
前言
3月的第一个开头,失业已久的我参加了一次线下面试,很有意思的是,这一次面试直接是开发+项目经理+HR,一轮到底。
具体结果暂不知道,但是我的回答确实一般般。总而言之,言而总之,面试复盘还是不能少,起码这一次知道了自己还有很多不足可以改进。


业务
表格获取大数据量,如何渲染
这个问题我首先答的是分页,毕竟这个最简单后端查一下表即可,也是业务中最常用的。
即使后端没有做分页,前端做分页也不是不行(除非万不得已,我从不前端分)。
PS:之前在重构时,确实因为时间关系,没有改造一处老代码,所以使用了前端分页。同时联合左树右穿梭框,这个组件的逻辑相当感人,改一处就是一个bug。
同时在前端直接渲染的情况下,我们肯定是可以用到虚拟滚动的,目前业内大部分组件库都有。
但是在查找了众多资料之后,发现似乎对于这块没有太好的业务处理办法?
- 使用虚拟滚动:当数据量非常大时,可以使用虚拟滚动的方式来进行渲染,即只渲染可视区域的数据。这样可以大大减少DOM节点的数量,提高性能。
- 使用分页:可以将数据进行分页处理,每次只加载一部分数据,这样可以提高渲染性能。
- 使用
Object.freeze():在Vue中,所有的数据都是响应式的,Vue会为每一个数据对象创建getter和setter,这在数据量大的时候会造成性能问题。如果你的数据不需要响应式,可以使用Object.freeze()来冻结数据,防止Vue将其转换为响应式。例如:
this.list = Object.freeze(list);
这时,说到虚拟滚动,面试官就来劲了!
表格中合并单元格因为虚拟滚动导致显示不全如何解决?
问:在使用虚拟滚动的表格中,合并单元格可能会导致显示问题。这是因为虚拟滚动的实现方式是只渲染可视区域的数据,而合并的单元格可能会跨越多个可视区域,从而导致显示不全的问题。
啊?我真没用过合并单元格。。。硬着头皮聊吧。
我个人认为这块要不就不用,要不就告诉表格,哪块需要联合渲染,从而不出现异常。
然后我回来了解了一下,也找到了一个github的issue,但感觉不太像是面试官想要的正确答案,有了解的大佬评论区说一下。
-
调整滚动策略:尝试调整滚动的实现方式,使其能够更好地处理合并的单元格。例如,你可以尝试在滚动时保持合并的单元格完全可见。
-
动态调整单元格大小:在滚动时动态调整合并单元格的大小,使其始终适应可视区域。
-
避免在使用虚拟滚动的表格中合并单元格:如果可能,你可以考虑避免在使用虚拟滚动的表格中合并单元格。虽然这可能会影响到表格的布局和视觉效果,但它可以避免由于单元格合并而导致的显示问题。
-
使用其他的表格库或工具:如果你的表格库或工具无法很好地处理这个问题,你可以考虑使用其他的表格库或工具。例如,有些表格库可能已经解决了这个问题,或者提供了更多的选项来处理合并单元格和虚拟滚动。
合并单元格并且冻结列 在虚拟滚动时不能共存 · Issue #970 · x-extends/vxe-table · GitHub.
前端如何在本地实现大数据量搜索,例如搜索1w条数据中name为gis?
上一个问题回答的不是特别好,而面对这一个问题,我也紧张兮兮的,大概只答出了使用map和原生方案。
其余方案我觉得比较好的可能是用模糊搜索算法,都了解一下吧:
-
分组插入数据:如果数据量太大,您可以将数据分组插入页面。例如,一次性插入100条数据,然后根据用户的搜索条件进行过滤和展示。
-
使用索引:如果您的数据是静态的,可以在加载数据时创建一个索引,以便快速搜索。例如,将
name字段作为索引,存储在一个对象中,然后根据用户输入的关键词在索引中查找匹配项。 -
使用Web Workers:如果您需要在主线程之外进行搜索操作,可以使用Web Workers。Web Workers是在后台运行的独立线程,不会阻塞主线程的执行。
-
本地存储:如果数据量不是很大,您可以将数据存储在本地,例如使用
localStorage或IndexedDB。然后在本地进行搜索操作。
如果是用数组原生方案,以下是一个简单的示例:
<template>
<div>
<input v-model="searchKeyword" @input="handleSearch" placeholder="Search...">
<ul>
<li v-for="item in filteredData" :key="item.id">{{ item.name }}</li>
</ul>
</div>
</template>
<script>
export default {
data() {
return {
data: [], // 假设这里是1万条数据
searchKeyword: ""
};
},
computed: {
filteredData() {
// 根据关键词过滤数据
return this.data.filter(item => item.name.includes(this.searchKeyword));
}
},
methods: {
handleSearch() {
// 处理搜索逻辑
// 可以在这里使用防抖函数
}
}
};
</script>
如何设置localStorage的过期时间
我当时脑子里面就嗡嗡的,啊?localStorage这个东西还能设置过期时间,过期时间不是cookie的吗?
