
低代码系列文章:
低代码相关仓库:
前言
ChatGPT,作为一个先进的自然语言处理工具,可以理解和生成人类语言,提供智能编程建议,自动化代码生成,以及提供交互式编程教学。这些功能为开发者提供了前所未有的便利,大大减少了编程的时间和复杂性。
低代码平台则允许用户通过图形界面来构建应用,减少了对专业编程知识的依赖,在特定业务场景下能够提升开发效率。用户可以通过拖放组件和模型驱动的逻辑来快速地创建应用程序,而无需编写大量代码。
如果可以把 ChatGPT 和低代码平台结合起来使用,那么用户就可以通过对话来快速地创建应用程序,从而简化了搭建应用程序的过程,并且提升了用户体验。
可行性
低代码平台通常使用 JSON 格式的 DSL(领域特定语言 domain-specific language 指的是专注于某个应用程序领域的计算机语言) 来描述一个页面。用户拖拽组件、编辑页面,实际上是在和页面的 JSON 在进行交互。低代码平台通过渲染引擎把 JSON 数据渲染成为页面,至于页面要渲染成为 Vue、React 或者是纯粹的 HTML 页面,就得看各个低代码平台自己的实现了。一个应用程序一般会包含多个页面,然后通过路由来决定各个页面的跳转逻辑。
因此,我们可以向 ChatGPT 提出生成页面的需求,ChatGPT 再根据我们提供的 prompt 来生成一份符合低代码平台数据格式的 JSON。理论上,这是可行的,现在来看一下怎么实现这个功能。
使用 ChatGPT 进行页面生成
首先,我们需要注册一个 openai 或者 azure 账号,在上面开通 api 服务(如何申请账号请自行搜索,网上有很多教程)。然后就可以使用这个 api 来和 ChatGPT 进行交互了。
另外,我们还需要一个低代码平台,因为生成的 JSON 需要一个低代码平台来验证生成 JSON 是否真实可用。刚好前几年我写了一个低代码平台教学项目,现在刚好可以用上。
低代码平台组件 DSL
首先,我们要知道每一个组件的 DSL 描述,下面的代码是一个文本组件的 DSL 描述:
{
"animations": [], // 动画属性
"events": {}, // 事件
"groupStyle": {}, // 组合组件样式
"isLock": false, // 是否锁定
"collapseName": "style",
"linkage": { // 联动组件
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText", // 组件类型
"label": "文字", // 组件名称
"propValue": "双击编辑文字", // 组件值
"icon": "wenben", // 组件图标
"request": { // 组件 API 请求
"method": "GET",
"data": [],
"url": "",
"series": false,
"time": 1000,
"paramType": "",
"requestCount": 0
},
"style": { // 组件样式
"rotate": 0,
"opacity": 1,
"width": 200,
"height": 28,
"fontSize": "",
"fontWeight": 400,
"lineHeight": "",
"letterSpacing": 0,
"textAlign": "",
"color": "",
"top": 157,
"left": 272
},
"id": "07l4byRWvsphAPo2uatxy" // 组件唯一 id
}
每一个组件就是一个 JSON 数据,那么整个页面就是一个 JSON 数组,里面包含了多个组件:
// 页面 JSON
[
{ ... }, // 组件1
{ ... }, // 组件2
{ ... }, // 组件3
]
prompt 编写
要让 ChatGPT 来生成页面,那么我们要让 ChatGPT 知道页面、组件的数据结构,并且要给它提供示例。然后再向它提出页面生成的需求,从而为我们生成符合要求的页面。这个 prompt 的格式如下:
我有一个低代码平台项目,它可以根据符合规范的 JSON 数据生成页面,这个 JSON 数据是一个数组,里面的每一项都是一个 JSON 对象,每个 JSON 对象都对应着一个组件。
下面用 ### 包括起来的代码就是所有的组件列表。
