
适配器模式
适配器模式也是前端开发中常用的设计模式,使用频率也是能够排的上前三的设计模式,使用这个设计模式能够在一定程度上避免一些代码的历史问题,能够提高代码的复用性和灵活性。
1、基本概念
适配器模式,将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
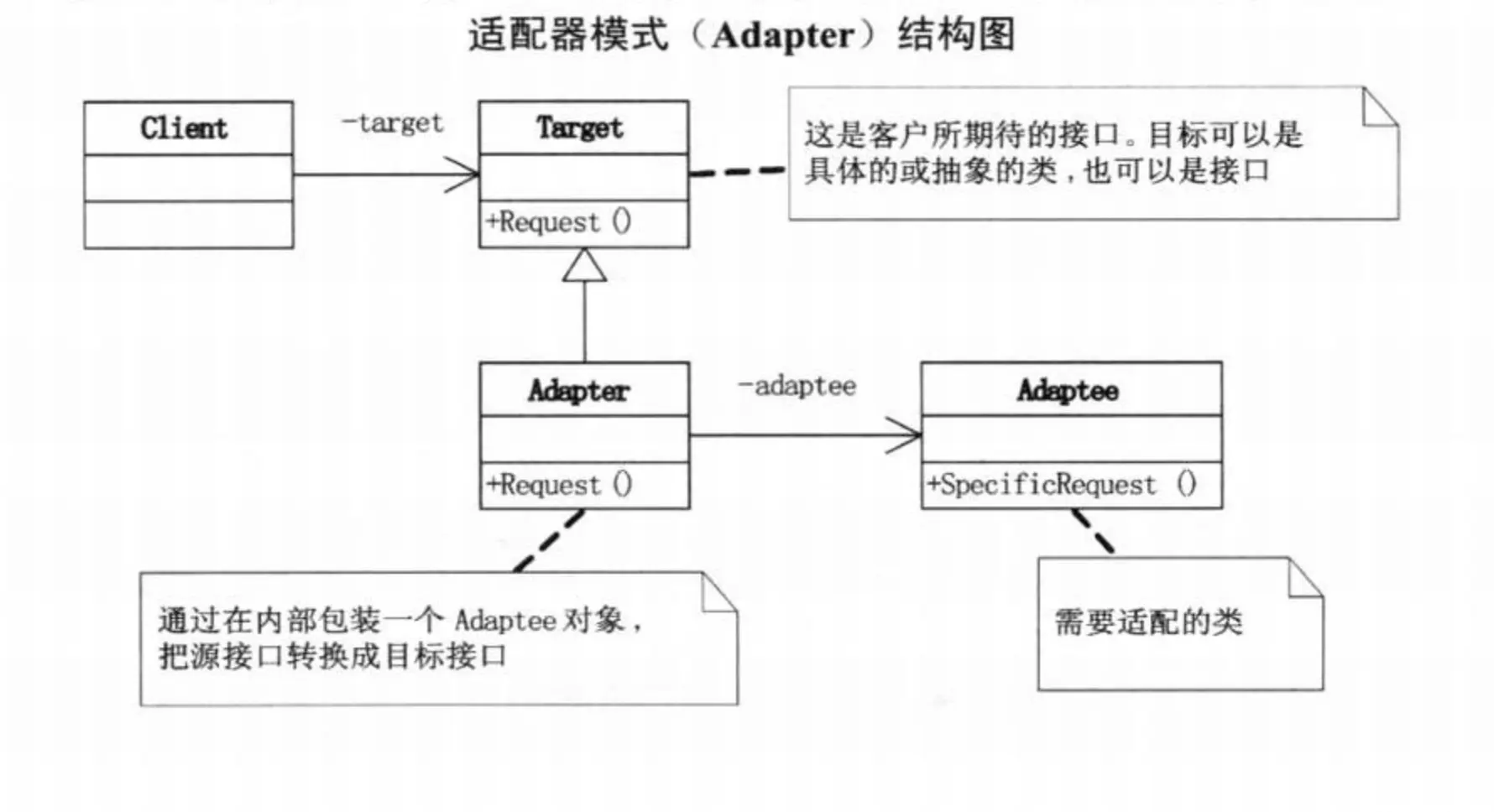

适配器模式的UML图如上述,其实挺简单的。
Target类定义了一套标准的API,但是因为现在Adaptee无法兼容Target的API,因此,编写了一个Adaptor类来保证API和Target的规格相同(所以Adaptor内部持有Adaptee),其内部实现就根据Target的规格调用与之能匹配的Adaptee的API。
2、 什么是防腐层?
