
在Vue中,从模板到页面更新的流程大概是这样的:模板编译器将用户提供的一个模板字符串(或dom节点id)解析生成抽象语法树,再经由优化器优化,标记所有的静态节点后,交由代码生成器生成渲染代码,再通过渲染函数构建器将渲染代码构建成一个渲染函数,调用这个渲染函数,我们就可以得到目标模板的虚拟dom,经过patching算法的对比后,得到最少更改的虚拟dom,再根据这个虚拟dom实现页面的更新。
万丈高楼平地起,模板编译器便是上述整个渲染过程的第一块砖头,可见其重要性(当然,你也可以直接使用现成的渲染函数,这样就可以跳过模板编译过程了,但我们绝大多数情况都是直接使用模板进行开发的)。
那么,我们现在来看一下,模板编译器是怎么实现的吧。
注:本文只是介绍模板编译器的原理与基本实现,有一些跟模板编译器关联性不是很大的代码可能会被省略,如果想要详细的了解这些未说明部分的原理和逻辑,可以看本人github最新分支(PS:不要看master分支,那个是第一版的代码,只实现了数据响应化等基本逻辑。),截止至本文发布,github已经更新值dev-0.0.1分支。附上github传送门:kinerVue/dev-0.0.1
parseHTML的原理
既然是解析模板字符串,也就是解析一段html的字符串,那么本质上其实就是对字符串的解析处理。在Vue中,对模板字符串的处理原理其实很简单:
就是我每匹配到一个满足要求的字符串
所谓的满足要求即:
- 是否是开始标签,如:<div …> ;
- 是否是结束标签,如:</div> ;
- 是否是一段文本,如:<div>这是一段代码</div>中的文字;
- 是否是一个注释,如:<!–这是一个注释–>
如果满足以上任何一种情况,他便会触发对应的钩子函数,通知调用paserHTML的地方去收集这些信息,然后根据这些信息生成抽象语法树。
大概的示例代码是这样的:
let html = '<div><!--这是一个注释--><span>这是一段文本</span></div>';
function parseHTML(html, options) {
while (html) {
// 首先通过正则匹配判断标签是否是注释元素(注释包括普通注释和条件注释)
// 如果是的话,触发注释钩子函数通知收集信息,并将当前匹配的文本从html中截取掉
// options.comment(text /*注释的文本*/ , curIndex /*注释所在的开始位置*/ , endIndex /*注释所在的结束位置*/ );
// html = html.substring(endIndex);
// 其次通过正则判断是否是结束标签
// options.end(tag /*标签名*/ , curIndex /*注释所在的开始位置*/ , endIndex /*注释所在的结束位置*/ );
// html = html.substring(endIndex);
// 其次通过正则判断是否是开始标签
// options.start(tag /*标签名*/ ,[]/*属性列表*/, true/*是否是自闭标签*/, curIndex /*注释所在的开始位置*/ , endIndex /*注释所在的结束位置*/ );
// html = html.substring(endIndex);
// 最后判断是否是文本
// options.char(text /*文本*/ , curIndex /*文本所在的开始位置*/ , endIndex /*文本所在的结束位置*/ );
// html = html.substring(endIndex);
}
}
parseHTML(html, {
start(tag, attrs, isUnary, startIndex, endIndex) {
// 收集整理信息
},
end(tag, startIndex, endIndex) {
// 收集整理信息
},
chars(text, startIndex, endIndex) {
// 收集整理信息
},
comment(text, startIndex, endIndex) {
// 收集整理信息
},
});
从上面的代码可以看到,我们将模板字符串是否存在作为while的终止条件,我们每匹配到 一种情况,就会将相应的文本从html中删除掉,这样不断循环下去,就会不断的触发响应的钩子函数收集数据,直至html变成空字符串退出循环,此时,我们已经将整个文本都解析完了。
那么,我们再来看看我们再钩子函数里都要做什么操作呢?
