
一、前言
在C端领域的同学,时常会遇到各类线上问题,如何快速定位问题,尤其是与营收相关的业务,显得尤为重要。
二、定位问题的感受和启发
在解决线上问题的过程中,笔者感觉到是在考场上解数学题。虽然线上问题千奇百怪,但具有一定的类别性、可枚举。而每一类线上问题也如数学题一样,时常具有相对通用的解题框架,辅助我们拆解、分析、正确提问,逐步走向真相。
随着对所在业务和整个技术架构组成有了梗概认识,以及后知后觉遇到了各种线上问题,笔者归纳了几类线上问题及其解题思路,并提供了一定的辅助工具实现,借此文分享交流,希望能帮助到有类似业务场景及困惑的同学,也欢迎大家分享更多优秀的经验,相互学习,共同提效。
三、问题的基本分类
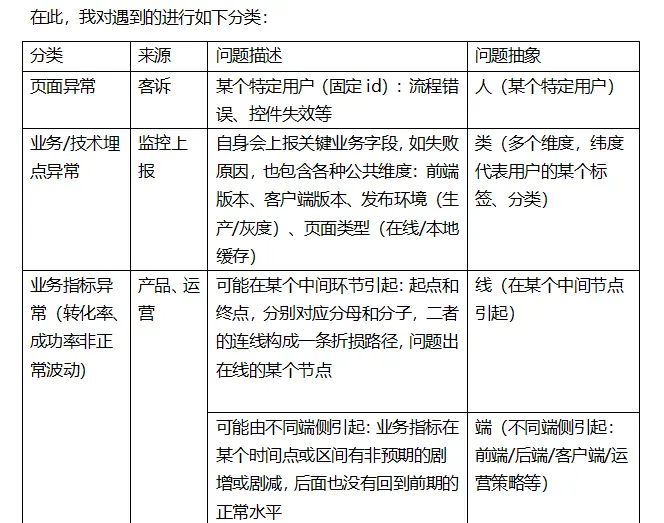

四、不同类别问题的解题思路
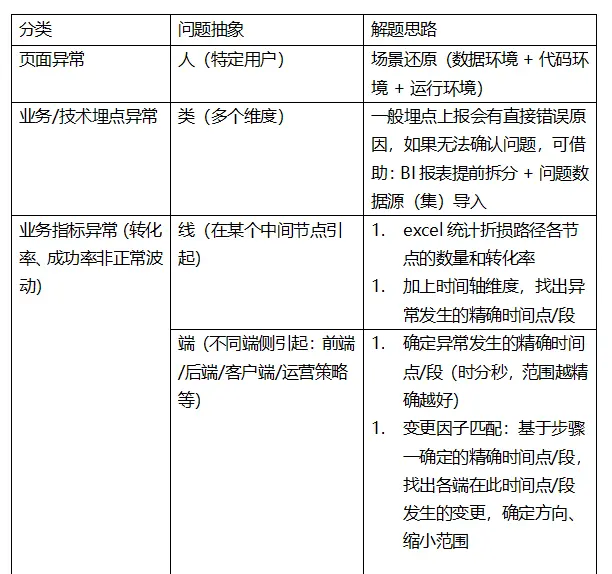
五、解决思路的工具化实现(工具辅助)
1、线(折损路径)
1.1、目的
- 找出业务指标(成功率、转化率)所在折损路径的异常中间节点
- 找出业务指标(成功率、转化率)异动发生的精确时间点
1.2、背景说明
1.2.1、桑基图(能量流转守恒)
在可视化图表里面,有一类图叫做桑基图,也叫桑基能量平衡图。其本质是是一个有向图,也可以看作是一棵树状图,包含一个起点,以及多个分支结点,然后某个子结点又可不断下分多个分支结点。在流量流转路径保持完整、即能全部枚举的情况下, 桑基图最明显的特征就是,始末端的分支宽度总和相等,即所有主支宽度的总和应与所有分出去的分支宽度的总和相等,保持能量的平衡。
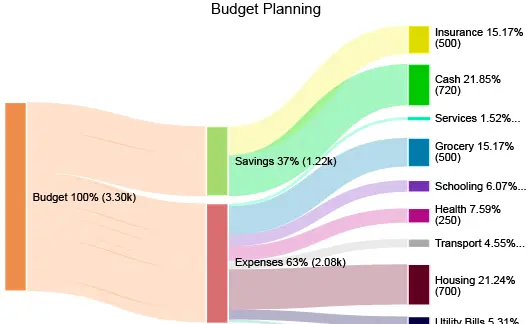
桑基图
1.2.2、线(折损路径)
本小节所指代的“线”,其实就是流量图中的某条折损路径。我们关注某个业务指标,其往往是某个转化率、成功率,有明确的计算公式,其值是百分比格式,分母代表前置结点,分子代表后置结点,分母和分子之间可以组成一段折损路径。
1.2.3、定位异常及发生时间
如果某个业务指标有突发异常,那么问题理论就是发生在这条路径上的中间节点。
那我们如何定位这个异常?