可能很多前端同学在之前没有接触过这个概念,因为现在前端的框架便利性,我们编写不用再直接操作DOM,开发难度显著降低,已经不像10年前了,很多同学没有代码分层的概念,正好利用适配器模式进行一下解释。
防腐层(Anti-Corruption Layer, ACL)是一种软件架构模式,用于隔离系统或应用程序中的不同部分,尤其是在集成旧系统或外部系统时。这个概念通常用在领域驱动设计(Domain-Driven Design, DDD)中,用以保护软件应用的领域模型不受外部系统的不良影响。
防腐层的主要目的和特点包括:
-
隔离变化: 防腐层充当应用程序与外部系统或旧系统之间的缓冲区。这样,当外部系统变更时,不需要对整个应用程序进行重大更改。只需在防腐层中处理这些变化。
-
翻译接口: 防腐层能够将外部系统的数据和行为转换为内部系统可以理解的形式,反之亦然。这包括数据格式的转换、方法调用的适配等。
-
保护领域模型: 防止外部模型的概念和问题污染内部的领域模型。防腐层确保内部模型的纯净性和一致性。
-
减少依赖性: 减少系统或子系统之间的直接依赖。通过防腐层,系统可以独立于外部系统的具体实现,使得未来的维护和升级更为容易。
防腐层在系统整合、微服务架构、遗留系统的现代化等场景中尤为重要。它可以帮助设计更加清晰、松耦合的系统架构,保证系统的长期健康和可维护性。
如果上述的论述你觉得有点儿晦涩难懂,我们就用普通的语言结合一个例子来阐述防腐层。
实际的开发中,有些后端的服务它可能是多个团队的数据生产者,而我们只是它的其中一个下游,因为它对多个下游提供服务,它的接口字段就比较脆弱,随时有面临修改的可能,当然也就不太可能单独为我们所在的团队做一些专有化的处理了;另外还有一个可能,后端可能提供2个版本的接口地址,比如/api/v1/getUserId和/api/v2/getUserId,有些时候可能产品需求在两个版本的接口环境下,前端页面都能够正常运行。
这个时候,我们就不能直接后端返给我们什么字段,就用什么字段,在这个位置上,我们就需要自行处理一个映射,这样,在后端面临可能的修改的时候,我们除了防腐层受到了影响,其它影响不会向我们更下层的软件系统传递,这样,就将改动的范围控制到了一个可接受的范围内。随着后端的不断迭代,软件系统并没有“腐化”,这就是为什么叫它防腐层的原因。
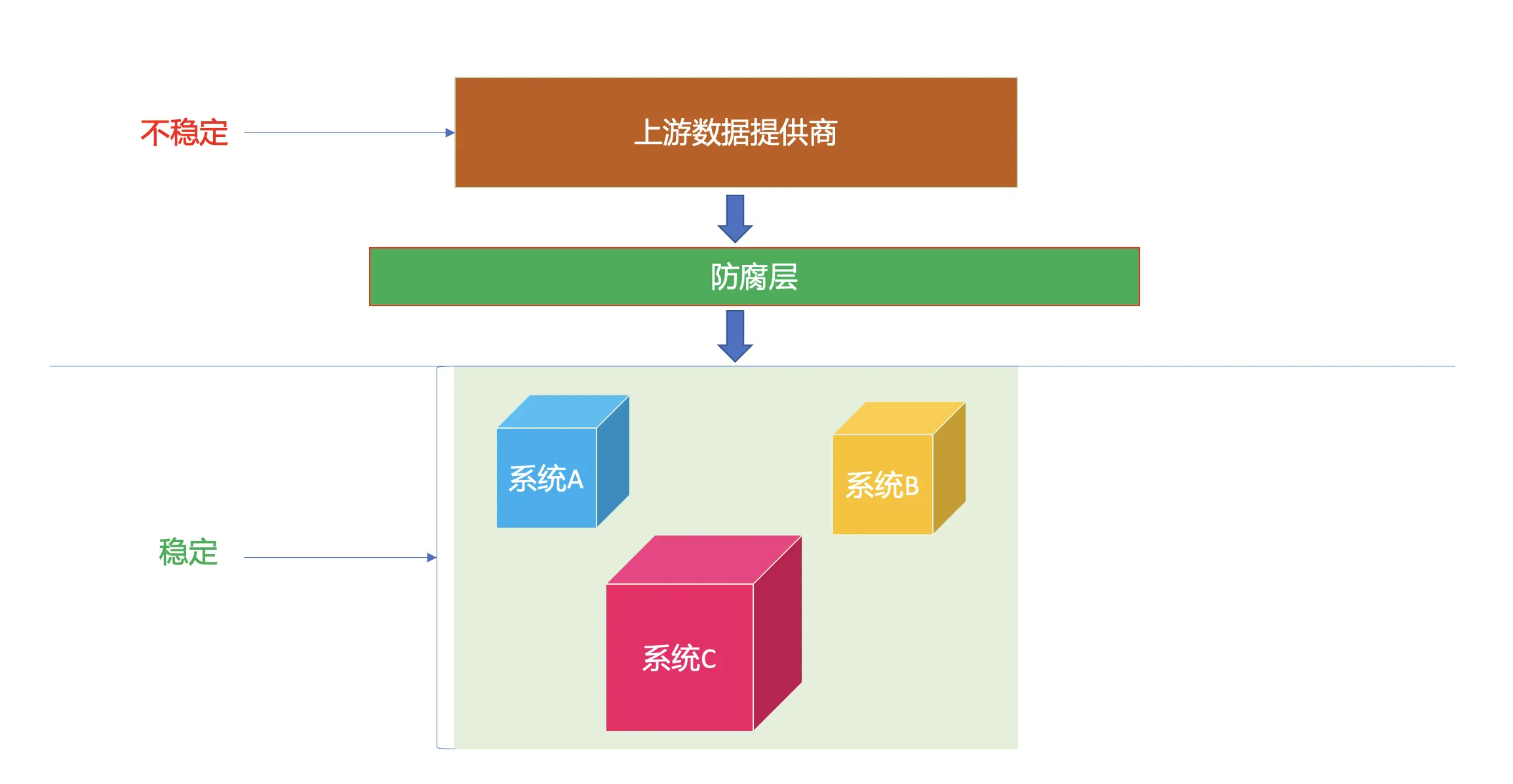
