
导语:最近在整理前端工程化的相关资料,发现前端异常处理这一块的知识点很多,所以写个文章记录一下。
本文目录:
- 前端报错种类及如何捕获前端错误
- sourcemap原理及如何通过sourcemap做错误还原
- sentry客户端错误处理方案:raven.js 原理及实战
- sentry客户端错误处理方案升级:@sentry/brower 原理及实战
- sentry 部署实战及功能介绍
- sentry 是怎么做错误聚合的
- 总结
- 补充:VLQ编码原理
1. 前端报错种类及如何捕获前端错误
根据 MDN Web Docs 的描述,js的错误大致分为以下八个类型:
EvalError: 与全局函数 eval() 相关的错误
在当前的
ECMAScript规范中,EvalError已经被移除了,具体可用如下代码验证,可以看到抛出的错误类型其实是:SyntaxError
try {
const code = 'alert("Hello, World!"'; // 缺少右括号,导致语法错误
eval(code); // 尝试评估包含语法错误的代码
} catch (error) {
if (error instanceof SyntaxError) {
console.log('SyntaxError:', error.message);
} else {
console.log('Other Error:', error.message);
}
}
RangeError: 数值变量或参数超出其有效范围的错误
// 1. 尝试创建一个超出范围的大数组
const bigArray = new Array(Infinity);
// 2. 尝试将数组的长度设置为负数
const arr = [1, 2, 3];
arr.length = -1;
// 3. 尝试使用超出范围的月份(12)
const date = new Date(2022, 12, 1);
ReferenceError: 在作用域中找不到变量或函数引用的错误
// 1. 尝试访问未声明的变量 x
console.log(x);
// 2. 尝试访问作用域外部的变量 innerVariable
function outer() {
console.log(innerVariable);
}
outer();
SyntaxError: 语法错误导致的代码无法被解析的错误
// 1. 缺少右括号,导致语法错误
const x = 10
console.log(x;
// 2. 使用保留关键字作为变量名,导致语法错误
const let = 5;
// 3. 引号不匹配,导致语法错误
const str = "Hello, World!';
TypeError: 类型错误
// 1. 尝试将非函数类型的值作为函数调用,导致类型错误
const num = 42;
num();
// 2. 尝试在 null 值上设置属性,导致类型错误
const obj = null;
obj.property = 42;
URIError: 使用全局 URI 相关函数时,传递了格式错误的参数导致的错误
当尝试使用
decodeURI()、decodeURIComponent()、encodeURI()或encodeURIComponent()等全局 URI 相关函数处理格式不正确的 URI 字符串时,可能会抛出URIError。
const invalidChar = '\uD800'; // 无效的 Unicode 字符
const encoded = encodeURIComponent(invalidChar); // 尝试对无效字符进行编码,导致 URIError
AggregateError: 用于表示多个错误的聚合
Promise.any([
Promise.reject('error 1'),
Promise.reject('error 2'),
Promise.reject('error 3')
])
.catch(error => {
console.log(error instanceof AggregateError);
console.log(error.errors);
console.log(error.message);
});
InternalError: ❗️非标准类型,一般是引擎内部错误的异常抛出,出现的概率很小,非业务代码造成,这里就不展开了。
那遇到上述的八种类型,如何捕获和抛出错误呢?没错,正是我们开发中经常用到的 try-catch 使用 try-catch,可以捕获代码中的错误,使程序在遇到异常时不会中断执行并且可以对捕获的错误做出一定的处理。
❗️注意:try-catch 只能捕捉指定代码块中的同步错误,异步的错误是捕获不到的,需要使用window.onerror 的方式,如下:
// try-catch捕获不到
try {
setTimeout(() => {
throw new Error('Async error');
}, 10);
} catch (error) {
console.log('Caught async error:', error);
}
// window.onerror 可以
window.onerror = function(message, source, lineno, colno, error) {
console.log('Caught async error:', error);
};
setTimeout(() => {
throw new Error('Async error');
}, 10);
但某些情况下有try-catch 和 window.onerror都捕获不到的错误:
Promise.reject(new Error('Something is wrong'));
需要使用 onrejectionhandled来处理
window.addEventListener('unhandledrejection', function(event) {
console.log('Unhandled promise rejection error:', event.reason);
});
Promise.reject(new Error('Something is wrong'));
通过这一部分,我们对报错类型及捕获方式有了一个大体的认识,根据捕获到错误的堆栈信息,我们可以很快看出问题所在,但往往有的时候事与愿违,相信很多时候大家在实际项目中都捕获过如下错误信息:
查?这查个鸡毛🪶??? 一句像极了爱情的你错了,自己想去吧!!!
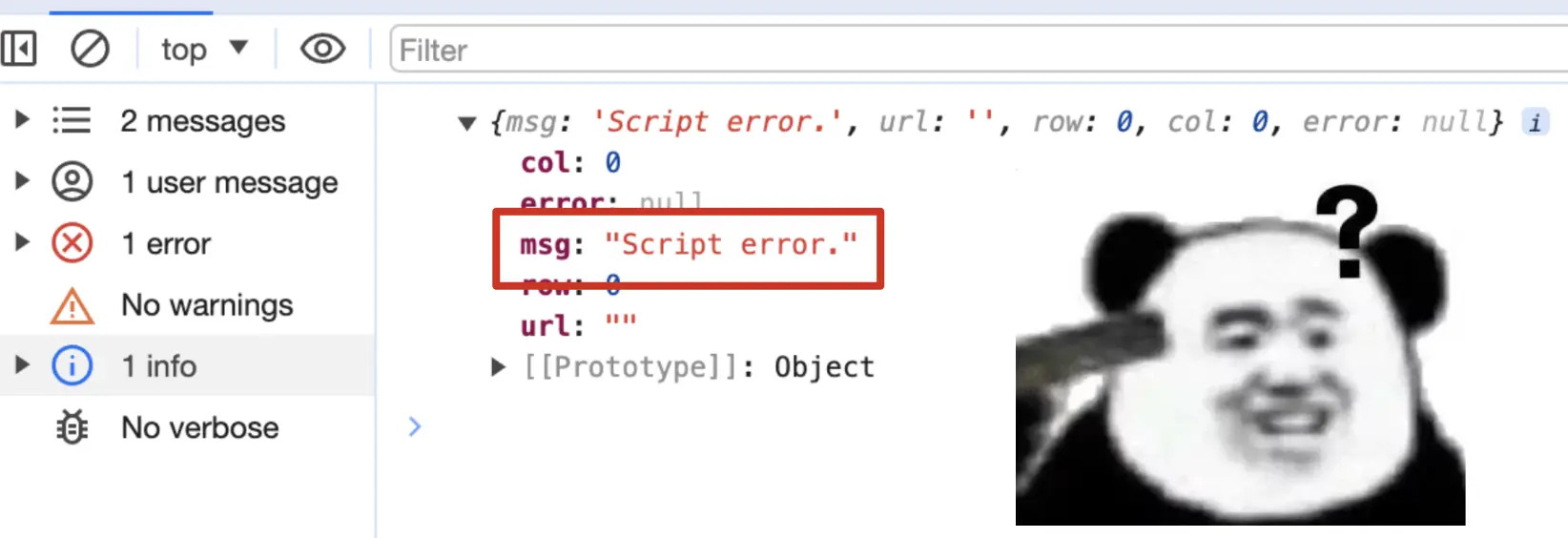

下面就结合实际代码具体说一说如何处理这种 Script error 的情况:
首先,我们了解下出现 Script error 的原因:
Script error是浏览器在同源策略限制下所产生的。浏览器出于安全上的考虑,当页面引用的非同域的外部脚本中抛出了异常,此时本页面无权限获得这个异常详情, 将输出 Script error 的错误信息。
我们结合下具体代码来看:
DEMO: github.com/ycvcb123/re…
执行方法:
npm i/npm run start
cro-domain-resources.js:
setTimeout(() => {
console.log(a.b);
})
index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
</head>
<body>
<script>
window.onerror = function (msg, url, row, col, error) {
console.log({msg, url, row, col, error});
};
</script>
<script src="http://127.0.0.1:8081/cro-domain-resources.js"></script>
</body>
</html>
将上述两个文件放在不同的文件夹下,cro-domain-resources.js所在文件夹下通过http-server -p 8081启动服务,index.html所在文件夹下通过http-server -p 8080启动服务,访问 http://127.0.0.1:8080 就能看到window.onerror捕捉到了一个Script error的错误,却无法看到具体的报错信息。这种正是刚才所提到的由浏览器同源策略限制所产生的跨域脚本执行异常
在这种情况下如何获取详细的报错信息呢?
-
script标签上添加crossorigin; - 请求响应头中添加
Access-Control-Allow-Origin;
index.html
<!--省略-->
<script src="http://127.0.0.1:8081/cro-domain-resources.js" crossorigin></script>
<!--省略-->
express.js
// 省略...
// 使用 CORS 中间件
app.use(cors({
origin: 'http://127.0.0.1:8080'
}));
// 省略...
