,开发者可能需要递归地调用一个异步函数。使用
process.nextTick()可以避免 JavaScript 调用堆栈过深,从而避免堆栈溢出。
下面举一个保证一致性的例子:
import { stat } from 'node:fs';
// WARNING! DO NOT USE! BAD UNSAFE HAZARD!
function maybeSync(arg, cb) {
if (arg) {
cb();
return;
}
stat('file', cb);
}
当我们以下面这样的形式调用时可能存在问题:
const maybeTrue = Math.random() > 0.5;
maybeSync(maybeTrue, () => {
foo();
});
bar();
上面这样的调用方式可能有下面两种可能:
- 如果
arg为真,它会同步地调用回调函数cb。 - 如果
arg为假,它会异步地调用stat,并在完成时调用回调函数cb。
这意味着,根据 arg 的值,foo() 可能在 bar() 之前或之后被调用。这种不确定性可能会导致难以追踪的错误,因为函数的行为取决于它的输入。
而如果我们以下面这种方式定义函数,则可以保证回调 cb 总是被异步调用:
import { nextTick } from 'node:process';
function definitelyAsync(arg, cb) {
if (arg) {
nextTick(cb);
return;
}
fs.stat('file', cb);
}
同样的两种情况:
- 如果
arg为真,它不会立即调用回调函数cb,而是使用nextTick将其推迟到下一个微任务队列中。 - 如果
arg为假,它的行为与maybeSync相同:异步地调用fs.stat并在完成时调用回调函数cb。
无论 arg 的值如何,definitelyAsync 函数都确保回调函数 cb 总是异步地被调用。这提供了一致的行为,保证了无论 arg 是真是假 bar() 预定在 foo() 之前调用。
完整的事件循环
上面我们提到在事件循环中比较重要的几个阶段:timers、poll、check,但根据 Node.js 官方文档,其实完整的事件循环还包括其他阶段,完整的事件循环如下:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
- timers: 这个阶段执行由
setTimeout()和setInterval()安排的回调函数。 - pending callback:处理那些延迟到下一个循环迭代的 I/O 回调。举个例子,当尝试使用已在使用中的端口进行绑定时会报错,对于这类错误,回调将被延迟到该阶段。需要注意的是,大多数 I/O 回调是在 poll 阶段处理的。
- idle,prepare:仅在 Node.js 内部使用。
- poll:检索新的I/O事件,执行I/O相关的回调。
- check:
setImmediate()的回调在这里被执行。 - close callback:处理一些 close 回调,例如
socket('on', ...)。
Node.js app 退出
只要 Node.js 程序执行,事件循环就会一直进行,那么 Node.js 什么时候知道自己该退出了?其实在每次事件循环迭代的最后,Node.js 都会检查它是否应该退出。它为定时任务设置引用计数:
- 通过
setImmediate()、setInterval()、setTimeout()添加定时任务会增加引用计数; - 运行定时任务会减少引用计数。
当引用计数在事件循环迭代的最后为零时,Node.js 退出。
例如下面这段代码(执行这段代码需要使用 Node.js module,文件后缀 .mjs),在 A 行有 setTimeout(resolve, ms),所以事件循环会等待其执行完成后引用计数归零并退出。
function timeout(ms) {
return new Promise(
(resolve, _reject) => {
setTimeout(resolve, ms); // (A)
}
);
}
await timeout(3_000);
而如果只是 Promise 的调用不会增加引用计数,例如下面这段代码:
function foreverPending() {
return new Promise(
(_resolve, _reject) => {}
);
}
await foreverPending(); // (A)
虽然 Node.js 程序也会退出,但是其退出属于异常退出,退出代码是 13 而不是 0。要想看到退出码,可以使用 shell 脚本。假设我们的测试文件为 testEventLoop.mjs,可以使用如下 shell 脚本运行代码,可以看到会输出 13。
#!/bin/bash
node testEventLoop.mjs
echo $?
更多关于 Node.js 退出代码可以参考官方文档:Node.js exit-codes。
总结
以上就是 Node.js 事件循环的全部内容。Node.js 的事件循环是其非阻塞 I/O 操作的核心,使其能够在单线程中高效地处理大量并发任务。事件循环按照特定的阶段顺序执行,每个阶段都有其特定的任务队列,在这些阶段中,重要的有三个阶段:“timers”、“poll“、”check“,同时也要记得在每个阶段开始前,要看是否有子循环(next-tick 和微任务),如果有子循环则优先执行子循环。只要开始运行 Node.js app,事件循环就会一直运行,为了能知道什么时候退出程序,Node.js 维护了一个定时任务的引用计数,当引用计数为零时,Node.js app 就会退出。
参考
原文链接:https://juejin.cn/post/7267167108609015871 作者:raymond