钩子函数start
- 根据传过来的标签名创建抽象语法树元素节点
- 检查一些非法属性或标签,并对一些特殊情况做预处理
- 解析attrs
- 解析指令v-if,v-for,v-once等
- 如果不是自闭标签的话,将当前元素加入到栈中,用于维护元素间的父子关系
钩子函数end
- 将栈顶元素弹出(因为当前标签已经结束后了,栈顶存的就是当前标签)
- 重新更正父级标签(因为当前标签已经结束,说明他的子节点也都解析完了,父标签不在是当前标签了,父级标签有重新变回当前标签的父级标签)
- 关闭标签,此时对if条件分支进行一些补充以及进行一些收尾工作等
钩子函数chars
- 创建抽象语法树文本节点
- 将这个文本节点加入到父节点的children中
钩子函数comment
- 创建抽象语法树注释节点
- 只要注释节点存在父级,就把注释节点加入到父级节点的children中
当执行完整个逻辑,我们就会得到一个抽象语法树的根节点,通过这个根节点可以找到他下面的所有子节点及其相应的属性、文本等。
以下为parseHTML涉及到的主要逻辑代码,如果想要看全部代码,可以观看本人github:kinerVue/dev-0.0.1
// compiler/parse.js 定义了用于真正解析html模板和解析文本(包括静态文本和带参数的动态文本)的方法
import {
cached,
canBeLeftOpenTag,
decodingMap,
isNonPhrasingTag,
isPlainTextElement,
isUnaryTag, makeMap,
noop
} from "../shared/utils.js";
import {
attribute,
comment,
conditionalComment, defaultTagRE,
doctype,
dynamicArgAttribute, encodedAttr, encodedAttrWithNewLines,
endTag, regexEscapeRE,
startTagClose,
startTagOpen
} from "../shared/RE.js";
import SimpleStack from "../shared/SimpleStack.js";
import {parseFilter} from "./filter-paser.js";
// #5992 忽略pre和textarea标签的第一个换行符
const isIgnoreNewlineTag = makeMap('pre,textarea', true);
const shouldIgnoreFirstNewline = (tag, html) => tag && isIgnoreNewlineTag(tag) && html[0] === '\n';
/**
* 解析html模板,并通过不断触发钩子函数通知调用者手机相关信息创建抽象语法树
* @param html
* @param options
*/
export const parseHTML = (html, options) => {
let {
start: startHook = noop,
end: endHook = noop,
chars: charsHook = noop,
comment: commentHook = noop,
shouldKeepComment = true,// 是否需要保留注释
shouldDecodeNewlinesForHref = false,// 是否应该对a标签的href进行一次编码
shouldDecodeNewlines = false// 是否应该对属性值进行一次编码
} = options;
let lastTag, last;
let endChars;// 截止字符串
let index = 0;// 当前指针所在的位置
const stack = new SimpleStack();// 用于存储标签信息的栈,通过将标签信息存储再栈中方便标签的匹配处理和父级标签的寻找
while (html) {
last = html;
if (!lastTag || !isPlainTextElement(lastTag)) {
// 父元素为正常元素
let textEnd = html.indexOf('<');
if (textEnd === 0) {
// 首先判断标签是否是注释元素
if (comment.test(html)) {
// 找出第一个注释结束标签的索引
endChars = '-->';
const commentEnd = html.indexOf(endChars);
if (commentEnd >= 0) {
// 看一下配置是否需要保留注释,如果不需要保留注释,则不触发钩子函数,否则触发
if (shouldKeepComment) {
// 触发钩子函数
// 参数有三个:
// 1、注释文本
// 2、指针开始位置,即上一个节点的结束位置
// 3、指针结束位置,即注释节点的结束位置
// 截取注释文本 <!-- 注释文本 -->
commentHook(html.substring(4, commentEnd), index, index + commentEnd + endChars.length);
// 指针向前,指向注释标签的后面一个节点
advance(commentEnd + endChars.length);
// 本次处理完毕,继续下一次的字符串切割处理
continue;
}
}
}
// 如果不是普通注释,再看看是不是条件注释
if (conditionalComment.test(html)) {
endChars = ']>';
// 找到条件注释的截止位置
const commentEnd = html.indexOf(endChars);
if (commentEnd >= 0) {
// 条件注释无需触发commentHook钩子函数,直接跳过即可
advance(commentEnd + endChars.length);
// 本次处理完毕,继续下一次的字符串切割处理
continue;
}
}
// 如果是文档类型标签,如:<!DOCTYPE html>
const docTypeMatch = html.match(doctype);
if (docTypeMatch) {
// 如果是文档类型标签,也直接跳过
advance(docTypeMatch[0].length);
// 本次处理完毕,继续下一次的字符串切割处理
continue;
}
// 如果是结束标签,如</div>
const endTagMatch = html.match(endTag);
if (endTagMatch) {
// 记录结束标签开始位置
const curIndex = index;
// 游标移动到结束标签终止位置
advance(endTagMatch[0].length);
// 处理结束标签
parseEndTag(endTagMatch[1], curIndex, index);
// 本次处理完毕,继续下一次的字符串切割处理
continue;
}
// 解析开始标签,如<div>
const startTagMatch = parseStartTag();
if (startTagMatch) {
// 处理开始标签
handleStartTag(startTagMatch);
if (shouldIgnoreFirstNewline(startTagMatch.tag, html)) {
// 如果在pre和textarea内第一个字符是换行符的话,需要忽略这个换行符,否则在解析文本的时候会出问题
advance(1);
}
// 本次处理完毕,继续下一次的字符串切割处理
continue;
}
}
// 解析文本
// 若textEnd>0,说明html字符串不是以标签开头,而是以文本开头
// e.g.
