

我正在参加「掘金·启航计划」,这篇文章主要是对 npm 的深入解析,2010 年 1 月,一款名为 npm 的包管理器诞生,时至今日,npm 已经从前端领域最早、而且最初只是为 Node.js 设计的包管理器演变成目前最大、生态最为健全的现代包管理工具,这里我想对它的架构及包安装原理进行一个深入解析。
npm 架构分析
一、npm 整体结构
在官方文档中,npm 包含 3 个组成部分:
- the website(网站)
- the Command Line Interface (CLI,命令行工具)
- the registry(源)
具体如下图所示:


从产品功能看,npm 包括 npm 网站、npm 源和 npm CLI 三个部分;从软件架构看,npm 又可以分为客户端和服务端两块。
- npm 源是 npm 的核心。npm 源是一个纯服务端的产品,包含一个超大数据库和一套读写数据库的接口。超大数据库目前用 Apache CouchDB 实现。数据库存储了软件包及其元数据、用户数据、钩子数据等,相应的读写接口定义在 registry api docs 中(这个文档不是太全)。
- npm 网站提供对 npm 源的可视化访问,通常包括软件包信息查询和用户信息查看及设置等功能。
- npm CLI 是一个功能强大的 npm 客户端,封装了对 npm 源的读写功能及对软件包数据的本地管理功能。
二、npm 源
npm 源可以大致分为官方源、镜像源和私有源三种。对应的 npm 网站为官方网站、镜像网站和私有网站。不同的 npm 源的路径是相同的,域名是不同的,所以一般用域名来指代某个特定的 npm 源。通过配置 registry 选项为各种 npm 源域名,npm cli 可以在不同的 npm 源之间无缝切换。
三种源之间的关系如下:
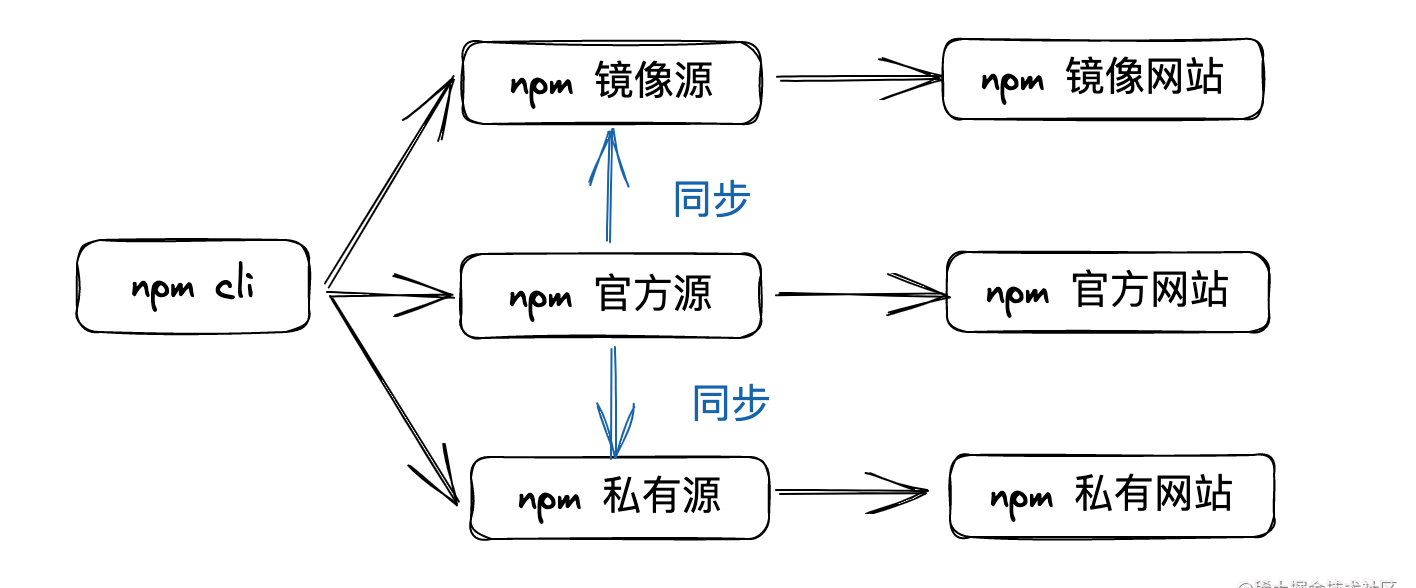
三种源示例如下:
| 分类 | npm 源 | npm 网站 |
|---|---|---|
| 官方域名 | registry.npmjs.org | npmjs.org |
| 国内镜像域名 | r.cnpmjs.org | cnpmjs.org |
| 淘宝镜像域名 | registry.npm.taobao.org | npm.taobao.org |
| 字节跳动私有域名 | bnpm.byted.org | web-bnpm.byted.org |
1、npm 官方源
npm 官方源即 npm 官方提供的 npm 源。
2、npm 镜像源
