

前言
前阵子在研究跟 HTTP Cache 有关的一些东西,看得眼花撩乱,不同的 Header 愈看愈混乱,像是Pragma, Cache-Control, Etag, Last-Modified, Expires 等等。找了许多参考资料阅读之后才有了比较深刻的理解,想说若是从一个比较不同的角度来理解 Cache,说不定会比较容易了解这些 Header 到底在做什么。
在之前查的资料里面,很多篇都是逐一解释各个 Header 的作用以及参数,而我认为其实参数讲多了容易造成初学者混淆,想说怎么有这么多奇怪的参数,而且每一个看起来都很像。所以这篇文章尝试一步一步借由不同的问题来引导出各个 Header 使用的场景以及出现的目的。还有,因为这篇是给初学者看的,所以不会讲到所有的参数。
其实关于 Cache 这一部分,很多网络资源的说法都不太一样,如果碰到有疑义的地方我会尽量以 RFC 上面写的标准为主。如果有错误的话还麻烦不吝指正,感谢。
为什么需要缓存
多问为什么是个好习惯,在你用一个东西之前,必须知道你为什么要用它。于是,我们需要问自己一个问题:为什么需要 Cache?
很简单,因为节省流量嘛,也节省时间,或是更宏观地来说,减少资源的损耗。
举例来说,今天电商网站的首页可能会有很多商品,如果每一个用户到首页你都去数据库重新查一次所有的数据,那对数据库的负担会非常非常大。
可是呢,其实首页的这些数据基本上短期之内是不会变的,一个商品的价格不可能上一秒是一千元,下一秒就变成两千元。所以这些不常变动的数据就很适合缓存起来,也就是我们说的 Cache。
上面这个例子中可以把首页的数据在查出来一次之后就存在某个地方,例如说 Redis,其实就是以一个简单的 Key Value 的形式存进去即可,接着只要是用到这些数据的时候,都可以用极快的速度查出来,而不是再到数据库里面重新算一次。
上面讲的是服务端的 Cache,借由把数据库的数据查出来之后存到别的地方实现。但服务端的 Cache 并不是我们今天的重点,今天的重点是 Server 跟浏览器之间的 Cache 机制。
拿电商网站的商品图举例。如果没有 Cache 的话,那首页出现的上百张商品图,只要网页被浏览几次,就会被下载几次,这个流量是非常惊人的。所以我们必须让浏览器可以把这些图片给缓存起来。这样只有第一次浏览这个网页的时候需要重新下载,第二次浏览的时候,图片就可以直接从浏览器的 Cache 里面去拿,不用再向 Server 请求数据了。
HTTP 缓存头的作用
Expires 和 Cache-Control
要达成上述的功能,可以在 HTTP Response Header 里面加上一个Expires的字段,里面就是这个 Cache 到期的时间,例如说:
Expires: Wed, 21 Oct 2023 07:28:00 GMT
浏览器收到这个 Response 之后就会把这个资源给缓存起来,当下一次用户再度访问这个页面或是要请求这个图片的资源的时候,浏览器会检查「现在的时间」是否有超过这个 Expires。如果没有超过的话,那浏览器「不会发送任何请求」,而是直接从电脑里面已经存好的 Cache 拿数据。
若是打开 Chrome dev tool,就会看到它写著:「Status code 200 (from disk cache)」,代表这个 Request 其实没有发出去,Response 是直接从 disk cache 里面拿的。


可是这样会碰到一个问题,因为浏览器检查这个 Expires 的时间是用「电脑本身的时间」,那如果我喜欢活在未来,把电脑的时间改成 2100 年,会怎样呢?
浏览器就会觉得所有的 Cache 都是过期的,就会重新发送请求。
Expires 其实是 HTTP 1.0 就存在的 Header,而为了解决上面 Expires 会碰到的问题,HTTP 1.1 有一个新的 header 出现了,叫做:Cache-Control。(注:Cache-Control 是 HTTP 1.1 出现的 Header,但其实不单单只是解决这个问题,还解决许多 HTTP 1.0 没办法处理的缓存相关问题)
其中一种用法是:Cache-Control: max-age=30,就代表这个 Response 的过期时间是 30 秒。假设用户在收到这个 Response 之后的第 10 秒重新请求,那就会直接取 Cache 里的数据。
但假如使用者是过 60 秒之后才重新请求,浏览器就会发送新的 Request。
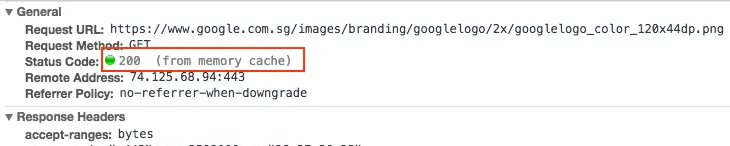
仔细观察 Google Logo 文件的 Response header,你会发现它的max-age设定成31536000秒,也就是 365 天的意思。只要你在一年之内访问这个网站,都不会对 Google logo 这张图片发出请求,而是会直接使用浏览器已经缓存住的 Response,也就是这边写的Status code 200 (from memory cache)。
现在就碰到一个问题了,既然Expires跟max-age都可以决定一个 Response 是否过期,那如果两个同时出现,浏览器要看哪一个呢?