详细代码见:github.com/ycvcb123/re…
下载后,执行npm i和npm run cors,再次访问 127.0.0.1:8080,发现Script error. 已经变成具体的报错信息:
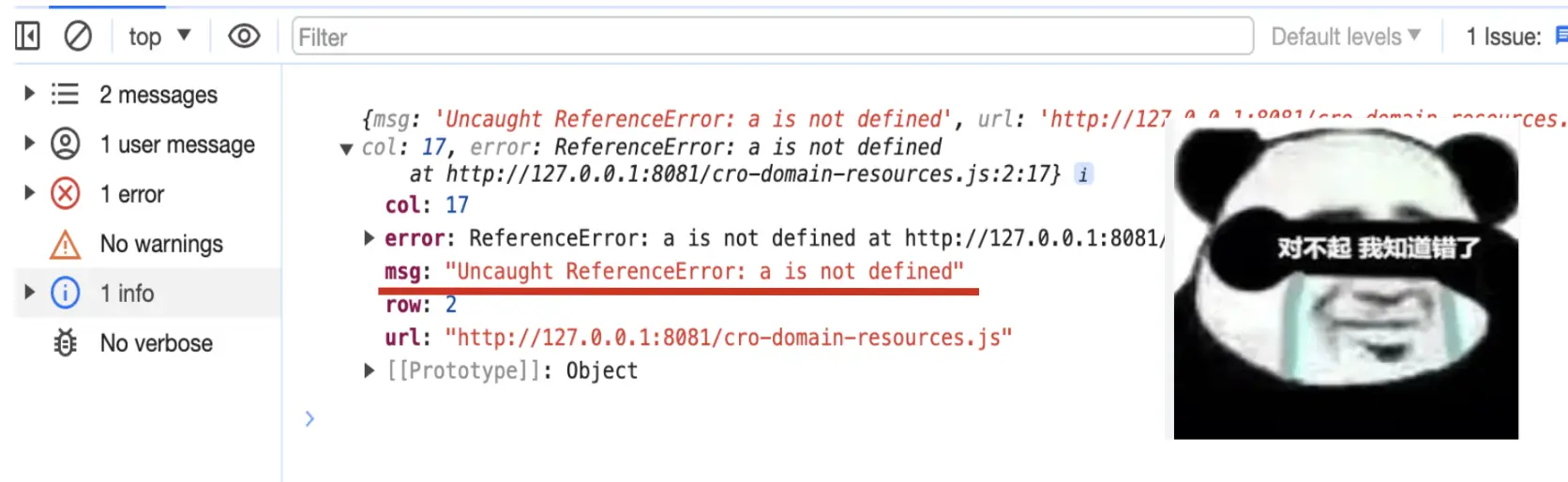
到此第一部分算是差不多完结了,在这一部分,我们了解了javascript错误的分类,捕获错误的方式以及script error问题发生的原因和处理办法。
但随着前端工程化的发展,在实际工作中,为了减小文件大小、增加代码的安全性和提高代码的执行效率,往往线上的代码都是压缩混淆合并后的,即使捕获到了错误信息也很难找到对因出问题的具体位置。
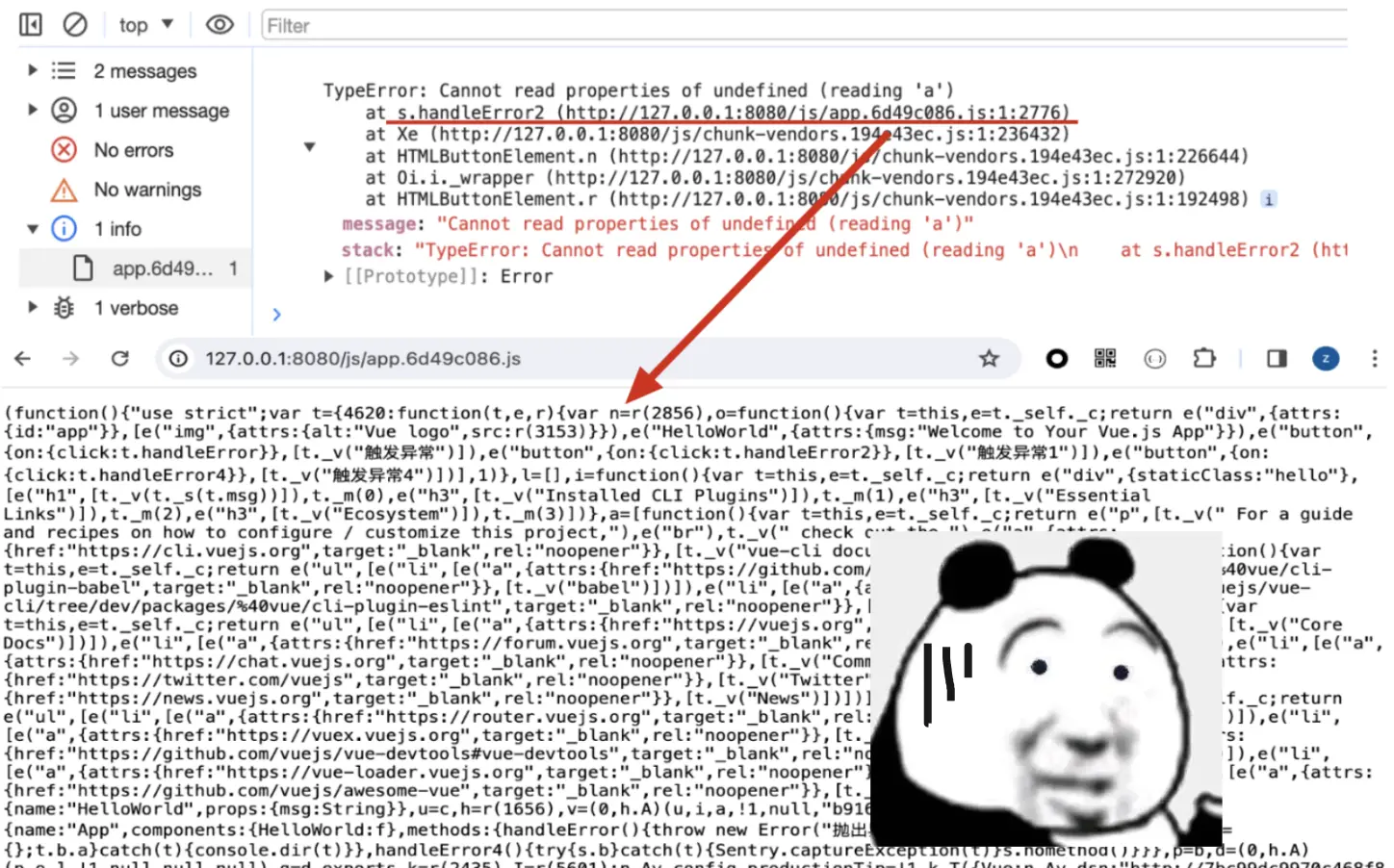
这个时候就轮到sourcemap✨闪亮✨登场了!!!

下面进入我们的第二部分 ⬇️ ⬇️ ⬇️ ⬇️
2. sourcemap原理及如何通过sourcemap做错误还原
首先一句话给Sourcemap做个定义:
它的主要作用就是将经过压缩、混淆、合并的产物代码还原回未打包的原始形态,帮助开发者在生产环境中精确定位问题发生的行列位置,在精简一点的话其实就是一个映射文件,能把转换后的代码位置映射到原始代码位置。
也就是说使用Sourcemap后,可以轻松看的报错代码对应的原始位置:
DEMO地址:github.com/ycvcb123/re…
启动方式:
npm i/npm run start/ 访问127.0.0.1:8081(关闭打开
Sourcemap,修改webpack.config.js中的devtool即可)
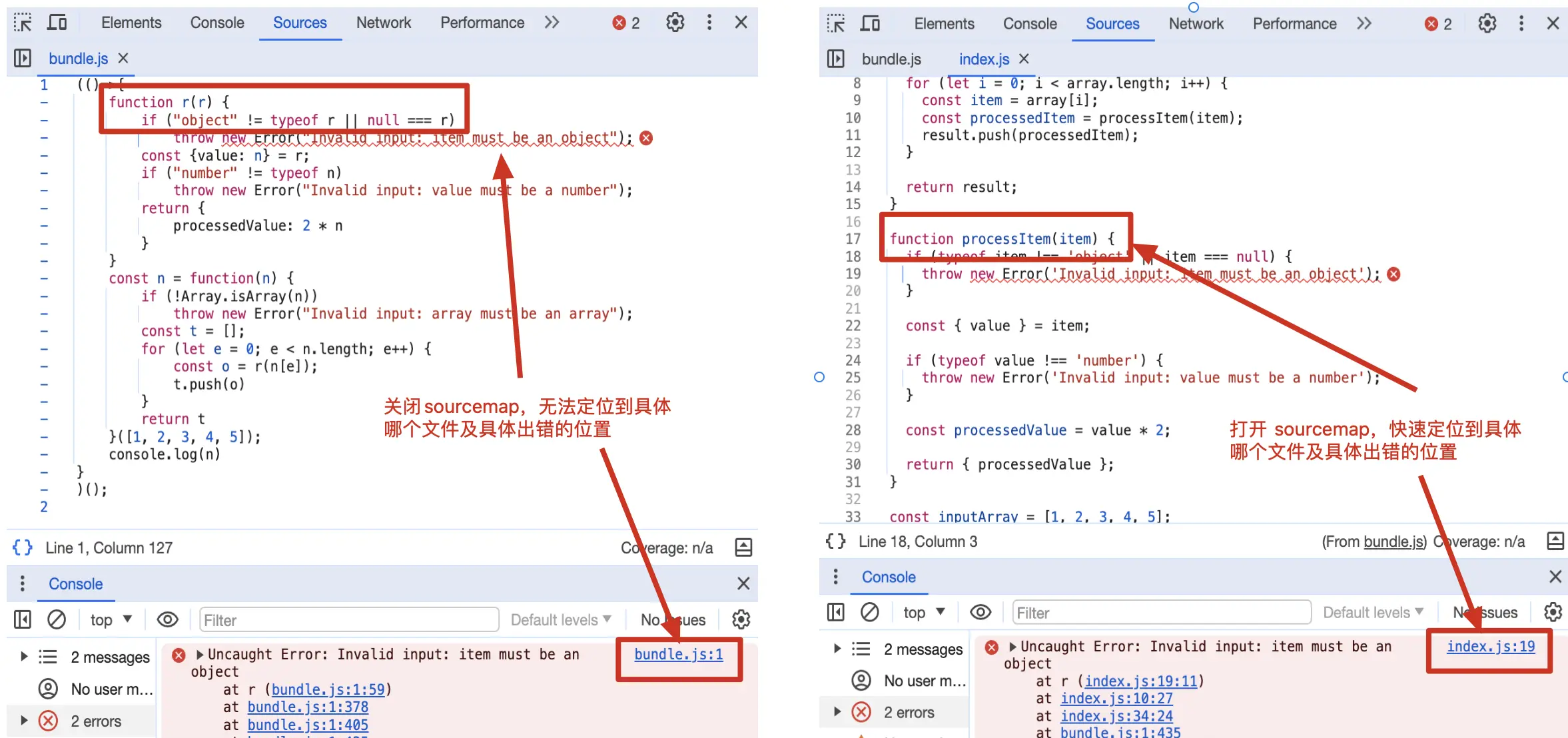
那Sourcemap究竟是如何做到代码还原的呢?下面我们就结合源码对Sourcemap的原理一探究竟!!!🧐🧐🧐
继续上面这个例子接着说,注意看,这个打包出来的文件叫bundle.js,在他的最底部有一行
// 省略其他代码...
