
TLDR;
许久没有动笔了,最近一年都专注在业务上,也参与并见证了公司的BFF从0到1的搭建和落地,在nodejs的监控和诊断方面投入了比较多的时间和精力。
今天就写一篇科普Nodejs addon的文章
什么是Nodejs addon
为了提高效率,就借用ChatGPT的话来回答


适用场景

Nodejs addon的本质
可以看到在build/Release目录下,有一个hello.node文件。
首先,它是一个文件后缀为.node的文件(这当然是一句废话😛)
其次,它是一个二进制文件
通过file build/Release/hello.node 可以看到这是一个Mach-O格式的文件

Mach-O文件就是苹果系统(macOS 或者 IOS)的可执行文件
通过otool -hv build/Release/hello.node可以查看Mach-O文件的头部信息

以下是Mach-O的头部信息的字段所代表的含义
| 字段名称 | 描述 |
|---|---|
| 魔术数 (Magic Number) | 标识文件类型的特殊数值。 |
| CPU 类型 (CPU Type) | 指定文件编译时针对的 CPU 架构。 |
| CPU 子类型 (CPU Subtype) | 指定文件编译时使用的具体 CPU 类型的子类型。 |
| 文件类型 (File Type) | 指定文件的类型,如可执行文件、动态链接库、静态库等。 |
| 加载命令数量 (Number of Load Commands) | 指定加载命令的数量。 |
| 加载命令的大小 (Size of Load Commands) | 指定所有加载命令的总大小。 |
| 标志 (Flags) | 文件相关的标志信息,如是否是共享库、是否是 PIE 等。 |
最后,从flags中的DYLDLINK关键字可以看出,它还是一个动态链接库

动态链接库的好处就是可以在程序运行时动态加载到内存中
这是动态链接库在不同平台对应的文件后缀
| system | suffix |
|---|---|
| Window | dll |
| Linux | so |
| Unix | dylib |
如何引入Nodejs addon
有以下两种方式
var addon = require('./build/Release/hello.node')
var addon = require('bindings')('hello')
require和process.binding加载nodejs addon的区别
require是 Node.js 提供的标准的模块加载机制,用于加载用户编写的模块、第三方模块以及一些核心模块。它是更常见、更通用的加载方式。process.binding对于加载底层的 C++ 插件或核心模块是非常有用的,它是 Node.js 内部使用的机制,可能在未来的版本中发生变化,因此在用户应用中直接使用时需要注意兼容性,一般情况下,开发者在应用程序代码中较少直接使用process.binding。
为什么要用require,而不能用import
无论 Node.js 版本是否支持 ES6 模块语法,通常都要使用 require 来引入 addon。这是因为 addon 本质上是一个共享对象(shared object)或动态链接库(dynamic library),而不是 ECMAScript 模块,因此不适用于 ES6 模块的 import 语法。
关于require的更多知识
-
对于
.js文件,是通过fs模块同步读取文件后编译执行(CommonJS模块规范的实现)在编译过程中,Node对获取的Javascript文件内容进行了头尾包装,
这样每个模块文件之间都有作用域隔离。
包装后的代码会通过vm原生模块的runInThisContext()方法执行(类似eval,只是具有明确上下文,不污染全局),返回一个具体的function对象,最后,将当前模块对象的exports属性、require方法、module(模块对象自身)以及在文件定位中得到的完整文件路径和文件目录作为参数传递给这个function执行
