
上一篇文章中,我们说完了浏览器的渲染进程(☞传送门),接下来聊聊v8引擎的工作原理。
概念
V8是由Google开源的采用C++编写的高性能JavaScript引擎和WebAssembly引擎,最初设计用于Chrome浏览器,现在也是Node.js的核心组成部分。
V8为什么叫V8
V8是它的设计者Lars Bak选择的这个名字,它的灵感来源于汽车的V型8缸发动机,这类发动机以其强大的动力和高效的性能而闻名,他希望V8会是一款性能极高的JavaScript引擎。
V8是做什么的
JavaScript是一种高级编程语言,其代码需要经过特定的处理才能被计算机硬件理解和执行。V8引擎在这个过程中通过高效地解析JavaScript代码,将这些代码转换为计算机可以直接运行的形式,也就是机器码,再交给机器执行。
工作原理
V8 引擎的核心功能是解析、优化和执行 JavaScript 代码。其工作过程可以分为以下几个主要阶段:
一,解析
V8引擎首先通过网络,缓存或者Service Workers下载源代码。当拿到了源代码以后,就需要将其转换为编译器能够理解的形式,这个过程称为解析,解析主要有以下阶段:
词法分析
扫描器(Scanner)用于对拿到的JavaScript代码进行词法分析,这个过程会将源代码转换为tokens,也叫词素,在 keywords.txt 文件中可以找到所有的JS tokens。该文件定义了一个结构体PerfectKeywordHashTableEntry,这个结构体包含两个字段,从文件中截取的部分代码如下所示:
struct PerfectKeywordHashTableEntry { const char* name; Token::Value value; };
%%
async, Token::ASYNC
await, Token::AWAIT
break, Token::BREAK
case, Token::CASE
catch, Token::CATCH
class, Token::CLASS
const, Token::CONST
...
上面提到的
tokens通常指的是最小语法单元,比如var x = 5;,它将被拆解为:var(关键字),x(标识符),=(运算符),5(字面量),;(终止符)。
使用esprima模拟对var x = 5;的词法分析得到的tokens为:
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "x"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "5"
},
{
"type": "Punctuator",
"value": ";"
}
]
语法分析
解析器(Parser)会对这些tokens进行语法分析,并根据它来构建抽象语法树(Abstract Syntax Tree,简写为AST),同时会验证语法,如果有语法错误就会抛出来。
AST是一种源代码的树形表示形式,展现了代码的结构和语法关系。请看下面这个例子:
function foo() {
let bar = 1;
return bar;
}
这段代码会生成下图中的树形结构:
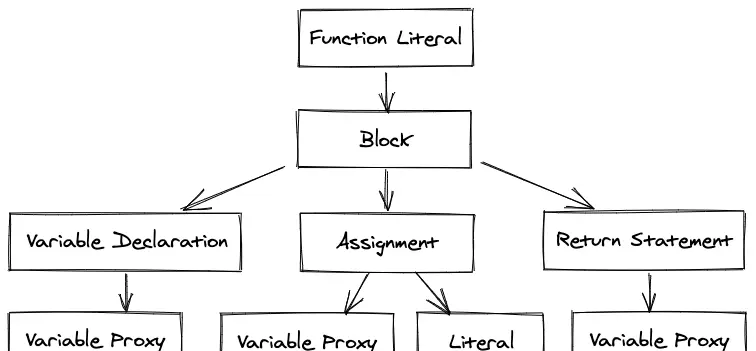

这段代码通过执行前序遍历(根节点,左子树,右子树)来执行:
- 定义
foo函数 - 声明
bar变量 - 把
1指向bar - 从函数中返回
bar
在构建AST的过程中,Parser同时还会进行作用域分析。在作用域分析过程中,Parser确定每个变量的作用域(例如,是局部变量、全局变量还是闭包中的变量)并处理相关的作用域链。这个过程中,VariableProxy节点在AST中被创建,用于表示变量的引用。
对词法分析得到的tokens进行语法分析后得到的AST为:
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "x"
},
"init": {
"type": "Literal",
"value": 5,
"raw": "5"
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
二,字节码生成
V8的解释器(Interpreter)名为Ignition,它会将AST转换成ByteCode(字节码),这是一种介于AST和机器码之间的中间表示形式,专为快速解释执行设计,由于需要通过解释器执行或编译成机器码,其执行速度通常比直接执行机器码更慢。
三,代码执行与优化
- 执行:
Ignition解释执行生成的字节码,这是JavaScript代码首次运行的形式。在执行的同时,V8会收集类型信息,为后续的优化编译提供数据。 - 优化:基于收集到的类型信息,然后V8的
JIT编译器TurboFan会将“热点代码”(经常执行的代码)编译成优化的机器代码,以提高执行效率。 - 去优化:在执行过程中,如果V8发现对象的结构被动态修改了,那么优化之后的代码势必会变成无效的代码,这时候就需要执行
去优化操作,经过去优化的代码,下次执行时就会回退到解释器解释执行。
解析执行,以及优化去优化过程如下图所示:
四,垃圾回收
V8使用了一种高效的垃圾回收机制来管理内存。它主要使用了分代垃圾回收策略,将对象分为新生代和老生代,分别使用不同的算法来进行内存回收,如副垃圾回收器(Scavenger)处理新生代对象的回收,而标记-清除(Mark-Sweep)、标记-压缩(Mark-Compact)算法则用于老生代对象。
即时编译(JIT)
为了执行你的代码,编程语言需要被翻译成机器码。
提前(Ahead-of-Time)编译
AOT编译指的是在程序运行之前将代码转换为机器码的过程。由于代码已经预先被编译成了二进制,因此它可以直接执行,无需等待JIT编译器的预热,从而减少了应用程序的首次运行慢的体验。C++,Java都是使用的这种方式。
解释执行
动态类型语言(如JavaScript,Python)一般都采用解释执行的方式,代码的每一行都会在运行时执行,代码在执行前无法准确的知道变量的确切类型。
可以看出,提前编译有利于整体评估代码来进行更好的优化,并生成性能更好的代码。而解释执行在实现上更简单,但它比提前编译的方式更慢。
即时(Just-in-Time)编译
为了同时兼具这两者的优点,JIT应运而生。在使用解释执行作为基础方法的同时,V8会监测热点代码并利用当前类型信息去编译来做优化,通过将热点代码编译成高效的机器码可以显著提高程序的执行速度。然而当类型发生变化时,我们需要对编译后的代码进行去优化,并改为退回到解释执行。
文章参考
原文链接:https://juejin.cn/post/7339791953784520731 作者:骨汤叉烧粥