//# sourceMappingURL=bundle.js.map
这个就是记录原始代码与经过工程化处理代码之间位置映射关系 Map 文件,一切的秘密都在这里。🤩🤩🤩

我们用简单一点代码来看下.map里的内容结构:
DEMO地址:github.com/ycvcb123/re…
npm run build后打开dist文件夹下的bundle.js.map

这里比较难以理解的是mappings里的内容,重点看下:
"mappings": "AACAA,QAAQC,IADE"
mappings由三部分构成:
-
以
;分割出的行映射。(因为我们构建后产物只有一行,所以没有出现;) -
以
,分割出代码中的片段(位置)映射。如本例中的AACAA,QAAQC,IADE -
转换后代码的片段(位置)映射到源码的具体位置的转换,每个位置最多由5个字母组成,以
AACAA为例子,5个字母的含义分别是:- 第一位,表示该片段在
(转换后的代码的)的第几列。 - 第二位,表示这个片段属于
sources属性中的哪一个文件 (sources数组的下标)。 - 第三位,表示这个片段属于转换前代码的第几行。
- 第四位,表示这个片段属于转换前代码的第几列。
- 第五位,表示这个片段属于 names 属性中的哪一个变量。
- 第一位,表示该片段在
片段(位置)映射则用到了一种比较高效数值编码算法 —— VLQ(Variable-length Quantity)编码。
对VLQ编码原理感兴趣的在最后补充内容中有详细介绍( 补充:VLQ编码原理),这里不重点描述了。
我们可以通过 base64vlq这个网站对AACAA做一个转换:
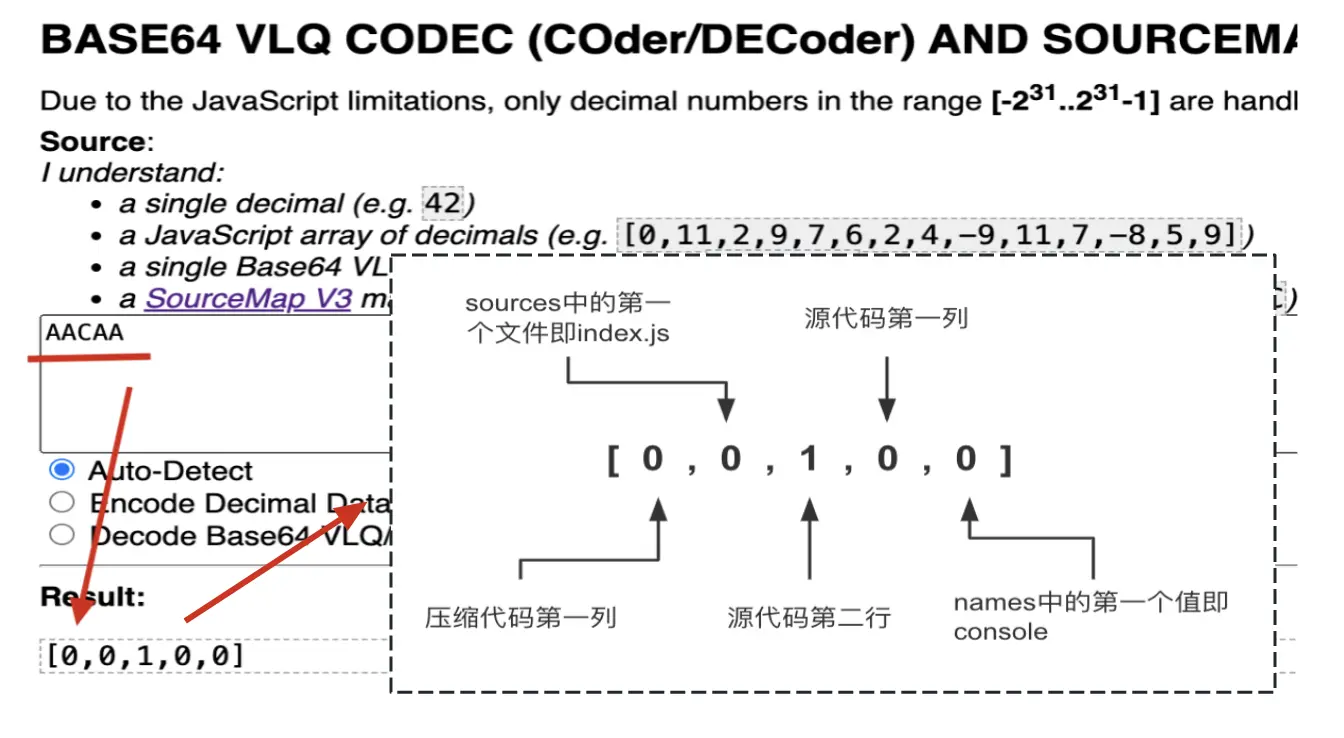
综上,就可以得到console在源代码中的具体位置了。
了解了Sourcemap的原理,我们再结合代码看下,他进行错误还原的过程:
npm i后npm run test会发现控制台出现报错信息,根据报错信息中的行列数,执行node recover-sourcemap.js line=xx column=xx,通过Sourcemap反解出出错的源代码位置
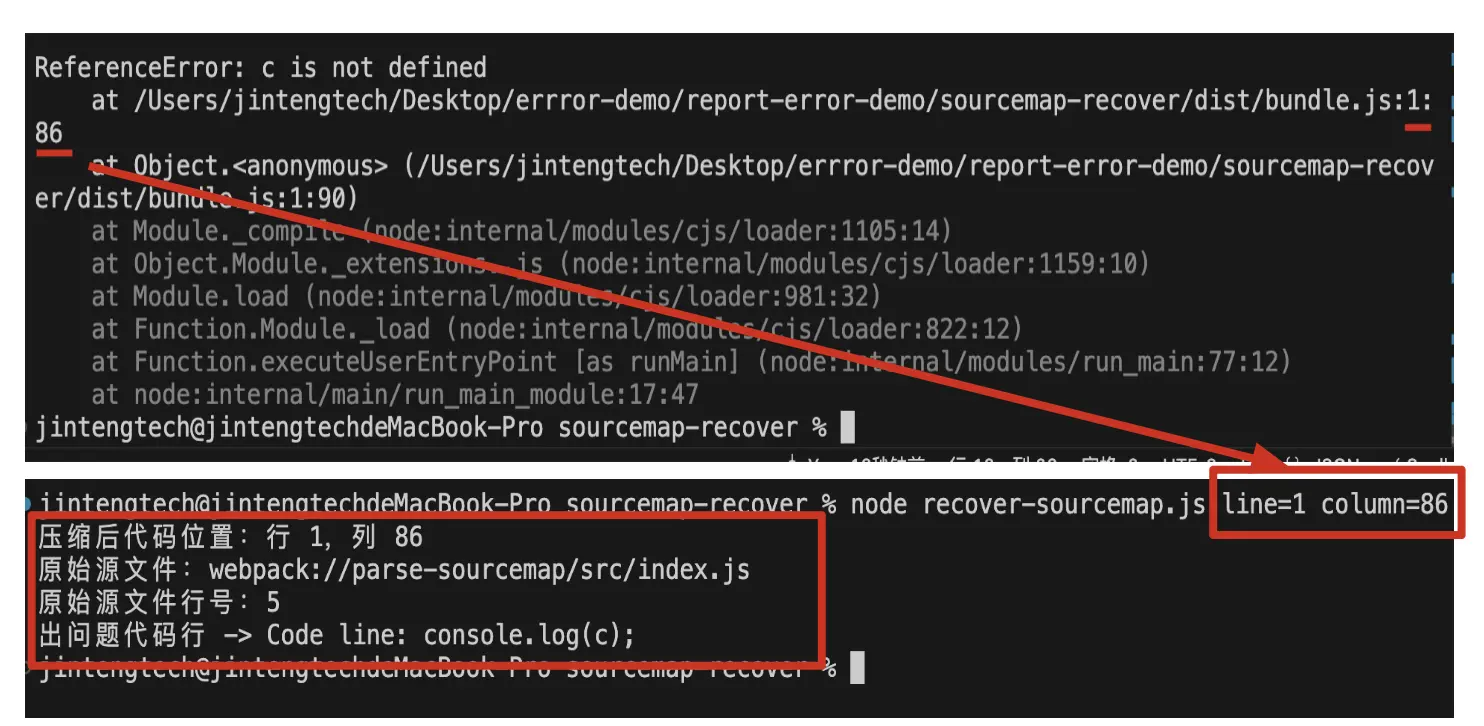
看下recover-sourcemap.js中的还原逻辑:
- 实例化了一个 SourceMapConsumer 对象。
- 根据压缩后的代码报错行列数获取源代码的位置信息。
- 读出原始文件内容,结合原始报错行列号,锁定原始错误位置。
const { SourceMapConsumer } = require('source-map');
//省略...
const sourcemapData = fs.readFileSync('./dist/bundle.js.map').toString();
// 1. 实例化了一个 SourceMapConsumer 对象
const sourcemapConsumer = new SourceMapConsumer(sourcemapData, null, 'webpack://parse-sourcemap/');
//省略...
sourcemapConsumer.then(consumer => {
// 2.1 根据压缩后的代码报错行列数获取源代码的位置信息
const originalPosition = consumer.originalPositionFor({
line: compressedLine,
column: compressedColumn
});
// 2.2 比如原始文件名称,原始行列号
const { source, line: originalLine, column: originalColumn } = originalPosition;
//省略...
if (source) {
// 3. 读出原始文件内容,结合原始报错行列号,锁定原始错误位置
const sourceContent = consumer.sourceContentFor(source);
if (sourceContent) {
const lines = sourceContent.split('\n');
const codeLine = lines[originalPosition.line - 1];
console.log('出问题代码行 -> Code line:', codeLine);
}
} else {
console.log('无法找到原始源文件位置。');
}
});
到此,总结一下,这一部分我们了解了什么是Sourcemap及他的原理和实际应用,它在真实的生产环境中,对我们快速定位线上问题起到了极大的作用。
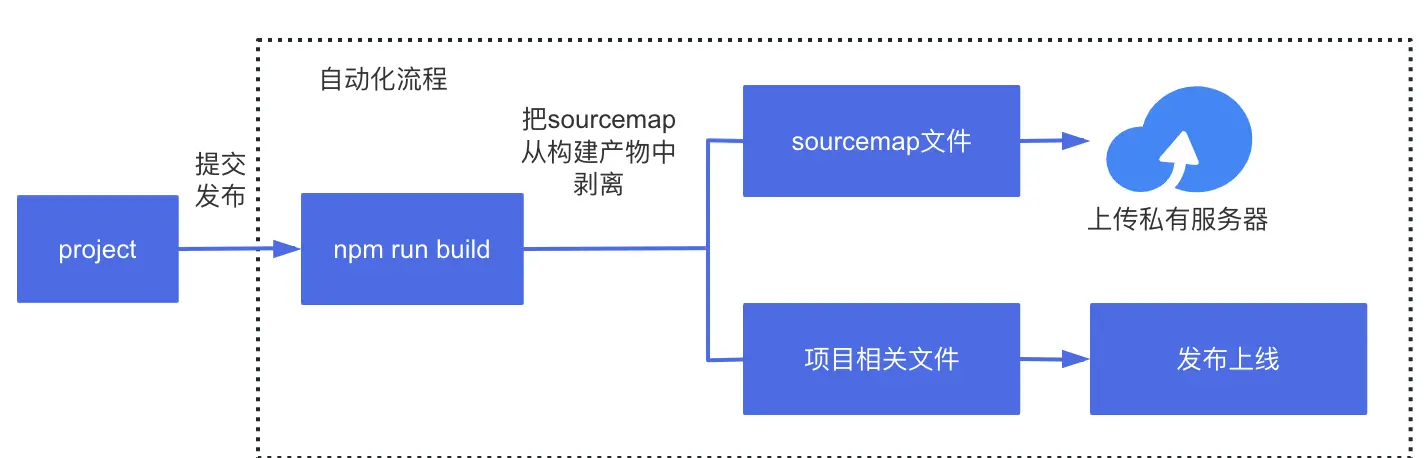
tips: 一般实际业务中,因为源代码可能存在一定的敏感性,为了安全性,在构建打包后,.map文件和其他构建文件会进行剥离,单独上传到一个私有服务器中,如下图所示
在进入第三部分前,我们先回顾下前面两部分:
- 前端错误的种类。
- 各种报错捕获的方法。
- 压缩混淆后的报错如何做错误还原。
有了上述三点,我们基本上可以对错误有个一个清晰的定位。但在实际的工作中,业务代码的复杂程度远远比我们上面具的例子大的多的多。再加上用户的网络环境,设备种类也是千奇百怪,仅仅就靠
trycatch,onerror,unhandledrejection...这种方式捕获到的错误信息,对我们分析问题来说是非常有限的。怎么办?🤔️🤔️🤔️🤔️ 接下来让我们进入第三部分:sentry客户端错误处理方案:raven.js。
3. sentry客户端错误处理方案:raven.js
sentry客户端错误处理方案:raven.js 首先我们看下同样一个错误,普通方式捕获到的错误信息,和通过raven.js加工后得到的信息:

相比较原始捕获到的错误信息,ravenjs在其基础上又增加了如面包屑信息、用户信息、环境信息、URL 信息、网络请求信息等。这些信息可以帮助开发人员更好地理解错误的发生环境和上下文,从而更有效地调试和解决问题。
下面结合ravenjs源码(此处用的是3.9.2的版本)来看下它的大概原理:
这里为了方便调试把
CDN上的代码直接复制到本地写了一个简单的 DEMO ,下载或者clone后,进入对应文件夹,直接http-server启动服务在浏览器打断点调试即可。
raven.js:
var TraceKit = require('../vendor/TraceKit/tracekit');
var stringify = require('json-stringify-safe');
//...
