

一、背景
前端 monorepo 在试行大仓研发流程过程中,已经包含了多个业务域的应用、共享组件库、工具函数等多种静态资源,在实现包括代码共享、依赖管理的便捷性以及更好的团队协作的时候,也面临大仓代码文件权限的问题。如何让不同业务域的研发能够顺畅的在大仓模式下开发,离不开有效的权限管理方法。好的权限管理方法能够确保研发同学轻松找到和理解项目的不同部分,而不受混乱或不必要的复杂性的影响,并且也应该允许研发同学合作并同时工作,同时也要确保代码合并的更改经过代码审查,以维护代码的质量和稳定性。本文通过实践过程中遇到的一些问题以及逐步沉淀下来的最佳实践,来阐述下前端大仓 monorepo 在权限这块是如何思考以及设计的。
二、前期调研
在做大仓权限设计的时候,前期做了很多的调研,也参考了国内和国外的一些技术文章,总结起来主要是基于以下三点的设计思路去实现:
- 文件系统的自研,能够做到文件读写权限的完全控制:对于文件系统的自研,国外的最佳实践不外乎是 Google 和 Meta,他们都是大仓实践的典范。对于文件系统的权限控制,有一套自研的文件系统,能够对核心代码和配置文件做到读写权限控制。在 Google 发表的一篇论文《Why Google stores billions of lines of code in a single repository》中也有提到:
Since Google’s source code is one of the company’s most important assets, security features are a key consideration in Piper’s design. Piper supports file-level access control lists. Most of the repository is visible to all Piper users;d however, important configuration files or files including businesscritical algorithms can be more tightly controlled. In addition, read and write access to files in Piper is logged. If sensitive data is accidentally committed to Piper, the file in question can be purged. The read logs allow administrators to determine if anyone accessed the problematic file before it was removed.
大致的意思是 Google 内部自研了 Piper,能够支持基于文件级别的访问控制列表,大多数仓库对所有 Piper 用户可见,但是重要的配置文件或包含业务关键算法的文件可以进行更严格的控制,并且对 Piper 中的文件的读写访问都会被记录。
