
前言
可乐他们团队最近在做一个文章社区平台,由于人手不够,后端部分也是由前端同学来实现,使用的是 nest 。
今天他接到了一个需求,就是在用户点开文章详情的时候,把阅读量 +1 ,这里不需要判断用户是否阅读过,无脑 +1 就行。
它心想:这么简单,这不是跟 1+1 一样么。
往期文章
- 切图仔做全栈:React&Nest.js 社区平台(一)——基础架构与邮箱注册、JWT 登录实现
- 切图仔做全栈:React&Nest.js社区平台(二)——👋手把手实现优雅的鉴权机制
- React&Nest.js全栈社区平台(三)——🐘对象存储是什么?为什么要用它?
- React&Nest.js社区平台(四)——✏️文章发布与管理实战
- React&Nest.js全栈社区平台(五)——👋封装通用分页Service实现文章流与详情
- 领导问我:为什么一个点赞功能你做了五天?
初版实现
我们用的 orm 框架是 typeorm ,然后他看了一眼官方文档,下面是一个更新的例子。


文章表里有一个字段 views ,表示该文章的阅读量。那我是不是把这篇文章的 views 取出来,然后 +1 ,再塞回去就可以了呢?
啪一下,就写出了下面这样的代码:
async addView(articleId: number) {
const entity = await this.articleRepository.findOne({
where: { id: articleId },
select: ['views', 'id'],
});
entity.views = entity.views + 1;
await this.articleRepository.save(entity);
}
然后就美滋滋的提测,继续摸鱼去了。
并发bug
不出意外的话意外就要发生了,测试下午就找到了可乐,说这个实现有 bug ,具体复现是在并发压测的时候。
这里用一个 node 脚本来模拟一下并发的请求:
import axios from "axios";
const axiosInstance = axios.create({
withCredentials: true,
headers: {
Cookie: "your cookie",
},
});
for (let i = 0; i < 10; i++) {
axiosInstance.get("http://localhost:3000/api/articles/getArticleInfo?id=2");
}
本来应该阅读量加 10 的,结果只加了 1 。

可乐当时脑瓜子嗡嗡的,这还能有 bug ?
具体来说,这是 mysql 处理并发的机制—— MVCC ,它有几种默认的隔离级别。默认的隔离级别是可重复读,在可重复读的隔离级别下,会出现以下这种情况:
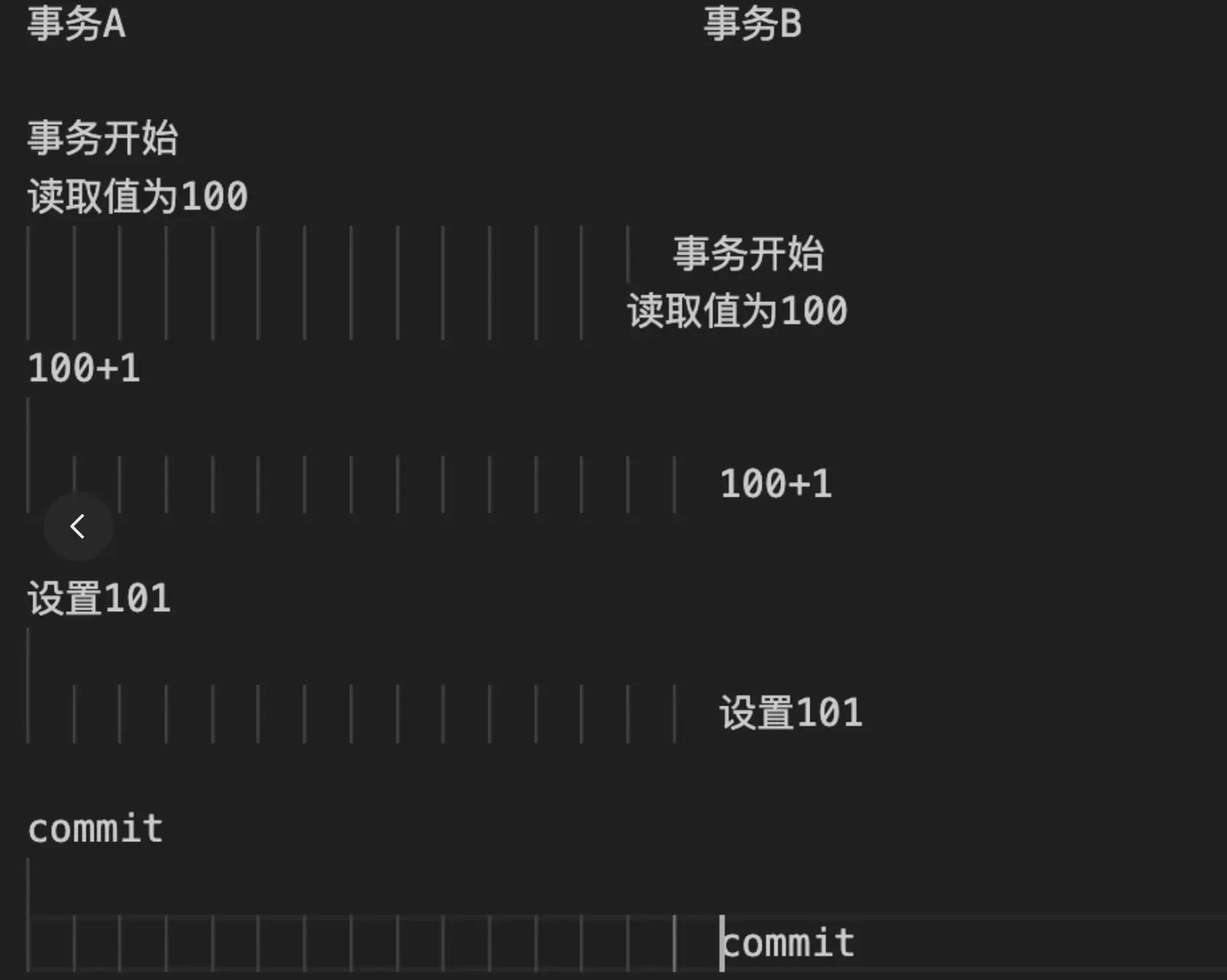
也就是说,当多个客户端同时读取相同的文章实体,然后分别对其浏览次数进行增加,并尝试保存回数据库,这有可能前面的提交会被后提交的操作覆盖,导致阅读量的的更新丢失。
update…set
最简单的解决方案就是不要取出来再更新,而是使用 mysql 的 update...set 语句,它本身自带的锁可以帮我们规避掉这种问题。
await this.articleRepository.query(
'UPDATE articles SET views = views + 1 WHERE id = ?',
[articleId],
);
这一次再用测试脚本去跑的时候,发现是没有问题的了,加的次数是对的。

乐观锁
如果你非要取出来,在代码里面做一些操作,再更新。那么也可以试试乐观锁,乐观锁的实现通常会使用比较与交换 (Compare-and-Swap,CAS) 或类似的机制来确保数据的一致性。
比较与交换是一种并发算法,用于实现原子操作,它会比较内存位置的值与预期值,如果相等则进行更新操作,否则不做任何操作或者重新尝试。
在乐观锁中,当读取实体时,会同时获取一个版本号标识,然后在保存时比较这个标识是否与读取时一致,如果一致,则执行更新操作。
具体的实现是在表里增加一个 version 字段:
ALTER TABLE jueyin.articles ADD version INT DEFAULT 0 NULL;
然后把查询出来的 version 值作为更新条件之一,判断这次更新是否生效,如果不生效,则等待并重试
async addView(articleId: number) {
const oldVersion = await this.articleRepository.findOne({
where: { id: articleId },
select: ['version'],
});
const res = await this.articleRepository.query(
'UPDATE articles SET views = views + 1,version = version + 1 WHERE id = ? AND version = ?',
