

前言
你是否被问到过为何第二次打开百度官网速度比之前快,其实这个问题就是http的缓存问题,本期文章就带大家深入认识这两个缓存,让你明白如何实现,以及二者带来的效果,优缺点……
为了方便理解两个缓存,容我这里介绍下内容协商机制,顺便模拟一个情景,让你更好理解请求头响应头
http内容协商
这里我用node的http和url模块来实现,获取前端请求数据时的url,然后判断,若是指定的路径则返回hello world给前端
url模块用于做url路径的解析,类似koa-router路由
const http = require('http')
const url = require('url') // url模块 做url路径的解析
const server = http.createServer((req, res) => {
const { pathname } = url.parse(`http://${req.headers.host}${req.url}`)
if (pathname === '/') {
res.end('<h1>hellow world</h1>')
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
这样,我直接访问localhost:3000根路径就可以拿到后端的数据
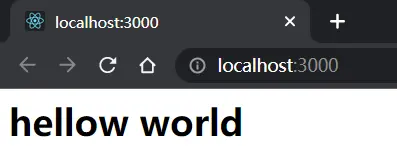

或许你会疑问,我向前端返回的不是个
html语句吗,怎么被解析了出来?因为这里我并没有设置响应头的格式,浏览器端会默认将html语句解析出来我可以往头部加个
'Content-Type': 'application/json'字段,这样就会读成json格式了
再判断下,若是其他路径返回not found 且404
const http = require('http')
const url = require('url')// url模块 做url路径的解析
const server = http.createServer((req, res) => {
const { pathname } = url.parse(`http://${req.headers.host}${req.url}`)
if (pathname === '/') {
res.writeHead(200, { 'Content-Type': 'application/json' })
res.end('<h1>hellow world</h1>')
} else {
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
如图
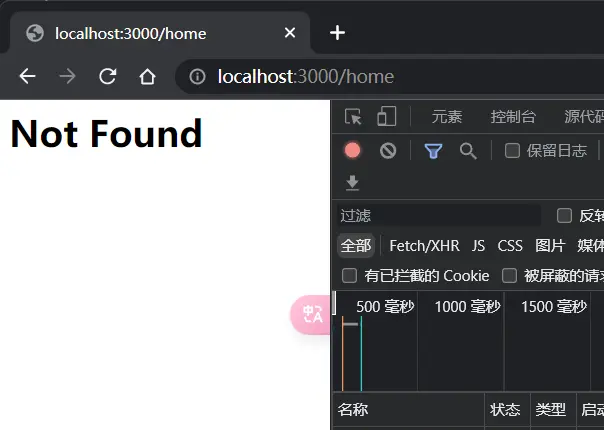
好了,这就是很简单的一个http服务
http1.0为何要搞个响应头,请求头?
这就是因为后端返回前端的文件格式不可能是一种,为了方便前端解析数据,请求头中就写入这些字段信息告诉前端应该以何种格式去读取后端返回的数据
内容协商是什么
请求头和响应头就是http的内容协商机制,很好理解,就是前后端协商好如何解析数据
另外,其实前端是可以告诉后端我期望接收到的是什么数据,后端拿到req.headers.accept可以看到前端期望的格式,前端没写就是默认的,如下这样

因此后端拿到这个数据后可以判断是否有指明的格式,比如json,前端表明需要这个格式,我就返回一个数据给前端
下面我继续改下,如果想要的东西没有json格式,我就返回一个html语句给前端
const http = require('http')
const url = require('url')// url模块 做url路径的解析
const responseData = {
ID: '2003',
Name: '海豚',
RegisterDate: '2024年3月30日'
}