- 基于 Git 提供的钩子函数,能做到文件写权限的控制:Git 本身是一个分布式文件系统,其提供了代码研发流程中的各种钩子函数,在不同的钩子函数里面对文件的修改做校验,可以做到代码文件写权限的控制,但是做不到代码文件的读权限控制;
- 基于 Gitlab 的能力,对文件目录权限做控制:Gitlab 开始引入了“Protected Environments”的概念,即允许为具体的文件或目录设置权限,并指定哪些用户或用户组拥有文件的“Maintainer”权限,以便管理文件的更改和合并请求,可以用于更细粒度的文件级别权限控制。当然此种方法也只能做到代码文件写权限的控制,做不到代码文件的读权限控制。
从上面的三种调研实现来看,如果要完全做到文件系统的读写权限控制,势必需要自研一套适合研发流程及业务体系的文件系统,这种实现成本会很大,且基于实际的应用场景去考虑,也不是很有必要。所以本文主要围绕基于 Git 提供的钩子函数和基于 Gitlab 的能力来阐述过程中是如何实践的。
三、设计实现
在前端 monorepo 实践过程中,对于权限模块的设计如果考虑不好的话,会带来很不好的研发体验,同时权限的实现不仅仅是代码逻辑层面,需要考虑很多方面。在实践过程中,具体考虑了分支模型的定义、角色权限的分配、文件目录权限以及研发流程的权限控制四个方面。
分支模型的定义
分支模型的定义即不同业务域在大仓下文件目录的定义,清晰的目录结构和文件命名规范是非常重要的,研发可以很快速的检索到所需的文件。前端大仓的分支模型定义如下:
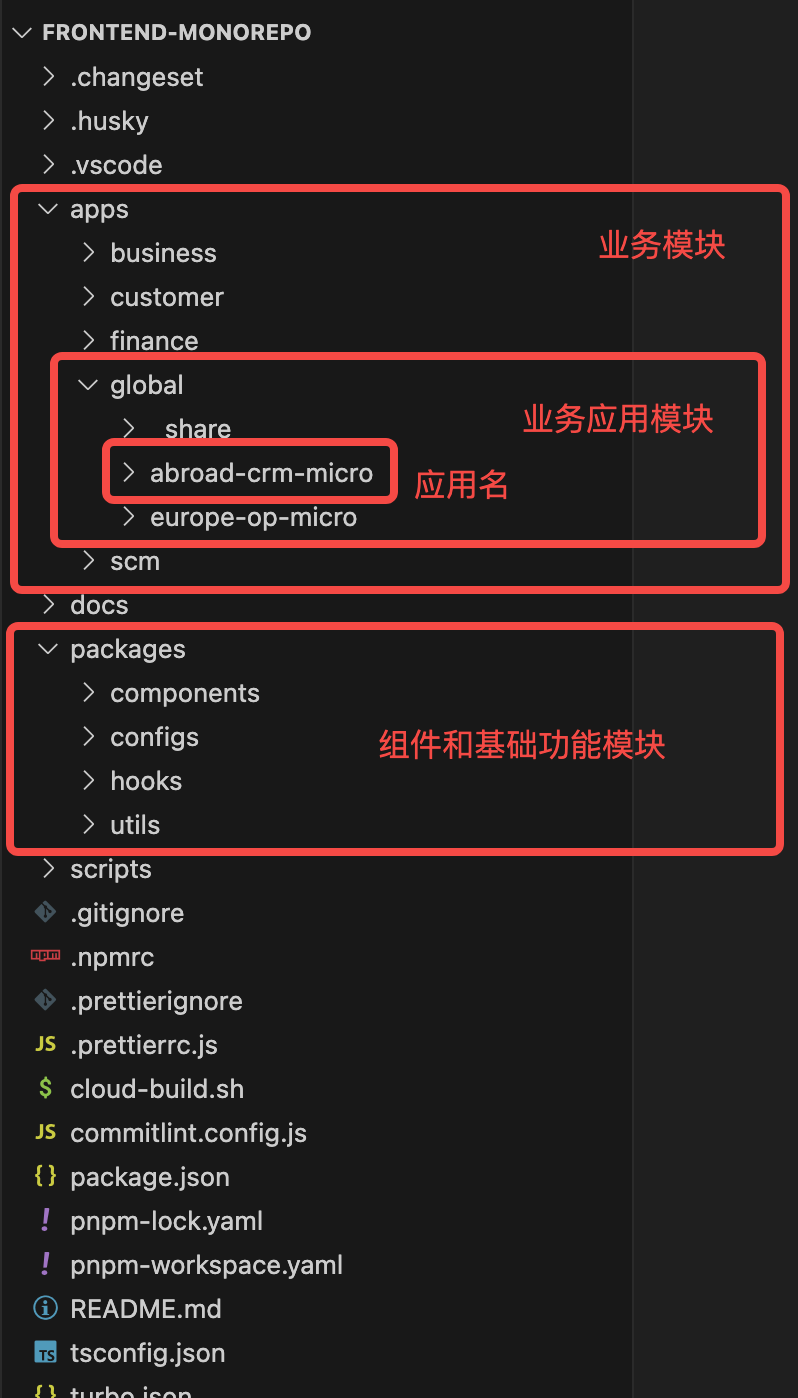

-
Apps:各业务域的目录结
-
_Share:业务域下通用依赖目录
-
Abroad-Crm-Micro:具体应用名
-
…:后续新增的应用都在业务域目录下
-
Components:业务域下通用组件目录(初始化固定目录)
-
…:可以自定义扩展目录
-
Global:国际业务域应用目录
-
…:后续新增的业务域目录都在 App 目录下
-
Packages:前端平台通用组件、工具函数、配置文件、Hooks 依赖
-
Components:平台通用组件目录(初始化固定目录)
-
Hooks:平台通用 Hooks 目录(初始化固定目录)
-
…:可以自定义扩展目录
通过使用语义化的文件和目录命名,减少了混淆和错误,使得分支模型的定义更加的清晰,研发成员也可以很清楚的知道自己所关注的业务应用在哪个目录下,同时如果需要看其他业务域的代码,也很容易检索到。
上面只是大仓 B 端应用的分支模型定义,目前融合了 C 端 H5 应用以及 Node 服务应用之后,大仓目录的划分会相对比较复杂的多,这里不再具体赘述。
角色权限的分配
在大仓模式下,角色权限没有另辟蹊径,还是沿用 Gitlab 已有的权限配置:Owner、Maintainer 和 Developer。