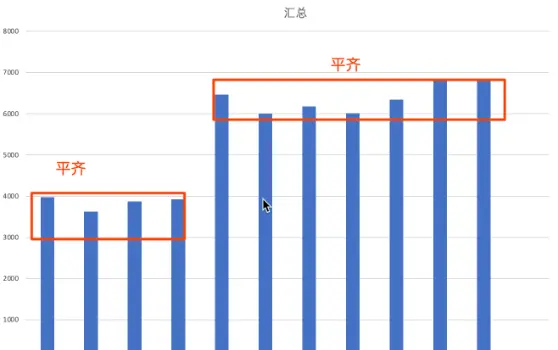
在正常下,某个指标是处于横盘波动,振幅较窄。如果发生异常,这个指标会陡增或陡降,随着错误因子的流量占比达到极值,这个指标的波动会处于一个新的平台,并且保持一定的天数。两个平台的分界点,就是我们所指代的异常。
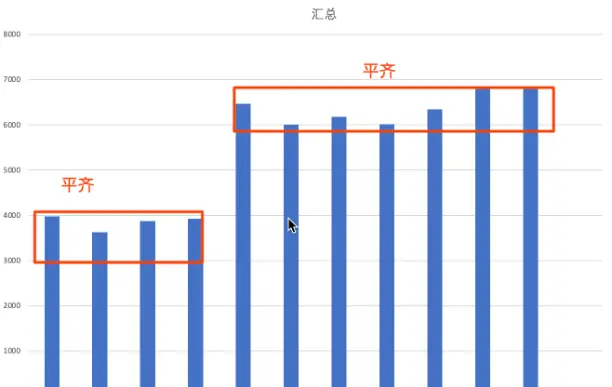
step out:天级别分析——判断到20230907~0908折损用户剧增
更进一步,我们的重点是要找出这个异常发生的精确时间点。然后找出在这个时间点,具体是什么因子导致了这个异常的发生,是引入新问题,or暴露旧问题?
在精确时间点的寻找上,我们可以先在天级别step out寻找这种变化(如上图),然后圈出几个可疑点,然后step in小时级别(如下图),乃至分钟级别,寻找更精确的异常变化起点。时间上,离这个异常变化起点越近越精确的改动因子,通常就是找出真相的关键切入点。而且时间越精确,因子的数量也会越少,甚至唯一,当我们对每一个可疑的改动因子都能提供解释性,真相会愈加明朗。
step in:小时级别分析——在2023-09-07 20:00:00 ~ 23:59:59 折损用户增加
1.3、工具使用
关于异常及其时间点的确定,这里提供excel模版,可以按照模版把折损路径上的每一个上报埋点串联起来,然后统计其数量,并计算前后结点的转化率(或者以入口为统一分母,如漏斗分析,看个人偏好),最后圈出异常的变化点和时间。
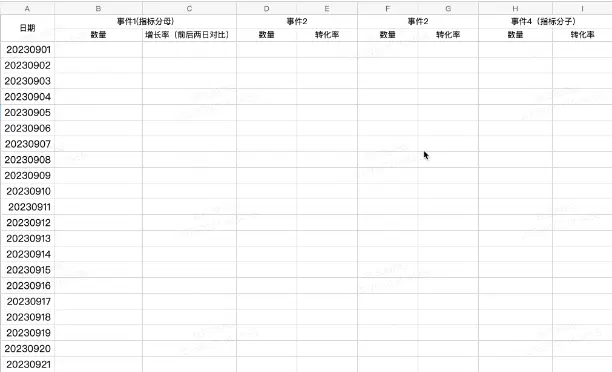
折损路径分析模板
1.4、案例
异常:某个指标成功率在9月7日~8日有10%的下降,按照“折损路径分析模版”,填充折损路径数据并计算每个节点的转化率,观察哪个环节开始折损

观测到20230907~20230907“指标成功率”有10%的下降
特别说明:有些转化率会超过100%,是因为在该场景下事件重复上报是合法的(用户可能反复操作),这里只关注异常的变化率,重复上报不影响趋势判断
1.5、技术畅想(构建有向图、程序化生成路径转化率)
1.5.1、工具实现的算法逻辑
对于还需要人工统计上述折损路径各个环节的转化率,会显得比较低效,其实还有进一步的优化空间。前面聊过,桑基图也是一个有向图,包含点和边。我们的埋点上报其实已经包含了所有节点,并且入库。其实只要再把有向图的边数据做好存储,我们就可以构建出整个有向图。
统计其某条折损路径的转化率,在技术上实现也不复杂。也就是说上述折损路径表格,其实是可以自动生成的,算法逻辑如下:
1.先罗列所有节点(对应埋点),然后进行某个时间级别的group by,并cout,统计数量
2.根据边的连接顺序,把前面计算得到的节点数据对象逐一存储到线性数组
3.计算相邻节点的转化率(或者以入口事件数量为公共分母,形如漏斗分析)
4.生成折损路径统计表格或漏斗图(均带时间轴)
即使没有预先存储好边数据,也完全可以写一个程序,将边数据作为输入(可由前端提供),动态生成折损路径统计表或漏斗图。
1.5.2、工具实现可以减少沟通成本:将分析方法固化到工具中
在当前技术工具未实现,产品/数据分析师掌握了分析方法,但是路径的确立更多依赖于前端工程师提供的埋点,而前端工程师可能未必经过系统化的数据分析,未必知道产品/数据分析师想要什么,特别是在没有标准化方法论的牵引下,跨专业背景的两拨人可能就会存在一定的沟通成本。
1.5.3、在设计阶段,埋点有向图元数据(边、点)理应被计划存储
而数据分析师在设计埋点之初,在“埋点分析系统”理应存储整个有向图的边、点数据,这样方便构图。后续在分析某条路径的折损情况时,可以较大程度摆脱对前端工程师的依赖,也能节约整个团队的人力。
2、端(确定问题部门)
2.1、目的
找出导致指标异常的端侧,通常包括:
- 前端发版
- 客户端发版