function toHTML(data) { // 将数据转成html语句
return `
<ul>
<li><span>账号:</span><span>${data.ID}</span></li>
<li><span>昵称:</span><span>${data.Name}</span></li>
<li><span>注册时间:</span><span>${data.RegisterDate}</span></li>
</ul>
`
}
const server = http.createServer((req, res) => {
const { pathname } = url.parse(`http://${req.headers.host}${req.url}`)
if (pathname === '/') {
const accept = req.headers.accept
if (accept.indexOf('application/josn') !== -1) {
res.writeHead(200, { 'Content-Type': 'application/json' })
res.end(JSON.stringify(responseData)) // 响应数据无法以对象传输,因此要先转成json格式
} else { // 前端想要的数据不是json,那么我就把这个html语句给前端,并告诉前端以html格式加载
res.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8' })
res.end(toHTML(responseData))
}
} else {
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
}
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
字符串也是有
indexOf这个api的,同数组一致,不存在就是-1
前端因此访问根路径就可以拿到html
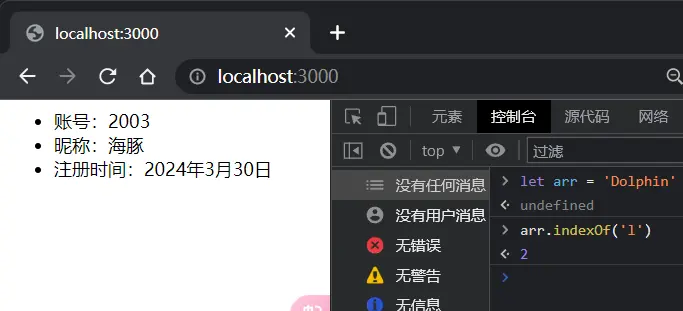
现在你对内容协商已经有了更深刻的认识了,就是通过请求头和响应头一起商量着来如何处理数据格式
接下来我们聊聊如何使用http服务向前端返回一个静态资源文件,这就是早期的前后端不分离开发方式,当初的前端工作量很少,就是切图仔,切好页面后给到后端java,后端将java嵌到页面中,然后返回给浏览器用户
不分离开发方式不
low,它也可以把页面写的很精致,问题主要是出在前端工作量太少了,导致开发效率很低。前后端不分离的开发方式也就是服务端渲染
后端返回静态资源文件给前端
这里实现的过程中顺带写了很多用不上的模块,纯粹是为了复习node,不愿意看的小伙伴可以直接跳到缓存那里
接下来,我写一个html文件,里面放上一个本地图片。这个html文件就是一个静态文件,现在我需要前端访问localhost:3000/index.html时,前端可以拿到这个页面
这就需要后端node再引入fs模块,读到html文件,并且需要拿到前端输入的url,这需要用上path模块解析出绝对路径最后读取到整个文件的绝对路径,然后判断资源是否存在
再用fs.statSync拿到文件的详细信息,比如创建时间修改时间等;还可以判断一下前端请求的资源是文件还是文件夹,若是文件夹可以拼接一下,若是文件,就把文件读到返回给前端,文件被读出来是一个十六进制buffer流的形式
前端是不知道buffer流这个格式的,因此后端需要重新写下响应头
const http = require('http')
const url = require('url')// url模块 做字符串url路径的解析
const path = require('path')// path 解析路径 解析绝对相对
const fs = require('fs') // 文件模块