看下ravenjs中依赖到的两个库:
json-stringify-safe:
// 首先看下raven.js中依赖的两个库一个是 json-stringify-safe,
// 一个对 JSON.stringify 的封装,安全的 json 序列化操作函数,不会抛出循环引用的错误,下面是一个例子:
const jsonStringifySafe = require('json-stringify-safe');
// 创建一个循环引用的对象
const objA = { name: 'Object A' };
const objB = { name: 'Object B' };
objA.child = objB;
objB.parent = objA;
// 转换为 JSON 字符串
const jsonString = jsonStringifySafe(objA); // 这里改成JSON.stringify会报循环引用的错
console.log(jsonString);
TraceKit:
// 另一依赖的个库就是tracekit,reven.js 的功能在很大程度上对它有所依赖,主要功能如下
┌─────────——————————————————————┐
│ tracekit │
├──────────────┬───────————————─┤
│ 错误收集 | 堆栈格式化 |
├──————————————┼─——————————─────┤
首先看下是如何做错误收集的:
我们从
raven.install()开始,沿着执行路径看到installGlobalHandler

function installGlobalHandler (){
// 省略...
_oldOnerrorHandler = _window.onerror;
_window.onerror = traceKitWindowOnError;
_onErrorHandlerInstalled = true;
}
发现这里,用traceKitWindowOnerror函数拦截了原有的window.onerror;
接着看下 traceKitWindowOnError:
function traceKitWindowOnError(message, url, lineNo, colNo, ex) {
// 省略...
else if (ex) {
stack = TraceKit.computeStackTrace(ex);
notifyHandlers(stack, true);
} else {
var location = {
'url': url,
'line': lineNo,
'column': colNo
};
// 省略...
stack = {
// 省略...
'stack': [location]
};
notifyHandlers(stack, true);
}
if (_oldOnerrorHandler) {
return _oldOnerrorHandler.apply(this, arguments);
}
// 省略...
}
traceKitWindowOnError 主要做了三件事:
- 如果
error为错误对象,使用computeStackTrace()格式化错误信息,再交给错误消费者。 - 如果
error不是错误对象(如字符串),则自行包装错误信息,交给消费者。 - 使用原来的
window.onerror()处理事件。
格式化错误信息我们等下会详细说明,这里我们先看下消费者是啥?

没错,这里的消费者正是在raven.install() 中传入给 TraceKit.report.subscribe 的函数:
TraceKit.report.subscribe(function () {
// 这个函数就是上文提到的消费者,
// 消费处理的就是在`traceKitWindowOnError`中格式化好的错误信息
self._handleOnErrorStackInfo.apply(self, arguments);
});
从消费者这里接着我们的流程,看格式化后的错误信息是如何处理和上报的:
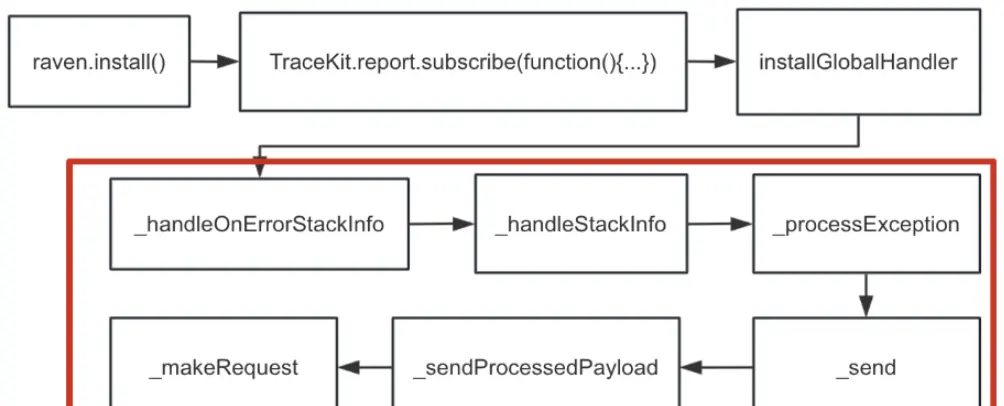
- _handleStackInfo: 遍历
