
1. 背景
人不是十全十美的,更何况人写出来的代码。我们之所以需要团队成员 code review,是因为这样能尽可能地在代码上线前发现 bug、不足或可优化之处。不仅能提高项目代码鲁棒性、可维护性,也能提升我们的编码能力,除此之外还能让新加入的同学熟悉项目。有了 code review,大佬们可以给其他同学提出修改建议,小白们也可以学习其他同学代码的优点。但往往由于各种原因,我们并不能抽身于查看每一个别人提的合并请求,更不用说仔细翻阅别人写的代码。
这时,假如有这么一个人,他可以随时随地查看同学们提交的合并请求、仔细翻阅代码、对不合理之处提出建议,在别人初次打开 MR 链接时就能看到他写的评论。那么在这种前提下,同学们就相当于看一遍别人总结过的代码,再研究结论是否合理,从而节约大量的时间。当然,团队中可以派一位同学专门干这件事。但有一个不错的人选来代替这位同学,这样就能将节省出的人力用在其他地方,这个人就是大模型(LLM)。
大模型可以很好地理解自然语言,根据给定的上下文(例如 prompt)生成高质量的文本[1]。而我们平常进行 code review 时,是将变更代码作为上下文,通过解读代码后完成错误解析并进行评论回复。从流程上看人工和大模型 code review 一致,所以完全可以使用大模型来模拟人工 code review,进而降低人力成本和减少线上 bug。
2. code review 模式
人工 code review 往往有三个阶段,一是代码提交时开发者本人自发地对比所变更的代码,进而对业务代码查漏补缺;二是在代码推送到远程仓库且发起 MR 后,开发者本人对整体代码进行审查,能够在合并分支前发现并修改错误;三是发起 MR 后由其他成员对代码批准或提出评论,在代码上线前及时止损。这三个阶段可以借助大模型完成,分别映射为三种自动化模式。
2.1 自动化
上文谈到代码提交时、代码推送到服务器后及发起 MR 后的 code review 可以对应三种自动化模式,分别依赖前端工具 husky+lint-staged、服务器端 git hook、gitlab webhook。
- 代码提交时:在执行 git commit 命令时,触发 pre-commit 等钩子调用 lint-staged。lint-staged则对提交暂存区的文件调用所编写的脚本,对提交文件进行 code review。


- 代码推送到服务器后:在执行 git push 命令后,代码仓库服务器接收到代码提交,会触发pre-receive 钩子。钩子调用脚本,使用 git diff 命令获取变更代码并对变更内容 code review。

