
前言
😀我们在做前端开发的时候,我们基本不涉及处理二进制的数据,但是在Node中我们在很多时候是需要进行二进制的处理的,这个时候我们就会涉及到Buffer和数据流的内容,服务器需要处理的文件比较多
- 比如我们在保存一个文件使用的不是UTF-8编码而是使用的GBK编码方式,,那么我们就需要首先读取二进制数据然后再转换为UTF8的编码。
- 比如我们需要读取一张图片的(二进制),而是通过图片对二进制的数据进行处理(剪裁,格式转换,添加滤镜)Node中有一个sharp库就是读取图片的二进制或者传入图片的Buffer对其进行处理。
- 比如在Node中通过TCP建立长链接,TCP传输的是字节流,我们需要将数据转换成字节再传入,并且知道字节的大小。
🤡buffer是什么?buffer被翻译为缓冲区,buffer其实就是一个交接计算机世界和人类世界的桥梁,二进制通过buffer能够转为人类能看得懂的东西,比如字符串,数字,举一个更加简单的例子,我们使用翻译器将英文翻译成中文,翻译器其实就是buffer。
一.了解buffer
😈经过上面的了解,我们知道了buffer大概是一个什么样的作用,其实在我们实际使用buffer的时候我们一般把buffer看做是一个存储二进制的数组,在这个数组中每一项可以保存八位二进制。
🥺为什么是8为哪?二进制不应该是010101这种样子的吗?为什么在buffer中是一位表示8位哪?
- 在计算机中我们很少情况会直接操作二进制数据,因为一位存储二进制是非常有限的
- 所以通常会把八位合并在为一个单元,这个单元称为字节。
- 也就是1byte = 8bit
- 比如在很多其他编程语言中int类型是四个字节,long类型是8个字节。
- 比如TCP传输的是字节流,在写入和读取的时候都需要说明字节的个数。
- 比如RGB的值分别都是255,所以在计算机中就是用了一个字节存储的。
- buffer的一位就是一个字节比如
[11111111,00000000]
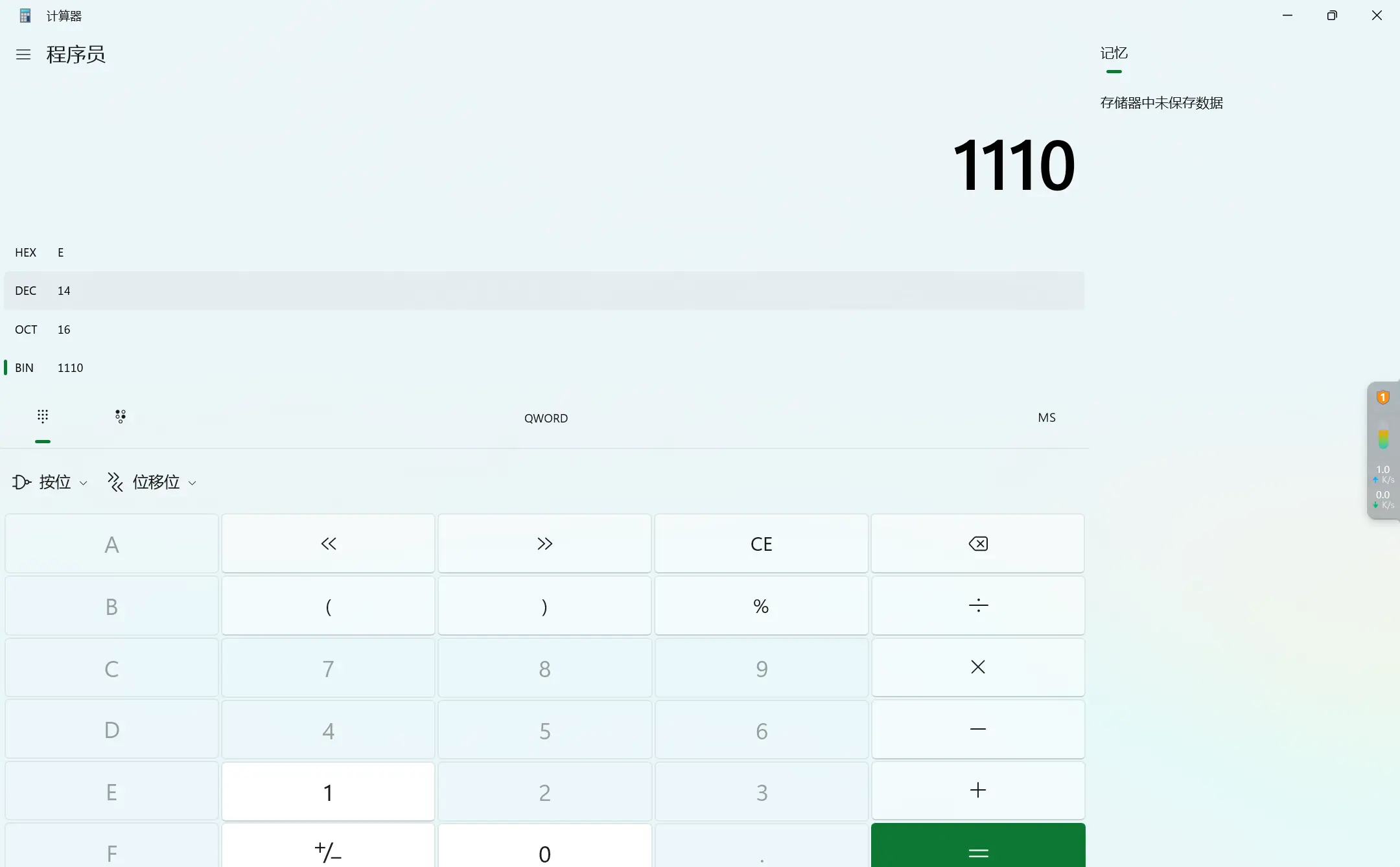
🐻如果不太熟悉进制之间的换算,我们可以去了解下各种进制之间是如何换算的,但是我建议我们可以直接使用电脑上的计算器来进行进制之间的转换,当我们选择二进制输入之后就会得到其他进制的结果,我们解释下计算器不同进制的符号。
- HEX:表示十六进制(Hexadecimal),也称为基数为16的数字系统。它使用0-9的十个阿拉伯数字和A-F的六个字母(代表10-15)来表示数字。例如,十进制的数字15在十六进制中表示为F。
- DEC:表示十进制(Decimal),也称为基数为10的数字系统。它使用0-9的十个阿拉伯数字来表示数字。例如,十进制的数字15在十进制中表示为15。
- OCT:表示八进制(Octal),也称为基数为8的数字系统。它使用0-7的八个阿拉伯数字来表示数字。例如,十进制的数字15在八进制中表示为17。
- BIN:表示二进制(Binary),也称为基数为2的数字系统。它使用0和1两个数字来表示数字。例如,十进制的数字15在二进制中表示为1111。
😈十六进制经常用于表示内存地址、颜色值等;八进制和二进制常用于表示文件权限、数据存储等。在编程和计算机系统中,我们经常需要在不同进制之间进行转换和操作,当然在buffer中表示的方法是将四位的二进制用十六进制来表示
bin:[1111 1111] ----> buffer: [ff]

二.buffer的基本使用
🥺buffer的初始化使用
const buf = new Buffer("HelloWorld") // 不推荐使用这种方法创建
console.log(buf)
// 创建Buffer
const buf2 = Buffer.from("world")