stackInfo.stack数组中的每个堆栈对象,调用_normalizeFrame函数对其进行规范化处理,并将返回的规范化帧对象添加到frames数组中。 - _processException: 根据 message 信息判断是否是需要忽略的错误类型,文件是否在黑名单中或者白名单中,对错误内容进行必要的整合与转换。
- _send: 对上报信息进一步处理,添加一些像
request,platform,release等的基础信息(面包屑信息就是在这一步里添加的)。 - _sendProcessedPayload: 会
_trimPacket(裁剪)过长的信息(message, stack, url, referer等),添加auth等信息,可以通过自定义 globalOptions.transport 的方式来自定义上报函数。 - _makeRequest: 对支持
fetch的浏览器使用fetch发送请求,不支持的使用XHR发送请求。
上面整个消费过程其实就是对捕获到的错误信息加工处理到上报的全部过程。
说完错误收集,我们接下来看下刚才提到的格式化错误信息。
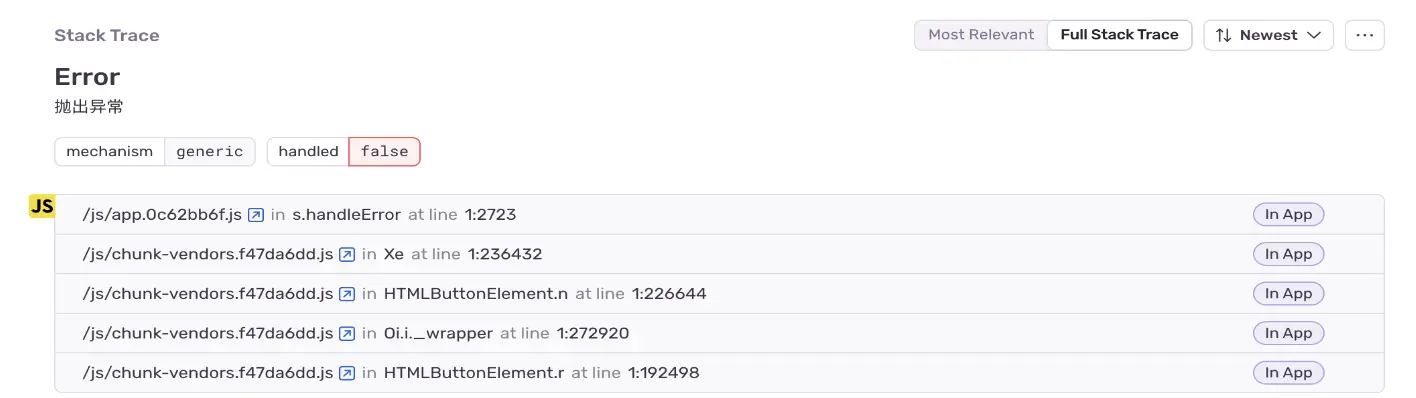
首先我们了解下ravenjs为什么要对堆栈信息做格式化处理❓❓❓先看下图:
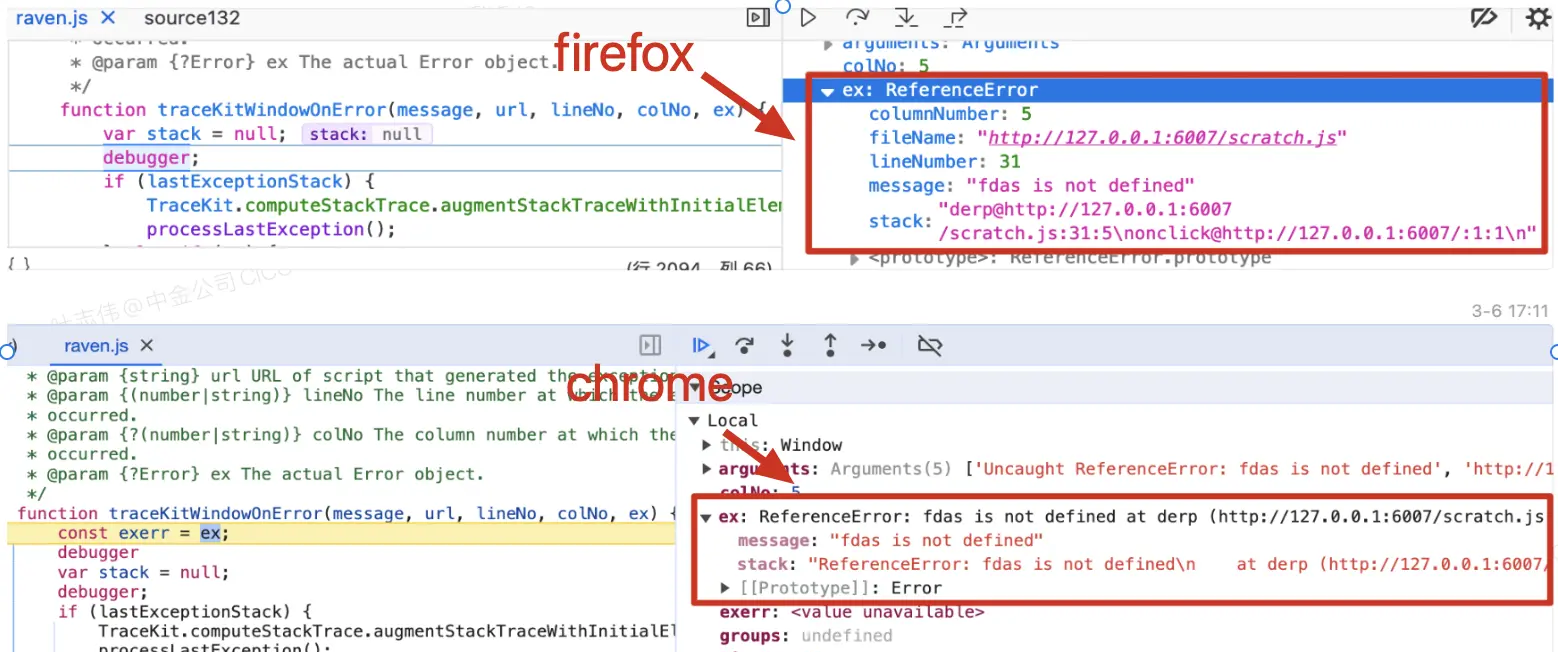
可以看到上报的错误信息在不同的浏览器中是有所区别的,甚至有一些是不返回调用栈的,这样会使得我们后面对这些信息处理时非常的麻烦,为了方便后期的分析逻辑和展示逻辑,ravenjs通过tracekit的computeStackTrace方法做到了报错信息格式的统一,看下经过格式化以后的信息:
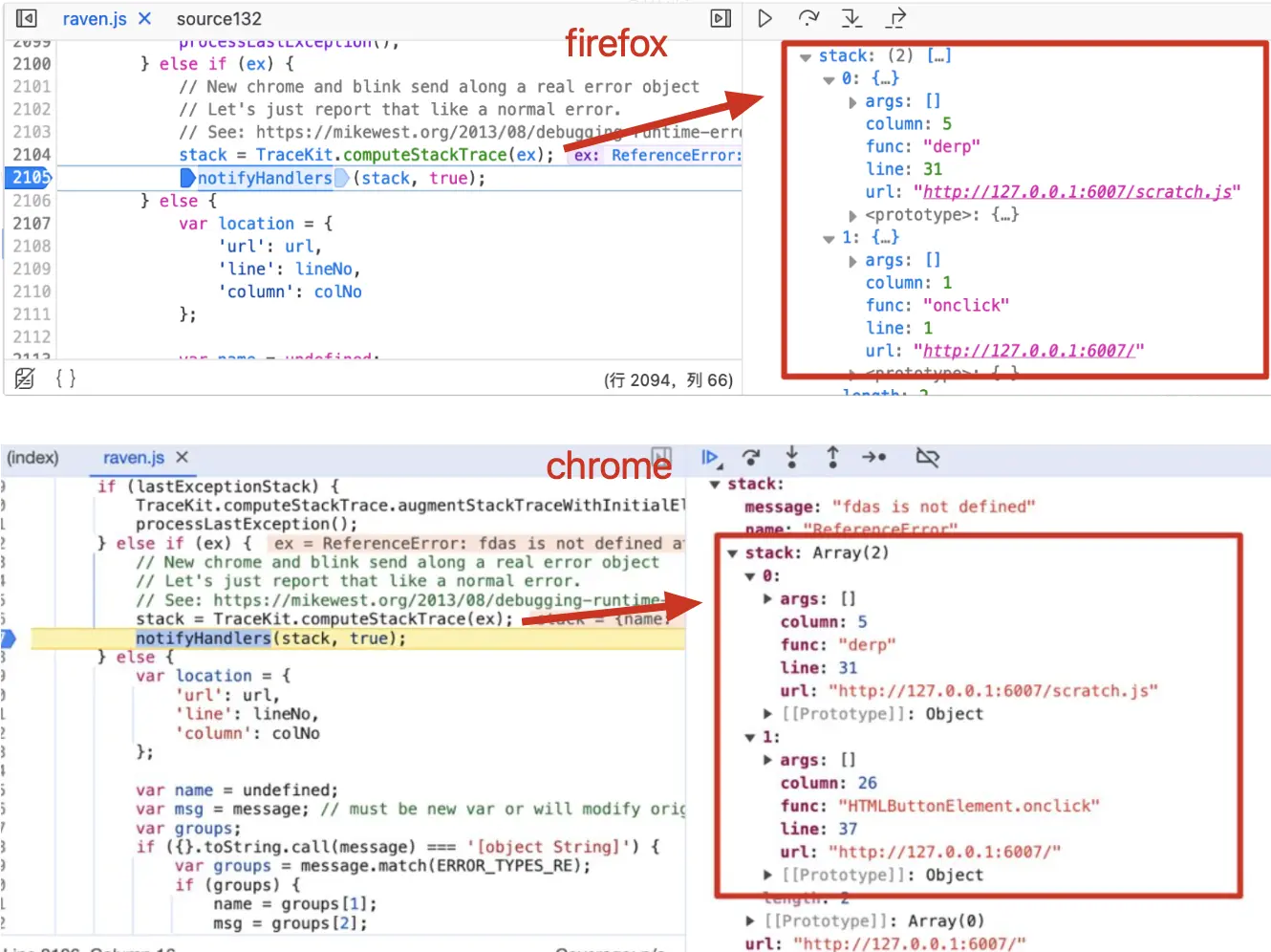
可以看到经过 TraceKit.computeStackTrace 的处理,不同浏览器的上报信息被统一格式化了。
说清楚了主要原理,我们用实际例子看下,ravenjs如何做错误还原:
DEMO地址:github.com/ycvcb123/re…
# 运行步骤
1. npm i
2. npm run start
3. 打开浏览器 http://127.0.0.1:8080, 点击按钮上报一个错误
4. 打开浏览器 http://127.0.0.1:3000, 即可看到根据ravenjs的上报信息做出的错误还原
左边是实际运行效果,右边是DEMO源码的大概逻辑,感兴趣的小伙伴可以
clone或者下载下来跑一下。
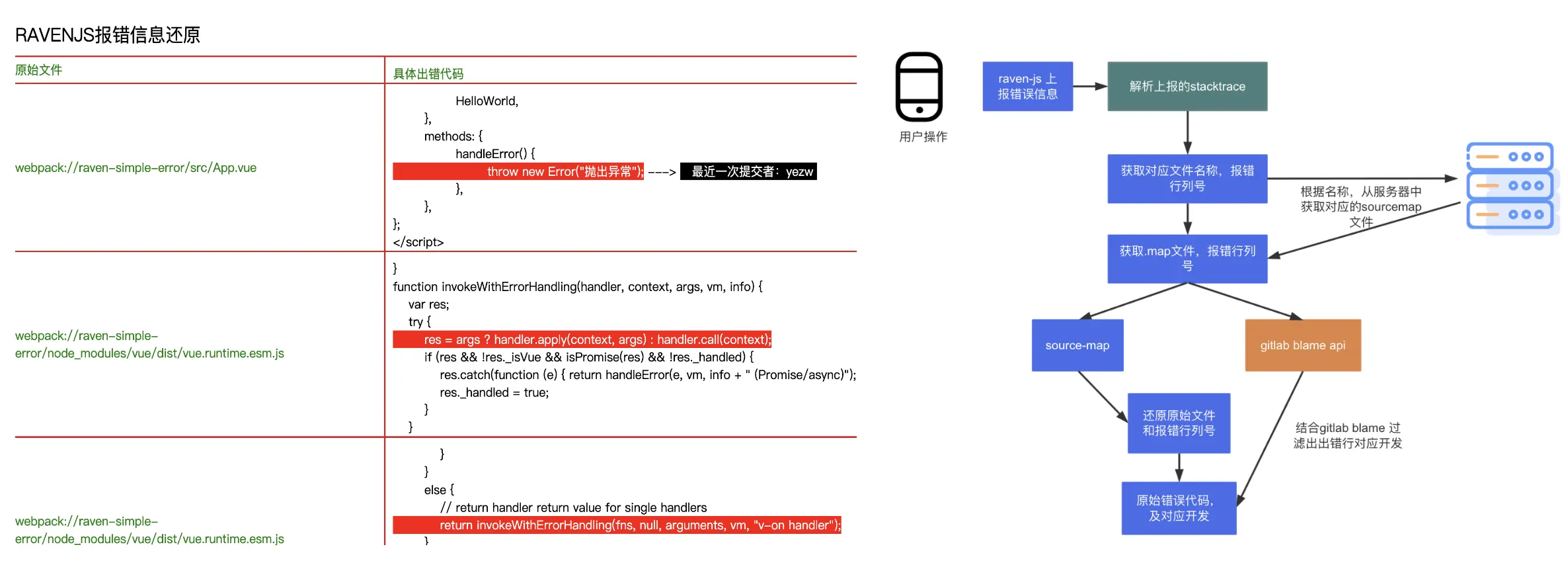
如上,在对ravenjs的上报信息解析后,错误还原的方法其实和第二部分sourcemap原理中提到的错误还原的 DEMO 原理是一样的:
// 省略...
const sourcemapConsumer = new SourceMapConsumer(sourcemapData, null, 'webpack://parse-sourcemap/');
let originalPosition;
let sourceContent;
return sourcemapConsumer.then(async (consumer) => {
originalPosition = consumer.originalPositionFor({
line: Number(item.line),
column: Number(item.column)
});
const { source, line: originalLine, column: originalColumn } = originalPosition;
sourceContent = sourcemapDataForJson.sourcesContent[sourcemapDataForJson.sources.indexOf(sourcesPathMap[source])];
console.log(`压缩后代码位置:行 ${item.line},列 ${item.column}`);
let owner;
if (source) {
// 省略...
if (sourceContent) {
const lines = sourceContent.split('\n');
const codeLine = lines[originalPosition.line - 1];
console.log('出问题代码行 -> Code line:', codeLine);
};
} else {
console.log('无法找到原始源文件位置。');
}
// 省略...