比如,在我去年做的BFF项目中,Node所有依赖的数据虽然全部来自服务端的gRPC服务,看起来似乎可以直接传递给更下层的逻辑使用,但是,我们并没有这样做,而是编写了一套对应的防腐层代码,在这层逻辑将后端的字段进行一些处理交给更下游的业务逻辑。这样就保证了gRPC调整的时候,我的改动范围仅仅被限制在了这个防腐层。
所以,这就是为什么在阐述适配器模式的时候有必要向大家聊一聊防腐层设计的原因,它的本质就适配器模式反向应用(这仅仅我个人的说法哦,我为什么是这么理解呢,适配器模式是为了解决A和B不兼容,A和B肯定是已经存在的,然后我们编写一层代码来连接A和B;而防腐层是在设计的时候就考虑到了A和B将来可能不兼容,因此抽离出一层来进行阻隔)实现分层设计,使得代码的耦合更低。
3、代码范式
abstract class Target {
abstract render(): void;
}
class Adaptee {
mount() {
console.log("渲染页面");
}
}
class Adaptor extends Target {
private adaptee: Adaptee;
constructor(adaptee: Adaptee) {
this.adaptee = adaptee;
}
render() {
this.adaptee();
}
}
function bootstrap() {
const adaptor = new Adaptor(new Adaptee());
adaptor.render();
}
有了Adaptor,比如你的项目最开始用的是高德地图API,现在换成百度地图API,只需要修改Adaptor类即可,因为适配之后规格已经一致了。
4、在前端开发中的实践
以下是在实际开发中可能遇到的例子。
4.1 使用适配器模式实现跨平台设计
相信大家一定都听说过uni-app,taro这类跨平台的框架(还有比如typeorm能支持不同数据库的dialect),这些跨平台框架除了能够支持将一份的代码编译到对应的平台(因为写法不同),还能支持在它顶层暴露一些可以支持操作各个平台都支持的API。
本文就以滴滴的mpx框架(一个增强自Vue的跨平台框架)来阐述。
比如有一个API,叫createApp,对于H5来说,可能这个API是从Vue里面导出的,对于小程序来说,可能这个API是存在于wx这个全局变量上的。
但是对于写业务代码的同学来说,他可不想在调用createApp这个API的时候还关心特定的环境,如果每个操作,代码都需要这样写的话,那么用跨平台框架的意义又是什么呢?所以框架的设计者对用户暴露的API必须是统一的。此刻,在框架设计时就可以引入一个适配器来处理根据当前环境应用不同的宿主能力了。
