
这篇结合自己的理解,将React文档中一些更细节的内容进行整理,便于快速回顾。
PS:这篇文章的组织方式是发散的,初学React的小伙伴还是建议直接读原文档哦。有React开发经验的小伙伴,如果针对某个点在业务上有更加深入的理解或实践,欢迎在评论区交流!
本篇文章如有描述错误之处,欢迎指正。
原文档
组件间通信
我还是会选择把组件间的通信写在最前面~
在我看来,组件间的通信,是开启任何一个现代前端框架的钥匙。无论是React还是Vue,构建应用的最小单元就是组件,组件通信的机制是组件间进行数据传递、交互、事件触发的关键机制。
React有一个非常出名的设计理念——单向数据流,即在组件与组件之间进行数据传递时,状态数据总是从父组件流向子组件,子组件不能够直接改变父组件的状态。
当一个组件需要改变它的 props(例如,响应用户交互或新数据)时,它不得不“请求”它的父组件传递 不同的 props —— 一个新对象!它的旧 props 将被丢弃,最终 JavaScript 引擎将回收它们占用的内存。
基于这样的理念,React在组件间的思路大概就是两种:
- 由顶级传递给子级;
- 集中管理,组件共同使用;
于是产生了下面具体的使用方式: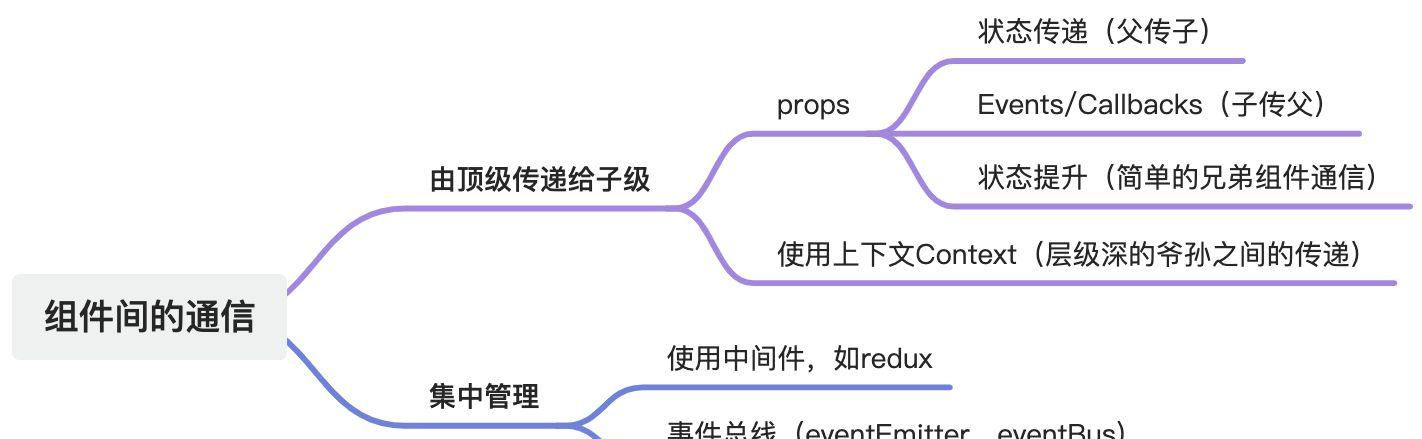

一个疑问:
当父组件想要使用子组件内部的某个状态时,我们怎么做?
可以通过props,向子组件传递一个函数,在函数被调用时,通过参数的方式拿到子组件内部的状态。
在这个参数是原始类型的情况下,在父组件中拿到的数据是子组件的“副本”,我们无法通过改变副本影响原始数据本身,这是符合单向数据流的。那么如果这个参数不小心是一个引用类型呢,这会发生什么意想不到的事吗?
不变性原则
什么是数据突变?
const p1 = { name: '张三' };
const p2 = p1;
p2.name = '李四';
console.log(p1.name); // '李四'
console.log(p2.name); // '李四'
在 JavaScript 中,对象属于引用数据类型,将一个对象赋值给两一个对象时,实际上是将对象的引用地址赋值给了另一个对象,此时两个变量同时指向了内存中的同一个对象,通过两个变量对对象进行的任何操作,都会影响另一方,这就是数据突变。
由于数据突变带来的不可预测,非常容易导致改 A 坏 B 的问题。
什么是数据的不变性?