由于官方源只有一个,全世界都要访问,网络链路长,并发量大,访问速度很难得到保证。由于官方源使用了 CDN 技术,整体访问速度还是可以的。为了提升访问速度,国内就出现了一些镜像源。镜像源与官方源一样,都是可以公开访问的。镜像源会定时从官方源同步软件包数据,一般通过 npm replicate api 实现。注意,镜像源一般只同步软件包数据,不同步用户数据等其他数据,也不维护登录态;镜像源一般只能读,不能写,比如不能发布软件包。因此,镜像源一般只实现软件包读取相关的 npm registry api。
3、npm 私有源
在使用 npm 的过程中,大公司一般希望自己的软件包不对外开放。为了达到这个目的,需要实现一个 npm 私有源。npm 私有源不仅要完成对软件包等数据的存储,还需要实现一套完整的 npm registry api。公司成员在使用 npm 私有源时,也希望可以访问公有源中的软件包。所以,npm 私有源一般会定时从 npm 公有源或 npm 镜像源同步软件包数据。另外,大公司一般会开发一个与 npm 私有源对应的 npm 私有网站。
npm 私有源几乎拥有 npm 公有源的全部功能。npm 私有源和 npm 公有源是完全独立的。为了便于管理,npm 私有源一般使用私有的用户鉴权系统。因此,两种源之间的登录态是完全独立的。如果希望发布在 npm 私有源上的软件包被外部用户访问,必需重新发布到 npm 官方源。
三、npm cli
除了 npm 源可以换,npm CLI 也是可以换的。Yarn 是一个后起之秀。Yarn 不仅支持 npm 源,还支持 Bower 源。相比 npm 官方 CLI: npm/cli, Yarn 更年轻,得到的关注更多,发展得也更快。Yarn 的优化特性反过来推动了 npm/cli 的发展。
当然,这些优化特性大部分在依赖包数目比较大时才能体现出来。

npm 的进化史
一、嵌套结构的依赖
npm 在最早期的 v1/v2 中的工作模式跟现在有很大区别,最主要的就是 node_modules 的目录管理,它采用了一种最直接的嵌套式结构,以下面的依赖关系为例:
Root -> A -> B
-> C -> B
项目依赖于包 A 和 C,并且 A 和 C 都依赖于包 B,这个时候项目的 node_modules 目录结构如下图所示:

如上图所示应用中 node_modules 的目录是层层嵌套的,这样的目录结构其实很符合我们的直觉,依赖包的安装和目录结构都十分清晰且可预测,但是却引来两个极为严重的问题:
1、重复安装
在上面的示例中就可以很明显的看出来,B 包被 A 依赖,同时也被 C 所依赖,因此 B 包就分别在 A 和 C 之下分别被安装了一次。此种设计结构直接导致了node_modules 体积过度膨胀,这也是臭名昭著的 Dependency Hell 问题。
2、嵌套层级过深