###
---所有组件的 JSON 数据结构---
###
如果一个页面包含了一个文本和按钮组件,那么这个页面的 JSON 代码如下:
###
---示例页面 JSON 数据结构---
###
你作为一个技术专家,现在需要按照上面的规则来为我生成页面,并且生成的页面中每一个组件的属性都不能忽略,也不需要解释,只需要返回 JSON 数据即可。要注意的是,有些数值的单位是没有 px 的。
现在我需要生成一个海报页面,主要用于宣传编程有什么用。
由于篇幅有限,上面只展示了这个 prompt 的大纲,JSON 数据都省略了。完整的 prompt 请在 lowcode-llm-demo 上查看。
prompt 准备好了,现在我们需要调用 ChatGPT 的 api 来生成页面,示例代码如下:
import { AzureChatOpenAI } from '@langchain/azure-openai'
import 'dotenv/config'
import { readFileSync } from 'fs'
import { resolve, dirname } from 'path'
import { fileURLToPath } from 'url'
const model = new AzureChatOpenAI({
modelName: process.env.AZURE_OPENAI_API_MODEL_NAME,
azureOpenAIEndpoint: process.env.AZURE_OPENAI_API_ENDPOINT,
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIEmbeddingsApiDeploymentName: process.env.AZURE_OPENAI_API_EMBEDDING_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
})
const dirName = dirname(fileURLToPath(import.meta.url))
const prompt = readFileSync(resolve(dirName, '../prompts/prompt-compress.md'), 'utf-8')
const response = await model.invoke(prompt)
console.log(JSON.stringify(response)) // 返回 ChatGPT 的结果
上面的代码执行后就能得到 ChatGPT 返回来的页面 JSON 数据。不过这个数据不能直接使用,还需要额外写点代码处理一下才能使用。下面的代码就是处理后的页面 JSON 数据结构:
[
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "Picture",
"label": "背景图片",
"propValue": {
"url": "img/programming_poster_bg.jpg" // 替换为自己的图片
},
"style": {
"rotate": 0,
"opacity": 1,
"width": 500,
"height": 700,
"top": 0,
"left": 0,
"position": "absolute",
"zIndex": 0
},
"id": "backgroundImage"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText",
"label": "标题文字",
"propValue": "编程改变世界",
"icon": "wenben",
"style": {
"rotate": 0,
"opacity": 1,
"width": 450,
"height": 100,
"fontSize": "32px",
"fontWeight": 700,
"textAlign": "center",
"color": "rgba(16, 15, 15, 1)",
"top": 50,
"left": 25,
"position": "absolute",
"zIndex": 10
},
"id": "titleText"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VText",
