
在软件开发和系统设计中,了解 CPU 密集型和 IO 密集型的任务对于优化应用程序和选择合适的技术栈极为重要。这些概念主要与应用程序的性能瓶颈有关,可以帮助开发者更好地理解如何设计高效的多线程和异步程序。
首先,我们的电脑可以简单地抽象为这么一种模式:
输入(键盘) -> 计算(CPU) -> 输出 (显示器)
输入和输出是 IO 的范畴,计算是 CPU
其次,单机程序是由多个方法或者函数串并行组合而成,可以抽象为:
入参 -> 计算 -> 返回值
最后,分布式服务是由多个,单机服务(集群)串并行组合而成,服务间交互可抽象为:
网络请求(入参) -> 计算 -> 网络响应(返回值)
请求和响应是 IO 的范畴,计算是 CPU
综上所述,无论从硬件还是从软件层面来看,它们都是由 I/O 和计算 CPU 来组成的。


CPU 密集型任务(CPU-bound)
CPU 密集型任务是指那些主要受中央处理器(CPU)速度限制的任务。这类任务需要大量的计算,消耗的时间主要在 CPU 上,而不是等待外部资源(如磁盘输入输出或网络通信)。
这些任务的主要有以下几个特点:
-
高计算需求:这类任务通常涉及复杂的数学计算,如视频编码解码、图像处理、科学计算等。
-
多线程优势:在多核 CPU 上,通过并行处理可以显著提高 CPU 密集型任务的执行效率。例如,使用多线程分解任
务到不同的核心上执行。 -
资源消耗:CPU 密集型任务在运行时会导致 CPU 使用率接近 100%。
一般的示例有如下内容:
-
数据分析和大规模数值计算。
-
图形渲染或视频处理软件。
-
加密货币挖矿。
你的笔记本电脑响的时候基本就都是这些类型了哈哈哈哈
对于 CPU 密集型,有如下几个优化的方向:
-
并行化:利用多核处理器通过并行计算来提升性能。
-
优化算法:改进算法可以减少必要的计算量。
-
编译优化:使用适合高性能计算的编译器和编译优化技巧。
I/O 密集型(I/O-bound)
IO 密集型任务是指那些主要受输入/输出(I/O),包括磁盘 I/O 和网络通信,限制的任务。这类任务的瓶颈主要在于等待 IO 操作的完成,而 CPU 计算量相对较小。
这些任务的主要有以下几个特点:
-
高 I/O 需求:这类任务可能需要频繁地读写文件系统,或者有大量的网络请求需要处理。
-
并发优势:IO 密集型任务适合使用事件驱动和异步编程模型来提高效率,如 Node.js 的非阻塞 I/O。
-
CPU 利用率低:由于大部分时间花在等待外部操作上,CPU 的利用率通常不高。
它们的主要使用场景有如下示例:
-
网页服务器和数据库服务器,这些应用需要处理大量的网络请求。
-
文件服务器,需要频繁地读写磁盘。
-
客户端应用,如电子邮件客户端或社交媒体应用,它们需要频繁地发送网络请求并接收数据。
对于 I/O 密集型,有如下几个优化的方向:
-
增加缓存:使用内存缓存来减少对磁盘 I/O 的需求。
-
异步编程:利用异步 I/O 操作来避免阻塞,提高程序整体的响应能力和吞吐量。
-
优化资源管理:合理安排 I/O 操作,避免不必要的读写。
NodeJs 的非阻塞 I/O
Node.js 是著名的非阻塞 I/O 模型的代表性实现,它允许单线程处理大量并发的客户端请求,这主要得益于其基于事件循环的架构。
什么是非阻塞 I/O?
非阻塞 I/O(Non-blocking I/O)是指在执行输入输出操作时,不会让程序完全等待 I/O 操作完成。这种方式允许程序在等待 I/O 操作完成的同时,还能继续执行其他任务。
Node.js 中的非阻塞 I/O 如何工作?