假设上面的示例中 B 包还依赖于 D 包,D 包还依赖于 E 包这样 node_modules 的目录结构会一直持续下去直到最终到某个没有其他依赖的包为止,因此稍微复杂一点的项目 node_modules 目录的嵌套层级往往会非常深。而 Windows 以及一些应用工具无法处理超过 260 个字符的文件和文件夹路径,嵌套层级过深则会导致相应包的路径名很容易就超出了能处理的范围 ,因此会导致一系列问题。比如在想删除相应的依赖包时,系统就无法处理了。(详情可以查看:Node’s nested node_modules approach is basically incompatible with Windows)
除此之外,npm 还存在一些问题被人诟病:
-
SemVer 版本管理使得依赖的安装不确定
-
缓存能力存在问题,且无离线模式
因此面对上述问题,特别是依赖包重复安装,经过社区的反复讨论,npm v3 几乎进行了重写。
二、扁平化
针对 npm v1/v2 暴露的问题在 npm v3 中提出的解决方案就是扁平化,上面的示例在 npm v3 扁平化改造之后变得完全不同:

npm v3 在处理 A 的依赖 B 时,会根据扁平化的核心 hoist 机制会将其提升到顶级依赖,然后再处理 C 包,然后发现 C 依赖的 B 包已经被安装了,就不用再重复安装了。
看起来这种机制极大程度上解决了 npm v1/v2 重复安装与嵌套层级过深的问题,但它实际上依然不是完美方案,依然存在如下问题:
1、幽灵依赖(phantom dependencies)
幽灵依赖,指的是业务代码中能够引用到 package.json 指定依赖以外的包。拿上面提到过得依赖关系为例:

package.json 中实际只写明了项目依赖 A包 和 C 包 ,但是由于 hoist 机制,B包 被提升到了 node_modules的第一层目录中,那么依照 node 依赖查找的方式,在我们的业务代码中是可以直接引用 B 包的。虽然乍一看也没有比较大的问题,但是 B 的版本管理是不在我们的感知之内的。也许某个时期使用了 B 包的某个方法看起来没有什么问题,等到下次 A 包有更新,相应的 A 包引用的 B版本也有了 breaking change 的更新,那么我们在原本代码中使用 B 的方法可能就出现报错。
2、依赖分身 (doppelgangers)
为了说明这个问题我们在上面的实例引入版本,具体依赖关系如下所示:
Root -> A_v1 -> B_v1
-> C_v1 -> B_v2
-> D_v1 -> B_v2
此时 node_modules 目录结构变为:
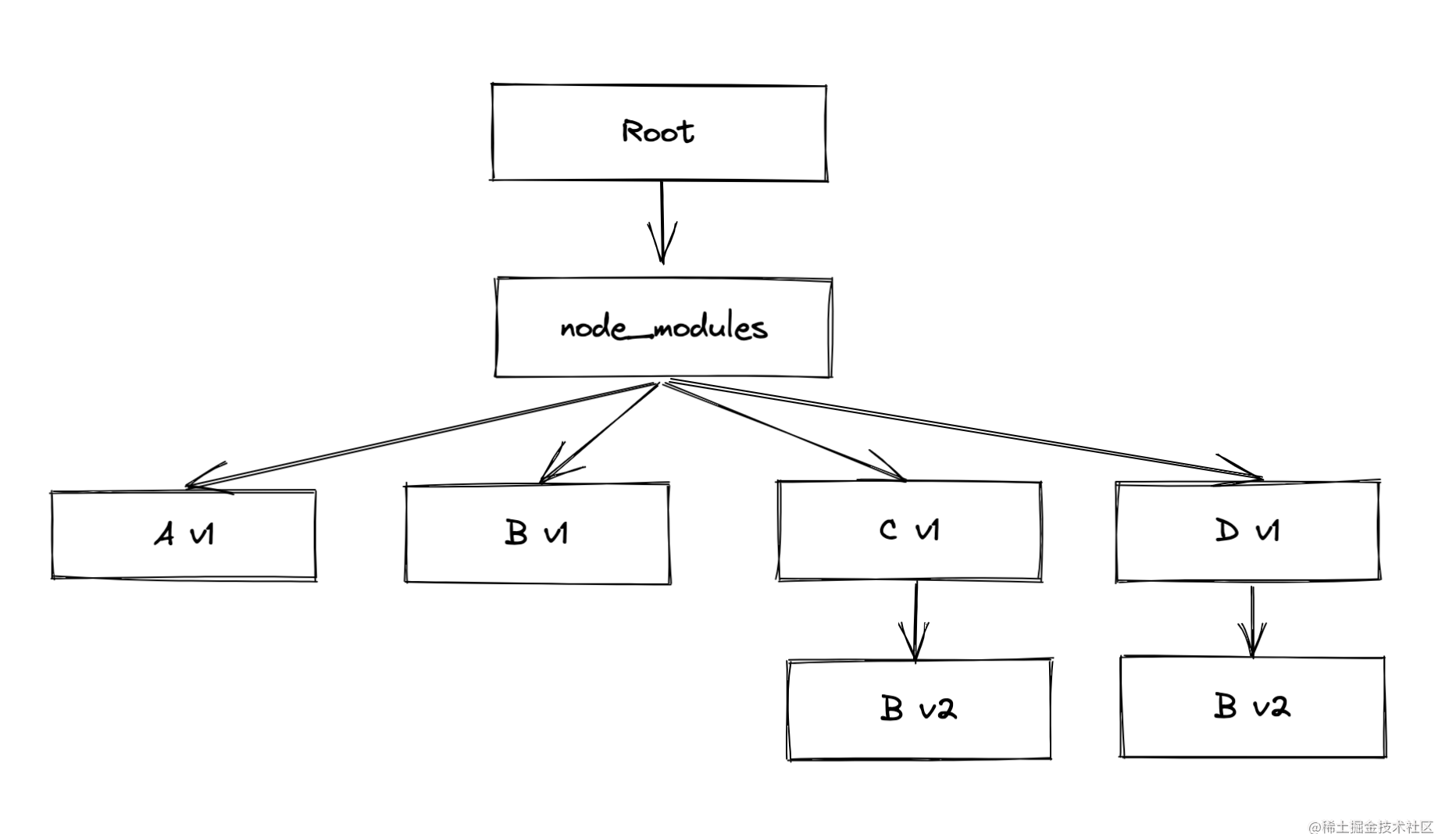
如上图所示,在依赖分析过程中,检查到 A v1 依赖了 B v1,因此将 B v1 提升到了顶层。再检查到 C v1 依赖了 B v2 时,发现顶层已经存在了 B v1,因此 B v2 无法提升到顶层,那么只能接着放在 C v1 之下,同样 D v1 依赖的 B v2 也只能放到 D v2 的下面。