"label": "描述文字",
"propValue": "通过编程,我们可以创建软件来解决问题、分析数据,甚至改善人们的生活。",
"icon": "wenben",
"style": {
"rotate": 0,
"opacity": 1,
"width": 400,
"height": 200,
"fontSize": "18px",
"fontWeight": 400,
"lineHeight": "1.5",
"textAlign": "center",
"color": "rgba(33, 31, 31, 1)",
"top": 180,
"left": 50,
"position": "absolute",
"zIndex": 10
},
"id": "descriptionText"
},
{
"animations": [],
"events": {},
"groupStyle": {},
"isLock": false,
"collapseName": "style",
"linkage": {
"duration": 0,
"data": [
{
"id": "",
"label": "",
"event": "",
"style": [
{
"key": "",
"value": ""
}
]
}
]
},
"component": "VButton",
"label": "行动按钮",
"propValue": "开始学习编程",
"icon": "button",
"style": {
"rotate": 0,
"opacity": 1,
"width": 200,
"height": 50,
"borderRadius": "25px",
"fontSize": "20px",
"fontWeight": 500,
"textAlign": "center",
"color": "#FFF",
"backgroundColor": "#f44336",
"top": 420,
"left": 150,
"position": "absolute",
"zIndex": 10
},
"id": "actionButton"
}
]
将 JSON 导入到低代码平台后,生成的页面如下所示:
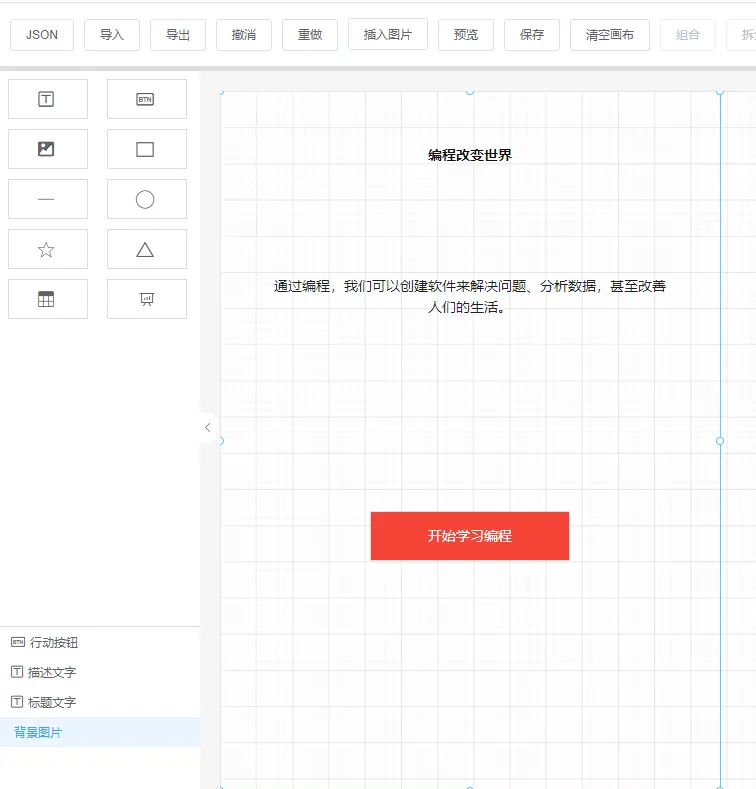

可以看到 ChatGPT 输出了一个半成品页面,背景图片的地址需要我们手动修改。ChatGPT 每次输出的页面都是随机的,下面是生成的另外一个页面。
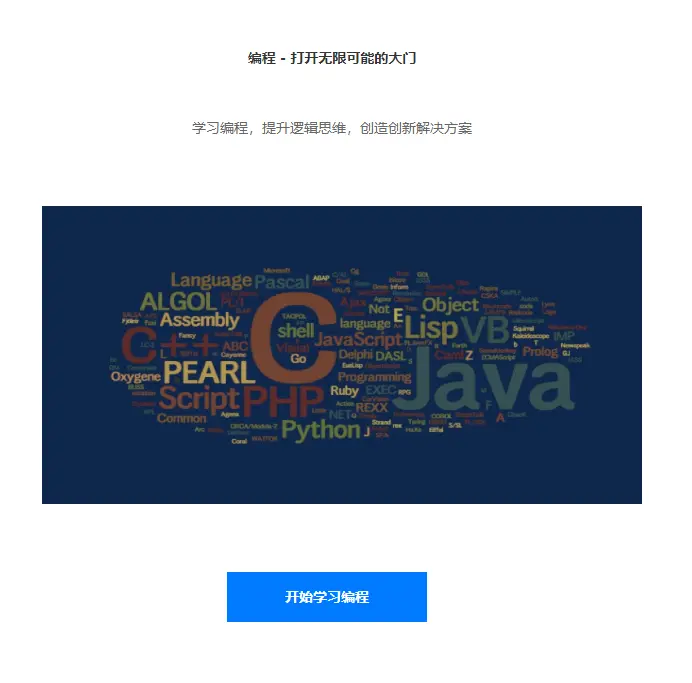
节省成本
ChatGPT 很好用,但是有一个缺点,太贵了。所以我们需要想一些办法来降低成本,下面是几个比较可行的办法:
- 精简 prompt
- 微调(Fine-tuning)
- 使用模板、分类标签
精简 prompt
ChatGPT 的 api 是通过 token 来收费的,所以最简单直接的方法就是优化 prompt。下面是一个未优化的 prompt 示例:
我需要一个用户管理系统的页面。在页面顶部,我需要一个添加用户的按钮。下面是一个表格,列出了所有用户的姓名、邮箱和注册日期。点击任何一个用户,将会打开一个包含完整用户信息的新页面,其中包含姓名、邮箱、注册日期、最后登录时间和用户角色。还需要有一个搜索栏,可以通过姓名或邮箱搜索用户。请基于这些要求为我的低代码平台生成代码。
现在将这个 prompt 优化一下:
生成页面:用户管理
组件:添加按钮,用户表格(姓名,邮箱,注册日期),用户详情(姓名,邮箱,注册日期,最后登录,角色),搜索栏(姓名,邮箱)
在这个例子中,我们简化了描述页面的需求,从而减少了 token 的数量。
微调(Fine-tuning)
在文章的开头,我展示了一个生成页面的 prompt 示例,并且可以看到这个 prompt 消耗的 token 数量非常大,因为它需要告诉 ChatGPT 每个组件的 JSON 数据结构是什么,以及一个完整的示例页面 JSON 数据结构是什么样的,这些示例都需要消耗大量的 token。
为了精简 prompt,同时又能达到未精简前的效果,这可以使用微调来实现。
微调是一种机器学习技术,它可以让你自定义机器学习模型以适应特定的任务或数据集。通过微调,您可以在一个预训练的模型(如ChatGPT)的基础上进一步训练它,使其更好地理解和执行特定的任务。这样,您可以创建一个专门为您的低代码平台生成页面的模型。
