



limu面向现代浏览器而设计,只考虑支持Proxy的运行环境,使用了读时浅复制写时标记更新的机制来达到让用户像操作原始数据一样操作可变数据,操作过程中始终只为读取节点生成代理对象返回给用户,读取后父子节点间直接用浅克隆节点相连,proxy对象隐藏到节点的meta数据中,结束操作后生成一个具有结构共享特性的新数据,同时移除这些读取过程中生成的meta数据。

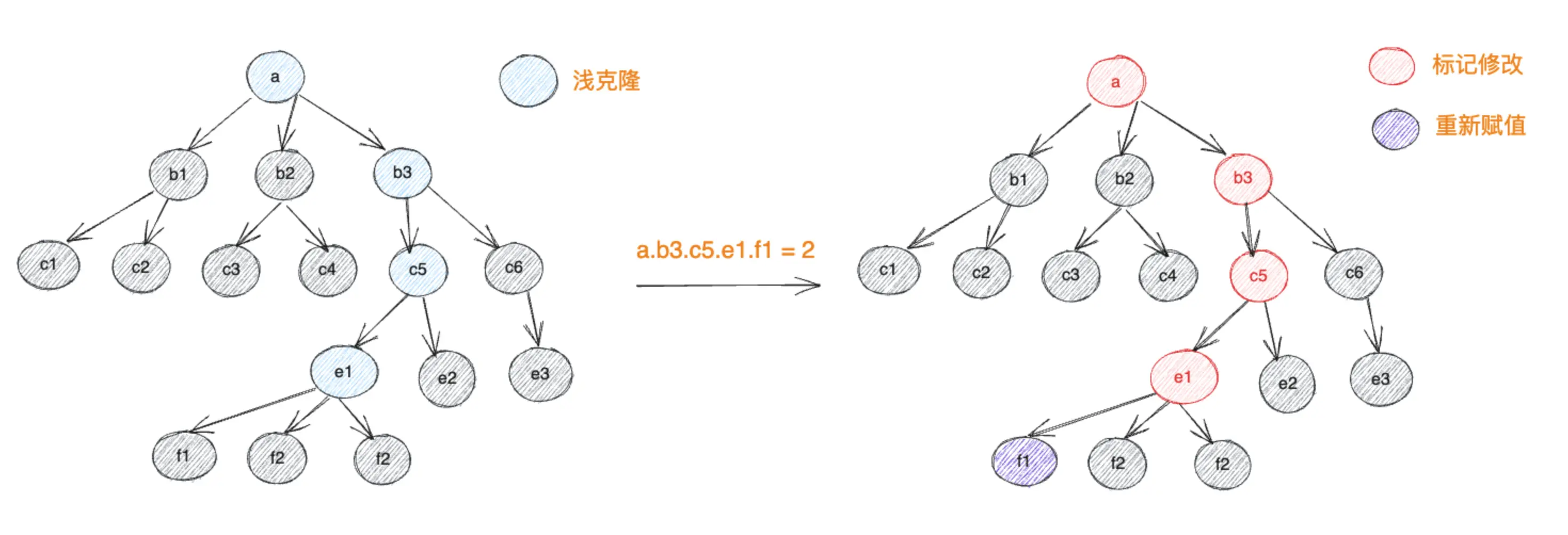
这样的设计带来了3大好处:
-
数据结构透明
limu是当下唯一一个可实时查看草稿的数据结构的不可变操作库,调试友好。 -
性能优异
由于提前做了浅克隆操作,且只克隆读取过的路径并改变父子节点相互之间的路径指向,在结束草稿时只需判断modified变量真假来瞬间完成新的副本生成动作,在数据大读取少的场景性能超过immer20倍以上(3.12之前数据为4倍左右) -
代码结构简洁
由于只考虑支持Proxy,代码设计没有历史包袱,可以专注于数据读写、代理生成、冻结实现等不可变数据的核心场景,利于后期升级和扩展更多面向现代浏览器标准的特性。
优化过程
在3.12之前,limu虽然性能已超过immer数倍,但离structura、mutative这些新起的不可变数据操作库还有不少差距,故只能把调试友好、比immer快几倍来作为宣传点,如需追求极致的速度还是默认推荐了mutative。
在3.12之后,limu终于抹平了这些差距,下面开始分享性能优化过程,看limu是如何修炼出关到达性能之巅的。
放置meta
开文我们提到了meta数据隐藏这个点,meta数据记录这当前节点的代理对象,父亲、孩子、可触达路径、数据版本号等重要信息,为了让用户不感知到这个数据的存在,先后做了2种尝试
symbol藏匿meta
内部使用一个symbol标记来存储meta
const LIMU_META = symbol('LIMU_META');
const obj = { a: 1, b: { b1: 1 } };
// 读取 obj.b 时,对象 { b1: 1 } 藏匿一个 meta
{ b1: 1, [LIMU_META]: { parent, path, version, modified ... } }
那么在操作草稿结束时,levelScopes操作力需要通过delete关键字来移除这些多余的数据,此种方式带来的不便就是打印数据时看到一个很刺眼的LIMU_META属性在对象中,给用户造成了一种污染数据的心里负担。