根据 RFC2616 的定义:
If a response includes both an Expires header and a max-age directive, the max-age directive overrides the Expires header, even if the Expires header is more restrictive
max-age会盖过Expires。
上面这两个 Header 都是在关注一个 Response 的过期时间,如果 Response 还没超过Expire或者是在max-age规定的期限里面,就直接从缓存里面拿数据。如果过期了,就发送请求去跟 Server 拿新的数据。
Last-Modified 和 If-Modified-Since
但是这边要特别注意一点:「过期了不代表不能用」
这是什么意思呢?刚刚有提到说 Google 的 Logo 缓存时间是一年,一年之后浏览器就会重新发出请求,可是很有可能 Google 的 Logo 在一年之后也不会换,代表其实浏览器缓存起来的图片还是可以用的。
如果是这种情况,那 Server 就不必返回新的图片,只要跟浏览器说:「你缓存的图片可以继续用一年喔」就可以了。
想要做到上面的功能,必须要 Server 跟 Client 两边互相配合才行。其中一种做法就是使用 HTTP 1.0 就有的:Last-Modified与If-Modified-Since的搭配使用。
在 Server 传送 Response 的时候,可以多加一个Last-Modified的 Header,表示这个文件上一次更改是什么时候。而当缓存过期,浏览器下次再发送请求的时候,就可以利用这个信息,改用If-Modified-Since来跟 Server 指定获取某个时间点以后有更改的数据。
直接举一个例子吧,假设我要求 Google 首页的图片文件,收到了这样的 Response(为了方便阅读,日期的格式有更改过,实际上的内容不会是这样):
Last-Modified: 2017-01-01 13:00:00
Cache-Control: max-age=31536000
浏览器收到之后就会把这张图片存进缓存,并且标明这个文件的最后更新时间是:2017-01-01 13:00:00,过期时间是一年后。
如果在半年后我重新请求这张图片,浏览器就会跟我说:「你不用重新请求了,这一份文件的过期时间是一年,现在才过了半年。你要数据是吧?我这里就有!」,于是就不会发送任何请求,而是直接从浏览器那边获得数据。
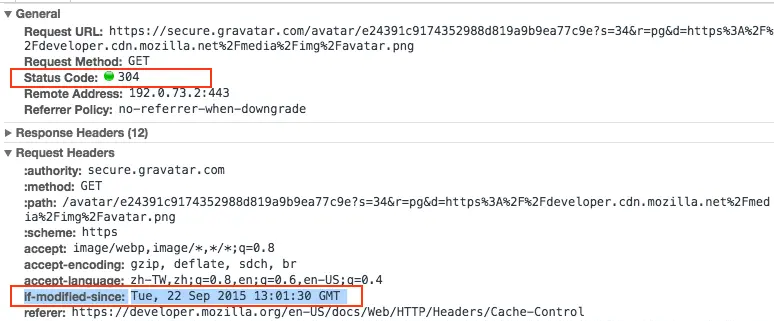
接着我在过了一年之后再请求一次这张图片,浏览器就会说:「嗯嗯,我这边的缓存的确过期了,我帮你去 Server 问一下文件从2017-01-01 13:00:00以后有没有更新」,会发送出下面这样的 Request:
GET /logo.png
If-Modified-Since: 2017-01-01 13:00:00
假设文件确实更新了,那浏览器就会收到一份新的文件。如果新的文件一样有那些 Cache 的 Header,就一样会缓存起来,跟上面的流程都一样。那假设文件没有更新呢?