// 这是一段文本<</div>
let text, rest, next;
if (textEnd > 0) {
// 将以<开头的字符串取出来,看一下这个字符串是不是开始标签、结束标签、注释、条件注释,
// 如果都不是,就把他当做是普通文本,然后继续往下找下一个<,知道匹配到开始标签、结束标签、注释、条件注释位置
rest = html.slice(textEnd);
while (
!endTag.test(rest) && // 是不是终止标签
!startTagOpen.test(rest) && // 是不是开始标签
!comment.test(rest) && // 是不是注释标签
!conditionalComment.test(rest) // 是不是条件注释
) {
// 能进入这里,说明rest里面的那个<不是开始标签、结束标签、注释、条件注释中的一种,那我们就把他当做是普通的文本
// 然后继续找下一个<
next = rest.indexOf('<',1);
// 如果找不到下一个<了,说明剩余的这个html就是以一段文字作为结尾的,如:这是一段文本<- _ ->
// 那么我们就不需要再往下寻找了,直接退出循环即可
if(next<0) break;
// <的位置变了,所以要更新一下textEnd,不然textEnd还是指向上一个<
textEnd += next;
// 以新的<作为起始再次截取字符串,进入下一个循环,看看这一次的<是不是开始标签、结束标签、注释、条件注释中的一种
rest = html.slice(textEnd);
}
// 当循环结束之后,textEnd就已经指向了文本节点的最后的位置了
text = html.substring(0, textEnd);
}
// 如果textEnd<0,那么说明我们的html中根本就没有开始标签、结束标签、注释、条件注释,他就是一个纯文本
if(textEnd<0){
text = html;
}
// 我们已经将当前的文本获取到了,如果有文本的话,那么我们就将游标移动到文本末尾,准备进行下一轮的查找
if(text){
advance(text.length);
// 文本节点已经获取到了,触发文本节点钩子
charsHook(text, index - text.length, index);
}
} else {
// 父级元素是script、style、textarea
// TODO 特殊标签逻辑暂不处理
}
}
/**
* 辅助函数,用于让切割文本的指针按照所传的步数不断向前,并在向前的同时不断的切割文本从而清理掉已经处理过或不需要处理的文本,
* 让指针始终指向待处理的文本
* @param step 要向前移动几步
*/
function advance(step) {
index += step;
html = html.substring(step);
}
/**
* 用于解析开始标签及其属性等
* @returns {{tag: *, attrs: Array, startIndex: number}}
*/
function parseStartTag() {
// 解析开始标签
const start = html.match(startTagOpen);
if (start) {
let match = {
tag: start[1],
attrs: [],
startIndex: index
};
// 找到开始标签的标签名了,往后走再看看他都有哪些舒缓型
advance(start[0].length);
let tagEnd,// 开始标签是否遇到结束符>,如果遇到了结束符,说明开始标签已经解析完毕了
attr;// 暂存当前的属性描述字符串,可能是常规的html标签属性,也可能是vue自带的动态属性,如:@click="a"、v-html="b"、:title="title"等
// 循环只有当遇到了结束符或者是已经再也解析不出属性来的时候才会结束
while (!(tagEnd = html.match(startTagClose)) && (attr = (html.match(attribute) || html.match(dynamicArgAttribute)))) {
// 记录每一个属性的开始位置
attr.start = index;
// 指针右移到属性末尾的位置
advance(attr[0].length);
// 记录属性的结束位置
attr.end = index;
// 将找到的属性添加到match中的属性列表中
match.attrs.push(attr);
}
// 当到达结束位置时,看一下这个标签是不是自闭标签,如果是的话,储存他的自闭分隔符/,方便只有用来判断该标签是否自闭
if (tagEnd) {
// 存储自闭符号
match.unarySlash = tagEnd[1];
// 指针右移至开始标签最后
advance(tagEnd[0].length);
// 记录下开始标签的结束位置
match.endIndex = index;
}
// 开始标签解析完成,返回匹配结果
return match;
}
}
/**
* 处理开始标签的属性等
* @param match
*/
function handleStartTag(match) {
const {tag, unarySlash, attrs, startIndex, endIndex} = match;
// 如果当前标签的上一个标签是一个p标签,并且当前正在解析的标签不是一个段落元素标签,那么我们就直接调用parseEndTag将p标签结束掉
// 因为在HTML标准中,p标签只能嵌套段落元素,其他元素如果嵌套在p标签中会被自动解析到p标签外面
// e.g.
// <p><span>这是内联元素</span><div>这是块级元素</div></p>
// 在浏览器中会被解析成:
// <p><span>这是内联元素</span></p><div>这是块级元素</div><p></p>
// html5标签相关文档链接:https://html.spec.whatwg.org/multipage/indices.html#elements-3
// 段落标签相关文档链接:https://html.spec.whatwg.org/multipage/dom.html#phrasing-content
if (lastTag === "p" && isNonPhrasingTag(tag)) {
parseEndTag(lastTag);
}
// 如果标签的上一个标签跟当前解析的标签名相同并且当前标签属于"可省略闭合标签",那么,直接调用parseEndTag把上一个标签结束掉
// e.g.