const server = http.createServer((req, res) => {
// 将前端请求的地址转换成真实的url,再拼接www这个路径,最后读取整个文件的绝对路径
let filePath = path.resolve(__dirname,path. join('www', url.fileURLToPath(`file:/${req.url}`))) // __dirname 绝对路径 macOS 需要 ///
if (fs.existsSync(filePath)) { // 判断资源是否存在
const stats = fs.statSync(filePath) // statSync读取文件的详细参数,比如创建时间等
console.log(stats);
const isDir = stats.isDirectory() // 是文件(false)还是文件夹(true)
if (isDir) { // 文件夹
filePath = path.join(filePath, 'index.html')
}
if (!isDir || fs.existsSync(filePath)) { // 文件
const content = fs.readFileSync(filePath) // 读取文件
res.writeHead(200, { 'Content-Type': 'text/html; charset=utf-8' })
return res.end(content) // node 默认读文件就是 buffer 16进制流 并且返回给前端 前端可以读出来
}
}
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
好了,目前前端是可以拿到这个静态资源的,但是有个问题,我们检查接口的时候发现,这个图片的Response是乱码的
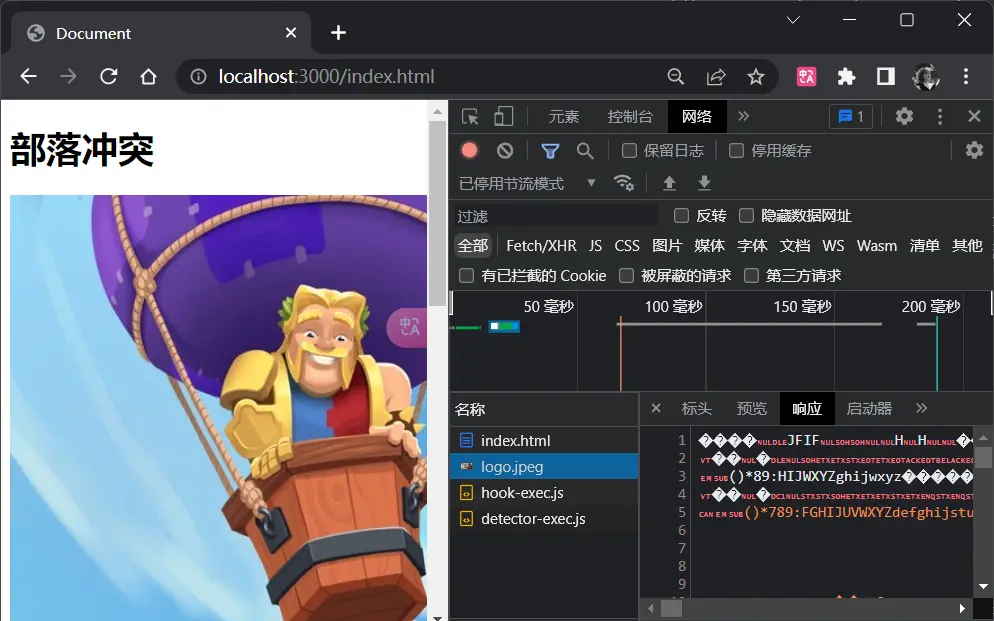
乱码也是可以理解的,刚刚后端的写法是,读到了index.html后返回的格式就是text/html,而这个图片是进入到index.html后再次请求的,这个请求我们并没有写格式
乱码依旧可以看到图片这纯粹是因为谷歌浏览器比较强大,换做是别的浏览器这个图片可能就加载不出了
解决图片乱码
解决这个问题我们可以拿到请求过程中的请求路径,比如这里的图片是jpeg格式,那么就可以拿到jpeg,用上path.parse(filePath)进行解构,拿到ext即可
const http = require('http')
const url = require('url')// url模块 做字符串url路径的解析
const path = require('path')// path 解析路径 解析绝对相对
const fs = require('fs') // 文件模块
const server = http.createServer((req, res) => {
// 将前端请求的地址转换成真实的url,再拼接www这个路径,最后读取整个文件的绝对路径
let filePath = path.resolve(__dirname,path. join('www', url.fileURLToPath(`file:/${req.url}`))) // __dirname 绝对路径
if (fs.existsSync(filePath)) { // 判断资源是否存在
const stats = fs.statSync(filePath) // statSync读取文件的详细参数,比如创建时间等
console.log(stats);
const isDir = stats.isDirectory() // 是文件(false)还是文件夹(true)
if (isDir) { // 文件夹
