
公众号|沐洒(ID:musama2018) 关注我,带你学点有用的
大家好,我是沐洒,一个 坚持原创,坚持深度思考 的互联网资深从业者。
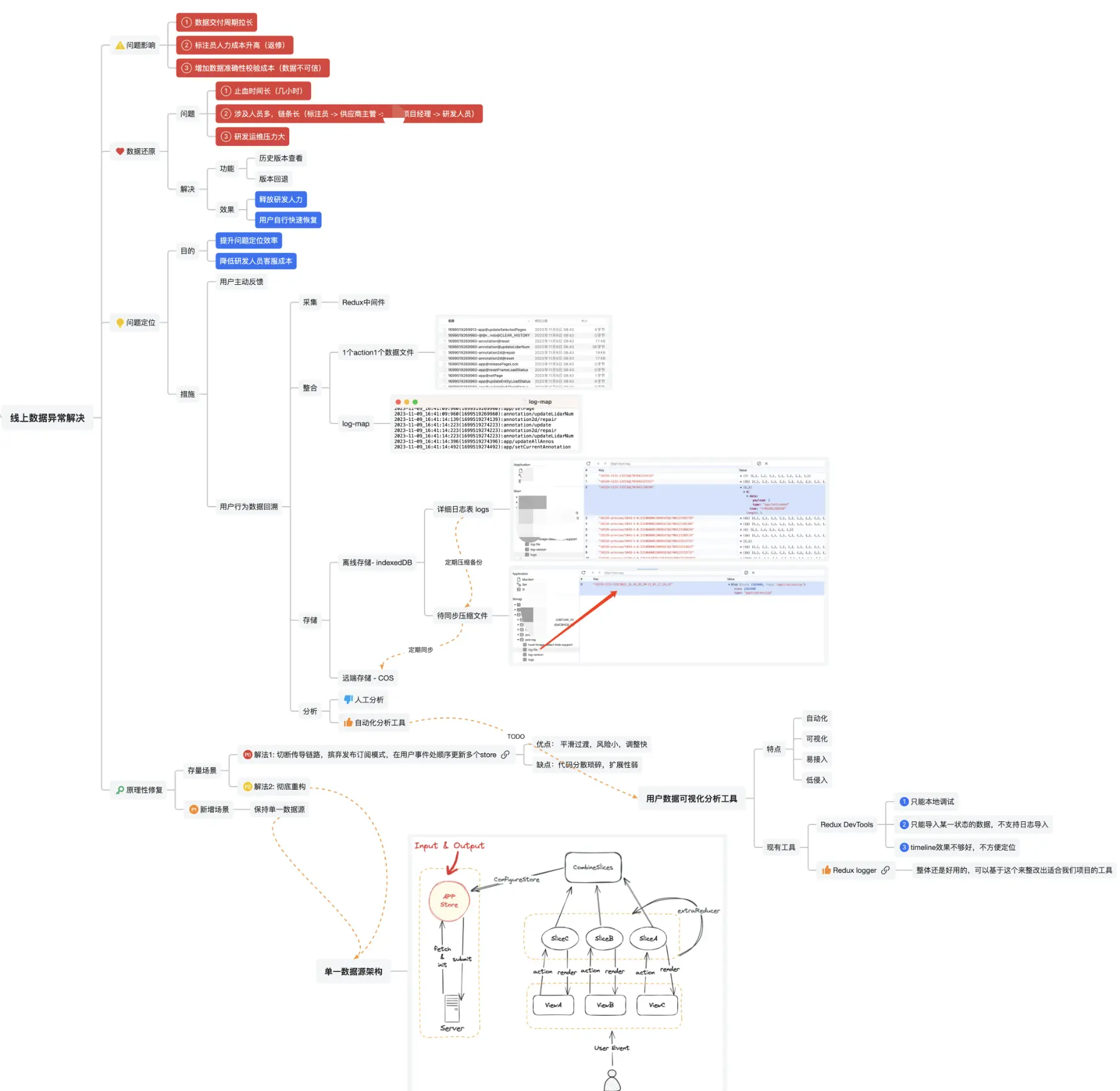
开发人员最怕的出现线上事故,尤其是明晃晃的损失清单摆在你面前时,你很难不慌。在自动驾驶3D点云标注项目里,我们就遇到了一个棘手的成本危机,来看看我们应对危机的完整处置流程吧。
『缘起』:鸡飞狗跳的线上救火
背景:低调开场
自动驾驶3D标注项目是2022年底启动的,研发一共就俩人,我和carven从传统Web前端开发切入到这个全新的3D开发领域,一时显得手足无措,所有的名词术语一概听不懂看不懂,几乎从头开始学习相关专业知识。
就在这样一个背景下,我们跌跌撞撞的花了三个月时间,把一个具备MVP路径的Demo搬上了线。紧接着又花了小半年时间持续打磨功能细节,在产品能力支持上逐渐具备了商业竞标的资格。
于是在今年H1,我们中标了一个外部订单。
这显然是一个喜事,但同时也是我们这段鸡飞狗跳的线上救火日子的开始。
危机:数据异常
经过了小半年的迭代打磨,又经过两个月的内测,今年6月底,项目正式投产,标注员正式开始在我们平台进行3D点云融合标注作业。
不出意外的话,就要出意外了。
正式生产开始后,用户群里陆续有人反馈 「飘框」,「丢框」 等数据异常现象。
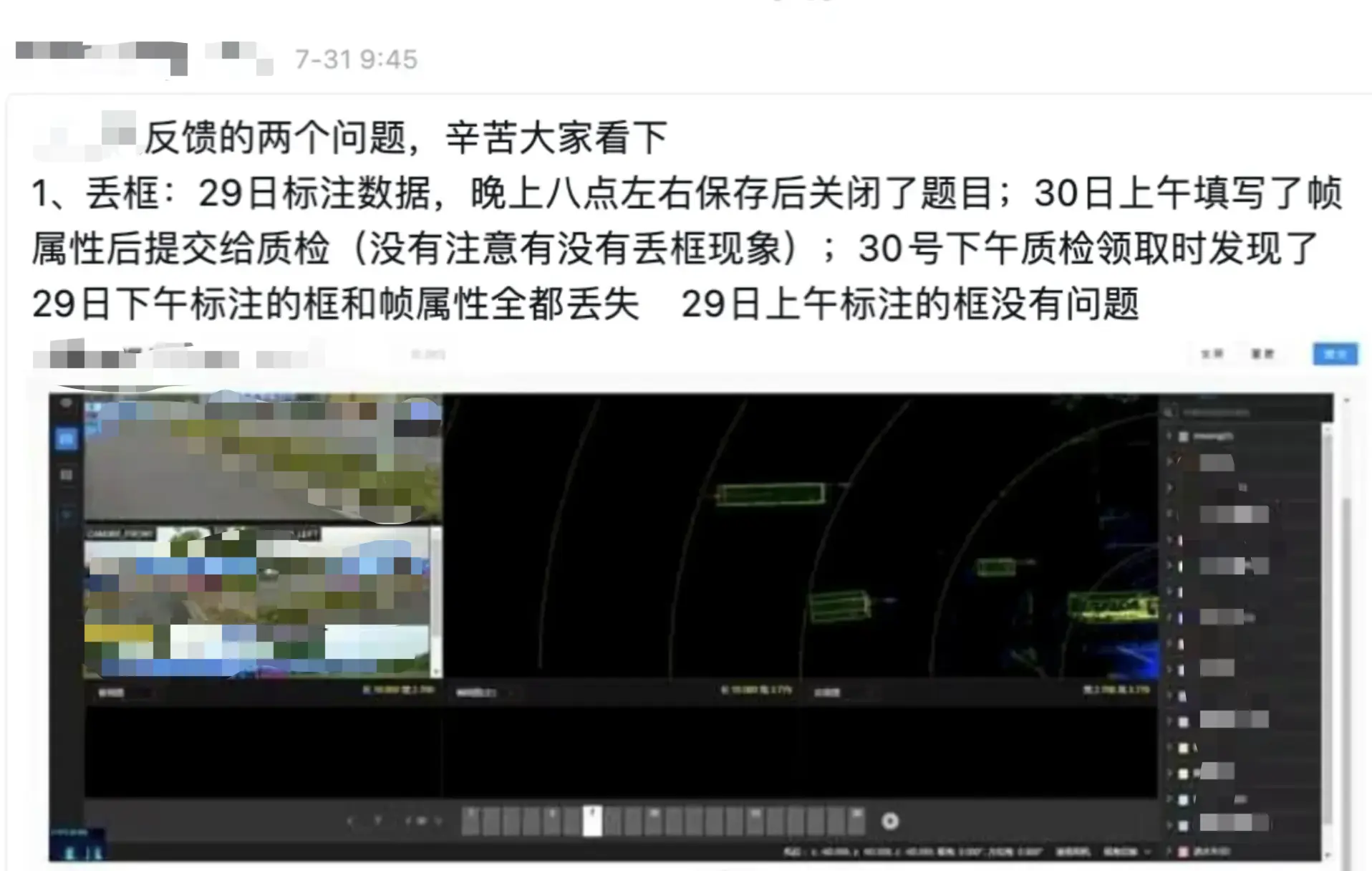

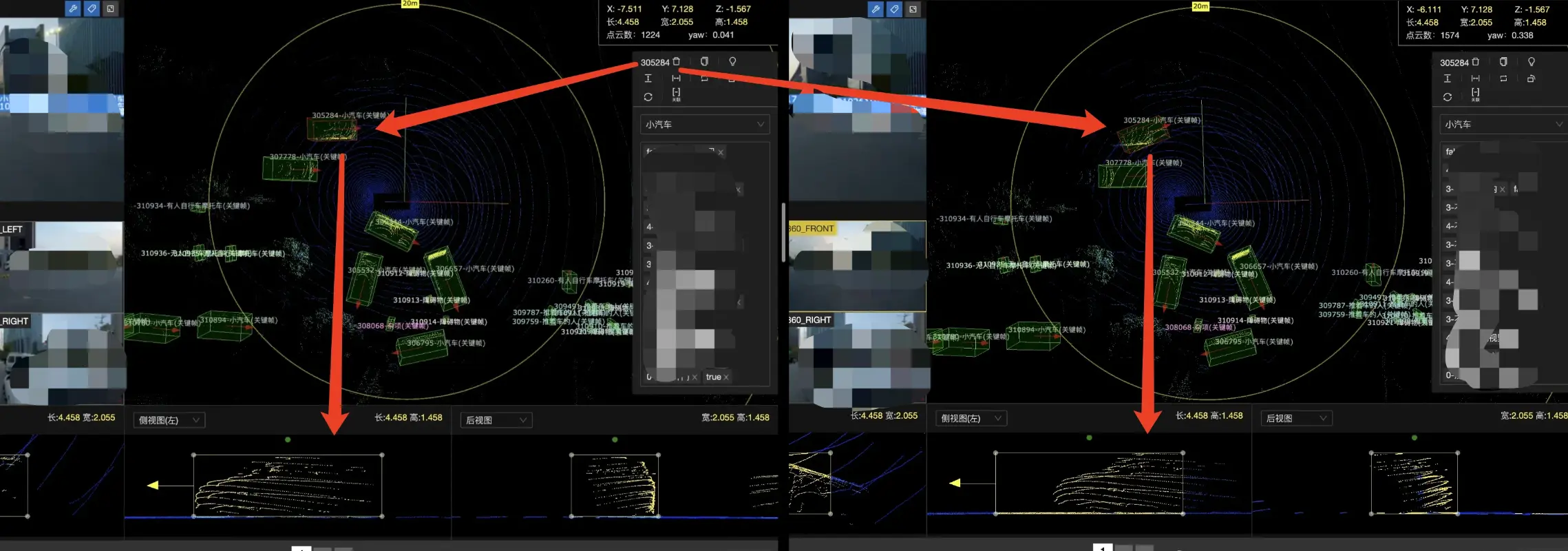
这里简单科普下什么叫做 “飘框”,如下图所示:
正常情况下,标注员提交后,质检员看到的框体应该是左边的样子,但却总是偶发性的出现右边的 “飘框” 现象。
在日常Web开发中,常见的异常无非这么两种:
- 通信错误(请求超时,连接异常,业务错误等)
- Javascript错误(比如常见的xxx of undefined,JSON.parse错误等)
上面两种错误因为较为常见,配套的Debug工具非常成熟,可以通过错误堆栈来轻松定位到异常代码。
很不幸的是,经过HTTP日志和JS日志分析后,我们便迅速排除了上面两种错误的可能性。
这就麻烦了呀。
在前端开发领域,为了应付日渐复杂的SPA状态管理难题,各种状态管理库百花齐放,而我们项目采用的是最为主流的Redux,配合最主流的UI框架React。