不变性指对引用类型的数据进行更改,更改并不会作用于原数据,而是返回一个更改后的全新的数据。
const before = ['a', 'b', 'c', 'd'];
const after = before.slice(0, 2);
console.log(after); // ['a', 'b']
console.log(before); // ['a', 'b', 'c', 'd']
可以把数据突变 想象为“保存”, 它会在原有数据上进行修改。 可以把数据的不可变想象为“另存为”,它会返回全新的更改后的数据。由于数据的不可变,使数据操作更加安全,更加可预测。
JavaScript 中的数据不可变
在 JavaScript 中,既提供了数据突变方法,又提供了数据不可变方法。
sort、splice、push、pop 等就属于数据突变方法。
map、filter、reduce、slice 等就属于数据不可变方法。
JavaScript 中的扩展运算符也可以比较方便的实现数据的不可变。
- 添加
const before = ['a', 'b', 'c', 'd'];
const after = [...before, 'e'];
console.log(after); // ['a', 'b', 'c', 'd', 'e']
console.log(before); // ['a', 'b', 'c', 'd']
- 删除
const before = ['a', 'b', 'c', 'd'];
const after = [...before.slice(0, 2), ...before.slice(3)];
console.log(after); // ['a', 'b', 'd' ]
console.log(before); // ['a', 'b', 'c', 'd']
- 更新
const before = ['a', 'b', 'c', 'd'];
const after = [...before.slice(0, 1), 'x', 'y', ...before.slice(3)];
console.log(after); // ['a', 'x', 'y', 'd' ]
console.log(before); // ['a', 'b', 'c', 'd']
不完整的数据不可变
JavaScript 不具备完整的数据不可变性,因为它提供的那些具有数据不可变的方法都属于浅拷贝,对于引用数据类型嵌套的情况,内层数据仍然是引用地址的拷贝。
以上问题可以通过深拷贝解决,但是深拷贝是有性能问题的,其一是每次深拷贝都要把整个对象递归的复制一份,递归的过程是消耗性能的,其二是在内存中多出了很多重复的相同的数据,占用内存。
不变性的意义在哪里?
- 编写纯函数
- 易于数据的跟踪变化(不同的对象只需要进行浅比较就能看出变化,无需递归深比较)
- 方便进行时间旅行和撤销/重做
- 优化渲染的性能
使用不变性的场景:
不变性与React渲染的性能优化
在 React 中,当调用 setState 方法更新数据时,即使传入的数据和以前一样,React 也会执行 diff 的过程,因为 JavaScript 中对象与对象的比较采用的是引用地址,所以即使两个对象长得一样,其实也是不相等的,所以会走 diff 的过程。为了解决这个问题,React 提供了 Pure Component ,但是 Pure Component 采用的是浅层比较,当数据结构比较复杂时,依然会存在无效的 diff 操作。
在函数组件中,可以通过React.memo来包裹组件,可以实现类似 Pure Component 的效果。
import React, { PureComponent } from 'react';
class Greeting extends PureComponent {
render() {
return <h1>Hello, {this.props.name}!</h1>;
}
}
import React, { memo } from 'react';
const Greeting = memo(({ name }) => {
return <h1>Hello, {name}!</h1>;
});
如何实现嵌套引用的不可变性?
- 手动创建新的引用
- 想要减少重复的拷贝代码,可以借助三方库 immer.js 或 Immutable.js
比如immer的Proxy对象可以帮助你直接修改对象,实际上并不会覆盖之前的state
updatePerson(draft => {
draft.artwork.city = 'Lagos';
});
对象并非真正嵌套
对象看起来是嵌套的,实际上不过是对象内的属性指向了另一个对象,它们是相互独立的,不同的对象属性是可以指向同一个对象的。
不要嵌套组件定义
- 在组件内定义组件,内部组件会在外部组件每次渲染的时候进行重新创建,带来性能损耗
- 耦合高,且内部定义的组件也没办法导出供其他组件使用,不利于复用和代码维护
JSX的本质
在写JSX的时候,你是否会有以下一些疑问?
- 为什么 JSX 一定要用一个父元素包裹?
- 为什么 class 需要写成 className ?
- 为什么属性名的链接符 – 需要替换成驼峰写法?
- 而为什么 data-* 和 aria-* 又可以用 – 符号?
- 为什么内联 style 属性需要使用驼峰命名法编写?
- <></>无法接受key值,可以用代替,那是什么呢?
滥用简洁展开语法传递Props
function Profile(props) {
return (
<div className="card">
<Avatar {...props} />
</div>
);
}
你可以使用这样的语法方便进行props的转发,但不要过度使用它!