这就是这些变量并没有定义在每个模块文件中却存在的原因,在执行之后,模块的exports属性被返回给了调用方。exports属性上的任何方法和属性都可以被外部调用到,但是模块中的其余变量和属性则不可直接被调用
-
对于
.json文件,则是通过fs模块同步读取文件后,用JSON.parse()解析返回结果 -
对于每个编译成功的模块都会将其文件路径作为索引缓存在
Module._cache对象上,以提高二次引入的性能,因此nodejs的模块查找是以缓存优先策略寻址的
.node文件的加载流程
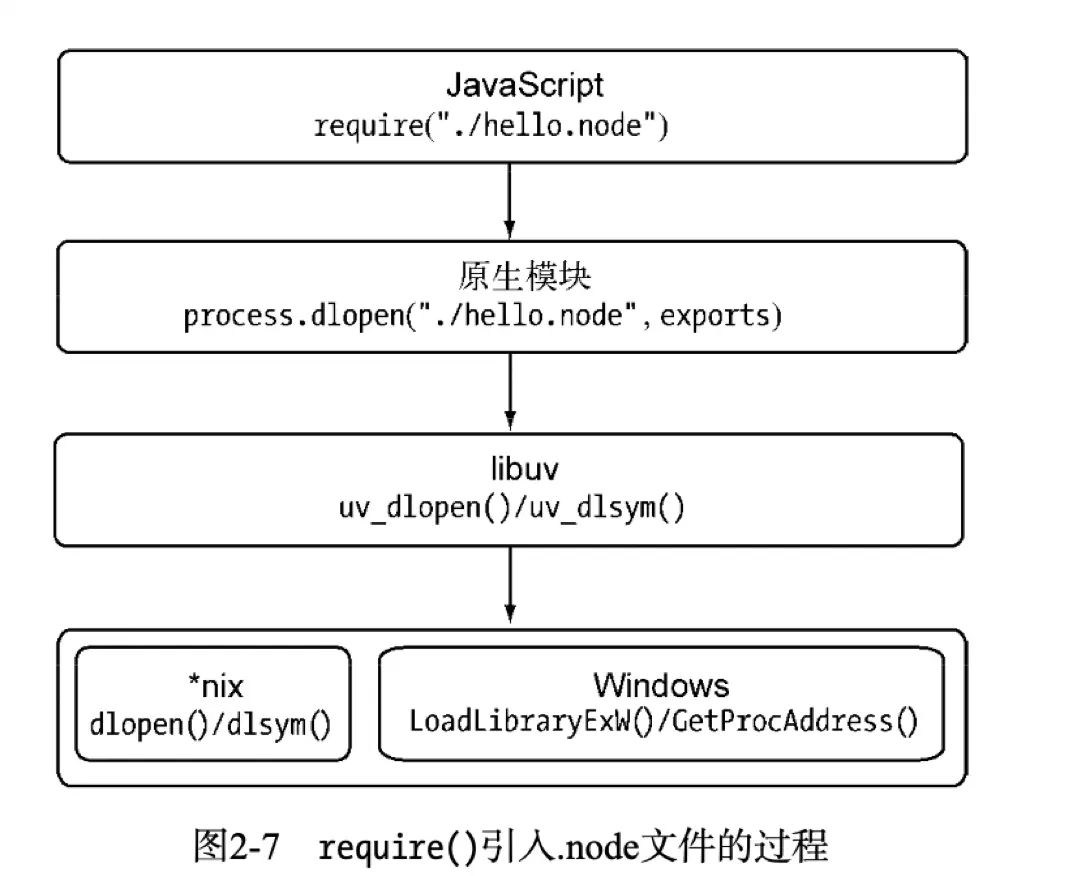
从上图可以看到加载.node文件实际上经历了两个步骤
第一个步骤是调用uv_dlopen方法去打开动态链接库
第二个步骤是调用uv_dlsym分发到动态链接库中通过NODE_MODULE宏定义的方法地址
这两个过程都是通过libuv库进行封装的
在*nix平台下实际调用的是dlopen和dlsym方法
在windows平台则是用过loadLibrayExW和GetProcAddress方法
他们分别加载.so和.dll文件(实际为.node文件)
Nodejs addon的前世今生
远古年代
直接 include v8 和 libuv 相关的 .h 文件,直接编译
但v8相关的 API 变化非常快,导致用这种方式封装的 native addon 无法跨 node 版本使用
NAN(Native Abstracions for Nodejs)
- 起源: 最早,Node.js C++ 插件的开发面临着不同版本 Node.js API 的变化,这导致了插件不够稳定且难以跨版本兼容。为解决这个问题,NAN 库应运而生
- 目的: NAN 的目标是提供一个抽象层,使得 C++ 插件能够更容易地跨不同版本的 Node.js 运行,从而提高插件的可维护性和稳定性
- 问题: NAN 将
v8/libuv相关的 API 进行了封装,虽然对外是稳定的抽象层 API ,但却无法保证是 ABI 稳定,用 NAN 进行封装的native addon几乎无法通过预编译的方式进行分发,因为跨 Node 版本底层v8/libuvAPI 变化之后需要对源码进行重新编译才能使用。
所以这就是为什么很多
native addon在npm install后还要调用一堆工具链在本地进行编译才能使用,以及为什么有时候node版本升级之后之前安装好的node_modules就无法直接使用了。
题外话:什么是稳定的ABI

ABI 化:(Application Binary Interface)应用程序二进制接口
- 可以理解为一种约定,是 API 的编译版本
- ABI 允许编译好的目标代码在使用兼容 ABI 的系统中无需改动就能运行
- 一套完整的 ABI 可以让程序在所有支持该 ABI 的系统上运行,无需对程序进行修改
N-API
- 起源: 由于 NAN 并未成为 Node.js 官方的 API 稳定解决方案,Node.js 社区决定推动一个官方的 C API,以解决插件跨版本兼容性的问题。
- 目的: N-API 的目标是提供一个稳定的、向后兼容的 Node.js C API,使得插件开发者能够更轻松地编写具有良好跨版本兼容性的插件。
自从 Node.js v8.0.0 发布之后,Node.js 推出了全新的用于开发 C++ 原生模块的接口,N-API。本质其实是将 NAN 这层抽象挪到了 node 源码中,在 node 编译的时候就编译好这层对外抽象,这样 N-API 对外就是稳定的 ABI 了。
与 NAN 相比,它把 Node.js 的所有底层数据结构全部黑盒化,抽象成 N-API 中的接口;不同版本的 Node.js 使用同样的接口,这些接口稳定且 ABI 化。只要 ABI 版本号一致,编译好的 C++ 扩展就可以直接使用,而不需要重新编译
node-addon-api
- 起源: N-API 提供了一个低级别的 C API,对于一些开发者来说,这可能仍然显得过于繁琐。Node.js 社区在此基础上推出了 node-addon-api,这是一个更高级别的 C++ API,简化了插件的开发。