我们可以给 ChatGPT 提供大量的数据集进行微调训练,比如大量的低代码页面示例。这样你再让它生成一个“用于宣传编程的海报页面”,就不需要提供每个组件的数据结构了,因为这些数据 ChatGPT 已经通过微调学会了。
现在来看一下用于微调训练的数据集是什么样的:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
上面是数据集的格式,现在我要提供大量的低代码平台数据集:
{"prompt":"生成一个带有矩形组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"RectShape\",\"label\":\"矩形\",\"propValue\":\"矩形\",\"icon\":\"juxing\",\"style\":{\"rotate\":0,\"opacity\":1,\"width\":200,\"height\":200,\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"center\",\"color\":\"\",\"borderColor\":\"#000\",\"borderWidth\":1,\"backgroundColor\":\"\",\"borderStyle\":\"solid\",\"borderRadius\":\"\",\"verticalAlign\":\"middle\",\"top\":143,\"left\":379},\"id\":\"j3i41NnZw8Zcxu3BfbXwv\"}]"}
{"prompt":"生成一个带有文本组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"VText\",\"label\":\"文字\",\"propValue\":\"双击编辑文字\",\"icon\":\"wenben\",\"request\":{\"method\":\"GET\",\"data\":[],\"url\":\"\",\"series\":false,\"time\":1000,\"paramType\":\"\",\"requestCount\":0},\"style\":{\"rotate\":0,\"opacity\":1,\"width\":200,\"height\":28,\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"\",\"color\":\"\",\"top\":145.3333282470703,\"left\":195},\"id\":\"WKqULBX4bKcmREgPJef3D\"}]"}
{"prompt":"生成一个带有按钮组件的页面","completion": "[{\"animations\":[],\"events\":{},\"groupStyle\":{},\"isLock\":false,\"collapseName\":\"style\",\"linkage\":{\"duration\":0,\"data\":[{\"id\":\"\",\"label\":\"\",\"event\":\"\",\"style\":[{\"key\":\"\",\"value\":\"\"}]}]},\"component\":\"VButton\",\"label\":\"按钮\",\"propValue\":\"按钮\",\"icon\":\"button\",\"style\":{\"rotate\":0,\"opacity\":1,\"width\":100,\"height\":34,\"borderWidth\":1,\"borderColor\":\"\",\"borderRadius\":\"\",\"fontSize\":\"\",\"fontWeight\":400,\"lineHeight\":\"\",\"letterSpacing\":0,\"textAlign\":\"\",\"color\":\"\",\"backgroundColor\":\"\",\"top\":126.33332824707031,\"left\":224},\"id\":\"6wgvR1wyRyNqIl37qs1iS\"}]"}
...
