
元字符、量词、重复匹配和可选匹配
什么是元字符?
在正则表达式中,元字符是具有超出字面含义的特殊含义的字符。
元字符是正则表达式的支柱。它们充当构建更好的正则表达式模式和定义您正在使用的正则表达式引擎的行为的构建块,但需要额外的学习曲线。
在本书的这一部分中,您将了解以下主题:
- 锚
- 单词边界
- 如何指定字符范围
- 如何将每个匹配项与通配符匹配
- 交替
- 正则表达式的贪婪和惰性以及如何防止贪婪
这里就列举这些,还有很多,感兴趣可自行研究。
如果要将任何元字符作为文字字符进行匹配,则必须使用反斜杠 ( \ ) 将其转义。如果有一个单词代表一个元字符,您也必须使用反斜杠对其进行转义。因此,反斜杠也是一个单独的元字符。
有一个元字符可以否定大多数元字符。例如, \b 和 \s 表示单词边界和空格元字符。如果你想否定它们,可以分别使用 \B 和 \S 。这是大多数元字符遵循的模式 – 小写字母是元字符,大写字母否定它。
元字符分为单元字符和双元字符。顾名思义,单元字符具有“单个”字符,双元字符具有“双”字符。
大多数元字符也称为速记字符类。当我们查看每个元字符时,您将看到它是单元字符还是双元字符。
单词和非单词元字符
用 \w 表示,单词元字符是匹配所有单词字符的简写字符类。单词字符是字母数字字符和下划线。因此,它们是 a-z 、 A-Z、 0-9 和下划线 ( _ )。
以下是在正则表达式测试器中使用 \w 时会发生的情况:
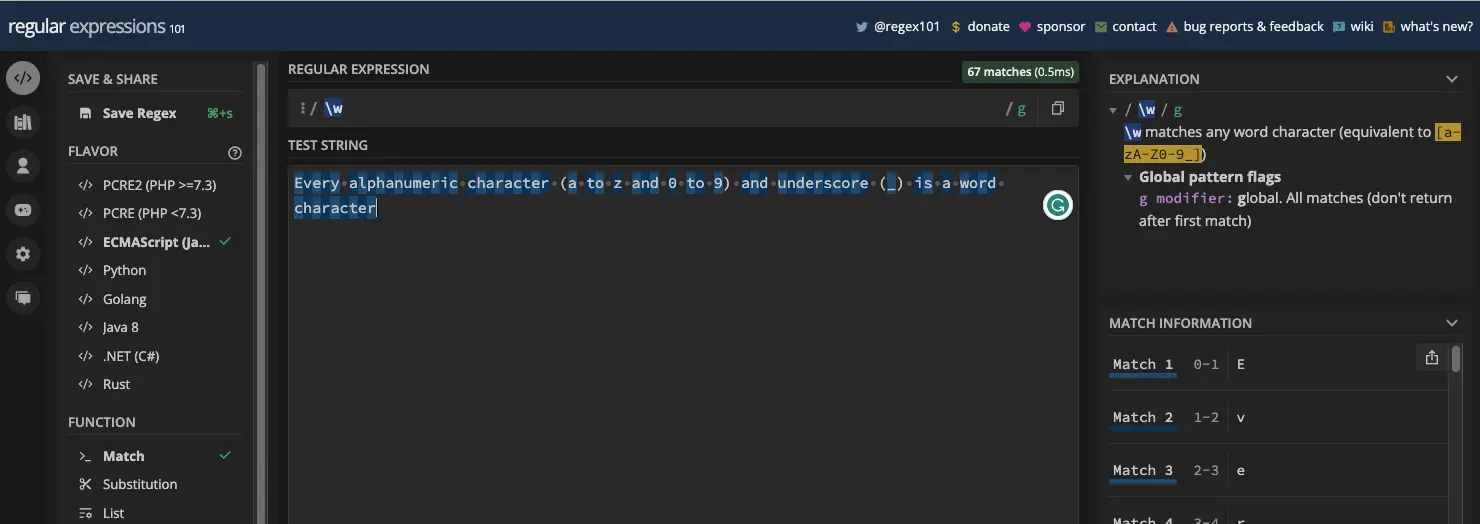

这是它在 JavaScript 中的工作原理:
const testStr =
'Every alphanumeric character (a to z and 0 to 9) and underscore (_) is a word character';
const wordCharacterRe = /\w/g;
console.log(testStr.match(wordCharacterRe));
由于单词字符是字母数字字符和下划线,因此您可以通过将所有示例放入字符集中来模拟 \w 元字符:
const testStr =
'Every alphanumeric character (a to z and 0 to 9) and underscore (_) is a word character';
const wordCharacterRe = /[a-z A-Z 0-9_]/g;
console.log(testStr.match(wordCharacterRe));
非单词元字符与单词元字符相反,它由转义大写字母 W ( \W ) 表示。
非单词元字符匹配除字母数字字符和下划线之外的所有其他字符。其中包括空格、标点符号和符号:
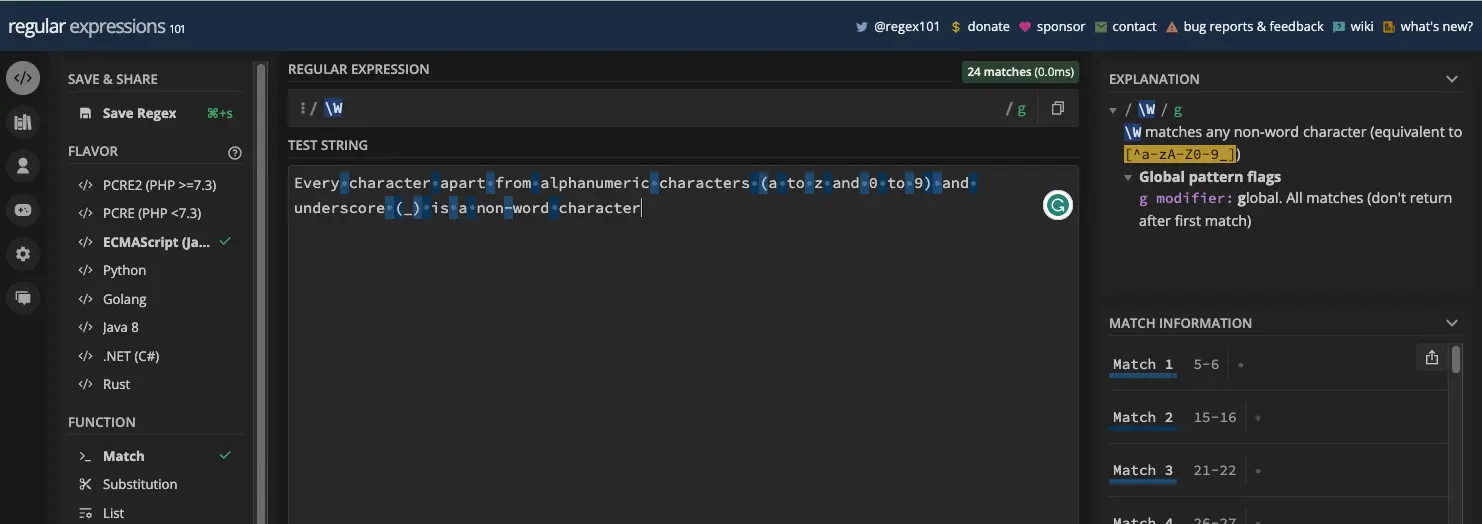
这是它在一些 JavaScript 代码中的运行情况:
const testStr =
'Every character apart from alphanumeric characters (a to z and 0 to 9) and underscore (_) is a non-word character';
const nonWordCharacterRe = /\W/g;
console.log(testStr.match(nonWordCharacterRe));
由于您可以通过将所有字符放入字符集中来表示单词元字符,因此您可能想知道如何对非单词元字符执行相同的操作。
这就是否定字符集的用武之地。插入符号 ( ^ ) 用于否定。它是两个锚定元字符之一,我们接下来将讨论它。
The Anchor Metacharacters 锚元字符
脱字符号 ( ^ ) 和美元符号 ( $ ) 是两个锚元字符。它们都是单个元字符。
插入符号将正则表达式模式锚定到行或字符串的开头,因此您可以将其称为“行锚点的开头”。
例如,如果您想要匹配文本“freeCodeCamp”并且想要确保它位于行或字符串的开头,则可以通过以下方式使用插入符号:
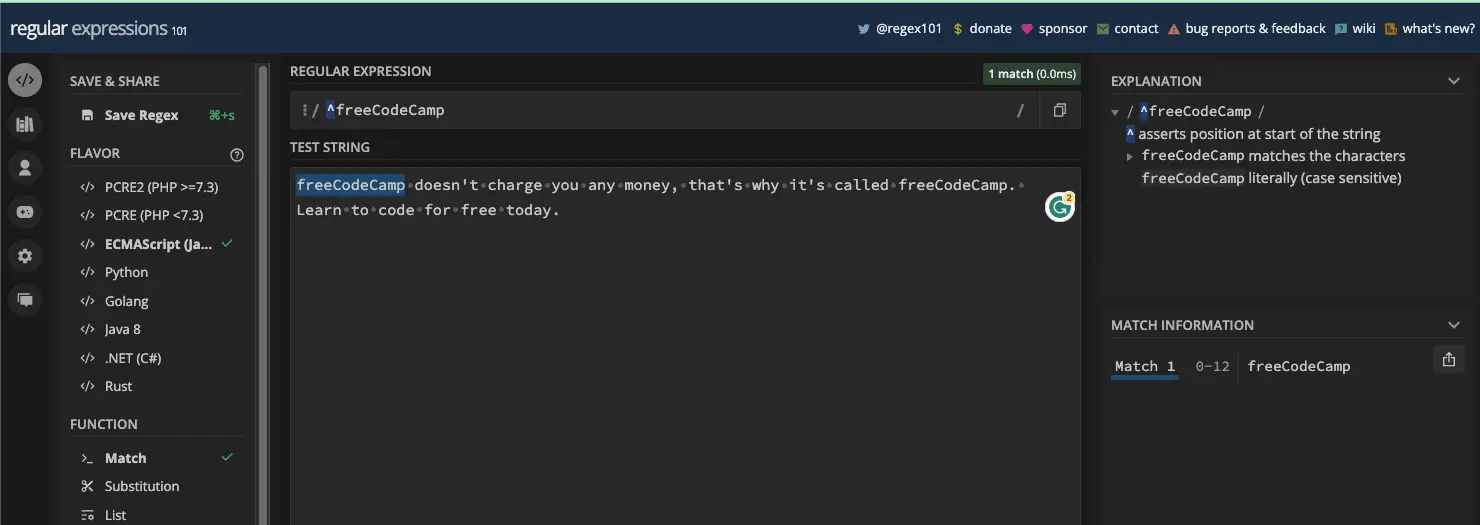
如果 freeCodeCamp 文本不在行的开头,则不会匹配:
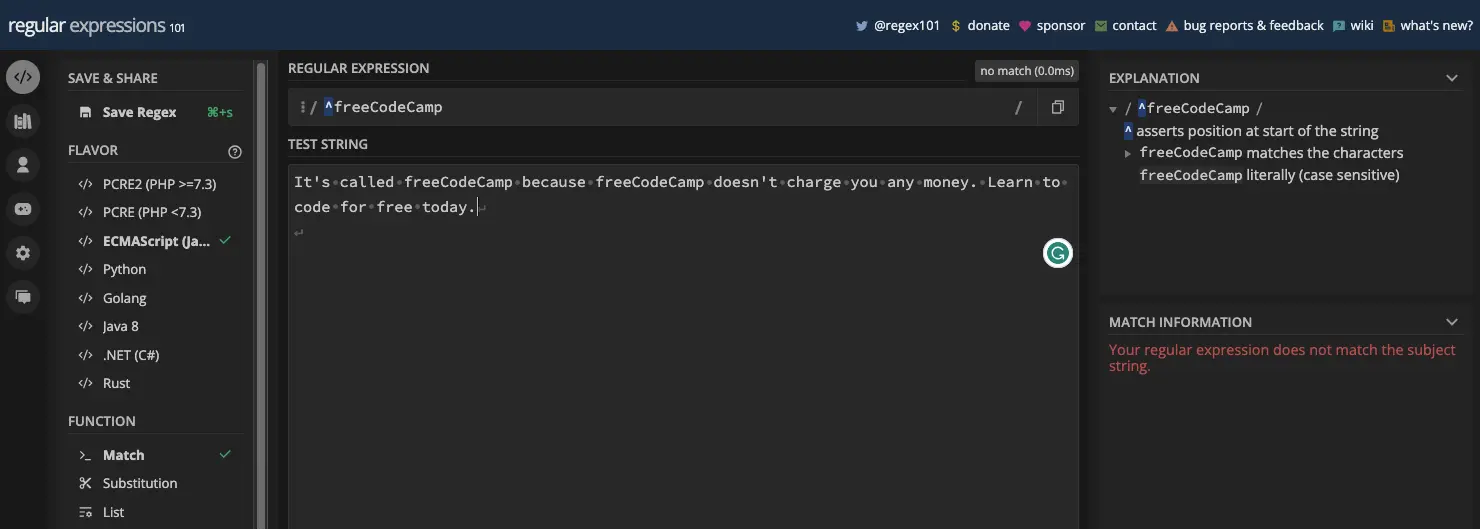
JavaScript 代码中存在以下两种情况:
const testStr =
"freeCodeCamp doesn't charge you any money. That's why it's called freeCodeCamp because. Learn to code for free today."; // has "freeCodeCamp" at the start of the line
const testStr2 =
"It's called freeCodeCamp because freeCodeCamp doesn't charge you any money. Learn to code for free today."; // does not have "freeCodeCamp" at the start of the line
const startAnchorRe = /^freeCodeCamp/;
console.log(startAnchorRe.test(testStr)); //true
console.log(startAnchorRe.test(testStr2)); //false