- 后端发版
- 运营策略调整(导致流量或用户意愿等发生变化)
2.2、背景说明
2.2.1、当专业经验夹杂恐惧,变成陷阱
以前遇到这样的情况:当某个业务指标发生异常时,恰逢在那个时间段,前端做了改动,而且是业务强关联,为了排除是否是自身因素影响,然后就陷入自查自证。但最后当问题真正定位出来的时候,其实跟前端无关,因为另外一个端侧也刚好在那个时间段,做了相关业务的变动,并引发了问题。
在历次不同的问题,观察到不少前端同学都有类似的经历和感受,也观察到其他端侧的同学也难逃此“陷阱”。这种在错误方向上的自查自证,耗费的时间有时候是在天级别,如果还需要编码验证、线上数据观察,周期将拉得更长,如何减少或避免这种情况,快速找出真正有问题的端侧?
2.2.2、时间是衡量运动的尺度
突然想起西湖大学校长施一公的一句话:“时间就是运动”

也想起一句话:“时间是衡量运动的尺度”

带时间轴的空间运动
时间记录了一切运动,时间是所有事物运动变化的统一尺度,真相就在时间里面
通过“指标异常运动”的精确时间,来匹配引起“指标异常运动”的运动,它们都发生在同一个时间点
也就是说因果律具有二因性:时间因(强调种因的时间)、因本身(强调原因的解释性)。
这个问题就好比某个班次的火车,上来了一个小偷,突然某个乘客说自己丢了钱包。那么除了被盗者,车上的每一个人都有嫌疑,如何快速找出这个嫌疑犯?而不是让所有乘客都搜身一次,自证清白(数百数千,工程巨大)。
相信大家很容易就想出查监控,我们可以通过录像的时间回放,观察被盗者口袋的变化异常及其时间点,在这个异常发生时间点,同时出现在被盗者身边的人,大概率就是小偷,我们的排查人员范围会极大缩小,这个异常时间点越精确,匹配的人物圈群也越小。
2.3、工具使用
要找出是哪个端侧引发的问题,有两大主要步骤:
2.3.1、找出异常发生的时间点
- 方法一:BI报表业务指标的异常拐点及对应的时间
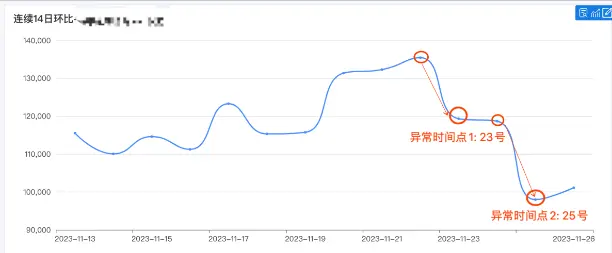
例子:20231123、25号有异常下降(可以观察前一日的变更因子)
- 方法二:excel统计转化率、成功率变化的异常的及其对应的时间

例子:观测到20230907~20230907“指标成功率”有10%的下降
- 方法三:折损用户数量变化的异常点及对应的时间
例子step out:天级别分析——判断到20230907~0908折损用户剧增
例子step in:小时级别分析——在2023-09-07 20:00:00 ~ 23:59:59 折损用户增加
2.3.2、找出与异常时间点高度匹配的变更(问题端侧)
执行nodejs程序,用精确的异常时间点作为输入,去匹配所有会引起系统异常的操作记录,进而确定问题端侧:
- 前端发版
- 客户端发版
- 后端发版
- 运营策略调整(导致流量或用户意愿等发生变化)
- ……
本人基于nodejs,接通了云平台、mo系统、和金融内部的审批系统,主体包含前端/后端/风控共64个PSA的上线历史、客户端版本商店上线审批单和各类运营策略变更审批单,而且程序在秒级别就能执行完毕,匹配速度、精确度和变更因子枚举的完整度,都有远超人工排查的巨大优势。最后输出的结构如下:
{
"time_range": {
"startTime": "2023-09-07",
"endTime": "2023-09-07"
},
"changeArea": {
"frontend": {
"fin-xxx-cash": [
{
"app_name": "fin-xxx-cash",
"version": "master-b84be10-20230907150329-3_886cacbf",
"source_branch": "master",
"commit_id": "b84be10e0e68a54d3282b22701b7cf0e02816620",