proto藏匿meta
为了让数据干净,于是除了继续用LIMU_META这个symbol作为私有属性之外,将这个属性提升到__proto__中藏匿,那么问题来了,如果直接操作__proto__,就污染了原型链
var a = 1;
a.__proto__.meta = 1;
var b = 2;
console.log(b.__proto__.meta); // 1
a.__proto__.meta = 100;
console.log(b.__proto__.meta); // 100 ❌ 原型链已被污染
为了绕过污染,采取了为每一个对象单独建立一个原型对象夹杂在原来的原型链中间,示意如下:
before:
a.__proto 指向 Object.Prototype
after:
a.__proto 指向 Limu.Prototype,Limu.ProtoType 指向 Object.Prototype
// 每一个 Limu.Prototype 都是通过 Object.create(null) 生成的干净对象
简化版代码实现如下
export function injectLimuMetaProto(rawObj) {
const pureObj = Object.create(null);
Object.setPrototypeOf(pureObj, Object.prototype);
Object.setPrototypeOf(rawObj, pureObj);
return rawObj;
}
这样达成了使用symbol藏匿私有属性和使用重建原型链达到提升私有属性到原型链上且不污染原型链的效果。
性能损耗分析
虽然利用meta完成了生成结构共享数据的目标,但测试结果离structura,mutative还是相差4 5 倍的结果让我相信limu一定还有上升的巨大空间。
于是开始不停微调源码并跑性能测试脚本,来找出可能存在的性能损耗点。
移除meta
结束草稿时我们需要移除 meta,以免照成内存泄露,那么就会使用到 delete 操作符来断开父节点指向的 LIMU_META , 我将这个delete操作屏蔽后,性能提升了2倍左右,那么关键点就变成了如何绕开delete操作
function finishDraft(){
levelScopes()