- 提交 MR 后:此动作会触发 gitlab merge request webhook,只要编写一个接口供 webhook 触发时进行请求。此时可像提供正常服务端接口一样,依赖 gitlab api 编写代码。

2.2 模式选择
| 模式 | 优势 | 劣势 |
|---|---|---|
| 代码提交时 | 每次提交都能对变更代码进行code review,能减少错误代码流向远程仓库。 | 结果只能直接展示给编码人员、易高频触发 code review 浪费资源及时间。 |
| 代码推送到服务器后 | 能直接对整个业务逻辑代码 code review,减少对非重要变更的重复检查。 | 不能直接获取变更代码、服务器上调试困难、可能影响服务器性能。 |
| 提交MR后 | 能将检查结果与 MR 绑定,直接展示给所有 CR 成员、不阻塞后续开发。 | 依赖 gitlab api 和 kdev api、接口流程长。 |
上表是三种模式之间的优劣对比,因为 commit 和 push 的频率总是大于 MR 的频率,在代码提交时和代码推送到服务器后进行 code review 两者都有相应的资源及性能问题。而提交 MR 后再 code review 只是在逻辑层面复杂一些,不会影响成员后续开发。
code review 产出的结论展示是否直观且方便也需要重点关注。如果结论只能给编码者查看或无法直接定位问题位置,那么这种 code review 只能起到提醒作用。而将结论与 MR 中需要 CR 的代码行数绑定,直接展示在相应的出错位置,不仅能提醒开发者,还能让所有成员相互学习与进一步探讨。
总的来说,使用 webhook 的方式,在提交MR后进行自动化code review,在项目代码整体规范性、鲁棒性、可维护性及评论管理层面上有极大的优势。因此,本次采取 webhook 调用接口 的方式,验证大模型 code review 可行性。
3. 整体方案

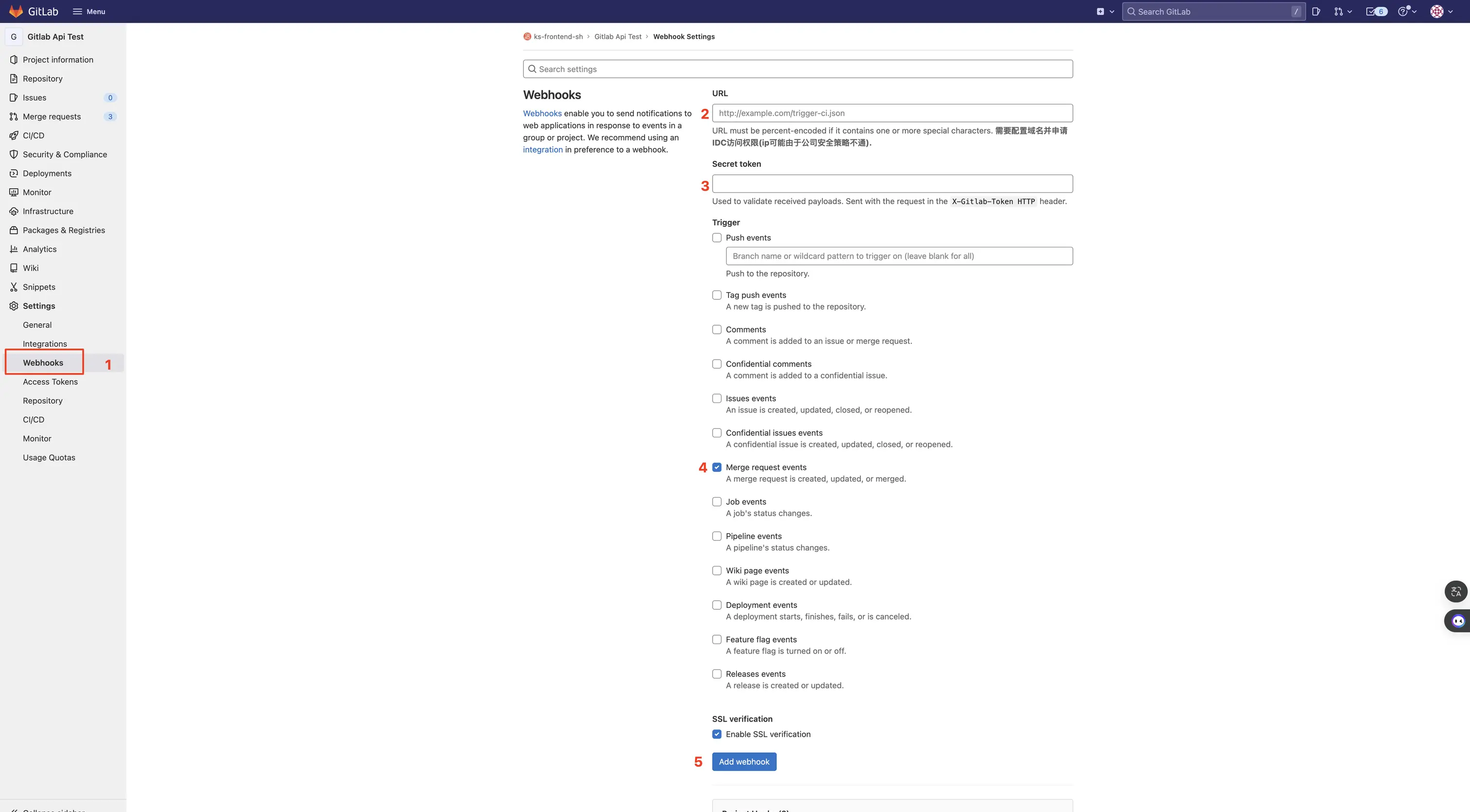
3.1 创建 webhook
- 在仓库设置中选择 Webhooks 选项卡进入配置页面。注:需要管理员权限(拥有者、维护者)
- 配置触发 webhook 所请求的url。
- 配置独立 token,便于统计接口访问情况。
- 选择触发条件,这里只选择 MR 事件触发。
- 点击添加按钮即可成功添加一个 webhook。
3.2 请求过滤
每当 webhook 被事件触发时,将会向我们的接口发送一次 post 请求。在收到请求后,将下列后续需要用上的参数取出。
{
"event_type": "merge_request",
"project": {
"id": 1,
...