这俩神器非常成熟和强大,但都有一个共性问题,就是有一定使用门槛,哪怕是熟练工都很容易因为写法不当而翻车,比如React的useEffect的依赖项使用不当就常常造成死循环。
通常来讲,一些简单的问题通过直接在代码里打log就能看出端倪来,稍微复杂的情况,也可以借助DevTools来Debug,比如针对Redux开发的Redux Devtool就是常用的状态调试插件。
然而这是本地开发调试啊,那线上数据异常怎么办呢?
这里明显出现了两个挑战:
- 数据异常出现在线上,调试工具无法触及。
- 这类异常非常随机且偶发,难以捕捉到(我们甚至一度用腾讯会议蹲守着用户共享屏幕操作…)。
当然了,稍微有点工程经验的开发同学在面对这两个问题的时候都会想到一个惯用解法:打用户行为日志。
我自然也不例外,第一时间就采用了这个策略,既然是数据异常,那么就在数据变动的链路上做拦截,把数据变动的情况给记录下来就可以了。
于是就有了第一版初步方案:
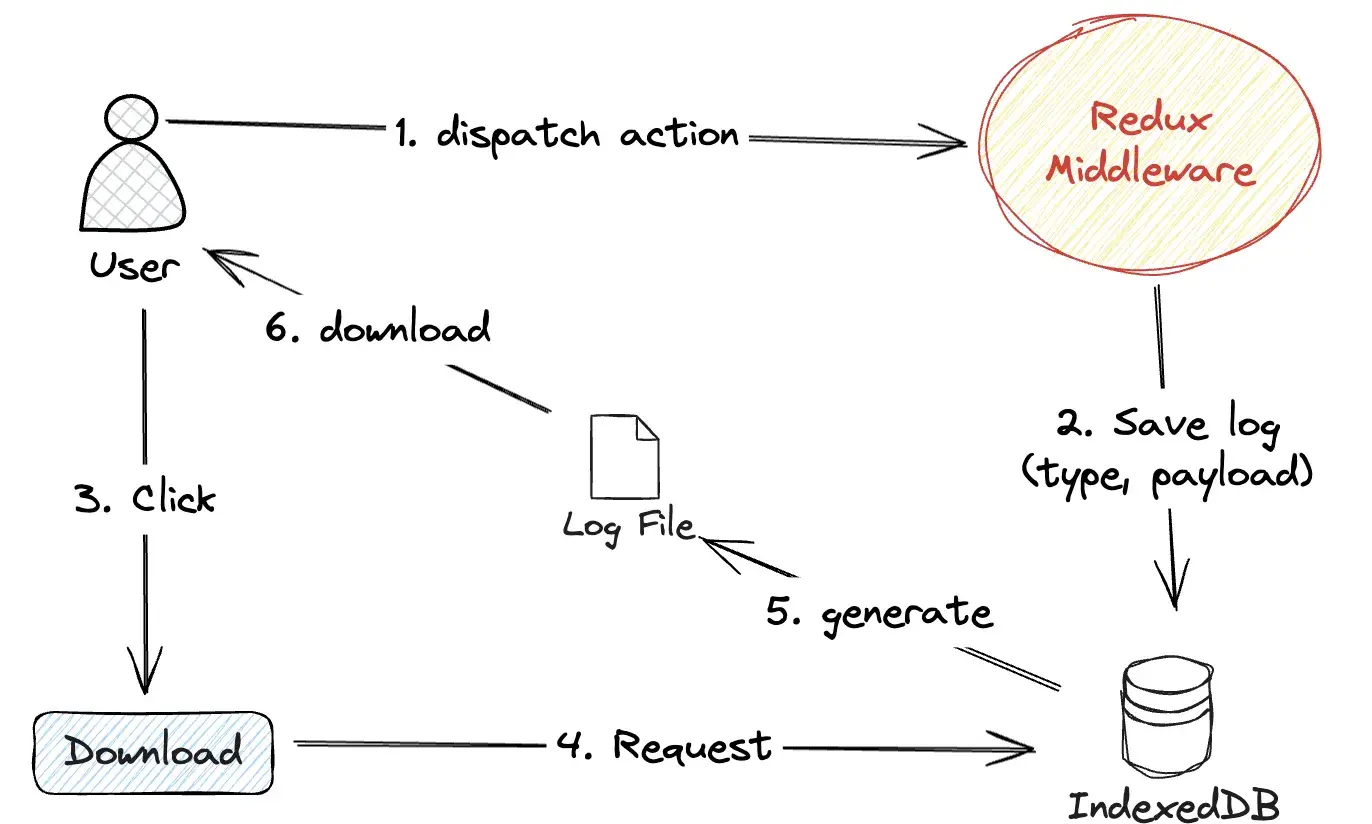
我显然知道这个方案非常之简陋,但谁说罗马是一日就建成的呢?况且,我这还等着救火呢!先把工具发上去,拿到用户数据再说。
止血:数据修复
救火么,显然是需要先止血的,因为我们是B端产品,标注员可是在系统上全天坐班8小时进行数据标注的,数据晚一分钟修复,他们就得守着电脑等一分钟,这空转的人力成本,最终是需要我们团队来为降低的人效买单的。
下图是某任务周期内数据异常造成的工时浪费统计:

说实话,这种成本浪费图,谁看了都得脊背发凉,胆战心惊。
所以通常情况下是等不了研发人员慢慢扒拉日志数据去定位问题的,必须先把数据修复,以便生产流水线持续运转下去。
而说到数据修复,得再提一嘴背景,这个3D点云标注系统,是没有后端服务的,而且在相当长的时间里,只有两个前端开发在迭代。
在人力吃紧的条件下,我们在一开始做系统架构的时候,就做了取舍:抓大(交付)放小(工程)。
抓交付,其实就是只要保证能把3D点云数据给正确标注完毕,交付给客户就成。那么这里的核心任务就是3D点云标注工具能力的建设。至于你用传统的Client-Server架构还是Serverless架构还是什么,并不重要,至少不是P0的重要紧急程度。
放工程,就是先别管怎么系统化,工程化,这些东西很重要,但并不紧急。毕竟如果连竞标资格都没有的话,项目存在的意义就产生了动摇,又哪来的机会去提升系统健壮性,稳定性呢?