}
function levelScopes()(
scopes.forEach((scope)=>{
// 注释掉 deletaMeta,性能提升 2 倍
// deletaMeta(scope);
});
)
原型链重组
上面提及的injectLimuMetaProto其实涉及到一个原型链重指向的过程,包含了两次setPrototypeOf操作,刻意屏蔽此函数,将meta下方到对象上放置,性能提升了4倍左右,发现大量节点的setPrototypeOf其实造成了很大的性能损耗。
injectLimuMetaProto(obj),
setMeta(obj, newMeta());
// 替换为如下写法,性能提升 4 倍
obj[LIMU_META] = newMeta();
定制优化方案
通过不停地注释代码跑脚本分析出性能损耗点后,我们的目标就很明确了,如何既能够屏蔽delete和setPrototypeOf这两个性能消耗大户,还能够保持数据干净和meta能够正常获取。
最终想到了es6的新数据结构Map,在createDraft时为每一个草稿生成一个metaMap,用于放置数据对应的meta即可,伪代码如下:
function getProxy(metaMap, dataNode){
const meta = !getMeta(dataNode);
if(!meta){
const copy = shallowCopy(dataNode);
const meta = newMeta(copy, dataNode);
// 用节点自身浅克隆引用作为key,存储 meta
metaMap[copy] = meta;
}
// 已有 meta,返回生成过的代理对象
return meta.proxyVal;
}
function createDraft(base){
const metaMap = new Map();
return new Proxy(base, {
get(parent, key){
const dataNode = parent[key];
return getProxy(dataNode);
},
})
}
有了这份metaMap,就没有了setPrototypeOf行为了,同时在finishDraft步骤里继续操作此metaMap,断掉相关meta记录,想把delete,map.delete更为高效,本身我们的数据就是存储到map里,故我们不再需要同delete打交道了。