React为什么需要key? (常青题)
最直观的原因,没有写key的时候eslint报错。
稍微深入一点,没有key可以帮助React更好地识别列表中的列表项,对性能更好。
key 还可以帮助你标识组件的身份,便于状态的保留和重置。
以上都是比较笼统的回答,我们可以展开说说。
首先作为key的值需要满足两个条件:
- key值在兄弟节点之间必须要是唯一的
- key值不能改变
为什么对key有这样的要求?那是因为key有它特殊的作用。
当兄弟元素有改变时,React会进行重渲染,简化重渲染的过程:
首先,React将改变前和改变后的两份虚拟Dom进行对比。
然后,React会识别已经存在的元素,以便重新利用它们,而不是从头开始创建。如果key属性不存在,React会默认将列表项的索引作为key。
第三步,React会:
- 删除在重渲染「之前」存在但「之后」不存在的项目——即卸载(unmount)它们。
- 从头开始创建在「之前」阶段不存在的项目——即加载(mount)它们。
- 更新 「之前」存在并在 「之后」继续存在的项目——即重新渲染(rerender)它们 。
这个过程称为【协调】,key 也是在这个过程起到作用。
key 可以帮助 React 更好地识别兄弟元素中哪些元素被移动、增加或删除,从而为 React 节省一些不必要的 DOM 操作;当某一项的 key 发生改变时,会被认为是不同的组件,从而强制触发 remount ,这个规则在需要重新渲染特定组件或其子组件时非常有用。
当 key 不变时,React 会尽可能地复用 DOM,但仍然会进行一些检查和比较,以确保组件的状态和属性是否发生了变化,即使 key不变,如果组件的 props 或 state 发生了变化,React 仍然会进行 rerender 。
当key是随机的,每次重新渲染列表时,React都会给每一个同类元素重新生成key的值,由于所有的 key属性都是新的,所有 “之前” 的项都将被视为 “已移除”,每个项都将被视为 “新的”,所以 React 将 unmount 所有列表项并将它们重新 mount 回去。
当兄弟元素的 key 不唯一时,具有相同 key 的元素会被认为是同一元素,会引起渲染的错误以及状态属性更新的错误。
用索引作为key,不是所有场景下,都是不好的,比如:列表翻页的情况
在列表翻页情况下,如果用唯一标识作为key,那么每一页的每一项都是不同的key,每项都会触发remount,但是如果用索引作为key,每一页的同一索引项,会被视为同一项,DOM会被复用,只是触发rerender。在不得不发生每一项重新渲染的情况下,比起大量的重新挂载,rerender就显得性能更优一些啦。
官方建议的纯函数组件
纯函数组件,意味着这个组件函数是一个没有副作用的函数,即它的输出只依赖于它的输入,而不受外部状态或变量的影响。
理想状态下,官方建议React 组件的渲染函数必须是纯函数,这一原则是 React 开发者必须遵守的重要规则。
但实际上,业务需求的开发必须依赖副作用。但我们可以通过解耦的各种手段进行代码分层,从而尽可能实现纯函数的目标。
冒泡和捕获
阻止事件进一步冒泡可以使用 e.stopPropagation()
但如果父组件想要捕获子元素的所有事件,即便它们阻止了传播,可以在事件末尾添加 Capture 来实现。比如 onClickCapture
React渲染
React的渲染发生在两个时机:
- 应用启动时的初次渲染。会调用根组件;
- 组件(或是祖先之一)的状态发生了变化。会调用内部状态更新触发了渲染的函数组件。如果是嵌套组件,那会一层层递归调用它返回的组件,直至最后没有更多的嵌套。React 仅在渲染之间存在差异时才会更改 DOM 节点。
渲染的步骤:
Hook
如何理解“如果你想在一个条件或循环中使用 useState,请提取一个新的组件并在组件内部使用它。”这句话?根据React官方文档,我们是清楚的:Hook比普通函数更加严格,我们只能在组件(或其他Hook)的顶层调用Hook。那么如果有些业务需求,逼着你就是要使用条件或循环才能实现呢?这种情况下,我们有一个选择——抽出一个组件,把这部分hook的逻辑,包装在这个组件中,通过条件或循环去渲染这个组件。
function ConditionalComponent({ condition }) {
useEffect(() => {
// 在条件满足时执行的逻辑
}, []);
return condition ? <div>条件满足的内容</div> : null;
}
异步的state更新
state快照
state快照可以很好地解释为什么在setState的时候,总是“异步的”。
每当设置一次state就会触发一次新的渲染,但是一个 state 变量的值永远不会在一次渲染的内部发生变化, 即使其事件处理函数的代码是异步的。
import { useState } from 'react';
export default function Counter() {
const [number, setNumber] = useState(0);
return (
<>
<h1>{number}</h1>
<button onClick={() => {
setNumber(number + 1);
setNumber(number + 1);
setNumber(number + 1);
}}>+3</button>
</>
)
}
//第一次点击按钮时,可以把以上代码视作
<button onClick={() => {
setNumber(0 + 1);
setNumber(0 + 1);
setNumber(0 + 1);
}}>+3</button>
当React渲染时,React会调用组件,它会为特定的那一次渲染提供一张 state 快照。
你的组件会在其 JSX 中返回一张包含一整套新的 props 和事件处理函数的 UI 快照 ,其中所有的值都是 根据那一次渲染中 state 的值 被计算出来的!相应地,在事件处理函数中,所使用到的state也是创建它们时候的那次渲染所有用的state值。
state批处理
在state快照的前提下,React还会对state的更新进行批处理,它会等到事件处理函数中的所有代码都运行完成,再进行state的更新。这样可以减少一些不必要的重新渲染。
但是React是不会跨多个需要可以触发的事件的,所以每次交互的事件都会正确更新成你预判中的状态。
如何避免state快照和批处理?