C v1 和 D v1 的依赖都是 B v2 版本,不存在任何差别,但是却依然被重复安装了两遍,这个现象就叫做 doppelgangers,中文一般称为“依赖分身”,也被叫做 “双胞胎陌生人”问题。
3、依赖不幂等 (Non-Determinism)
先不考虑依赖分身的现象,可以转过来思考一下 B v2 明明有两个却没有提升到顶层,仍然还是 B v1 在顶层,是什么决定的这个关系呢。
安装顺序很重要。
正常来说,如果是 package.json 里面写好了依赖包,那么 npm install 安装的先后顺序则由依赖包的字母顺序进行排序,那如果是使用 npm install 对每个包进行单独安装,那就看手动的安装顺序了。
这里网上大部分说法是这里的安装顺序主要是根据 package.json 里面的顺序,放在前面的包依赖的内容会被先提出来,实际上 npm 其实会调用一个叫做 localeCompare 的方法对依赖进行一次排序,实际上就是字典序在前面的 npm 包的底层依赖会被优先提出来。 )
如果是先安装的 C v1 ,然后再安装的 A v1,那么提升到顶层的就是 B v2 了。
如果情况再复杂一点,项目又依赖了 E v1 的包:
Root -> A_v1 -> B_v1
-> C_v1 -> B_v2
-> D_v1 -> B_v2
-> E_v1 -> B_v1
那么目录结构就会变成:
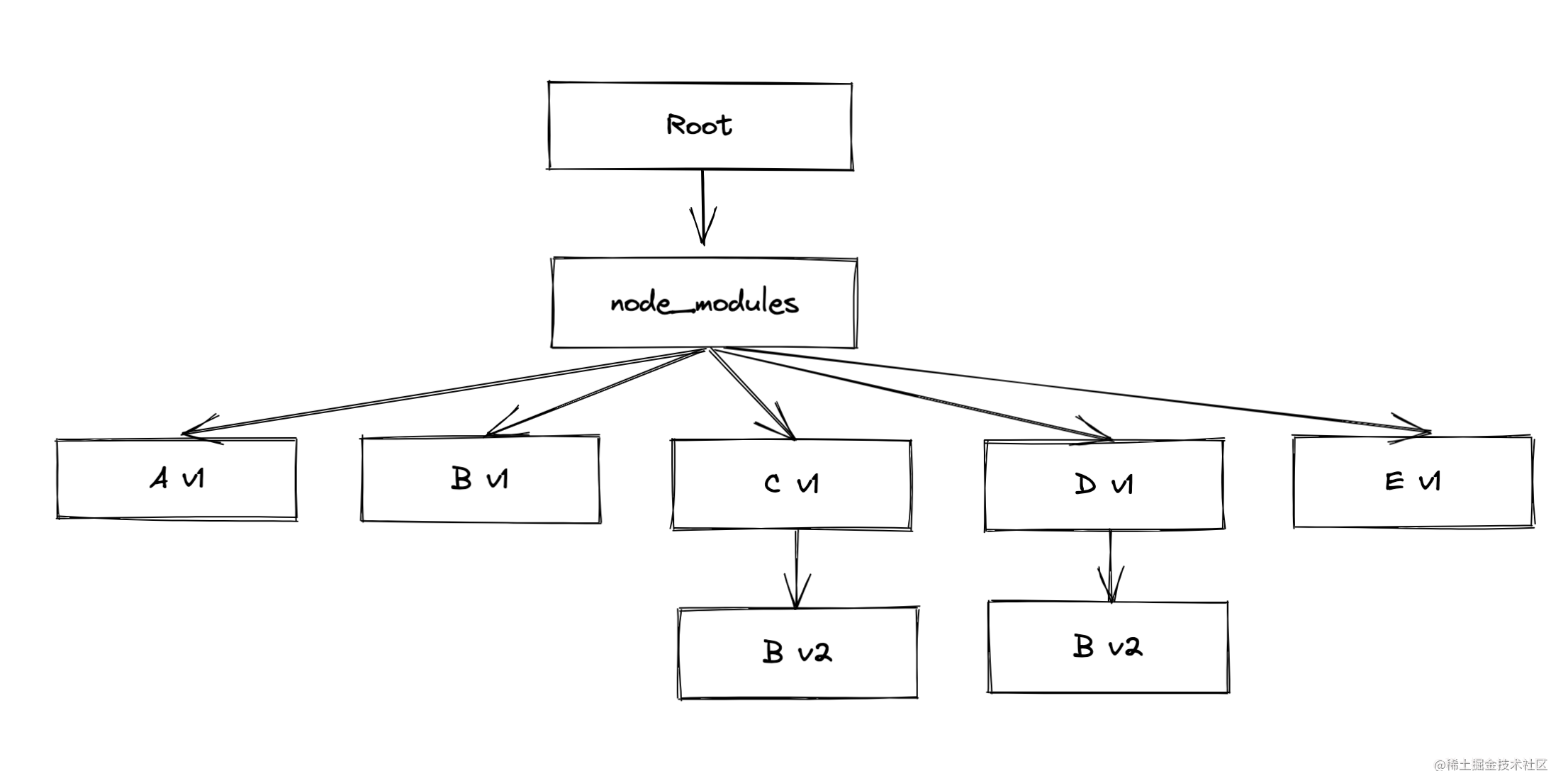
假设之后的迭代过程中, A v1 包被手动升级成 A v2,其依赖项变成了 B v2,那么本地的依赖树结构就变成了:

因为是直接升级的A版本,而不是删掉 node_modules 进行重新安装,而由于 E v1 存在,那么 B v1 不会被从 node_modules 中删掉,因此 A v2 的依赖包 B v2 仍然得不到提升,而是依然放在 A v2 之下。
但是,当这版代码上传到服务器上进行部署时,依赖进行重新安装,由于 A v2 的依赖会被最先安装,所以服务器上的依赖树结构则为如下:
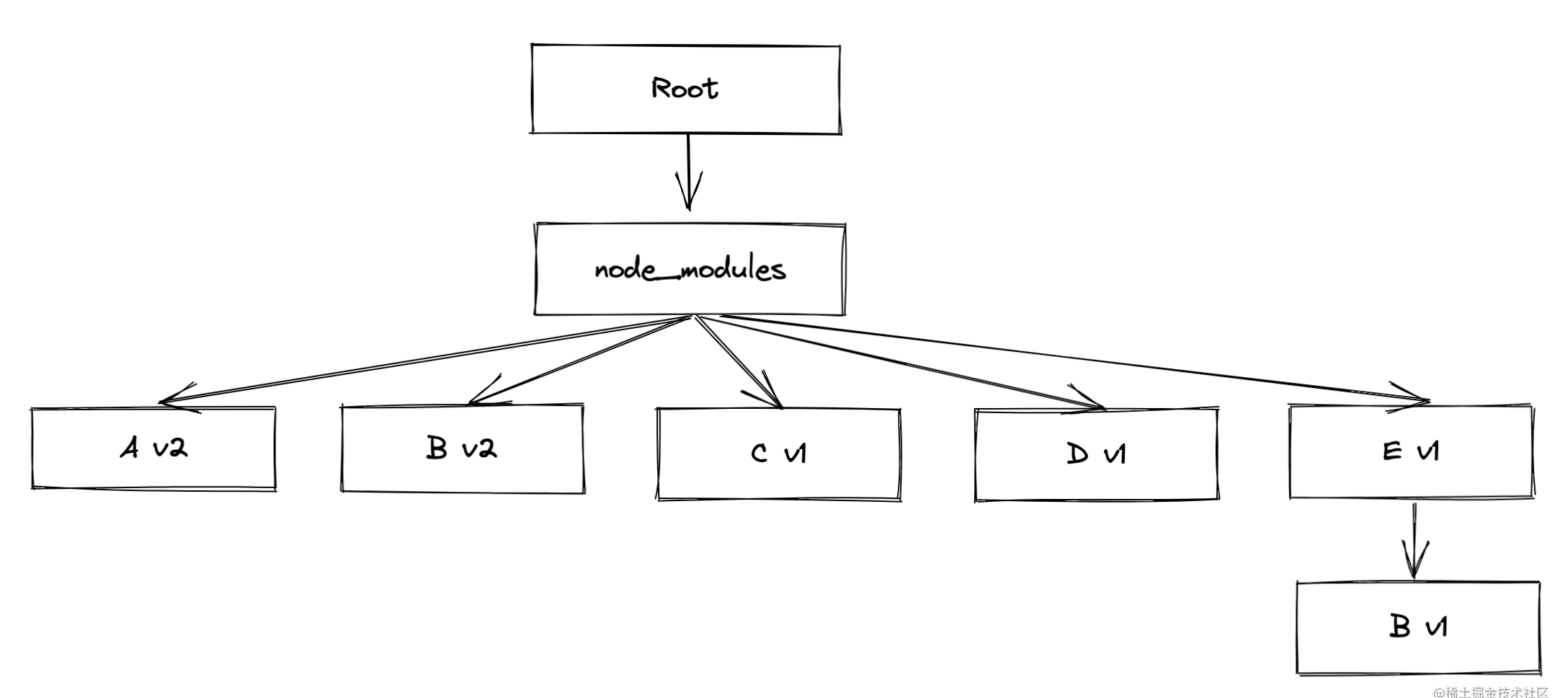
因此可见,本来就因为 SemVer 机制导致的依赖不幂等问题被进一步放大了。
4、锁文件
上面提到三个典型问题,其中依赖不幂等的问题在 npm v3 中是提出了相应的解决方法的,那就是 npm-shrinkwrap.json 文件
在 npm v3 版本中,需要手动运行 npm shrinkwrap 才会生成 npm-shrinkwrap.json 文件,之后每次改动版本依赖,都无法自动更新 npm-shrinkwrap.json 文件,仍然需要手动运行更新,因此这个特性对于开发者来说有一定的成本(开发者可能不知道该特性,或者没有每次及时更新)。
