
Vue3 的调度系统
Vue3 中需要处理许多任务,比如:用户操作、watch 回调、组件自更新(渲染)等。Vue3 为了合理的管理这些任务,提高框架性能,特意设计了任务调度系统。所以,Vue3 中调度系统的作用是为了保证任务的执行顺序和框架性能。比如:要保证父组件比子组件先渲染,组件的生命周期回调、watch API 的回调函数等的执行顺序,同时也要避免任务的重复调用,提高框架性能。
Vue3 的任务调度系统的源码在 packages/runtime-core/src/scheduler.ts 文件中。可在源码中知道任务(Job)的数据结构为:
export interface SchedulerJob extends Function {
id?: number
pre?: boolean
active?: boolean
computed?: boolean
/**
* Indicates whether the effect is allowed to recursively trigger itself
* when managed by the scheduler.
*
* By default, a job cannot trigger itself because some built-in method calls,
* e.g. Array.prototype.push actually performs reads as well (#1740) which
* can lead to confusing infinite loops.
* The allowed cases are component update functions and watch callbacks.
* Component update functions may update child component props, which in turn
* trigger flush: "pre" watch callbacks that mutates state that the parent
* relies on (#1801). Watch callbacks doesn't track its dependencies so if it
* triggers itself again, it's likely intentional and it is the user's
* responsibility to perform recursive state mutation that eventually
* stabilizes (#1727).
*/
allowRecurse?: boolean
/**
* Attached by renderer.ts when setting up a component's render effect
* Used to obtain component information when reporting max recursive updates.
* dev only.
*/
ownerInstance?: ComponentInternalInstance
}
本文的源码均摘自 Vue.js 3.2.45
从源码中可以知道,Vue3 中的任务其实就是函数,其中每个字段的含义如下;
-
id,任务的唯一标识,用于表示任务的优先级,id值越小,任务的优先级越高。 -
pre,标识是否为pre类型的任务 -
active,表示当前任务是否为激活状态 -
computed,表示是否是计算属性的任务 -
allowRecurse,表示任务是否允许递归触发-
默认情况下,任务是不允许递归触发的,因为一些内置方法的调用,比如: Array.prototype.push (数组的 push 方法),在执行写的时候也同时执行了读取操作(push 方法执行后会读取数组的 length 属性),这可能会导致令人困惑的无限循环。
-
允许递归触发的情况为组件更新函数和 watch 回调,watch 回调函数默认是 pre 任务类型,会在组件更新前执行。当组件更新时,可能会改变子组件的 props ,可能会导致子组件 watch 回调的执行,watch 回调又有可能改变父组件的状态,从而产生递归触发任务的情况。watch 侦听器不会追踪自己的依赖,因此当 watch 回调再次触发自身时,有可能是用户有意为之,因此由用户负责避免任务无限递归触发自身的情况。
-
-
ownerInstance,存储对应组件的实例,仅用于开发环境,用于递归调用超出最大次数时,报告相关组件信息
Vue3 的调度系统中,由 3 种不同类型的任务队列,分别为 Pre 队列、queue 队列、Post 队列
| Pre 队列 | queue 队列 | Post 队列 | |
|---|---|---|---|
| 队列作用 | 执行组件 DOM 更新之前的任务 | 执行组件 DOM 更新的任务 | 执行组件 DOM 更新之后的任务 |
| 出队方式 | 先进先出 | 允许插队,按 id 从小到大执行 | 允许插队,按 id 从小到大执行 |
Pre 队列 的作用是执行组件 DOM 更新之前的任务,queue 队列 的作用是执行组件 DOM 更新的任务,Post 队列 执行组件 DOM 更新之后的任务。
Pre 队列 的出队方式是先进先出,没有优先级的机制,先入队先执行。
queue 队列 和 Post 队列 则由优先级机制,任务按 id 从小到大排序,id 小的优先级高,会先执行,并且允许插队。