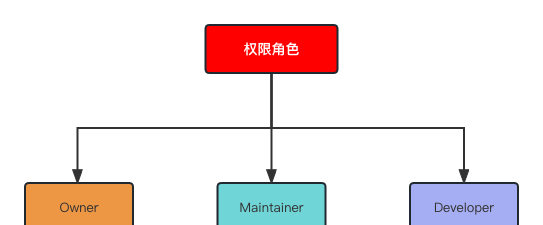
- Owner:即代码仓库的所有者,所有者是拥有最高权限的角色,可以对项目进行完全控制。他们可以添加和删除项目成员,修改项目设置,包括访问级别、分支保护规则和集成设置等。只有项目的所有者才能转让或删除项目;权限配置角色为 TL。
- Maintainer:即代码仓库的维护者,可以管理项目的代码、问题、合并请求等。可以创建和管理分支,添加和删除文件,创建和关闭问题,合并和推送分支等。维护者不能更改项目的访问级别或添加新的维护者;权限配置角色为 TL/PM。
- Developer:即代码仓库的开发者,是项目的一般成员,具有对代码进行修改和提交的权限。他们可以创建和分配问题、合并请求,查看代码、提交变更以及推送和拉取分支等。权限配置角色为研发人员。
这里需要考虑的是只要开发者具备 Developer 权限,那么他就可以修改大仓任何目录下的代码,并且本地可以提交,这样会导致本地源码依赖出现很大的风险:会出现本地代码构建和生产环境构建不一致的情况,在研发流程意识不强的情况下很容易引发线上问题。 本着对代码共享的原则,对于代码文件读权限不做控制,也允许研发修改代码,但是对修改的代码的发布会做流程上的强管控。这里就会涉及到 Gitlab 的分支保护机制以及文件 Owner 权限配置。
文件目录权限配置
在 GitLab 未支持文件目录权限设置之前,对于文件目录权限的控制主要依赖 Git 的钩子函数,在代码提交的时候,对暂存区的变更文件进行识别并做文件权限校验,流程设计也不怎么复杂,只需要额外再开发文件目录和研发的权限映射配置平台即可。在 GitLab 开始支持文件目录权限设置,可以用于更细粒度的文件级别的权限控制,内部就支持文件目录和研发的权限映射关系,其配置页面如下:

当有对应的文件或者目录路径下的文件变更的时候,在 CodeReview 过程中必须由对应的 Owner 成员确认无误之后,才可以 MR 代码。 比如:
- .husky/ 表示 .husky 目录下的文件变更,必须由具体的文件 Owner评审通过才可以 MR;
- Apps/XXX/crm/ 表示 Apps/XXX/crm 目录下的文件变更,必须由对应的文件 Owner 其中之一审批通过才可以 MR。
通过 GitLab 提供的文件目录权限配置,即使研发可以修改任意目录下的文件代码,但是最终在 CodeReview 的流程中,需要对应的文件 Owner 进行确认评审,这样就避免了研发在不注意的情况下,提交了原本不该变更的文件的代码,同时也避免了线上问题的发生。
研发流程的权限控制
前面提到的分支模型的定义、角色权限的分配以及文件目录权限的配置都是需要约定俗成的,但是在真实的研发过程中,需要考虑的场景会复杂的多。比如研发可以绕开 MR 的流程,直接本地合并代码到发布分支。对于这类场景,对大仓下的分支做了规范约束以及 MR&CodeReview 流程中的强管控。