美元符号元字符与插入符号相反。它将正则表达式模式锚定到行或字符串的末尾。因此,只有当目标文本位于行尾时才会匹配。
要使用 $ 元字符,它必须是模式中的最后一个字符:
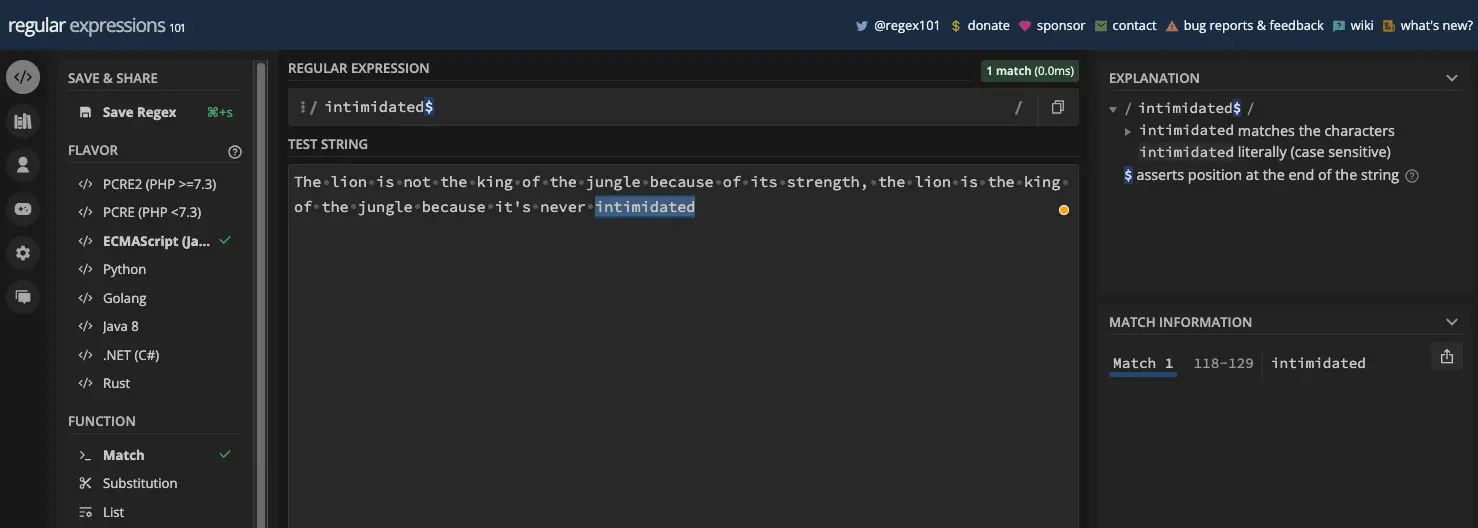
如果目标字符串有多于一行并且目标文本位于每一行的末尾,则最后一个匹配:
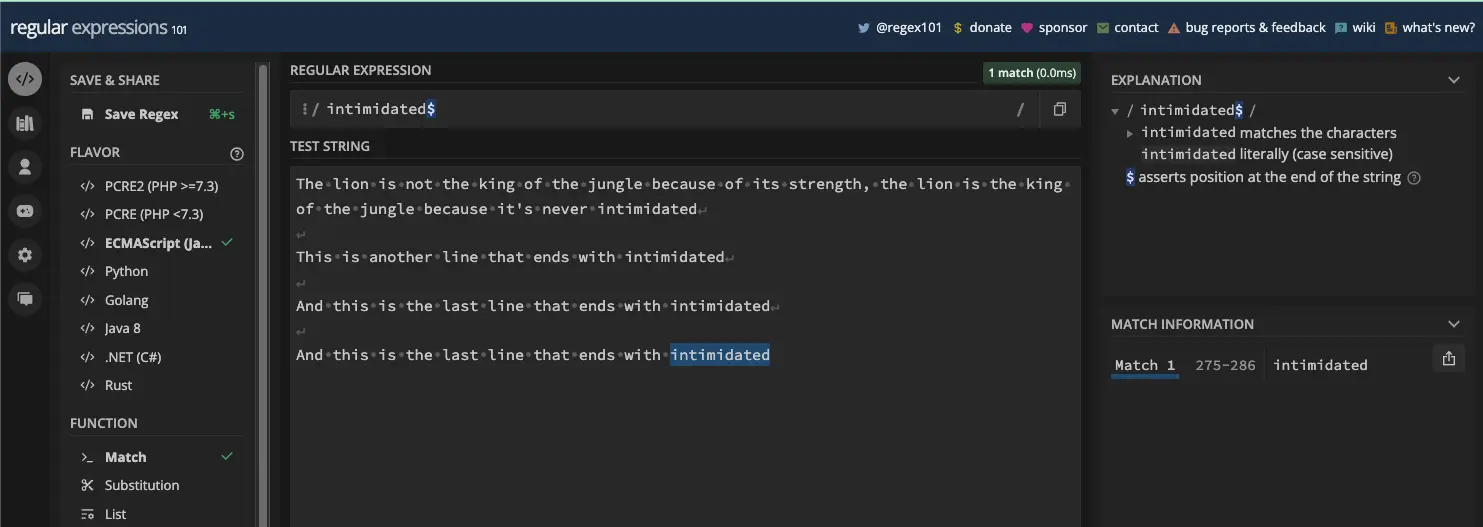
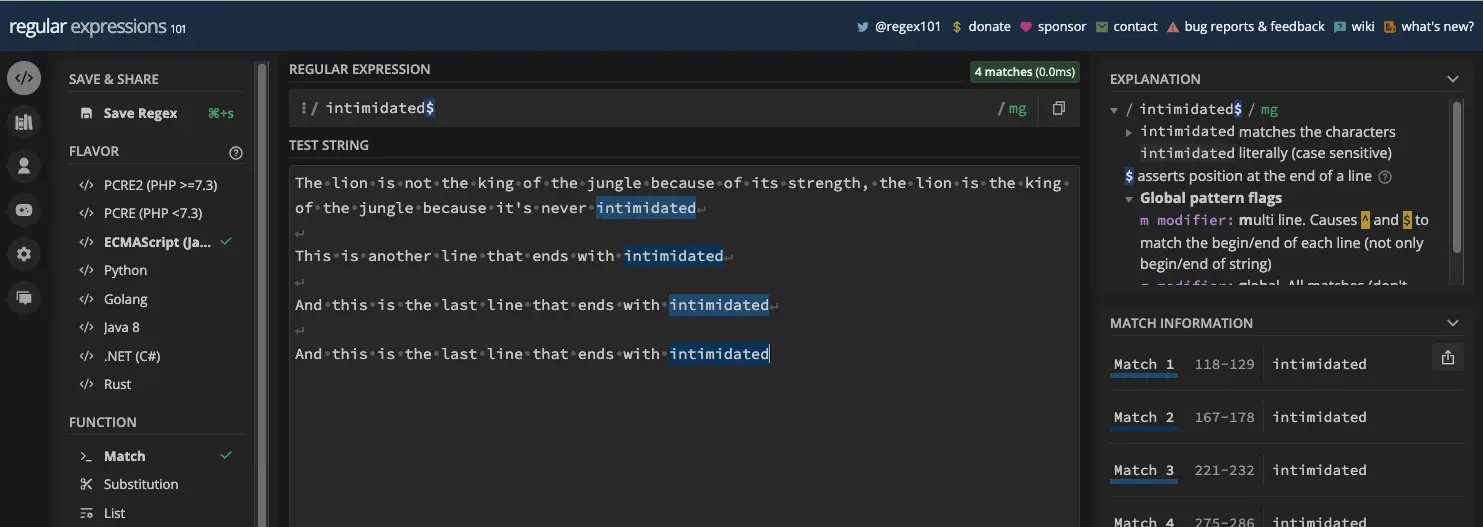
要纠正此行为,您必须同时使用 g 和 m 标志:
以下是 JavaScript 代码中的所有情况:
const testStr =
"The lion is not the king of the jungle because of its strength, the lion is the king of the jungle because it's never intimidated";
const testStr2 = `The lion is not the king of the jungle because of its strength, the lion is the king of the jungle because it's never intimidated
This is another line that ends with intimidated
And this is the last line that ends with intimidated
And this is the last line that ends with intimidated`;
const re = /intimidated$/;
const re2 = /intimidated$/gm;
console.log(re.test(testStr)); // true
console.log(re.test(testStr2)); // true
console.log(re2.test(testStr2)); // true
如果目标文本不在行尾,则不会有任何匹配:
const testStr =
"A lion can never be intimidated because it's the king of the jungle";
const re = /intimidated$/;
console.log(re.test(testStr)); // false
当您将美元和脱字符元字符与 g 和 m 标志一起使用时,它们不仅在行的开头和结尾处匹配,还会在开头查找匹配项以及每行的结尾:
//dollar with g and m flags
const testStr1 = `The lion is not the king of the jungle because of its strength, the lion is the king of the jungle because it's never intimidated
Another line with intimidated
And another line with intimidated`;
const re1 = /intimidated$/gm;
const matches1 = testStr1.match(re1);
console.log(matches1); // [ 'intimidated', 'intimidated', 'intimidated' ]
// caret with g and m flags
const testStr = `freeCodeCamp doesn't charge you any money. That's why it's called freeCodeCamp because. Learn to code for free today.
freeCodeCamp starts this line
freeCodeCamp starts this line too
`;
const re2 = /^freeCodeCamp/gm;
const matches2 = testStr.match(re2);
console.log(matches2); // [ 'freeCodeCamp', 'freeCodeCamp', 'freeCodeCamp' ]
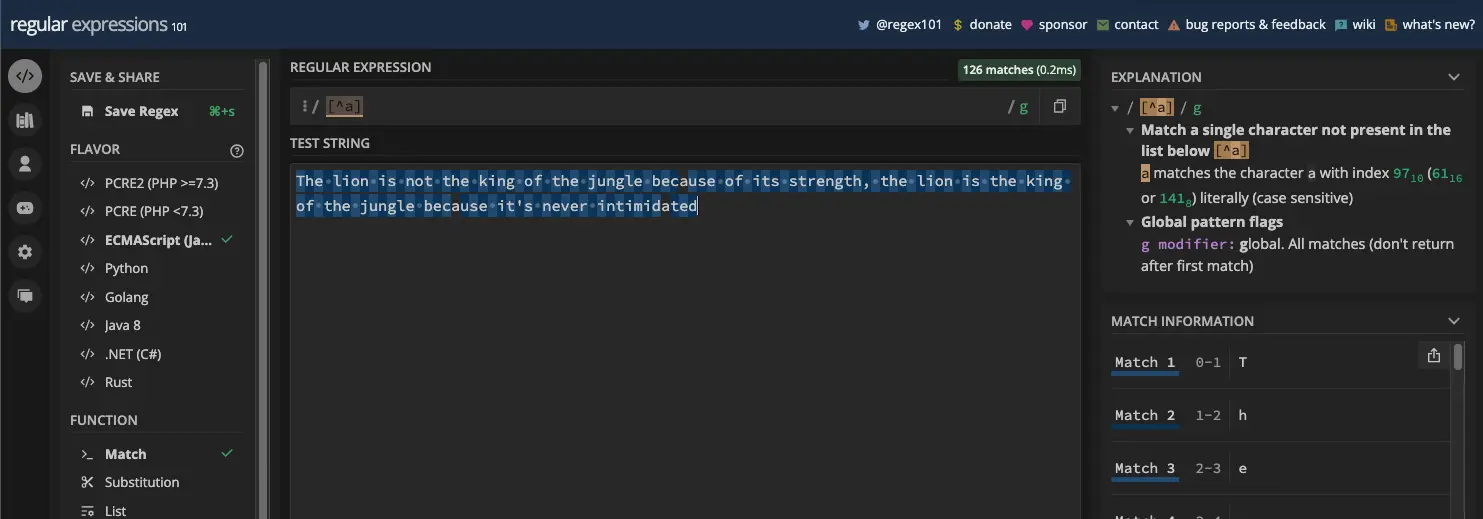
正如我之前指出的,脱字符号元字符通常用于否定字符集或任何其他字符。这样,您就可以告诉正在使用的正则表达式引擎不要匹配该字符或每个字符集。
例如,如果您有模式 [^a] ,则测试字符串中的所有字母“a”都不会作为匹配项返回:
如果您有模式 [^aeiou] ,则测试字符串中的所有元音都不会作为匹配项返回:
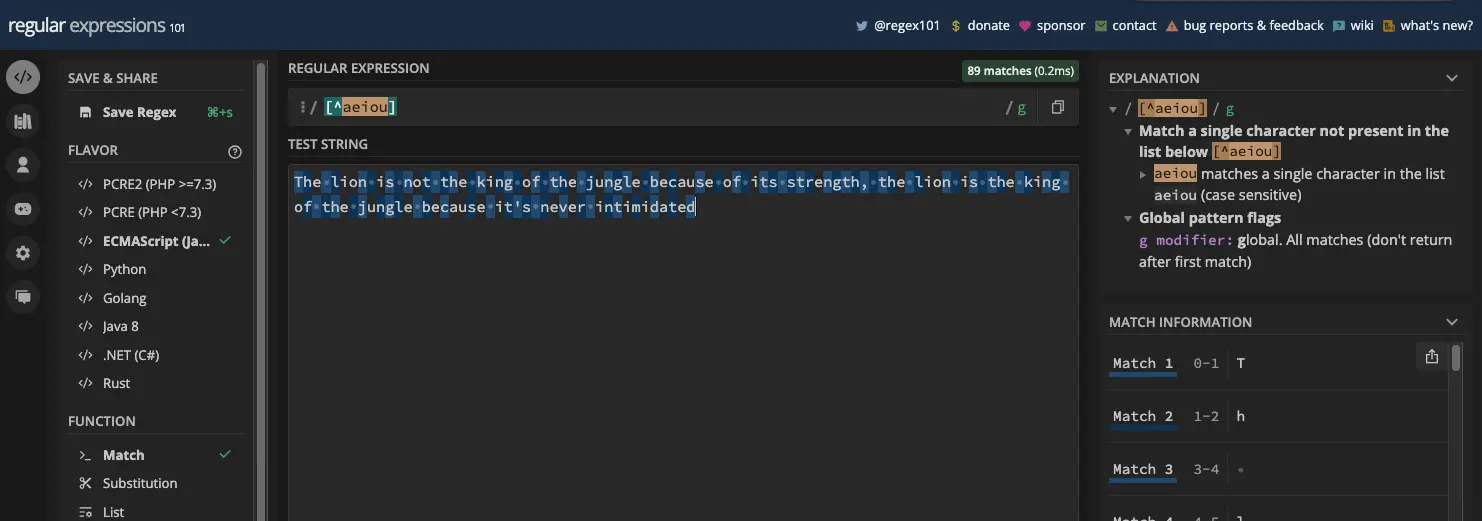
如果您有模式 [^a-zA-Z0-9_] ,则相当于非单词元字符 ( \W ):
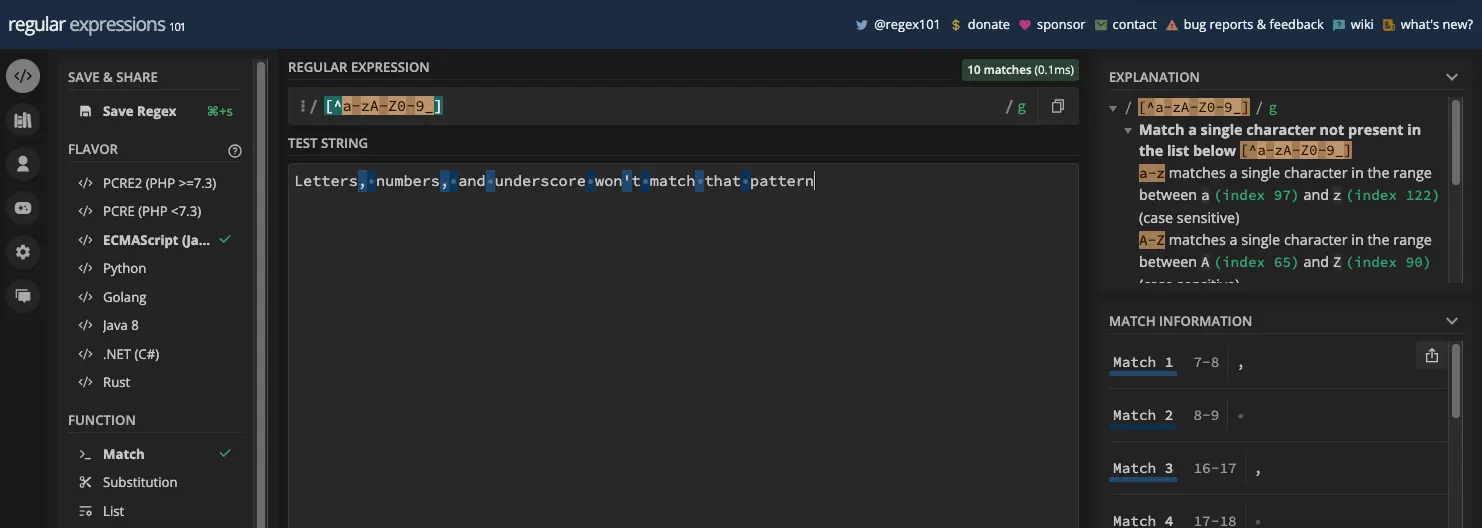
The Digit and Non-digit Metacharacters 数字和非数字元字符
数字元字符由 \d 表示。您可以使用 \D 对其取反,因此 \D 是非数字元字符。
\d 匹配所有数字(0 到 9),因此它是 [0-9] 的简写字符类。因此,如果您有一个字符串并且想要从中提取数字,则可以使用 \d 元字符。但是您必须将其与 g 标志一起使用,以便它匹配测试字符串中的每个数字:
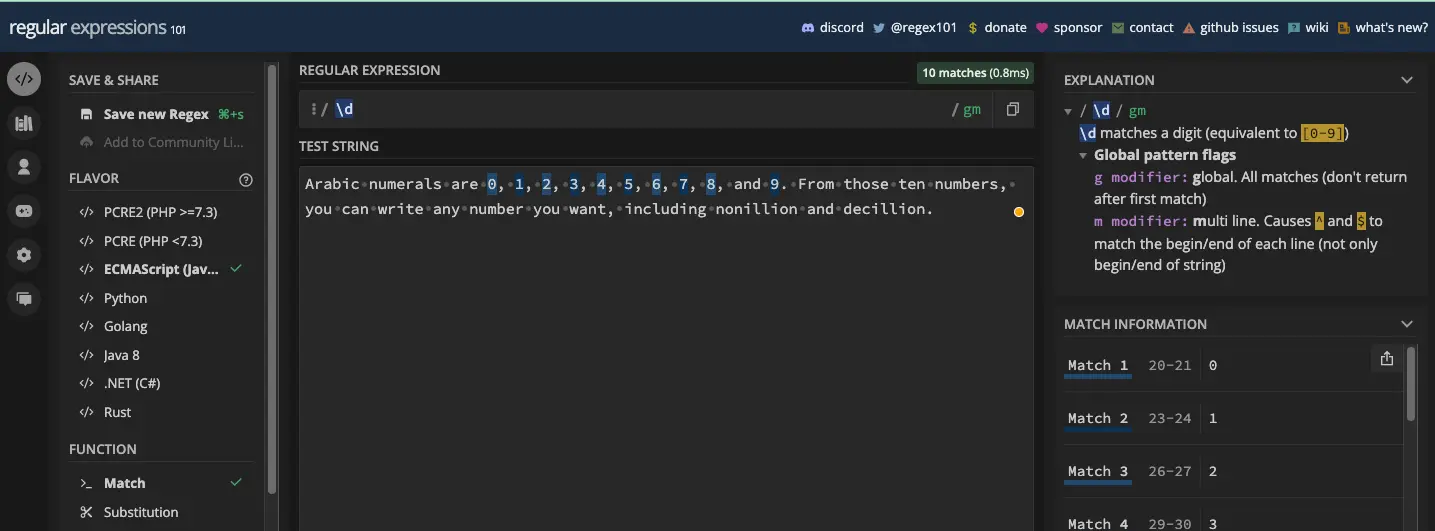
您也可以使用 match() 方法在 JavaScript 中提取数字:
const testStr =
'Arabic numerals are 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9. From those ten numbers, you can write any number you want, including nonillion and decillion.';
const re = /\d/g;
console.log(testStr.match(re));
/* output
[
'0', '1', '2', '3',
'4', '5', '6', '7',
'8', '9'
]
*/
一个更简单的例子是匹配日期,因为日期主要是数字。例如,如果您想匹配 dd/mm/yyyy 格式的日期,可以将其与模式 /\d\d/\d\d/\d\d\d\d/ 匹配:
const date = '22/04/2023';
const re = /\d\d/\d\d/\d\d\d\d/;
console.log(re.test(date)); // true
由于您还可以使用句点或连字符作为日期的分隔符,因此您也可以通过将所有可能的分隔符放入字符集中来解释这些分隔符:
const slashSeparatedSate = '22/04/2023';
const hyphenSeparatedDate = '22-04-2023';
const periodSeparatedDate = '22.04.2023';
const re = /\d\d[/.-]\d\d[/.-]\d\d\d\d/;
console.log(re.test(slashSeparatedSate)); // true
console.log(re.test(hyphenSeparatedDate)); // true
console.log(re.test(periodSeparatedDate)); // true
注意:上面的模式匹配一个日期,但也匹配一个无效日期,如 99/45/2022 。正则表达式的应用程序章节提供了一种更好的匹配日期的方法。
另一个例子是匹配电话号码。例如,美国电话号码的格式为 (123) 456-7890 。您可以使用模式 /(\d\d\d) \d\d\d-\d\d\d\d/ :
const USPhone = '(123) 456-7890';
const re = /(\d\d\d) \d\d\d-\d\d\d\d/;
console.log(re.test(USPhone)); // true
非数字元字符与数字元字符相反。它匹配所有非数字字符。即字母、空格和符号。换句话说,它是 [^0-9] 的简写字符类。
如果要提取字符串中的所有非数字字符,可以使用 \D 元字符: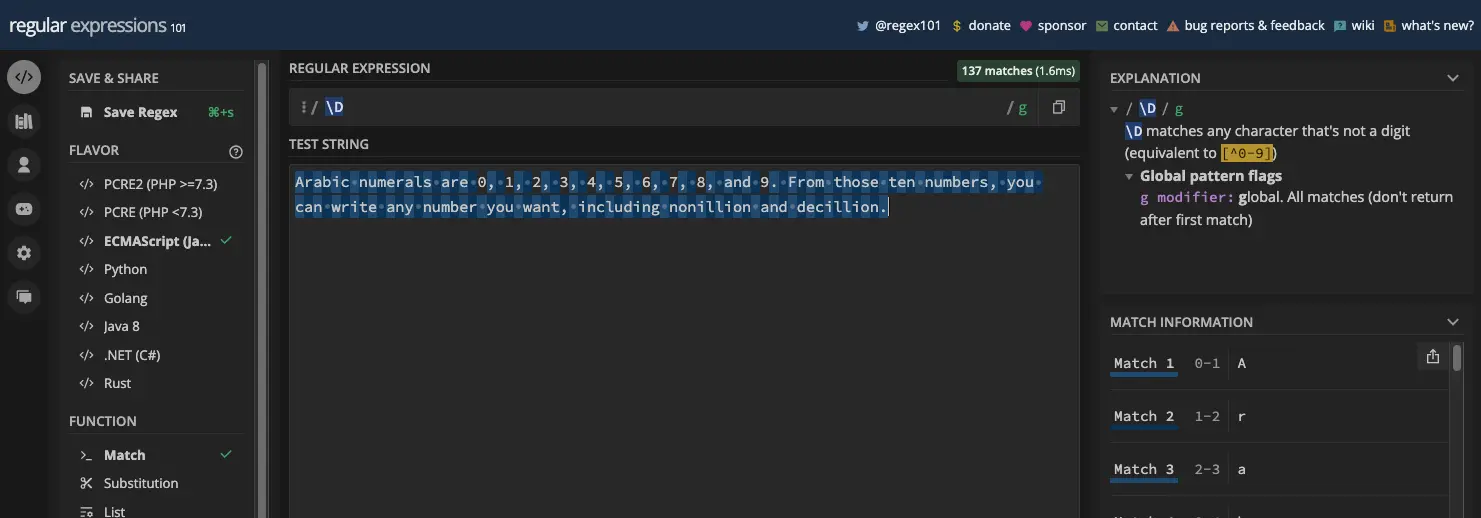
这是 JavaScript 代码:
const testStr =
'Arabic numerals are 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9. From those ten numbers, you can write any number you want, including nonillion and decillion.';
const re = /\D/g;
console.log(testStr.match(re));
/* output
A total of 137 matches is too much to show here, but you can test it out yourself.
*/
The Square Brackets Metacharacter 方括号元字符
您已经看到了方括号 ( [] ) 元字符的作用。方括号用于指定字符类或字符集。如果您想将它们作为文字字符进行匹配,那么您必须对它们进行转义。
需要记住的一件事是,某些元字符在字符集中会失去其含义。例外情况是:
- 插入符号 (
^) 可用于否定字符集 - 您可以使用连字符 (
-) 指定范围
注意:有时,您可能会遇到必须转义字符集中的某些元字符的情况。
如果要匹配字符集中的任何这些字符,则必须对其进行转义。如果您只是直接传递这三个字符,并且插入符号不是第一个字符,则无需转义它们。
const testStr =
'If you want to match the caret (^), hyphen and (-) symbols in a character set, you might not have to escape them.';
const re = /[-^]/g;
console.log(testStr.match(re)); // [ '^', '-' ]
但是,如果插入符号是字符集中与某些单词和非单词字符并列的第一个字符,则应该对其进行转义,否则它将否定所有其他字符:
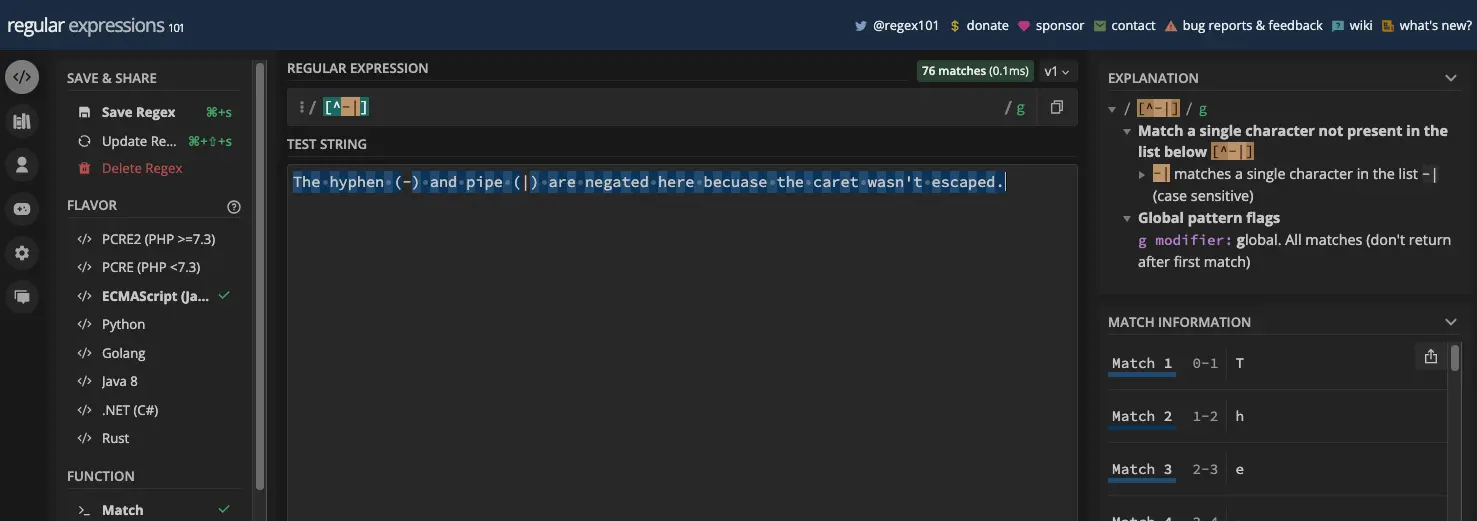
The Word Boundary and Non-word Boundary Metacharacters 词边界和非词边界元字符
字边界元字符由 \b 表示,非字边界元字符由 \B 表示。两者都允许您匹配字符串中存在单词字符和非单词字符的特定部分。