Node.js 使用 JavaScript 运行在 V8 引擎上,并利用 libuv 库实现非阻塞 I/O 和异步编程。NodeJs 之所以能实现非阻塞 I/O,主要由以下这几个核心来实现:
-
事件循环:事件循环是 Node.js 实现非阻塞 I/O 的核心机制。它允许 Node.js 执行非阻塞操作,如网络通信、文件 I/O,同时还能处理用户接口或定时事件。当 NodeJs 启动时,它会初始化事件循环,处理任何提供的输入脚本(这可能会触发异步操作),然后进入事件循环。
-
调用堆栈:所有同步任务(即阻塞操作,如计算或直接数据处理)都在调用堆栈中执行。如果堆栈中的操作耗时较长,会导致程序阻塞,即常说的“堵塞主线程”。
-
回调队列:异步操作完成时,其回调函数被放入回调队列等待执行。事件循环按照顺序检查这些队列,并将可运行的回调函数返回到调用堆栈中执行。
-
非阻塞操作:对于文件系统操作,Node.js 调用 libuv 库实现非阻塞功能,这涉及到使用底层非阻塞的 POSIX API。对于网络请求,Node.js 使用非阻塞的网络 I/O。
请看下面的示例:
const fs = require("fs");
fs.readFile("./test.md", "utf8", (err, data) => {
if (err) {
console.error("读取文件错误:", err);
return;
}
console.log("文件内容:", data);
});
console.log("叼毛");
在这个例子中,fs.readFile 是异步执行的。Node.js 会继续执行 console.log('叼毛') 而不用等待文件读取操作完成。当文件读取完毕后,回调函数被推入回调队列并最终执行,显示文件内容。
通过事件驱动和回调,使得单个线程可以同时处理多个操作,在处理大量 I/O 密集型请求时,可以显著提升应用性能和资源利用率。
非阻塞文件系统操作
当 Node.js 执行文件系统操作(如读取文件)时,它使用 libuv 来进行这些操作,而不是直接使用 POSIX 文件系统 API。libuv 决定使用最佳的方法来执行这些操作,以便它们不会阻塞事件循环。
libuv 维护了一个固定大小的线程池(默认为四个线程),用于执行操作系统级别的阻塞 I/O 调用。这意味着文件 I/O 操作实际上是在这些线程上异步执行的,因此不会阻塞主事件循环线程。