保护分支
在大仓研发模式下,主要有四类分支,其命名规范如下:
- Dev 分支命名规范:feature-[应用标识]-版本号-自定义
- 测试分支命名规范:test-[应用标识]-版本号
- 发布分支命名规范:release-[应用标识]-版本号
- 热修复分支命名规范:hotfix-[应用标识]-版本号
其中 Feature 分支为开发分支,由 Developer 创建和维护;Release 和 Hotfix 分支为保护分支,Developer 和 Maintainer 都可以创建,但是 Developer 角色没有权限直接将 Feature 分支合入 Release 或者 Hotfix 分支,只能由 Maintainer 角色来维护。基于目前不同业务域会经常创建 test 分支用于不同测试环境的部署,这里 test 分支并未设置为保护分支。当然 Matser 分支也是保护分支,只有 Owner 角色才有权限直接将分支代码合并到主干分支。
通过对不同类型的分支的定义,基于 GitLab 提供的保护分支能力,避免了研发本地合并代码的情况,使得 Feature 分支的代码必须走研发流程的 MR&CodeReview 流程,才能最终合入代码。
钩子函数
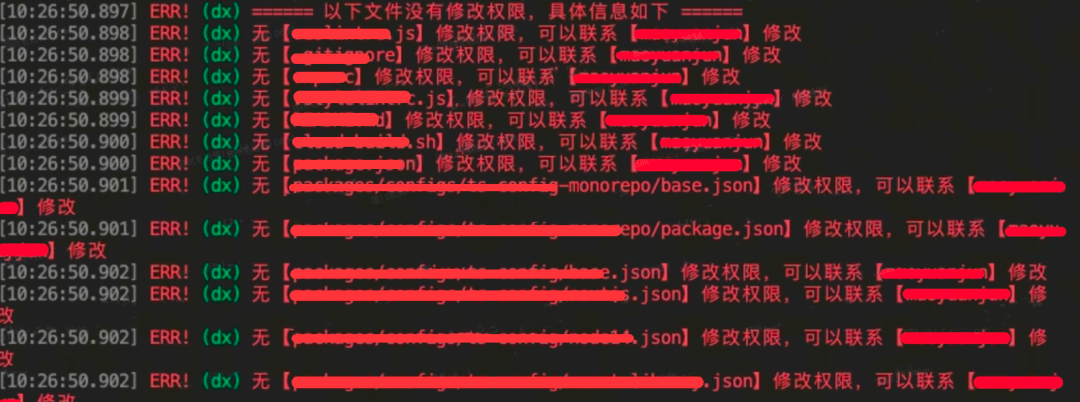
通过保护分支的约束,避免了本地直接合发布分支带来的风险,但是在本地代码提交的过程中,如果不做权限的校验,就会在 CodeReview 流程中出现文件 Owner 权限不足的情况,为了在代码提交阶段就能识别到非变更文件的提交,这里基于 Git 的钩子函数,做了权限校验,其流程如下:

通过 Git Hooks 提供的 Pre-Commit 和 Pre-Push 两个节点做权限校验,防止出错。Pre-Commit 不是必须的,如果影响代码提交的效率,可以跳过这个步骤,Pre-Push 是必须的,不允许非 Owner 做本地发布。
当然这里也会带来一个问题:当迭代的 Release 分支落后于 Master 分支,此时基于 Master 分支创建的 Feature 分支就会和 Release 分支代码不一致,导致出现很多非必要的变更文件,此时研发会很疑惑为什么会出现没有修改过的变更文件。这个问题在大仓研发模式下是无法避免的,通过分析之后,在本地提交阶段,过滤了 Apps 目录的校验,只保留了大仓顶层部分核心文件的权限校验,因为大部分的变更都在业务域下的应用里面,顶层的文件很少会去修改。
MR&CodeReview
通过保护分支的约束以及钩子函数对部分核心文件的校验,减少了很多在 MR&CodeReview 中本该遇到的问题。基于文件 Owner 权限的 MR 和 CodeReview 流程:Commit 阶段 -> Push 阶段 -> 创建 MR -> CodeReview -> 执行 MR,每个阶段的流程如下:
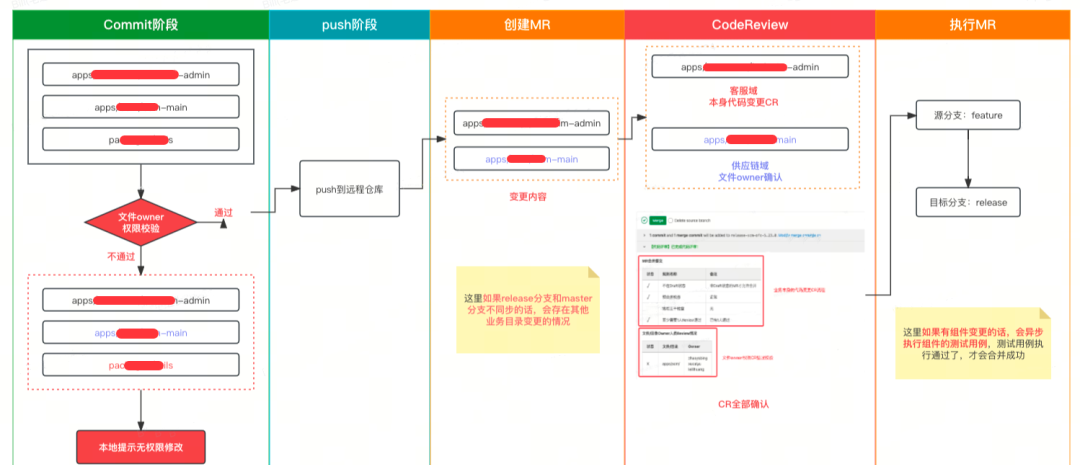
-