于是我们放弃了传统的Client-Server架构,将仅有的两个前端人力,全部投入到3D标注工具能力的建设上,比如2D/3D融合标注,静态叠帧标注,线性插值,自动边缘检测,大规模点云渲染性能优化等。这些清一色全是Client能力,不涉及Server。
但是没有Server层,数据怎么落地,做持久化呢?
我们提供了一种Serverless解法:离线缓存(indexedDB)+ 定期备份(COS),如图:
COS:Cloud Object Storage,腾讯云对象存储服务,类似于Amason的S3。
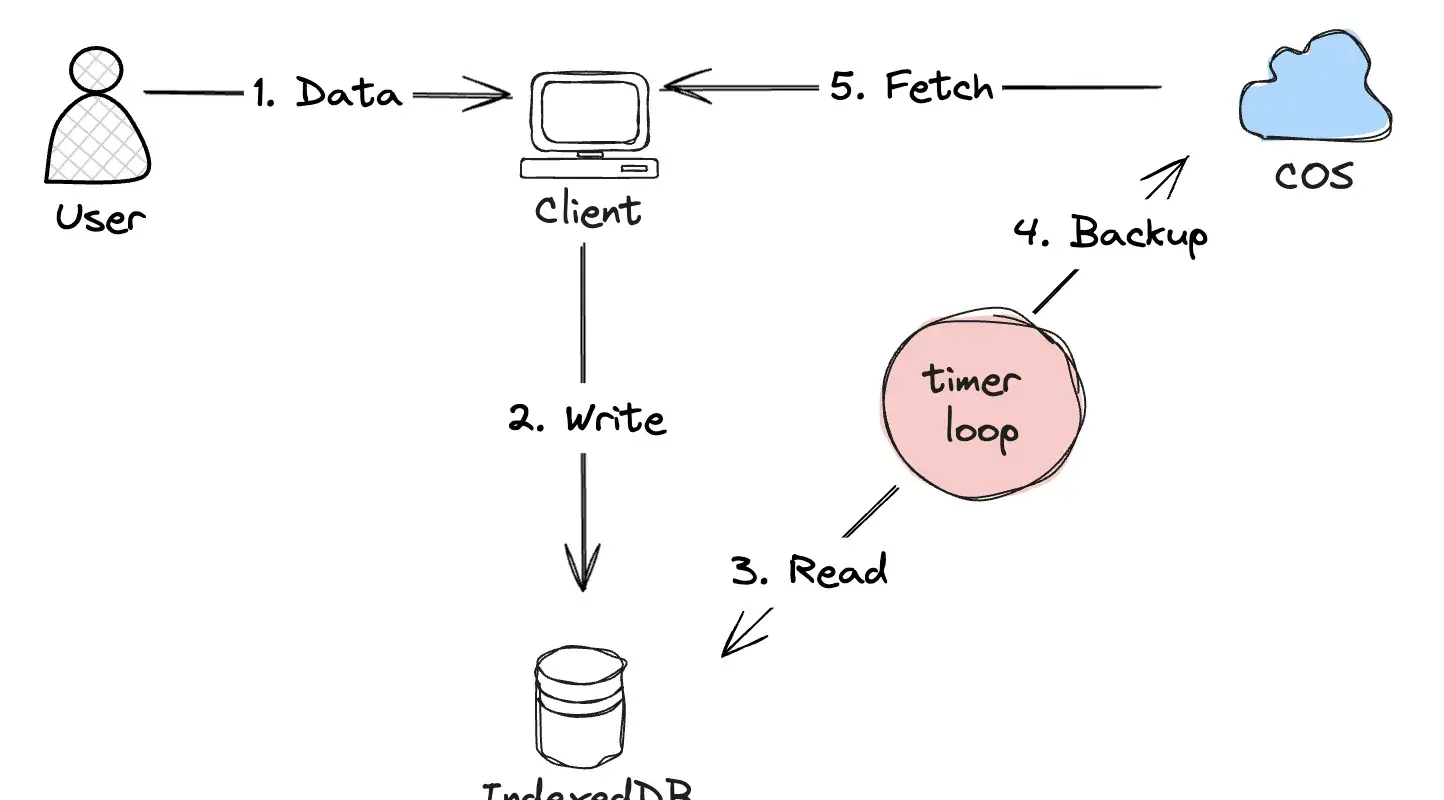
这种架构的好处显而易见,就是流程简单,开发速度快,也刚好符合我们当时的核心诉求(保交付)。
然而缺点也多如牛毛,别的先不提,就拿数据修复这个场景来讲,因为用户标注的数据采用的是对象存储 + 定期备份的方式,数据的回滚颗粒度往往很大(文件级别),而且因为是非结构化存储,在决定要还原到哪一份数据的时候,往往非常困难,因为从COS上的Object列表里肉眼看,根本看不出每个Object里存储的结构化数据有什么异常和差异,因此需要大量的人工筛查工作。
而因为是B端项目,在研发人员和标注员之间,通常还隔着几道职能人员,链路很长:
标注员 -> 供应商主管 -> 项目经理 -> 产品经理 / 研发主管 -> 研发人员
这种信息传递链路的复杂度给问题定位和数据修复工作带来了很大的困扰,因为所有人都不清楚哪一份数据才是正确的,研发人员需要经过层层传递,才能把很多信息逐一问到手,用 “4W1H” 做个概括就是:
- Who:谁的数据出现异常?(任务及人员的相关信息,taskId,userId等等)
- What:发生了什么样的异常?(多帧异常?单帧异常?单框异常?丢框还是飘框?等等)
- When:什么时候发现异常的?(1标N审的哪个环节发现的?具体什么时间?等等)
- How:你想怎么修复数据?(数据版本回滚?打回修正?打回到哪环节?完全重做?等等)
经过长时间的反复交流问询(通常情况下短则几小时,长则一两天),研发人员才终于拿到了充足的信息,进行数据修复,完成止血工作。
光听我这么讲你都能感受到这里面存在多少可优化的点吧!
那么接下来看看我们在痛过之后又做了些什么。
『渡己』:痛定思痛的武器升级
代价:肉眼可见飙升的成本
To be honest,一个问题即使错的再离谱,如果对业务或用户不造成任何实质性影响,那也不值得投入人力去修复,我们只会加一行注释:It's a featute,not a bug 。
而我们遇到的数据异常问题不仅不是毫无影响,甚至可以说影响极其恶劣,可以归纳概括为四个方面:
- 【交付】标注人力空转导致的:交付周期拉长
- 【生产】数据返修导致的:人力成本升高
- 【生产】数据失信后增加验收轮次导致的: 生产工艺成本增加
- 【研发】问题定位和数据修复困难导致的:运维成本增加,研发人员压力增大
相关数据前文已经贴过图了,两个星期的时间内造成的标注员工时浪费高达200多小时, 不仅对商业交付周期产生了实质性影响,也直接拉升了我们的生产成本,把商业竞标里至关重要的 人效值拉低了很多。
另一方面,我们作为研发人员,完全没办法持续专注的投入到新能力的建设中去,总是被频繁的用户反馈打断,被迫从功能迭代中抽出精力来做问题定位和数据修复。常常一弄就是大半天,非常耽误事。
最关键的是,研发人员的运维压力是真的大,每天最怕的就是看到有人在群里反馈说数据又丢了,这可比有人反馈说页面白屏了要压力大很多很多。
基于此,这一系列问题的解决显得迫在眉睫。
进化:持续迭代工具能力
“工欲善其事,必先利其器”。前文也讲过,刀耕火种并不是我们的无奈之举,而是我们彼时几乎唯一的选择,具有历史必然性。
在保交付和保工程之间,我们曾经义无反顾的选择了前者,但这不代表我们需要一直容忍这些简陋的基建。当工程问题已经成为我们实现目标(保交付)路上的绊脚石的时候,很显然就是时候去改造升级它了。
We need it,so we did.
