


我们在用VSCode写document这个对象时,VSCode会弹出很多代码提示选项,排在第二个的是Document,相信大家有过不小心将document选成Document的情况,然后代码运行就报错了。
我们都知道document可以干啥,它有很多的成员方法和属性。但是Document又是个啥?
这就要引入的我们的今天的主题,文档对象模型,英文全称:Document Object Model,简称DOM,后面咱们就统一用简称DOM。
本篇文章的目标读者群是Web前端的初学者。
初识DOM
在浏览器中,HTML用于显示界面,JavaScript用于和界面交互,JavaScript作为一个编程语言本身并没有操作界面的能力,浏览器基于JavaScript引擎的API拓展出了一套API用于操作页面元素,这套API就是DOM API。
也就是说JavaScript如果想操作界面,那就调用DOM的API。
DOM API既然可以操作页面的任何元素,那就要把页面的元素管理起来,这样才可以定位到任意元素。
下面我们通过一个例子来看一下DOM是如何组织页面元素的,下面的例子来自于W3C:
<TABLE>
<ROWS>
<TR>
<TD>Shady Grove</TD>
<TD>Aeolian</TD>
</TR>
<TR>
<TD>Over the River, Charlie</TD>
<TD>Dorian</TD>
</TR>
</ROWS>
</TABLE>
上面是一段HTML,一个表格,DOM会按照下面的样子来组织这些HTML元素:

可以看到DOM对HTML进行了结构化,是一个树状结构。
树状结构用面向对象的形式来进行描述,每一个节点都对应一个JavaScript对象,这些节点对象可以通过其属性找到其它任何节点。
举例如下:
节点对象:node
节点的子节点:node.childNodes
节点的第一个子节点:node.firstChild
节点的最后一个子节点:node.lastChild
节点的前一个兄弟节点:node.previousSibling
节点的后一个兄弟节点:node.nextSibling
节点的父节点:node.parentNode
等等。
这种对HTML结构进行描述的方式就是文档对象模型,简称DOM。
DOM的API非常多,我们可以在Chrome的调试控制台输入console.dir(node)来查看一个节点都有哪些API,例如我们要查看<body>节点的API,可以这样:console.dir(document.body)。(Chrome打开调试控制台的方式,Mac:command + option + j,Windows:ctrl + shift + j)。
在HTML的DOM结构中,最顶层的节点是document。
我们最常用的DOM API:document.getElementById('xxx'),用于通过元素的id来找到这个元素的DOM节点对象,下面咱们的例子中会频繁使用该方法。
node.childNodes和node.children的不同
我们在用DOM的API进行节点操作时,经常会遇到这两个APInode.childNodes和node.children,有没有感觉很奇怪,一看名字就知道这两个API都是用来表示子节点的,为什么会有两个API做同样的事情呢?
其实它们有些不一样。
childNodes
childNodes是Node的属性,它返回的是所有的子节点,包括子元素、文本等等。
举一个例子:
<div id="container">
IT技术
<div>
</div>
</div>
通过下图,我们看一下container的子节点都有哪些(通过document.getElementById('container').childNodes查看所有子节点):

可以看到container有三个子节点,IT技术和其前面的空字符串是第一个子节点,里面的div是第二个子节点,里面的div后面依然有空字符,是第三个子节点。
childNode返回数据的类型是NodeList。关于整个DOM的面向对象的类结构体系我们在下面讲。
这里我们想说的是NodeList本身,NodeList有两点特性需要说明:
-
NodeList并不是数组类型,但是是类数组。
不是数组那就意味着它没有常用的数组方法,例如filtermap等,但是forEach可以。
是类数组那就意味,它具有数字索引,可以使用[index]这种方式来访问。它有length属性,可以获取节点数。传统的将类数组转成数组的方法对它都适用,不过在ES6时代,可以用Array.from()方法将其转成真正的数组。 -
NodeList可以是动态的也可以是静态的(Live 或者 Static)
由于JavaScript可以动态地添加DOM元素,因此NodeList的值可以动态的变化。
举例如下:const parent = document.getElementById("parent"); let childNodes = parent.childNodes; // 假设子节点数是2 console.log(childNodes.length); parent.appendChild(document.createElement("div")); // 这时childNodes变成了3 console.log(childNodes.length);上面的例子中,