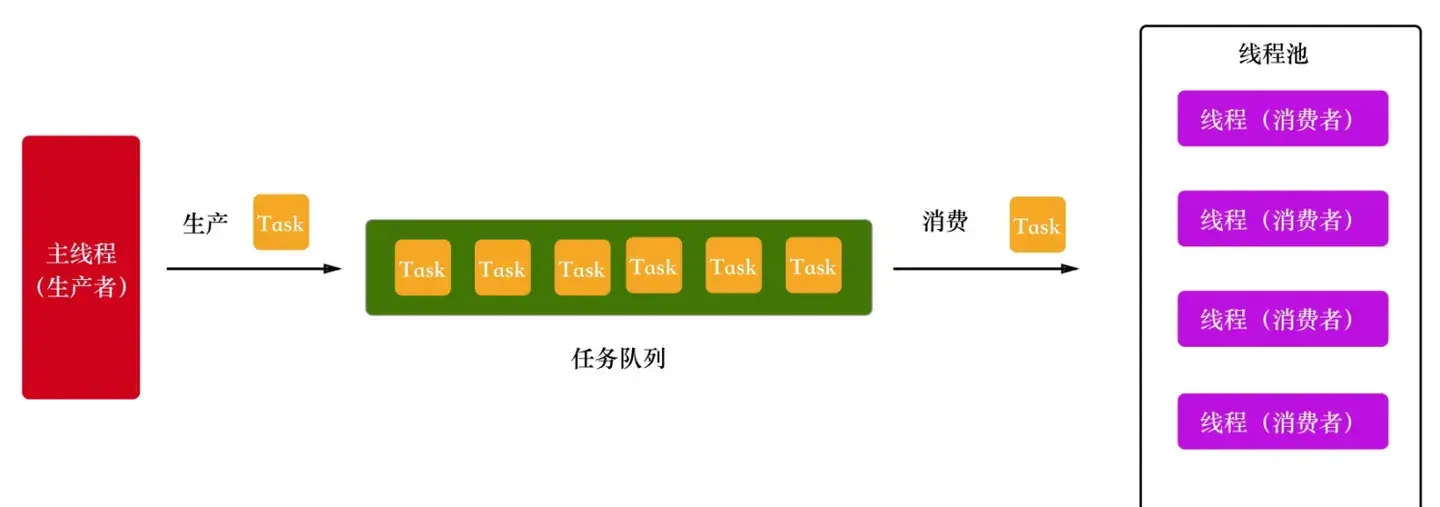
Node.js 的文件操作支持同步调用和异步调用,根据 Libuv 官网的介绍,我们知道它没有跨平台的异步文件 IO 可以使用,所以它的异步文件 IO 是通过在线程池中执行同步文件 IO 实现的。那具体是怎么实现的呢?答案就是生产者消费者模型。Libuv 的线程包括 2 部分,一个是主线程,一个是线程池。主线程的一部分工作是描述任务并将其提交给线程池,线程池进行处理。拿异步文件操作为例,主线程生成一个描述文件操作的对象,将其提交到任务队列;线程池从任务队列获取该对象进行处理。其中主线程是生产者,线程池中的线程是消费者,任务队列是生产者和消费者之间的桥梁,下面是一个简单的示意图:
Libuv 在生产者消费者模型中多加了一步,线程池执行完任务后,将结果交给主线程,主线程拿到结果后,如果发现有回调函数需要执行,就执行。所以 Libuv 的线程模型如下:
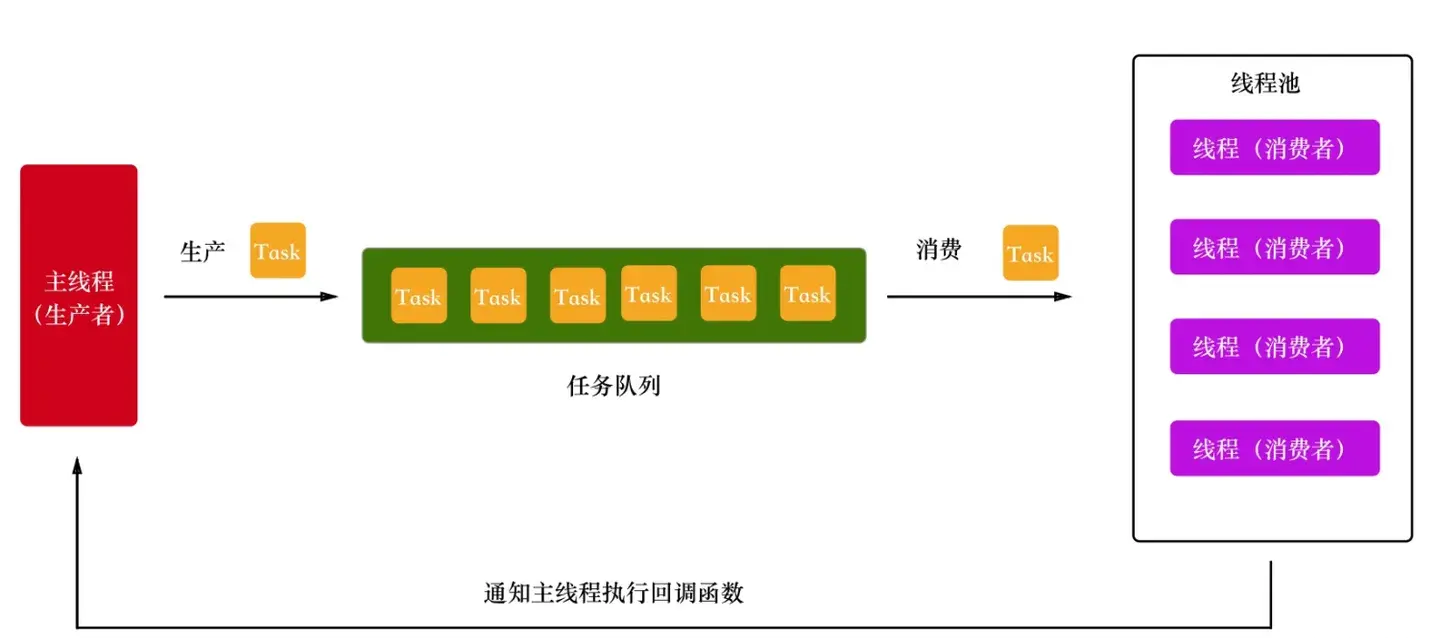
通过上面对生产者消费者模型的介绍,该代码大致分为 4 部分:任务队列、主线程提交任务到任务队列(提交任务)、线程池从任务队列获取任务并执行(消费任务)、线程池执行完任务通知主线程执行回调函数(回调处理)。
一旦线程池中的线程完成了任务(例如,文件读取操作),它将任务的回调函数放入事件循环待处理的队列中。当事件循环轮到这个回调函数时,主线程将执行它,完成整个异步任务的周期。这确保了即使在进行重量级 I/O 操作时,主线程也能保持轻量和响应用户交互。
参考资料
扩展资料
总结
选择正确的处理方式和技术栈对于提高应用程序的性能至关重要。例如,Node.js 非常适合处理 IO 密集型的 Web 应用程序,因为它的非阻塞 I/O 模型可以处理大量并发的网络请求,而不会造成线程资源的浪费。对于 CPU 密集型任务,使用支持多线程的语言和平台(如 Java、C 艹或 Go)会更加合适,这可以让应用程序充分利用多核 CPU 的计算能力。
最后分享两个我的两个开源项目,它们分别是:
这两个项目都会一直维护的,如果你想参与或者交流学习,可以加我微信 yunmz777 如果你也喜欢,欢迎 star 🚗🚗🚗
原文链接:https://juejin.cn/post/7356450983838384137 作者:Moment