问题定位
终于讲到本次分享的核心部分了。
之前讲到,为了快速响应,尽可能早的保留住用户现场,我先发布了一个简陋的离线日志下载功能。
有一说一,这个功能虽然简陋,但的确帮助我解决了 “缺少用户日志数据” 的燃眉之急,首先完成了 “有没有” 的使命,让我得以喘口气再来解决 “好不好” 的问题。
然而我们还是得实事求是的说,这仅仅是个临时方案,这里面存在很多问题,比如日志的存储和获取方式,采用 离线存储 + 用户下载 的方式有一个直观的缺点:随着日志越来越多,日志文件越来越大,一方面对用户的硬盘空间造成了挤占,另一方面在需要用户提供日志时,常常需要下载几百MB的文件,然后再层层转发给到研发手中。
这显然是不可接受的糟糕体验。
除此之外,在日志采集阶段,临时方案里直接把Redux中间件里拿到的每一条Action原始数据(type和payload)平铺存储起来了。
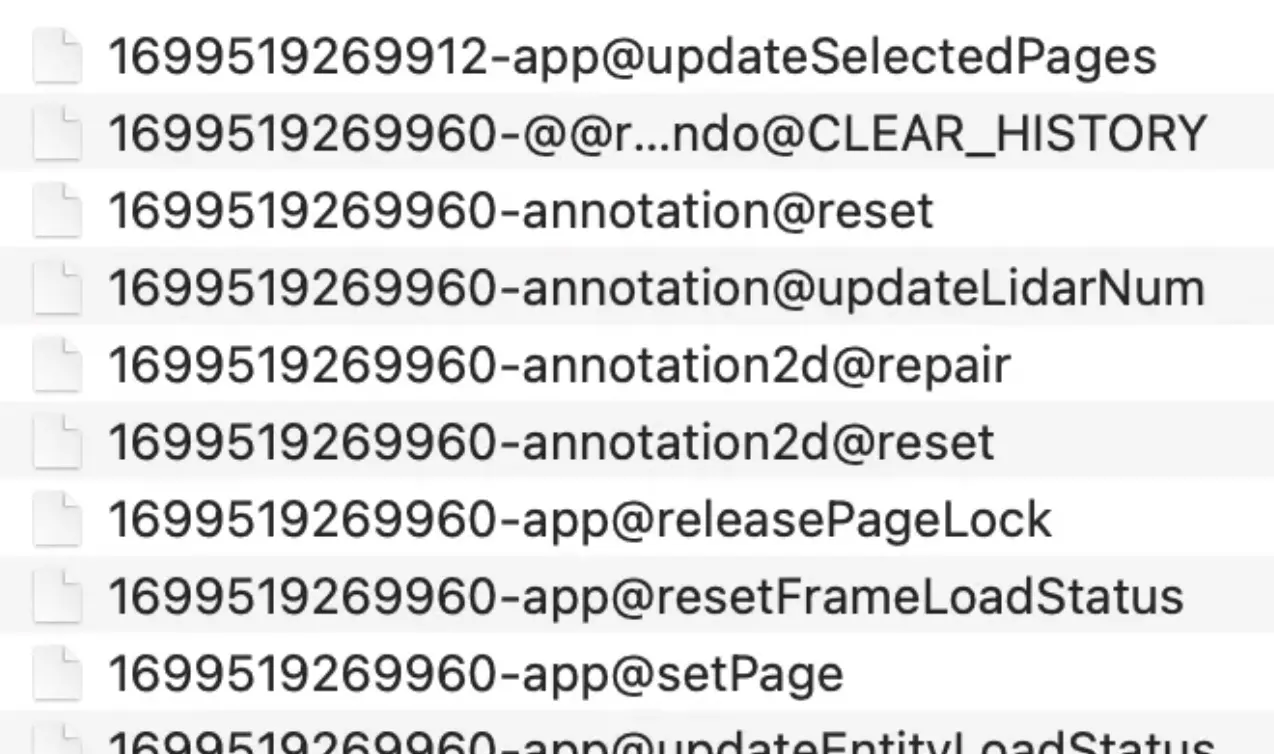
这就带来另一个致命问题:“存储一时爽,分析火葬场”。
研发拿到日志之后,仅仅是故事的开始,接下来需要动用各种手段去拆解,分析,关联,这才是拖垮研发精力的重头戏,研究起来动辄几小时。
更别说用户换电脑的情形了,还得跨设备组合日志进行分析:
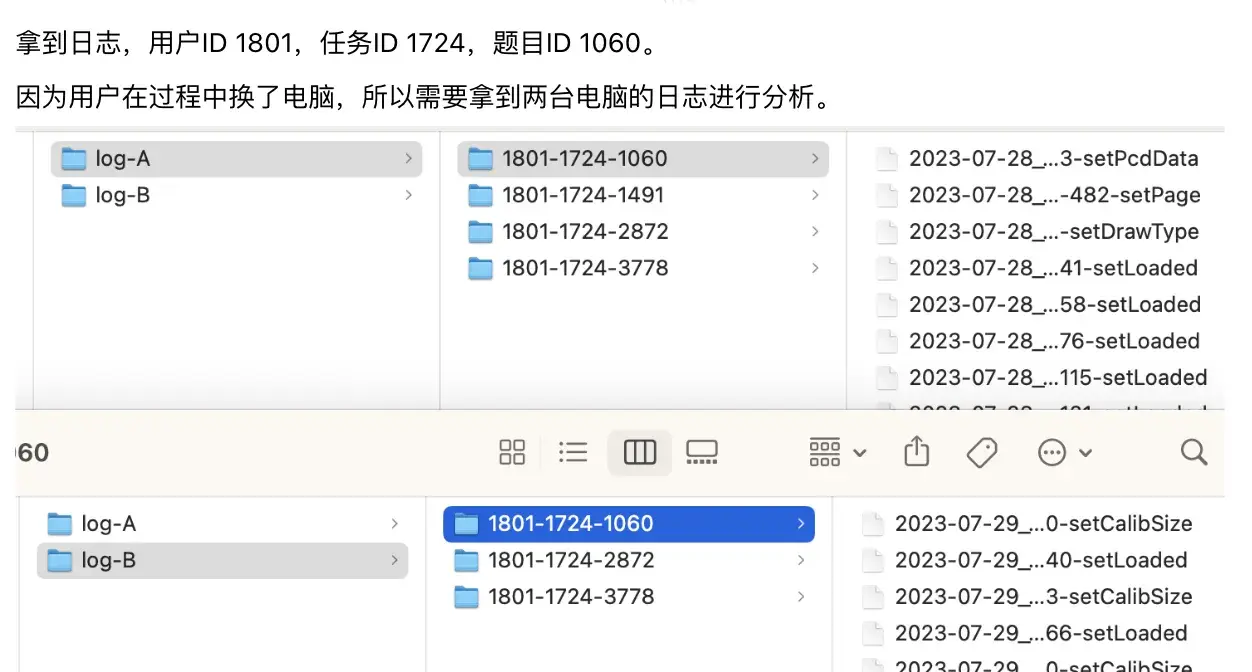
诸如此类的问题细节还有很多,我们来列举下并逐个击破:
问题:全量数据太大,采样又会影响后期分析准确性。
解法:不存储完整payload,只保留diff数据。
问题:离线日志获取麻烦,且用户有频繁切换设备的习惯。