// 是否正在刷新队列
let isFlushing = false
// 是否正在等待刷新队列,即将 flushJobs 方法放入微任务队列前
let isFlushPending = false
// 存放 Pre 任务和 queue 任务的队列
const queue: SchedulerJob[] = []
// queue 队列的指针,并于遍历 queue
let flushIndex = 0
// 等待执行的 Post 任务队列,用于存放等待执行的 Post 任务
const pendingPostFlushCbs: SchedulerJob[] = []
// 当前激活的 Post 任务队列
let activePostFlushCbs: SchedulerJob[] | null = null
// activePostFlushCbs 的指针,用于遍历 activePostFlushCbs
let postFlushIndex = 0
// 用于将刷新任务队列的函数(flushJobs)放入微任务中,
// 用于创建一个微任务
const resolvedPromise = /*#__PURE__*/ Promise.resolve() as Promise<any>
// 存储当前刷新队列的 Promise
let currentFlushPromise: Promise<void> | null = null
// 任务递归的最大次数
const RECURSION_LIMIT = 100
👆 上面代码解释了 Vue3 调度系统中一些变量的含义和作用
Pre 队列和组件 DOM 更新队列(queue 队列)的入队函数是 queueJob ,它们公用同一个队列(queue)。Post 队列的入队函数是 queuePostFlushCb ,用的是另外一个队列(pendingPostFlushCbs),并且在执行时,会将等待执行的 Post 队列(pendingPostFlushCbs)放入激活的 Post 队列中(activePostFlushCbs)。
export function queueJob(job: SchedulerJob) {
// the dedupe search uses the startIndex argument of Array.includes()
// by default the search index includes the current job that is being run
// so it cannot recursively trigger itself again.
// if the job is a watch() callback, the search will start with a +1 index to
// allow it recursively trigger itself - it is the user's responsibility to
// ensure it doesn't end up in an infinite loop.
if (
!queue.length ||
// 去重处理
!queue.includes(
job,
// isFlushing 表示正在执行刷新队列
// flushIndex 当前正在执行的任务(Job)的 index
// 数组 includes 函数的第二个参数,是表示从该索引开始查找
// 整个表达式意思:如果允许递归,则当前正在执行的任务(Job),不加入去重判断,
// 由用户负责避免无限递归
isFlushing && job.allowRecurse ? flushIndex + 1 : flushIndex
)
) {
if (job.id == null) {
// 没有 id 的加入到队列末尾,优先级最低
queue.push(job)
} else {
// 二分查找 job.id,计算出需要插入的位置,
// 用于插队,保证队列中的任务以正确的顺序执行
queue.splice(findInsertionIndex(job.id), 0, job)
}
// 将队列放到微任务中执行
queueFlush()
}
}
queueJob 函数使用了数组方法 includes 去重。这里不使用 Set 数据结构来去重,是为了保证队列中副作用函数的顺序。Set 是无序的数据结构,它不会保持元素的插入顺序。另外数组自带的 includes 方法提供了 startIndex 参数,可以更灵活地进行去重搜索,即指定从特定的索引开始搜索。
如果副作用函数唯一标识符 (id 为 null),则直接使用 push 方法将副作用函数添加到队列(queue)末尾。该任务的优先级最低,会在最后执行。
queue 使用数组方法 splice 执行任务的插入操作。在 findInsertionIndex 函数中使用使用二分查找,根据 id 查找插入的位置。
// #2768
// Use binary-search to find a suitable position in the queue,
// so that the queue maintains the increasing order of job's id,
// which can prevent the job from being skipped and also can avoid repeated patching.