});
一句话总结
ravenjs的作用:集成了前端错误的各种捕获处理,并且对错误信息进行了跟踪,格式化的处理,使上报的上下文信息统一且更加丰富。
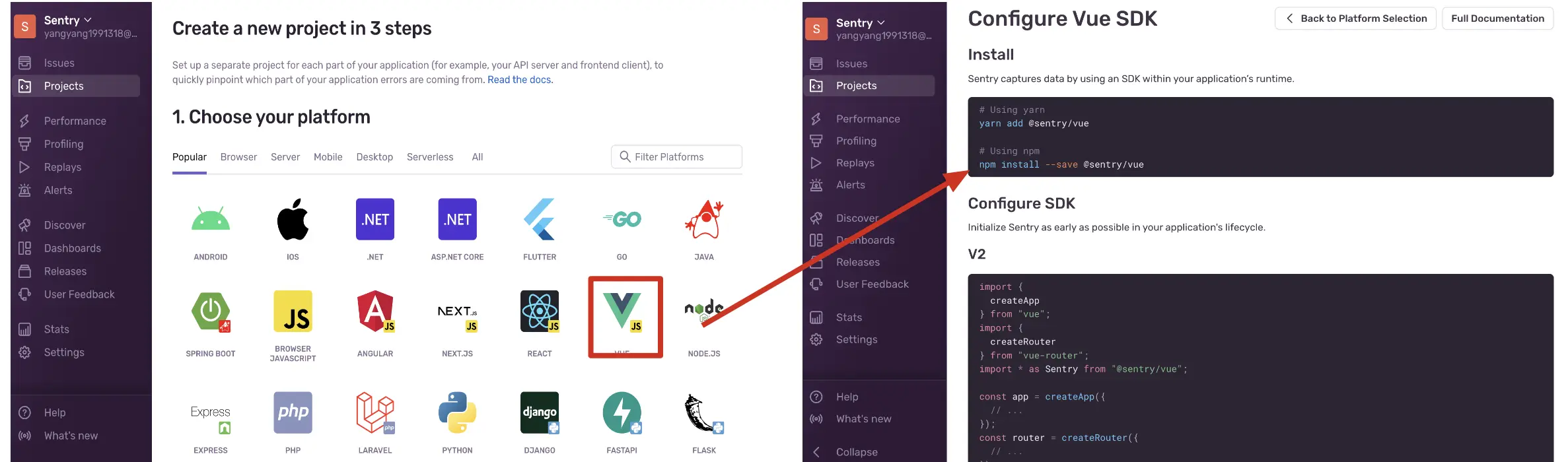
4. sentry客户端错误处理方案升级:@sentry/brower
sentry客户端错误处理方案升级:@sentry/brower现在大家在npmjs中查找ravenjs库会发现如下提示:
查看了下github中sentry-javascript的版本发布记录,从4.0.0开始启用了@sentry/browser,在 5.16.0 中彻底删除了raven-js的代码。
我们先对其源码进行一个分析(此处使用的@sentry/browser的版本是7.101.1);
DEMO地址:github.com/ycvcb123/re…
这个demo也是为了方便源码调试,把
CDN上打包好,未经压缩的代码复制到本地,DEMO 下载或者clone到本地后,在相应文件下用http-server启动服务,即可打开浏览器进行断点调试。
首先初始化阶段,按照@sentry/browser的执行步骤,大概整理了一个流程图,中间有些过程需要结合源码认真分析下:
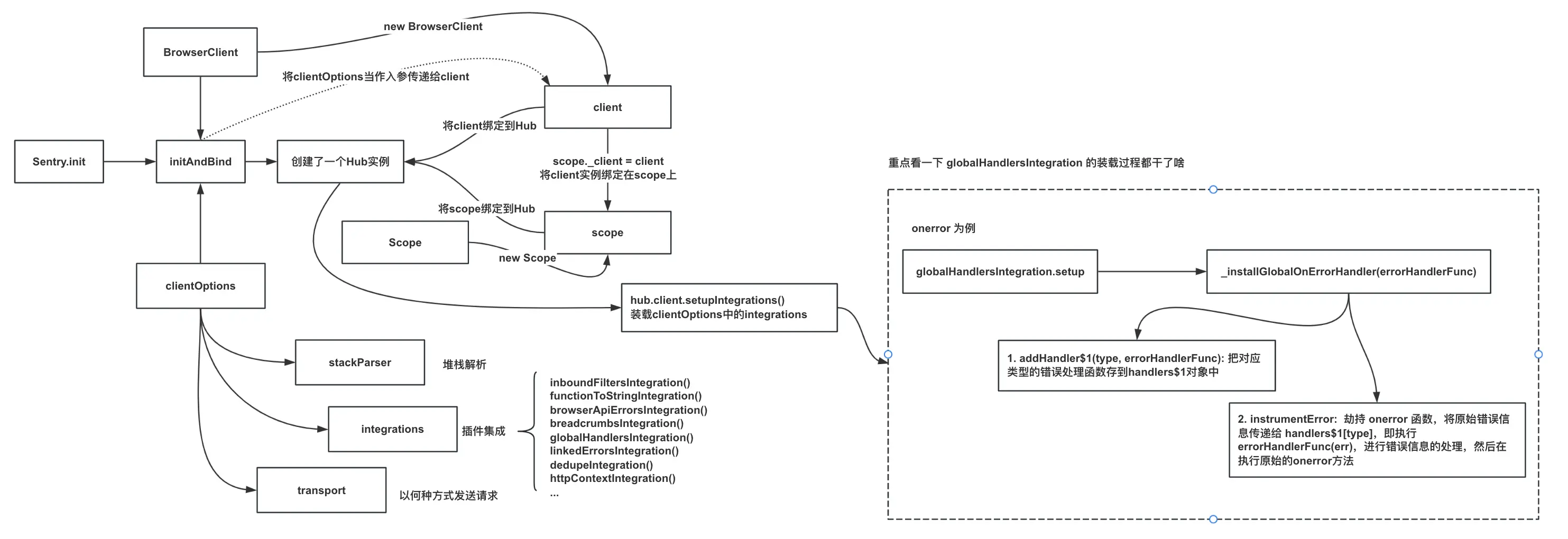
以上图为例可以看出,其实本质上还是劫持了onerror进行错误信息的处理和上报,然后在执行原始的onerror方法。(这里本质上原理与raven-js是相同的)
结合上图和源码,我们发现,新的sentry客户端主要有几重要的部分组成:
Hub:控制中心,管理client和Scope的交互,上报到Sentry服务的事件一般会统一经由Hub组件处理派发。Client:实现了事件从捕获到上报的完整处理流程。(stackParser,integrations,transport都是挂载在client上由client维护)Scope:添加、修改和控制附加的上下文信息。- 添加额外的上下文信息:
- 用户信息:
scope.setUser; - 添加标签,用于对错误进行分类和过滤:
scope.setTag。 - 。。。
- 用户信息:
- 设置错误级别:
scope.setLevel - 添加面包屑:
scope.addBreadcrumb
- 添加额外的上下文信息:
Integration:客户端(插件/集成),向Sentry系统内注册全局事件处理器。(默认的插件有8个,也可以传入自己自定义的插件)。官方文档:integrationsinboundFiltersIntegration: 允许你忽略给定异常中基于类型、消息或 url 的特定错误。functionToStringIntegration: 重写了Function原型链上的toString,方便还原原始的函数和名称,因为有些函数在错误处理和面包屑处理中被包装。
// 举个例子说明下,如下是一个原始函数
function calculateSum(a: number, b: number): number {
if (typeof a !== 'number' || typeof b !== 'number') {
throw new Error('Invalid arguments');
}
return a + b;
}
// 在sentry错误处理的过程中会经常看到有类似下面这种wrap函数把原始函数包装起来
function wrapperFunction(a: number, b: number): number {
if (a === 0) {
throw new Error('Divide by zero');
}
return calculateSum(a, b);
}
// 这个时候如果执行wrapperFunction(0 ,2),给出的错误信息是如下:
Error: Divide by zero
at wrapperFunction (file.ts:5:11)
// 这个信息就很难让我们定位到具体错误,functionToString的功能就是在类似情况下,还原原始函数和名称
browserApiErrorsIntegration: 通过fill函数包装一些常见的浏览器 API ,来捕获和处理浏览器 API 错误。XMLHttpRequesteventTargetsetInterval,setTimeout...
breadcrumbsIntegration: 收集面包屑。globalHandlersIntegration: 拦截浏览器error和unhandledrejection事件,把错误信息交给hub处理。linkedErrorsIntegration: 允许用户去配置错误的关联性,这里比较抽象,我们使用官方提供的代码跑个DEMO看下:
document.getElementById('linkError').addEventListener('click', async () => {
const movie = event.target.dataset.title;
try {
const reviews = await fetchMovieReviews(movie);
renderMovieReviews(reviews);
} catch (e) {
const fetchError = new Error(`Failed to fetch reviews for: ${movie}`);
fetchError.cause = e; // 这里建立了错误链,可以把这行在注释前后分别上报一遍看下区别
Sentry.captureException(fetchError);
}
});

dedupeIntegration: 用于去除重复的错误事件,以避免重复报告。httpContextIntegration: 记录请求的 URL、方法、头部、IP 地址等信息,可以更好地了解错误的来源和请求环境。
四者间的大概关系如下图:
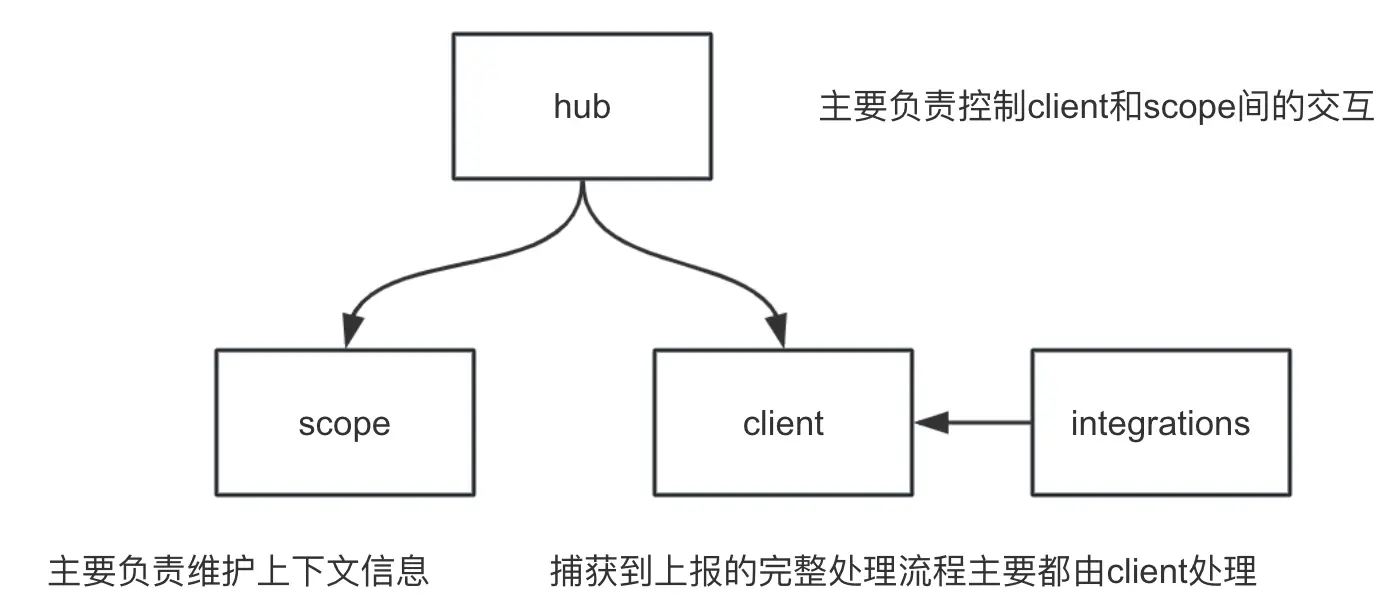
弄清楚上述概念,再看一下错误被捕获后大概的消费流程: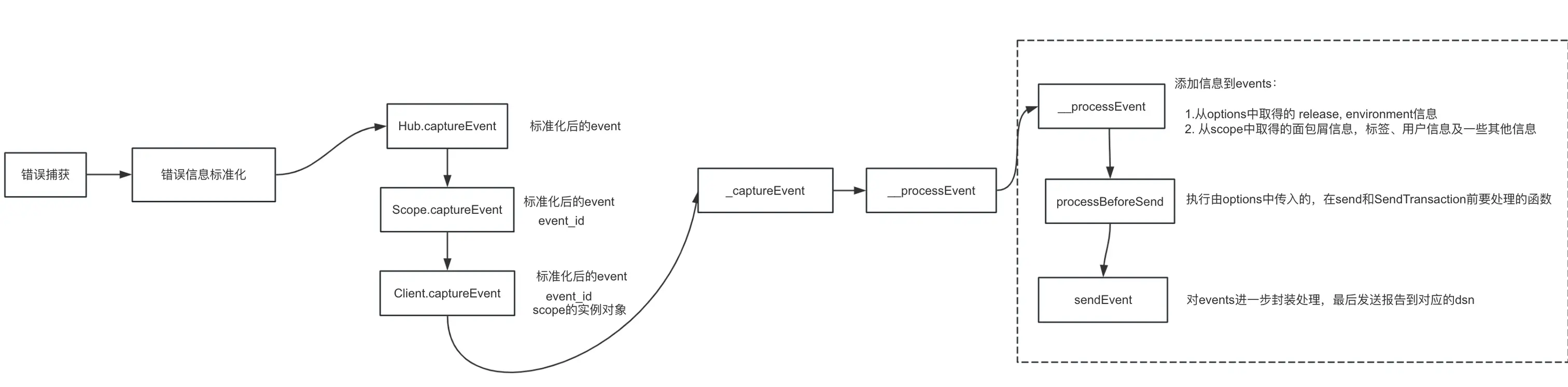
相比较于ravenjs,@sentry/browser 是 Sentry 团队在 raven-js 基础上进行重写和改进的全新代码库(基本原理其实是一样的)。
- 使用
TypeScript编写,提供了完整的类型定义文件,提供了更好的类型检查和代码提示。 @sentry/browser是通过Lerna工具进行模块化管理的,根据需要选择性地引入和使用不同的模块和功能,更加灵活,更轻量级的包。- 功能更加强大,比如上面提到的
linkedErrorsIntegration错误链,还增加了性能监控和报告的功能等。 - 更好的可扩展性和定制性,通过
Integration的插拔使得sentry的功能定制和扩张非常方便,比如刚才第三点提到的性能监控,插入一个集成即可:
import { BrowserTracing } from "@sentry/tracing";
Sentry.init({
dsn: "https://examplePublicKey@o0.ingest.sentry.io/0",
integrations: [new BrowserTracing()],
tracesSampleRate: 0.2
});
上面说了这么多,都是在聊sentry客户端的解决方案和原理,是时候实战接入下sentry,从全貌上看下sentry强大的监控平台了!!!