解法:同步至远端(COS),同步后删除离线日志。
问题:日志太琐碎,写操作频繁。
解法:定期压缩日志表,写成Blob存入中间表,等待备份。压缩后,删除原日志数据。
问题: dispatch是高频同步操作,而存储逻辑复杂,有一定耗时,会对主逻辑产生堵塞风险。
解法:1. debounce包裹saveLog操作 2. 建立任务队列,闲时异步处理
问题:diff操作耗时(10-30ms)远高于状态更新耗时(0-2ms),会降低Redux吞吐量。
解法:把diff放入saveLog事务中,享受任务队列和防抖的效果。
问题:日志量太大,非结构化存储不好查找出想要的日志。
解法:日志备份操作时,计算出时间区间,再加上业务信息和用户信息,一并作为文件名。
问题:人工分析日志极其低效。
解法:开发日志解析工具,配合diff信息,输出可视化的timeline视图,并支持关键字段筛选。
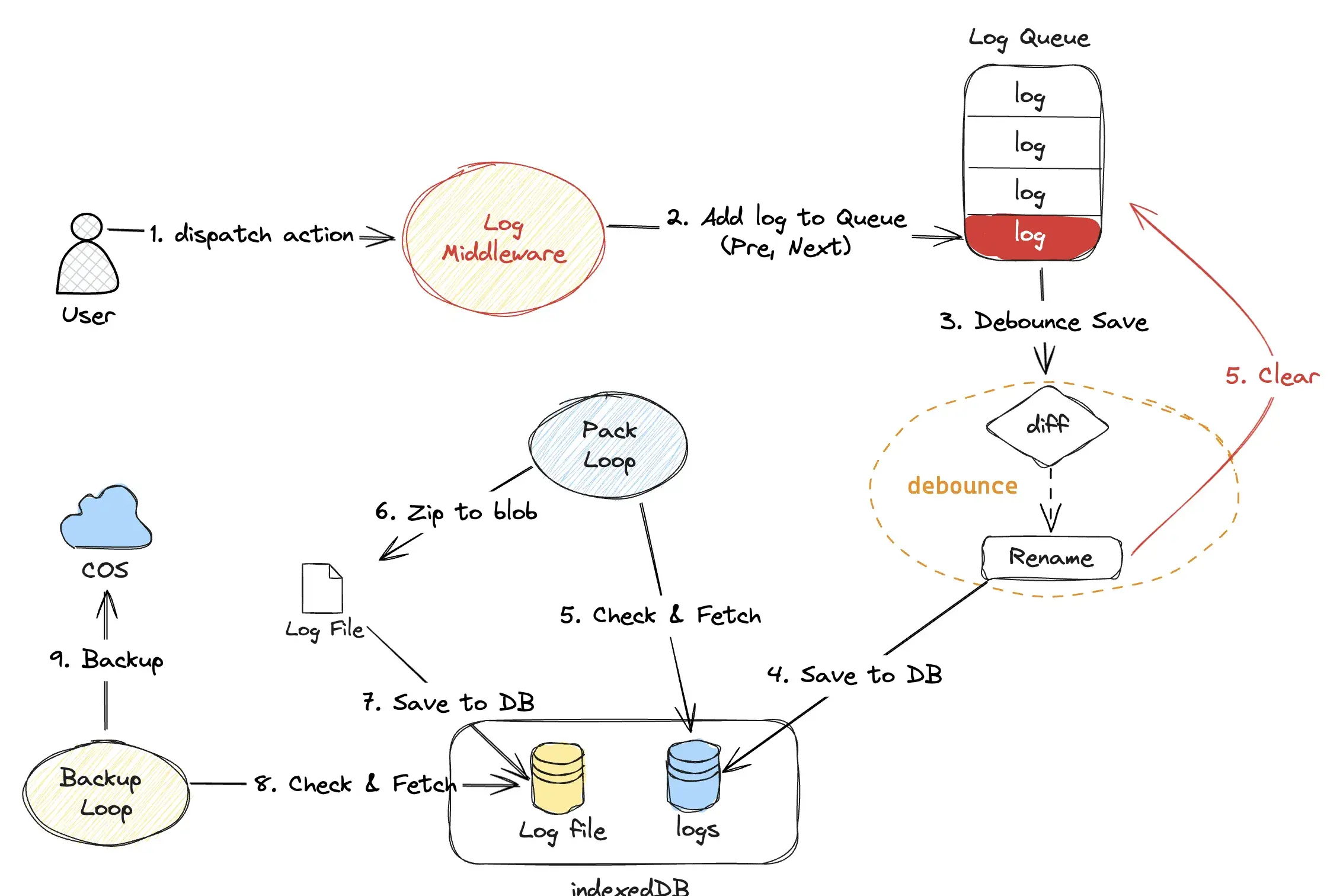
以上措施总结起来就4类:
- 采集
- 整合
- 存储
- 分析
完整的架构图如下:
来看看日志表长什么样:
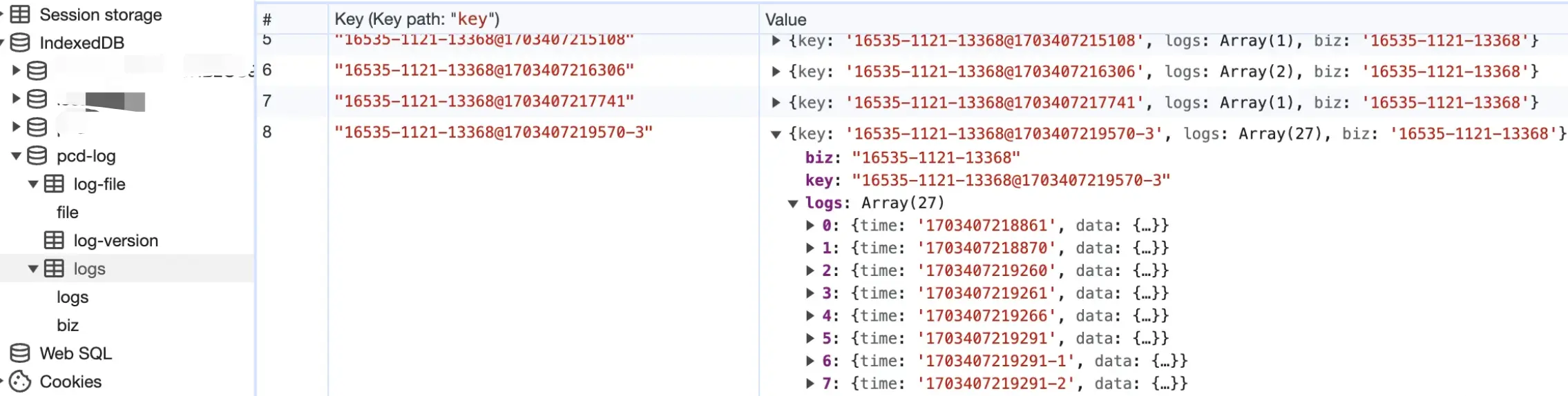
细心的人应该发现了,为什么图上有的time里会有奇怪的-1,-2呢?
其实是因为,dispatch的速度太快了,有时候多条action排入待写队列的时候,其时间戳哪怕精确到毫秒级别都一模一样,类似这样:
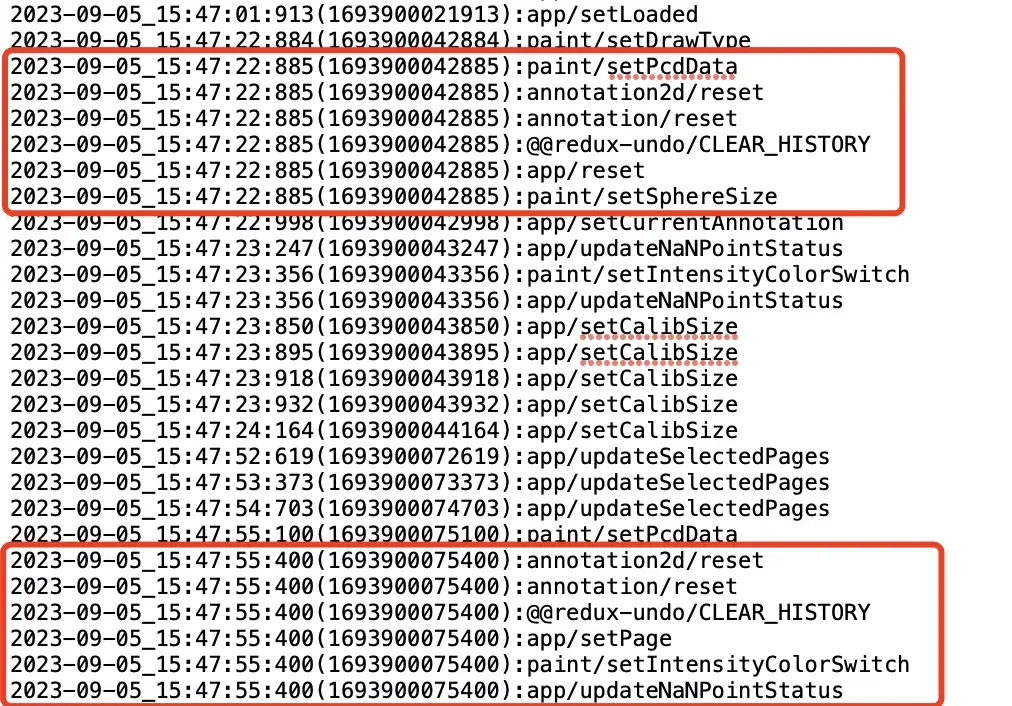
前端时间戳只精确毫秒,那我分析用户行为的时候怎么能判断出action的先后顺序呢?