假设没有更新的话,Server 就会回一个Status code: 304 (Not Modified),代表你可以继续沿用缓存的这份文件。
Etag 和 If-None-Match
虽然上面的这个方法看起来已经很好了,但还是有一个小问题。
上面讲的是文件有没有被「编辑」过,但其实这个编辑时间就是你电脑上文件的编辑时间。若是你打开文件什么都不做,然后保存,这个编辑时间也会被更新。可是尽管编辑时间不一样,文件的内容还是一模一样的。
比起编辑时间,若是能用「文件内容更动与否」来当作是否要更新缓存的条件,那是再好不过了。
而Etag这个 Header 就是这样的一个东西。你可以把 Etag 想成是这份文件内容的 hash 值(但其实不是,但原理类似就是了,总之就是一样的内容会产生一样的 hash,不一样的会产生不一样的 hash)。
在 Response 里面 Server 会带上这个文件的 Etag,等缓存过期之后,浏览器就可以拿这个 Etag 去问说文件是不是有被变更过。
Etag跟If-None-Match也是搭配使用的一对,就像Last-Modified跟If-Modified-Since一样。
Server 在响应 Response 的时候带上Etag表示这个文件独有的 hash,缓存过期后浏览器发送If-None-Match询问 Server 是否有新的数据(不符合这个Etag的数据),有的话就发送新的过来,没有的话就只要响应 304 就好了。
流程可以参考下图:

小结
让我们来总结一下到目前为止学到的东西:
-
Expires跟Cache-Control: max-age决定这份缓存的过期时间,也就是什么时候「过期」。在过期之前,浏览器「不会」发送出任何请求 -
当缓存过期之后,可以用
If-Modified-Since或是If-None-Match询问 Server 有没有新的资源,如果有的话就发送新的,没有的话就响应 Status code 304,代表缓存里面的资源还能继续使用。
如何合理使用 cache
有了这几个 Header 之后,世界看似美好,好像所有的问题都解决了一样。
是的,我说「好像」,代表其实还有一些问题存在。
有一些页面可能会不想要任何的缓存,例如说含有一些机密资料的页面,就不希望任何的东西被保留在 Client 端。
还记得我们一开始有提过Cache-Control这个 Header 其实解决了更多问题吗?除了可以指定max-age以外,可以直接使用:Cache-Control: no-store,代表说:「我就是不要任何缓存」。
因此每一次请求都必定会到达 Server 去要求新的数据,不会有任何数据被缓存。
(注:HTTP 1.0 里面有一个Pragma的 Header,使用方法只有一种,就是:Pragma: no-cache,有网络上的资料说它就是不要任何缓存的意思,但根据 RFC7232 的说法,这个用法应该跟Cache-Control: no-cache一样,而不是Cache-Control: no-store,这两个的差异等等会提到)
刚刚上面提到的都是一些静态资源例如说图片,特性就是会有好一阵子不会变动,因此可以放心地使用max-age。
但现在我们考虑到另外一种状况,那就是网站首页。
网站首页虽然也不常会变动,但我们希望只要一变动,使用者就能够马上看到变化。那要怎么办呢?设max-age吗?也是可以,例如说Cache-Control: max-age=30,只要过 30 秒就能让缓存过期,去跟 Server 拿新的数据。
但如果我们想要更及时呢?只要一变动,使用者就能够马上看到变化。你可能会说:「那我们可以不要缓存就好啦,每次都请求新的数据」。可是如果这个首页有一个星期都没有变,其实使用缓存会是比较好的办法,节省很多请求。
因此我们的目的是:「把数据缓存起来,但只要数据一变动,就能够立刻看到新的数据」
这个怎么做到呢?第一招,你可以用Cache-Control: max-age=0,这就代表说这个 Response 0 秒之后就会过期,意思是浏览器一接收到,就会标识为过期。这样当用户再次访问页面,就会去 Server 询问有没有新的数据,再搭配上Etag来使用,就可以保证只会接收到最新的 Response。
例如说第一个 Response 可能是这样:
Cache-Control: max-age=0
Etag: 1234
我重新访问一次,浏览器发出这样的请求:
If-None-Match: 1234
如果文件没有变动,Server 就会回传:304 Modified,有变动的话就会发送新的文件并且更新Etag。如果是使用这种方式,其实就是「每一次访问页面都会发送一个请求去确认有没有新的文件,有的话就下载更新,没有的话沿用缓存里的」。
除了上面这招max-age=0,其实有一个已经规范好的策略叫做:Cache-Control: no-cache。no-cache并不是「完全不使用缓存的意思」,而是跟我们上面的行为一样。每次都会发送请求去确认是否有新的文件。
如果要「完全不使用缓存」,是Cache-Control: no-store。这边不要搞混了。
为了怕大家搞混,我再讲一次这两个的差异:
假设 A 网站是使用Cache-Control: no-store,B 网站是使用Cache-Control: no-cache。