单词边界 ( \b ) 匹配单词字符 ( \w ) 和非单词字符 ( \W ) 之间的位置,反之亦然。当您想要匹配字符串中的某个单词,或者想要确保特定单词或字符在字符串中时,它会很有用。
Here’s an example in a regex tester:
这是正则表达式测试器中的示例:
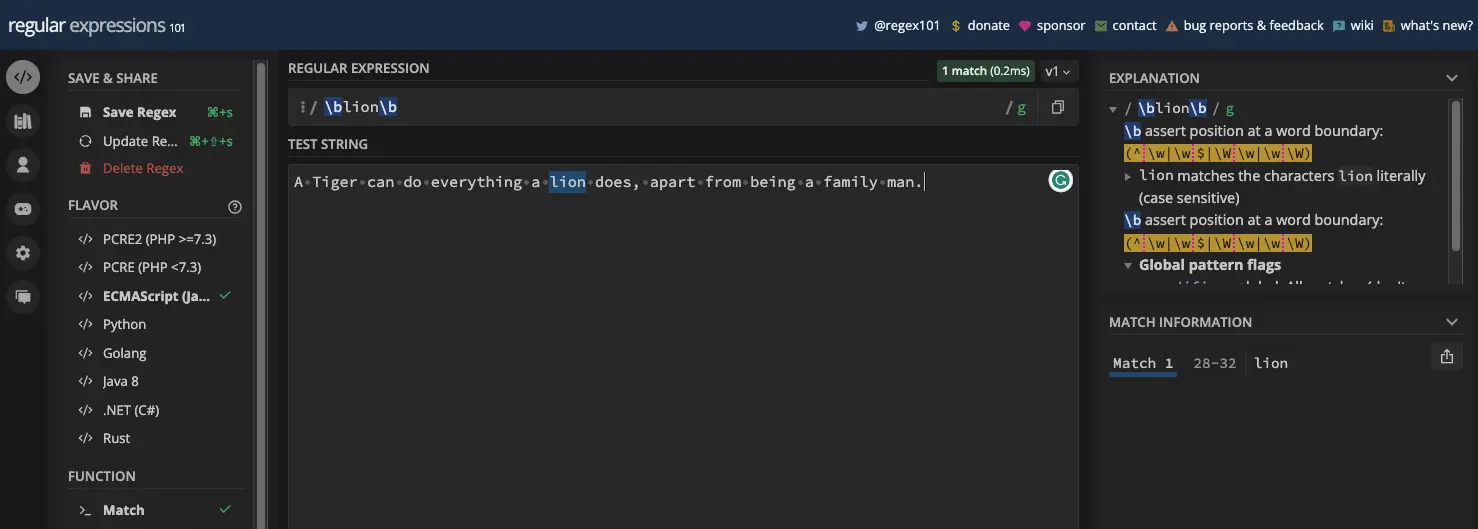
JavaScript 代码中的相同示例:
const myStr =
'A Tiger can do everything a lion does, apart from being a family man.';
const re = /\blion\b/;
console.log(myStr.match(re));
/*
Output:
[
'lion',
index: 28,
input: 'A Tiger can do everything a lion does, apart from being a family man.',
groups: undefined
]
*/
如果您将 g 标志与模式一起使用并使用 match() 方法,则将返回所有匹配项 – 正如预期的那样:
const myStr =
'A Tiger can do everything a lion does, apart from being a family man. Not even a tiger can intimidate a lion within his family.';
const re = /\blion\b/g;
console.log(myStr.match(re)); // [ 'lion', 'lion' ]
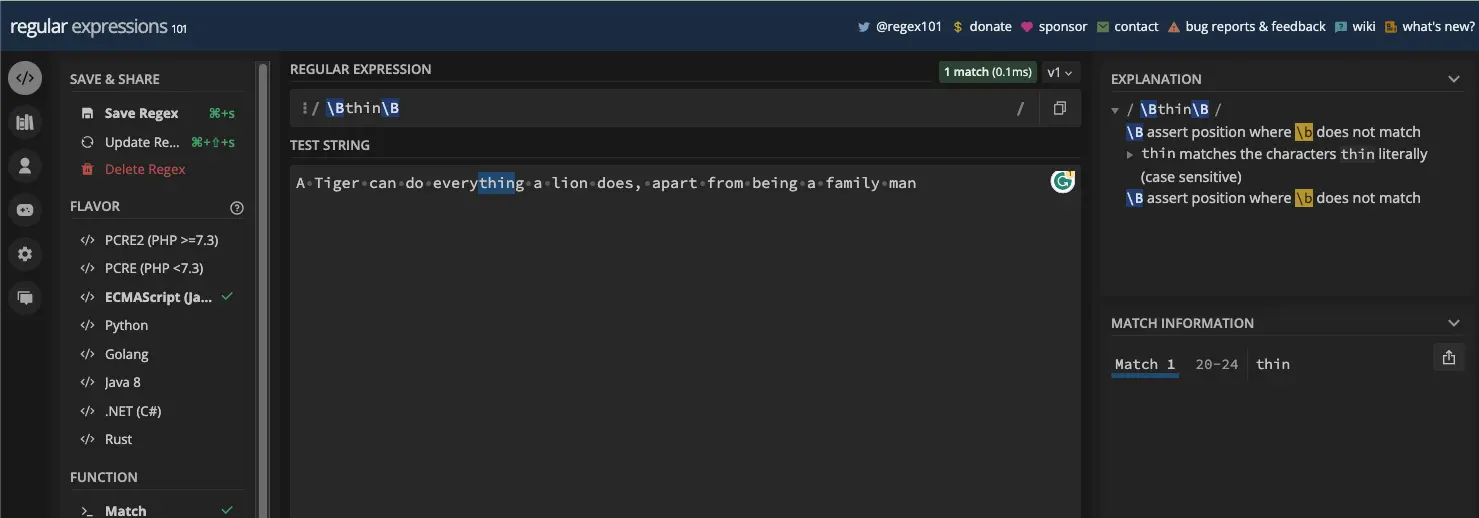
另一方面,非单词边界 ( \B ) 与单词边界 ( \b ) 相反。因此,它会匹配单词边界不会返回匹配项的所有位置。例如“一切”中的“薄”:
当您使用不区分大小写( i )标志时,还有“freeCodeCamp”中的“代码”:
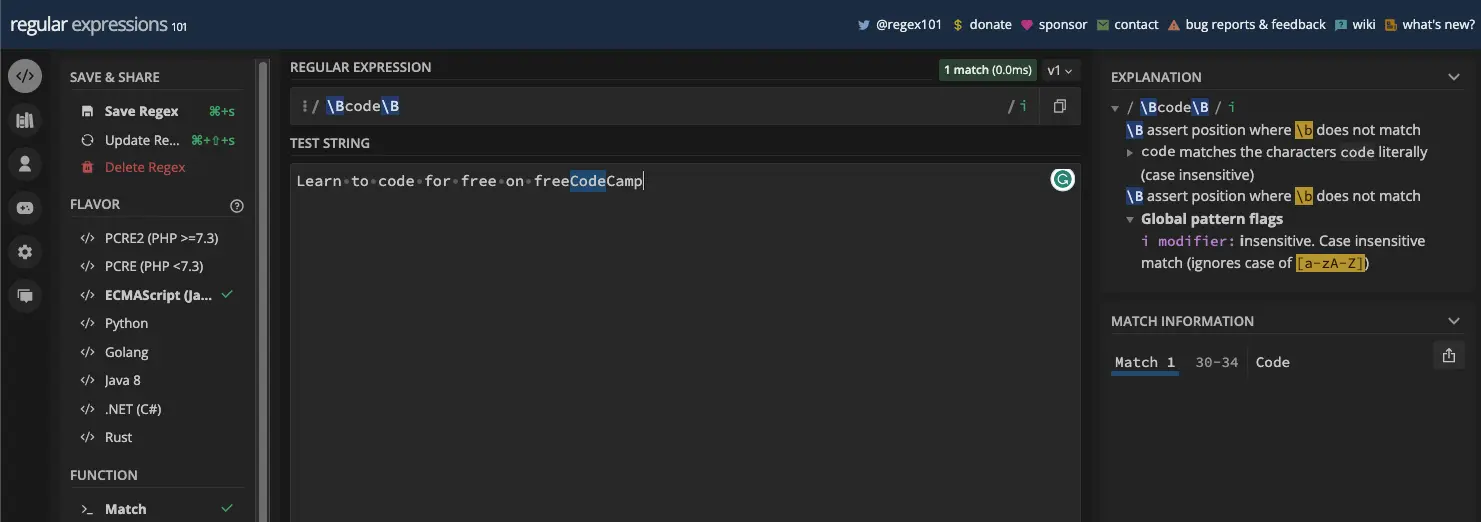
您可以看到文本中的第一个“代码”不是返回的匹配项。这就是单词和非单词边界元字符的力量。
以下是两者在 JavaScript 代码中揭示的内容:
const myStr1 =
'A Tiger can do everything a lion does, apart from being a family man.';
const myStr2 = 'Learn to code for free on freeCodeCamp.';
const re1 = /\Bthin\B/;
const re2 = /\Bcode\B/i;
console.log(myStr1.match(re1));
console.log(myStr2.match(re2));
/*
Output:
[
'thin',
index: 20,
input: 'A Tiger can do everything a lion does, apart from being a family man.',
groups: undefined
]
[
'Code',
index: 30,
input: 'Learn to code for free on freeCodeCamp.',
groups: undefined
]
*/
The Parenthesis Metacharacter 括号元字符
括号元字符( ( 和 ) )允许您创建分组和捕获。使用它们,您可以将任何字符组视为一个单元,并对它们应用通用修饰符或量词。
括号还用于创建前向断言和后向断言。
创建组和断言时,您可以稍后使用反斜杠和它们出现的顺序以相同的模式引用它们。例如,您可以通过在模式中指定 \1 来引用第一组。
在本书中,有一整章专门讨论分组和捕获。在那里,您将了解有关分组和捕获的更多信息,以便您可以看到括号元字符的作用。
The Space and Non-space Metacharacters 空间和非空间元字符
如果没有空格,文本就不可能有意义。不仅仅是“空格”,还包括其他空格字符,例如制表符、回车符和换行符。这就是正则表达式中提供空格和非空格元字符的原因。
空格元字符由 \s 表示,非空格元字符由 \S 表示。
\s 匹配所有空格字符:
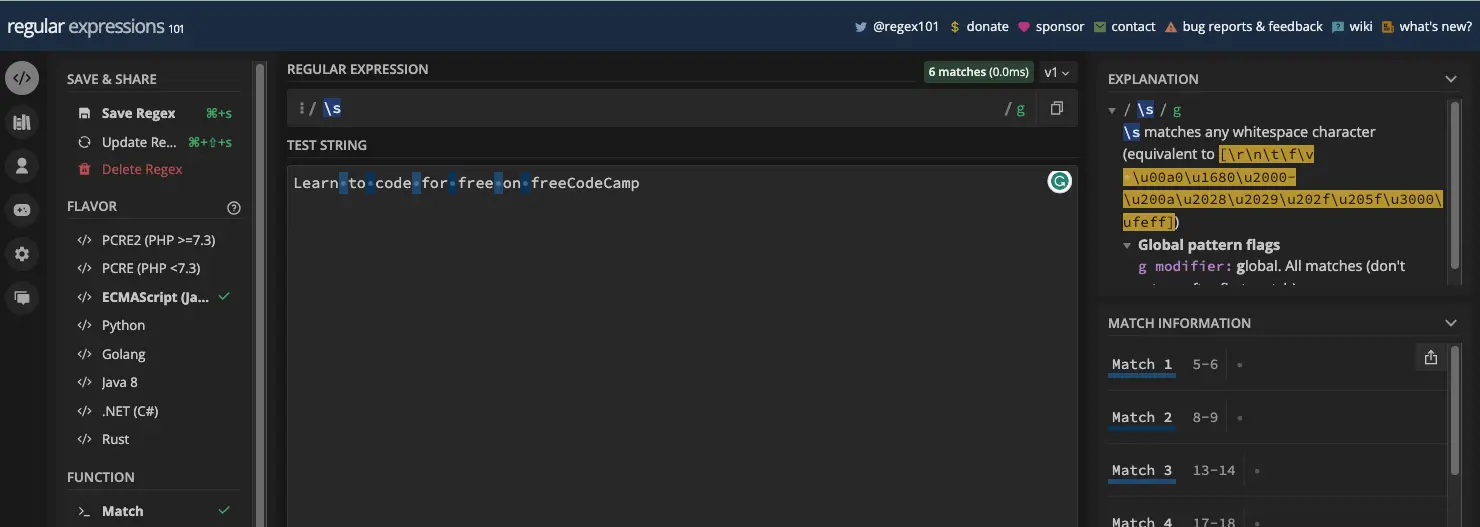
并且 \S 匹配所有非空格元字符:
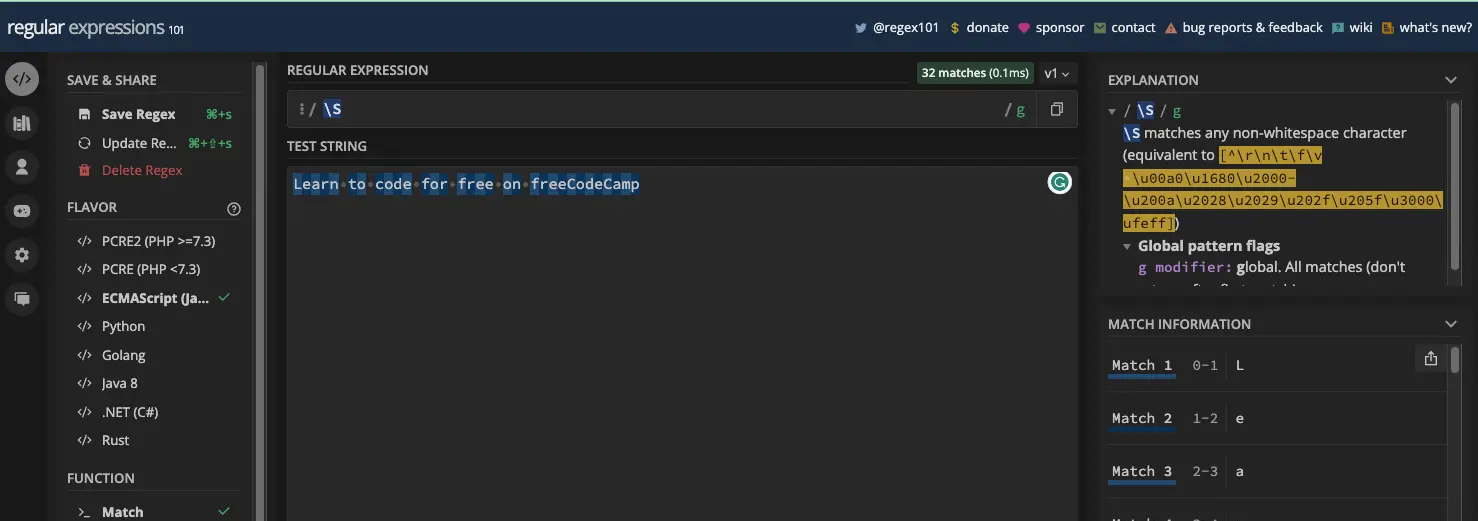
以下是 \s 和 \S 元字符在 JavaScript 代码中的工作方式:
const myStr = 'Learn to code for free on freeCodeCamp';
const spaceRe = /\s/g;
const nonSpaceRe = /\S/g;
console.log(myStr.match(spaceRe)); // [' ', ' ', ' ', ' ', ' ', ' '];
console.log(myStr.match(nonSpaceRe));
// [
// 'L', 'e', 'a', 'r', 'n', 't',
// 'o', 'c', 'o', 'd', 'e', 'f',
// 'o', 'r', 'f', 'r', 'e', 'e',
// 'o', 'n', 'f', 'r', 'e', 'e',
// 'C', 'o', 'd', 'e', 'C', 'a',
// 'm', 'p'
// ]