之后受到 yarn.lock 的启发,npm 在 v5 版本中设计了我们现在比较熟悉的 package-lock.json 文件,此时锁文件就是自动生成和更新了。
在2016年 yarn 推出 yarn.lock 后 npm 在2017年才推出了 package-lock.json
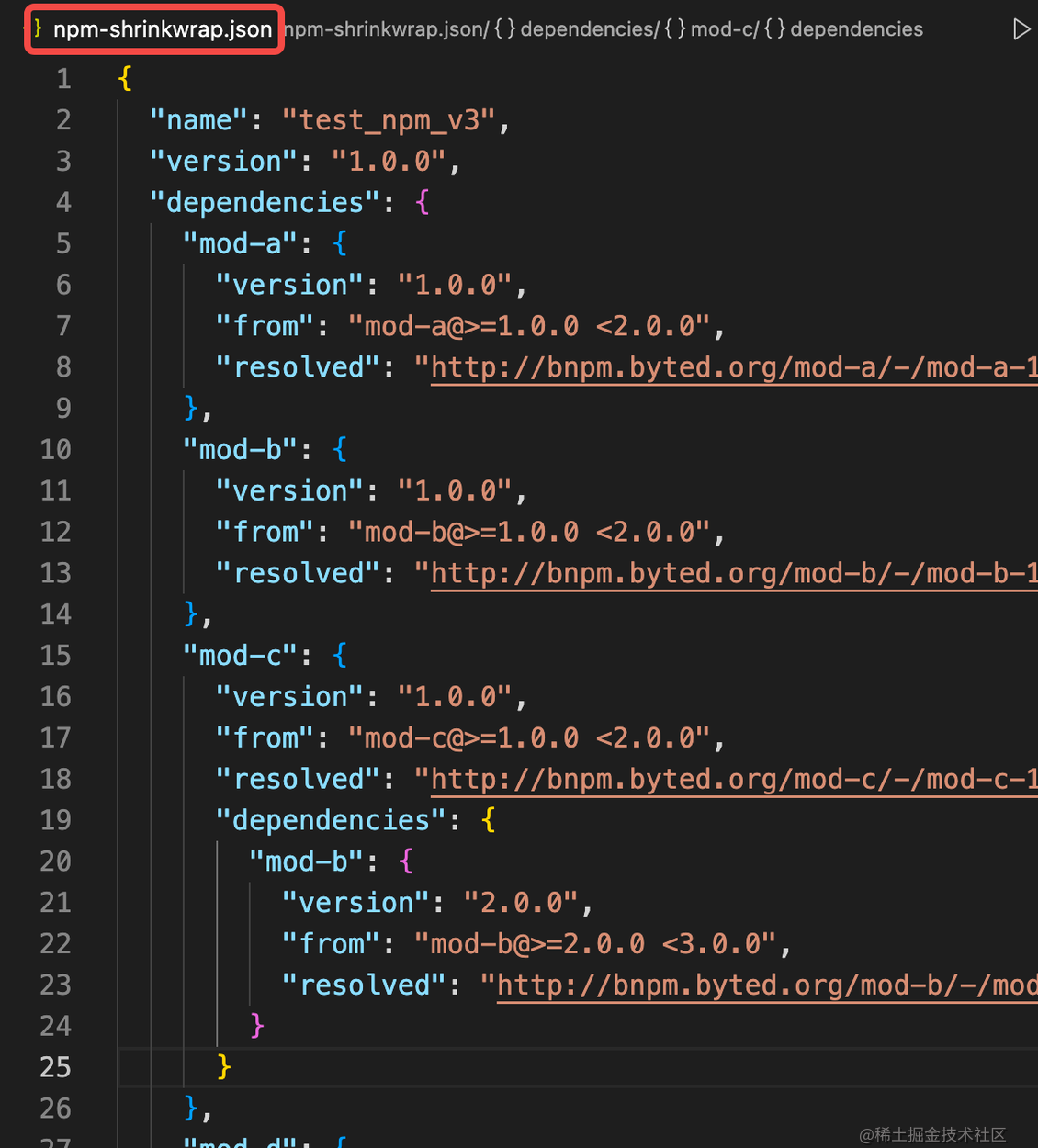

package-lock.json 文件的结构如下所示:
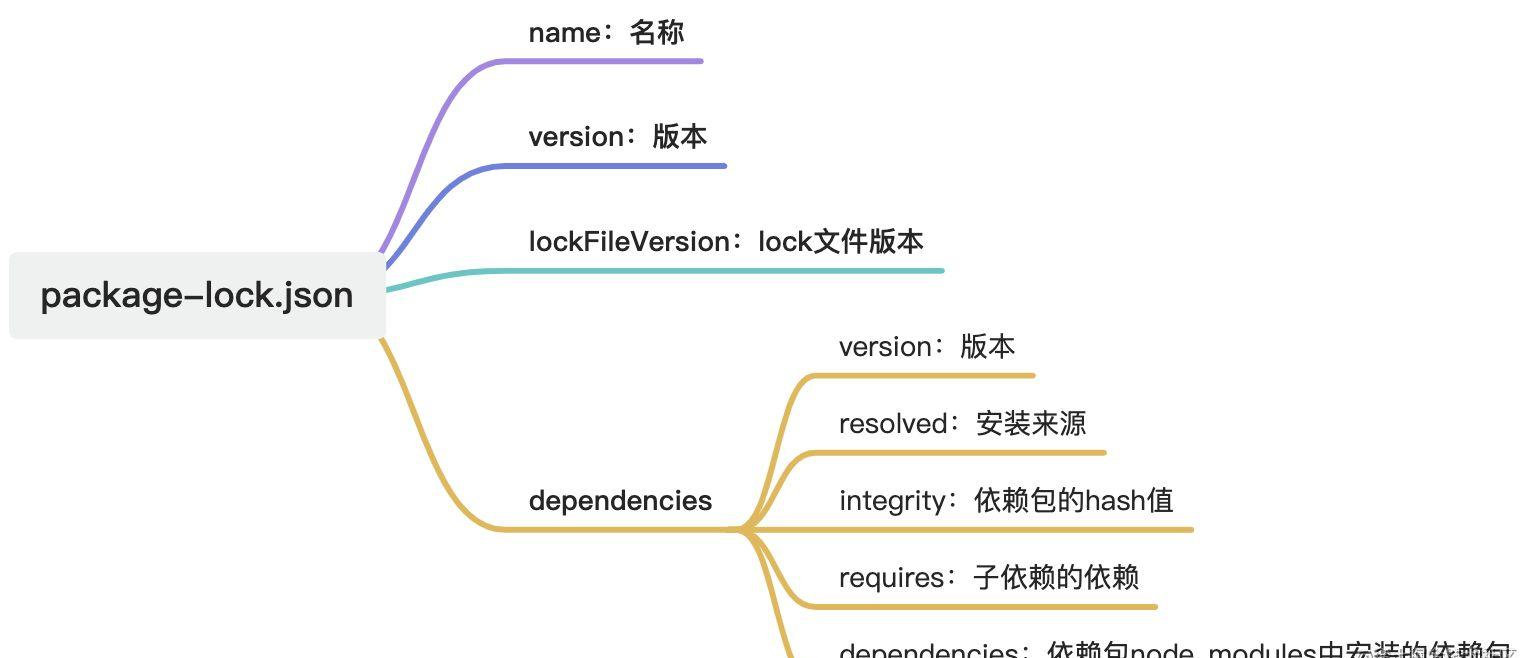
package-lock.json 文件精确描述了 node_modules 目录下所有的包的树状依赖结构,每个包的版本号都是完全精确的,因为这个文件记录了 node_modules 里所有包的结构、层级和版本号甚至安装源,它也就事实上提供了 “保存” node_modules 状态的能力。只要有这样一个 lock 文件,不管在哪一台机器上执行 npm install 都会得到完全相同的 node_modules 结果。
可以看到 package-lock.json 和 npm-shrinkwrap.json 的作用基本一致,只有一些细微差别:
- package-lock.json 不会在发布包中出现。
之前 npm-shrinkwrap.json 允许在发布包中进行版本控制,这样使得子依赖包的版本不容易被共享,从而增加依赖包的体积。 - package-lock.json 多了 integrity 参数,用来进行包的 Subresource Integrity验证。
在本地存在 package-lock.json 文件的情况下,npm 就不需要再去请求查看依赖包的具体信息和满足要求的版本,而是直接通过 lock 文件中内容先去查找文件缓存。若发现没有缓存则直接下载并进行完整性校验,如若无误,则安装。
这边简单举例一下完整性校验的demo,拿 mod-a 包为例,其 integrity 值为:
sha512-LHSY3BAvHk8CV3O2J2zraDq10+VI1QT1yCTildRW12JSWwFvsnzwLhdOdrJG2gaHHIya7N4GndK+ZFh1bTBjFw==
// 其格式为:(加密函数)-(摘要)
那么先下载包,包路径为 resolved 值: http:///mod-a/-/mod-a-1.0.0.tgz
然后对包进行 SHA512 加密并进行 base64 编码:

发现下载下来的依赖包计算出来的 integrity 值和本地的 integrity 值一致,则通过校验。
npm install 原理解析
前面我们介绍了在不同版本 npm 中依赖包的不同嵌套结构,那么这个嵌套结构是如何发生的呢?在执行 npm install 的过程中又发生了什么呢?