import { createApp as createAppInH5 } from "vue";
// 微信小程序 适配器,适配在微信小程序中的处理
function wxAdaptor() {
return wx.createApp();
}
// vue 适配器,适配在浏览器中的处理
function vueAdaptor() {
return createAppInH5();
}
// 适配器工厂,根据mpx提供的宿主环境选择对应平台的API处理
function getAdaptor() {
let selectedAdaptor = null;
switch (mode) {
case "wx":
selectedAdaptor = wxAdaptor;
break;
default:
selectedAdaptor = vueAdaptor;
break;
}
return selectedAdaptor;
}
// 对外暴露一个包裹好的API,业务开发人员可以毫无心智负担的调用
export function createApp(...args) {
const adaptor = getAdaptor();
return adaptor.apply(this, args);
}
4.2 数据源和业务的解耦
就拿现在我所在的业务团队来举例吧,因为公司的业务调整,原来北京的研发团队全部被解散,在成都新建了研发团队。
由于不同的团队,有自己的编码风格,所以后来后端的接口就有一些调整,比如原来北京的同事取名叫user_id,现在的同事取名叫userId,还有些项目叫userid,拉齐他们的接口有一定的历史包袱,所以不能100%的做到拉齐。因此就只能通过业务开发去做这个兜底。
此时,如果去改业务代码是不太聪明的,而且改动量不可估量,容易产生潜在的bug,这显然是不太符合开闭原则的。
但是我们有个比较好的办法,因为原来的数据接口(axios请求后端的接口)全部抽离在了一个数据访问层的,此刻就可以给它套一个适配器就可以精准解决这个问题。
没有修改之前的代码如下:
// 获取榜单数据列表
function getRankList() {
return fetch("https://xxx.com/v2/api/getRankList").then((res) => res.json());
}
添加适配器之后的代码如下:
function getRankList() {
return fetch("https://xxx.com/v2/api/getRankList")