通过微调训练后,ChatGPT 就变成了一个专门的低代码模型,它会更好地理解低代码的需求。后面我们再让 ChatGPT 生成页面就不需要大量的 prompt 了,可以直接让它生成一个“用于宣传编程的海报页面”。记住,微调是一个需要精心设计和执行的过程,需要我们不停的校正,才能达到最好的效果。
使用模板、分类标签
一个成功的低代码平台,一定会内置大量的模板,包括但不限于页面模板、应用模板等等。其实在大多数时候,用户提出生成页面的需求时,我们可以提取关键词,根据关键词找到符合用户需求的模板,再展示给用户选择。如果没有找到符合要求的模板,才使用 ChatGPT 来生成页面,这样不仅能节省成本,还避免了 ChatGPT 随机生成页面并且有可能生成错误页面的弊端。
现在我们来看看怎么做。首先,除了给模板命名,还需要给模板归类,比如打上几个类似于“医疗”、“后台管理系统”之类的标签。
当用户提出一个”生成用于宣传编程的页面“需求时,我们可以使用自然语言处理(NLP)库,如 natural 或者 compromise 进行关键词提取,然后再通过 Elasticsearch 来进行搜索,最后把搜索到的模板返回给用户。下面是代码示例:
const { Client } = require('@elastic/elasticsearch');
const { NlpManager } = require('node-nlp');
// 初始化Elasticsearch客户端
const client = new Client({ node: 'http://localhost:9200' });
// 初始化NLP管理器
const nlpManager = new NlpManager({ languages: ['en'], nlu: { useNoneFeature: false } });
// 假设我们有一些模板数据
const templates = [
{ name: 'Medical Service Promotion Page', tags: ['medical', 'promotion'] },
{ name: 'Programming Education Poster', tags: ['education', 'programming', 'poster'] },
{ name: 'Backend Management System Dashboard', tags: ['backend', 'management', 'system'] }
];
// 创建Elasticsearch索引
async function createIndex(indexName) {
// 省略创建索引代码
}
// 索引模板数据到Elasticsearch