function findInsertionIndex(id: number) {
// the start index should be `flushIndex + 1`
let start = flushIndex + 1
let end = queue.length
while (start < end) {
const middle = (start + end) >>> 1
const middleJobId = getId(queue[middle])
middleJobId < id ? (start = middle + 1) : (end = middle)
}
return start
}
队列中的任务 id 是递增的,使用二分查找的方式寻找插入的位置,主要是为了保证任务队列中的任务 id 保持递增的顺序,这样可以防止任务被跳过,也可以避免重复更新。
const getId = (job: SchedulerJob): number =>
job.id == null ? Infinity : job.id
由 getId 函数的实现可知,对于没有 id 的任务,该任务的 id 会被认为是 Infinity ,表示该任务的优先级最低,会排在任务队列的最后面,因此会最后执行。
function queueFlush() {
if (!isFlushing && !isFlushPending) {
isFlushPending = true
currentFlushPromise = resolvedPromise.then(flushJobs)
}
}
当前不是正在刷新任务队列与正在等待执行任务队列,则将执行刷新任务队列的函数(flushJobs) 放入微任务队列中。这样可以保证 1 个微任务队列中只有 1 个任务队列在刷新。
function flushJobs(seen?: CountMap) {
isFlushPending = false
// 把表示正在刷新任务队列的标识设置为 true ,
// 避免重复刷新
isFlushing = true
if (__DEV__) {
seen = seen || new Map()
}
// Sort queue before flush.
// This ensures that:
// 1. Components are updated from parent to child. (because parent is always
// created before the child so its render effect will have smaller
// priority number)
// 2. If a component is unmounted during a parent component's update,
// its update can be skipped.
queue.sort(comparator)
// 用于检测是否是无限递归,最多 100 层递归,否则就报错,只会开发模式下检查
const check = __DEV__
? (job: SchedulerJob) => checkRecursiveUpdates(seen!, job)
: NOOP
try {
// 循环组件异步更新队列,执行 job
for (flushIndex = 0; flushIndex < queue.length; flushIndex++) {
const job = queue[flushIndex]
// 失效的 job 不可执行
if (job && job.active !== false) {
// 开发环境下,任务递归次数超过 100 次,
// 则跳过,不执行该任务
if (__DEV__ && check(job)) {
continue
}
// 调用 job,带有错误处理
callWithErrorHandling(job, null, ErrorCodes.SCHEDULER)
}
}
} finally {
flushIndex = 0
// 清空任务队列
queue.length = 0
// 执行 Post 队列
flushPostFlushCbs(seen)
isFlushing = false
currentFlushPromise = null
// 检查队列 queue 、pendingPostFlushCbs 是否还由未执行的任务,
// 如果有,则继续执行刷新队列的函数 flushJobs ,
// 直到 queue 队列、pendingPostFlushCbs 队列为空为止
if (queue.length || pendingPostFlushCbs.length) {
flushJobs(seen)
}
}
}
实现刷新任务队列的函数 flushJobs 。在刷新任务队列时,会先调用 sort 方法对任务队列进行排序,通过任务对象的 id 与 pre 属性来判断任务队列中的优先级。如上面源码中的注释也说明了对任务队列进行排序的原因:
-
确保先执行父组件的渲染任务,因为父组件总是在子组件之前创建,所以父组件渲染任务的 id 值会比子组件的小,使用 sort 排序后,可保证任务队列中的任务 id 保持递增的顺序,这样可以保证父组件的任务比子组件的任务先执行。
-
如果在父组件更新过程中卸载了子组件,则该子组件的更新可以跳过(此时,子组件产生的任务不会被加入队列中,因为组件已经被卸载,执行该组件的任务毫无意义)
在 Pre 队列、queue 队列执行完后(queue.length = 0), 会执行 Post 队列(调用 flushPostFlushCbs 函数)。
因为 Post 队列执行过程中,可能又会将 Job 加入进来,所以最后会检查 queue (Pre 队列、queue 队列)、pendingPostFlushCbs (Post 队列)是否还有任务,如果有则会继续执行刷新任务队列的函数 flushJobs ,直到任务队列为空。
const comparator = (a: SchedulerJob, b: SchedulerJob): number => {
const diff = getId(a) - getId(b)
if (diff === 0) {
if (a.pre && !b.pre) return -1
if (b.pre && !a.pre) return 1
}
return diff
}
comparator 函数是用于比较任务优先级的函数,comparator 函数首先通过调用 getId 函数获取两个任务( SchedulerJob 对象)的 id 值,并计算它们的差值,将结果保存在变量 diff 中。
-
如果 diff 大于 0,则说明 a 的优先级低于 b
-
如果 diff 小于 0,则说明 a 的优先级高于 b
-
如果 diff 等于 0 ,则说明两个任务( SchedulerJob 对象)的 id 值相等,这个情况下会进一步比较它们的 pre 属性。
-
如果 a.pre 为 true,而 b.pre 为 false,则说明 a 的任务应该先执行,此时函数返回 -1 。相反,如果 b.pre 为 true,而 a.pre 为 false,则说明 b 的任务应该先执行,此时函数返回 1 。
function checkRecursiveUpdates(seen: CountMap, fn: SchedulerJob) {
if (!seen.has(fn)) {
// 1. 使用 map 记录 fn 的调用次数
seen.set(fn, 1)
} else {
const count = seen.get(fn)!