在 JavaScript 中,您可以使用 \s 做的一件很酷的事情就是用连字符或任何其他您想要的东西替换所有空格:
const myStr = 'Learn to code for free on freeCodeCamp';
const replaceHyphen = myStr.replace(spaceRe, '-');
console.log(replaceHyphen); // Learn-to-code-for-free-on-freeCodeCamp
空格元字符不仅仅与您在设备键盘上按的空格键匹配。它还匹配:
- 制表符
- 一个回车符
- 换行符
- 垂直制表符
- 换页符
这是一个例子:
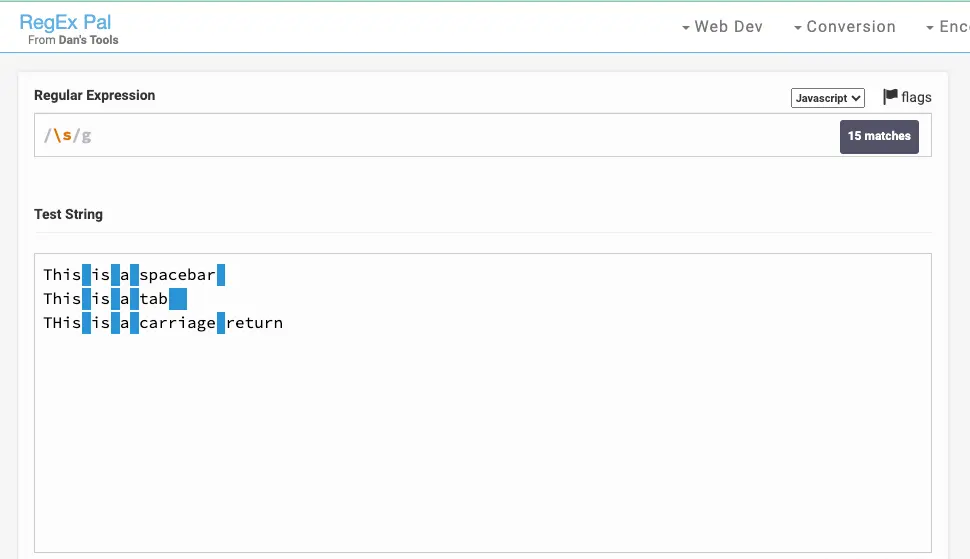
您看不到回车符的匹配项,但它就在那里:
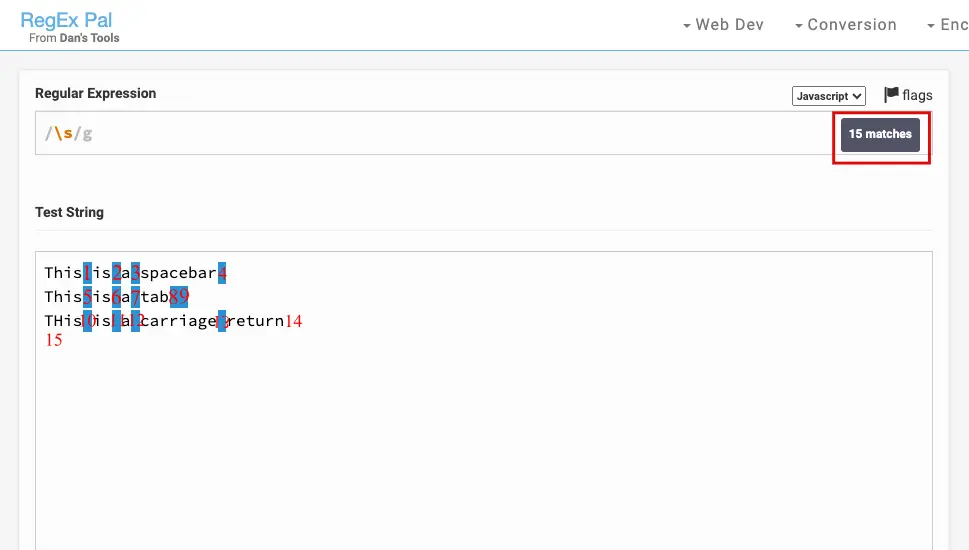
如果您想匹配每个空格字符,它们也有其独特的元字符:
\t用于选项卡\r用于回车\n用于新行\v用于垂直制表符\f用于换页。
您应该知道,大多数时候, \s 就是您所需要的,因为它可以匹配任何空格字符。
The Pipe Metacharacter 管道元字符
管道元字符也称为 OR 运算符,由管道符号 ( | ) 表示。它允许您指定多个匹配选项。
竖线与其前面的字符或后面的字符匹配。例如,如果您将 website|web\sapp 作为模式,则 website 和 web app 之一或两者将作为匹配项返回:
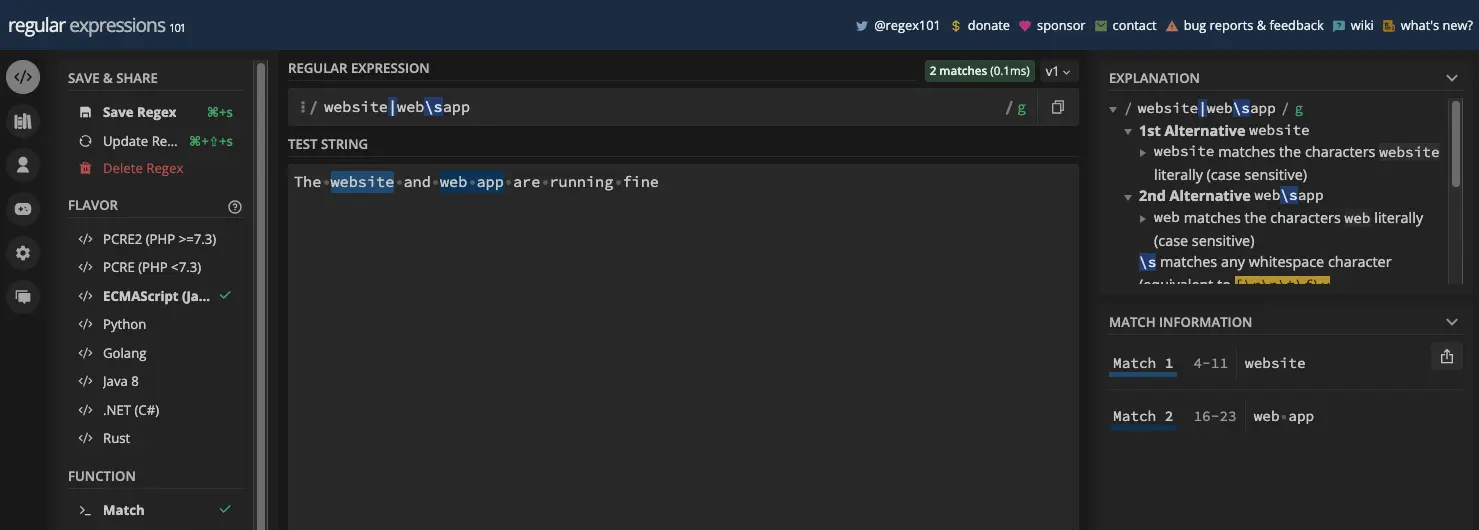
评价从左到右进行。如果在左侧找到匹配项,则返回该匹配项。如果左侧没有匹配项,则会评估右侧的字符是否有可能匹配。如果左侧和右侧的字符都在测试字符串中,则两者都作为匹配项返回。
您还可以使用两个以上的字符,并用管道符号分隔。例如,模式 /o|a|i|re/ 将匹配 o 、 a 、 i 和 re :
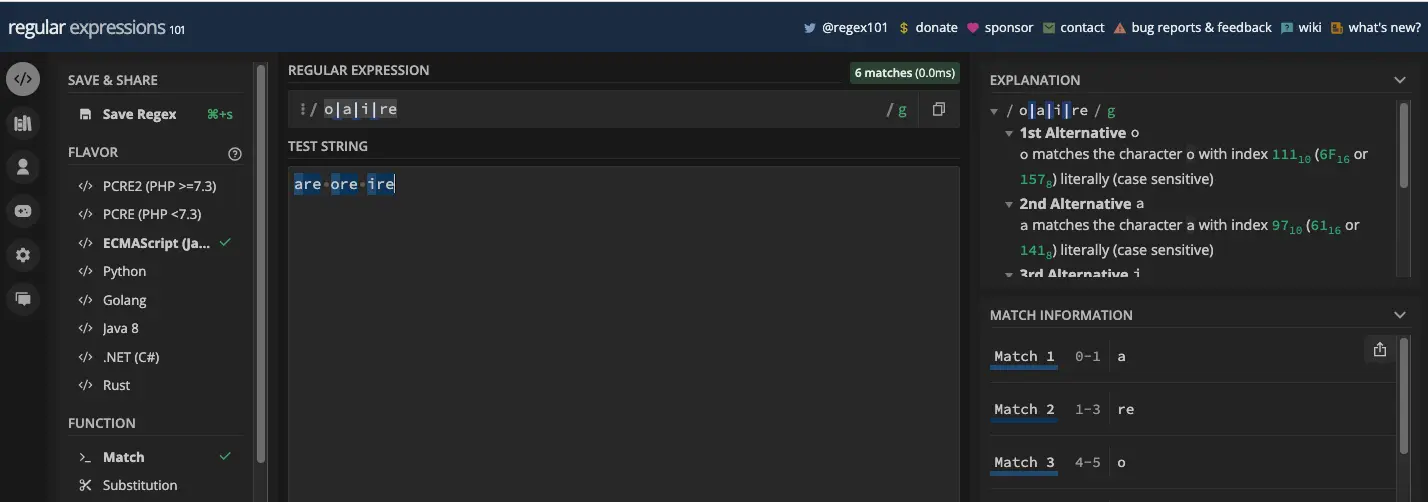
您可以用它分隔的字符没有限制。
您可以看到我在这些示例中使用了 g 标志。如果不使用 g 标志并且左右字符都匹配,则仅返回测试字符串中的第一个匹配项:
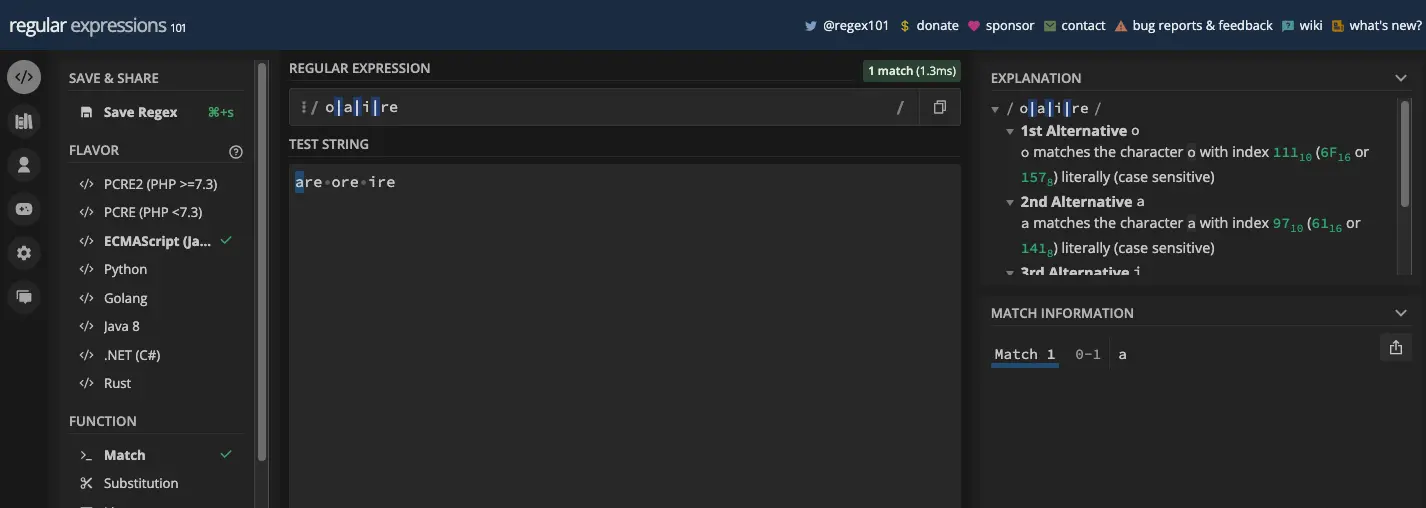
这是一个更清楚的例子:
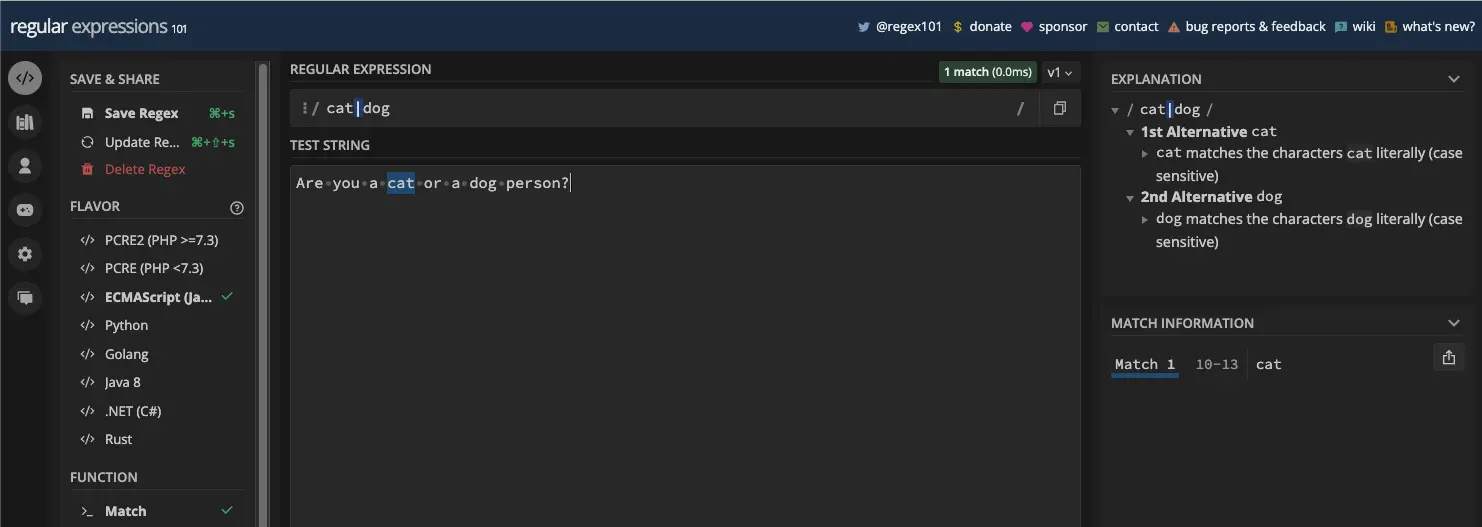
以下是在代码中使用 OR 运算符与 g 标志的方式:
const myStr = 'The website and web app are running fine';
const re = /website|web\sapp/g;
console.log(myStr.match(re)); // returns [ 'website', 'web app' ] because of the g flag
以下是没有 g 标志时它的工作原理:
const myStr = 'The website and web app are running fine';
const re = /website|web\sapp/;
const matches = myStr.match(re);
for (const match of matches) {
console.log(match); // returns "website" and ignores web app because there's no g flag
}
How to Match Repeated Characters With Quantifiers 如何将重复字符与量词匹配
当同一字符连续出现在多个数字中时,就会出现重复字符。
当测试字符串中有重复的字符时,您不需要在模式中重复特定字符来匹配它。这是因为有元字符可用于一个或多个匹配、零个或多个匹配以及零个或一个匹配(又称可选匹配)。
One or More Matches with the Addition Sign Metacharacter 与加法符号元字符的一个或多个匹配
您可以猜到,加号元字符用加号 ( + ) 表示。您也可以将其称为“一个或多个量词”。
如果您希望某个特定字符重复一次或多次,这就是加号元字符的作用。
例如,模式 /fe+d/ 将匹配包含一个字母 e 或连续出现的多个字母 e 的任何单词。例如, fed 和 feed :
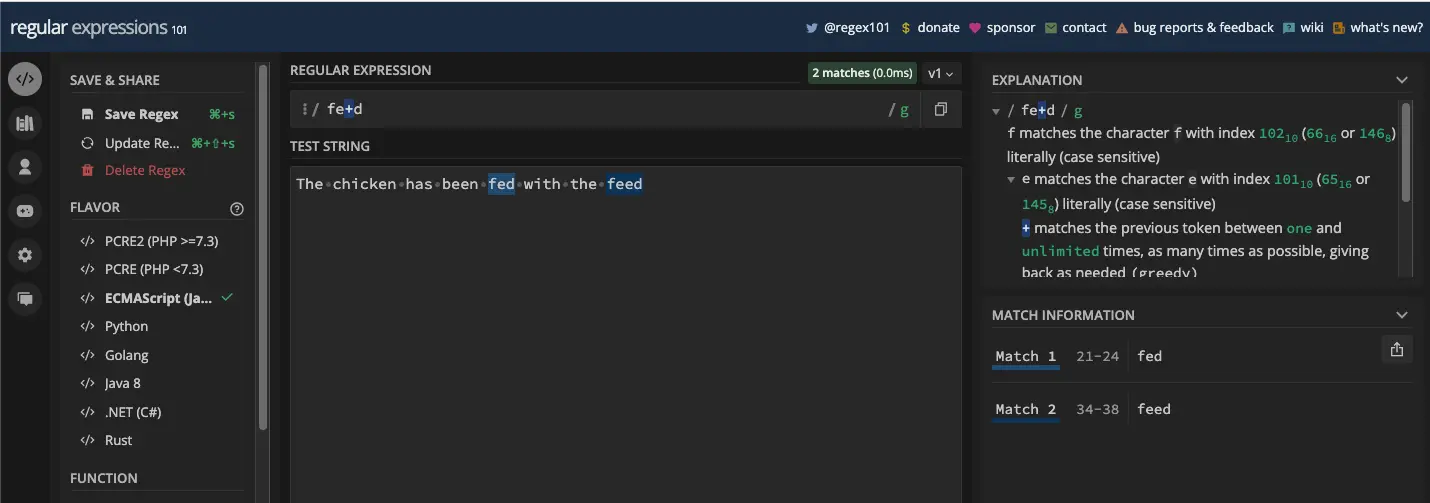
JavaScript 中的一个实际示例是提取测试字符串中的元音,同时通过确保还返回多个相继的元音来限制出现次数:
const myStr = 'You should plant trees to save mother earth';
const re = /[aeiou]+/gi;
console.log(myStr.match(re));
/*
Output:
[
'ou', 'ou', 'a',
'ee', 'o', 'a',
'e', 'o', 'e',
'ea'
]
*/
您还可以将加号元字符附加到其他元字符。例如,/\d+/ 将匹配一位或多位数字:
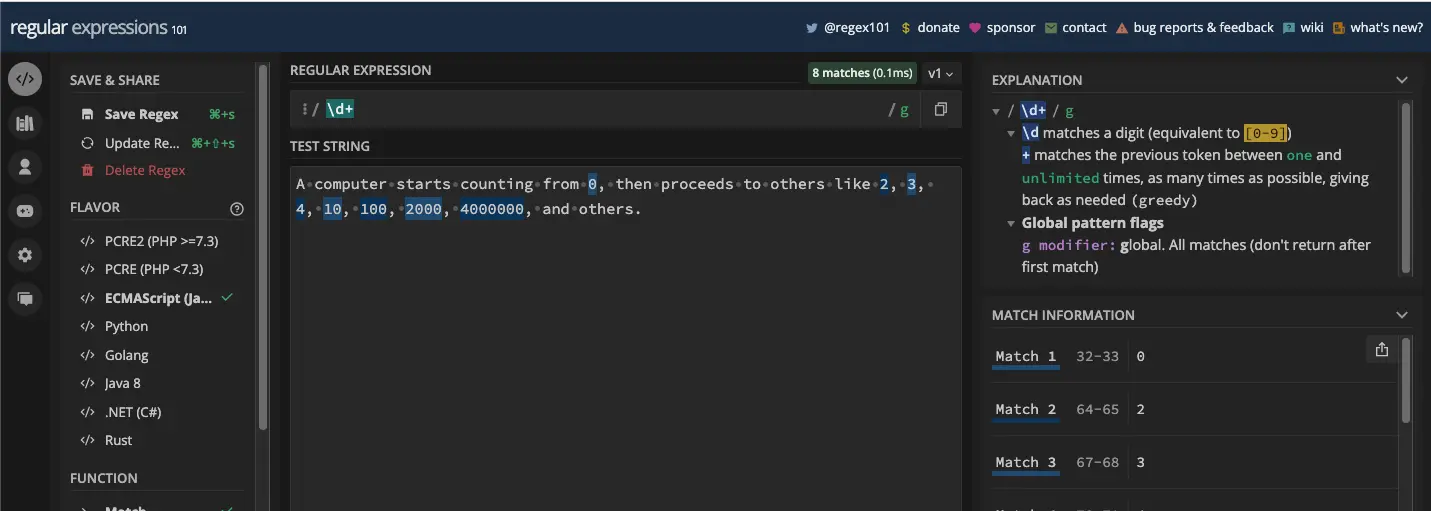
您还可以将 + 元字符添加到字符集中以重复一次或多次。在下面的屏幕截图中,模式 /f[a-z]+/ 将匹配一个或多个字母 f 后跟任何一组小写字母:
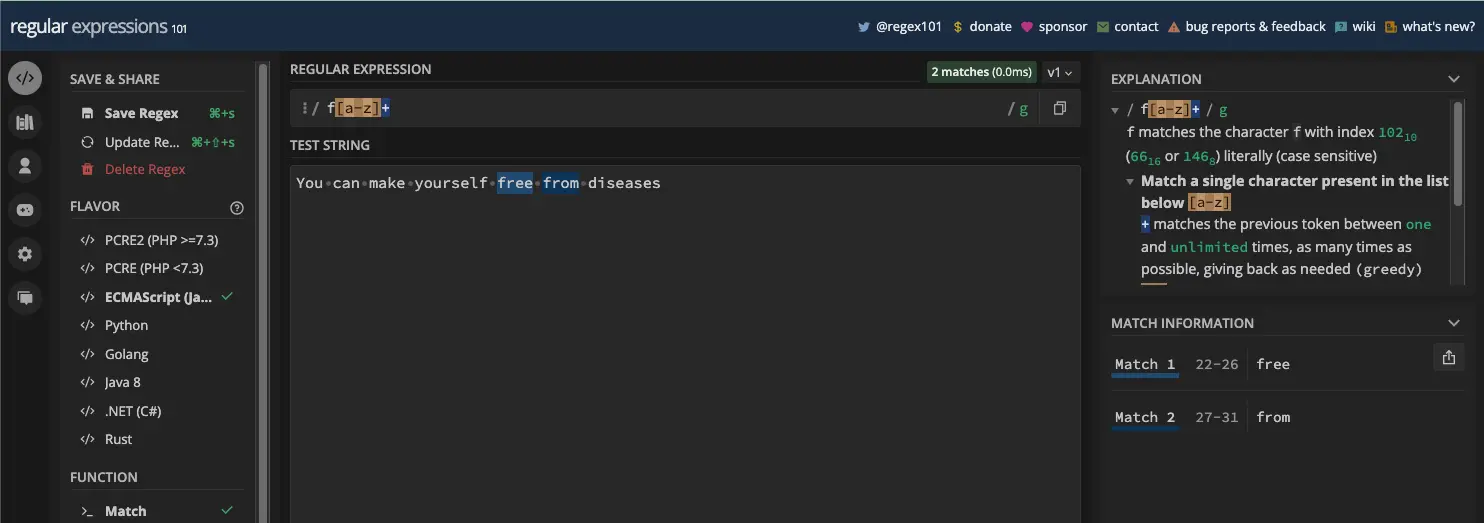
Zero or More Matches with the Asterisk Metacharacter 与星号元字符的零个或多个匹配