- 目的: node-addon-api 旨在提供一个简单且更易用的接口,同时保留 N-API 的跨版本稳定性。它能够在底层使用 N-API 来实现跨版本兼容性,但提供了更友好的 C++ 接口。
node-addon-api和N-API都是用于在 Node.js 中创建 C/C++ 插件的工具,它们有不同的设计目标和优势。以下是它们之间一些主要区别:
- 抽象级别:
N-API: 提供了更低级别的抽象,允许开发者更直接地与 JavaScript 对象和 V8 引擎的底层细节交互。node-addon-api: 提供了更高级别的抽象,简化了插件的编写。它建立在N-API之上,通过提供类和方法的方式,将一些常见的操作进行了封装。
- C++封装:
N-API: 原生的C接口,需要在C++中使用时手动进行封装。node-addon-api: 提供了用于封装的C++类,使得在C++中更容易编写插件。
- 升级和维护:
N-API: 当 V8 引擎升级时,不同版本的 Node.js 可能需要重新编译插件。N-API的目标是提供更好的向后兼容性,但不是完全无需修改就能在新版本上运行。node-addon-api: 构建在N-API之上,通过提供更稳定的接口,试图减少由于 Node.js 或 V8 引擎的变化而导致的插件代码修改。
- 易用性:
N-API: 相对较底层,需要更多的手动管理内存和对象的生命周期。node-addon-api: 提供了更友好的 C++ API,简化了内存管理和对象生命周期的处理。
- 社区支持:
N-API: 是 Node.js 官方提供的 API,具有广泛的支持和文档。node-addon-api: 是由社区维护的一个库,它建立在N-API之上,提供了更高级别的抽象。
因此在选择使用哪个库时,取决于你的需求和偏好。如果你喜欢更底层的控制,并且希望在不同版本的 Node.js 之间更好地保持兼容性,可能会选择使用 N-API。如果你更倾向于使用 C++,而且希望更简单地编写插件,并且不太担心 Node.js 版本变化的影响,那么 node-addon-api 可能更适合你。
napi-rs
即使有了N-API和node-addon-api,可是还有以下问题的存在
- 分发困难
- 分发源码
- 只分发
Javascript代码,postInstall下载对应产物 - 不同平台的
native addon通过不同的npm package分发
- 生态和工具链
- 使用多个不一样构建工具链的库的时候可能会很难搞定编译
- 由于没有好用的包管理器,很多优质的
C/C++代码都是作为一个大型项目的一部分存在的,而不是独立成一个库
因此N-API的Rust Binding:napi-rs应运而生
-
Rust的安全性: napi-rs 利用了 Rust 的内存安全性,防止了常见的内存错误,如空指针引用、越界访问等。
并在编译时执行借用检查,以防止数据竞争和内存安全问题。这可以减少一类常见的编程错误,但也可能导致某些性能开销。在某些情况下,这种开销可能是合理的权衡,特别是在追求更可维护、安全的代码时。 -
Rust的性能: Rust 是一种系统级语言,具有出色的性能。通过使用 Rust,你可以在插件中获得高性能的同时,仍然能够与 Node.js 交互。
-
N-API的跨版本兼容性: napi-rs 构建在 N-API 之上,这意味着插件在不同版本的 Node.js 上具有更好的向后兼容性,无需频繁修改代码以适应新的 Node.js 版本。
-
抽象层次的提高: 提供了更高级别的 Rust API,使插件编写更加简单和直观,同时仍然可以访问 N-API 的强大功能。
-
社区支持: 作为一个社区驱动的项目,napi-rs 受到了 Rust 和 Node.js 社区的支持,有活跃的维护者和用户群。
-
工具链:Rust 有现代化的包管理器: Cargo ,经过这么多年的发展在生态上尤其是与 Node.js 重叠的 服务端开发 、跨平台 CLI 工具、跨平台 GUI (electron) 等领域有了非常多的沉淀。比起 C/C++ 生态,Rust 生态的包属于只要有,都可以直接用 的状态,而 C/C++ 生态中的第三方代码则属于 肯定有,但不一定能直接用 的状态。这种状态下,用 Rust 开发 Node addon 少了很多选择,也少了很多选择的烦恼。