parent用appendChild新增了一个元素,此时childNode实时反映了目前节点的真实情况。因此这是一个动态的NodeList。NodeList也可以是静态的,document.querySelectorAll()方法返回的NodeList就是静态的。所谓静态就是DOM新加的元素不会体现到已经获取到的NodeList对象中。document.querySelectorAll()是通过CSS选择器语法来选择出所有符合条件的节点。
children
children是Element的属性,Element代表HTML元素,只有HTML元素有children属性。children返回的子节点也都是Element,HTML元素。而文本节点并不在children返回之列。
还是用childNodes的那个例子:
<div id="container">
IT技术
<div>
</div>
</div>
我们通过document.getElementById('container').children查看所有的子元素:
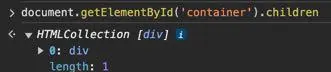
可以看到只有一个子元素div,文本节点都被忽略了。
大部分时候,children会更有用一些。
children在IE上似乎支持得不太好,其他主流浏览器都是从早期就已经支持了这两个属性,只要你没有IE用户,是可以放心使用的。
children返回数据的类型是HTMLCollection。关于整个DOM的面向对象的类结构体系我们在下面讲。
这里我们想说的是HTMLCollection本身,用这个名字来形容HTML元素确实不太贴切,但是这是历史原因导致的,要改掉几乎不可能。
和NodeList一样,HTMLCollection也有两点特性需要说明:
-
HTMLCollection并不是数组类型,但是是类数组。
不是数组那就意味着它没有常用的数组方法,例如filtermap等,但是forEach可以。
是类数组那就意味,它具有数字索引,可以使用[index]这种方式来访问。它有length属性,可以获取节点数。传统的将类数组转成数组的方法对它都适用,不过在ES6时代,可以用Array.from()方法将其转成真正的数组。 -
HTMLCollection是动态的,由于JavaScript可以动态地添加DOM元素,因此HTMLCollection的值可以动态的变化。
举个例子:
const parent = document.getElementById("parent");
let childrenCollection = parent.children;
// 假设子节点数是2
console.log(childrenCollection.length);
parent.appendChild(document.createElement("div"));
// 这时childNodes变成了3
console.log(childrenCollection.length);
上例中childrenCollection就是那个HTMLCollection类型的变量,它会动态的反馈出当前DOM节点的情况。
DOM的节点类型
上面咱们说到childNodes和children返回的数据类型不同,可以看到虽然DOM由节点组成,但是节点会有不同的类型。每个类型可通过一个number类型的数字表示,具体的API是node.nodeType,node代表节点对象。
通过对节点类型进行分类,让DOM 的API更强大了。
举例如下:
<!Doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>
</title>
</head>
<body>
<div id="container">
<!-- 标题 -->
IT技术
<div>
fdsafs
</div>
</div>
</body>
</html>
如果我们要找到container中所有的注释怎么找呢?
注释也是节点,其节点类型值是8,示例代码如下:
const childNodes = document.getElementById('container').childNodes;
const commentNodes = Array.from(childNodes).filter(node => node.nodeType == 8)
上例中我们通过过滤出nodeType属性是8的节点,便找出了子节点中所有的注释。
DOM所有的节点类型,每个节点类型对应的数字和解释如下:
| 节点名字 | 类型值 | 解释 |
|---|---|---|
| ELEMENT_NODE | 1 | 元素节点 |
| ATTRIBUTE_NODE | 2 | 元素的属性 |
| TEXT_NODE | 3 | 文本节点 |
| CDATA_SECTION_NODE | 4 | XML的纯文本标识<!CDATA[[ … ]]> |
| PROCESSING_INSTRUCTION_NODE | 7 | XML中的处理指令节点 |
| COMMENT_NODE | 8 | 注释节点,例如:<!-- --\> |
| DOCUMENT_NODE | 9 | DOM树的根节点:document |
| DOCUMENT_TYPE_NODE | 10 | 文档类型节点,例如:<!Doctype html> |
| DOCUMENT_FRAGMENT_NODE | 11 | 文档片段,多个节点可以组成文档片段,一次性插入父节点,批量操作,提高性能 |
可以看到数字不连续,那是因为有几个节点类型已经被废弃了。
这些节点当中,我们最最常用的节点类型应该是元素节点,可以看到它的nodeType是1。是不是比较好记呢?