Commit 阶段通过对核心文件的 Owner 校验,避免核心文件被乱改的情况;
-
CodeReview 阶段通过文件 Owner 权限的校验,确保非本身业务域被修改之后被其他业务域的 Owner 知悉。
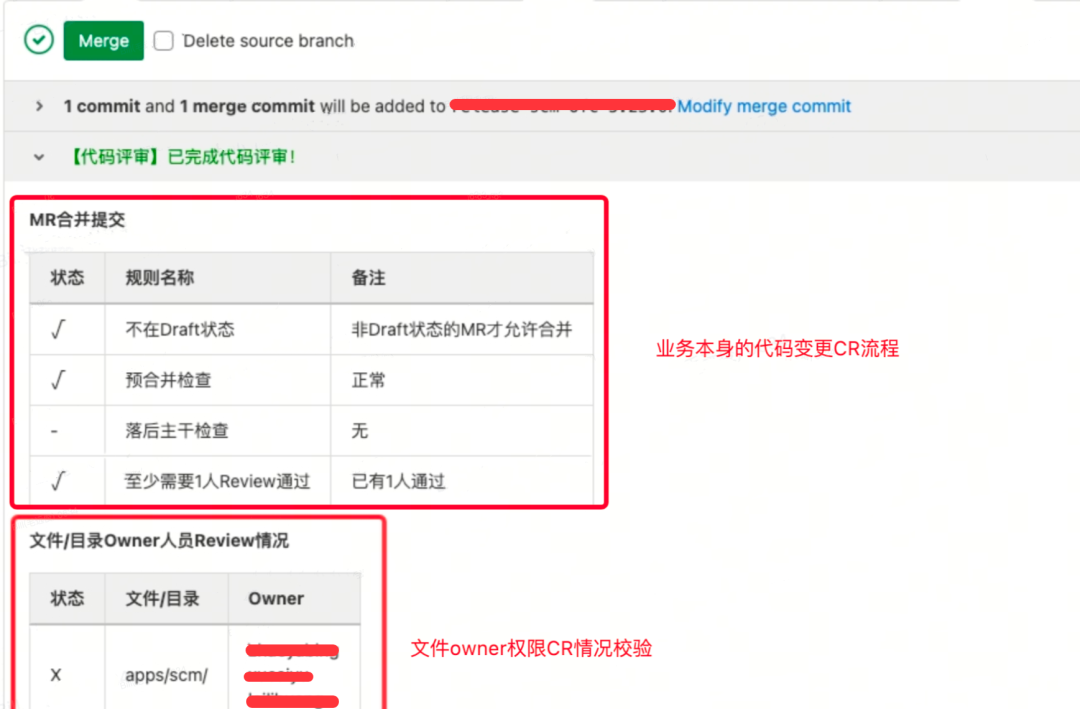
这里会带来一个问题:当 Release 分支回合 Master 代码的时候,会创建临时 MR,这个过程也会有文件 Owner 权限的校验(比如客服同学同步代码的时候,也会将商家和供应链的代码一起同步过来),就需要其他业务域的文件 Owner CR 通过才行,但 Master 的代码实际已经是 CR 过的,没有必要重复 CR,并且同步频繁的时候,会经常 CR 确认,导致回合代码的效率非常低。这里给效率技术那边提了需求,在 Release 分支回合 Master 代码的时候,不做文件 Owner 的校验。
通过上面对研发流程中的权限控制,避免了出现本地代码构建和生产环境构建不一致的情况,确保了提交代码的质量和稳定性。
四、扩展思路
通过以上的设计实现,基本上大仓下的权限设计能满足现有的研发模式了。为了弥补文件读权限控制的缺陷,过程中,也考虑了访问控制列表以及文件访问日志的实现,但是最终觉得不是很有必要,就没有在大仓里面应用起来。这里可以分享下访问控制列表以及文件访问日志实现的几种思路。
访问控制列表
访问控制列表即大仓下对文件目录的访问控制,以便更精确地控制对敏感信息或关键代码的访问。之前有提到 Google 和 Meta 都是通过自研的文件系统实现,但是如果不是自研,是不是就一定实现不了了呢,其实未必见得。
VSCode设置文件隐藏
通过在大仓目录下的 .vscode/settings.json 文件配置 files.exclude 属性可以实现文件的显隐,如下:
{
"files.exclude": {
"**/scripts": true
}
}
上面的配置表示大仓目录下的 scripts 目录是不可见的。
存在的问题: 如果懂 .vscode/settings.json 配置的研发,可以直接本地将 True 改为 False,这里配置就失效了。还有并不是所有研发都是用的 VSCode IDE,还有不少研发用其他的 IDE,每个人的研发习惯不一样,很难做到强约束。
MAC下隐藏文件
MAC 下可以通过 shell 命令设置文件的显隐,如下:
chflags hidden **/scripts
上面的 shell 命令表示隐藏大仓下的 scripts 目录。结合大仓研发模式下提供的代码按需拉取能力,可以在代码拉取的最后环节执行如上的命令,就可以隐藏对应的文件。
存在的问题:如果懂 MAC 下文件显隐的设置,可以在 shell 终端上执行 chflags nohidden **/scripts ,这样 scripts 就会变为可见了,达不到最终的效果。
对于访问权限列表的控制,实际上是可以通过一些其他的方式实现,但其实现思路基本都是治根不治本,起不了多大的作用,所以最后都没有在大仓的研发流程里面体现。
