
在计算机所有的内容中,无论是文字、数字、图片、音频、视频最终都会使用二进制展示。
JavaScript 可以处理非常直观的数据,例如字符串,无论是宽字节字符串或者是单字节字符串,通常我们展示给用户的也是这些内容,但是 JavaScript 处理图片这些就显得无能为力了,实际上在网页端,图片一直是交给浏览器去处理的,我们只是负责告诉浏览器一个图片的地址,浏览器最终显示出来。
由于应用场景的不同,在 Node 中,应用需要处理网络协议、操作数据库、处理图片、接受文件上传等,在网络流和文件的操作中,还要处理大量二进制数据,JavaScript 自有的字符串远远不能满足这些需求,于是 Buffer 对象应运而生。
Buffer
Buffer 类是 JavaScript Uint8Array 类的子类,并扩展了涵盖其他用例的方法。Node.js api在任何支持 buffer的地方都接受普通的 Uint8Arrays。在 Node 源码中具体有以下定义:
class FastBuffer extends Uint8Array {
constructor(bufferOrLength, byteOffset, length) {
super(bufferOrLength, byteOffset, length);
}
}
Buffer 在中文有缓冲的意思,在数据的传送过程中,数据到达的速度比进程消耗的速度快,那么少数早到达的数据会处于等待去等候被处理,反之则如果数据到达的速度比进程消耗的数据慢,那么先到达的数据需要等待一定量的数据到达之后才能被处理,这里的等待区就之的是 Buffer 缓冲区。
Buffer的基本使用
在了解了 Buffer 的一些概念我们开始对它的一些 API 进行讲解,想要查看更多的示例请查阅官方文档。
Buffer.from()
在官方文档中, Buffer.from 方法根据传进来的参数不同,它会对其进行不同的处理,具体如下所示:


在这里我们看看第四个方法,该方法接收一个字符串和一个可选参数(编码方式),返回一个新的 Buffer,其中包含所提供字符串的副本,具体实例如下所示:
import { Buffer } from "node:buffer";
const buffer = Buffer.from("moment");
console.log(buffer);
具体的返回的是一个新的 Buffer,它是一串16进制的东西,再将这些值转换为10进制的值,也可以说转换为 ASCII 值,它们会对应回原来的英文单词,具体如下图所示:

Buffer.toString()
既然可以做到编码,那么也有对应的解码方式,Buffer.toString() 就是对 Buffer 进行解码的方法,请看以下实例代码所示:
import { Buffer } from "node:buffer";
const buffer = Buffer.from("moment");
const foo = Buffer.from("你个叼毛", "utf16le");
const bar = Buffer.from("你小子", "utf16le");
const baz = Buffer.from("小黑子");
console.log(buffer); // <Buffer 6d 6f 6d 65 6e 74>
console.log(foo); // <Buffer 60 4f 2a 4e fc 53 db 6b>
console.log(bar); // <Buffer 60 4f 0f 5c 50 5b>
console.log(baz); // <Buffer e5 b0 8f e9 bb 91 e5 ad 90>
// 解码
console.log(buffer.toString()); // moment
console.log(foo.toString("utf16le")); // 你个叼毛
console.log(bar.toString()); // `O\P[
console.log(baz.toString()); // 小黑子
什么样的编码方式就应该用什么样的解码方式,如果两者不同有可能会引起乱码的情况出现,编码和解码两者如果都不传参数,默认使用的是 utf-8 的字符编码。
BUffer.alloc()
该方法返回一个已初始化的 Buffer,如果没有填充,则默认为0,具体代码示例如下所示:
import { Buffer } from "node:buffer";
const foo = Buffer.alloc(10);
const bar = Buffer.alloc(10, "hi");
foo[0] = 0x66;
console.log(foo); // <Buffer 66 00 00 00 00 00 00 00 00 00>
console.log(bar); // <Buffer 68 69 68 69 68 69 68 69 68 69>
Buffer和文件之间的操作
在 Node 中,操作图片等文件是最常见不过的操作了,那么接下来我们看看通过 fs 模块读取过来的内容是一个怎么样的数据,具体如下所示:
import { readFileSync } from "node:fs";
const file = readFileSync("./moment.jpg");
console.log(file);
最终查看终端有如下输出:

我们可以通过返回的数据来进行操作,可以直接进行文件的写操作,具体代码如下所示:
import { readFileSync, writeFileSync } from "node:fs";
const file = readFileSync("./moment.jpg");
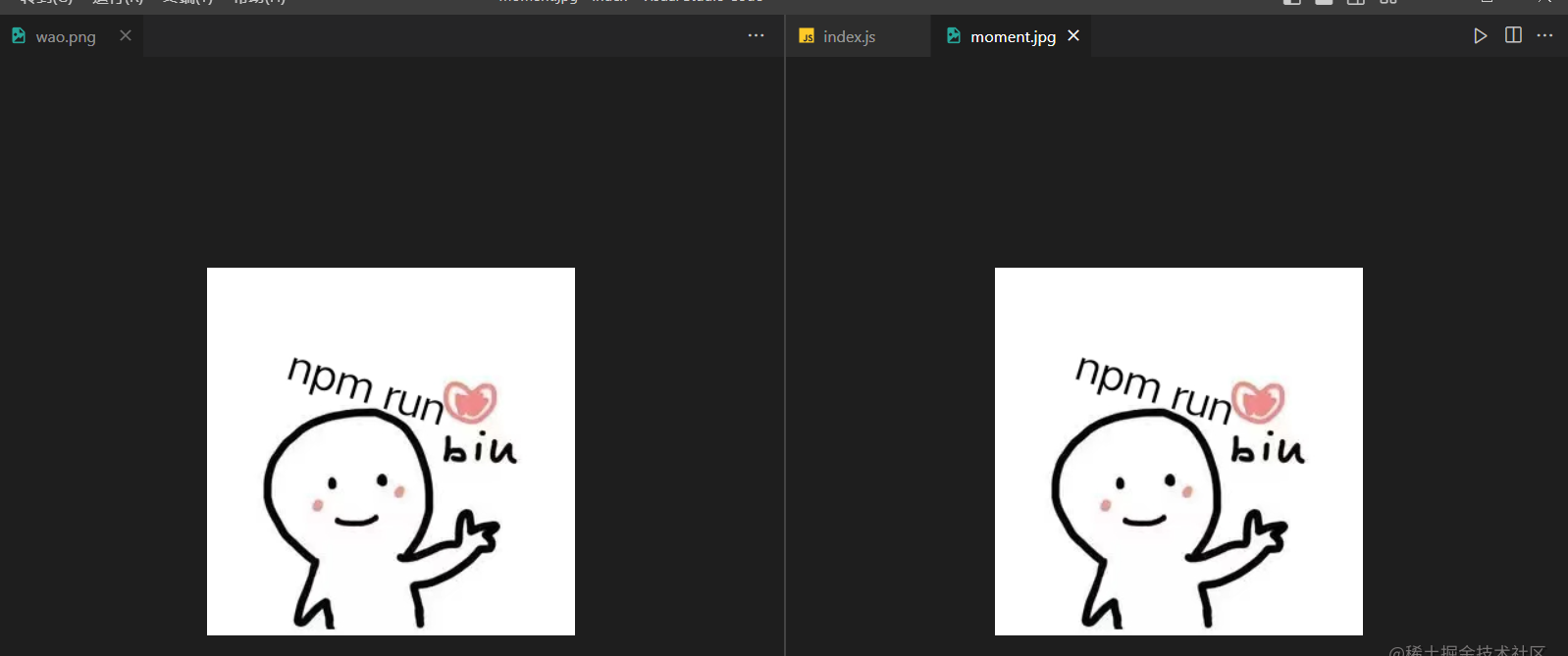
writeFileSync("./wao.png", file);
执行代码你会发现图片被完整的输出了,如下图所示:
Buffer的内存分配
Buffer 对象的内存分配不是在 V8 的堆内存中,而是在 Node 的 C++ 层面实现内存的申请的,引起理大量的字节数据不能采用需要一点内存就向操作系统申请一点内存的方式,这可能造成带量的内存申请的系统调用,对操作系统有一定压力。为此 Node 在内存的使用上应用的是 C++ 层面申请内存,在 JavaScript 中分配内存的策略。这种内存的分配方式被称为堆外内存。
为了高效地使用申请来的内存,Node 采用了 slab 分配机制,它是一种动态内存分配管理机制,简单而言它就是一块申请好的固定大小的内存区域,它分为以下三种状态:
- full: 完全分配状态;
- partial: 部分分配状态;
- empty: 没有被分配状态;
因为当我们创建 Buffer 时,并不会频繁的向操作系统申请内存,它会默认申请一个 8 * 1024 个字节打下的内存,也就是 8kb,它在源码中有如下的定义:
Buffer.poolSize = 8 * 1024;
此时,新构造的 slab如下图所示:

当我们分配一个大小为 1 KB的 Buffer 对象之后,slab 的内存如下图所示:

这个时候的 slab 状态为 partial,当再次创建一个 Buffer 独享时,构造过程中将会判断这个 slab 的剩余空间是否足够,如果足够,使用剩余空间,并更新 slab 的分配状态,再次分配的示意图如下图所示:

如果 slab 剩余的空间不够,将会构造新的 slab,原 slab 中剩余的空间会造成浪费。
由于同一个 slab 可能分配给多个 Buffer 对象使用,只有这些小 Buffer 对象都在作用域释放时并都可以回收时,slab 的 8KB 空间才会被回收,尽管创建一个字节的 Buffer 对象,但是如果不释放它,实际可能是 8KB 内存没有被释放。
Buffer 对象分配
在整个应用启动的时候,Node 就直接调用了 createPool() 方法来初始化了一个 8kb 的内存空间,这样在第一次进行内存分配时也会变得更高效,另外在初始化的同时还初始化了一个新的变量 poolOffset = 0 这个变量会记录已经使用了多少字节,在源码中的具体定义如下所示:
Buffer.poolSize = 8 * 1024;
let poolSize, poolOffset, allocPool;
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeBuffer(poolSize).buffer;
markAsUntransferable(allocPool);
poolOffset = 0;
}
createPool();
Buffer的拼接
Buffer 在使用场景中,通常是以一段一段的方式传输,以下是常见的从输入流中读取内容的示例代码,如下所示:
import { createReadStream } from "fs";
const result = createReadStream("./moment.md");
let data = "";
result.on("data", (chunk) => {
data += chunk;
});
result.on("end", () => {
console.log(data); // 不是所有的牛奶都叫特仑苏
});
一旦输入流中有宽字节编码时,问题就会暴露出来,如果你在通过 Node 开发的网站看到乱码符号 �,那么该问题的起源多半来自于这里,在上面的代码中,data += chunk; 等价于下列的代码,如下:
data = data.toString() + chunk.toString();
值得注意的是,歪国人的语境通常是指英文环境,在它们的场景下,这个 toString() 不会造成任何问题,但对于宽字节的中文,却会形成问题,我们将文件可读流每次读取的 Buffer 长度限制为 7,具体情况如下代码所示:
import { createReadStream } from "fs";
const result = createReadStream("./moment.md", { highWaterMark: 7 });
let data = "";
result.on("data", (chunk) => {
data += chunk;
});
result.on("end", () => {
console.log(data); // 不是���有��牛奶都叫���仑��
});
在上面的示例中,产生这个输出结构的原因在于文件可读流在读取时会逐个读取 Buffer,我们将其设置了 Buffer 对象的长度为 7,它需要读取多次才能完整的读取,在这个过程,我们已知一个中文的长度为三个长度的 Buffer 对象,这就导致了有些数据的 Buffer 对象是缺失的,所以只能显示乱码了,我们在看上面的输出,7 个长度的 Buffer 对象只能读取两个中文,所以在 不是 后面也就显示了 � 乱码了。
Buffer 的 JS 层的实现
Buffer 模块的实现非常复杂,代码也非常多,但是很多都是编码解码以及内存分配的逻辑,在 Node 中,它的实现方式分为三种,分别是:
JavaScript层实现;C++层实现;C++层的另一种实现;
我们从常用的使用方式 Buffer.from 来看看 Buffer 的核心实现,具体代码如下所示:
Buffer.from = function from(value, encodingOrOffset, length) {
if (typeof value === "string") return fromString(value, encodingOrOffset);
};
function fromString(string, encoding) {
return fromStringFast(string, ops);
}
function fromStringFast(string, ops) {
const length = ops.byteLength(string);
// 长度太长,从 C++ 层分配
if (length >= Buffer.poolSize >>> 1)
return createFromString(string, ops.encodingVal);
// 剩下的不够了,扩容
if (length > poolSize - poolOffset) createPool();
let b = new FastBuffer(allocPool, poolOffset, length);
const actual = ops.write(b, string, 0, length);
if (actual !== length) {
b = new FastBuffer(allocPool, poolOffset, actual);
}
poolOffset += actual;
alignPool();
return b;
}
这段代码的主要逻辑如下:
- 如果长度大于
Node.js设置的阈值,则调用createFromString通过C++层直接分配内存; - 否则判断之前剩下的内存是否足够,足够则直接分配。
Node.js初始化时会首先分配一大块内存由JavaScript管理,每次从这块内存了切分一部分给使用方,如果不够则扩容;
在上面的代码中出现了 createPool() 函数的调用,该函数在前面已经讲过了,在该函数中 通过 new FastBuffer(allocPool, poolOffset, length) 从内存池中分配一块内存。
参考资源
- 书籍:
深入浅出 Node.js - Node官网
- Node.js 源码剖析
总结
体验过 JavaScript 友好的字符串操作后,有些开发者可能会形成思维定势,将 Buffer 当做字符串来理解。但字符串与 Buffer 之间有实质上的差异,即 Buffer 是二进制数据,字符串与 Buffer 之间存在编码关系。
在文章的标题中为什么称之为卧龙呢,因为我觉得这个在 Node 的核心模块比较难的一个,有卧龙的地方就有凤雏了,另外一个是流,我们将会在下一篇文章中讲解,敬请期待,马上就呈上。
本文正在参加「金石计划」
原文链接:https://juejin.cn/post/7222952967459717177 作者:Moment