伪代码如下
function finishDraft(){
levelScopes();
}
function levelScopes()(
scopes.forEach((scope)=>{
metaMap.delete(scope.meta.copy);
});
)
到此为止,我们完成了彻底屏蔽delete和setPrototypeOf的目的,同时用户的数据完全干净透明,接下来我们进入优化后的性能测试环节。
性能测试
我们已经性能测试相关代码放置到benchmark,你只需要执行以下步骤即可体验到最新版本的性能测试表现。
git clone git@github.com:tnfe/limu.git
cd limu
cd benchmark
npm i
然后执行下面四组命令,观察打印结果即可
npm run s1 // 不操作草稿数组,结果不冻结
npm run s2 // 操作草稿数组,结果不冻结
npm run s3 // 不操作草稿数组,结果冻结
npm run s4 // 操作草稿数组,结果冻结
测试数据设计
为了模拟复杂数据,我们的的是测试数据包含一个20+key的字典,
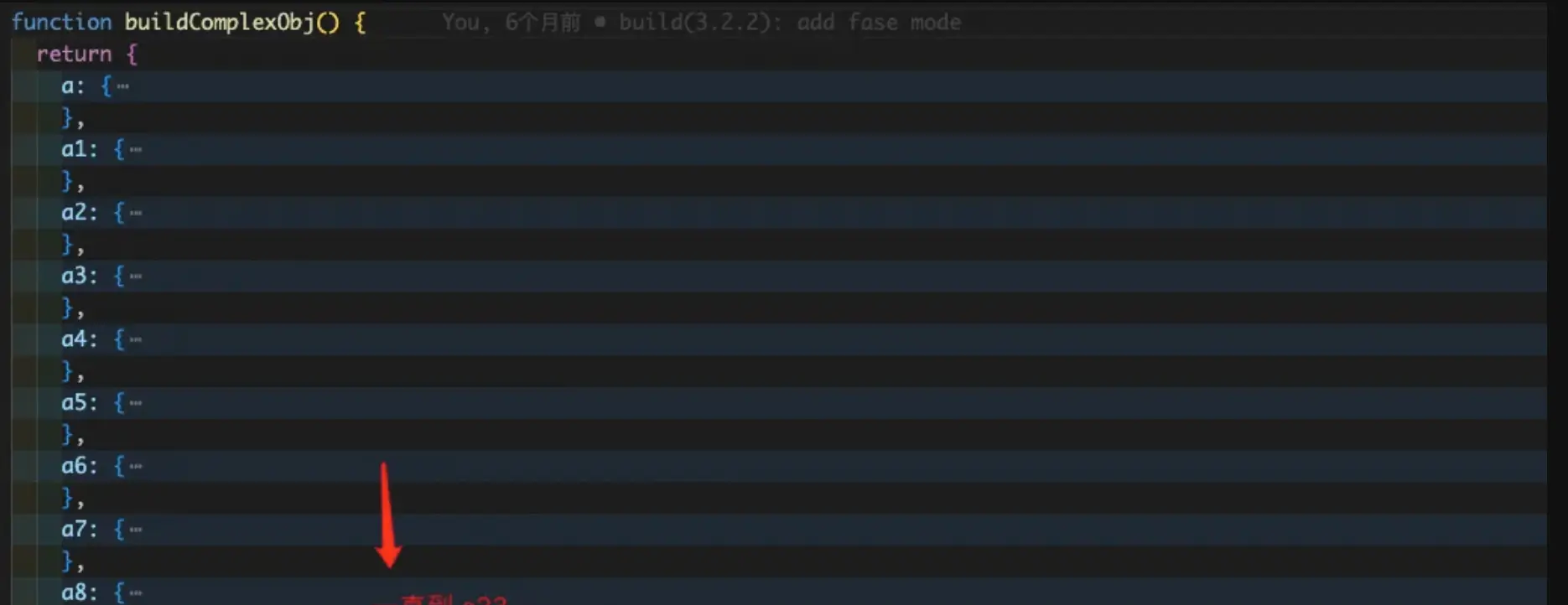
key对应的数据深度为 26层
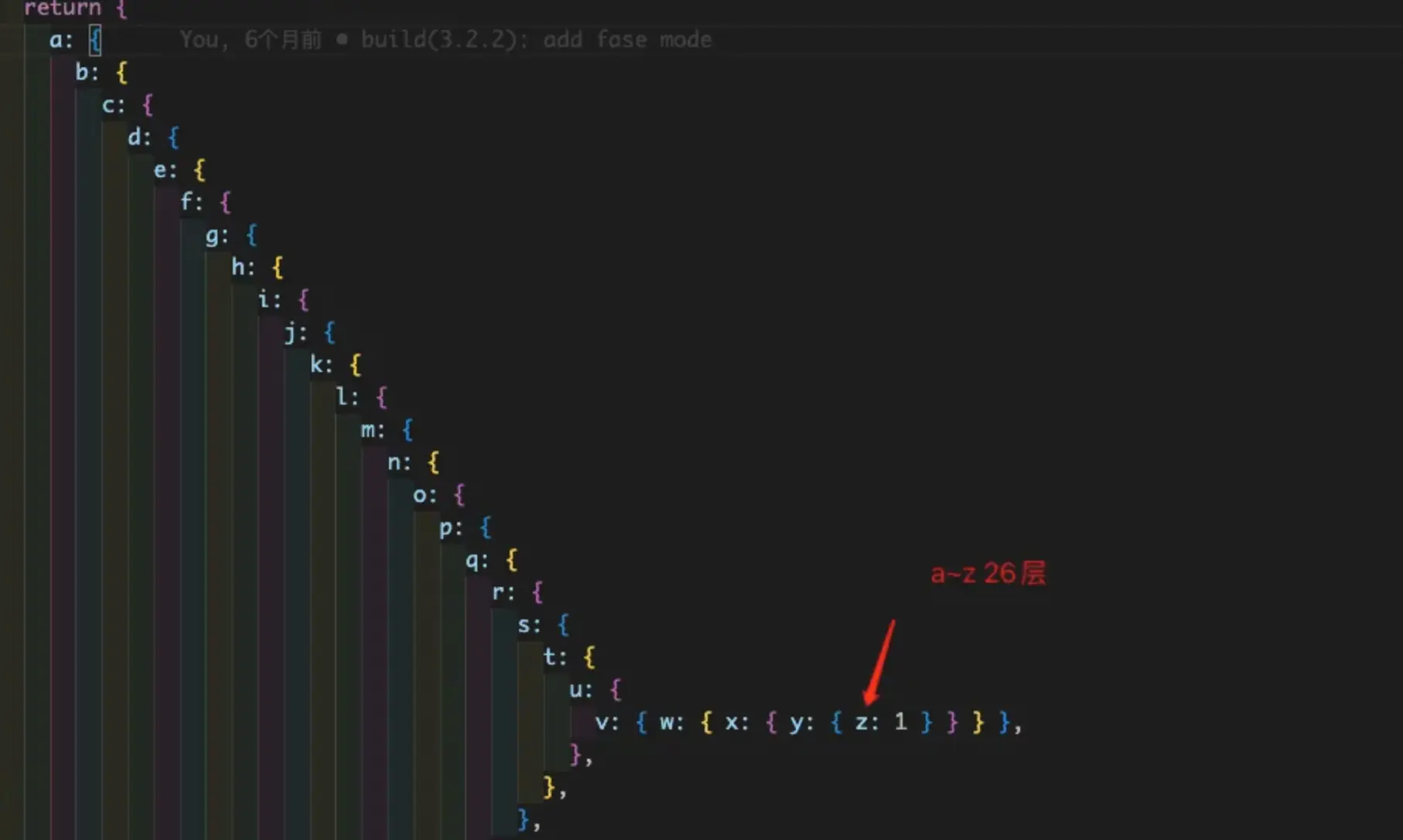
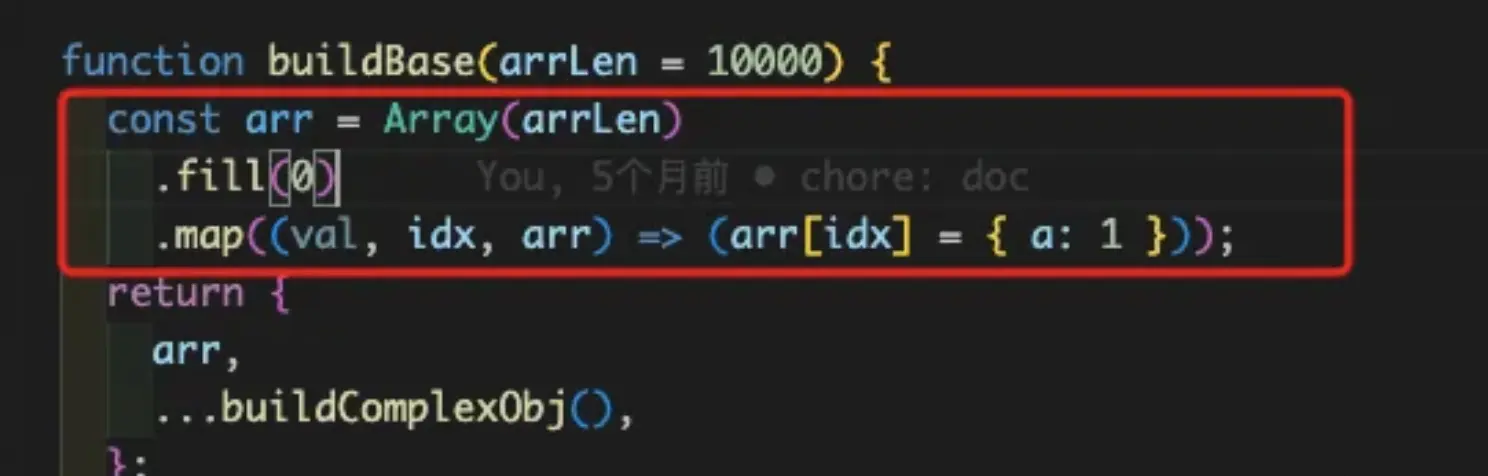
同时还会生成一个长度10000的数组
测试角色准备
测试角色除了immer,limu,mutative,structura这四个库,还新增了pstr和native
pstr使用JSON.parse和JSON.stringify来模拟immer的produce
// code of pstr
exports.createDraft = function (obj) {
return JSON.parse(JSON.stringify(obj));
};
exports.finishDraft = function (obj) {
return obj;
};
exports.produce = function (obj, cb) {
cb(exports.createDraft(obj));
};
native则啥也不干,就是操作原生对象