// <ul>
// <li> 选项1
// <li> 选项2
// <li> 选项3
// <li> 选项4
// </ul>
// ???如果加上这个判断的话,回到值触发两次end回调,因为在浏览器中出现上述情况时,我们再获取outerHTML的时候浏览器已经把元素转换为:
//
// <ul>
// <li> a
// </li><li> b
// </li><li> c
// </li><li> d
// </li></ul>
if (canBeLeftOpenTag(tag) && tag === lastTag) {
parseEndTag(lastTag);
}
// 当前解析的标签是否为自闭标签
// 自闭标签分为两种情况,一种是html内置的自闭标签,一种是用户自定义标签或组件时自闭的
const unaryTag = isUnaryTag(tag) || !!unarySlash;
// 由于在不同的浏览器中,对标签属性的处理有所区别,如在IE浏览器中,会将所有的属性值进行一次编码,如:
// <div name="\n"/> => <div name=" "/>
// 再如在chrome浏览器中,会对a标签的href属性进行一次编码
// <a href="\n"/> => <a href=" "/>
// 因此,我们需要对属性值做一下处理,对这些属性进行解码
let len = attrs.length;
let newAttrs = new Array(len);
for (let i = 0; i < len; i++) {
let attrMatch = attrs[i];
const value = attrMatch[3] || // 匹配属性格式:name="kiner"
attrMatch[4] || // 匹配属性格式:name='kiner'
attrMatch[5] || // 匹配属性格式:name=kiner
"";
// 若解析的标签是a标签且当前属性名是href,则根据当前浏览器环境看是否需要对\n换行符进行解码(有些浏览器会对属性值进行编码处理)
const theShouldDecodeNewlines = tag === 'a' && attrMatch[1] === 'href'
? shouldDecodeNewlinesForHref
: shouldDecodeNewlines;
// 将处理过的属性放到newAttrs中
newAttrs[i] = {
name: attrMatch[1],
value: decodeAttr(value, theShouldDecodeNewlines)
}
}
// 判断当前标签是否为自闭标签,若不是自闭标签,则需要将解析出来的当前标签的信息压入栈中,方便后续用来匹配标签以及查找父级使用
if (!unaryTag) {
stack.push({
tag: tag,
lowerCaseTag: tag.toLowerCase(),
attrs: newAttrs,
startIndex: match.startIndex,
endIndex: match.endIndex
});
// 将当前标签名赋值给lastTag,方便后续的对比操作
lastTag = tag;
}
// 开始标签的信息已经解析完毕,通知钩子函数
startHook(tag, newAttrs, unaryTag, startIndex, endIndex);
}
/**
* 对一些已经被编码的属性值进行解码
* @param val
* @param shouldDecodeNewlines
* @returns {string | * | void}
*/
function decodeAttr(val, shouldDecodeNewlines) {
const reg = shouldDecodeNewlines ? encodedAttrWithNewLines : encodedAttr;
return val.replace(reg, match => decodingMap[match]);
}
function parseEndTag(tag, startIndex = index, endIndex = index) {
let pos,// 用于查找当前结束标签对应开始标签的游标变量
lowerCaseTagName;// 当前结束标签的小写标签名
if (tag) {
lowerCaseTagName = tag.toLowerCase();
// 通过结束标签名在标签栈中从上往下查找最近的一个匹配标签,并返回标签的游标索引
pos = stack.findIndex(tag => tag.lowerCaseTag === lowerCaseTagName);
} else {
pos = 0;
}
if (pos >= 0) {
let popElems = stack.popItemByStartIndex(pos);
popElems.forEach(elem=>{
//找到了开始标签了说明这个结束标签是有效的,触发endHook
endHook(elem.tag, startIndex, endIndex);
});
let top = stack.top();
(top&&(lastTag = top.tag));
} else if (lowerCaseTagName === "br") {
// br是一个自闭的标签,有三种写法:<br/> 或 <br> 或 </br>
// 这里就是匹配第三中写法的,虽然这种写法很少见,而且不太推荐使用,
// 但在html中这么使用确实是不会报错,所以还是要兼容一下
// 因为br是自闭标签,也没没有什么其他情况需要处理的,我们指直接触发他的startHook就可以了
startHook(tag, [], true, startIndex, endIndex);
} else if (lowerCaseTagName === "p") {
// 由于通过pos没能在标签栈中找到与当前p标签匹配的开始标签,因此,这个标签应该是一个 </p> 的一个单独的标签
// 因为在html解析的时候,遇到这样一个单独的闭合p标签,会自动解析为<p></p>,因此,此时既要触发startHook也要出发endHook
startHook(tag, [], false, startIndex, endIndex);
endHook(tag, startIndex, endIndex);
}
}
};
// compiler/compile-tpl-to-ast.js 本文件用于将一个html模板生成一个抽象语法树