"update_date": "2023-09-07 17:02:08",
"updated_by": "{"user_id":"W9xxx9755","user_name":"x瑞","phone":"","user_email":"v-xxx@oppo.com","user_role":["develop"],"tenantId":"","tenantName":""}"
}
],
"loan-xxx-h5": [
{
"app_name": "loan-xxx-h5",
"version": "loan-xxx-h5-20230907-master-2_680f45d5",
"source_branch": "master",
"commit_id": "da0a47cd4b64fdf026515cc29e88187f1a478327",
"update_date": "2023-09-07 17:07:27",
"updated_by": "{"user_id":"W9069755","user_name":"x瑞","phone":"","user_email":"v-xxx@oppo.com","user_role":["develop"],"tenantId":"","tenantName":""}"
}
]
},
"backend": {
"phecda-xxxx-biz": [
{
"app_name": "phecda-xxx-biz",
"version": "phecda-xxx-external-biz-master-20230907142744-335",
"source_branch": "master",
"commit_id": "733ff66d3b1ed0b012237d716509fec44d108366",
"update_date": "2023-09-07 16:17:25",
"updated_by": "{"user_id":"80220945","user_name":"xx","phone":"","user_email":"xxx@oppo.com","user_role":["develop","test","owner"],"tenantId":"","tenantName":""}"
}
]
},
"client": {
"client1": [
{
"FormTitle": "应用V5.x.0软件商店第三轮灰度发布申请(P及以下系统)",
"ProcSetName": "客户端发布申请",
"CreateDateTime": "2023/9/7 20:39:04",
"DispatchDatetime": "2023/9/7 20:52:48",
"public_date": "2023-09-07 20:52:48",
"CreateUserFullName": "xxx",
"CreateUserAccount": "W9xxx7882"
}
]
},
"workOrder": [
{
"app_name": "xx科技平台",
"app_id": "fin-xxx-loan-web",
"audit_status_desc": "审批通过",
"now_node_name": "结束",
"task_title": "API/H5通用规则新增",
"task_status_desc": "成功",
"template_name": "xx系统-合规安全-渠道审批模板",
"template_type_desc": "MO工单",
"last_audit_time": "2023-09-08 10:47:30",
"user_name": "杜xx",
"user_id": "803xxx14",
"reader_names": "郭x,康x,黄xx,xx,张xx"
},....