},
"object_attributes": {
"iid": 1, //合并请求id
"target_branch": "master",
"source_branch": "ms-viewport",
"action": "open", //触发事件
...
},
...
}
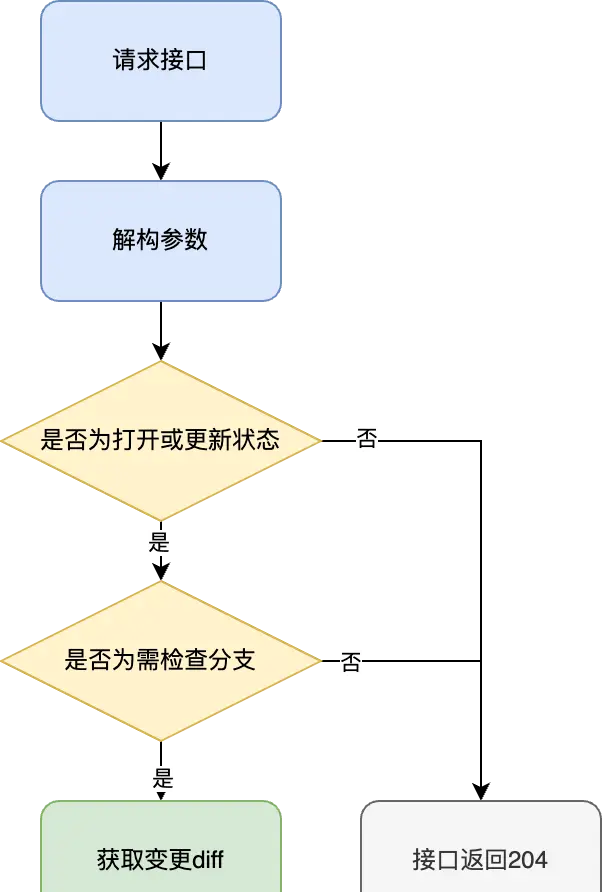
由于 MR webhook 会被open|close|reopen|update|approved|unapproved|approval|unapproval|merge[2] 九个事件触发,为了避免重复对同一个 MR 重复检查,因此只对其中的 open 和 update 事件作出响应,这两个事件分别对应初次提交 MR 和 push 更新代码时刻,其他事件直接返回。
在正常情况下,在一个开发周期不同人员会有多个分支,且整个发布流程会涉及多个辅助分支的合并。以 gitflow 工作流[3]为例,只需要使用正则表达式判断 source_branch 和 target_branch 是否分别是 feature 和 develop,以及 source_branch 是否是 hotfix,即可进入 code review 流程,否则直接返回。
3.3 获取变更内容
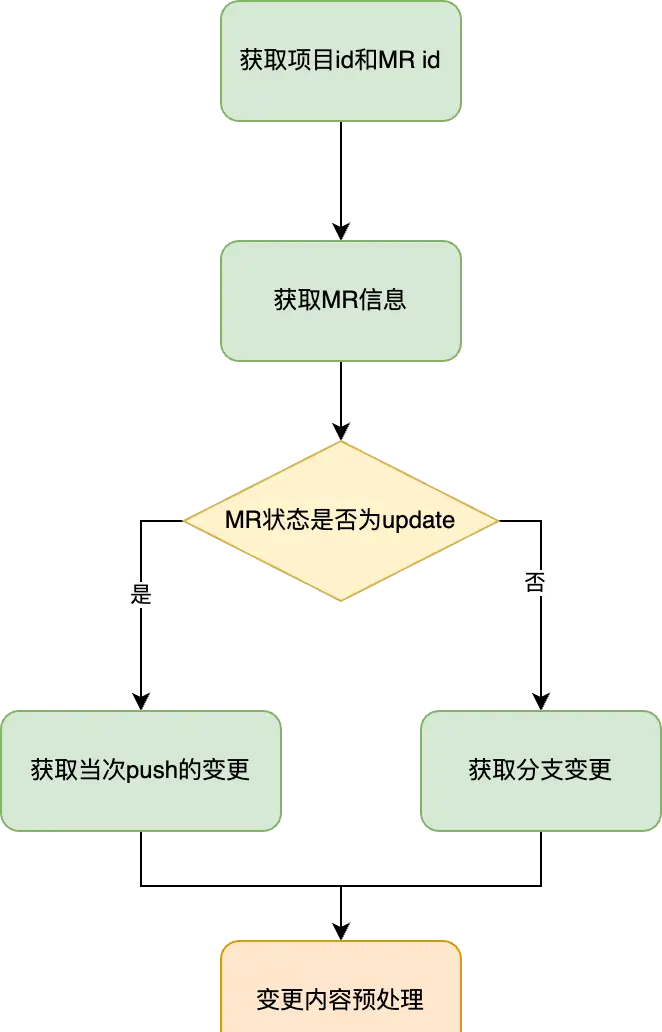
上节说到解构 post 请求体获取到项目 id 和 MR id,通过调用 gitlab api[4] 能获取 MR 对应的一些信息。其中必要的字段是 diff_refs 对象内的 base_sha 和 head_sha,两者分别是此次 MR 分支的起始 commit 以及最后一次 commit 的哈希值,后续需要通过两个哈希获取 diff 内容。
{
"diff_refs": {
"base_sha": "1162f719d711319a2efb2a35566f3bfdadee8bab",
"head_sha": "e82eb4a098e32c796079ca3915e07487fc4db24c",