其实也简单,因为dispatch毕竟是同步行为,js又是单线程运行,必定是有先后的,只是时间精度不够罢了,那么我只需要在毫秒的基础上,增加上每次action在待写队列里的索引值即可。
一个看起来很小的细节,很大程度上帮助了后续分析阶段的准确性。
数据修复
先来看一张图:

这就是之前研发在做数据修复工作时,在用户群里的惯常操作,这里有个核心问题:
研发进行数据修复时,需要大量信息做参考比对,才能最终找到合适的数据。而研发和标注员之间隔了很多人,信息传递效率低,有信息丢失风险。
其实这个问题不难解决,只要把数据修复的能力开放给标注员自己就好了。
研发人员找数据困难,那是因为用户A的数据对于研发来讲,就是数据海洋里平平无奇的一朵浪花,他需要用各种手段层层筛选出属于用户A的那一堆浪花,并在其中找到最漂亮的那一朵……
但用户自己的数据,他可比谁都熟悉,他和数据的关系是1对1的,他甚至能记起来第104个框是在午休起来后标的,第201个框是在下午5点59分下班前又挪动了一下的。
然而这些你并不知道,这就是关键信息丢失。
你要知道,想要对抗信息衰减的物理规律,保证信息经过漫长的链路后完整无缺,是需要付出极其高昂的养护成本的。但其实你只需要减少信息传输,尽可能原地完成信息消费,就能以极低的成本完成这项艰巨的任务。
基于此分析,我给标注员开发了一套简单的版本管理工具:
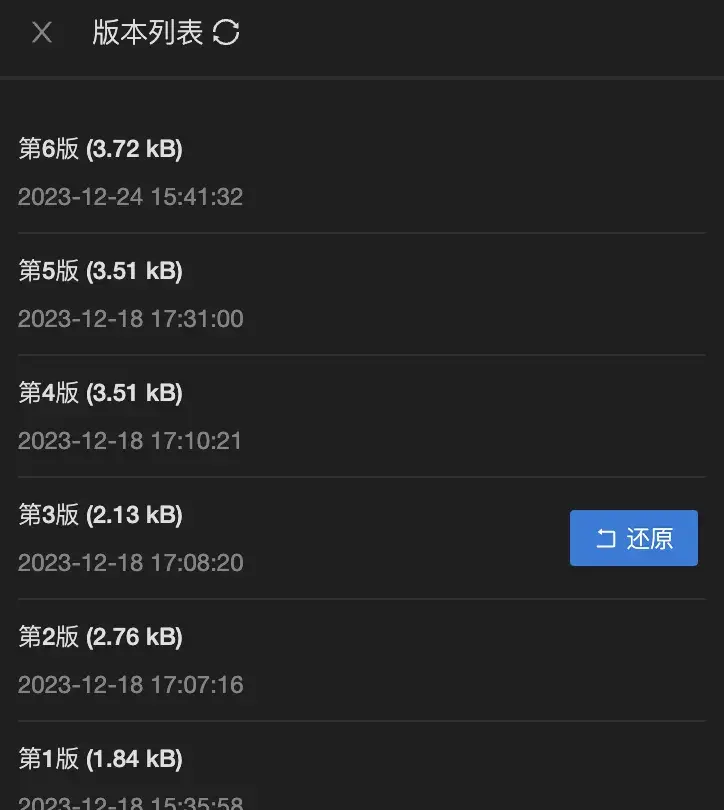
并提供了精准友好的提示:
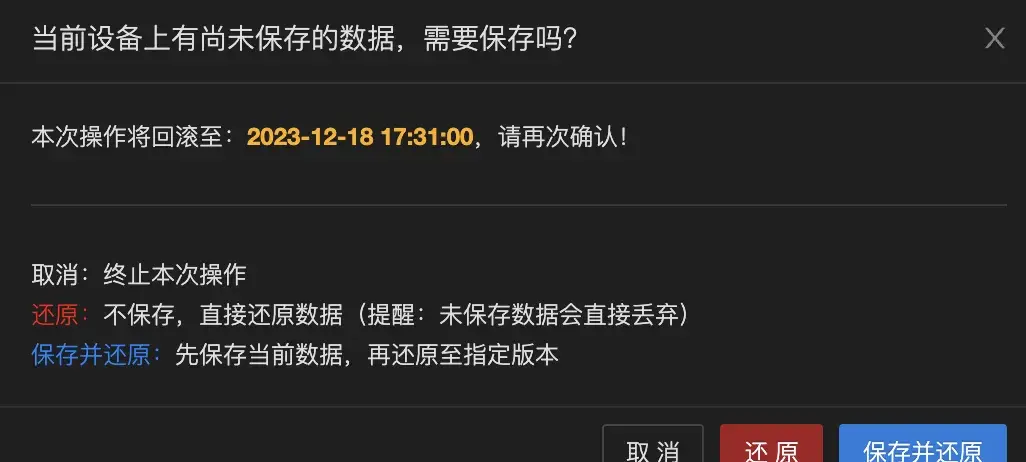
很多事就这么简单!
这个工具上线后,研发再也没有去处理过这种恶心又无聊的数据修复工作。
日志分析

不管是为了修复数据,还是为了定位到逻辑bug,日志分析都是一件非常令人头痛的事情。
作为一个前端,能用GUI的方式解决问题,我绝对不去看花眼的黑白色调试日志里找东西。我找遍了npm和git都没有找到一个理想的工具来帮我完成这件事,最终决定还是从Redux Devtool下手,正当我准备把它的核心逻辑抽取出来封装一个适合我们用的工具时,我又发现了Redux-logger :
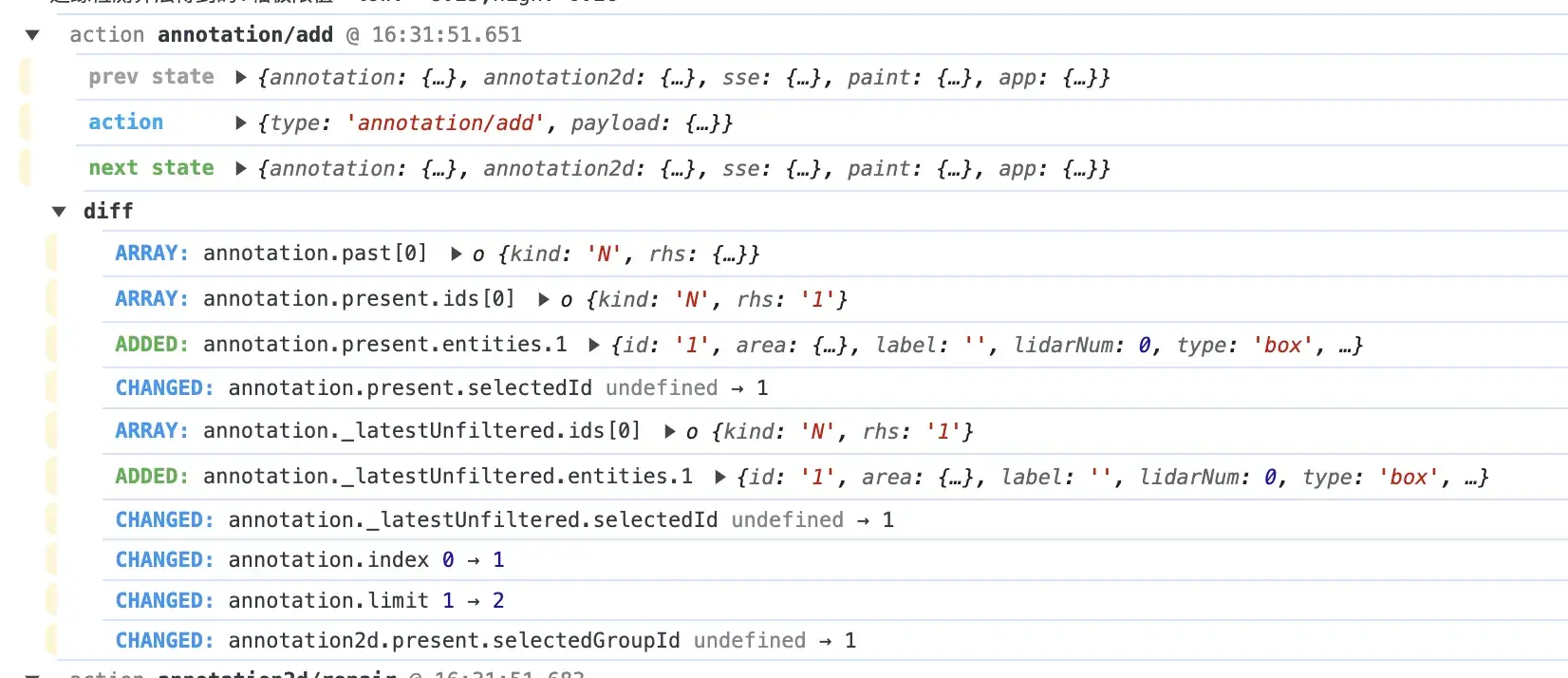
它可以在控制台里打印出每次action的完整的diff信息,而且竟然还蛮好看的,虽然离我想要的还是有一些距离。不过我研究完它的源码,发现核心代码极其简单。
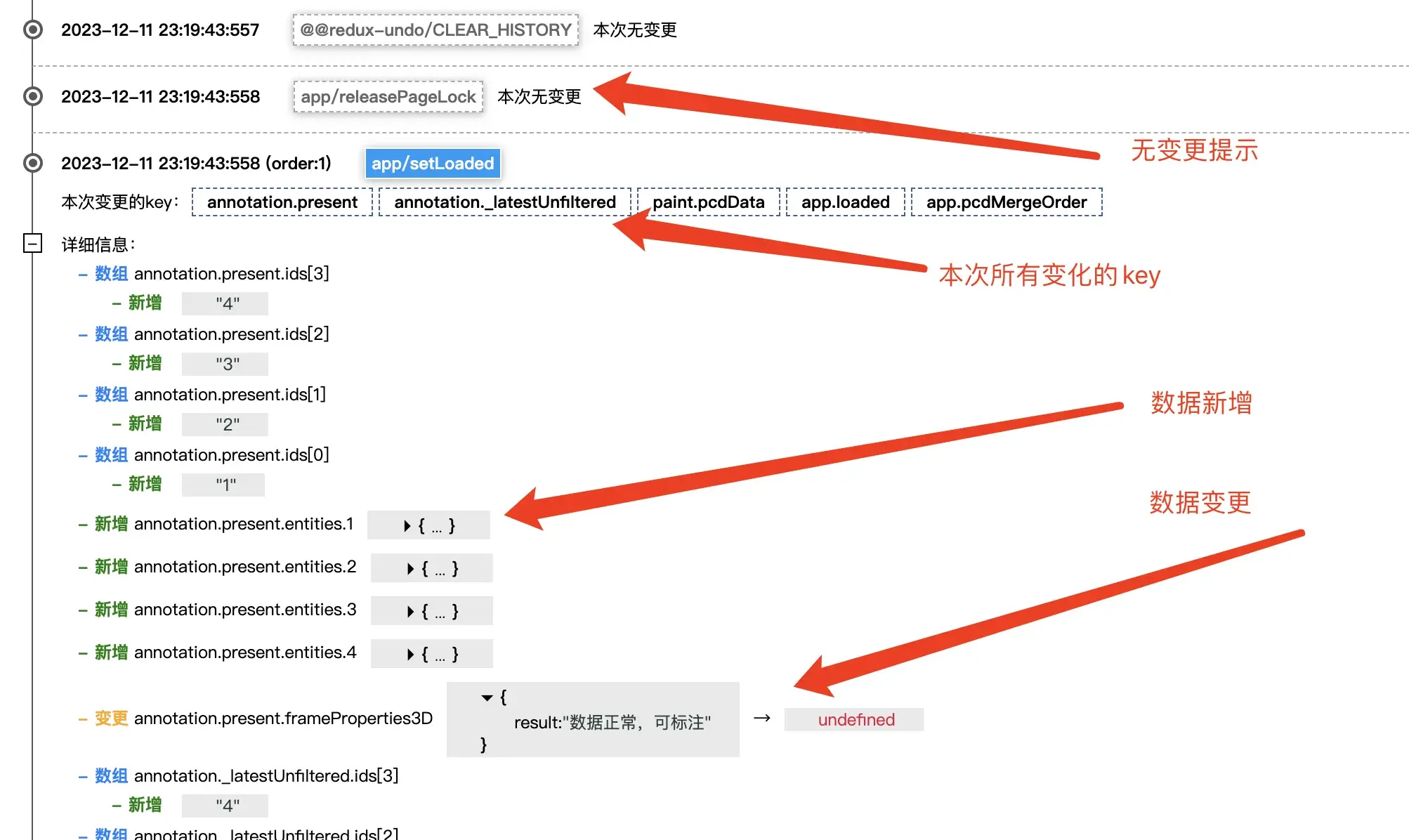
于是我参考着它的diff逻辑,重写了语义解析的部分,再加上一些我认为可以提升用户体验的能力,最终开发了一个日志分析工具,一键导入日志文件,自动可视化输出关键信息。
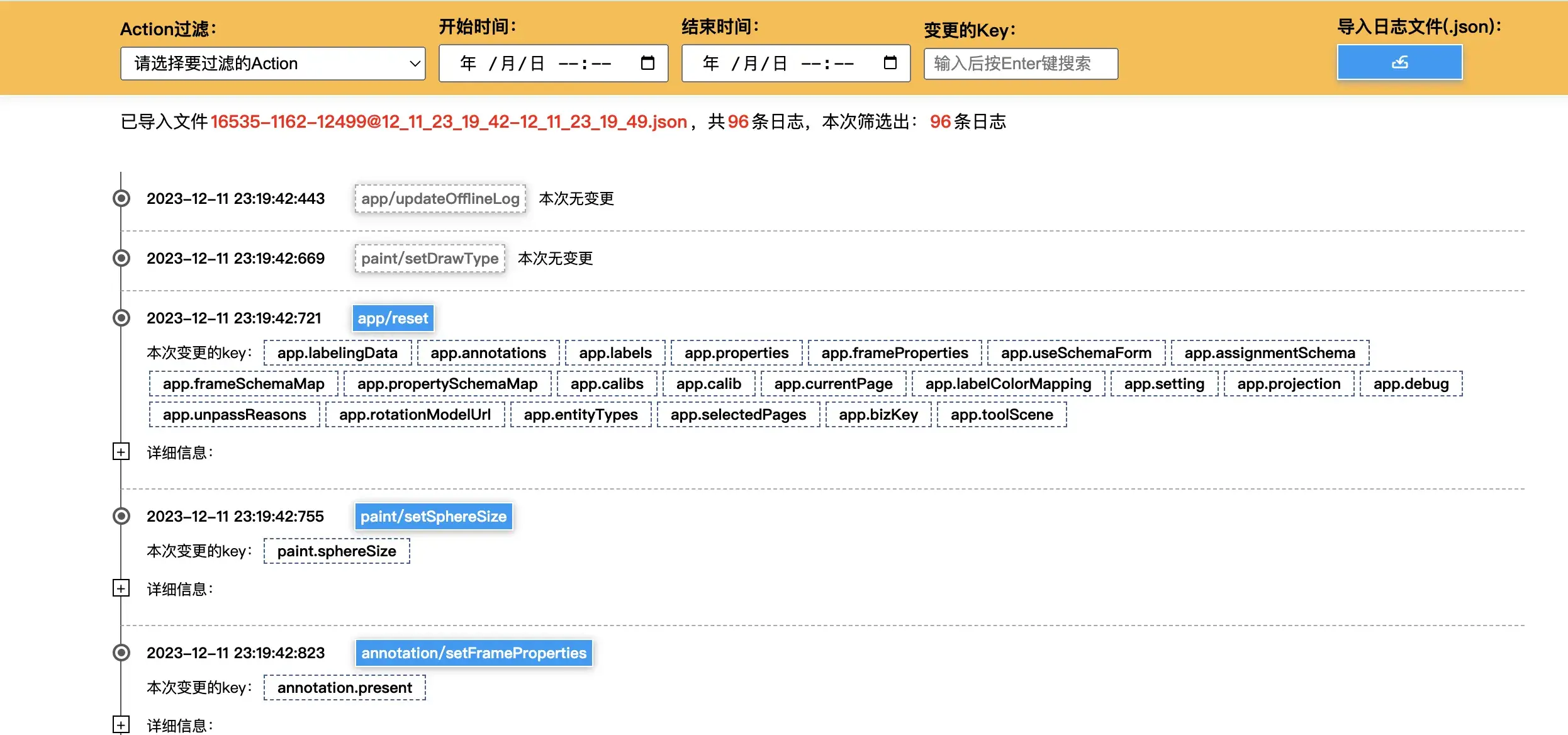
让我们展开一条日志看看,清晰明了:
架构重构
花了巨大的篇幅聊问题定位和数据修复,一直没聊造成这些问题的根本性代码Bug,你可能会以为是我忘了,其实不然,我是刻意弱化这块内容的。
为什么呢?