]
}
}
异常时间点碰撞变更因子的结果输出
古语有云:“失之毫厘,差之千里”。以前一些问题没有及时排查出来,时间的精确度不够(关联因子较多,导致排查方向不对)、变更因子枚举的完整度不够(没有参与分析),也是两个重要因素。
2.3.3、程序能力共享讨论
此程序都是接入公司的公共系统,如果读者也需要此程序,可以在文章留言,人数较多可以考虑申请内部开源,也可以共同讨论是否可以作为云平台的公共能力,更多参考专项分享下一篇文章《线上数据波动定位原理与实现》。
2.4、案例
可参考下一篇文章《线上数据波动定位原理与实现》
2.5、价值
- 极大缩小问题范围:思想类似于git bisect二分查找法,在未确定真正问题的情况下,先确定问题commit(这里是确定问题的端侧)
- 快速定位问题端侧:能够在秒级别完成整个系统端侧的变更匹配
- 减少在错误方向上的人力浪费
2.6、感言:不着虚妄之相,找准正确维度
金刚经有句话:“凡所有相,皆是虚妄”。有时候我们苦求不得果,可能就是“着相”,在问题的投影里面找真相,难免徒劳无功。
| 三维(立体)在二维的投影 | 二维(平面)在一维的投影 | 一维(直线)在零维的投影 |
|---|---|---|
| 面 | 线 | 点 |
高维在低维的投影(能感知却难全知)
我们前面提到过的“专业经验夹杂恐惧,变成陷阱”,其实也是某种程度的着相。在这里再举个例子,在某次线上数据波动中,运营由于合规对某策略进行调整,导致用户走完某个流程的意愿下降。而从前端、客户端的埋点数据来看,我们只看到点击下降、身份验证成功下降。而从真相来看,这两种下降可能就是用户意愿下降的投影,但是技术人员容易陷入自己的认知经验,在本领域的维度展开排查。这里不否定这种排查,相信也能找到一些优化提升点,只是觉得这种排查,容易有徒劳无功的风险,优先级可以缓一缓,尤其是在问题发现之初,如果是并行或已有其他解释性结论则无妨。
爱因斯坦也认为:“在问题的原有维度上不能解决问题;在原有维度上,只能呈现问题;只有换一个维度,才能解决现有问题。”

问题要展开的维度可以很多很多,甚至是超出你的领域认知。所以我们不能急于着手解决问题,而是多思考如何找准正确的维度。而通过异常发生的精确时间点,来匹配整个体系的变更因子,不仅能极大缩小问题的排查范围,也能一定程度摆脱认知局限,它是符合运动规律、因果律的,有助于我们快速找到问题的真正维度,然后正确提问。
2.7、工具落地的缘起和倡议(所有对业务指标可能产生波动的行为,都应该持久化、信息化、可回溯)
2.7.1、想法的诞生(先有组织流程,再有工具思想)
其实对于端侧定位的问题,并不是因为有了工具才有想法,而是有了想法才有工具。
定位体系的想法初步形成
以前当领悟到可以通过异常时间点来匹配变更因子时,就有想过,当再次遇到业务指标异常波动,在组织流程上,先让大家把异常时间点做精确了,然后弄一个统一的checklist(包含所有关联端侧),让每个端侧(部门),都罗列在该时间点附近做的变更操作,并提供该领域的解释性。只要把异常时间点的精度做精,把变更因子的枚举度做全,这个过程就跟玩扫雷一样,离真相肯定会越来越近。
2.7.2、落地的推动
但是作为前端,未必有这么大的能量调动所有相关部门:
- 这种想法和理念是否被认可?
- 即便被认可,在当下,优先级是否能得到倾斜(各端侧同学手头可能还有重要紧急事情)
为了减少流程落地的阻力,一些尽量能用工具替代的,我先用工具替代。于是,我首先从大前端部门内部开始推动:
- 先从云平台接入了前端的发版记录