到家之后我就查呀查,果然这个东西就是面试官挖出来的坑,怎么会有嘛。

大致了解了这个方案,就是将过期时间和value一起存入,下次取出来的时候,就知道这个值是否过期了,给大家推荐我看到的方案,在这里就不cv了:
面试官: 如何让localStorage支持过期时间设置? – 掘金
cookie是怎么设置,为什么浏览器会将cookie带到请求中发给后端?
这是两个问题,怎么设置这个很简单,大家只要日常有用到cookie的都会。
Set-Cookie可以让后端直接将cookie写入到浏览器(当然,需要浏览器不关闭cookie的使用,默认开启),例如:

难就难在如果你不了解cookie是怎么带上去的,就只回答了一半,很难受,比如我这个小菜鸡就只回答了一半。
那么cookie是怎么带上去的呢?
根据其余博主写的文章中总结就是:
前提:默认开启cookie的使用。
-
同源请求(同一域名):自动携带,并且服务端需要设置响应头
Access-Control-Allow-Credentials: true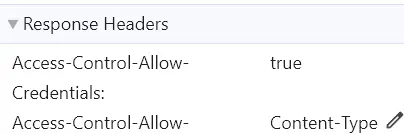
-
非同源请求(跨域请求):需要自己设置
credentials,具体怎么设置呢?但是有一点哈,跨域带cookie非常危险。
例如ajax:
axios.get('http://server.com', {withCredentials: true})

canvas在vue里面怎么使用?
在Vue.js中使用Canvas可以通过以下步骤进行:
- 在Vue组件中引入Canvas元素,可以使用
<canvas></canvas>标签或者通过<div>元素动态创建Canvas。 - 在Vue组件的
mounted生命周期钩子函数中获取Canvas元素的上下文。您可以使用document.getElementById('canvasId')或者通过ref属性获取元素。
以下是一个简单的Vue组件示例,展示了如何在Vue中使用Canvas:
<template>
<div>
<!-- 使用ref属性获取Canvas元素 -->
<canvas ref="myCanvas"></canvas>
</div>
</template>
<script>
export default {
mounted() {
this.initCanvas();
// 当调整窗口大小时重绘canvas
window.onresize = () => {
this.initCanvas();
};
},
methods: {
initCanvas() {
console.log("初始化canvas");
const canvas = this.$refs.myCanvas;
const ctx = canvas.getContext("2d");
// 设置Canvas宽高为窗口大小
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
// 绘制Canvas内容
this.drawCanvas(ctx);
},
drawCanvas(ctx) {
// 在这里编写您的Canvas绘制逻辑
ctx.beginPath();
ctx.moveTo(20, 20);
ctx.lineTo(140, 70);
ctx.lineWidth = 1.0;
ctx.strokeStyle = "#cc0000";
ctx.stroke();
}
}
};
</script>
vuex和pinia的区别,pinia为什么要删除vuex的mutations方法?