.then((res) => res.json())
.then((res) => {
return {
...res,
data: {
list: res.data.list.map((row) => {
const userId = row.userid || row.userId || row.user_id;
// 兜底全部可能的key,这样业务代码不需要进行修改
return {
...row,
userId,
user_id: userId,
userid: userId,
};
}),
},
};
});
}
所以,从这个例子可以看出,对于前端的组件开发中,如果直接把数据请求的逻辑写到组件上,可能是不太好的。
还有一个场景也与这个场景类似,其实我们在写的业务组件内部兜底需要做很多事儿的,而且代码也会比较多。
如果我们直接用验证器校验数据,然后在组件内部就不需要做兜底的话,那代码写起来肯定要舒服很多,此刻就可以利用适配器的思路,在给组件传递数据之前对其进行标准化。
下述代码是一个简单的例子:
// 数据访问层
function standardUserInfo(user) {
return {
...user,
address: user.address || {
province: "北京市",
city: "北京市",
area: "海淀区",
},
};
}
function getUserList() {
return fetch("/getUsers").then((res) => {
return {
...res,
data: (res.data || []).map(standardUserInfo),
};
});
}
// 业务组件
import React from "react";
import getUserList from "repository";
class UserList extends React.Component {
constructor() {
super();
this.state = {
userList: [],
};
}
componentDidMount() {
getUserList().then((res) => {
this.setState({
userList: res.data,
});
});
}
render() {
return (
<div class="wrapper">
{this.state.userList.map((u, idx) => {
return <User info={u} key={idx} />;