"start_sha": "1162f719d711319a2efb2a35566f3bfdadee8bab"
},
...
}
需要补充的是,在初次提交 MR 时和 push 更新代码时都会触发一次 webhook,此时需要根据两种情况进行区分。在初次提交 MR 时获取分支全量变更内容,而在 push 更新代码时只需要获取当次 push 的变更内容,这样就不会重复检查历史变更内容。
因此获取到 MR 信息后,再根据 webhook 状态进行区分。当接口是初次提交 MR 触发的,需要根据 base_sha 和 head_sha 请求 api[5] 获取两次提交之间的变更内容;而当接口是 MR 代码更新触发的,则首先需要调用接口获取当次 push 的 base_sha 和 head_sha,再请求 gitlab api 拿到当次 push 的变更内容。
const diffs = [
{
"diff": "@@ -71,6 +71,8 @@\n sudo -u git -H bundle exec rake migrate_keys RAILS_ENV=production\n sudo -u git -H bundle exec rake migrate_inline_notes RAILS_ENV=production\n \n+sudo -u git -H bundle exec rake gitlab:assets:compile RAILS_ENV=production\n+\n ```\n \n ### 6. Update config files",
"new_path": "doc/update/5.4-to-6.0.md",
"old_path": "doc/update/5.4-to-6.0.md",
"a_mode": null,
"b_mode": "100644",
"new_file": false,
"renamed_file": false,
"deleted_file": false
}
]