import {parseHTML, parseText} from "./parse.js";
import SimpleStack from "../shared/SimpleStack.js";
import {cached, isForbiddenTag, isIE, isPreTag, isTextTag, warn} from "../shared/utils.js";
import {createASTComment, createASTElement, createASTExpression, createASTText} from "./Ast.js";
import {invalidAttributeRE, lineBreakRE, whitespaceRE} from "../shared/RE.js";
import {
addIfCondition,
preTransformNode, processElement,
processFor,
processIf, processIfConditions,
processOnce,
processPre,
processRawAttrs
} from "./helper.js";
import {AST_ITEM_TYPE} from "../shared/constants.js";
// 第三方html编码解码库
import he from "../shared/he.js";
// 将解码方法加入到缓存中
const decodeHTMLCached = cached(he.decode);
/**
* 根据模板与选项转换成抽象语法树
* @param tpl
* @param options
* @returns {{type: string, tag: *, attrList: *, parent: Window, children: Array}|*}
*/
export const parse = (tpl, options) => {
tpl = tpl.trim();
console.log('待转换模板:', tpl);
return compilerHtml(tpl, options);
};
let currentParent = null;
let nodeStack = new SimpleStack();
let inVPre = false;// 是否标记了v-pre,若标记了,则编译时可以跳过内部文本的编译工作,加快编译效率
let inPre = false;// 当前标签是否为pre标签
let root;// 根节点
/**
* 编译html模板,编译完成返回抽象语法树的根节点
* @param tpl
* @param options
* @returns {*}
*/
export const compilerHtml = (tpl, options) => {
parseHTML(tpl, {
...options,
start(tag, attrs, isUnary, startIndex, endIndex) {
// 当解析到标签开始位置时会执行这个钩子函数,将标签名和对应的属性传过来
let elem = createASTElement(tag, attrs, currentParent);
// 检测非法属性并提示
attrs.forEach(attr => {
if (invalidAttributeRE.test(attr.name)) {
warn(`属性名:${attr.name}中不能包含空格、双引号、单引号、<、>、\/、= 这些字符`);
}
});
// 如果当前标签是一个<style>...</style>或<script></script>、<script type="type/javascript"></script>的话
// 提示用户这是一个在模板中被禁止使用的标签,因为模板仅仅只是用来描述状态与页面的呈现的,不应该包含样式和脚本标签
if (isForbiddenTag(elem)) {
elem.forbidden = true;
warn(`模板文件只是用来建立状态与UI之间的关系,不应该包含样式与脚本标签,当前使用的标签:${elem.tag}是被禁止的,我们不会对他进行便编译`);
}
// 处理checkbox、radio等需要预处理的标签
preTransformNode(elem);
// 如果inVPre为false,可能还没有解析当前标签是否标记了v-pre
if (!inVPre) {
// 解析一下
processPre(elem);
// 如果解析过后发现elem上标记有pre=true,说明标签确实标记了v-pre
if (elem.pre) {
// 修正inVPre
inVPre = true;
}
}
// 当然,除了vue的指令v-pre之外,我们html也自带一个pre标签,
// 如果标签名是pre,那也要将inPre标记为true
isPreTag(elem.tag) && (inPre = true);
if (inVPre) {
// 如果一个标签被标记了v-pre,那我们只需要把attrList中剩余的属性复制到elem的attrs中去即可
// 因为attrList中的其他属性都在刚刚进行预处理的时候已经处理并从attrList中删除了
processRawAttrs(elem);
} else if (!elem.processed) {
// 如果还有没有处理的结构指令,如v-for、v-if等,就处理一下
processFor(elem);
processIf(elem);
processOnce(elem);
}
// 如果不存在根节点,则当前节点就是根节点
!root && (root = elem);
// 判断当前节点是不是一个自闭标签,如果是一个自闭标签,那么直接结束当前标签解析
// 如果是不是自闭标签,我们需要记录下当前节点当做是下个节点的父级元素,并加这个元素压入栈中
if (isUnary) {
closeElement(elem);
} else {
currentParent = elem;
nodeStack.push(elem);
}
},
end(tag, startIndex, endIndex) {
// TODO 触发了两次,未解决
// console.log(`解析到终止标签:${tag}`, startIndex, endIndex);
// 当前标签已经解析结束了,将标签从栈中弹出
let elem = nodeStack.pop();
// 此时栈顶元素便是我们下一个元素的父级
currentParent = nodeStack.top();
