
NodeJS默认是异步的,这意味着它已经能够同时处理多个请求,但它只适用于I/O操作,如HTTP请求、文件系统操作、数据库查询、实时聊天应用等。在处理CPU密集型任务时,可能需要很长时间,这就是为什么NodeJS提供了一些我们将在下面介绍的特定包。
因此,以下是您可以在NodeJS API中实现的一些方法的摘要:
系好安全带,这将是一个相当长且饱含内容的文章
Redis缓存


如果你有一组数据在加载应用程序时经常需要获取,你可能希望将这些数据缓存起来,而不是发送HTTP请求或运行查询。这就是为什么我建议你使用Redis。它非常简单易用。它基本上是另一个与主数据库分开的数据库,用于存储所有缓存数据。
您需要在系统上安装Redis,并可以使用以下代码与Redis进行交互。
user@username:/mnt/c/Users/HP$ sudo service redis-server start
user@username:/mnt/c/Users/HP$sudo service redis-server-start
user@username:/mnt/c/Users/HP$redis-cli
user@username:/mnt/c/Users/HP$set mykey "hello"
user@username:/mnt/c/Users/HP$get mykey
现在要在您的NodeJS应用程序中使用它,您需要安装redis包,并在名为redis.js的文件中创建一个redis客户端的实例(您可以随意命名)。
import redis from 'redis'
const PORT = process.env.REDIS_URL || 'redis://localhost:6379'
const client = redis.createClient({
url: PORT
})
await client.connect()
client.on('error', (error) => {
console.error('Redis client error:', error);
});
client.on('connect', (err) => {
console.log('Connected to redis')
})
export default client
完成上述步骤后,您可以通过简单地编写以下代码来导入客户端并设置一个键
await client.set('mykey', 'hello')
节点缓存
这只是一个简单的缓存机制。在我们讨论如何使用这个node-cache包之前,我们需要谈谈为什么这与Redis缓存不同。
Node缓存是一个内存缓存,而Redis缓存是存储在“外部”的。这意味着,一旦您的节点应用程序重新启动,它将丢失其数据并且必须重新缓存。而Redis数据将存储在网络中,直到被删除。Redis缓存也可以从另一个设备访问,因为它基本上就像一个数据库,但是node缓存只存在于特定的nodejs应用程序中。除非您的nodejs应用程序中有一个获取路由来获取缓存数据。
首先,安装node-cache包并创建一个node-cache对象的实例来设置对象
import NodeCache from "node-cache"
const myCache = new NodeCache()
// to set one element
const success = myCache.set( "myKey", "hello");
// to set multiple elements
const obj = { my: "Special", variable: 42 };
const obj2 = { my: "other special", variable: 1337 };
const success = myCache.mset([
{key: "myKey", val: obj, ttl: 10000},
{key: "myKey2", val: obj2},
])
// to get the data
const value = myCache.get( "myKey" );
集群
通常,我们运行一个单独的NodeJS应用程序,它将接收任何类型的请求。想象一下,我们可以分别运行大约8个副本的应用程序,并放置一个负载均衡器,将请求分发到可用的应用程序。这正是集群所做的事情!
与其他不同,这是一个内置的NodeJS包,不需要您下载任何类型的包。
需要注意的一点是,如果您运行N个NodeJS应用程序,数据不会在这些应用程序之间共享。它们每个都以一个进程ID独立运行。
让我以一个基于express的应用程序为例。通常我们做的是:
const app = express()
const PORT = process.env.PORT || 5000
app.listen(PORT, () => console.log(`Server is running successfully on PORT ${PORT}`))
但是在运行集群时,您需要运行N个这样的服务器。(N代表系统中的CPU数量)
import cluster from 'cluster'
const numCpu = os.cpus().length
if(cluster.isPrimary){
console.log(`Primary ${process.pid} is running`)
for(let i=0; i<numCpu; i++){
cluster.fork()
}
cluster.on('exit', (worker, code, signal) => {
console.log(`${worker.process.pid} has exited`)
cluster.fork()
})
}else{
app.listen(PORT, () => console.log(`Server ${process.pid} is running successfully on PORT ${PORT}`))
}
fork()函数是触发新工作进程的函数,如果您注意到了,它会触发fork()函数numCpu次。主工作进程监听所有连接,然后以轮询方式将负载分配给其他工作进程。“轮询”只是指一种算法,它仅在一组可用资源/服务器之间分配任务。
工作线程
再次强调,这是NodeJS提供的另一个内置包。
首先,您需要了解NodeJS默认是单线程的。单线程意味着您的Node应用程序只有一个实例在运行,即主线程。这个主线程接收所有请求并按顺序执行它们。这个主线程被称为“事件循环”。事件循环负责异步管理I/O操作,如网络请求、文件操作和数据库查询。
现在这带来了自己的优势和劣势。当单线程出现错误时,错误处理变得困难,因为主线程会崩溃。但如果是多线程,它确保只有发生错误的线程崩溃,其余线程将继续正常工作。
这就是为什么Node.js给我们提供了一个名为worker-threads的包的选项,它可以帮助我们将单线程的Node应用程序转换为多线程应用程序。让我们看看如何在我们的应用程序中实现这一点:
主线程(calc.js):
import { Worker, workerData } from "worker_threads"