DOM的类继承体系
HTML有各种类型的节点,例如:div select等等,这些不同的节点既有共通的地方,又有不同的地方。例如作为节点,它们应该都可以被插入或者删除,但是select有disabled属性可以让其变成不可选择状态,而div就没有。
用面向对象的方式来描述HTML的节点非常合适。
我们来看看浏览器是如何对DOM进行面向对象的,请看下图:
这里由于篇幅所限,并没有把XML相关的类型和所有具体的HTML元素类型都放在这里。
此图展示了DOM的类继承关系。图中所有的叶子节点代表了各种DOM的节点的类型。
HTMLDivElement代表着div,HTMLSelectElement代表了select选择框,所有的HTML元素都继承于HTMLElement。
上面说的HTMLCollection就是HTMLElement的集合。
最左边的叶子节点HTMLDocument是window.document对象的类型,它继承于Document。咱们标题中说的Document和document的区别就在这里了。Document是document对象的父类型。
最右边的Text Comment分别代表文本节点的类型和注释节点的类型。
所有的节点类型都继承于Node,节点通用的属性和方法都放在这里,例如:node.appendChild() node.removeChild()等。
上面我们说到的NodeList,它里面节点的类型就是Node,因为NodeList代表的是所有类型的节点,所以用Node类型是最合适的,因为所有节点都继承于Node。
Node又继承于EventTarget,基础的DOM事件相关的方法都放在这里。
比较有意思的是,这些类或者说构造函数都被挂在了window对象下,可以直接访问。
DOM的历史背景
这部分内容来自于维基百科。
当JavaScript和微软的JScript出来后,第一版的DOM就诞生了,用于侦测用户事件和修改HTML文档。第一版DOM被称为“DOM Level 0”,没有独立的标准,但是有一部分文档被放到了HTML 4的说明文档中。
1997年,IE和网景的浏览器分别发布了4.0版本,两个4.0版本的浏览器都支持DHTML,DHTML的DOM扩展分别由两个浏览器厂商各自开发,相互不兼容。这段时间的DOM叫做“Intermediate DOM”。
JavaScript被ECMA组织标准化为ECMAScript后,W3C的DOM工作组也开始起草DOM标准。这个DOM标准被称作“DOM Level 1”,1998年成为正式标准被W3C推荐。到2005年,大部分“DOM Level 1”的特性已经被能运行标准JavaScript的浏览器广泛支持。这些浏览器包括 IE 6、Opera、Safari、基于Gecko的浏览器(Mozilla、Firefox、SeaMonkey和Camino)。
2015年,DOM几经易手后,DOM Level 4发布,它是WHATWG小步快跑式DOM流式标准的一个快照,从此以后W3C每个隔一段时间就会对WHATWG的DOM标准进行一次快照,作为一个正式的推荐版本。所谓流式标准就是以小特性集合的方式高频的发布新特性标准,很像敏捷开发中小步快跑迭代的概念。
下面是对DOM几个历史版本的介绍:
- DOM Level 1 提供了完整的HTML或者XML文档的模型,可以修改文档的任何部分。
- DOM Level 2 于2000年发布,引入了
getElementById方法、事件模型、支持XML命名空间和CSS。 - DOM Level 3 发布于2004年4月,开始支持XPath、键盘事件处理、支持将文档序列化成XML。
- HTML5于2014年10月份发布。部分HTML5替换了 DOM Level 2 的HTML模块。
- DOM Level 4 于2015年发布。它是WHATWG流式标准的一个快照。
结束语
到这里关于DOM的基础概念部分就讲完了。其实还有DOM的事件处理和常用API、Range相关的知识。这个我们会在Web基础精讲系列另开文章讲解。
原文链接:https://juejin.cn/post/7328335887016247330 作者:吉灵云