if (count > RECURSION_LIMIT) {
// 3. count 超过限制次数,则打印警告信息
const instance = fn.ownerInstance
const componentName = instance && getComponentName(instance.type)
warn(
`Maximum recursive updates exceeded${
componentName ? ` in component <${componentName}>` : ``
}. ` +
`This means you have a reactive effect that is mutating its own ` +
`dependencies and thus recursively triggering itself. Possible sources ` +
`include component template, render function, updated hook or ` +
`watcher source function.`
)
return true
} else {
// 2. fn 每调用 1 次,count 加 1
seen.set(fn, count + 1)
}
}
}
checkRecursiveUpdates 函数的作用是用于检查任务(Job)递归调用的次数是否超过限制,主要是通过计数的方式来实现,即记录任务(Job)的调用次数,如果任务(Job)的调用次数超过阈值(RECURSION_LIMIT),就会提示用户。
export function queuePostFlushCb(cb: SchedulerJobs) {
if (!isArray(cb)) {
// 如果 cb 不是数组
if (
// activePostFlushCbs 不存在或者通过去重处理 ,activePostFlushCbs 中不存在 cb,
// 才能将 cb 加入到 Post 队列,
// postFlushIndex 是当前 Post 任务的索引,如果任务允许递归,
// 则从 postFlushIndex + 1 开始查找
!activePostFlushCbs ||
// 去重处理
!activePostFlushCbs.includes(
cb,
cb.allowRecurse ? postFlushIndex + 1 : postFlushIndex
)
) {
pendingPostFlushCbs.push(cb)
}
} else {
// 如果回调函数(cb)是一个数组,说明它是一个组件生命周期钩子,
// 因为组合式 API 可以多次调用同一个钩子。
// 生命周期钩子函数只能由 post 任务队列管理触发执行,
// 由于 post 任务(cb)会在执行的时候做去重处理,
// 所以可以直接加到 post 的等待执行队列中(pendingPostFlushCbs)
pendingPostFlushCbs.push(...cb)
}
queueFlush()
}
queuePostFlushCb 函数是 Post 队列入队的函数。手动设置了 post 的 watch 回调、mounted、updated 等生命周期的回调,它们都会被加入到 Post 队列中。反正,凡是需要等 DOM 更新后再执行的任务,都会加入到 Post 队列中管理。
queuePostFlushCb 函数也是用数组方法 includes 做去重,上文已经分析过使用 includes 去重的原因,这里不再赘述。
组件实例会用数组来存储组件生命周期钩子的回调函数,因为组合式 API 可以多次调用同一个钩子。
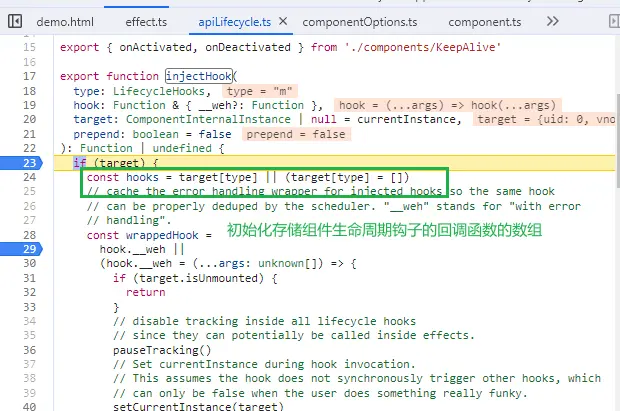

执行 Post 队列的函数是 flushPostFlushCbs 。
export function flushPostFlushCbs(seen?: CountMap) {