const makeCalculation = async (req, res) => {
try {
const worker = new Worker('./worker.js', {
workerData: {
num: 10
}
})
worker.on('message', (message) => {
if(message.success){
res.send({message: 'Successfully calculated', success: true, ans: message.ans})
}else{
res.send({message: 'Calculation not possible', success: false})
}
})
} catch (error) {
console.log('Error 7: ', error)
}
}
export default makeCalculation;
工作线程(worker.js):
import { parentPort, workerData } from 'worker_threads';
const ans = workerData.num*10
parentPort.postMessage({message: 'Successfully calculated', success: true, ans: ans})
这样的工作方式是,在主线程上,我们使用Worker()函数创建一个新的工作线程,该函数接受一个文件名作为参数。我们还向该文件传递数据,这些数据可以通过workerData对象访问。因此,主线程等待来自工作线程的消息事件,这样可以很容易地避免在工作线程中出现任何错误时导致应用程序崩溃。
微服务架构
通常我们使用的是单体架构,这在一定程度上是可以的。但是在某个阶段,一些项目会涉及到多个表、数据库等,这种架构已经无法满足需求。这就是微服务概念诞生的原因。
顾名思义,多个服务被创建来执行特定的任务,这些服务相互连接。基本上,我们正在分发应用程序,每个应用程序负责在特定主题上执行一组特定的操作。
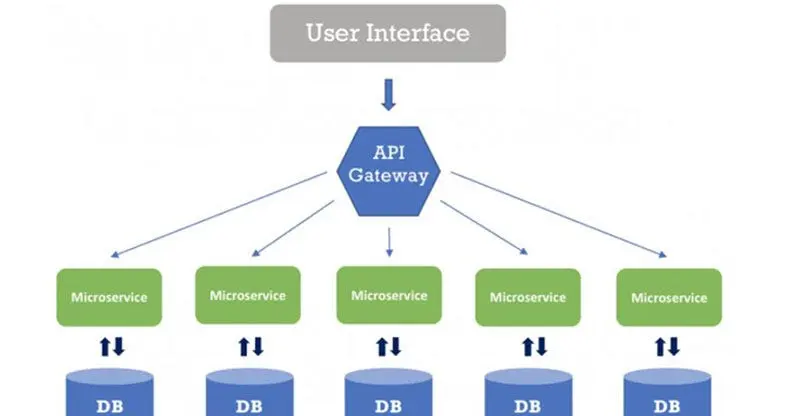
举个例子,想象一下你要创建一个类似滴滴的应用。你可能会在单个数据库中为用户和司机各创建一个表。这是普通开发者的做法。但是对于滴滴及其庞大的网络来说,这种方法行不通。这就是为什么他们需要一个专门负责用户的nodejs应用,另一个专门负责司机的应用。在某些情况下,它们可能会进一步分成更多的应用。需要注意的是,用户和司机的整个数据库也必须分别创建。
现在设计这样的架构可能会导致问题,如数据不一致、服务间通信、部署管理等,这些都应在实施之前考虑到。因此,需要非常谨慎的设计和观察来完成这项工作。
实现这一点的方法很简单,只需创建两个运行在不同端口上的不同应用程序:
users.js
const express = require('express');
const app = express();
app.listen(3000, () => {
console.log('Users service is running on port 3000');
});
drivers.js
const express = require('express');
const app = express();
app.listen(4000, () => {
console.log('Drivers service is running on port 3000');
});
Redis Lock
正如我所说,Redis提供了许多服务,锁就是其中之一。
首先,当您想要防止可能导致死锁的情况发生时,就会使用锁。这种情况发生在您想要运行进程A,而该进程需要使用另一个正在运行的进程B返回的数据时。因此,进程A必须等待进程B完成后才能继续。
为了实现这一点,我们使用Redis Lock。当进程B启动时,它会获取一个锁,直到它的工作完成,它将保持锁定。只有在执行完成后,它才会释放锁。现在进程A可以恢复其工作。
让我们在代码中看看这个,这可能会让你更好地理解:
import redis from 'redis'
const client = redis.createClient();
function processA() {
client.set('my_lock', 'locked', 'NX', 'EX', 10, (error, result) => {
if (result === 'OK') {
console.log('Function A is executing...');
setTimeout(() => {
client.del('my_lock', (error, result) => {
console.log('Lock released by Function A.');
});
}, 5000);
} else {
console.log('Function A is waiting for the lock...');
setTimeout(functionA, 1000);
}
});
}
function processB() {
client.set('my_lock', 'locked', 'NX', 'EX', 10, (error, result) => {
if (result === 'OK') {
console.log('Function B is executing...');
setTimeout(() => {
client.del('my_lock', (error, result) => {
console.log('Lock released by Function B.');
});
}, 3000);
} else {
console.log('Function B is waiting for the lock...');
setTimeout(functionB, 1000);
}
});
}
processA();
processB();
所以这里我正在运行processA()和processB()。一旦processA()开始,它就使用set()函数设置一个锁。
“NX”代表“不存在”。它确保只有在锁不存在时才设置锁。“EX”代表“过期”。10确定了锁将被设置的秒数。
由于processA()已经获取了锁,processB()中的结果将为null,因此它将无法执行其任务并开始等待。
注意:默认情况下,Javascript是单线程的,因此每个函数按顺序执行。这意味着在这个例子中,无论锁是否被获取,processB()都只会在processA()完成后执行。因此,要完全理解Redis锁的用例,您必须在应用程序中拥有分布式实例。想象一下在不同的应用程序上运行processA()和processB()。这才是您实际需要实现这一功能的时候。
总结一下..
我们已经简单了解了Redis缓存、Node缓存、集群、工作线程、微服务架构和Redis锁。这篇文章中写的只是简单的介绍和使用,如果想要深入了解,请参考官方文档。
原文链接:https://juejin.cn/post/7311880893840949282 作者:睡醒想钱钱