星号元字符 ( * ) 与其后的字符匹配零次或多次出现。您也可以将其称为“零个或多个量词”。
因此,如果您希望某个字符重复零次或多次,可以使用星号元字符。一个基本的示例是使用模式 /go*d/ 将匹配以字母 g 开头、后跟任意数量的字母 o 并以字母结尾的任何单词 d :
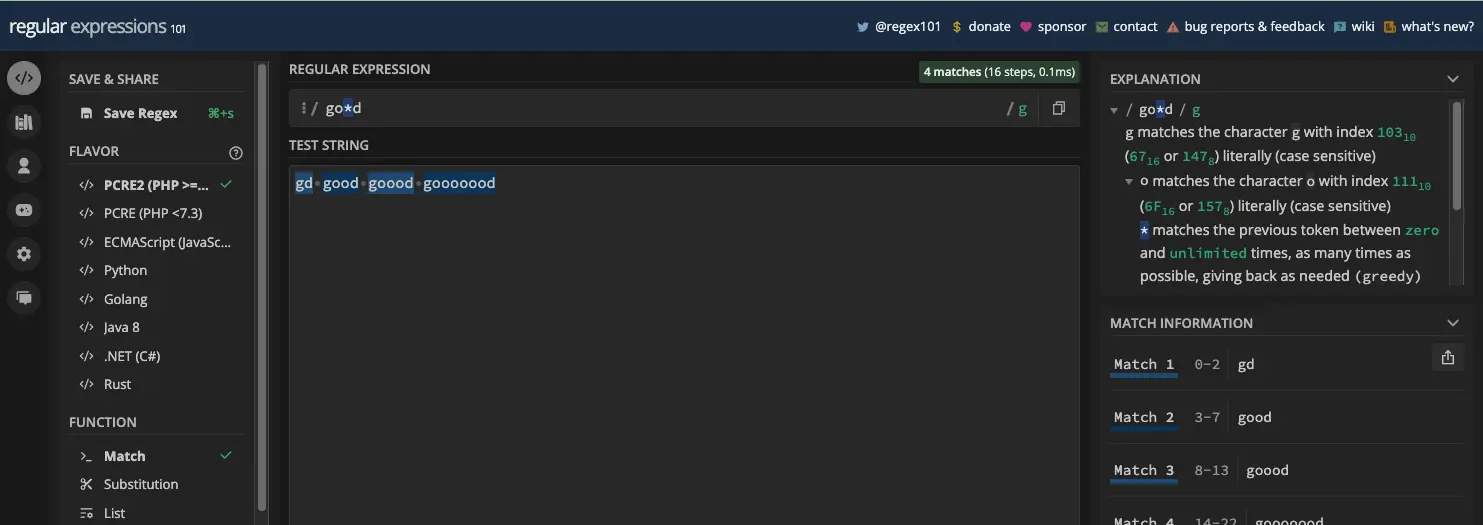
就像使用加号元字符一样,您也可以将星号元字符附加到任何其他元字符。例如,您可以将空字符串与模式 /\s*/ 匹配:
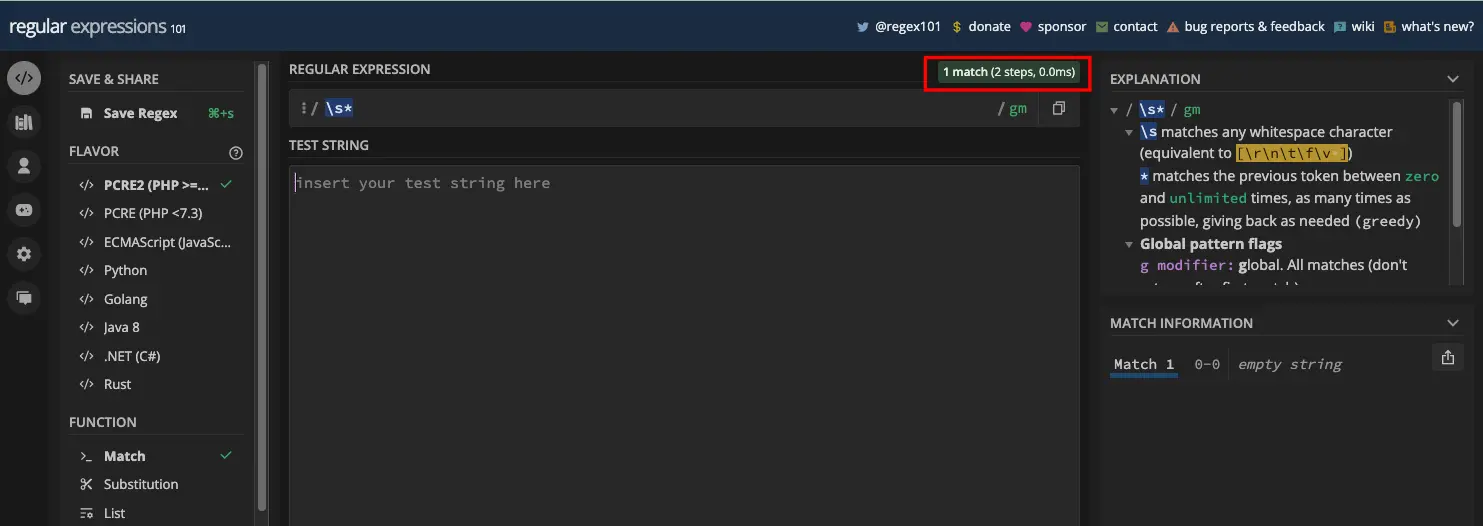
对此表示怀疑?这是 JavaScript 代码:
const re = /\s*/;
const emptyString = '';
console.log(re.test(emptyString)); // true
直到我读到书中的这一点之前,我才知道匹配空字符串是如此简单!
同样,与加号元字符一样,您也可以将 * 元字符添加到字符集中以重复零次或多次:
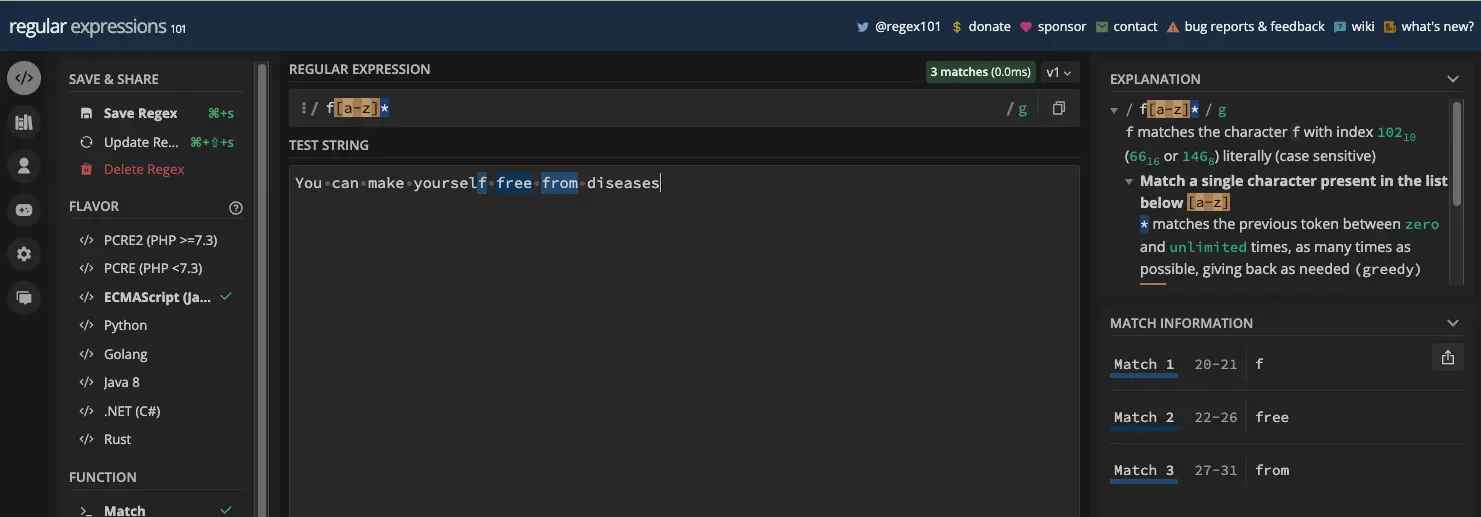
JavaScript 代码中也有同样的事情:
const myStr = 'You can make yourself free from diseases';
const re = /f[a-z]*/g;
console.log(myStr.match(re)); // [ 'f', 'free', 'from' ]
您可以看到单词 yourself 中的 f 甚至也是匹配的。这是推断星号 ( * ) 比加法符号 ( + ) 元字符返回更多匹配项的一种方法,因为它更贪婪。您将在本章的最后部分了解正则表达式的贪婪性。
Zero or One Matches with the Question Mark Metacharacter 与问号元字符的零个或一个匹配
问号元字符 ( ? ) 也称为零或一量词。它允许您将其前面的字符设为可选,因此它在防止贪婪方面发挥着重要作用。
例如,模式 /ab?c/ 将匹配 abc 和 ac ,但永远不会匹配 abbbc 或任何其他数字的 b 在 a 和 c 之间:
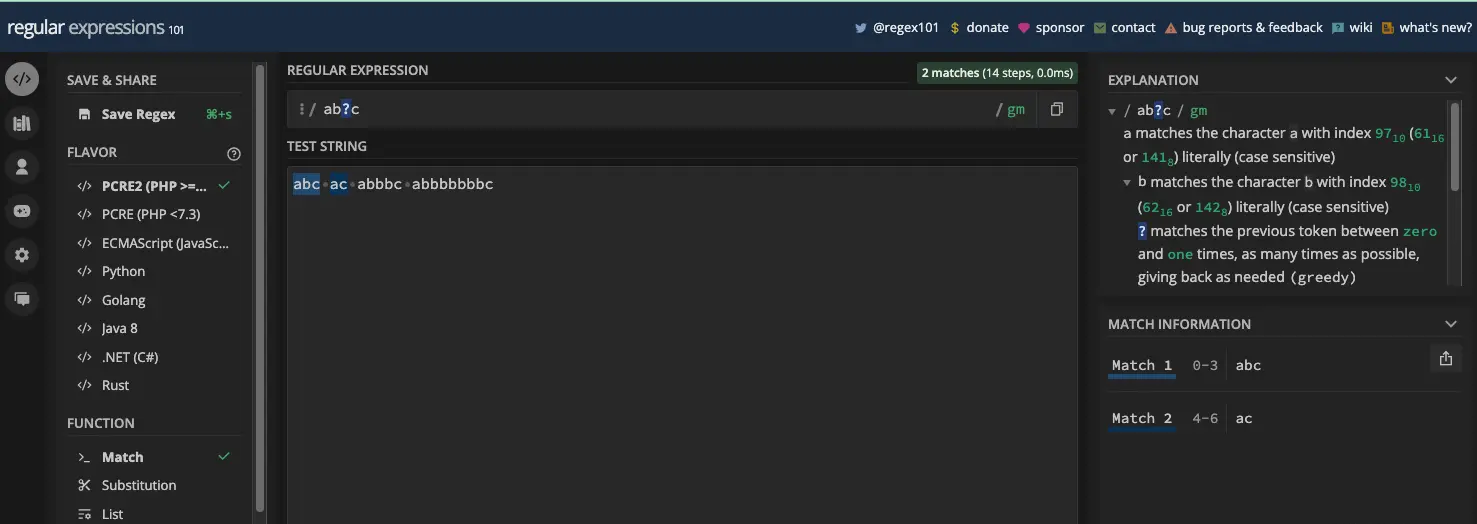
用于匹配重复字符的其他两个元字符( + 和 * )的情况并非如此。模式 /ab*c/ 将匹配所有 abc 、 ac 、 abbbc 和 abbbbbbbc ,而 /ab+c/ 将忽略ac:
const myStr = 'abc ac abbbc abbbbbbbc';
const re1 = /ab*c/g;
const re2 = /ab+c/g;
const re3 = /ab?c/g;
console.log(myStr.match(re1)); // [ 'abc', 'ac', 'abbbc', 'abbbbbbbc' ]
console.log(myStr.match(re2)); // [ 'abc', 'abbbc', 'abbbbbbbc' ]
console.log(myStr.match(re3)); // [ 'abc', 'ac' ]
一个更好的例子是定制正则表达式模式来匹配由于英式英语和美式英语的微小变化而具有不同拼写的单词。例如, color 和 colour :
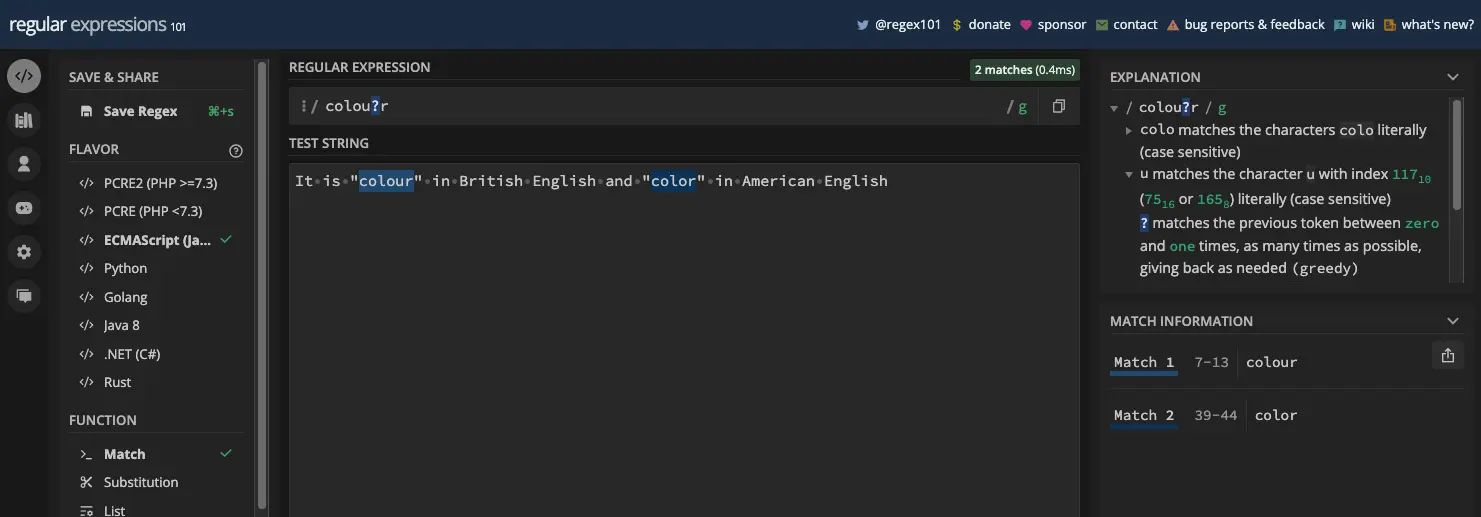
还有 centre 和 center :
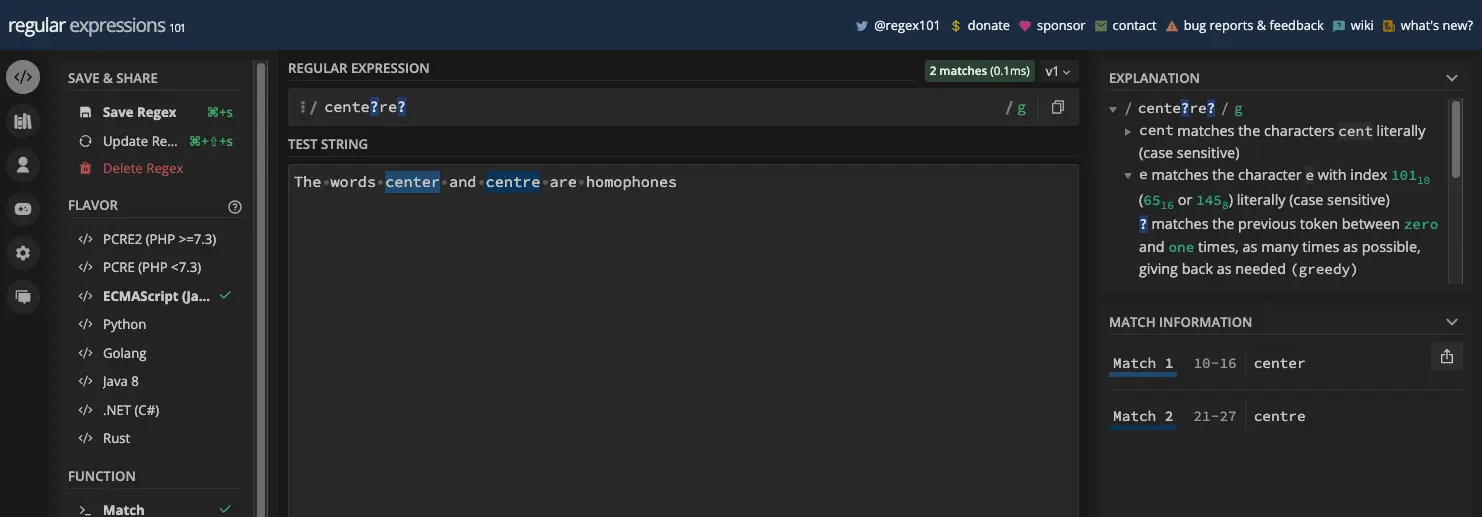
您可以在 JavaScript 中提取这些单词。您不能为此使用 match() 方法,因为它与 ? 元字符一起使用时会导致一些意外行为。
以下是我对 color 和 colour 执行此操作的方法:
const myStr = 'The words center and centre are homophones';
const re = /cente?re?/g;
let match;
const matches = [];
while ((match = re.exec(myStr)) !== null) {
matches.push(match[0]);
}
console.log(matches); // ["center", "centre"]
我使用相同的方法来提取 center 和 centre :
const myStr =
'It is "colour" in British English and "color" in American English';
const re = /colou?r/g;
let match;
const matches = [];
while ((match = re.exec(myStr)) !== null) {
matches.push(match[0]);
}
console.log(matches); // [ 'colour', 'color' ]
很多时候,知道在这三个元字符( * 、 + 和 ? 之间使用哪个字符重复是很困难的。如果您刚开始使用正则表达式,甚至可能很难习惯它们各自的作用。
请注意,识别它们并知道在它们之间使用哪个并不是一项艰巨的任务。关于他们三人,有以下几点需要注意:
- 星号 (
*) 表示“零个或多个”:如果您希望目标字符串中不出现某个字符或者希望同一字符出现多个,请使用它 - 加号 (
+) 表示“一个或多个”:如果您希望某个字符在目标字符串中出现一次或多次,请使用它 - 问号 (