})}
</div>
);
}
}
4.3 参数归一化
这个例子是来源于渡一前端袁进老师的短视频,但是很多同学可能没有把它和适配器模式联系起来。
以下是使用适配器模式编写的一个工具函数groupBy:
/**
* 对数据进行分组
* @param arr 源数据
* @param groupByPredicate 分组条件
* @returns
*/
export function groupBy<T>(
arr: T[],
groupByPredicate: ((item: T) => string) | string
) {
const fn =
typeof groupByPredicate === "string"
? (item: T) => item[groupByPredicate]
: groupByPredicate;
const record: Record<string, T[]> = {};
arr.forEach((item) => {
const groupByProp = fn(item);
let group = record[groupByProp];
if (!group) {
record[groupByProp] = [item];
} else {
group.push(item);
}
});
return record;
}
以下是这个函数的测试用例,它既可以对普通类型进行分组,也可以对复杂类型进行分组,就提高了我们代码的适应性,对外部的调用者非常友好。
import { groupBy } from "./group-by";
describe("group by test", () => {
it("group age", () => {
const list = [
{
name: "wangwu",
age: 12,
},
{
name: "zhangsan",
age: 12,
},
{
name: "lisi",
age: 18,
},
{
name: "zhaosi",
age: 17,
},
];
const res = groupBy(list, "age");
expect(res).toEqual({
12: [
{
name: "wangwu",
age: 12,
},
{
name: "zhangsan",
age: 12,
},
],
18: [
{
name: "lisi",
age: 18,
},
],
17: [
{
name: "zhaosi",
age: 17,
},
],
});
});