当每一次重新访问同样一个页面的时候,无论 A 网站有没有更新,A 网站都会发送来「整份新的数据」,假设index.html有 100 kb 好了,访问了十次,累积的流量就是 1000kb。
B 网站的话,我们假设前九次网站都没有更新,一直到第十次才更新。所以前九次 Server 只会回传 Status code 304,这个封包大小我们姑且算作 1kb 好了。第十次因为有新的文件,会是 100kb。那十次加起来的流量就是 9 + 100 = 109 kb
可以发现 A 跟 B 达成的效果一样,那就是「只要网站更新,使用者就能立即看到结果」,但是 B 的流量远低于 A,因为有善用缓存策略。只要每一次请求都先确认网站有没有更新即可,不用每一次都下载完整的文件下来。
这就是no-store跟no-cache的差异,永远不用缓存跟永远检查缓存。
现在 Web App 当道,许多网站都是采用 SPA 的架构搭配 Webpack 打包。前端只需要引入一个 JavaScript 的文件,Render 就交给 JavaScript 来做就好。
这类型的网站,HTML 可能长得像这样:
<!DOCTYPE html>
<html>
<head>
<link rel='stylesheet' href='style.css'></link>
<script src='script.js'></script>
</head>
<body>
<!-- body 为空,所有内容都交给 js 去 render -->
</body>
</html>
当 JavaScript 加载完成之后,利用 JavaScript 把页面渲染出来。
面对这种情境,我们就会希望这个文件能够跟上面的首页文件一样,「只要文件更新,使用者能够立即看到新的结果」,因此我们可以用Cache-Control: no-cache来达成这个目标。
可是呢,还记得刚说过no-cache其实就是每一次访问页面,都去 Server 问说有没有新的结果。意思就是无论如何,都会发出请求。
有没有可能,连请求都不发呢?
意思就是:「只要文件不更新,浏览器就不会发请求,直接沿用缓存里的即可。只要文件一更新,浏览器就要立即下载新的文件」
前者其实就是我们一开始讲的max-age在做的事,但max-age没办法做到判断「文件不更新」这件事情。
所以其实这个目标,没办法单靠上面我们介绍的这些浏览器的缓存机制来达成,需要 Server 那边一起配合才行。其实说穿了,就是把 Etag 的机制自己实现在文件里面。
什么意思呢?我们直接来看一个范例,我们把index.html改成这样:
<!DOCTYPE html>
<html>
<head>
<link rel='stylesheet' href='style.css'></link>
<script src='script-qd3j2orjoa.js'></script>
</head>
<body>
<!-- body 为空,所有内容都交给 js 去 render -->
</body>
</html>
注意到 JavaScript 的文件名变成:script-qd3j2orjoa.js,后面其实就跟 Etag 一样,都是代表这个文件的 hash 值。然后我们把这个文件的缓存策略设成:Cache-Control: max-age=31536000。
这样子这个文件就会被缓存住一年。一年之内都不会对这个 URL 发送新的请求。
那如果我们要更新的话怎么办呢?我们不要更新这个文件,直接更新index.html,换一个 JavaScript 文件:
<!DOCTYPE html>
<html>
<head> <link rel='stylesheet' href='style.css'></link> <script src='script-8953jief32.js'></script></head><body> <!-- body 为空,所有内容都交给 js 去 render --></body></html>
因为index.html的缓存策略是no-cache,所以每一次访问这个页面,都会去看index.html是否更新。
以现在这个例子来说,它的确更新了,因此新的这份就会传回给浏览器。而浏览器发现有新的 JavaScript 文件就会去下载并且缓存起来。
借由把 Etag 的机制实作在index.html里面,我们就达成了我们的目标:「只要文件不更新,浏览器就不会发送请求,直接沿用缓存里的即可。只要文件一更新,浏览器就要立即下载新的文件」
原理就是针对不同的文件采用不同的缓存策略,并且直接用「更换 JavaScript 文件」的方式强制浏览器重新下载,流程如下图所示。

总结
HTTP 缓存的机制确实有点复杂,是因为分成不同的部分,每一个相关的 Header 其实都是在负责不同的部分。例如说Expires跟max-age是在负责看这个缓存是不是在缓存时间内,Last-Modified, If-Modified-Since, Etag, If-None-Match是负责询问这个缓存能不能「继续使用」,而no-cache与no-store则是代表到底要不要使用缓存,以及应该如何使用。
最后,希望这篇文章能让初学者更理解 HTTP 的缓存机制。
原文链接:https://juejin.cn/post/7332386070049538100 作者:写bug写bug