filePath = path.join(filePath, 'index.html')
}
if (!isDir || fs.existsSync(filePath)) { // 文件
const content = fs.readFileSync(filePath) // 读取文件
const { ext } = path.parse(filePath) // 解析路径
if (ext === '.jpeg') {
res.writeHead(200, {'Content-Type': 'image/jpeg'})
} else {
res.writeHead(200, {'Content-Type': 'text/html; charset=utf-8'})
}
return res.end(content) // node 默认读文件就是 buffer 16进制流 并且返回给前端 前端可以读出来
}
}
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
好了,现在图片没有乱码了,正常情况下就是不会显示任何东西
但是问题来了,请求到页面后,页面会有很多种格式,难道每个格式都分别判断下然后给特定的格式吗,自己写肯定不现实,这里用轮子
mime-types
安装mime-types,他可以帮我们自动识别前端请求的文件格式,然后后端写入响应头对应的格式
写法最终如下
const http = require('http')
const url = require('url')// url模块 做字符串url路径的解析
const path = require('path')// path 解析路径 解析绝对相对
const fs = require('fs') // 文件模块
const mime = require('mime-types')
const server = http.createServer((req, res) => {
// 将前端请求的地址转换成真实的url,再拼接www这个路径,最后读取整个文件的绝对路径
let filePath = path.resolve(__dirname,path. join('www', url.fileURLToPath(`file:/${req.url}`))) // __dirname 绝对路径
if (fs.existsSync(filePath)) { // 判断资源是否存在
const stats = fs.statSync(filePath) // statSync读取文件的详细参数,比如创建时间等
console.log(stats);
const isDir = stats.isDirectory() // 是文件(false)还是文件夹(true)
if (isDir) { // 文件夹
filePath = path.join(filePath, 'index.html')
}
if (!isDir || fs.existsSync(filePath)) { // 文件
const content = fs.readFileSync(filePath) // 读取文件
const { ext } = path.parse(filePath) // 解析路径
console.log(ext);
res.writeHead(200, { 'Content-Type': mime.lookup(ext) })
return res.end(content) // node 默认读文件就是 buffer 16进制流 并且返回给前端 前端可以读出来
}
}
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
这样,前端请求的后缀是什么,它能自动帮我们识别出对应的响应头字段格式
node-pipe