exports.createDraft = function (obj) {
return obj;
};
exports.finishDraft = function (obj) {
return obj;
};
exports.produce = function (obj, cb) {
cb(exports.createDraft(obj));
};
新增pstr和native是为了对比不可变操作效率先比硬克隆JSON.parse(JSON.stringify(obj))和原始操作的性能差距。
测试代码编写
为了测试复杂数据读写,会做多个深层次读并写的操作,同时增加operateArr控制是否便利数组做操作,部分示意代码如下:
runPerfCase({
loopLimit: 1000,
arrLen: 10000,
userBenchmark: (params) => {
const { lib, base, operateArr, moreDeepOp } = params;
const final = lib.produce(base, (draft) => {
draft.k1.k1_1 = 20;
if (moreDeepOp) {
draft.a.b.c.d.e.f.g.h.i.j.k.l.m.n.o.p.q.r.s.t.u.v.w.x.y.z = 666;
draft.a1.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a2.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a3.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a4.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a5.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a6.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
draft.a7.b.c.d.e.f.g.h.i.j.k.l.m.n = 2;
}
if (operateArr) {
draft.arr[draft.arr.length - 1].a = 888;
// draft.arr.forEach((item, idx) => { // bad way
lib.original(draft.arr).forEach((item, idx) => { // good way
if (idx === 100) {
draft.arr[1].a = 888;
}
});
}
});
if (base === final) {
die('base === final', lib);
}
},
}).catch(console.error);
每个角色正式开始执行前都会做一次预热,然后开始1000次遍历,每次遍历结束得到一个耗时,最后耗时加总除1000得到每次遍历耗时平均值,部分示意代码如下:
function oneBenchmark(libName, options) {
const { userBenchmark, arrLen } = options;
let lib = immutLibs[libName]; // 获得不同的 immutable 库
const base = getBase(arrLen);
const start = Date.now();
try {
// 执行用户编写的性能测试用例
userBenchmark({
libName,
lib,
base,
operateArr: OP_ARR,
moreDeepOp: MORE_DEEP_OP,
});
const taskSpend = Date.now() - start;
return taskSpend;
} catch (err) {
console.log(`${libName} throw err`);
throw err;
}
}
function measureBenchmark(libName, options) {
const loopLimit = options.loopLimit || LOOP_LIMIT;
let totalSpend = 0;
const runForLoop = (limit) => {
for (let i = 0; i < limit; i++) {
totalSpend += oneBenchmark(libName, options);
}
};
// preheat
oneBenchmark(libName, options);
runForLoop(loopLimit);