console.log(buf2)
// 创建buffer包含中文
const buf3 = Buffer.from("你好啊")
console.log(buf3)
😈buffer和字符串,我们知道buffer相当于是一个字节数组,数组中的每一项对应一个字节的大小,那么如果我们把一个字符串放入buffer是怎样的过程哪?
如果将字符串转成buffer首先英文字符串会通过ASCII编码转为十六进制数据,然后将十六进制数据进行存储在二进制数组中也就是buffer中。
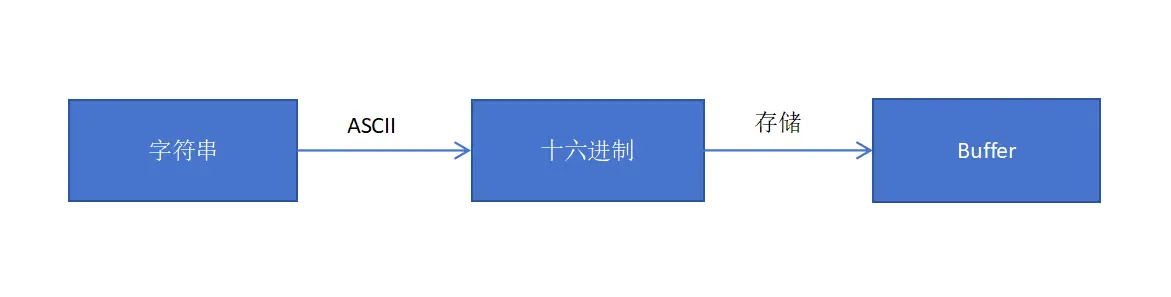
那么如果我们想把转为buffer的数据再转换回来我们应该如何做哪?其实buffer中也提供了将字符串转换回来的方法toString()我们使用这个方法可以将buffer转为普通的字符串。
const buf3 = Buffer.from("你好啊")
console.log(buf3)
console.log(buf3.toString())
👹手动指定创建buffer过程的编码,我们在上述进行创建buffer的时候默认让buffer进行自动进行编码的,但是我们其实也可以自己指定,但是要注意的是我们使用什么样的方式编码就要使用什么样的方式解码,否则会出现问题的,但是其实在开发过程中我们尽量使用buffer的默认编码,buffer的默认编码使用的是utf8的方式。
const buf = Buffer.from("你好啊","utf8")
console.log(buf.toString('utf8'))
😊创建一个8个字节大小的buffer对象。
const buf = Buffer.alloc(8)
console.log(buf)
// 手动对每个字节进行操作
console.log(buf[0])
console.log(buf[1])
// 对buffer进行赋值
buf[0] = 100 // 会进行转换为16进制
buf[1] = 0x66
// 转为字符串
buf[1] = 102
console.log(buf.toString())
当我们需要对单个字符进行编码的时候我们需要charCodeAt()方法进行编码
const buf = Buffer.alloc(8)
buf[0] = 'm'.charCodeAt()
console.log(buf[0]) // 输出结果
三.从文件中读取buffer
fs.readFile('./aaa.txt',(err,data)=>{
console.log(data.toSting())
})
🤡在计算机中的底层都是二进制数据的方式,无论是图片还是其他文件,我们首先来读取一个图片的二进制数据
fs.readFile('./aaa.png',(err,data)=>{
console.log(data)
})
三.buffer的创建过程
🤡事实上我们在创建buffer时,并不会频繁的向操作系统申请内存,它会默认先申请一个8*1024个字节大小的内存,也就是8kb,也就是8*1024byte,这个其实buffer做的一个性能优化,buffer的内存增加策略是
- 这里做的事情就是判断剩余的长度是否还足够填充这个字符串。
- 如果内存不够,那么就通过
createPool创建新的空间。 - 如果够就直接使用,但是之后要进行poolOffset的偏移变化。
四.buffer数组的常见操作汇总
🦝我们在上述内容中了解了buffer是什么,了解了buffer的基本创建,在这里我们对buffer的常见操作做一个总结来对buffer的使用有一个整体的了解
- 创建buffer
// 创建一个长度为10的Buffer数组
const buffer = Buffer.alloc(10);