面试官:

Vuex 和 Pinia 的区别
-
数据结构:
- Vuex:使用模块化的方式来组织状态,包括
state、mutations、actions和getters。 - Pinia:更简洁,只有
state、actions和getters,没有mutations。
- Vuex:使用模块化的方式来组织状态,包括
-
同步和异步操作:
- Vuex:支持同步和异步的
mutations和actions。 - Pinia:只有异步的
actions,没有同步的mutations。这是因为同步的mutations可能导致状态变更不可追踪,而异步的actions更容易进行状态管理。
- Vuex:支持同步和异步的
-
体积和性能:
- Vuex:相对较大,适用于大型、复杂的应用程序。
- Pinia:非常轻量级(体积约 1KB),适用于中小型应用。
pinia为什么要删除vuex的mutations方法
其实我还是赞同大部分人了解的,pinia的actions同步异步都支持,而且mutation确实冗余,我们直接上官方图:

composition-api函数式编程和面向对象编程的不同。
-
数据处理方式:
- 函数式编程:强调使用纯函数(Pure Functions),即输入相同,输出也相同,没有副作用。它关注数据的转换和处理,避免共享状态和可变数据。
- 面向对象编程:将数据和操作封装在对象中,通过方法调用来处理数据。它关注对象之间的交互和继承。
-
数据不可变性:
- 函数式编程:鼓励使用不可变数据,避免直接修改原始数据。
- 面向对象编程:通常使用可变数据,通过方法来改变对象的状态。
-
代码组织方式:
- 函数式编程:更加模块化,强调函数的组合和复用。函数是一等公民,可以作为参数传递和返回值。
- 面向对象编程:更加面向业务逻辑,强调对象之间的关系和继承。类和对象是核心概念。
-
状态管理:
- 函数式编程:通常使用不可变数据结构来管理状态,例如Redux中的不可变状态树。
- 面向对象编程:使用类和对象来管理状态,例如Vue中的响应式数据。
-
代码风格:
- 函数式编程:更加函数式,注重表达式和纯函数的组合。
- 面向对象编程:更加面向对象,注重类、继承和方法的调用。
总之,两者并不是对立的,而是可以结合使用。在现代前端开发中,Vue 3的Composition API借鉴了函数式编程的思想,提供了更灵活的组合方式,同时也保留了面向对象编程的特性。选择适合项目需求的编程范式是关键,而不是死板地追求某一种方式。
我认为这两篇文章也写的很好,分享:
PC端的Vue中如何实现移动端的onload函数,仅在第一次加载时执行一次,之后不再执行?(例如:单点登录后加载,但是重复刷新页面后不加载)
emmm,说实话,这块我也是在已读乱答,了解到需求之后,我回答的逻辑是
- 放在created生命周期里面
- 标识放在Vuex或者pinia里面做全局变量
但面试官说,要刷新之后也知道是第2次进来,我就说放在localstorage里面。
其实回来之后我又想到为啥不写到cookie,后端在读到这个cookie的时候就下发一个字段,前端识别到之后不再处理逻辑。
总之就是做持久化保存,不知道大家认为对不对?
我看网上的一些答案,也差不多呀。。。
- 使用
localStorage或sessionStorage:在onload函数中,检查是否已经执行过。如果已经执行过,将一个标志位存储在localStorage或sessionStorage中,以便后续判断。例如:
export default {
data() {
return {
hasLoaded: false
};
},
mounted() {
if (!this.hasLoaded) {
// 执行初始化操作
this.doInitialLoad();
this.hasLoaded = true;
}
},
methods: {
doInitialLoad() {
// 在这里执行只需在第一次加载时执行的操作
}
}
};
- 使用
beforeCreate钩子:将只需在第一次加载时执行的操作放在beforeCreate钩子中。这样,每次组件被创建时都会执行,但只有在第一次加载时才会执行初始化操作。
export default {
beforeCreate() {
// 在这里执行只需在第一次加载时执行的操作
this.doInitialLoad();
},
methods: {
doInitialLoad() {
// 在这里执行只需在第一次加载时执行的操作
}
}
};
- 使用
created钩子和标志位:在created钩子中执行初始化操作,并使用一个标志位来判断是否已经执行过。例如:
export default {
data() {
return {
hasLoaded: false
};
},
created() {
if (!this.hasLoaded) {
// 执行初始化操作
this.doInitialLoad();
this.hasLoaded = true;
}
},
methods: {
doInitialLoad() {
// 在这里执行只需在第一次加载时执行的操作
}
}
};
如何实现表格中的树已经加载了,但是在刷新页面之后仍然展示上一次加载的数据?