一、long long ago
在早期版本中这个过程是非常简单的,npm 会以递归的形式,严格按照 package.json 结构以及子依赖包的 package.json 结构将依赖安装到他们各自的 node_modules 中。那么具体每个依赖包的安装过程主要分三步:
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在
~/.npm目录 - 解压压缩包到当前项目(子依赖包)的 node_modules 目录
这里的 registry 就是我们前面提到的 npm 源,以 npmjs.org 为例,它的查询服务网址是 registry.npmjs.org/ 。这个网址后面跟上模块名,就会得到一个 JSON 对象,里面是该模块所有版本的信息。比如,访问 registry.npmjs.org/react,就会看到 react 模块所有版本的信息。
它跟如下命令的效果是一样的:
$ npm view react
$ npm info react
$ npm show react
$ npm v react
registry 网址的模块名后面,还可以跟上版本号或者标签,用来查询某个具体版本的信息。比如访问 registry.npmjs.org/react/v0.14… React 的 0.14.6 版。
返回的 JSON 对象里面,有一个 dist.tarball 属性,是该版本压缩包的网址。
dist: {
shasum: '2a57c2cf8747b483759ad8de0fa47fb0c5cf5c6a',
tarball: 'http://registry.npmjs.org/react/-/react-0.14.6.tgz'
},
到这个网址下载压缩包,然后会将这个包放置在 ~/.npm 目录下缓存,这个目录下会存放着大量用户已经安装过模块的压缩包,储存结构是 {cache}/{name}/{version} ,下次如果再用到
$ npm cache ls react
~/.npm/react/react/0.14.6/
~/.npm/react/react/0.14.6/package.tgz
~/.npm/react/react/0.14.6/package/
~/.npm/react/react/0.14.6/package/package.json
可以看到每个模块的每个版本,都有一个自己的子目录,里面是代码的压缩包 package.tgz 文件,以及一个描述文件 package/package.json。
但是,事实上运行 npm install 的时候,只会检查 node_modules 目录,而不会检查 ~/.npm 目录。也就是说,如果一个模块在 ~/.npm ****下有压缩包,但是没有安装在 node_modules 目录中,npm 依然会从远程仓库下载一次新的压缩包。
这种方式好处是可以保证总是取得最新代码,但是它也极大地影响了我们的安装速度,因此 npm 提供了一个 --cache-min 参数,使我们可以从缓存目录安装模块。
--cache-min 参数指定一个时间(单位为分钟),只有超过这个时间的模块,才会从 registry 下载。
$ npm install --cache-min 9999999 <package-name>
上面命令指定,只有超过999999分钟的模块,才从 registry 下载。实际上就是指定,所有模块都从缓存安装,这样就大大加快了下载速度。
但是,这并不等于离线模式,这时仍然需要网络连接。因为 --cache-min 实现有一些问题。
(1)如果指定模块不在缓存目录,那么 npm 会连接 registry,下载最新版本。这没有问题,但是如果指定模块在缓存目录之中,npm 也会连接 registry,发出指定模块的 etag ,服务器返回状态码304,表示不需要重新下载压缩包。
(2)如果某个模块已经在缓存之中,但是版本低于要求,npm会直接报错,而不是去 registry 下载最新版本。
另外根据是否离线或失去对目标远程仓库的访问权限,npm 还提供了 fallback-to-offline 模式。该模式使无法访问远程仓库的情况下,npm 将直接使用本地缓存。
此外还提供了新的参数,是用户可以指定缓存使用的策略
- –prefer-offline: 将使 npm 跳过任何条件请求(304检查)直接使用缓存数据,只有在缓存无法匹配到的时候,才去访问网络。这样我们将依赖包添加到项目的过程就会快很多。例如,
npm install express --prefer-offline将现在缓存中匹配 express,只有在本地缓存没有匹配到的情况下,才去联网下载。 - –prefer-online: 与它将强制 npm 重新验证缓存的数据(使用304检查),并使用重新验证的新鲜数据刷新缓存。
- –offline 将强制 npm 使用缓存或退出。如果尝试安装的任何内容尚未在缓存中,则它将出现代码错误。
至此我们简单介绍了在早期版本中 npm install 中模块安装的主要过程并介绍了一下缓存机制,除了之前我们提到嵌套结构本身的缺陷外其在安装过程中也并没有很好的利用缓存来加快安装速度,我们接着来介绍 npm v5 以后的模块下载流程。
二、npm cache
在详细介绍 npm v5 以后模块下载流程之前我们先介绍一下 npm cache,npm cache 是 npm 包管理器的一个内置缓存系统,用于存储和管理从 registry(npm 官方仓库)下载的软件包,以便在以后的安装过程中更快地访问它们。
1、npm cache的目录结构
npm cache 的目录结构与 npm 的版本有关。在 npm v5 之前,npm cache 的目录结构如下所示:
~/.npm
└── cache
├── package_name
└── ...
其中,~/.npm 是 npm 的主目录,cache 目录存储缓存。每个缓存项的目录名称是包名,里面存储了对应包的缓存。
在 npm v5 及之后的版本中,npm cache 的目录结构发生了改变。现在,npm cache 的目录结构如下所示:
~/.npm
├── _cacache
├── content-v2
├── index-v5
└── tmp
其中,_cacache 目录存储缓存,content-v2 目录存储了所有下载过的包文件,这些包文件都以 tar 包的形式存储在该目录下;index-v5 目录存储了所有缓存的包文件的元数据信息,包括包名、版本号、缓存路径、缓存时间等。这些信息被存储在一些 .json 文件中,以方便 npm 快速地读取和查询;tmp 目录存储缓存的临时文件。registry.npmjs.org 目录存储从官方 npm registry 下载的包的缓存。
2、npm cache 命令
在讲解 npm 包安装实现的过程中有一个绕不开的概念就是 npm cache,在早期版本中,npm 包管理器缓存的工作方式与现在不同。缓存的默认行为是将所有已下载的软件包存储在本地磁盘上,并且缓存的位置是不可配置的。此外,npm 还没有提供任何直接的方式来清理缓存中的软件包。
随着时间的推移,npm 不断改进了缓存的行为,引入了 npm cache 命令,允许开发人员更好地管理缓存。npm cache 命令提供了多个子命令,可以用于管理 npm 包管理器的缓存。以下是一些常用的 npm cache 命令:
- npm cache ls: 列出当前 npm 缓存中的所有软件包及其相关信息。
- npm cache clean: 清除 npm 缓存中的所有软件包。
- npm cache verify: 验证缓存的有效性并删除过期的条目。
- npm cache add: 将软件包添加到 npm 缓存中,以便以后使用。
- npm cache rm: 从 npm 缓存中删除指定的软件包。
- npm cache dir: 显示当前 npm 缓存的目录路径。
- npm cache –force: 强制执行 npm 缓存操作,即使存在错误或警告。
这些命令允许开发人员更好地管理 npm 缓存,包括清理不需要的软件包、检查缓存的有效性以及添加和删除软件包。
3、npm cache 实现原理
pacote 子系统
pacote 子系统用于管理软件包的元数据,包括版本号、依赖关系、许可证信息等。pacote 系统的核心是一个用于获取 npm 包元数据和下载 npm 包的 pacote 包。pacote 包的主要作用是获取软件包的信息,例如包的名称、版本和依赖项,以及下载和提取软件包。