当在某些场景,你需要在一个事件中,多次更新同一个state,可以使用更新函数:
import { useState } from 'react';
export default function Counter() {
const [number, setNumber] = useState(0);
return (
<>
<h1>{number}</h1>
<button onClick={() => {
setNumber(n => n + 1);
setNumber(n => n + 1);
setNumber(n => n + 1);
}}>+3</button>
</>
)
}
更新函数会被放在队列中,待事件处理函数中的其他代码都执行完成后,队列中的更新函数会被一一遍历执行,最终得到最后的结果 3 。
一个很好的例子:
import { useState } from 'react';
export default function Counter() {
const [number, setNumber] = useState(0);
return (
<>
<h1>{number}</h1>
<button onClick={() => {
setNumber(number + 5);
setNumber(n => n + 1);
setNumber(42);
}}>增加数字</button>
</>
)
}
以下是 React 在执行事件处理函数时处理这几行代码的过程:
- setNumber(number + 5):number 为 0,所以 setNumber(0 + 5)。React 将 “替换为 5” 添加到其队列中。
- setNumber(n => n + 1):n => n + 1 是一个更新函数。React 将该函数添加到其队列中。
- setNumber(42):React 将 “替换为 42” 添加到其队列中。
- 然后 React 会保存 42 为最终结果并从 useState 中返回。
构建state的原则
“让你的状态尽可能简单,但不要过于简单。”
- 合并掉那些总是同时更新的多个state变量。
- 不要在state中镜像props,直接从props中解构获取就可以,除非你就是需要只获取初始值,忽略掉之后父组件的更新。
- 移除掉多余的,或是具有重复信息的state,变量越多,发生的情况就越多,出现意外中的UI的概率就越大,尽可能用少量的state,就可以描述各种状态场景,这样你所需要关注的state也就可以减少一些。
- 避免将可以通过现有state或props计算就能得出的值作为state。
- 尽量扁平化构建state,如果避免不了使用嵌套结构,请使用immer等库保证state的不变性。
使用reducer管理状态
受控组件和非受控组件
受控组件:组件中的重要信息由props驱动。
非受控组件:组件的重要信息由自身状态驱动。
非受控组件通常很简单,因为它们不需要太多配置。但是当你想把它们组合在一起使用时,就不那么灵活了。受控组件具有最大的灵活性,但它们需要父组件使用 props 对其进行配置。
当编写一个组件时,你应该考虑哪些信息应该受控制(通过 props),哪些信息不应该受控制(通过 state)。当然,你可以随时改变主意并重构代码。
state的保留和重置
一般来说,如果你想在重新渲染时保留 state,几次渲染中的树形结构就应该相互“匹配”。结构不同就会导致 state 的销毁,因为 React 会在将一个组件从树中移除时销毁它的 state。
保留
对于相同位置的相同组件,状态会被保留下来
对 React 来说重要的是组件在 UI 树中的位置,而不是在 JSX 中的位置!