如何开发一个Nodejs addon
以N-API为例
开发流程
-
安装编译工具:node-gyp
npm install node-gyp -
给addon项目添加package.json及依赖
// package.json { "name": "hello_world", "version": "0.0.0", "description": "Node.js Addons Example #1", "main": "hello.js", "private": true, "dependencies": { "bindings": "~1.2.1" }, "scripts": { "test": "node hello.js" }, "gypfile": true } -
编写C/C++/Rust Code
// hello.c #include <assert.h> #include <node_api.h> static napi_value Method(napi_env env, napi_callback_info info) { napi_status status; napi_value world; status = napi_create_string_utf8(env, "world", 5, &world); assert(status == napi_ok); return world; } #define DECLARE_NAPI_METHOD(name, func) \ { name, 0, func, 0, 0, 0, napi_default, 0 } static napi_value Init(napi_env env, napi_value exports) { napi_status status; napi_property_descriptor desc = DECLARE_NAPI_METHOD("hello", Method); status = napi_define_properties(env, exports, 1, &desc); assert(status == napi_ok); return exports; } NAPI_MODULE(NODE_GYP_MODULE_NAME, Init) -
编写Binding Code
// binding.gyp { "targets": [ { "target_name": "hello", "sources": [ "hello.c" ] } ] } -
构建和编译addon
正常情况,
npm install就会执行node-gyp rebuild,但如果已经存在
binding.gyp文件了,可以执行以下命令node-configure (optional) node-gyp build -
在Nodejs中引入addon
var addon = require('bindings')('hello');
各位可以参照以下两个链接,自己跑一下,玩玩看
总结
- 首先介绍了什么是
Nodejs addon,了解了它的本质就是一个动态链接库- 如何引入
Nodejs addon- process.binding
- require
- 以及
.node在不同平台的加载流程
- 如何引入
- 其次介绍了
Nodejs addon开发工具的发展历程- 远古时代直接引用v8的api
- 封装好API的
NAN - ABI稳定的
N-API - 针对C++封装的
node-addon-api - 利用Rust语言特性和生态优势的
napi-rs
- 最后介绍了开发一个
Nodejs addon的基本步骤
希望能够让大家轻松的理解Nodejs addon :)
参考链接
- 用 Rust 和 N-API 开发高性能 Node.js 扩展
- 从暴力到 NAN 再到 NAPI——Node.js 原生模块开发方式变迁
- 深入浅出Node.js
- node-addon-examples
- napi-rs examples
原文链接:https://juejin.cn/post/7336287879332479027 作者:逸杰