it("group by age+gender", () => {
type Person = { name: string; age: number; gender: string };
const list: Person[] = [
{
name: "wangwu",
age: 12,
gender: "male",
},
{
name: "zhangsan",
age: 12,
gender: "female",
},
{
name: "lisi",
age: 18,
gender: "female",
},
{
name: "zhaosi",
age: 17,
gender: "male",
},
{
name: "Alice",
age: 18,
gender: "female",
},
];
const res = groupBy(list, (item: Person) => {
return item.age + "+" + item.gender;
});
expect(Object.keys(res).length).toBe(4);
});
it("group by basic type", () => {
const nums = [1, 2, 3, 4, 5, 6, 7, 8];
const res = groupBy(nums, (item) => {
return item % 2 !== 0 ? "odd" : "even";
});
expect(res).toEqual({
odd: [1, 3, 5, 7],
even: [2, 4, 6, 8],
});
});
});
4.4 Axios中的Adaptor
这个适配器模式,说的就比较宏观了,它实现的是我们上层的接口能力和底层API的差异适配。
在浏览器中,我们能够通过XMLHttpRequest对象(或Fetch)和服务端进行通信,俗称Ajax,但是在Node环境中,因为它不是运行在浏览器中了,只有node提供的http模块。但是,对于axios的使用者来说,我们不关心你
用什么手段进行通信,反正我只要能够把请求发出去,你把结果返回给我,这就是我的目的。
所以,axios在设计的过程中,就分别对浏览器和Node环境分别编写了两套适配器,然后根据当前的使用环境决定使用哪个适配器,这样用户就可以和服务端进行通信了。
有经验的同学已经看到了,这儿不仅是适配器模式的应用,而是一个策略模式的使用场景,因为它根据环境决定了使用什么策略处理逻辑,所以,设计模式往往可能并不是单一存在的,只要能够把代码写的好,用什么设计模式不重要。