async function indexTemplates(indexName, templates) {
// 省略索引数据代码
}
// 提取关键词
async function extractKeywords(text) {
const result = await nlpManager.extractEntities(text);
const keywords = result.entities.map(entity => entity.option || entity.utteranceText);
return keywords;
}
// 使用Elasticsearch进行搜索
async function searchTemplates(indexName, keywords) {
const { body } = await client.search({
index: indexName,
body: {
query: {
bool: {
should: [
{ match: { name: { query: keywords.join(' '), boost: 2 } } },
{ terms: { tags: keywords } }
]
}
}
}
});
return body.hits.hits.map(hit => hit._source);
}
// 主程序
async function main() {
const indexName = 'templates';
// 创建索引并索引数据
await createIndex(indexName);
await indexTemplates(indexName, templates);
// 用户输入
const userInput = "I want to create a poster page for programming promotion";
// 提取关键词
const keywords = await extractKeywords(userInput);
// 执行搜索
const results = await searchTemplates(indexName, keywords);
// 输出结果
console.log(results);
}
main().catch(console.error);
使用开源大语言模型 ChatGLM-6B 进行页面生成
对于无法使用外网或预算有限的项目,我们可以考虑使用开源的大语言模型。本文选了 ChatGLM-6B 开源模型来做演示。
安装
ChatGLM-6B 本地部署的教程网上有很多,由于我的电脑是 Windows,并且没有 N 卡,所以我参考了这篇文章手把手教你本地部署清华大学KEG的ChatGLM-6B模型来部署 ChatGLM-6B。