5. sentry 部署实战及功能介绍
这里需要一些 docker 的基础知识,不太了解的小伙伴最好先熟悉下。
首先我们需要有一台自己的服务器,腾讯云、阿里云、华为云或者其它,自己准备一台就好。但要❗️注意下sentry的官方文档 Self-Hosted Sentry 对服务器的配置要求:
Minimum system specification for running Sentry looks like this:
- 2 CPU cores
- 4 GB RAM
recommended system specification for running Sentry is:
- 4 CPU cores
- 16 GB RAM
- 20 GB free disk storage space
不满足2核4G的最低配置,是跑不起来的,最好是4核16G以上。
然后我们来看具体的安装步骤(我这里用到的版本是23.7.1):
# 1. 下载源码
wget https://github.com/getsentry/self-hosted/archive/refs/tags/23.7.1.tar.gz
# 2. 源码解压并进入解压后文件
tar -zxf 23.7.1.tar.gz
cd self-hosted-23.7.1
# 3. 在安装之前我要们修改下Dockerfile的镜像(重要!!!重要!!!重要!!!)
# RUN apt-get update && apt-get install -y --no-install-recommends cron && \ rm -r /var/lib/apt/lists/*
# 主要是上面这句会导致非常的慢,而且一旦下载没成功,就会报错退出,我重试了好几次都不行
vim self-hosted-23.7.1/cron/Dockerfile
加入这句修改下镜像:Run sed -i 's#http://deb.debian.org#https://mirrors.163.com#g' /etc/apt/sources.list
# 4. 安装
./install.sh
第四步安装完成后看到如下图的提示,说明安装成功:
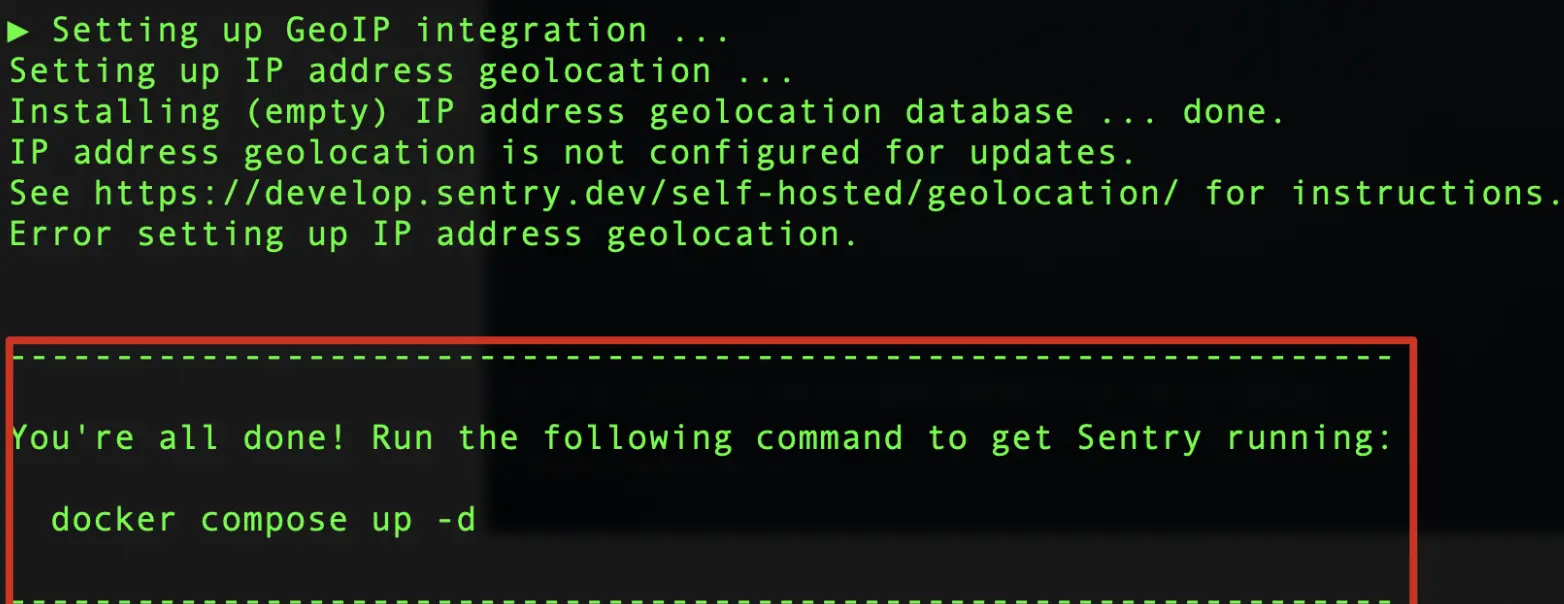
根据提示docker compose up -d启动sentry
然后在浏览器中打开相应地址(地址是你自己的服务器地址,或者自己的域名,端口默认是9000):
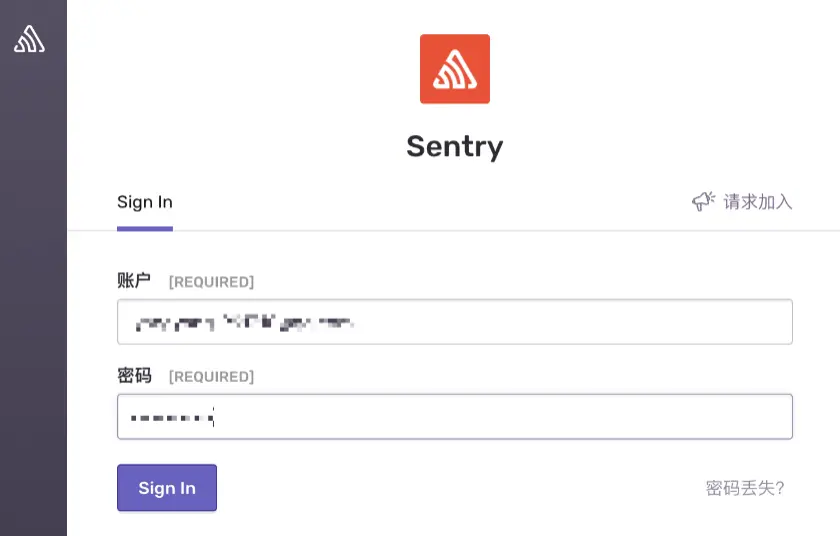
看到这里需要一个账号密码,我们登入容器设置一下:
# 进入容器
docker exec -it sentry-self-hosted-web-1 bash
# 在容器中执行创建用户命令
cd /etc/sentry/
./entrypoint.sh createuser --email <账号> --password <密码> --superuser
然后用设置的账号密码进行登陆:
进入后可以根据自己的实际项目选择如何接入,确认后,会自动生成指引文件,复制到项目中接入即可:
接入后,我们上报一个错误,然后到issues中查看,虽然成功上报了但是错误信息并没有被还原:
回想之前的几个部分,错误还原需要通过.map文件,而我们操作到现在,并没有上传过sourcemap文件到sentry,所以下一步就是解决如何上传sourcemap文件到sentry服务器:
方法很简单,已经有了现成的webpack插件:@sentry/webpack-plugin
vue.config.js
const { defineConfig } = require('@vue/cli-service');
const { sentryWebpackPlugin } = require("@sentry/webpack-plugin");
module.exports = defineConfig({
transpileDependencies: true,
configureWebpack: {
devtool: "source-map",
plugins: [
sentryWebpackPlugin({
// release: 'pro@1.0.0',
// include: './dist',
// ignore: ['node_modules'],
authToken: process.env.SENTRY_AUTH_TOKEN, // 在这里找到后复制到本地 Settings > Account > API > User Auth Tokens