import { useState } from 'react';
export default function App() {
const [isFancy, setIsFancy] = useState(false);
return (
<div>
<Counter isFancy={true} />
{isFancy ? (
<Counter isFancy={true} />
) : (
<Counter isFancy={false} />
)}
<label>
<input
type="checkbox"
checked={isFancy}
onChange={e => {
setIsFancy(e.target.checked)
}}
/>
使用好看的样式
</label>
</div>
);
}
function Counter({ isFancy }) {
const [score, setScore] = useState(0);
const [hover, setHover] = useState(false);
let className = 'counter';
if (hover) {
className += ' hover';
}
if (isFancy) {
className += ' fancy';
}
return (
<div
className={className}
onPointerEnter={() => setHover(true)}
onPointerLeave={() => setHover(false)}
>
<h1>{score}</h1>
<button onClick={() => setScore(score + 1)}>
加一
</button>
</div>
);
}
不同位置的相同组件,想要状态保留,可以:
重置
相同位置的不同组件,会引起状态的重置
如果想要使在相同位置的相同组件实现state的重置的话,可以:
状态管理
使用reducer整合状态
当设置状态的逻辑和处理事件的逻辑很复杂时,为了帮助代码更好理解,可以将状态处理的代码整合到reducer中,达到分离关注点的目的。这样的话,事件处理函数就只需要dispatch和专注进行事件处理,而无需关注状态具体是如何更新的。
import { useReducer } from 'react';
import AddTask from './AddTask.js';
import TaskList from './TaskList.js';
export default function TaskApp() {
const [tasks, dispatch] = useReducer(tasksReducer, initialTasks);
function handleAddTask(text) {
dispatch({
type: 'added',
id: nextId++,
text: text,
});
}
function handleChangeTask(task) {
dispatch({
type: 'changed',
task: task,
});
}
function handleDeleteTask(taskId) {
dispatch({
type: 'deleted',
id: taskId,
});
}
return (
<>
<h1>布拉格的行程安排</h1>
<AddTask onAddTask={handleAddTask} />
<TaskList
tasks={tasks}
onChangeTask={handleChangeTask}
onDeleteTask={handleDeleteTask}
/>
</>
);
}
function tasksReducer(tasks, action) {
switch (action.type) {
case 'added': {
return [
...tasks,
{
id: action.id,
text: action.text,
done: false,
},
];
}
case 'changed': {
return tasks.map((t) => {
if (t.id === action.task.id) {
return action.task;
} else {
return t;
}
});
}
case 'deleted': {
return tasks.filter((t) => t.id !== action.id);
}
default: {
throw Error('未知 action: ' + action.type);
}
}
}
let nextId = 3;
const initialTasks = [
{id: 0, text: '参观卡夫卡博物馆', done: true},
{id: 1, text: '看木偶戏', done: false},
{id: 2, text: '打卡列侬墙', done: false}
];
把 useState 转化为 useReducer:
- 通过事件处理函数 dispatch actions;
- 编写一个 reducer 函数,它接受传入的 state 和一个 action,并返回一个新的 state;当state为引用类型时,使用immer库帮助维护参数的不可变性
- 使用 useReducer 替换 useState;
useReducer的特点:
编写一个好的reducers:
- 必须保证是纯函数,不能有任何的副作用,内部不可以进行异步请求、定时器等
- 必须保证state参数的不可变性
- 每个action都描述了一个单一的用户交互,即使会引发数据的多个变化
Context传递state
使用context三个关键的api
context的使用弊端
- 当多个组件同时修改context的状态时吗,会使得状态变得难以追踪
更佳于context的替代方案:
值得使用context的场景
- 主题: 如果你的应用允许用户更改其外观(例如暗夜模式),你可以在应用顶层放一个 context provider,并在需要调整其外观的组件中使用该 context。
- 当前账户: 许多组件可能需要知道当前登录的用户信息。将它放到 context 中可以方便地在树中的任何位置读取它。某些应用还允许你同时操作多个账户(例如,以不同用户的身份发表评论)。在这些情况下,将 UI 的一部分包裹到具有不同账户数据的 provider 中会很方便。
- 路由: 大多数路由解决方案在其内部使用 context 来保存当前路由。这就是每个链接“知道”它是否处于活动状态的方式。如果你创建自己的路由库,你可能也会这么做。
- 状态管理: 随着你的应用的增长,最终在靠近应用顶部的位置可能会有很多 state。许多遥远的下层组件可能想要修改它们。通常 将 reducer 与 context 搭配使用来管理复杂的状态并将其传递给深层的组件来避免过多的麻烦。
reducer和Context结合使用
步骤
- 创建 context。
- 将 state 和 dispatch 放入 context。
- 在组件树的任何地方 使用 context。
原文链接:https://juejin.cn/post/7265946243195928616 作者:Viva49641