console.log(buffer); // <Buffer 00 00 00 00 00 00 00 00 00 00>
- 读取数据
// 从Buffer数组中读取指定索引位置的字节值
const buffer = Buffer.from([10, 20, 30, 40]);
console.log(buffer[0]); // 10
console.log(buffer[2]); // 30
// 读取部分数据
const slicedBuffer = buffer.slice(1, 3);
console.log(slicedBuffer); // <Buffer 14 1e>
- 写入数据
// 将字节值写入到指定的索引位置
const buffer = Buffer.alloc(4);
buffer[0] = 10;
buffer[2] = 30;
console.log(buffer); // <Buffer 0a 00 1e 00>
// 将字符串写入到Buffer数组中
const strBuffer = Buffer.alloc(6);
strBuffer.write('Hello!');
console.log(strBuffer.toString()); // Hello!
- 转换数据
// 将Buffer数组转换为字符串
const buffer = Buffer.from('Hello!');
console.log(buffer.toString()); // Hello!
// 将Buffer数组转换为JSON对象
const buffer = Buffer.from([10, 20, 30]);
console.log(buffer.toJSON()); // { type: 'Buffer', data: [ 10, 20, 30 ] }
- 拷贝数据
// 将一个Buffer数组的数据拷贝到另一个Buffer数组中
const sourceBuffer = Buffer.from([1, 2, 3]);
const targetBuffer = Buffer.alloc(3);
sourceBuffer.copy(targetBuffer);
console.log(targetBuffer); // <Buffer 01 02 03>
- 比较数据
// 比较两个Buffer数组的内容
const buffer1 = Buffer.from([1, 2, 3]);
const buffer2 = Buffer.from([1, 2, 3]);
const result = buffer1.compare(buffer2);
console.log(result); // 0 (相等)
- 截取数据
// 截取Buffer数组的一部分数据
const buffer = Buffer.from([10, 20, 30, 40, 50]);
const slicedBuffer = buffer.subarray(1, 4);
console.log(slicedBuffer); // <Buffer 14 1e 28>
五.总结
😀buffer是一个存储二进制的数组,我们可以理解为一个转换中英文的转换器的角色,但是buffer存储的时候不会直接以二进制的方式进行存储,而是会把8个bit为每4为一个单位进行存储,在内存中buffer会首先申请一个8kb的内存空间,创建buffer的方式Buffer.from(),申请固定buffer的长度Buffer.alloc(8),并且可以将文件读取为二进制,在服务端开发中我们会经常用到buffer~
原文链接:https://juejin.cn/post/7320523496865464361 作者:一溪风月