刚才给前端返回文件的时候是以node读取的buffer格式,然后res.end返回给前端,当然,其实我们也可以用node中的pipe来返回给前端,这个读取到的文件是流类型,不同于buffer
const fileStream = fs.createReadStream(filePath) // 读文件读成流类型
fileStream.pipe(res) // 将流类型资源汇入到响应体中
不过如今的新版node好像弃用掉了这个方法
好了,现在进入今天的正题,强缓存和协商缓存
强缓存
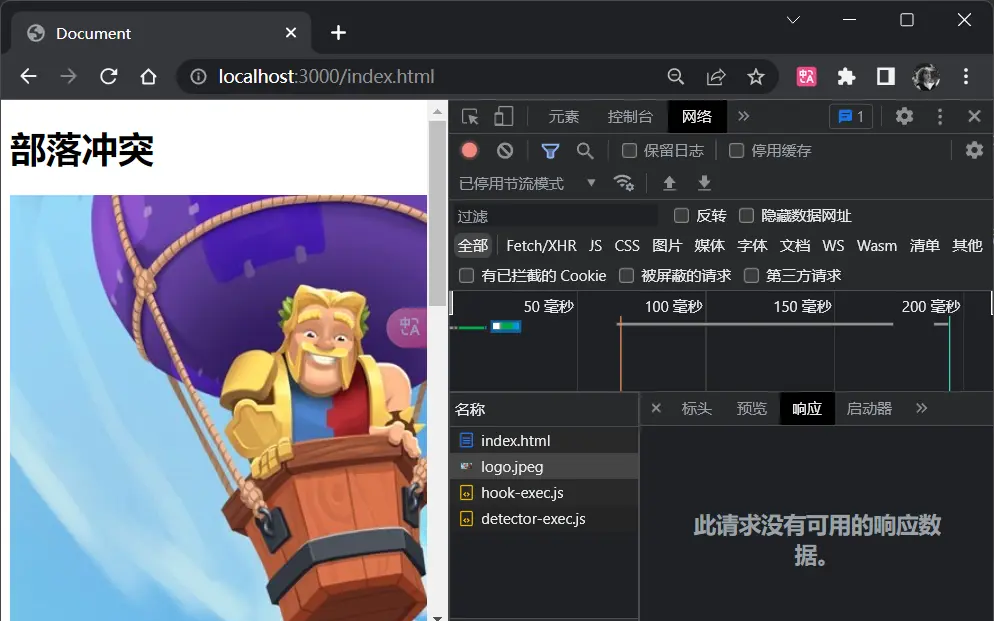
上面返回静态资源的情景已经差不多实现了,但是有个问题,我这个页面的图片就是不会去变更了,但是我每次刷新页面这个图片都会去请求一下,且耗时5ms,如下

这就像是百度的首页,百度的logo基本上不会去变更,因此也非常没有必要重新发请求拿到这个logo
我们重复刷新百度首页,检查图片的请求基本上都是耗时
0ms,这就是因为百度已经做好了http缓存
优化这个东西就是http的缓存
我们现在就去看下百度首页,刷新地址,来到result.png的请求,这就是百度的logo图标,查看标头
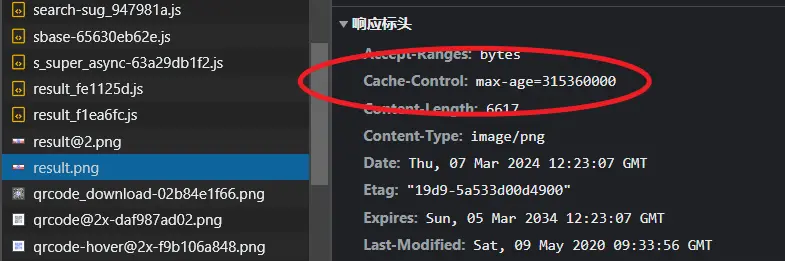
里面有个Cache-Control字段,里面有个最大期限为315360000,单位是s,我们算下是多久
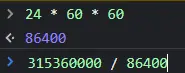
3650天,就是10年,其实这就是百度将这个请求缓存了10年,10年内不会发接口请求,拿到这个logo都是从本地中读取,因此耗时0毫秒
其实这就是强缓存
如何实现
实现起来非常简单,只需要写响应头时加入下面这个字段即可
'Cache-Control': 'max-age=xxx'
const http = require('http')
const url = require('url')// url模块 做字符串url路径的解析
const path = require('path')// path 解析路径 解析绝对相对
const fs = require('fs') // 文件模块
const mime = require('mime-types')
const server = http.createServer((req, res) => {
let filePath = path.resolve(__dirname, path.join('www', url.fileURLToPath(`file:/${req.url}`)))
if (fs.existsSync(filePath)) {
const stats = fs.statSync(filePath)
const isDir = stats.isDirectory()
if (isDir) {
filePath = path.join(filePath, 'index.html')
}
if (!isDir || fs.existsSync(filePath)) {
const content = fs.readFileSync(filePath)
const { ext } = path.parse(filePath)
res.writeHead(200, {
'Content-Type': mime.lookup(ext),
'Cache-Control': 'max-age=86400' // 一天
})
return res.end(content)
}
}
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
这里强缓存了一天,我们先看下效果
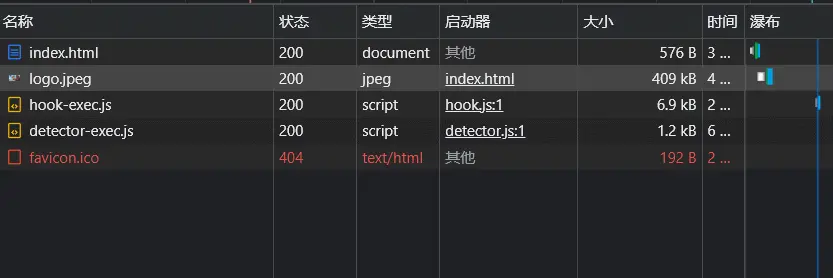
直接变成了0ms,已经实现了~
缺点
我们现在替换一个图片,命名与之前一致
我们再去刷新,大家可以先猜下浏览器那边是否会刷新?