-
本地存储(LocalStorage 或 SessionStorage):将状态存储在本地浏览器中。当页面刷新时,您可以从本地存储中获取状态并还原应用程序的状态。请注意,本地存储的数据会一直保留,直到用户手动清除或浏览器缓存过期。
-
服务端存储:将状态存储在服务器上,而不是仅存在于前端内存中。当页面刷新时,您可以从服务器获取状态并重新加载应用程序的状态。这需要与后端进行交互,但可以确保状态的持久性。
-
URL 参数:将状态信息作为 URL 参数传递。当页面刷新时,您可以从 URL 参数中获取数据并还原应用程序的状态。
-
Cookies:将状态信息存储在 Cookie 中。这样,即使页面刷新,您也可以从 Cookie 中读取数据并还原应用程序的状态。
G6大数据量如何优化
这块没得说,G6底层源码确实写的也一般,我常用的就是分步渲染,丢到下一个宏任务里去。不过看到网上说,能够局部刷新和Web Workers时,我感觉我新世界大门又打开了。
-
分层渲染:将图形数据分层,只渲染当前视窗内的数据,而不是一次性渲染所有节点和边。这可以减少渲染的工作量。
-
虚拟化:只渲染可见区域内的节点和边,而不是整个图。这可以通过设置视窗大小和缩放级别来实现。
-
局部刷新:仅重新渲染发生变化的部分,而不是整个图。例如,当用户拖动或缩放图时,只更新可见区域内的节点和边。
-
使用Web Workers:将图形渲染操作放在Web Workers中,以便在后台线程中执行,不会阻塞主线程。
-
GPU加速:使用支持GPU加速的布局算法,例如Fruchterman布局。在大规模数据时,GPU布局的性能通常更好。
-
数据聚合:对于大量数据,可以考虑数据聚合,例如将多个节点合并成一个聚合节点,以减少渲染的节点数量。
-
性能测试和分析:使用Chrome DevTools的Performance面板来分析性能瓶颈,并查看哪些操作占用了大部分时间。
为此我找了一些关于G6渲染大数据量的优化方案给大家详细了解:
项目管理:
敏捷项目中使用的项目管理工具
我确实在23年3月考完PMP之后,很长时间没有再将PMP的知识点进行复习了。
像其他的管理方案,敏捷项目管理也分为不同的阶段,例如:
- Scrum:Scrum 是一种流行的敏捷方法,强调团队协作、迭代开发和持续交付。它包括角色(Scrum Master、Product Owner、开发团队)、仪式(Sprint Planning、Daily Standup、Sprint Review、Sprint Retrospective)和工件(Product Backlog、Sprint Backlog、Increment)。
详细请看:What is Scrum? | Scrum.org. - 看板:看板是一种敏捷项目管理工具,它使用可视化任务板来管理项目。每个任务都有一个状态标签,表示任务的当前状态。看板可以帮助团队可视化任务的状态,并推动团队完成任务。
- FDD(特性驱动开发)和TDD(测试驱动开发),将开发过程分解为小的功能特性或者测试点,从而达到逐步完成的目的,它们也都是很好的工具。
- 甚至还有XP(极限编程):XP 是一种软件开发方法,强调测试驱动开发、持续集成、结对编程、简单设计和迭代开发。它适用于高度协作的团队。
- 或者更加离谱的“日不落编程”,指的是东半球的程序员开发完成之后,交给西半球的程序员,从而达到这个系统每时每刻都在开发。
算法
长数字转财务格式的算法
说实话算法这一块我实在是没有刷过多少题,斐波那契数列算是我的极限水平(经典算法:爬楼梯,入室抢劫)。
比大部分掘金的大佬都菜。
所以我大致只想到能够转为字符串或者转为数组,但是面试官强烈要求说一些算法,我比较懵,如果有懂的大佬,可以告诉我一下。
我想到的方案如下:
-
添加千位分隔符:
- 将数字转换为字符串。
- 从右向左遍历字符串,每隔三位插入一个逗号(或其他千位分隔符)。
-
保留小数位数:
- 如果您需要保留小数位数,可以使用四舍五入或截断的方式。
- 将数字转换为字符串。
- 使用适当的方法来处理小数位数,例如使用
toFixed()函数。
以下是一个示例的JavaScript代码,演示了如何将长数字转换为财务格式:
function formatNumberToFinance(number, decimalPlaces) {
// 将数字转换为字符串
const numStr = number.toString();
// 添加千位分隔符
let formattedStr = '';
let count = 0;
for (let i = numStr.length - 1; i >= 0; i--) {
formattedStr = numStr[i] + formattedStr;
count++;
if (count % 3 === 0 && i > 0) {
formattedStr = ',' + formattedStr;
}
}
// 处理小数位数
if (decimalPlaces > 0) {
formattedStr = parseFloat(formattedStr).toFixed(decimalPlaces);
}
return formattedStr;
}
// 示例
const longNumber = 1234567890.1234567;
const financeFormat = formatNumberToFinance(longNumber, 2);
console.log(financeFormat); // 输出:1,234,567,890.12
总结
这次面试还是发现自己的日常总结不到位,经常使用的方案可以再复习一下。
还有算法要刷了,哭死!
还有CSS,这块我想是大部分前端开发的痛点,我也得复习一下了(虽然这次没问)。
原文链接:https://juejin.cn/post/7341408996597448723 作者:狗子爱吃草莓