?) 表示“零或一”:如果您希望目标字符串中的某个字符是可选的,请使用它。
How to Specify Match Quantity with the Curly Braces Metacharacter 如何使用大括号元字符指定匹配数量
量词允许您使用大括号 ( {} } 指示模式中前导字符的数量或频率。使用这些大括号,您可以指定精确量词、最小量词和范围量词。
The Range Quantifier 范围量词
范围量词的一般语法如下所示:
char{n1,n2}
-
cha是您要应用量词的任何字符 -
n1是您希望字符重复的最小次数 -
n2是您希望字符重复的最大次数
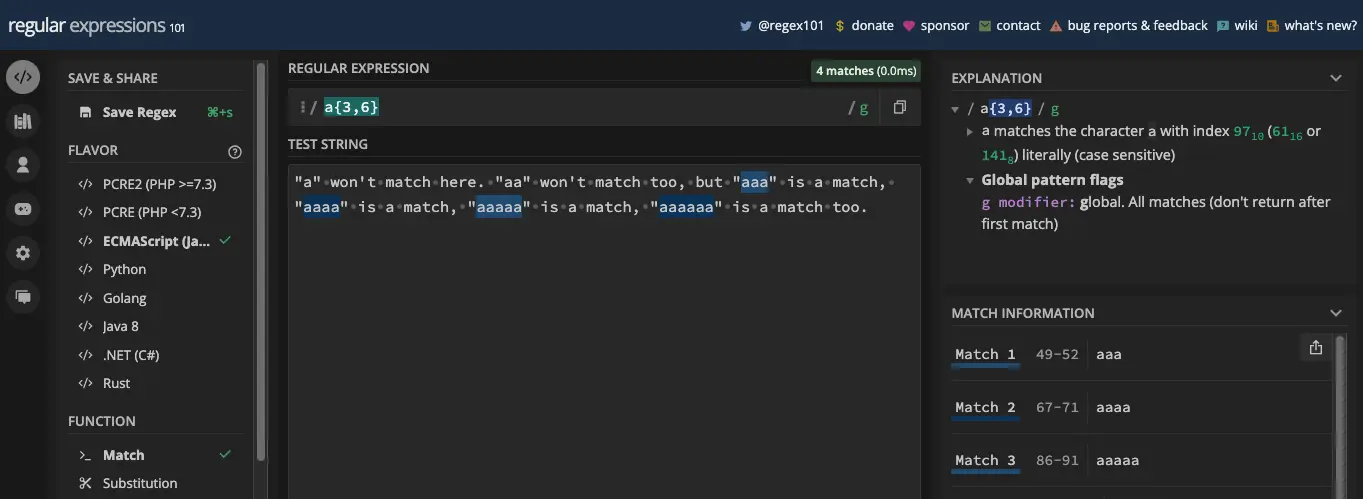
一个例子是模式 /a{3,6}/ 。这意味着您想要匹配三到六个字母 a :
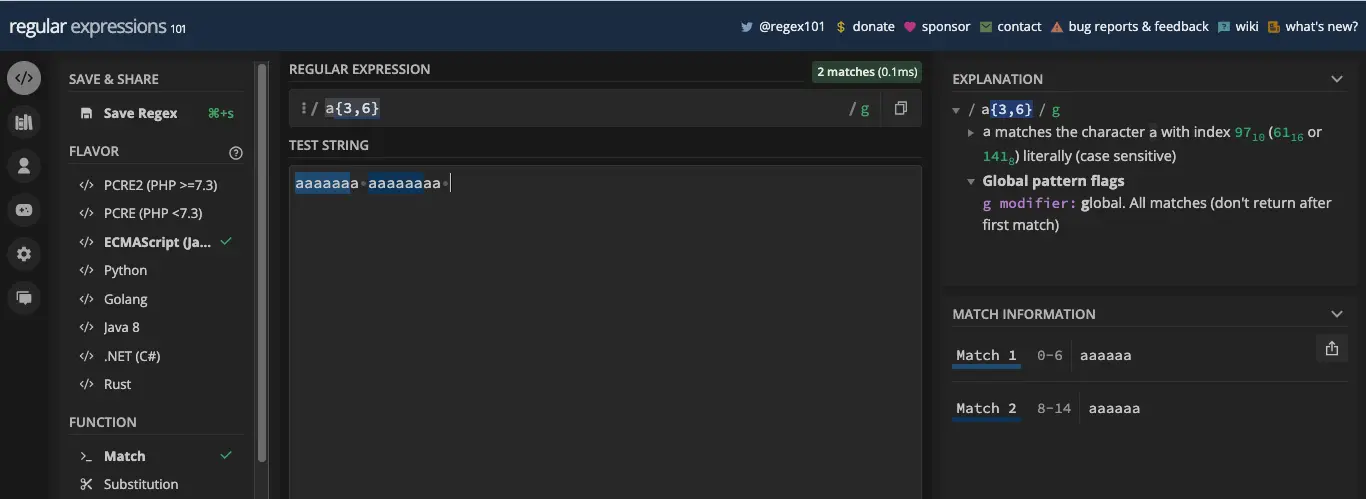
如果测试字符串中的字母 a 超过六个,则前六个字母将匹配:
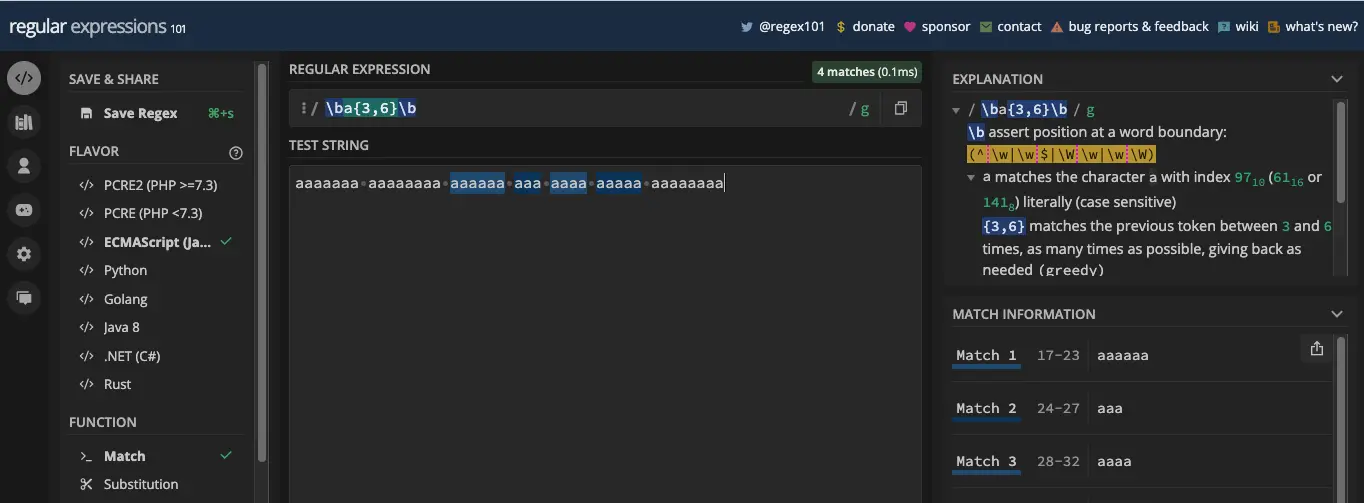
要解决此问题,您可以将模式包围在单词边界中:
您还可以将范围量词附加到元字符。例如,您可以通过以下方式提取至少数百的任何数字:
const myStr =
'The marathon had 500 participants, with 251 finishing under 3 hours, and the winner crossed the line at 4800 seconds.';
const re = /\b\d{3,6}\b/g;
console.log(myStr.match(re)); // [ '500', '251', '4800' ]
The Minimum Quantifier 最小量词
最小量词允许您指定希望其前面的字符匹配的最小次数。您可以通过在大括号中的数字后面放置一个逗号来完成此操作。一般语法如下所示: {n,} 。
例如,模式 /a{3,}/ 表示您需要至少三个字母 a 。在这种情况下,一个字母 a 和两个字母 a 不会匹配,但三个字母 a 及以上将作为匹配返回:

让我们使用 match() 方法提取这些匹配项:
const myStr =
'"a" won't match here. "aa" won't match too, but "aaa" is a match, "aaaa" is also a match, and every other number of "a"';
const re = /a{3,}/g;
console.log(myStr.match(re)); // [ 'aaa', 'aaaa' ]
The Exact Quantifier 精确量词
确切的说明符由 {n} 表示。在本例中, n 代表您希望该字符重复的确切次数。例如,模式 /a{3}/ 表示您希望 a 重复三次
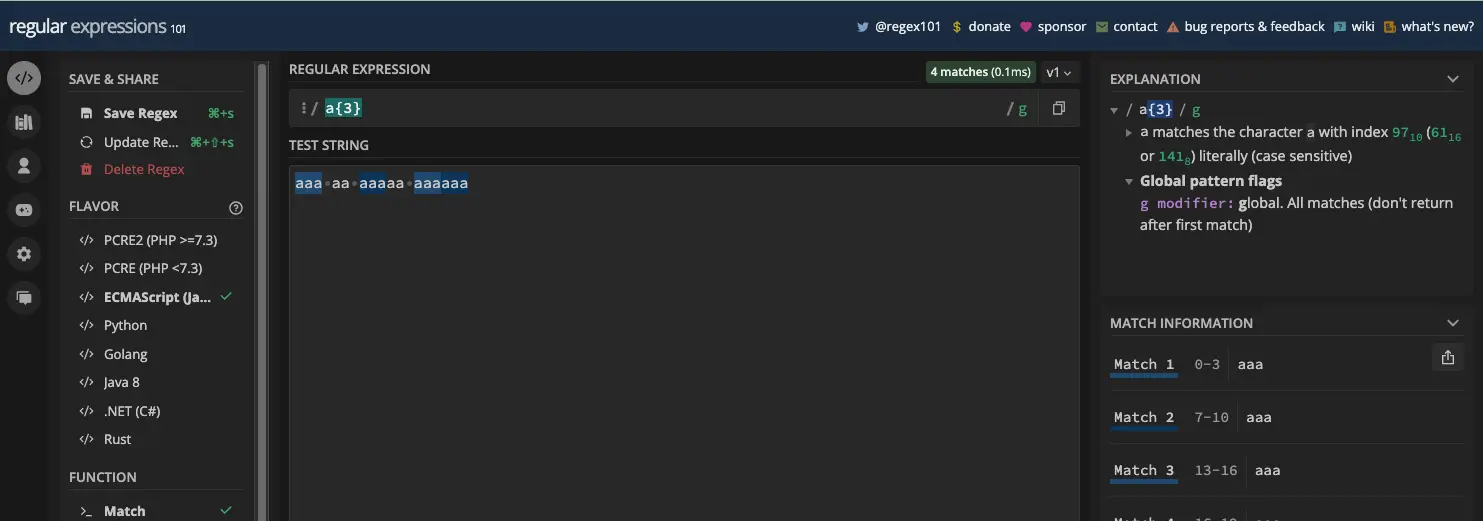
不幸的是,只要有三个字母 a 彼此相连,就会返回匹配项。您可以使用字边界( \b )来防止此行为:
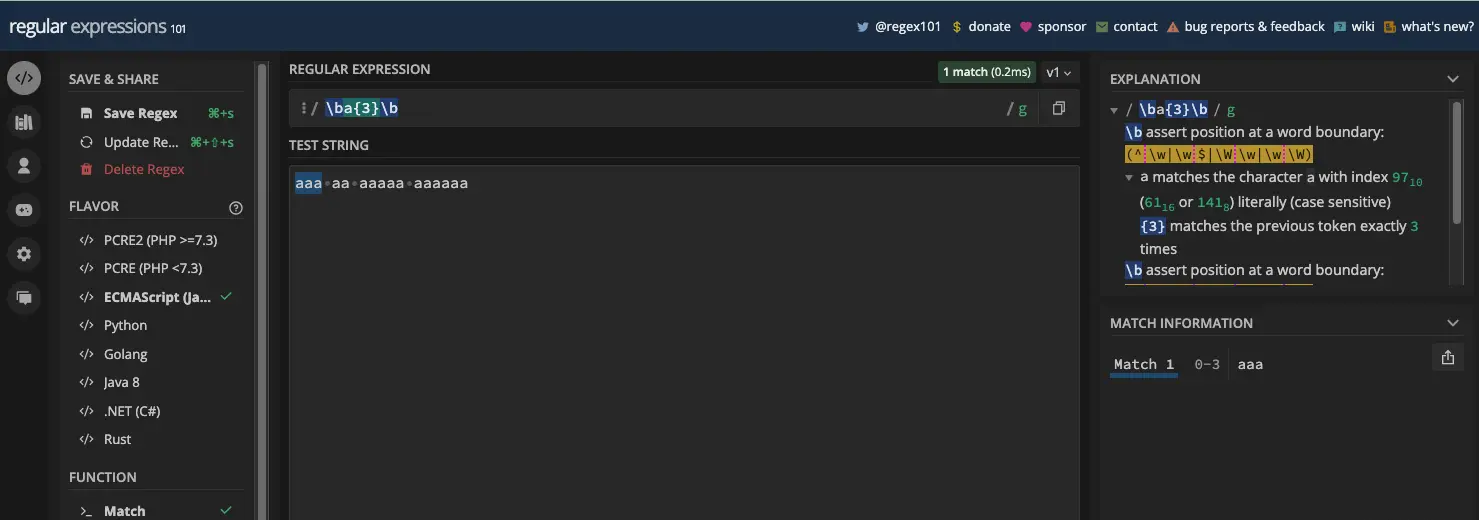
这样,您可以使用 match() 方法从字符串中提取缩写 AAA 。下面是一个例子:
const myStr =
"There is American automobile association (AAA)and there is Australian automobile association (AAA). What I've never seen is AAAA or AAAAAA.";
const re = /\ba{3}\b/gi;
console.log(myStr.match(re)); // [ 'AAA', 'AAA' ]
还记得我为匹配 dd/mm/yyyy 格式的日期而编写的模式吗?您可以使用精确量词使其更好、更容易阅读,如下所示:
\d{2}[/.-]\d{2}[/.-]\d{4}
一切仍然正常:
const slashSeparatedSate = '22/04/2023';
const hyphenSeparatedDate = '22-04-2023';
const periodSeparatedDate = '22.04.2023';
const re = /\d{2}[/.-]\d{2}[/.-]\d{4}/;
console.log(re.test(slashSeparatedSate)); // true
console.log(re.test(hyphenSeparatedDate)); // true
console.log(re.test(periodSeparatedDate)); // true
您还可以使用相同的方法使与美国电话号码匹配的模式更好、更短:
(\d{3}) \d{3}-\d{4}
一切仍然工作正常:
const USPhone = '(123) 456-7890';
const re = /(\d{3}) \d{3}-\d{4}/;
console.log(re.test(USPhone)); // true
The Wildcard Metacharacter 通配符元字符
通配符元字符由点 ( . ) 表示,因此您也可以将其称为点元字符。
通配符可让您匹配除换行符 ( \n ) 之外的任何字符。这意味着您可以使用它来匹配字母数字字符、空格和符号。
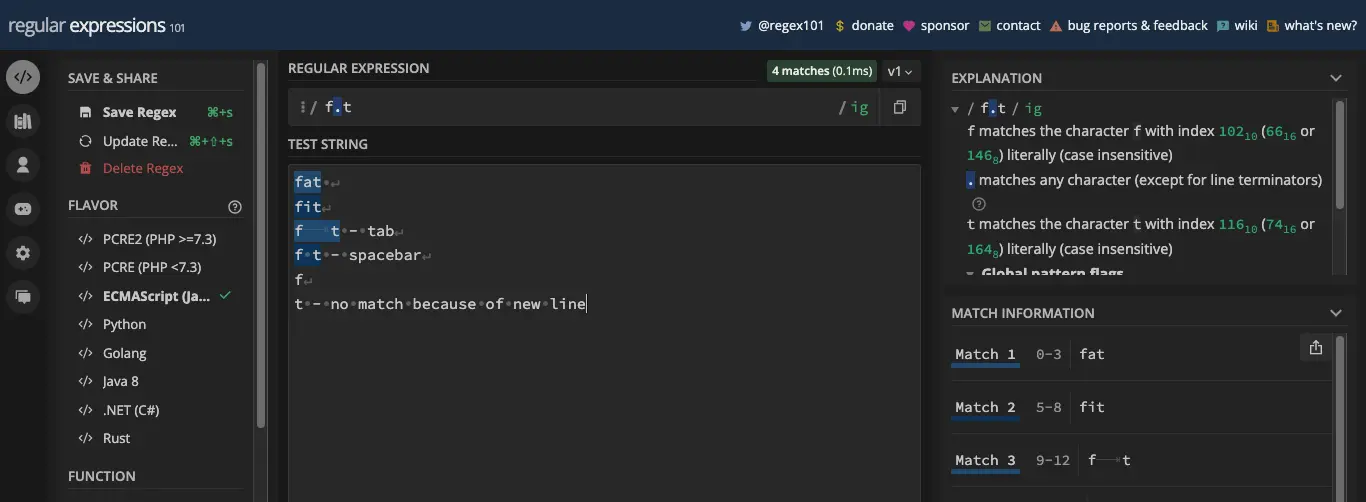