答案是不会的,那个图片已经被缓存到浏览器本地了,服务器的资源发生变更,强缓存是不知道的
这个时候我们可以强制刷新来获取更改后的图片
强制刷新 === shift + F5
另外,大家是否发现,我后端写的强缓存,前端重新刷新,只缓存住了图片资源,index.html没有被缓存,index.html同样也是静态资源
我们查看index.html的响应头,里面同样有这个缓存字段
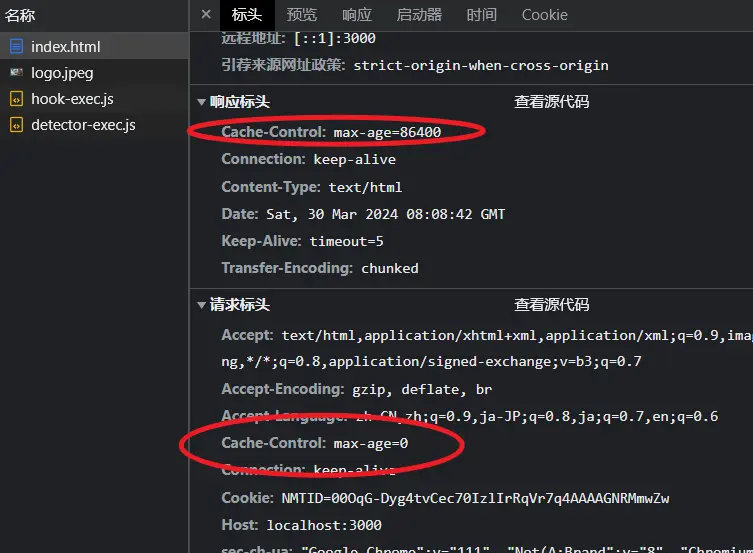
响应头有这个可以理解,请求头我们刚才并没有动啊,请求头是前端设置的,浏览器居然自动给他添加了这个字段并且max-age为0,浏览器特殊对待index.html并不是因为它是个html文件类型,而是因为这个请求是在输入url后发起的
前端发请求可以看成两部分,前部分就是输入
url后发起的get请求,之后的请求就是页面加载时碰到需要资源的请求,也就是ajax请求浏览器这么做其实也可以理解,输入
url后的请求怎么能被强缓存起来,请求的东西一定是实时的,最新的
这也是强缓存的缺陷,就是无法缓存输入url后的get请求,只能缓存
输入url的请求一定是
get请求,没有post请求
总结
实现:
设置响应头:
'Cache-Control': 'max-age=xxx'
缺点:
- 服务器资源命名不变但是文件变了,浏览器不会去更新
- 无法缓存输入
url后的的get请求
协商缓存
你肯定又会疑惑了,既然百度的logo被缓存了10年,但是每逢过节,那个logo又都会变,这是怎么做到的,说好的10年呢,10年按道理不会重新发请求了
这就要靠协商缓存来解决了
如何实现
在强缓存实现的基础上往响应头添加如下字段
'Last-Modified': stats.mtimeMs
我们再打印下stats,里面就是文件的各种信息,其中mtimeMs是文件的修改时间,ctimeMs是文件的创建时间
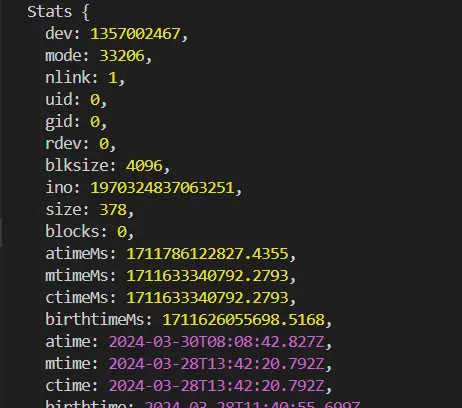
Last-Modified就是上次修改的意思,将这个字段加入到响应头给到前端有何用呢
我们查看index.html的接口请求
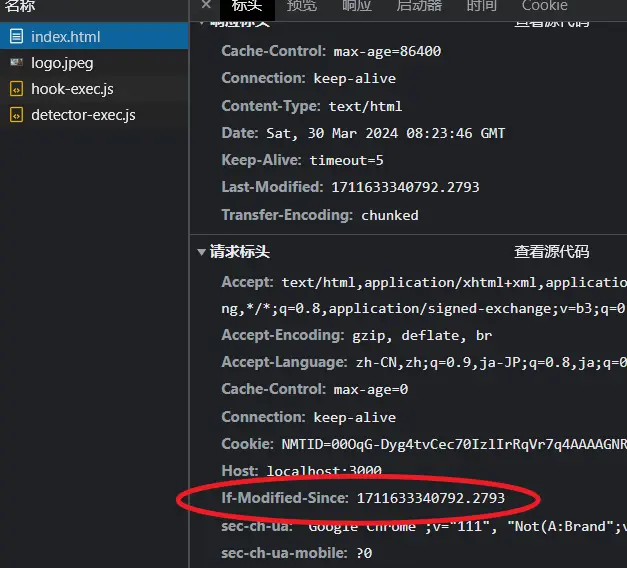
它的请求头多了个If-Modified-Since字段,并且这个字段的值就是mtimeMs,最后的数字都是2793,也就是说浏览器已经拿到了后端修改文件的时间戳
既然前端记录到了这个时间,那么我现在去index.html中添加个标题,那么它的变化就会被操作系统记录到,也就是说后端的mtimeMs就会变更,试着打印下
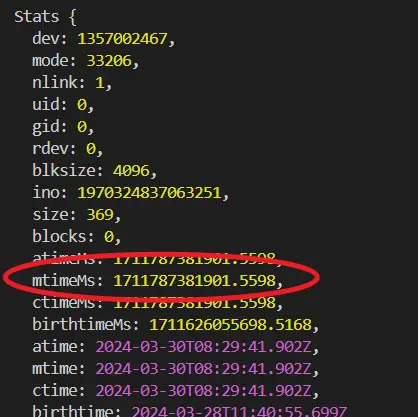
果不其然,后端的mtimeMs变了
因此我们如果拿到前端的请求头中的这个字段与后端实时的mtimeMs进行对比就可以判断出文件是否修改,没有修改就将状态码改成304,304的含义就是资源未修改
const http = require('http')
const url = require('url')// url模块 做字符串url路径的解析
const path = require('path')// path 解析路径 解析绝对相对