[articleId, oldVersion.version],
);
// 没有更新成功
if (res.affectedRows === 0) {
await wait();
await this.addView(articleId);
}
}
当然,这个阅读量 +1 的场景其实也没必要用到乐观锁了。这里只是通过这个场景,来举例乐观锁的使用。
悲观锁
我们一般使用 SELECT FOR UPDATE 实现悲观锁,即在数据读取的同时锁定数据,以防止其他事务修改数据,从而确保当前事务能够安全地读取和更新数据。
SELECT FOR UPDATE 获取数据并将选定行上的排他锁,别的事务无法读取和修改该行的数据。
总的来说,SELECT FOR UPDATE 适用于需要确保数据一致性和完整性的场景,特别是在并发环境中需要对共享数据进行读取和修改的情况下。通过锁定数据行,可以确保在操作过程中其他事务不会对相同的数据进行修改,从而避免并发冲突和数据不一致性。
但是,这可能会导致大量的线程阻塞,因此使用与否需要根据你自身的业务场景来进行判断。
async addView(articleId: number) {
return this.entityManager.transaction(async (entityManager) => {
const query = `SELECT views FROM articles WHERE id = ? FOR UPDATE`;
const res = await entityManager.query(query, [articleId]);
const value = res[0].views + 1;
await entityManager.update(
ArticleEntity,
{ id: articleId },
{ views: value },
);
});
}
消息队列
再拓展一下,首先阅读量计数是一个频繁的逻辑。尤其对一些热榜文章来说,所以这里可以用到消息队列来做流量控制。
我们可以把一些频繁触发的任务交给消息队列去处理,然后再通过控制消息队列的消费频率或消费者个数,让一些任务可以较为平滑的处理而不是一下子全部处理,这样可以平衡系统的负载。
而且,也可以指定消息队列的消费者数量,比如你可以指定只有一个消费者,来规避上述的并发问题。
我们这里用到了 Bull ,它是一个基于 redis 的消息队列。它提供了简单而灵活的 API ,可用于实现各种队列和后台任务处理的需求。
首先安装一下需要的包:
npm i bull @nestjs/bull
然后可以在 app.module.ts 中进行配置:
@Module({
imports: [
ScheduleModule.forRoot(),
BullModule.forRoot({
redis: {
host,
port,
db: 2,
password: configService.get<string>('REDIS_PASSWORD', 'password'),
},
})
],
})
export class AppModule { }
以阅读量计数为例,当需要对文章的阅读量计数时,可以往队列里面扔一个任务,然后队列根据配置的逻辑,把任务取出来执行。
在 article.service 中,主要组装好参数,然后调用 queue-provider.service ,并加上重试逻辑
async addView(articleId: number) {
const addQueue = async (retryTime = 3) => {
if (retryTime === 0) {
return;
}
try {
const jobId = uuidv4();
await this.queueProviderService.pushAddView({
jobId,
articleId,
});
} catch (error) {
addQueue(retryTime - 1);
}
};
await addQueue();
}
这个 jobId 主要是用来保证消息只会被消费一次,至于怎么做,在流程的最后会介绍。
然后来实现一个 queue-provider.service ,它主要是操作队列,往队列里面丢东西。
import { Injectable } from '@nestjs/common';
import { InjectQueue } from '@nestjs/bull';
import { Queue } from 'bull';
import { QUEUE } from '../utils/constant';
@Injectable()
export class QueueProviderService {
constructor(@InjectQueue(QUEUE) private readonly queue: Queue) {}
async pushAddView(data: { jobId: string; articleId: number }) {