3.4 变更内容预处理

实际上,很多变更文件都是配置变更,不需要 code review。与此同时,单独的 css 文件变更由于没有 html 上下文,脱离 html 连人工都难以审阅,更不用说大模型。除此之外,已删除文件也没必要保留。
因此需要对不必 code review 的文件给筛选去除,从而减轻大模型负担及减少不必要的支出。此处使用正则表达式数组依次筛选文件,同时根据 deleted_file 字段忽略已删除文件,最终筛选出需检查的文件对象数组。
const blockFilePatterns = [
/.json$/,
/.gitignore$/,
/.env$/,
/pnpm-lock.yaml$/,
/yarn.lock$/,
/.sh$/,
/.less$/,
/.css$/,
];
通过观察 4.3 节的 diffs 数组例子可以得知,每个对象对应一个文件,每个 diff 属性中的字符串则是文件中的变更内容,而不同变更之前都有类似@@ -71,6 +71,8 @@的标识。其中-71,6表示变更前代码一共 6 行,从 71 行开始;+71,8表示变更后代码一共 8 行,从 71 行开始。
由于大模型根据上下文进行文本生成[1],其本身不具备计算能力,因此只给他一个变更行数标识没办法准确找到每行变更的具体行数。更重要的是,字符串中的变更行通过前缀+/-来标注当行变更具体内容,即使强制指示大模型通过辨别两行之间的前缀来确认变更,也无法百分百判断正确。因此需要对每个文件变更的内容人工格式化成变更前后两段代码,并在每行行首设置当行行数,进而使大模型更容易识别变更内容及行数。

此处使用正则表达式/@@ -(\d+),\d+ +(\d+),\d+ @@\[\S\s]\*?\n/g匹配标识,进行变更行数获取及分割变更内容。分割之后获得一个由各一个变更前后字符串组成的对象数组,再加上变更文件名将这个数组重新组合成一个当前文件的完整变更前后字符串。
3.5 调用大模型
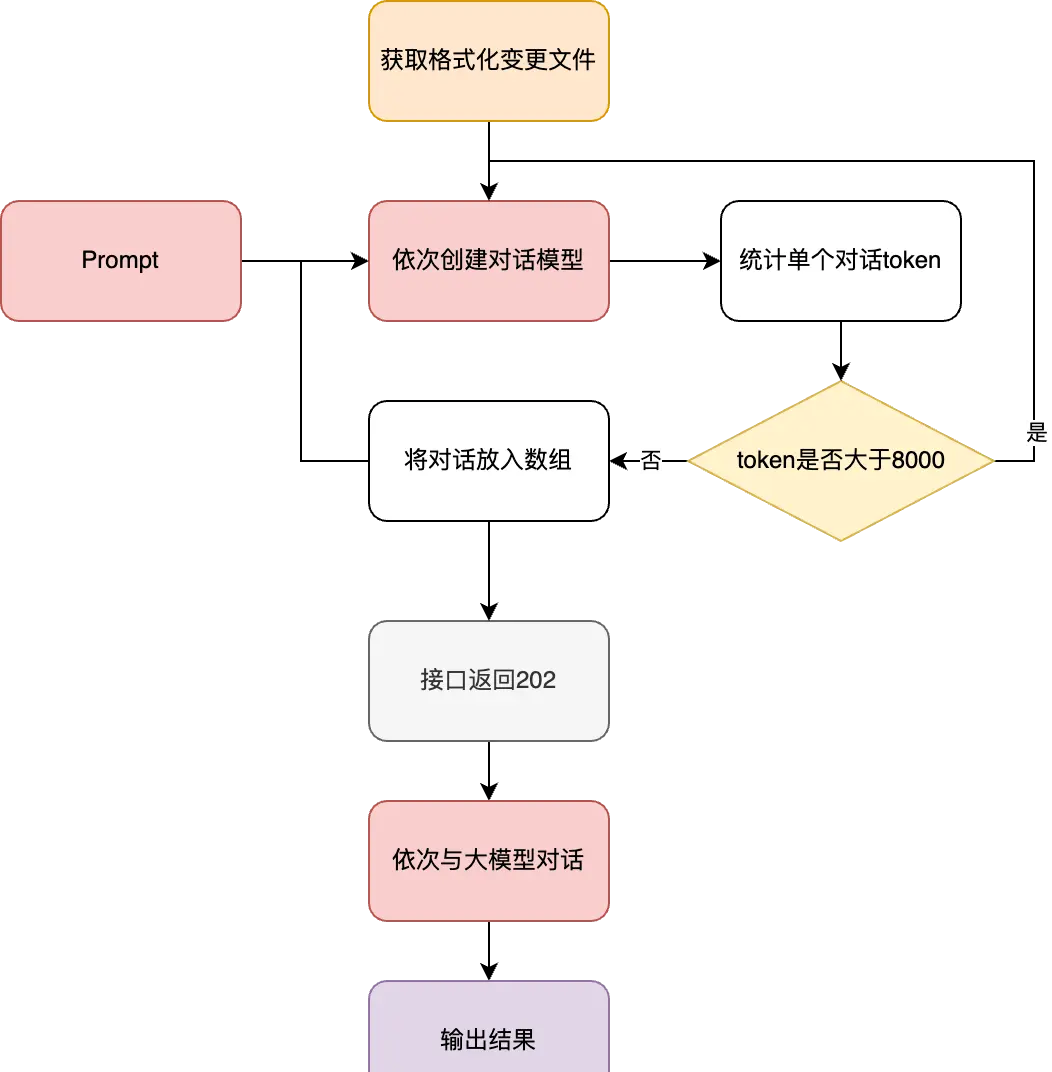