// 存在等待执行的 Post 任务队列
if (pendingPostFlushCbs.length) {
// 执行 Post 任务队列前去重,并赋值到 deduped
const deduped = [...new Set(pendingPostFlushCbs)]
// 清空 pendingPostFlushCbs
pendingPostFlushCbs.length = 0
// #1947 已经存在激活的 Post 队列,说明是在一个嵌套的 flushPostFlushCbs 调用中,
// 则将去重后的任务队列 push 到当前激活的任务队列中
if (activePostFlushCbs) {
activePostFlushCbs.push(...deduped)
return
}
activePostFlushCbs = deduped
if (__DEV__) {
seen = seen || new Map()
}
// 执行 Post 任务队列前先对任务排序,保证任务的执行顺序正确
activePostFlushCbs.sort((a, b) => getId(a) - getId(b))
// 循环执行 Post 任务队列中的任务
for (
postFlushIndex = 0;
postFlushIndex < activePostFlushCbs.length;
postFlushIndex++
) {
// 开发模式下,校验无限递归的情况
if (
__DEV__ &&
checkRecursiveUpdates(seen!, activePostFlushCbs[postFlushIndex])
) {
continue
}
// 取出 Post 任务队列中的任务执行
activePostFlushCbs[postFlushIndex]()
}
// 收尾工作
activePostFlushCbs = null
postFlushIndex = 0
}
}
由上面的代码可知道,Vue3 在执行 Post 队列的时候,会先进行去重处理,主要是为了避免任务重复调用,还会使用任务 id 来对任务队列进行排序,id 值小的任务会排在前面,优先级较高,从而会优先执行,通过排序的方式保证了 Post 任务队列的任务以正确的顺序执行。
执行 Pre 队列的函数是 flushPreFlushCbs 。
export function flushPreFlushCbs(
seen?: CountMap,
// if currently flushing, skip the current job itself
i = isFlushing ? flushIndex + 1 : 0
) {
if (__DEV__) {
seen = seen || new Map()
}
// 循环 pre 队列
for (; i < queue.length; i++) {
const cb = queue[i]
// 判断必须是 pre 类型的任务
if (cb && cb.pre) {
// 开发环境,校验无限递归
if (__DEV__ && checkRecursiveUpdates(seen!, cb)) {
continue
}
// 将当前 cb 从队列中删除
queue.splice(i, 1)
i--
// 执行任务
cb()
}
}
}
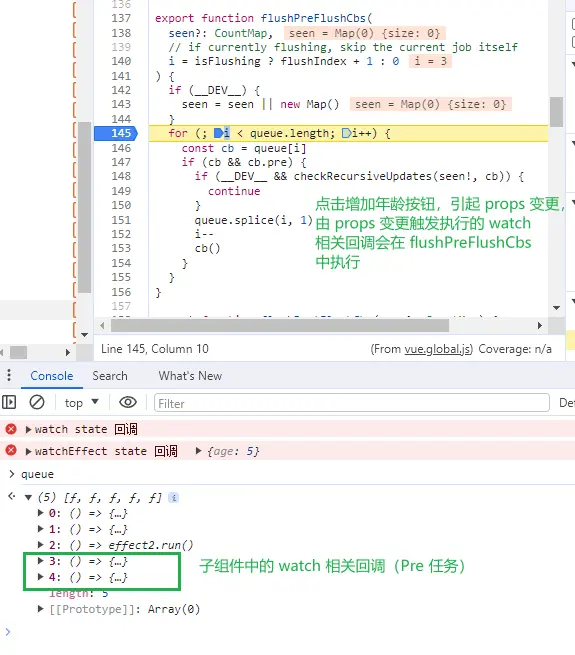
由上面的代码可知道,Vue3 中 Pre 队列没有自己的队列,而是复用了 queue 队列,同时也没有自己的入队函数,复用的 queueJob 方法,Pre 队列和 queue 队列的任务共用了一个队列 queue ,任务通过 pre 属性来区分。并且 flushPreFlushCbs 函数在执行 pre 任务的时候,会从队列(queue)中删除,不会影响后续在组件更新时执行的 queue 队列任务。
Vue3 执行 Pre 队列的任务时,会采用先进先出的策略执行任务,不允许插队,也没有优先级的区分。