当 npm 需要下载或更新一个软件包时,它会首先调用 pacote 库来获取软件包的元数据。pacote 库通过与 npm registry 交互来获取软件包的元数据,包括软件包的名称、版本和依赖项。pacote 还负责解析软件包的依赖项,并在必要时递归下载这些依赖项。pacote 库在下载软件包时使用 HTTP 协议进行传输,支持压缩和断点续传功能。
在下载软件包之后,pacote会将其缓存到本地缓存目录 .npm/_cacache/content-v2 和 .npm/_cacache/index-v5 中。
- content-v2 目录用于存储已经下载的包的二进制文件。每个包会对应一个或多个文件,文件名由包的 SHA-1 值和包的版本号组成。例如,content-v2/sha1/24/2d/5c8…/package-1.0.0.tgz 表示一个包的二进制文件。
- index-v5:该目录用于存储已经下载的包的元数据信息。每个包会对应一个或多个 JSON 文件,文件名由包的 SHA-1 值和包的版本号组成。例如,index-v5/23/f8/87…/package-1.0.0.json 表示一个包的元数据文件。
等到 npm 在执行安装时,可以根据 package-lock.json 中存储的 integrity、version、name 生成一个唯一的 key 对应到 index-v5 目录下的缓存记录,从而找到 tar 包的 hash,然后根据 hash 再去找缓存的 tar 包直接使用。
我们以 lodash 包为例,其在 package-lock.json 中如下所示:
"lodash": {
"version": "4.17.11",
"resolved": "https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz",
"integrity": "sha512-cQKh8igo5QUhZ7lg38DYWAxMvjSAKG0A8wGSVimP07SIUEK2UO+arSRKbRZWtelMtN5V0Hkwh5ryOto/SshYIg=="
},
接下来我们在 index-v5 目录下搜索 lodash 的 resolved 属性:
grep "https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz" -r index-v5
搜索结果如下所示:
~/.npm/_cacache » grep "https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz" -r index-v5
index-v5/c5/aa/e95d015d781c87be2624a9ab47e8ec4c837d810d460caff18786393fe403:9879571c811af837057a968c7b4d7c38f532d58d {"key":"pacote:range-manifest:https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz:sha512-cQKh8igo5QUhZ7lg38DYWAxMvjSAKG0A8wGSVimP07SIUEK2UO+arSRKbRZWtelMtN5V0Hkwh5ryOto/SshYIg==","integrity":"sha512-C2EkHXwXvLsbrucJTRS3xFHv7Mf/y9klmKDxPTE8yevCoH5h8Ae69Y+/lP+ahpW91crnzgO78elOk2E6APJfIQ==","time":1540047087604,"size":1,"metadata":{"id":"lodash@4.17.11","manifest":{"name":"lodash","version":"4.17.11","dependencies":{},"optionalDependencies":{},"devDependencies":{},"bundleDependencies":false,"peerDependencies":{},"deprecated":false,"_resolved":"https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz","_integrity":"sha512-cQKh8igo5QUhZ7lg38DYWAxMvjSAKG0A8wGSVimP07SIUEK2UO+arSRKbRZWtelMtN5V0Hkwh5ryOto/SshYIg==","_shasum":"b39ea6229ef607ecd89e2c8df12536891cac9b8d","_shrinkwrap":null,"bin":null,"_id":"lodash@4.17.11"},"type":"finalized-manifest"}}
返回结果中前部分是对应 JSON 文件的目录
index-v5/c5/aa/e95d015d781c87be2624a9ab47e8ec4c837d810d460caff18786393fe403:9879571c811af837057a968c7b4d7c38f532d58d
我们对后部分 JSON 文件保存 lodash 的元数据信息格式化:
{
"key":"pacote:range-manifest:https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz:sha512-cQKh8igo5QUhZ7lg38DYWAxMvjSAKG0A8wGSVimP07SIUEK2UO+arSRKbRZWtelMtN5V0Hkwh5ryOto/SshYIg==",
"integrity":"sha512-C2EkHXwXvLsbrucJTRS3xFHv7Mf/y9klmKDxPTE8yevCoH5h8Ae69Y+/lP+ahpW91crnzgO78elOk2E6APJfIQ==",
"time":1540047087604,
"size":1,
"metadata":{
"id":"lodash@4.17.11",
"manifest":{
"name":"lodash",
"version":"4.17.11",
"dependencies":{
},
"optionalDependencies":{
},
"devDependencies":{
},
"bundleDependencies":false,
"peerDependencies":{
},
"deprecated":false,
"_resolved":"https://registry.npmjs.org/lodash/-/lodash-4.17.11.tgz",
"_integrity":"sha512-cQKh8igo5QUhZ7lg38DYWAxMvjSAKG0A8wGSVimP07SIUEK2UO+arSRKbRZWtelMtN5V0Hkwh5ryOto/SshYIg==",
"_shasum":"b39ea6229ef607ecd89e2c8df12536891cac9b8d",
"_shrinkwrap":null,
"bin":null,
"_id":"lodash@4.17.11"
},
"type":"finalized-manifest"
}
}
这里元数据中的 _shasum 保存的是 lodash tar 包的 hash,其中前四位是具体的目录信息:
~/.npm/_cacache » ls content-v2/sha1/b3/9e/
a6229ef607ecd89e2c8df12536891cac9b8d
~/.npm/_cacache » file content-v2/sha1/b3/9e/a6229ef607ecd89e2c8df12536891cac9b8d
content-v2/sha1/b3/9e/a6229ef607ecd89e2c8df12536891cac9b8d: gzip compressed data, from Unix, original size 2254336
至此我们就可以获得 lodash 的 tar 包。
make-fetch-happen 子系统