上节获取到格式化后的文件变更字符串,接下来将依赖 Langchain 框架,以文件为粒度调用大模型。经过综合评判,本次采用的大模型为 Chat GPT turbo,上下文窗口为 8000 token[6]。因此在将变更内容传入大模型前,需要单独对每个文件统计 token,若超出限制则直接舍弃。如果超限则接口返回204,不超限则接口返回202,后续持续较长时间的大模型对话放在后台执行。
3.5.1 什么是 Prompt
Prompt 可以被理解为一种启动机器学习模型的方式,它是一段文本或语句,用于指导机器学习模型生成特定类型、主题或格式的输出。在自然语言处理领域中,Prompt 通常由一个问题或任务描述组成,例如“给我写一篇有关人工智能的文章”、“翻译这个英文句子到法语”等等。在图像识别领域中,Prompt 则可以是一个图片描述、标签或分类信息[7]。
Prompt 能把大模型的输入限定在一个特定的范围之中,进而更好地控制模型的输出。在很多大模型应用场景下,基于经验或者训练语料总结出一些优质的 Prompt 组成结构,可将其抽离成为一种模板,在模板中去填充对象信息来进行大模型推理,从而获得更准确的推理结果[8]。
而本次创建大模型对话使用的 Prompt 则使用了一个模板字符串进行模型范围的限定。经过不断地调试与优化,最终它的结构分为三个部分。
3.5.2 指令与背景
该部分的作用是将上文所收集变更内容的背景知识以及任务告知大模型,将大模型约束在 code review 场景,进而遵循我们设定的规则。
你是一位code review专家,现在需要你来对一些变更的代码进行分析检查。
变更前后代码每行行首都有该行的行数,行数后的+号或-号代表代码增减。
请给出检查的建议和对应的代码行数,并以一个对象进行输出。
3.5.3 额外规则与强调信息
若只由指令和背景作出限制,大模型无法对任务细节做出判断。因此需要输入额外的规则以及强调部分信息使得大模型进一步对输出作出限制。
请注意:
1. 不要检查语法错误、命名错误,只检查逻辑错误。
2. 不检查属性可能返回undefined的问题。
3. ...