const fs = require('fs') // 文件模块
const mime = require('mime-types')
const server = http.createServer((req, res) => {
let filePath = path.resolve(__dirname, path.join('www', url.fileURLToPath(`file:/${req.url}`)))
if (fs.existsSync(filePath)) {
const stats = fs.statSync(filePath)
console.log(stats);
const isDir = stats.isDirectory()
if (isDir) {
filePath = path.join(filePath, 'index.html')
}
if (!isDir || fs.existsSync(filePath)) {
const content = fs.readFileSync(filePath)
const { ext } = path.parse(filePath)
const timeStamp = req.headers['if-modified-since']
let status = 200
if (timeStamp && Number(timeStamp) === stats.mtimeMs) { // 该资源没有被修改
status = 304 // 资源未修改
}
res.writeHead(status, {
'Content-Type': mime.lookup(ext),
'Cache-Control': 'max-age=86400', // 一天
'Last-Modified': stats.mtimeMs // 时间戳 资源修改的时间
})
return res.end(content)
}
}
res.writeHead(404, { 'Content-Type': 'text/html' })
res.end('<h1>Not Found</h1>')
})
server.listen(3000, () => {
console.log('listening on port 3000');
})
好了,协商缓存已经实现了,现在去看下index.html
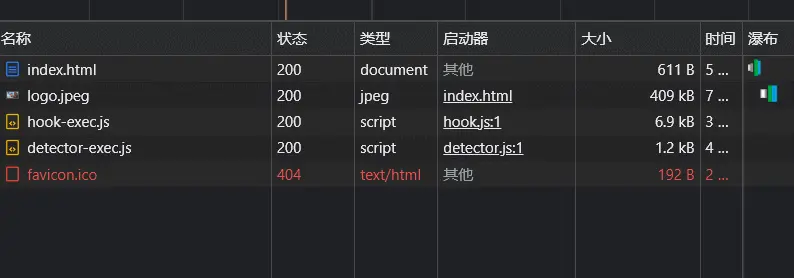
看到没,index.html的状态码变更为304,也就是说资源未修改,并且大小由原来的611B缩小到了203B
html文件不可能被缓存到大小为0
这样,但状态码为304时,浏览器就会自动从缓存中读取这个资源了
现在就解决了强缓存无法缓存输入url发的请求问题
缺点
但是协商缓存依旧无法解决服务器资源命名不变但是文件变了,浏览器不会去更新这个问题
这个问题其实解决办法是通过哈西值,就是文件名最后接一个hash值,只要资源被修改,hash值一定会变更,这样文件名就会被修改,文件名被修改,浏览器就会重新请求
还有个很少见的问题,就是我不小心修改了服务端的资源后立马反悔了,又给改成原样了,mtimeMs依旧会变,因此前端又会重新请求