使用Http模块实现的Node环境下的通信:
使用XHR对象实现的浏览器环境下的通信: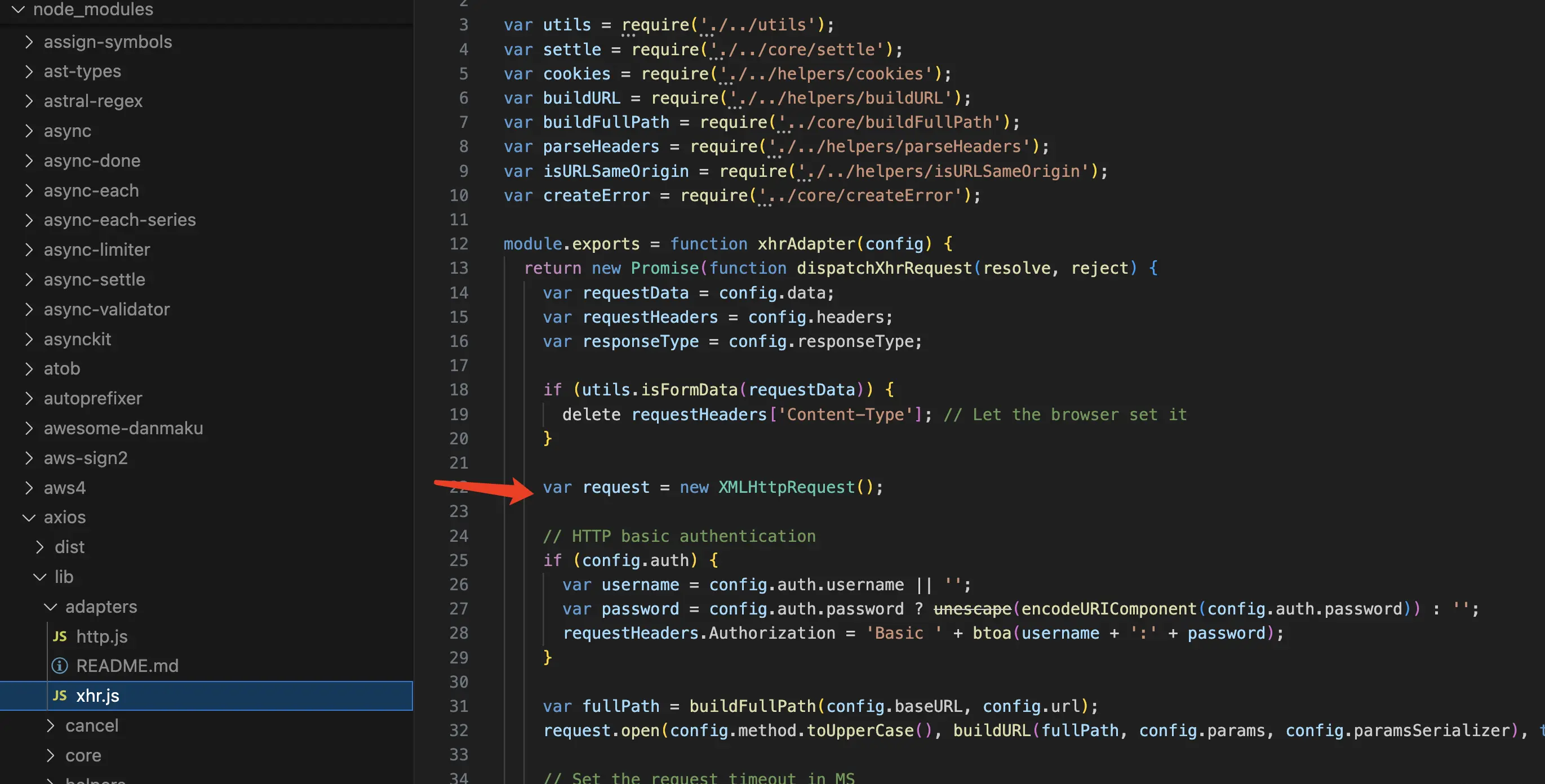
4.5 NestJS中的Adaptor
这个应用案例,跟上面我们提到的axios的例子也是差不多的,也是宏观上的适配器模式。
对于Node框架编写Http服务器来说,框架它肯定是对一些更底层逻辑进行封装,最终肯定还是调用的是Node的原生模块(比如Http模块)。因为开发的团队不同,大家都有自己独特的见解,于是就出现了Express,Fastify等框架。
而NestJS是一个帮助我们组织代码架构的一层抽象,就是说它仅仅是帮助我们更好组织代码,实际上,我们还是操作的是Express。
实际应用中,有些团队觉得Express好,有些团队觉得Express不好,那怎么能够让这些觉得Express不好的团队也加入NestJS呢,那就需要允许这些觉得Express不好的人能够换一个他们觉得好的底层框架,但是仍然使用NestJS中代码组织方式编写,这样就解决了矛盾。
所以,这也就是NestJS团队所提出的平台无关的哲学。为此,NestJS提供了官方两套实现,一个是默认的Express HttpAdaptor,一个是Fastify HttpAdaptor供我们选择,而如果你的团队觉得这两套实现都不好,NestJS还允许你自己编写一个HttpAdaptor实现。
以下是Express的实现: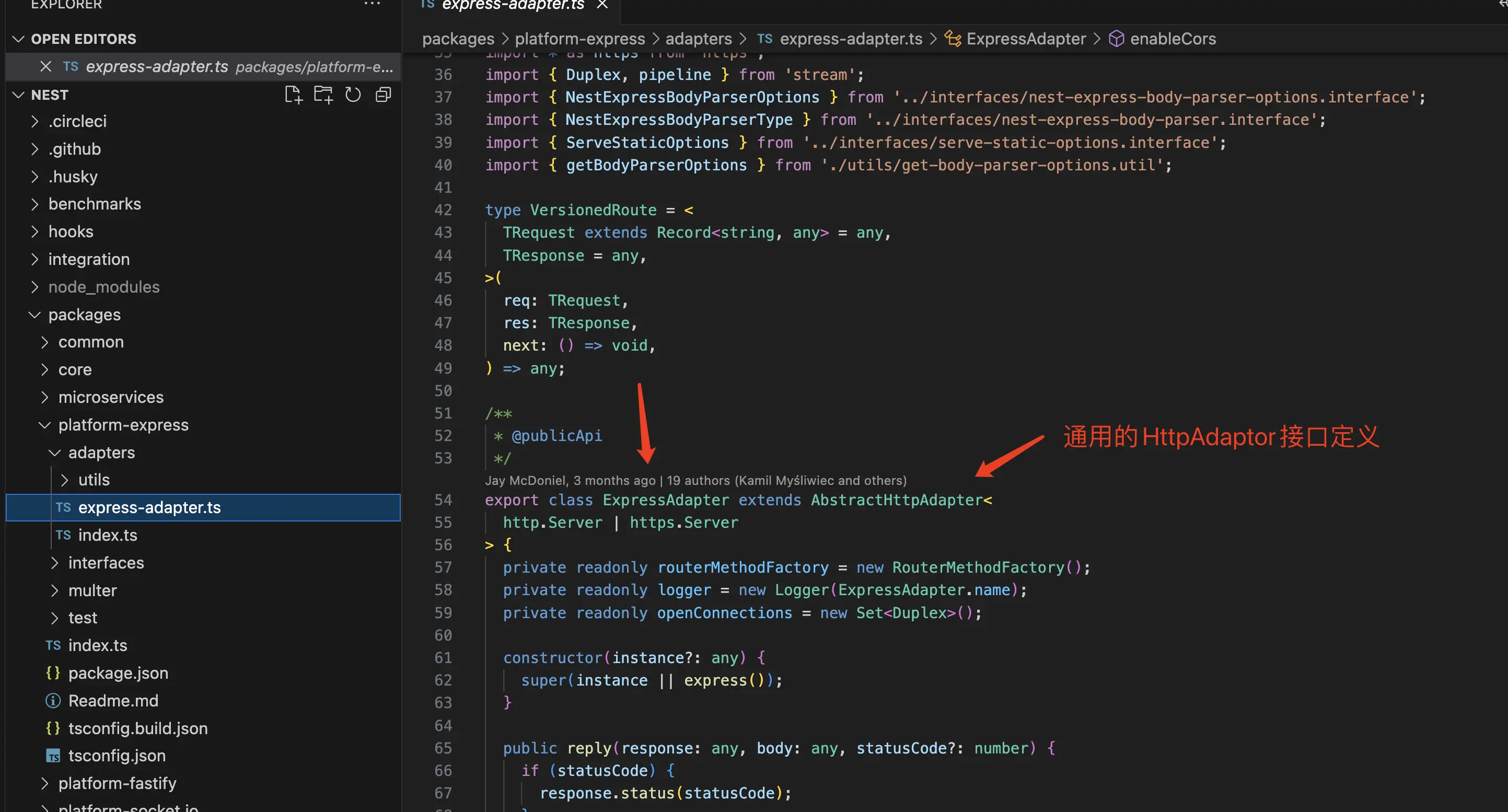
以下是Fastify的实现: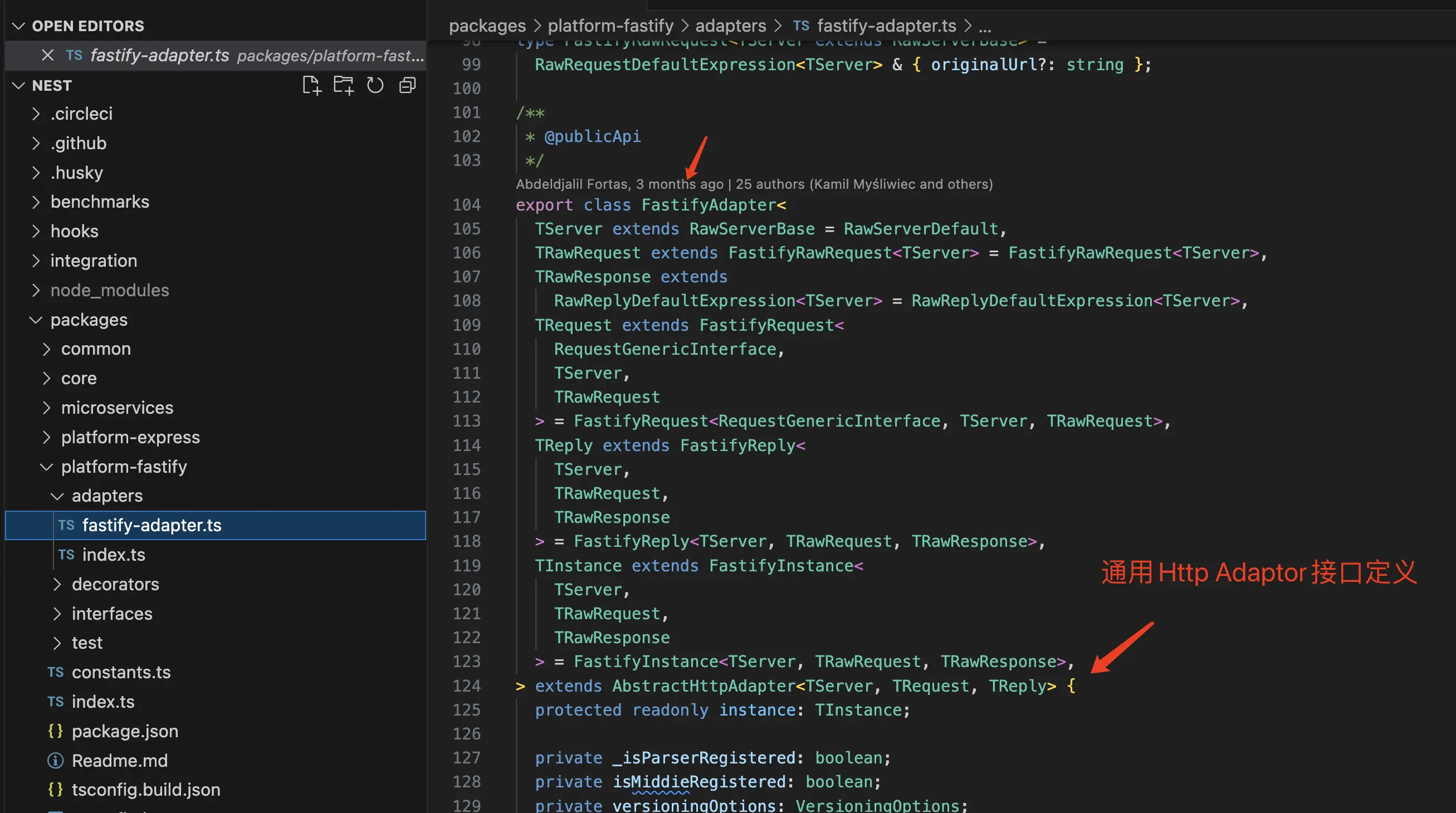
以下是通用的Adaptor的定义,如果我们想使用别的底层框架编写NestJS项目,直接实现这个接口即可。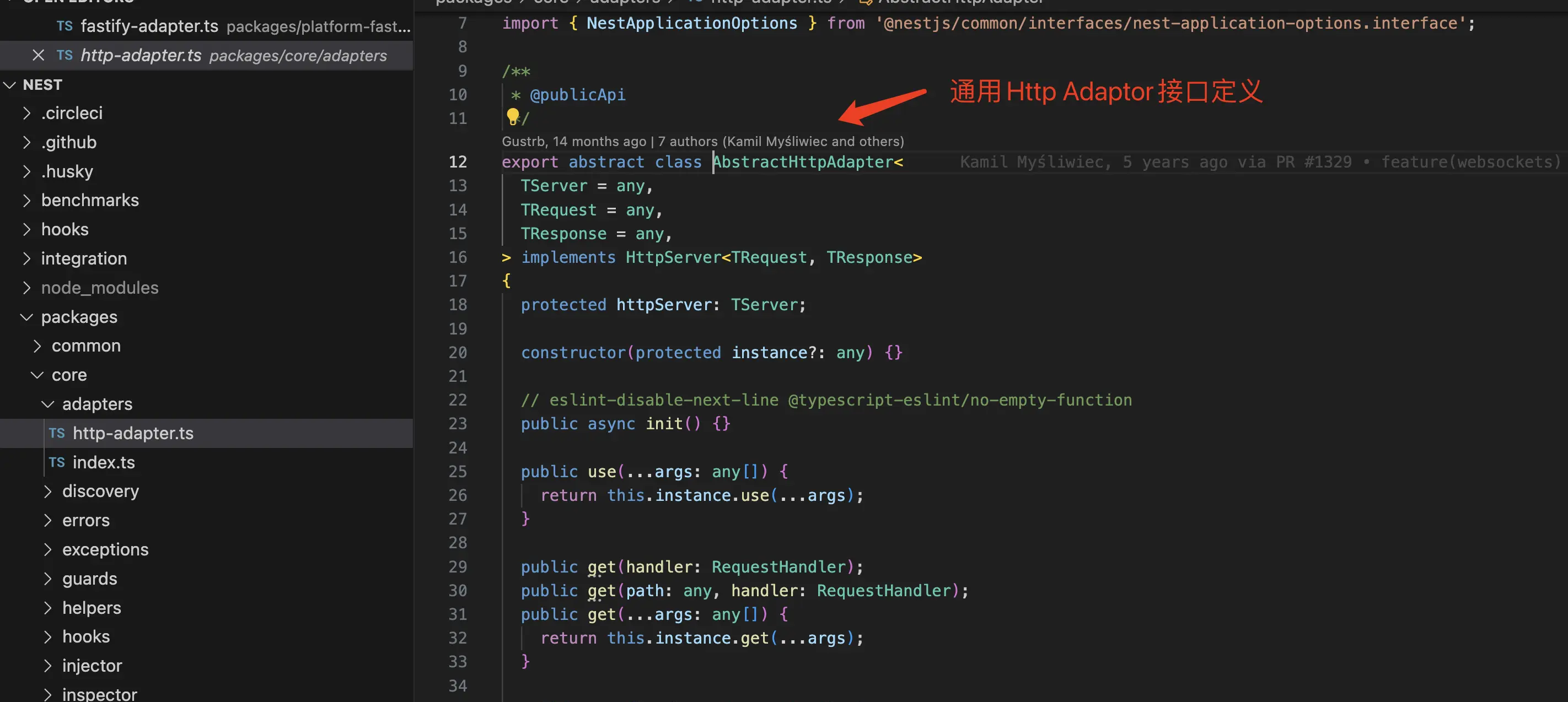
总结
从上面的案例可以看出,使用适配器模式能够解决很多代码设计不兼容的问题,从而提高代码的复用性和灵活性。
但是从代码的运行效率来说,适配器模式因为增加了一层转接层,实际上我们的代码的运行效率是降低了的(是不是显著的降低,具体还看你的实际情况哦),但是这并不妨碍我们使用它,毕竟能用只是慢一点儿,总比可能出错要好吧,哈哈哈。
在编写一些基础库的时候,使用适配器模式进行设计,可以增加系统的可扩展性,各位读者可以结合自己的实际项目加以体会。
原文链接:https://juejin.cn/post/7323203806795186210 作者:HsuYang