3.5.4 Few-Shot
少样本学习(Few-Shot Learning)是一种机器学习方法,旨在让机器学会如何通过有限的样本数据,快速地适应新的任务,并且能够在不同的任务之间进行泛化[9]。而通过 Prompt 驱使大模型往既定方向执行任务,本质上也是单次的训练,只不过训练结果不保存在记忆中。因此提供少量样本给大模型,能进一步规范大模型输出及准确度。
以下是输出示例:
示例1:[]
示例2:[{"row": 0, "suggestion": "xxx"}]
请注意,示例内容仅为参考,不应该直接使用任何示例。
3.6 输出结果
将大模型返回的建议数组依次调用 gitlab api[10] 添加评论接口,即可在对应行数添加评论,示例如下:
初步采用三个等级对大模型评论效果进行评估,分别定义如下:
| 等级 | 定义 |
|---|---|
| good | 高价值评论,能指出代码中的bug、冗余代码、性能优化之处。 |
| normal | 可参考评论,用户可根据业务逻辑判断是否采纳。 |
| bad | 错误评论,行数判断错误、无意义内容、评论本身逻辑错误。 |
本次评估采用共 237 条评论数据进行人工标注评估,其中高价值评论 41 条,可参考评论 181 条,错误评论 15 条。统计得出整体评论正确率为 93.67%,其中高价值评论占比 17.3%。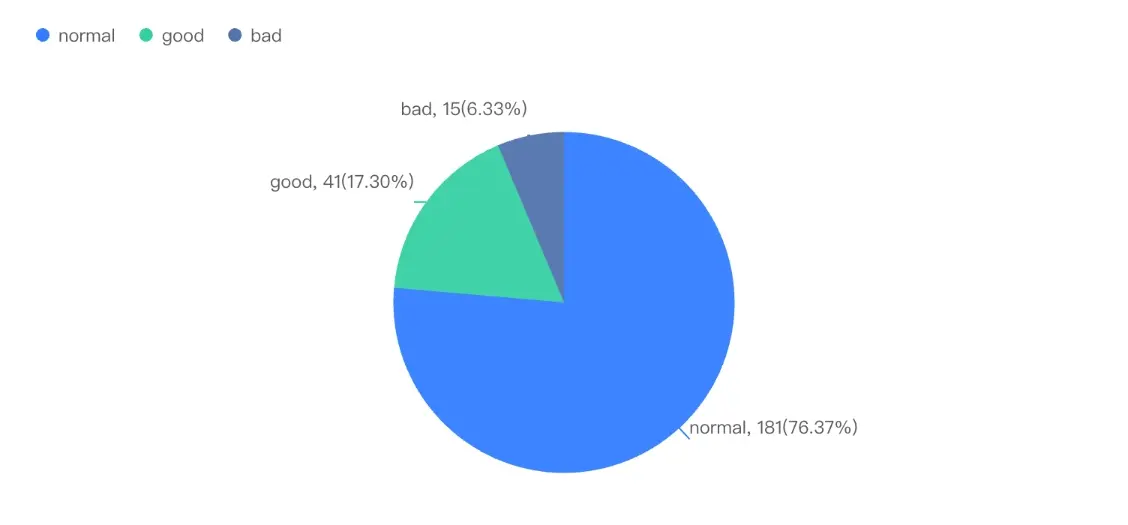
4. 总结与展望
本次大模型 code review 使用 Chat GPT 大模型,采用 webhook 方式接入,在用户创建 MR 时会自动触发 gitlab 的 MR webhook 调用接口。尽管大模型 code review 可行性已验证成功,但现在仍处于测试优化阶段,还有不少的问题需要解决:
- 安全问题、不可控因素;
- 变更文件检查行数受限;
- 大范围使用后 GPT token 费用支出问题;
- 响应速度慢、效果不稳定;
前 3 点无法通过进一步优化解决,第 4 点则需要不断调试优化 Prompt 使大模型能力更符合任务需求。除此之外,训练并部署一个私有大模型则是解决安全等问题的根本方案。一可以避免任何数据流向外部;二不会因为 token 上限和触发敏感词而绕过对某些文件 code review;三是针对某个垂直领域进行训练,可以提高准确性和稳定性。进一步来看,依赖外部大模型的支出问题也能迎刃而解。
5. 引用
[3] Gitflow Workflow | Atlassian Git Tutorial
[4] Merge requests API | GitLab
[7] 什么是Prompt?——深度学习中的重要概念 – luch的博客
[8] 文心千帆文档首页-百度智能云
[9] Zero-Shot, One-Shot, and Few-Shot Learning概念介绍-阿里云开发者社区
原文链接:https://juejin.cn/post/7317593425372758028 作者:火龙果然