watch 、watchEffect 的回调函数默认都会进入 Pre 队列进行管理。由于 props 变更触发的 watch 、watchEffect 回调函数会在 flushPreFlushCbs 函数中被执行,由组件自身状态变更触发的 watch 、watchEffect 回调函数会在 flushJobs 中被执行。如下面的例子所示:
<script src="../../dist/vue.global.js"></script>
<script type="text/x-template" id="child-template">
<div>
<p>名字:{{productName}}</p>
<p>年龄:{{age}}</p>
<button @click="changeName">改名</button>
</div>
</script>
<script>
const DemoChild = {
template: '#child-template',
props: {
age: Number
},
setup(props) {
const productName = Vue.ref('小明')
const watchEffectCb = function testWatchEffect() {
console.error('子组件 watchEffect props 回调 ====== ', {
age: props.age
})
}
const changeName = function updateName() {
productName.value = productName.value + props.age
}
Vue.watchEffect(watchEffectCb)
Vue.watchEffect(() => {
console.error('子组件 watchEffect state 回调', {
name: productName.value
})
})
Vue.watch(() => props.age, () => {
console.error('子组件 watch props 回调')
})
return {
productName,
changeName
}
}
}
</script>
<div id="app">
<demo-child
:age="age">
</demo-child>
<button @click="addAge">增加年龄</button>
</div>
<script>
Vue.createApp({
components: {
DemoChild
},
setup () {
const age = Vue.ref(3)
function addAge() {
const old = age.value
age.value = old + 1
}
Vue.watch(age, () => {
console.error('watch state 回调')
})
Vue.watchEffect(() => {
console.error('watchEffect state 回调 ', {
age: age.value
})
})
return {
age,
addAge
}
}
}).mount('#app')
</script>
父组件和子组件的 watch 、watchEffect 的回调函数复用了同一个任务队列(queue),那 Vue3 是如何保证父组件的 watch 相关回调比子组件的 watch 相关回调先执行的?因为父组件比子组件先渲染,所以父组件的 watch 相关回调会比子组件的相关回调先入队,因此父组件的 watch 相关回调会比子组件的 watch 相关回调先执行。同时在执行子组件的 watch 相关回调的时候,会从未执行的任务索引处开始遍历,这样也避免了重复执行父组件的 watch 相关回调。
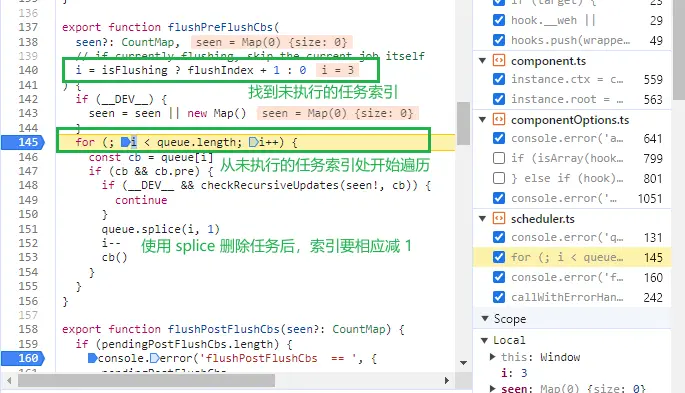