这篇文章讲得很细致,按照流程走下来只出现了两个小问题,解决后就跑通了。这里也记录一下这两个问题及相应的解决办法。
TDM-GCC 编译错误
按照文章中的要求安装了 TDM-GCC 后发现编译 quantization_kernels_parallel.c 文件错误,卸载 TDM-GCC 后换了 MinGW-w64 就好了,编译顺利通过。
执行 python 脚本偶尔没反应
这个问题排查了很久,经过不断的调试和重启,最后发现是系统资源不足(我的电脑 CPU 是 6800H,32G 内存,没有显卡)。在关掉无关程序后,只保留一个终端用于启动脚本后,就没有问题了。
使用
ChatGLM-6B 的相关代码已经上传到了 Github ,大家可以把项目下载下来,然后按照仓库文档中的说明修改目录位置后,就可以执行 cli-demo.py 或者 web-demo.py 脚本和 ChatGLM-6B 进行交互了。下面的几张图片就是部署在我电脑上的 ChatGLM-6B 使用示例:
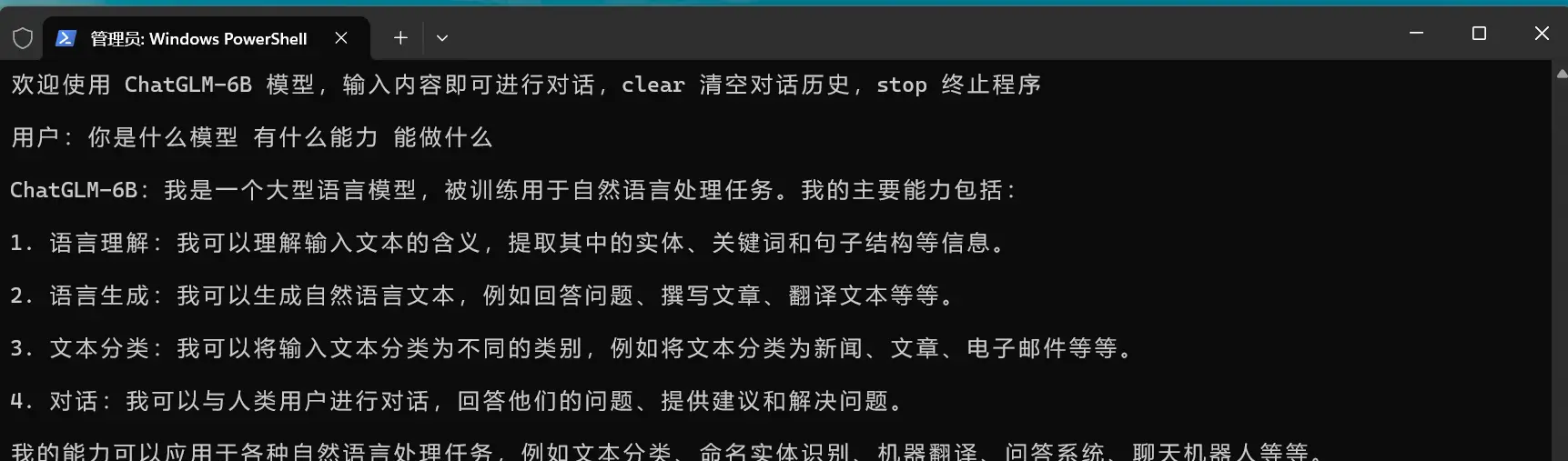
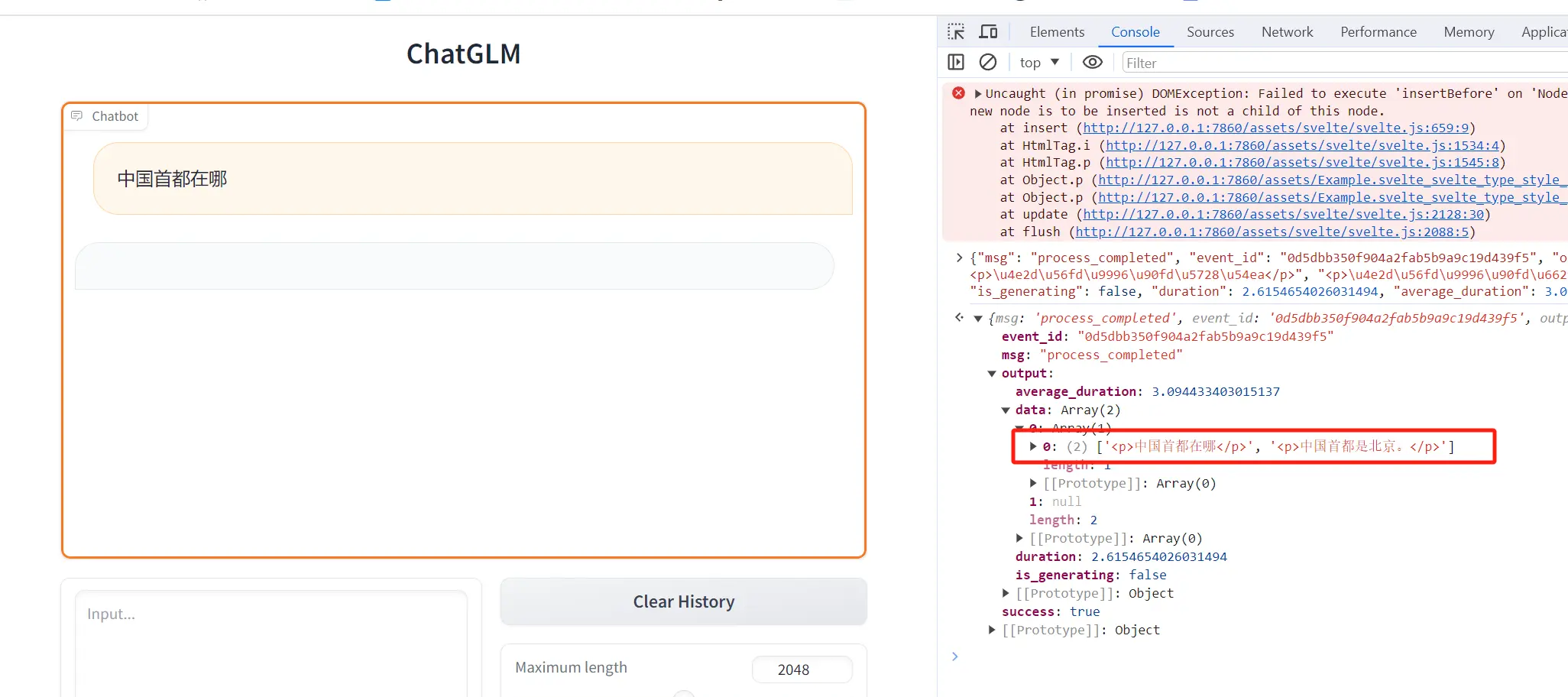
由于电脑配置不是特别好,ChatGLM-6B 在我电脑上运行起来比较慢,一个问题回答起来要花几分钟。像生成低代码页面的这个需求,就跑了十几分钟,最后程序直接崩了,只给我输出了一半的 JSON,不过数据结构是对的,所以换个好点的显卡后应该不是问题。
总结
其实,大语言模型不仅能和低代码领域配合使用,经过训练后的模型可以和任何领域结合,从而生成该领域的专门模型。例如 Figma、即时设计、MasterGo 这种设计工具,它们存储的也是一份 JSON 数据。所以理论上也可以通过对话来生成设计页面。
还有其他的类似于 AI 客服、催收机器人都可以通过这种方法训练出来。
参考资料
求职
我是一名有 7 年工作经验的前端,学历是非全大专,目前正在看机会。我的期望工作地点是北京/天津/远程,期望的岗位是前端/全栈。
以下是我掌握的一些技能:
- 前端有做过低代码、监控、脚手架、前端工程化、性能优化,业余时间有研究过微前端、浏览器渲染原理、编译原理等
- 后端能用 nodejs 写业务,懂点 docker k8s
- 有带团队经验(团队规模 15 +)
- 了解 Rust、 LLM 应用相关知识,做过一些练手项目
我的 Github: github.com/woai3c 和微信号:qq411020382,有兴趣的大佬请加我微信联系。
原文链接:https://juejin.cn/post/7338717224436760626 作者:谭光志