因为我坚定的认为,寻找答案的过程,比答案本身更重要。
上学的时候,不管我们做什么难度的题,题目本身总是有标准答案的,我们只需要想办法去往标准答案尽可能靠拢就好。然而毕业后,真正的难题才缓缓展开。
不管是在生活中,还是工作中,我们会遇到非常多纷繁复杂的问题,而问题本身往往没有标准答案,甚至连参考答案都没有,也自然不会有人手把手教你朝着某个既定的,正确的方向去探索。
我们经验总结和分享的时候,可能出于某些原因,往往会把结果前置,摆指标数据,摆竞品对比,无限放大结果的优越性,试图用这个牛X轰轰的成果去证明你的技术实力。
事实上,成功的人说什么都是对的,但观众在认知到这份成果之后,并不能反推出一条必然导致同样成果的过程。那么当他遇到一些自己的问题的时候,也很难举一反三的应用在自己的问题解决里。
授人以鱼不如授人以渔。
我分享的目的,是尽可能的还原出我当初赤手空拳面对业务真实危机时的思考,和策略选择背后的原因。
好了,价值观输出完,还是要给个结论的,否则别人会说你比划了半天啥问题都没分析出来,那岂不是差生文具多么?显然不是哈,上图:
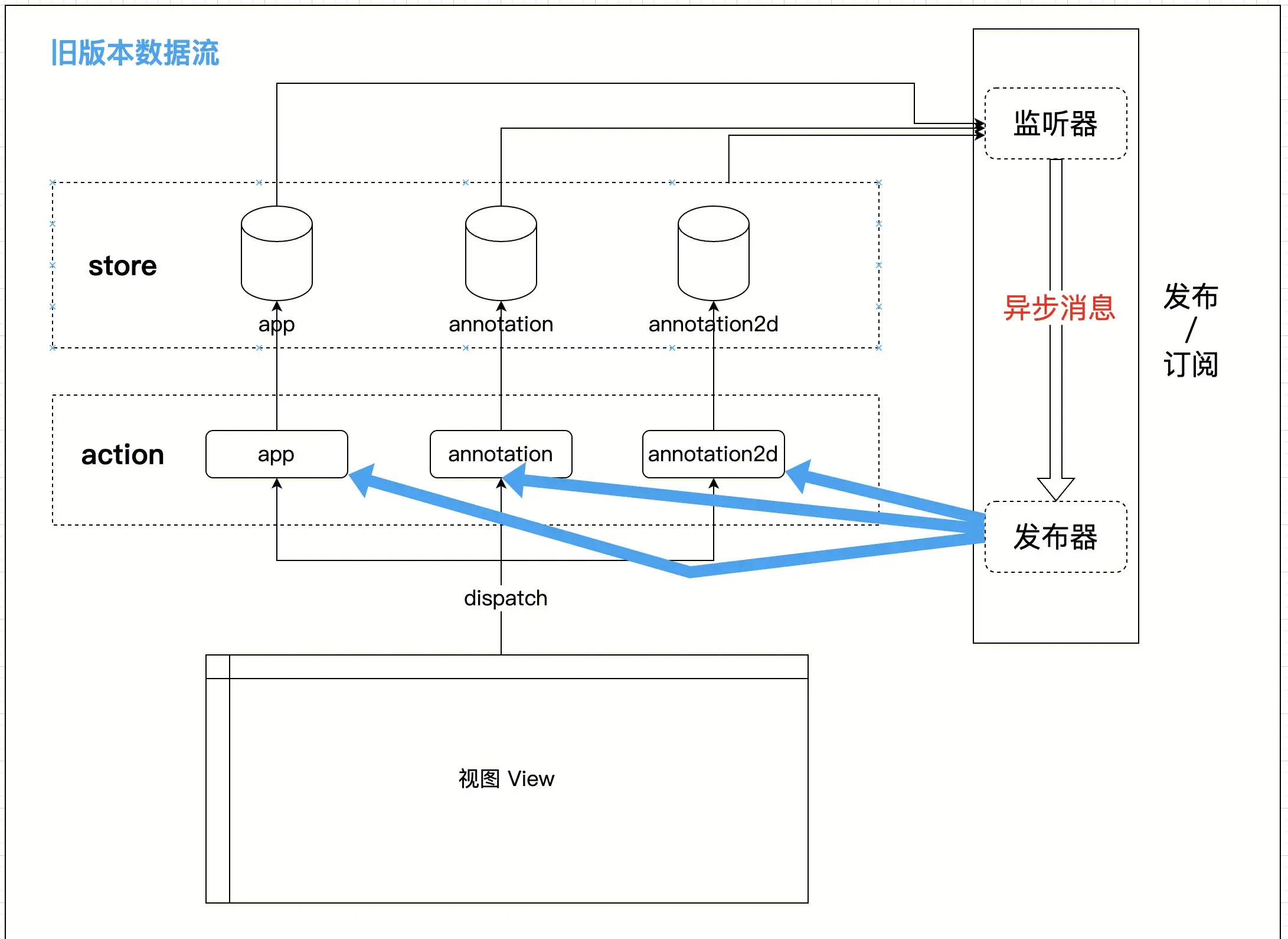
这是系统原有的旧版本数据流动示意图,可以清楚的看到,在原本同步流动的Redux数据流里,因为一些原因(为了解决多个子系统之间的数据同步问题),引入 「发布/订阅」 模式,继而导致了数据变化的次序被打乱了。
这就是数据异常的根源性问题所在。
你若要问我,这个结论是怎么得出的,那我只能说,debug不是开发者最基本的素养吗?有了趁手的兵器,还愁打不了魑魅魍魉?
好了,既然知道了问题,解法自然也就有了。其实这就是一次前端状态管理的错误使用示范,只需要回归到状态管理的第一哲学即可:保证单一数据源,保持数据同步流动。
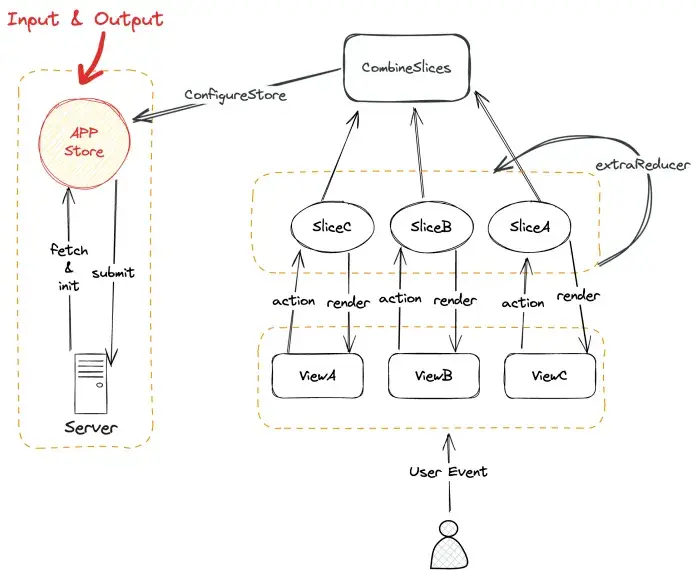
这是我新画的架构图,其实并没有任何创新的技术,无非是针对我们的业务场景,根据状态管理哲学,重新梳理了一下而已。
至此,问题得以彻底解决。
最后附上本次分享的完整心智模型:
『及人』:精心打磨的工具开源
其实我在做日志分析工具的时候就在想,既然市场上没有找到合适的工具,而这类前端数据管理问题应该是具有普遍性的,那我为何不抽一个工具开源给大家使用呢?
所以我在写这个工具的时候,尽可能的本着开源的目的去编写,比如尽可能不依赖第三方库,用原生Html+Js+Css去写。即便如此,现在这套代码还不足够抽象,接下来我还需要一定的时间去做抽象和封装,希望最终能帮到遇到同样问题的小伙伴,尽情期待吧。
当然了,如果你有更好用的工具和方案,也欢迎评论区和我交流,或者直接加我微信私聊。
如果还想继续看我写的东西,记得一键三连!你的支持是我继续写下去的动力。
公众号|沐洒(ID:musama2018)
掘金2023年度人气创作者打榜中,快来帮我打榜吧~ activity.juejin.cn/rank/2023/w…

原文链接:https://juejin.cn/post/7316203818651435017 作者:沐洒