org: "org-name", // 项目所在组织名称
project: "project-name", // 项目名称
url: "http://xx.xxx.xxx.xxx:9000/", // 你的sentry地址
})
],
}
})
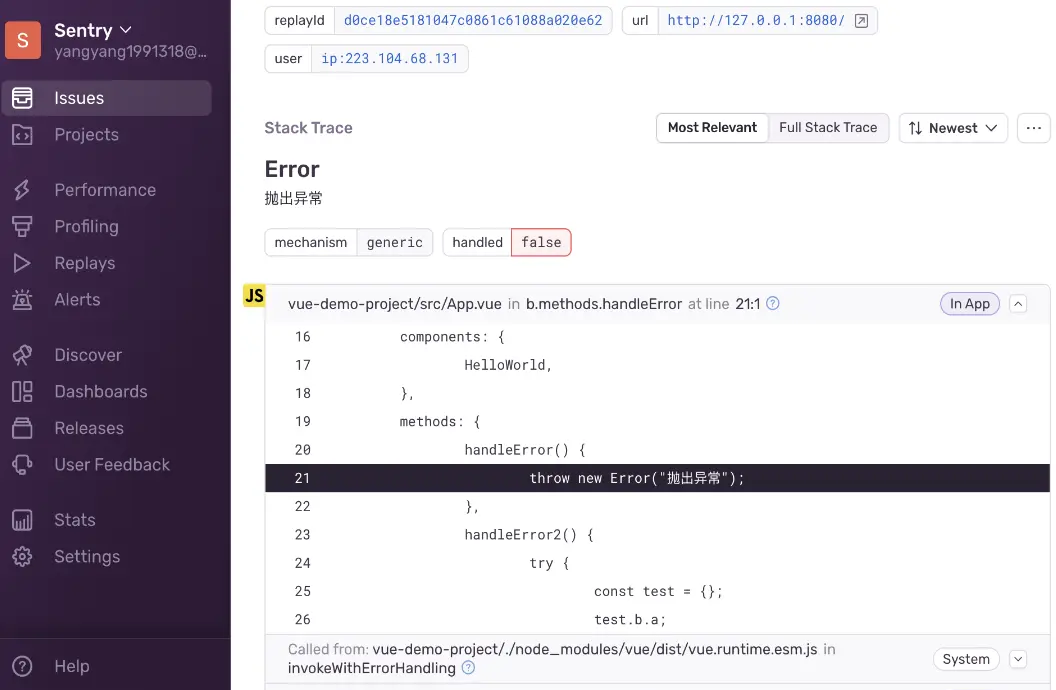
配置好后,重新npm run build,重新触发一个错误信息,发现新的错误报告中有了具体的还原信息:
到此,就是大概一个接入 sentry 基本流程,当然 sentry 中的功能非常强大,在处理错误监控时还可以配置根据面包屑信息生成用户操作轨迹的视频。除了错误监控还能接入性能监控等等,各种丰富功能等待你的解锁~ 🤩🤩🤩
6. sentry 是怎么做错误聚合的
官方文档:# Issue Grouping
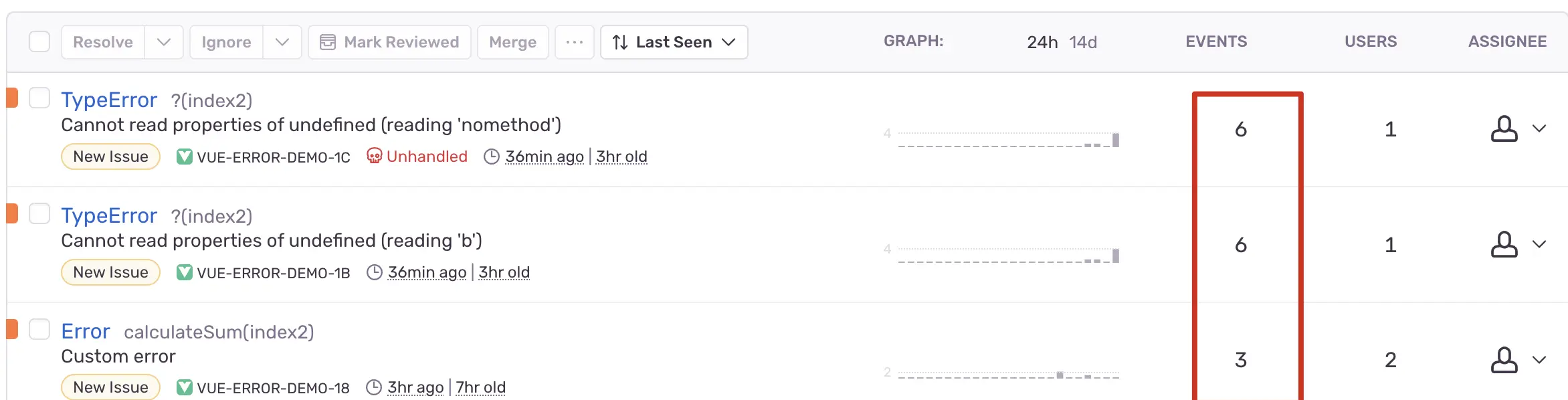
首先解释一个问题:为什么要做错误聚合?
如上图,相同的错误,监控平台已经自动帮我们做了合并,如果没有这种合并,在实际业务中,可能一个相同的错误会被触发成千上万次,我们将被淹没在大量的错误报告中;如果同一种类型的错误以不同的形式出现,我们很难将它们归类为同一类问题。
那错误是通过什么聚合的呢?
Fingerprint: 指纹是一种用于唯一标识事件的方式,所有事件都有一个指纹。具有相同指纹的事件将被分组到一个问题中。
我们上报的错误信息大概是如下这个结构:
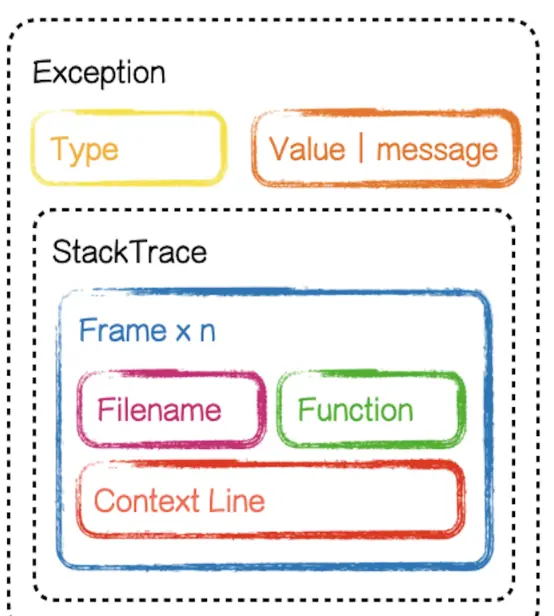
指纹生成算法通常使用哈希函数,将错误信息中的关键部分(如错误消息、堆栈跟踪等)转换为一个固定长度的字符串,字符串相同,及指纹相同的错误聚合在一起,Fingerprint具体的生成逻辑:fingerprinting
7. 总结
通过此文,我们掌握了如下内容:
- 前端报错的种类
- 前端各类错误的捕获方式
- 为什么要有
sourcemap及sourcemap的原理 sentry的客户端ravenjs和@sentry/brower的原理sentry的私有化部署及功能介绍
前端异常是我们平时开发中时常会遇到的问题,有时因为项目进度,基本都是遇到啥就解决啥,可能没有时间完整系统性的对这块的内容作梳理,希望本文可以从一个比较全面的角度结合实战代码帮助你对前端异常的知识体系有个全面的认识,到此,全文终~ (下次再见👋)
8. 补充:VLQ编码原理
Sourcemap为什么会用到VLQ编码❓❓❓
Sourcemap最初版本生成的.map文件确实非常大,通常会比编译产物的大小大约多出10倍。这对于前端开发者来说是一个挑战,因为这可能会导致加载速度变慢,尤其是在大型项目中。
Sourcemap V2引入了一种称为Base64 VLQ的编码算法。这是一种结合了Base64编码和VLQ编码的方法,用于将Sourcemap数据嵌入到.map文件中。这种编码方式减少了大约 20% ~ 30% 的文件体积,对于大型项目来说是一个可观的改进。
Sourcemap V3相较于V2在VLQ编码的基础上引入了连续位的概念,进一步优化了.map文件的大小,使得.map文件更加紧凑和高效。
一句话解释:为了节省空间 ❗️❗️❗️
弄明白为啥要用VLQ编码,我们看下具体的编码原理:
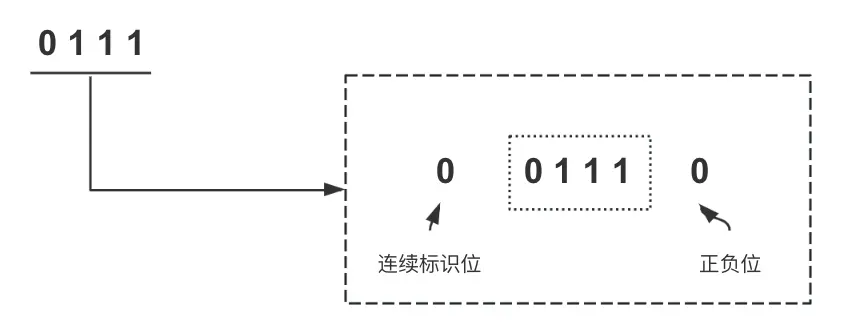
首先看下编码规则,以7为例子:
-
第一位连续标识位(0:不连续;1:连续)。
-
最后一位正负位(0:正;1:负)。
-
中间的4位用于表示数值,所以最大范围是
-15~15,超过这个范围就需要拆分组合:以
-19举例:19的二进制:10011,因为超过-15~15所以拆分下:
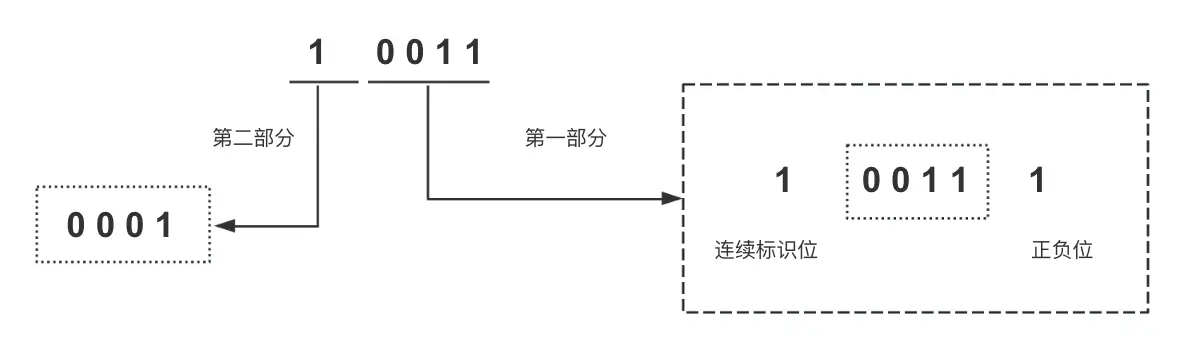
两部分从左至右组合就是[100111, 000001] 根据 # Base64编码对照表转换后就是 nA
看到这个nA,是不是会想起第二部分(sourcemap原理及如何通过sourcemap做错误还原)中提到的mappings?
回顾下示例中提到的mappings:
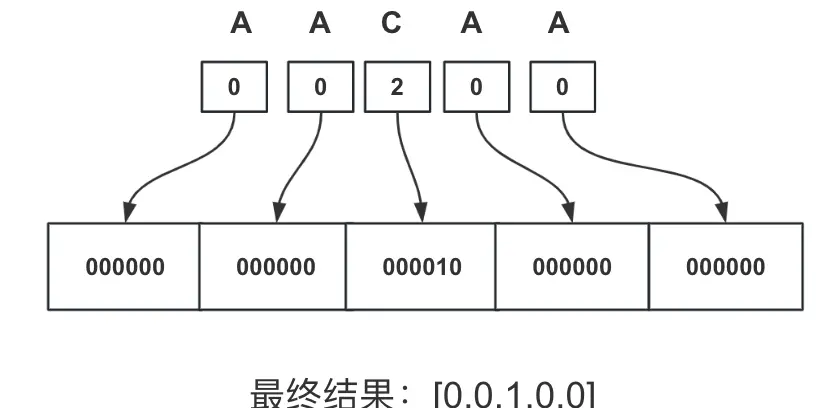
"mappings": "AACAA,QAAQC,IADE"
其中的 AACAA,QAAQC,IADE即使根据上述编码原理转换得出的。
之前我们是通过base64vlq这个网站对AACAA做一个还原,现在知道了原理,通过# Base64编码对照表可以手动还原一下:
原文链接:https://juejin.cn/post/7352661916387475494 作者:你猜我叫啥