await this.queue.add('addView', data, {
attempts: 5, // 任务失败后的重试次数
backoff: {
type: 'exponential', // 两次重试之间的时间间隔将以指数形式增长
delay: 5000, // 重试时间间隔,单位:毫秒
},
});
}
}
这样,消息就被发送到了队列中,然后我们还要实现一个消息的消费者,来消费这条消息。
import { Process, Processor } from '@nestjs/bull';
import { QUEUE } from '../utils/constant';
import { ArticleService } from '../modules/article/article.service';
@Processor(QUEUE)
export class QueueConsumerService {
constructor(private articleService: ArticleService) {}
@Process('addView')
async handleAddView(job: any) {
// 处理任务
console.log('Processing job:', job.data);
const { jobId, articleId } = job.data;
await this.articleService.handleAddView({ jobId, articleId });
}
}
这里实现一个 queue-consumer.service ,用来处理消息的消费,最后还是调用了 article.service 中的方法,这里 article.service 的 handleAddView 方法就是用来真正阅读量计数的。
async handleAddView(data: { jobId: string; articleId: number }) {
const { jobId, articleId } = data;
await this.entityManager.transaction(async (transactionalEntityManager) => {
try {
await transactionalEntityManager.save(JobRecordEntity, {
jobId,
});
} catch (error) {
if (error?.sqlMessage?.includes('Duplicate entry')) {
return;
} else {
throw error;
}
}
await this.articleRepository.query(
'UPDATE articles SET views = views + 1,version = version + 1 WHERE id = ?',
[articleId],
);
});
}
好的,这里就需要提到一开始说的 jobId ,这个 jobId 可以认为是这条消息的唯一标识,我们是用 uuid 这个库生成的。一个 jobId 对应的消息只应该被消费一次,这里被消费一次的定义是,一条消息只能是阅读量 +1 。
在生产者一侧,我需要保证消息一定发成功,所以我们会加重试逻辑。但是这并不意味着消费者只收到了一条消息。所以这里需要保证消息的幂等性。
可以使用一个唯一索引来做这件事情,这里新建一张 job_records 表,并把 job_id 作为唯一索引。
-- jueyin.job_records definition
CREATE TABLE `job_records` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `job_records_job_id_IDX` (`job_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8mb4;
然后在真正消费消息的时候会开启一个事务,如果报了数据重复的数据,表示这个 jobId 已经存在,这条消息已经被消费过了,此时可以直接 return ,提交事务。
否则就正常走事务的逻辑,成功就提交,失败就回滚。
感悟
或许很多前端都有成为全栈的梦想,所以自发去学习一些后端知识。但无论是前端工程师,还是后端工程师,他们都是软件工程师。软件工程师的必备技能应该是网络、数据库、操作系统。
我见过工作几年的后端只会用框架里的分页组件,让他写一个分页 sql 写不出来;我也见过在分布式系统下用了内存缓存,导致的一些奇葩问题。。
不是说学了一些上层的 node 框架怎么用,会写写 CURD 就是全栈(虽然真正工作中大多数都是这个),我们还是要不断精进自身的能力,才能一步步成为更资深的开发。
诸君,共勉~
最后
以上就是本文的全部内容,如果你觉得有意思的话,点点关注点点赞吧~
原文链接:https://juejin.cn/post/7358704806779764777 作者:可乐鸡翅kele