- 再从mo系统接入客户端的发版记录
在这个基础上,初步演绎、验证了该体系的有效性(以前有个问题跟客户端有关),于是内部发文,争取更多的认可和支持:《线上数据波动定位原理与实现》
后面我又推动后端(自营、贷超、风控),在讲明白原理之后,得到了后端同学的积极响应,及时为我开通了权限,并在半天内就完成了64个PSA的配置接入(psa名称、psa id、部署分组等 ),这里表示感谢。同时也与自营后端同学进行验证,也对过往某次线上问题异常时间点进行了碰撞,能够找到对应的发版记录,相信对问题的排查会有一定的启发和指引。
再最后就是接入产品、运营的审批单,这个过程需要找产品、运营对齐,有哪些行为操作会对系统的业务运营指标产生影响,而且是有类似于审批单的信息化记录,并找到相关系统的运维人员,开通相应权限。
大概在10月31日,nodejs碰撞程序完成了所有端侧的接入,整个落地周期在一个半月。在9月16日~10月31日期间,也有部分问题的定位,是通过与异常时间点的精确碰撞,找到相应的变更因子,然后定位解决。
2.7.3、倡议(所有对业务指标可能产生波动的行为,都应该持久化、信息化、可回溯)
前面介绍整个组织流程的想法和接入过程,其实是想让大家知道整个过程,是有很多依赖于人的环节。一个流程对人的依赖越多,其可靠性和稳定性就越弱,周期也会拉得很长。所以在此倡议:
所有对系统业务指标,可能产生波动的行为,都纳入信息化管理,有类似于发版记录或审批单这样的持久化存档,方便程序回溯。
如果把整个基本动作做好,整个程序匹配过程,可以在秒级别完成,提升的效率可想而知。
3、类(多维度拆解分析)
3.1、目的
- 展现异常/折损用户群的用户画像(纬度分布),辅助发现问题关联维度
3.2、背景说明
3.2.1、画像分析,智能诊股(思想借鉴)
有过股票投资经验的同学,不难发现一些券商的APP应用,有智能诊股的功能:以报表的形式,提供个股的画像分析(包含了个股多维度的基本面信息和技术指标信息)。可以通过切换个股,观察不同个股的画像报表。

股票画像分析(可切换个股)
同理,对于问题用户群,我们也可以借鉴此思想,提前制作好BI看板,只需往这些看板导入相应问题用户群的数据源,就能快速对该用户群进行画像分析,观察各个维度的分布和统计。
3.2.2、BI报表的分析优势
在定位问题没太有方向的时候,本人以前喜欢通过捞一批问题用户,观察其维度特征:
- sql的单表查询,找出异常用户群(主要针对埋点上报的无法直接确认原因的异常)
- 或sql的表关联查询,找出折损用户群(主要针对某个结点的转化折损)
然后对这两类问题用户群,进行数据透视表分析,其本质也是画像分析。多拆分几次之后,发现其中有不少重复工作,这些完全可以交给BI工具。
通过BI报表,观察问题用户群的共性维度,既能让我们了解到问题的影响范围、影响程度,有时候甚至能够帮助我们快速定位到问题的关联纬度,引领我们往更准确的方向去定位问题(如部署环境、代码版本、运行环境等)。
而如果不借助于BI报表,这些维度的拆解也依赖于手工,而且还涉及一些计算工作如分布统计。一些新加入的同学可能没有拆解维度的意识,或还不太熟悉要拆解哪些维度。另外老手在拆解维度的时候,也有可能拆漏,维度较多的话可能还需要借助数据透视表(前期有学习成本)。何不把这种重复的、需要枚举、计算的工作交给BI工具?
如果让资历较深的同学提前拆分好这些维度,也能起到指导新人的作用:让新人知道在业务和技术上,有哪些维度需要格外关注。
3.3、工具使用
3.3.1、BI工具的选择
-
-