// 关闭标签
closeElement(elem);
},
chars(text, startIndex, endIndex) {
// console.log(`解析到文本:${text}`, startIndex, endIndex);
// 如果不存在父级节点,那么我们可以得知,
// 这个解析出来的文本,要么就是在根节点之外,要么,压根就没有根节点,所给的tpl直接就是一段文本
if (!currentParent) {
// 如果解析出来的文本跟传入的模板完全相同,那么,说明直传进来一个文本内容,警告提示
if (text === tpl) {
warn(`组件模板需要一个根元素,而不仅仅是文本。`);
} else if ((text = text.trim())) { // 文本定义在了根节点的外面,警告提示
warn(`定义在根节点之外的文本:${text}将会被忽略掉`);
}
// 没有父节点的文本,压根就没有存在的意义,直接人道毁灭,不管他吧
return;
}
// 在IE浏览器中的textarea的placeholder有一个bug,浏览器会将placeholder的内容会被作为textarea的文本节点放入到textarea中
// 如果是这种情况框,直接忽略他吧,IE太难伺候了
if (isIE &&
currentParent.tag === 'textarea' &&
currentParent.attrsMap.placeholder === text
) {
return;
}
const children = currentParent.children;
// 如果当前文本在pre标签里或者是文本去掉前后空白后依然不为空
if (inPre || text.trim()) {
// 如果父级标签是纯文本标签,那么解析出来的文本就是我们要的内容
// 如果不是的话,需要进行一定的解码,这里使用的是一个第三方的html编解码库:he
// he链接为:https://www.npmjs.com/package/he
text = isTextTag(currentParent) ? text : decodeHTMLCached(text);
} else if (!children.length) {
// 如果当前文本父级元素下面没有子节点的话并且当前文本删除前后空格之后为空字符串的话,我们就清空文本
// 请注意,判断当前文本删除前后空格之后是否为空字符串是在上线的if语句中判断的,我刚开始看的时候不理解,
// 为啥父元素没有子节点就要清空文本呢,那要是他是<div>这是一段文字</div>呢?原来是因为我漏了上面的if判断里面
// 还有一个text.trim(),如果一个文本去除前后空白之后不为空的话,那他就应该进入到if的分支,而不会进入到这里。正是
// 因为他去除空白之后是空的,所以才会进入到这个判断逻辑,那么,结果就很明显了,现在正在判断的情况是:
// <div> </div>,那么我们直接把text清空就可以了。
text = '';
} else if (options.whitespaceOption) {// 根据不同的去空白选项将空白去掉
// ``` html
// <!-- source -->
// <div>
// <span>
// foo
// </span> <span>bar</span>
// </div>
//
// <!-- whitespace: 'preserve' -->
// <div> <span>
// foo
// </span> <span>bar</span> </div>
//
// <!-- whitespace: 'condense' -->
// <div><span> foo </span> <span>bar</span></div>
// ```
if (options.whitespaceOption === 'condense') {
text = lineBreakRE.test(text) ? '' : ' '
} else {
text = ' ';
}
} else {// 其他情况:看看是不是需要保留空格
text = options.preserveWhitespace ? ' ' : '';
}
if (text) {
// 如果不是在pre标签中且删除空白的选项是condense,则删除文本中的换行符
if (!inPre && options.whitespaceOption === "condense") {
text = text.replace(whitespaceRE, '');
}
let res, elem;
// 如果当前节点没有v-pre属性且是一个空白符并且可以解析出动态变量
if (!inPre && text !== ' ' && (res = parseText(text, options.delimiters))) {
elem = createASTExpression(text, res.exp, res.tokens);
} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
elem = createASTText(text);
}
// 将创建的文本节点或表达式节点加入到父级节点的children中
if (elem) {
children.push(elem);
}
}
},
comment(text, startIndex, endIndex) {
// 只有在根节点下创建注释才有效,只要不在根节点内部的注释都会被忽略
if (currentParent) {
let elem = createASTComment(text);
currentParent.children.push(elem);
}
}
});
return root;
};
let warned = false;
/**
* 辅助警告提示类,由于在生成模板过程是在循环体里面,为避免重复警告提示,定义这个只要提示一次就不再提示的警告方法
* @param message
*/
function warnOnce(message) {
if (!warned) {
warn(message);
warned = true;
}
}
/**
* 关闭标签并做一些收尾工作
* @param elem
*/
export const closeElement = elem => {
if(!elem) return;
// 若当前元素不是pre元素,则删除元素尾部的空白文本节点
trimEndingWhitespace(elem);
// 如果当前标签没有v-pre并且没有编译过,则编译一下