这个问题的根本原因在于返回给前端的是最近一次的文件修改时间,若这个东西是文件本身就不会有这个问题了
etag
刚才说协商缓存的实现需要加上这个Last-Modified,这里我换成etag来实现,其value是签名,可以完整代表这个文件本身
这需要我们下载checksum依赖
这个依赖可以帮我们判断文件是否被修改
checksum.file(filePath, (err, sum) => {
const resStream = fs.createReadStream(filePath)
sum = `"${sum}"`
if (req.headers['if-none-match'] === sum) {
res.writeHead(status, {
'Content-Type': mime.lookup(ext),
'Cache-Control': 'max-age=86400',
'etag': sum // 签名(文件资源)也可以做协商缓存
})
} else {
res.writeHead(200, {
'Content-Type': mime.lookup(ext),
'etag': sum
})
return resStream.pipe(res)
}
})
具体实现这里就不再介绍~
总结
过程
后端先将最近修改文件的时间戳mtimeMs给到前端,前端请求头中多出一个If-Modified-Since字段,并且其值就是后端给的mtimeMs,然后后端再拿到前端的请求体中的这个字段与实时的mtimeMs进行比较,如果不一致就是说明资源变更了,正常读取数据返回给前端,如果没有变更,返回状态码304给前端,浏览器此时就会从缓存中读取静态资源
实现:
设置响应头:
'Cache-Control': 'max-age=xxx'
'Last-Modified': stats.mtimeMs
缺点:
服务器资源命名不变但是文件变了,浏览器不会去更新(通过hash值来解决)
优点:
-
可以缓存输入
url后的请求 -
服务器资源变更可以立即拿到这个资源再进行缓存
最后
像是页面的logo,我们肯定需要缓存,每次请求就会很浪费资源,因此强缓存就解决了这个问题,但是强缓存有个缺陷,输入url的get请求是无法强缓存的,一般输入url后碰到需要请求的资源可以再强缓存,强缓存还有个问题就是无法拿到服务端最新的变更,你不可能让用户去强制刷新页面
协商缓存解决了强缓存无法缓存输入url的请求这个问题,就是可以缓存输入url的请求,协商缓存的前端请求头有个if-modified-since字段(先是后端给响应头添加了last-modified字段,里面存放了时间戳),后端可以判断文件的修改时间和这个字段的时间是否一致,一致就是304未修改状态码,不一致说明静态资源发生了变更需要重新请求
如果你对春招感兴趣,可以加我的个人微信:
Dolphin_Fung,我和我的小伙伴们有个面试群,可以进群讨论你面试过程中遇到的问题,我们一起解决
另外有不懂之处欢迎在评论区留言,如果觉得文章对你学习有所帮助,还请”点赞+评论+收藏“一键三连,感谢支持!
原文链接:https://juejin.cn/post/7352075703859183667 作者:Dolphin_海豚