您还可以将通配符元字符附加到另一个元字符。例如,模式 /\d./g 应至少匹配一个数字及其后面的所有内容:
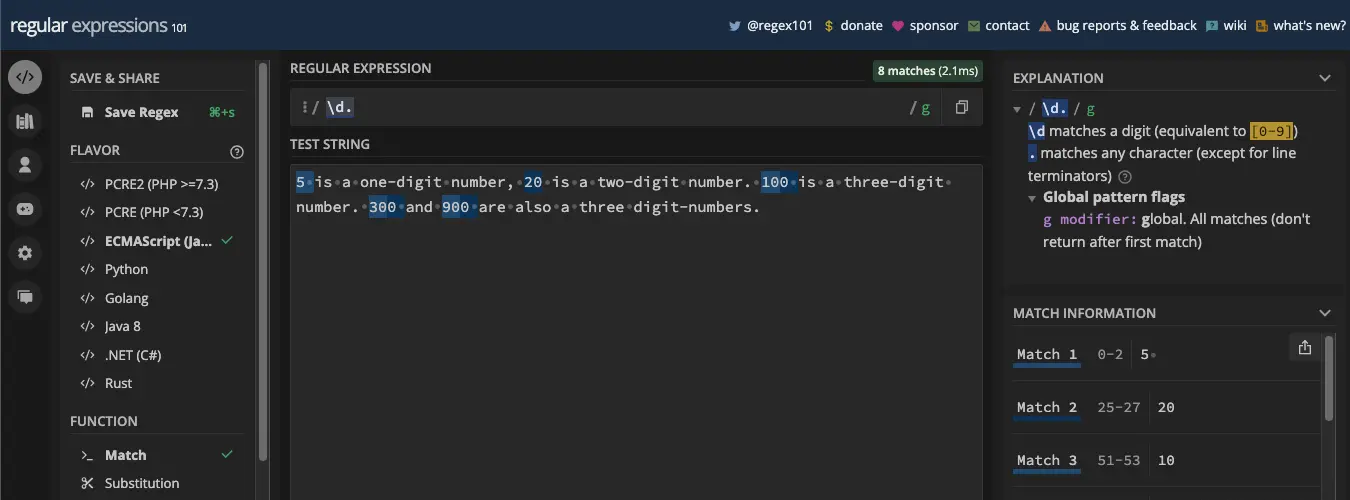
通过匹配数字后面的空格,您可以看到该模式超越了数字。这就是所谓的贪婪。
模式 /\d.*/g 更加贪婪,因为它会在遇到第一个数字后匹配所有内容:
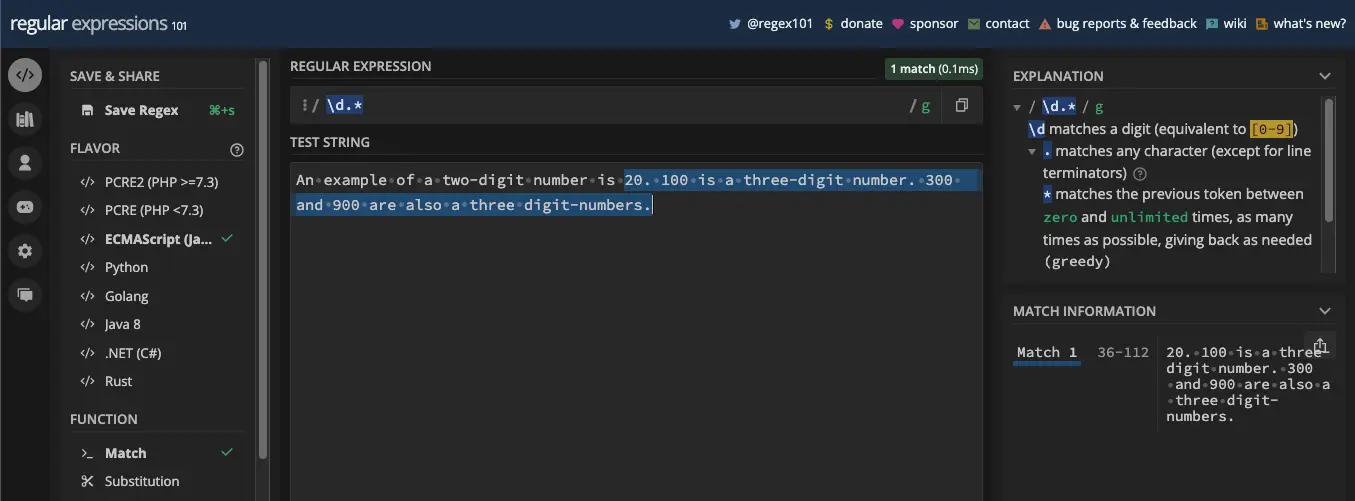
代码中也是一样的:
const myStr =
'An example of a two-digit number is 20. 100 is a three-digit number. 300 and 900 are also three-digit numbers.';
const re = /\d.*/g;
console.log(myStr.match(re)); // [ '20. 100 is a three-digit number. 300 and 900 are also three-digit numbers.']
如果您希望通配符也匹配新行,则可以使用 s 标志。这是一个例子:
let codeBlock = `
function add(x, y) {
/* This is a function
that takes two numbers
and adds them together. */
return x + y;
}
`;
let commentRegex = //*(.*)*//s; // gets everything between /* and */
const match = codeBlock.match(commentRegex);
console.log(match);
结果如下:
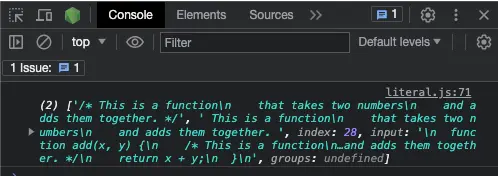
您可以使用 dotAll 属性来检查模式中是否使用了 s 标志:
let codeBlock = `
function add(x, y) {
/* This is a function
that takes two numbers
and adds them together. */
return x + y;
}
`;
let commentRegex = //*(.*)*//s; // gets everything between /* and */
const match = codeBlock.match(commentRegex);
console.log(commentRegex.dotAll) // true;
您可以使用 if 语句提取匹配项:
let codeBlock = `
function add(x, y) {
/* This is a function
that takes two numbers
and adds them together. */
return x + y;
}
`;
let commentRegex = //*(.*)*//s; // gets everything between /* and */
const match = codeBlock.match(commentRegex);
if (match) {
console.log(match[1]);
}
/*
Output:
This is a function
that takes two numbers
and adds them together.
*/
由于通配符始终匹配除换行符之外遇到的任何字符,因此除非绝对必要,否则最好不要使用它。对于通配符匹配的每个字符,总是有另一种方法来匹配它。
Greediness and Laziness in Regular Expressions 正则表达式中的贪婪和惰性
默认情况下,正则表达式模式是贪婪的,这意味着它们总是尝试匹配尽可能多的字符。但贪婪的概念主要适用于量词( * 、 + 、 ? 和 {} )和通配符( . )。
例如,模式 /f.*h/gi 在遇到目标字符串中的 f 后将匹配尽可能多的字符:

模式相同, /f.*h/gi :
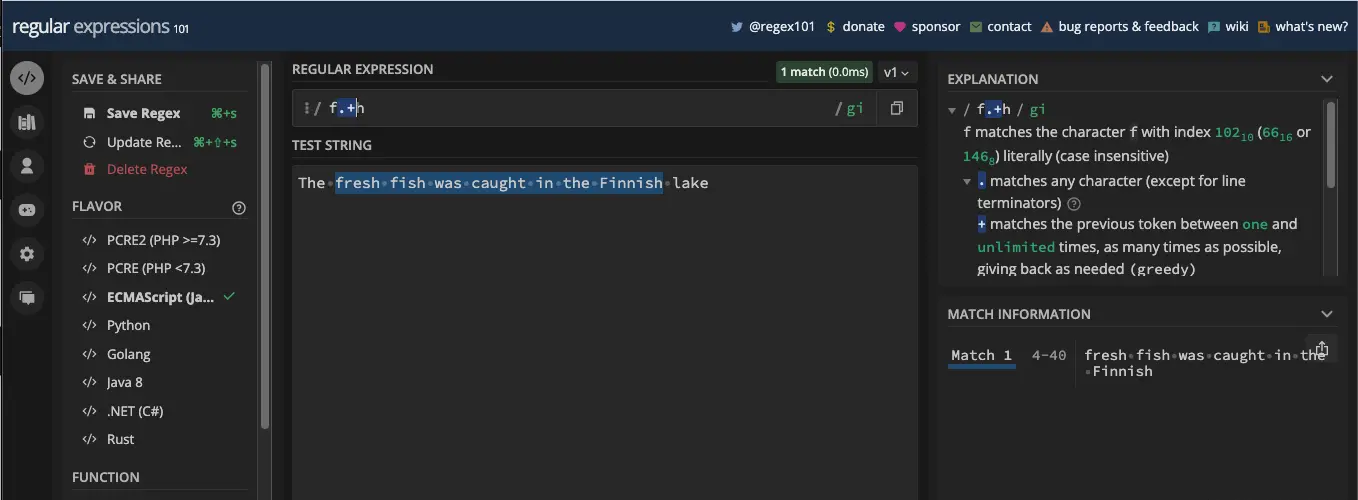
代码中也是一样的:
const myStr = 'The fresh fish was caught in the Finnish lake';
const re = /f.*h/gi;
console.log(myStr.match(re)); // [ 'fresh fish was caught in the Finnish' ]
懒惰是贪婪的反面,也是阻止贪婪的方法。在许多情况下,如果您想停止贪婪,您所需要做的就是将零或个量词 ( ? ) 应用于导致贪婪的元字符。
以下是我如何阻止星号元字符的贪婪:
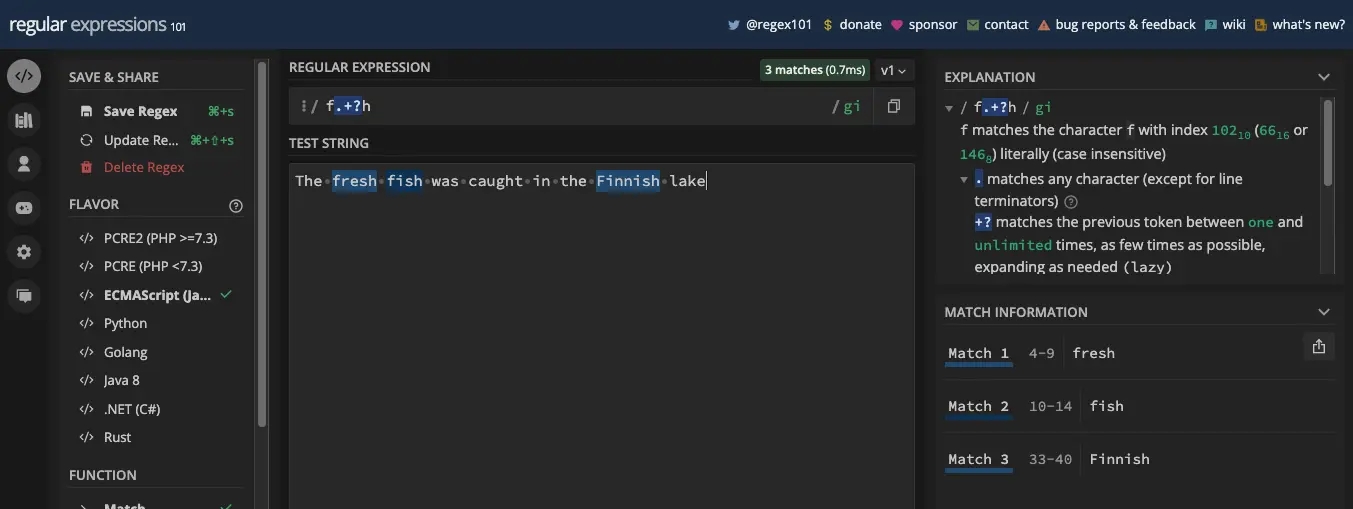
我以同样的方式停止了加号元字符:
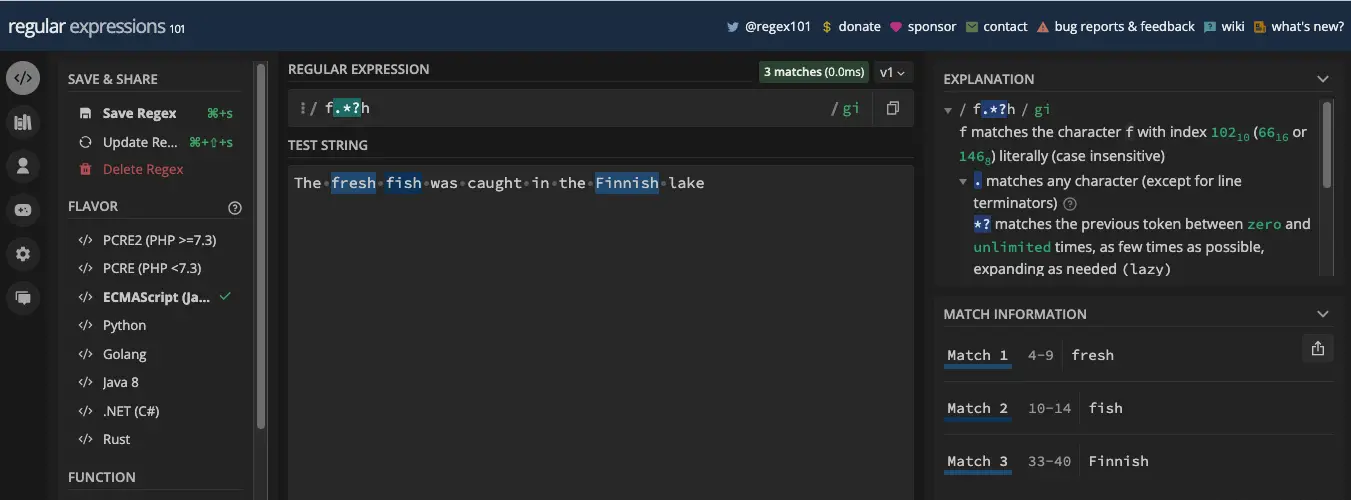
我现在可以安全地提取以 f 开头并以 h 结尾的每个单词:
const myStr = 'The fresh fish was caught in the Finnish lake';
const re = /f.*?h/gi;
console.log(myStr.match(re)); // [ 'fresh', 'fish', 'Finnish' ]
在线工具
参考文献
原文链接:https://juejin.cn/post/7334523075467345960 作者:惊墨