if (!inVPre && !elem.processed) {
processElement(elem);
}
// 当我们的元素存储栈为空并且当前元素不是根节点时
// 即模板中的元素都是自闭标签,如:
// 正确的做法(由于加上了判断,因此,同时只可能有一个元素被输出):<input v-if="value===1"/><img v-else-if="value===2"/><br v-else="value===3"/>
// 错误的做法(因为vue模板始终需要一个根元素包裹,这里已经有三个元素了):<input/><img/><br/>
// 此时根节点root=input,但当前元素是br,由于元素都是自闭标签,因此不存在父子关系,大家都是平级,
// 因此,也就不会想用于维护层级关系的nodeStack中添加元素
if (!nodeStack.size() && root !== elem) {
if (root.if && (elem.elseIf || elem.else)) {
addIfCondition(root, {
exp: elem.elseIf,
block: elem
});
} else {
warnOnce(`模板必须保证只有一个根元素,如果你想用v-if动态渲染元素,请将其他元素也用v-else-if串联成条件链`);
}
}
// 如果不是根节点且不是script或style之类被禁止的标签的话
if (currentParent && !elem.forbidden) {
// 如果当前标签绑定有v-else-if或v-else,则需要解析一下
if (elem.elseIf || elem.else) {
processIfConditions(elem, currentParent);
} else {
// 如果当前标签是一个作用域插槽
if (elem.slotScope) {
// 获取插槽名称
const name = elem.slotTarget || '"default"';
// 将它保留在子列表中,以便v-else(-if)条件可以
// 找到它作为prev节点。
(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = elem;
}
// 把当前元素加入到父级元素的子节点列表中,从而创建AST的父子层级关系
currentParent.children.push(elem);
// 同时也将当前节点的父级节点标记为当前的父级节点
elem.parent = currentParent
}
}
// 最后,因为作用域插槽并不是一个真实的标签,我们需要把他从子节点中移除掉
elem.children = elem.children.filter(item => !item.slotScope);
// 因为我们上线又操作过元素了,可能会在后面产生一些空白文本节点,我们再清理一下
trimEndingWhitespace(elem);
// 然后,因为我们的inVPre和inPre是公共变量,一个标签解析结束之后,需要重置一下,否则会影响下一个标签的解析
if (elem.pre) {
inVPre = false;
}
if (isPreTag(elem.tag)) {
inPre = false;
}
// 注:vue还有这样一个不走,不过我看了一下,这个步骤好像只对weex环境才有注入方法postTransforms,因此此处就不实现了
// // apply post-transforms
// for (let i = 0; i < postTransforms.length; i++) {
// postTransforms[i](element, options)
// }
};
/**
* 若当前元素不是pre元素,则删除元素尾部的空白文本节点
* @param elem
*/
function trimEndingWhitespace(elem) {
if (inPre) {
let lastNode;
while (
(lastNode = elem.children[elem.children.length - 1]) && // 节点存在
lastNode.type === AST_ITEM_TYPE.TEXT && // 是文本节点
lastNode.text === ' ' // 文本节点的内容是空白符
) {
// 弹出该元素
elem.children.pop();
}
}
}
parseText的原理
上面已经解释了html的解析原理,但并没有对文本,特别是带有插值表达{{name}}这样的文本进行解析,现在,咱们再来看一下如何解析特殊文本的。
/**
* 构建动态文本转化正则表达式
* @type {function(*): *}
*/
const buildRegex = cached(delimiters => {
// 将分割符变为转义字符
// "{{".replace(/[-.*+?^${}()|[\]\/\\]/g,'\\$&');
// \{\{
const open = delimiters[0].replace(regexEscapeRE, '\\$&');
// "}}".replace(/[-.*+?^${}()|[\]\/\\]/g,'\\$&');
// \}\}
const close = delimiters[1].replace(regexEscapeRE, '\\$&');
return new RegExp(open + '((?:.|\\n)+?)' + close, 'g')
});
/**
* 文本解析器,用于解析文本中的变量
* @param {String} text
* @param {Array} delimiters 分隔符,默认是:["{{","}}"]
* @returns {Object}
*/
export const parseText = (text, delimiters) => {
const expRE = delimiters ? buildRegex(delimiters) : defaultTagRE;
if (!expRE.test(text)) return '';
// 将正则的游标移动到开始的位置
let lastIndex = expRE.lastIndex = 0;
let match, index, res = [],tokenValue = '',rawTokens = [],exp;
while ((match = expRE.exec(text))) {
index = match.index;
// 将{{之前的文本加入到结果数组