文件访问日志
文件访问日志即当研发打开文件的时候,发送一条日志到服务端并保存下来,这样可以对包含敏感信息的配置文件进行监听, 设置审计日志和监控,以便跟踪谁做了什么操作,并在出现异常情况时能够快速识别和应对问题。通过 VSCode 插件是可以实现的,VSCode 启动之后,提供了对应文件目录路径的打开事件 onDidOpenTextDocument,当研发打开任何文件的时候,都可以触发监听事件,那么我们就能在监听事件里面去做日志发送相关的逻辑,实现文件访问日志记录的功能,大致的实现如下:
export function monitorPermissionOfTargetFile(targetFilePath: string, repoRootPath: string) {
const targetFileFullPath = repoRootPath + targetFilePath;
// 打开项目目录下任意文件的回调函数
vscode.workspace.onDidOpenTextDocument(textDocument => {
// 获取被打开的文件路径
const filePath = textDocument.uri.fsPath;
if (filePath === targetFileFullPath) {
// 添加日志发送逻辑
}
});
}
存在的问题:该功能强依赖 VSCode IDE,只有在 VSCode 里面才能实现,并非所有的研发都在用 VSCode,并且实时监听文件的点击事件也会带来一定的系统开销成本。现在本来打开多个 VSCode IDE,电脑运行就比较慢了,再加上该功能,性能损耗估计会更多。
上面只是提供了大仓权限实践过程中未落地的两个扩展思路,如果还有其他更好的思路能实现文件的读权限控制,欢迎随时沟通交流。
五、总结
前端 monorepo 大仓的权限设计在实现的过程中,遇到了很多的问题,有些时候想的很好,但是实际在研发流程中会因不同的业务域场景存在不一样的问题。比如基于 Master 新建 Feature 分支还是基于 Release 新建 Feature 分支这个问题就尤其突出,起初基于 Master 新建的 Feature 分支,带来的问题是研发在合 Release 分支的时候,有很多非变更文件,导致 CR 都不清楚具体要看哪些文件;然后改成基于 Release 新建的 Feature 分支,带来的问题是会遗漏部分已发版的 Release 分支代码;最后综合考虑还是基于 Master 新建的 Feature 分支。大仓的权限设计也离不开参与研发流程改造的小伙伴以及效能技术的小伙伴,过程中为了适配大仓的权限,做了很多研发流程的改造以及 GitLab 能力的扩展,希望本文能给读者带来一定的帮助。

原文链接:https://juejin.cn/post/7326814224331554816 作者:聪明的竹子爱学习