从 npm v5 开始,npm 的缓存子系统从 pacote 切换到了 make-fetch-happen。在此之前,npm 使用 pacote 缓存已安装软件包的元数据和版本信息,而使用 npm-registry-fetch 进行网络请求。而在 npm v5 中,npm 统一使用 make-fetch-happen 来处理网络请求和缓存,从而简化了 npm 的代码和架构。
make-fetch-happen 子系统的核心是 npm 的 HTTP 请求库 make-fetch-happen,make-fetch-happen 的主要作用是下载和管理 npm 软件包的二进制和其他文件。
当 npm 需要下载或更新软件包的二进制或其他文件时,它会使用 make-fetch-happen 库进行 HTTP 请求。make-fetch-happen 库会检查本地缓存目录中是否已经缓存了这些文件,如果已经缓存,则会直接从缓存目录中提取文件。否则,它会从远程服务器下载文件,并将其缓存到本地缓存目录中。
make-fetch-happen 库使用软件包的 URL 和哈希值作为缓存键。如果软件包的 URL 和哈希值都相同,则认为它们是相同的软件包,并且可以使用缓存的版本。
以下是 make-fetch-happen 子系统的详细解析:
1、HTTP请求处理
make-fetch-happen 使用 node-fetch 库进行 HTTP 请求处理,它支持 GET、POST、PUT、DELETE 等 HTTP 请求方法,并且可以设置请求头、请求体和查询参数等请求参数。make-fetch-happen 还支持 HTTPS 请求和自签名证书。
make-fetch-happen 还支持请求重试和超时机制。在网络请求失败时,它会自动进行重试,直到达到最大重试次数或请求成功为止。同时,它也支持设置请求超时时间,当请求超时时,会抛出超时异常。
2、缓存管理
make-fetch-happen 使用 npm 缓存目录来管理 npm 软件包的缓存。它根据软件包的 URL 和哈希值作为缓存键来管理缓存,如果软件包的 URL 和哈希值都相同,则认为它们是相同的软件包,并且可以使用缓存的版本。如果软件包的 URL 和哈希值不同,则认为它们是不同的软件包,需要重新下载和缓存。
make-fetch-happen 支持缓存的有效期设置和缓存清理机制。缓存的有效期可以根据软件包的类型和大小进行动态设置,可以设置为永久有效或在特定时间段内有效。缓存清理机制会自动清理过期的缓存和缓存空间不足的缓存。
3、代理支持
make-fetch-happen 支持 HTTP 代理和 HTTPS 代理。如果用户设置了 HTTP 代理或 HTTPS 代理,则make-fetch-happen 会使用代理进行请求处理。同时,make-fetch-happen 也支持使用环境变量设置代理,例如 http_proxy 和 https_proxy 环境变量。
总的来说,make-fetch-happen 子系统是 npm 缓存子系统的重要组成部分之一。它通过处理 HTTP 请求和管理缓存来实现 npm 软件包的下载和缓存管理。make-fetch-happen 具有请求重试、超时机制、缓存管理和代理支持等功能,可以提高 npm 的性能和可靠性,并且帮助 npm 成为现代 JavaScript 应用程序开发的核心工具之一。
总结
pacote 缓存子系统与 make-fetch-happen 缓存子系统的主要不同在于,pacote 缓存子系统是旧版 npm 使用的缓存机制,而 make-fetch-happen 缓存子系统是从 npm v5 开始使用的缓存机制。make-fetch-happen 缓存子系统更加高效,具有更好的并发性能,能够更快地下载和缓存软件包。同时,make-fetch-happen 缓存子系统还支持 HTTPS 和 HTTP/2 协议,能够更安全和更快速地下载和缓存软件包。
而且虽然 pacote 缓存子系统和 make-fetch-happen 缓存子系统都是 npm cache 的一部分,但它们的实现细节上确实有一些不同。
pacote 缓存子系统是 npm 5.0 之前的版本中使用的缓存实现。它使用文件系统来缓存 npm 包和其元数据,通过存储 tar 包和 package.json 文件来实现对包的缓存。在 pacote 缓存中,对于每个包,都有一个单独的目录,其中包含该包的所有版本的 tar 包和 package.json 文件。这种缓存方式可以减少下载时间,并允许使用本地的缓存来构建项目,但它无法处理依赖项解析时的多个源问题,因为它只能缓存来自一个源的包。
make-fetch-happen 缓存子系统是 npm 5.0 之后的版本中引入的缓存实现。它使用了更复杂的缓存算法,支持多个源,并且具有更高的灵活性和可配置性。make-fetch-happen 缓存系统使用 key-value 存储方式,其中 key 是根据请求 URL 和一些其他因素生成的哈希值,value 是响应内容。make-fetch-happen 缓存系统还可以设置各种选项,以控制缓存的大小、有效期和其他行为。
因此,make-fetch-happen 缓存子系统相对于 pacote 缓存子系统来说更为灵活和高效,也更适合处理依赖项解析时的多个源问题。
三、npm install
在介绍了缓存机制的基础上我们介绍一下 npm install 执行的完整流程:
- 检查依赖项:当用户执行 npm install 命令时,npm 会首先检查 package.json 文件中的依赖项,确定需要下载的包的名称和版本号。
- 解析依赖关系:npm 会根据依赖项,从 package.json 文件中解析出所有需要下载的包的名称、版本号和依赖关系,并生成依赖关系树(dependency tree)。
- 下载包:npm 会从 npm 仓库中下载需要的包,如果包已经存在于本地缓存中,则会直接从缓存中读取,避免重复下载。下载的包会被保存到本地的 .npm 目录中。
- 安装依赖:npm 会将下载的包解压缩,并将其安装到项目的 node_modules 目录中。在安装过程中,npm 会根据包的元数据文件 package.json 安装包的依赖项。如果有多个版本的包存在,npm 会根据语义化版本规则(Semver)选择合适的版本。
- 生成 shrinkwrap 文件:如果项目中存在 shrinkwrap 文件(npm-shrinkwrap.json 或 package-lock.json),npm 会根据安装的包信息生成新的 shrinkwrap 文件,以确保在后续安装过程中使用相同的版本。
- 执行预安装脚本:在包安装完成后,npm 会执行包中的预安装脚本(preinstall script),以完成一些必要的配置和初始化工作。
- 执行 postinstall 脚本:在预安装脚本执行完成后,npm 会执行包中的 postinstall 脚本,以完成一些额外的配置和初始化工作。
需要注意的是,npm install 还有一些常用的参数,可以用于控制安装行为。例如,使用 –save 参数可以将依赖包添加到 package.json 文件中的 dependencies 属性中,使用 –global 参数可以将包安装到全局环境中。
具体流程我们用下面的图更加直观的展示:

这儿需要注意如下几点:
- 检查配置: 读取 npm config 和 .npmrc 配置,比如配置镜像源,这里的优先级为:项目级的 .npmrc 文件 > 用户级的 .npmrc 文件> 全局级的 .npmrc 文件 > npm 内置的 .npmrc 文件
- 确定依赖版本,构建依赖树:在这一步会检查是否存在 package-lock.json,这是因为存在进行版本比对,处理方式和 npm 版本有关,根据最新 npm 版本处理规则,版本能兼容按照 package-lock 版本安装 , 反之按照 package.json 版本安装
- 检查缓存并下载:在这一步会首先判断是否存在缓存,存在将对应缓存解压到 node_modules 下,生成 package-lock.json,不存在则下载资源包,验证包完整性并添加至缓存,之后解压到 node_modules 下,生成 package-lock.json。
参考文章
原文链接:https://juejin.cn/post/7245201923506094140 作者:藤椒金汤力