组件由于自身状态变更触发执行的 watch 、watchEffect 回调函数会在 flushJobs 中被执行
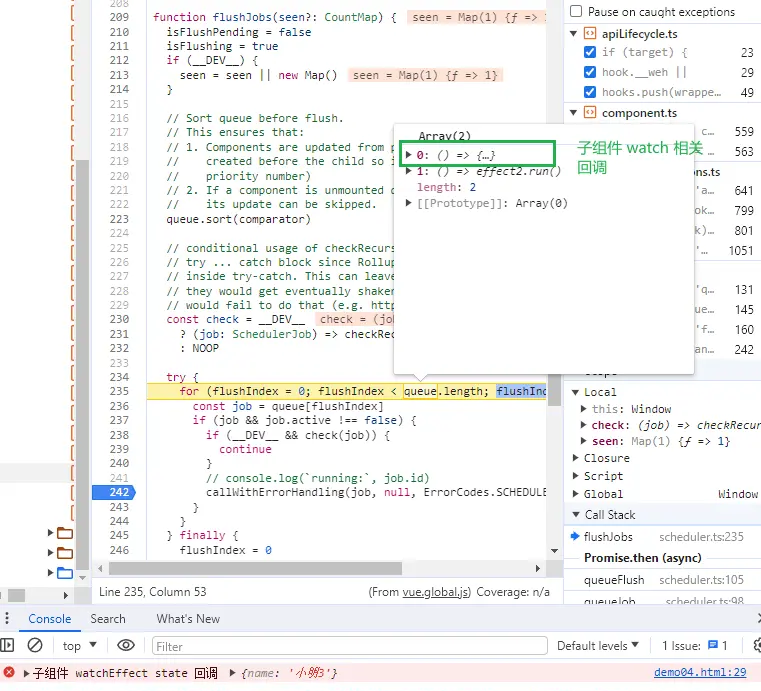
组件由于 props 变更触发执行的 watch 、watchEffect 回调函数会在 flushPreFlushCbs 函数中被执行。
export function invalidateJob(job: SchedulerJob) {
const i = queue.indexOf(job)
if (i > flushIndex) {
queue.splice(i, 1)
}
}
invalidateJob 函数用于删除队列(queue)中的任务。由于组件 DOM 更新(instance.update),是深度更新(深度优先),会递归的对所有子组件执行更新(instance.update)。
因此,在父组件深度更新完成之后,不需要再重复更新子组件,在执行子组件的更新任务前,会将该任务从队列中删除。
比如,当子组件更新了自己的状态,同步向父组件 emit 一个事件,通过这个事件更新父组件内部的状态和自身的 props ,从而再次触发子组件的更新,这时子组件的更新任务就会被删除。因为在父组件的更新的深度更新,会递归地把子组件也更新了,所以就没有必要再次执行子组件的更新任务了。
<script src="../../dist/vue.global.js"></script>
<script type="text/x-template" id="grid-template">
<div>
<button @click="add">add {{ count }}</button>
<p>Children props count {{ count }}</p>
<p>childrenCount {{ childrenCount }}</p>
</div>
</script>
<script>
const DemoGrid = {
template: '#grid-template',
props: {
count: Number
},
setup(props, ctx) {
const childrenCount = Vue.ref(0)
const add = () => {
ctx.emit('add')
childrenCount.value++
}
return {
add,
childrenCount
}
}
}
</script>
<div id="app">
<div>Father {{ count }}</div>
<demo-grid
:count="count"
@add="onAdd">
</demo-grid>
</div>
<script>
Vue.createApp({
components: {
DemoGrid
},
setup () {
const count = Vue.ref(0)
function onAdd() {
count.value = count.value + 1
}
return {
count,
onAdd
}
}
}).mount('#app')
</script>
如上面的例子,点击子组件的 add 按钮后,会更新自己的状态,同时向父组件 emit 了一个事件(add 事件),然后父组件会更新自己的状态,同时改变了子组件的 props 。
nextTick
理解 Vue3 的调度系统会有助于对 nextTick 的理解。通过查询 Vue 的官方文档,可以了解 nextTick 的用法,nextTick 是等待下一次 DOM 更新刷新的工具方法。
nextTick 的源码只有两行代码(当时看到这里的时候,内心是有点惊讶的,好家伙,怎么只有两行!)。
const resolvedPromise = /*#__PURE__*/ Promise.resolve() as Promise<any>
let currentFlushPromise: Promise<void> | null = null