- 公司级innerEye(需要接入数据库、excel表导入最大支持10M)
- 中心内部的BI系统(一些埋点数据的实时性暂时无法满足)
- 自搭建supersetBI系统 (excel表大小没有限制、适合DIY)
-
由于数据的安全性和实时性要求,本人在本地搭建了superset BI系统。
3.3.2、提前创建好BI报表(包含需要关注的技术维度、业务维度)
这里有个BI报表的小技巧,在创建BI图表时,首先要指定一个数据集,我们可以把这个数据集定义为一个sql查询类型的数据集,将该sql数据集作为所有图表的接口数据集。如果需要切换数据源,只需要修改数据集的sql即可。
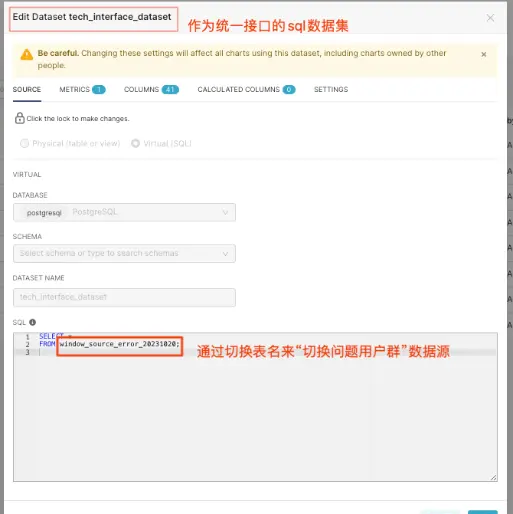
定义BI报表统一的接口数据集
3.3.3、捞取问题用户群数据(dataset)
-
- 从南天门捞取(可以导出excel格式)
- BI系统可以直接访问埋点库
3.3.4、导入问题用户群数据(数据源切换)
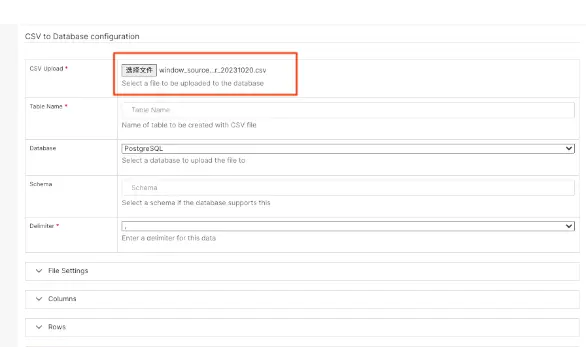
上传数据源
3.4、案例
a. 收到一个监控上报

资源加载异常
b. 导出问题用户群数据,表名为:window_source_error_20231020(excel形式)
问题用户群数据源(excel格式)
说明:如果BI系统直接可访问埋点库或者数据实时性可以保证,则可以直接跳到步骤d
c. 导入BI系统,作为“问题用户群window_source_error_20231020”的数据源
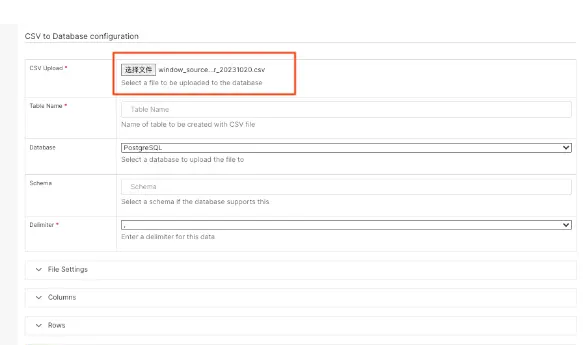
数据源导入
d. 切换数据源
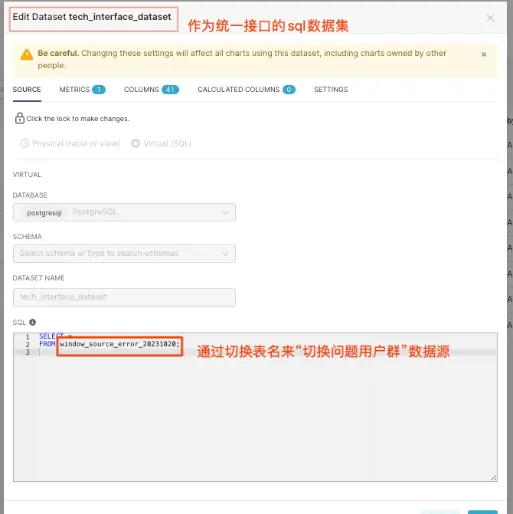
切换数据源(问题用户群)
e. 画像分析

问题用户群画像分析
f. 分析
发现问题主要集中在灰度、而且是苹果手机,不难联想到最近上线的灰度代码引发异常,且跟苹果手机有关,可能是兼容性相关问题。
g. 结论
真正原因是:苹果手机图片加载兼容性问题(不支持gif的base64格式),BI报表的维度拆解加速问题方向。的确认
3.5、价值
- 问题用户群画像分析
- 预拆解纬度(减少重复工作),并提供一定的计算能力
- 辅助问题维度定位
- 指导新人(关注重点业务纬度、技术维度)
4、人(关联某个特定用户)
4.1、目的
- 快速还原线上用户的操作场景(页面快照)
4.2、背景说明
4.2.1、复杂的运行时(运行环境、业务流程、代码环境、数据环境)
作为C端应用的金融现金贷(钱包的借钱),有时候会收到来自于客户的页面异常反馈。
- 在运行环境上,用户量较大,手机品牌、系统等千差万别
- 在业务上,流程复杂,几大流程相互关联、依赖,也接入了许多第三方渠道的流程
- 在代码上,多年堆叠,复杂页面甚至有几千行代码,而且拆分了各种组件和util库,程序执行流复杂
- 在数据上,涉及各种角色权限,每个用户的可见视图也有较大的差异
4.2.2、静态阅读代码难以真正还原问题
遇到此类问题时,可能我们会想着先看看代码。然而,通过静态的阅读代码的方式来定位问题,不仅显得低效,而且可能方向不对,因为引发问题的原因还可能与数据环境(用户角色)、运行环境有关(浏览器版本、客户端版本和操作系统等)。
也观察到即便是在业务上有一两年开发经验的同学,想通过这种方式来找出问题原因,也有些耗时、吃力,甚至徒劳无功。
4.2.3、定位问题的正确思路:先复现问题