if (index > lastIndex) {
rawTokens.push((tokenValue = text.slice(lastIndex, index)))
res.push(JSON.stringify(tokenValue));
}
exp = match[1].trim();
// 解析过滤器
exp = parseFilter(exp);
// 将解析出来的变量转化为调用方法的方式并加入结果数组如:_s(name)
res.push(`_s(${exp})`);
rawTokens.push({ '@binding': exp });
// 设置lastIndex保证下一次循环不会重复匹配已经解析过的文本
lastIndex = index + match[0].length;
}
// 将}}之后的文本加入到结果数组
if (lastIndex < text.length) {
rawTokens.push((tokenValue = text.slice(lastIndex)));
res.push(JSON.stringify(tokenValue));
}
return {
exp: res.join('+'),
tokens: rawTokens
};
};
从上面的代码中,我们可以看到,其实对于文本的解析逻辑也并不难,就是通过正则匹配目标表达式,然后,然后将匹配到的所有表达式生成的代码片段 `_s(${exp})` 和普通文本的加入到一个数组中 ,最后通过join(‘+’)将这些字符串串联起来。其中,_s是一个运行时才会注入的工具方法,其实就把一个值转换成字符串的方法。
构建一个具有父子层级关系的抽象语法树
从上面解析html代码的时候,我们可以看到,我们使用了一个叫做nodeStack的栈用来存储标签,我们之前也说了,通过这个栈,可以帮助我们维护标签之前的父子关系,那么,他到底是怎么通过nodeStack维护父子关系的呢?nodeStack有到底是什么呢?
我们先来解释一下nodeStack吧,这个其实本质上就是一个普通的栈结构的对象,所谓栈,就是严格遵循后进先出的顺序操作的数组。下面来看一下这个栈的具体实现:
// shared/SimpleStack.js 实现了一个简单的栈
class SimpleStack {
constructor() {
this.stack = [];
}
push(item) {
this.stack.push(item);
}
pop() {
return this.stack.pop();
}
size(){
return this.stack.length;
}
empty(){
return this.size()===0;
}
top(){
return this.stack[this.size()-1];
}
findIndex(handle){
let pos = this.size() - 1;
for(;pos>=0;pos--){
let cur = this.stack[pos];
if(cur&&handle(cur)){
return pos;
}
}
return -1;
}
get(pos){
return this.stack[pos];
}
popItemByStartIndex(index){
return this.stack.splice(index).reverse();
}
clear(){
this.stack = [];
}
print(){
console.log(`%c当前栈的数据结构是:`,'color: green', JSON.stringify(this.stack));
}
}
export default SimpleStack;
需要注意的是,在vue源码中其实并没有这样一个对象,Vue源码中是直接使用数组来模拟栈结构的操作的,不过原理都是一样的,我这边对这个栈进行了封装,方便理解与使用。从上面的代码可以看出,其实底层原理使用的也是一个数组,我们所有的操作其实也都是基于数组的操作,我们将它封装起来,只是为了不让外界随意的访问而已。
了解了栈是怎样的,那么我们再来看看如何通过这个栈来帮助我们解析节点之间的父子关系。
我们举个例子来说明一下:
加入说我们的html结构是这样的:
<div>
<p>这是一段文字</p>
<ul>
<li>选项1</li>
<li>选项2</li>
</ul>
</div>
当我们解析到<div>时,将div加入到栈中,此时栈中只有div一个元素,然后继续解析,解析到<p>的时候,我们再把p也加入到栈中,此时栈中有div和p两个元素,栈顶的元素是p。再往下解析,解析到一段文字,触发chars收集并生成抽象语法树文本节点,那么,此时,这个文本节点的父级是什么呢?显而易见,就是我们栈顶的元素p。所以我们将这个文本节点加入到p的children中即可。继续解析,发现</p>结束标签,我们将栈顶元素p弹出来,也就是说,现在我们的栈里又只有一个div了,同理,下面的ul和li也是这样操作。当最后解析到</div>时,栈里也就只有一个div元素了,将栈顶的div弹出,栈空了,已经解析完了。流程如下:
- 发现<div> ==[入栈]=> [div] 栈顶元素为div
- 发现<p> ==[入栈]=> [div,p] 栈顶元素为p
- 发现</p> ==[出栈]=> [div] 栈顶元素为div
- 发现<ul> ==[入栈]=> [div,ul] 栈顶元素为ul
- 发现<li> ==[入栈]=> [div,ul,li] 栈顶元素为li
- 发现</li> ==[出栈]=> [div,ul] 栈顶元素为ul
- 发现<li> ==[入栈]=> [div,ul,li] 栈顶元素为li
- 发现</li> ==[出栈]=> [div,ul] 栈顶元素为ul
- 发现</ul> ==[出栈]=> [div] 栈顶元素为div
- 发现</div> ==[出栈]=> [] 栈为空
因此,使用栈来辅助,我们要找到当前节点的父标签其实很容易,栈顶元素就是了。
经过模板编译器的编译,我们就能得到一个抽象语法树的根节点
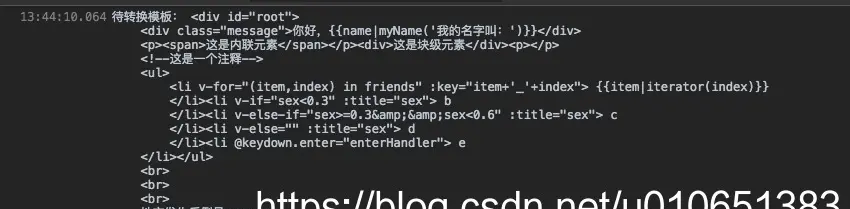

图为带编译模板
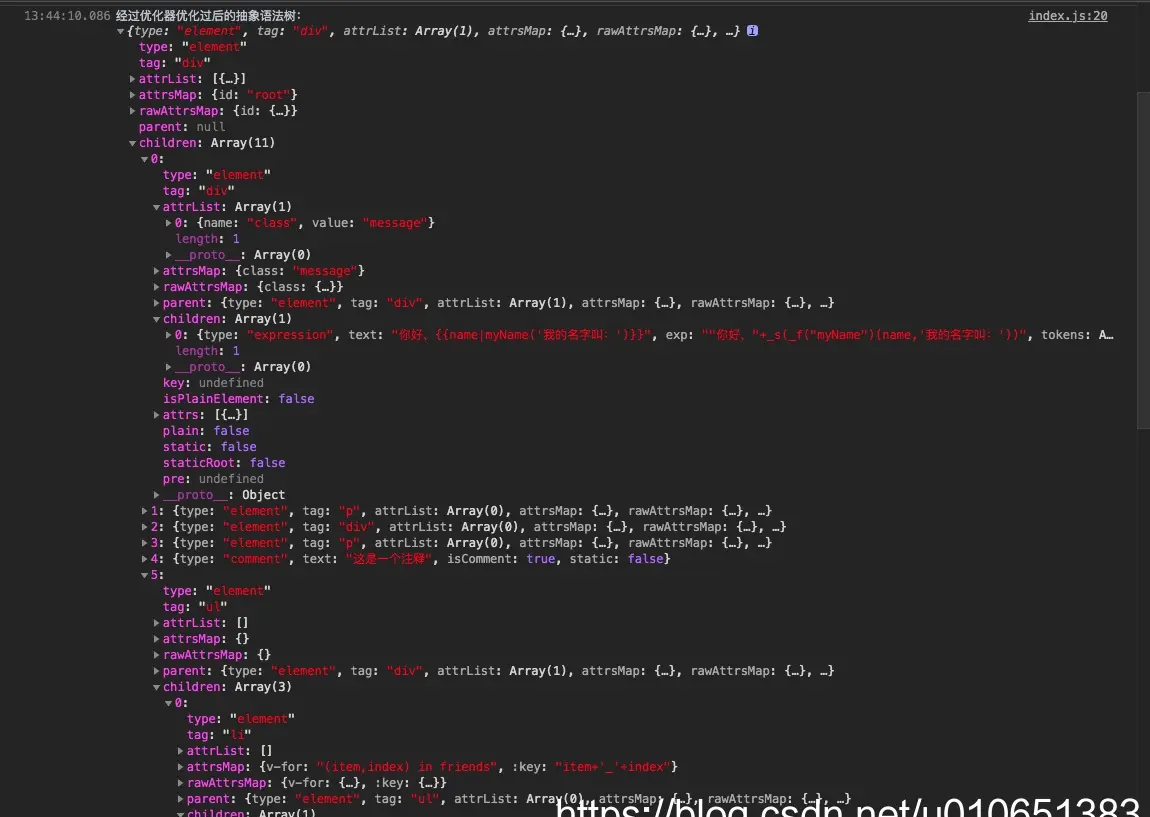
图为生成的抽象语法树
好了,模板编译器的相关原理就讲到这里吧,之后还会陆续更新优化器、代码生成器等相关原理的文章,欢迎共同学习讨论。
最后,再附上项目github:kinerVue/dev-0.0.1 ,欢迎star!
原文链接:https://juejin.cn/post/7328273660791095348 作者:kinertang