export function nextTick<T = void>(
this: T,
fn?: (this: T) => void
): Promise<void> {
const p = currentFlushPromise || resolvedPromise
return fn ? p.then(this ? fn.bind(this) : fn) : p
}
nextTick 的原理也是利用了 JS 的执行机制,将 nextTick 的回调放入到微任务中,从而 nextTick 中的回调会在下一轮事件循环中执行,因此 nextTick 中的回调可以拿到更新完成后的 DOM 。
从源码中可以看出,使用 nextTick 的时候还要传递 1 个 this 参数,为啥最终使用的时候只要传回调就可以了?其实是 Vue 最后使用了 bind 将组件实例传给了 nextTick 的 this。
// packages/runtime-core/src/componentPublicInstance.ts
export const publicPropertiesMap: PublicPropertiesMap =
/*#__PURE__*/ extend(Object.create(null), {
$: i => i,
$el: i => i.vnode.el,
$data: i => i.data,
// 省略其他
$forceUpdate: i => i.f || (i.f = () => queueJob(i.update)),
// 使用 bind 将组件实例传给 nextTick
$nextTick: i => i.n || (i.n = nextTick.bind(i.proxy!)),
$watch: i => (__FEATURE_OPTIONS_API__ ? instanceWatch.bind(i) : NOOP)
} as PublicPropertiesMap)
使用 bind 将函数的多个参数合并成 1 个参数的处理方式有个专业的名字,叫 函数柯里化 😎 ,我们在平时的开发中,也可以使用函数柯里化的技术实现:
-
参数复用
-
提前返回
-
延迟计算/运行
在 Vue3 的 nextTick 的实现中,就是借助了函数柯里化的参数复用和延迟计算/运行的作用。
总结
Vue3 的调度系统中有三种队列,分别为 Pre 队列、queue 队列、Post 队列。Pre 队列用于管理组件 DOM 更新前的任务,queue 队列用于管理组件 DOM 更新的任务,Post 队列则用于管理 DOM 更新后的任务。Pre 队列和 queue 队列共用同一个队列,通过 pre 属性来区分。Pre 队列中的任务没有优先级的区分,采用先进先出的策略执行。 queue 队列、Post 队列都有优先级机制,而且可以插队,任务中的唯一标识 id 也代表了任务本身的优先级,id 越小优先级越高,这样其实是为了保证父组件的任务比子组件先执行。
Vue 中的 watch 、组件自更新、生命周期等 API 的实现都依赖它的调度系统。
Vue3 调度系统的本质是利用了微任务和队列的数据结构实现的。将任务放到队列中,然后通过给任务添加唯一的 id 标识做优先级的划分,保证队列中的任务以正确的顺序执行,然后借助数组的 includes 、Set 数据结构去重,避免任务的重复执行,保证 Vue 框架的性能。
nextTick 的本质也利用了微任务的异步执行机制,通过 Promise.then 回调将 nextTick 的回调放到下一轮事件循环中执行,从而可以拿到已经更新后的 DOM 。同时也借助了 bind 方法(函数柯里化),提前将组件实例绑定到 nextTick 上,简化了 nextTick 的参数,用户不需要手动将组件实例传到 nextTick 中就可使用。
参考
原文链接:https://juejin.cn/post/7326268986797293605 作者:云浪