有经验的程序员和测试工程师,在遇到问题时,比较正确的思路应该是:先复现问题。而要想复现问题,主体包含:代码环境、数据环境和运行环境。
4.2.4、用户操作场景的还原思路
- 数据环境还原
在当得知后端有上报接口访问埋点,且线上用户的接口访问日志,可以通过kibana这种web化日志分析平台来查看。
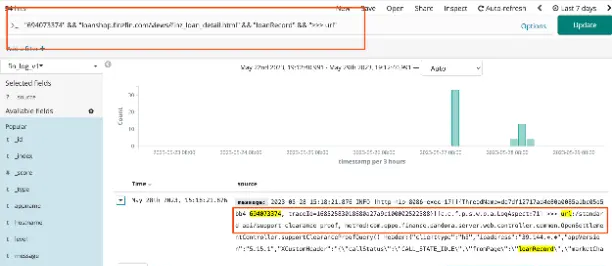
kibana日志分析平台——查看后端接口
由于本人有过爬虫相关的经验,很容易想到从web页面中批量萃取出这种api接口数据源。然后将api接口地址、api接口数据转化为代理服务器whistle的配置文件,并导入,就能快速还原该用户的数据环境快照。
具体实现参考下下篇《用户操作场景(数据环境)快速还原》
- 代码环境还原
对代码版本进行一个本地化代理,就还原代码环境。还原了数据环境和代码环境,即便在不了解业务的情况下,我们也可以通过简单的调试,快速定位到问题的关键点。
- 运行环境还原
其实大部分问题,只要还原数据环境和代码环境就可以定位了。个别兼容性问题可能需要找到指定的机型和系统版本,只要找到相应的测试机即可。
4.3、工具使用
4.3.1、获取API接口数据
在工具使用上,只需要在程序输入:人物(用户id)、时间、地点(一个或多个页面),
就能捞取这个用户在某个时段内,访问过的若干页面的所有API接口数据。
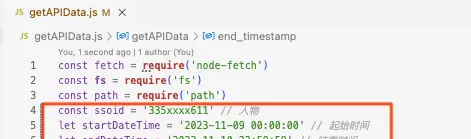
数据三要素:人物、时间、地点
4.3.2、生成whistle代理服务器所需的数据配置
并在此基础上,生成whistle两个配置文件:
- 路由匹配规则文件
- 接口values文件
4.3.3、导入数据配置并代理
将这两个文件导入whistle,既可能快速还原数据环境。至于代码环境,只需要代理到本地代码,就可以轻松解决,这里不赘述。
4.3.4、工具提效(5倍以上)
在工具完成之后,对于此类问题,从数据准备到基本调试,本人大概在半小时内就可以确定问题的核心点,即便对该业务不了解,也能正确提问。而如果没有这个工具,以前可能要大半天,甚至方向都未必准确。借助此还原工具,问题的定位效率从半天/全天级别,降低到了小时级别,效率提升起码5倍以上,而且具有极强的通用性,适合各个水平层次的开发同学,对不熟悉业务的新同学尤其友好。
4.4、案例
需了解更多,可参考《用户操作场景(数据环境)快速还原》
4.5、价值
- 引导问题定位的正确思路:重现——优先还原用户操作场景
- 能够摆脱流程的配置依赖,直接定点还原到指定页面(快照)
- 不仅能还原单个页面,也能还原流程(即多个页面)
- 极大加速问题的定位效率(半天/全天级别 => 小时级别)
- 辅助业务学习:还原某个特定场景
- 通用性强,适用性高
- 避免手工一个条条捞数
六、结尾语
定位线上问题不仅如考场做题,其实更如战场打仗。对胜利的渴望,对战败的恐惧,领导的督战,关注的对齐,潜在的后果,各种情绪、压力交织,时时刻刻都笼罩在一线的定位人员,甚至形成某种干扰。我们要把血的教训沉淀、固化在系统和流程中,变成标准化、高稳定、可迁移、能复用的应对体系,而不是当战争发生时,高度依赖于个体、老手,也不能在战争发生时,只能抄起木棍锄头去抵抗,我们更需要能摧枯拉朽的钢铁洪流(辅助工具)。
真正的战场没有演习一说,和平时期的总结、练兵、铸剑尤为重要。
原文链接:https://juejin.cn/post/7316796493298925578 作者:OPPO互联网服务系统技术运营官