console.log(`loop: ${loopLimit}, ${libName} avg spend ${totalSpend / loopLimit} ms`);
}
测试结果展示
我的机器是macbook pro 2021,M1芯片,32GB内存。
执行npm run s1,表示不操作草稿数组,结果不冻结,结果如下
loop: 1000, immer avg spend 13.19 ms
loop: 1000, limu avg spend 0.488 ms
loop: 1000, mutative avg spend 0.477 ms
loop: 1000, structura avg spend 0.466 ms
loop: 1000, pstr avg spend 17.877 ms
loop: 1000, native avg spend 0.084 ms
可视化结果为(单位ms,柱越低性能越好)

执行npm run s2,表示操作草稿数组,结果不冻结,结果如下
loop: 1000, immer avg spend 11.315 ms
loop: 1000, limu avg spend 0.95 ms
loop: 1000, mutative avg spend 0.877 ms
loop: 1000, structura avg spend 0.646 ms
loop: 1000, pstr avg spend 9.945 ms
loop: 1000, native avg spend 0.107 ms
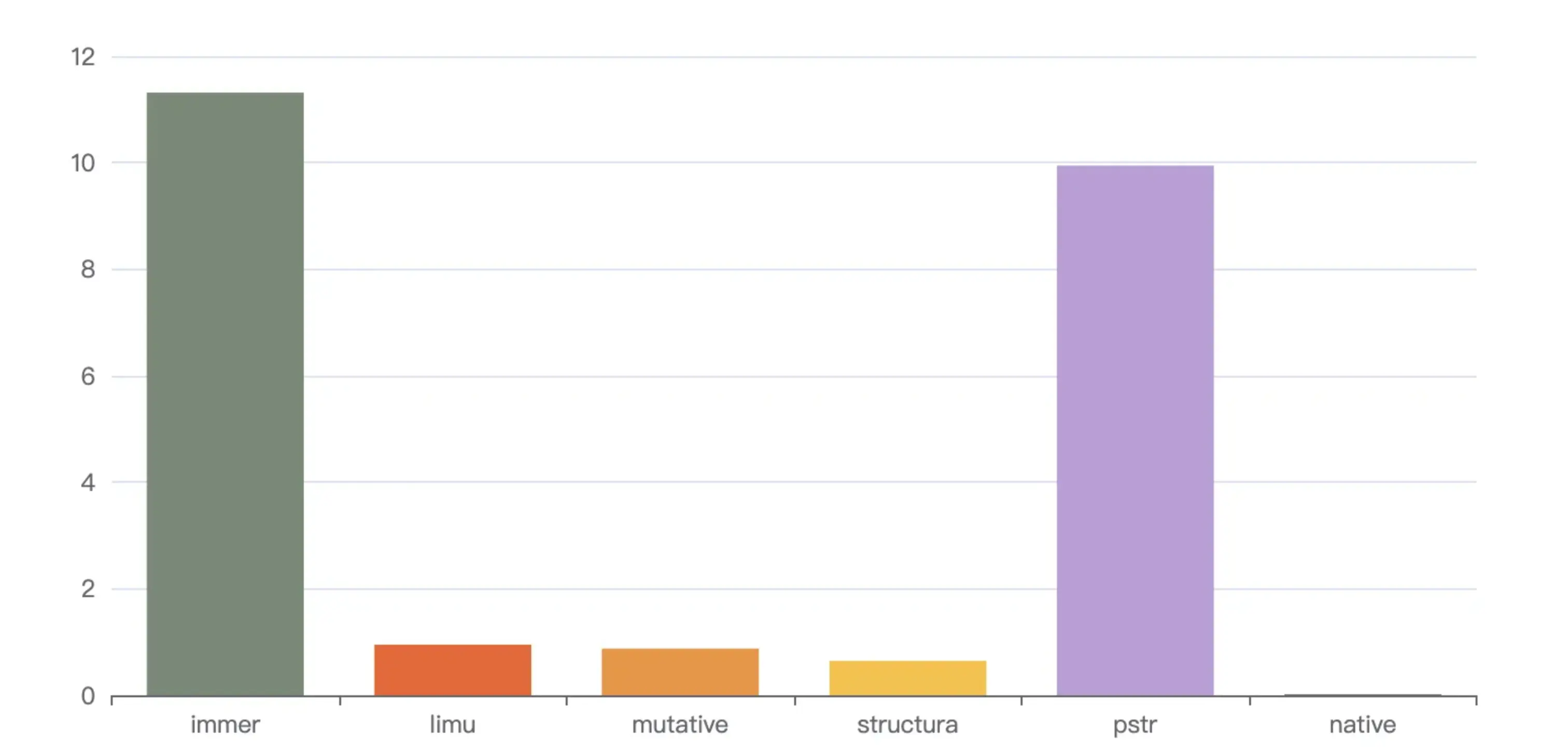
执行npm run s3,表示不操作草稿数组,结果冻结,结果如下
loop: 1000, immer avg spend 18.931 ms
loop: 1000, limu avg spend 5.274 ms
loop: 1000, mutative avg spend 8.468 ms
loop: 1000, structura avg spend 17.328 ms
loop: 1000, pstr avg spend 10.449 ms
loop: 1000, native avg spend 0.02 ms
structura 和 immer 在此场景表现还不如硬克隆pstr,limu表现最好,mutative次之。
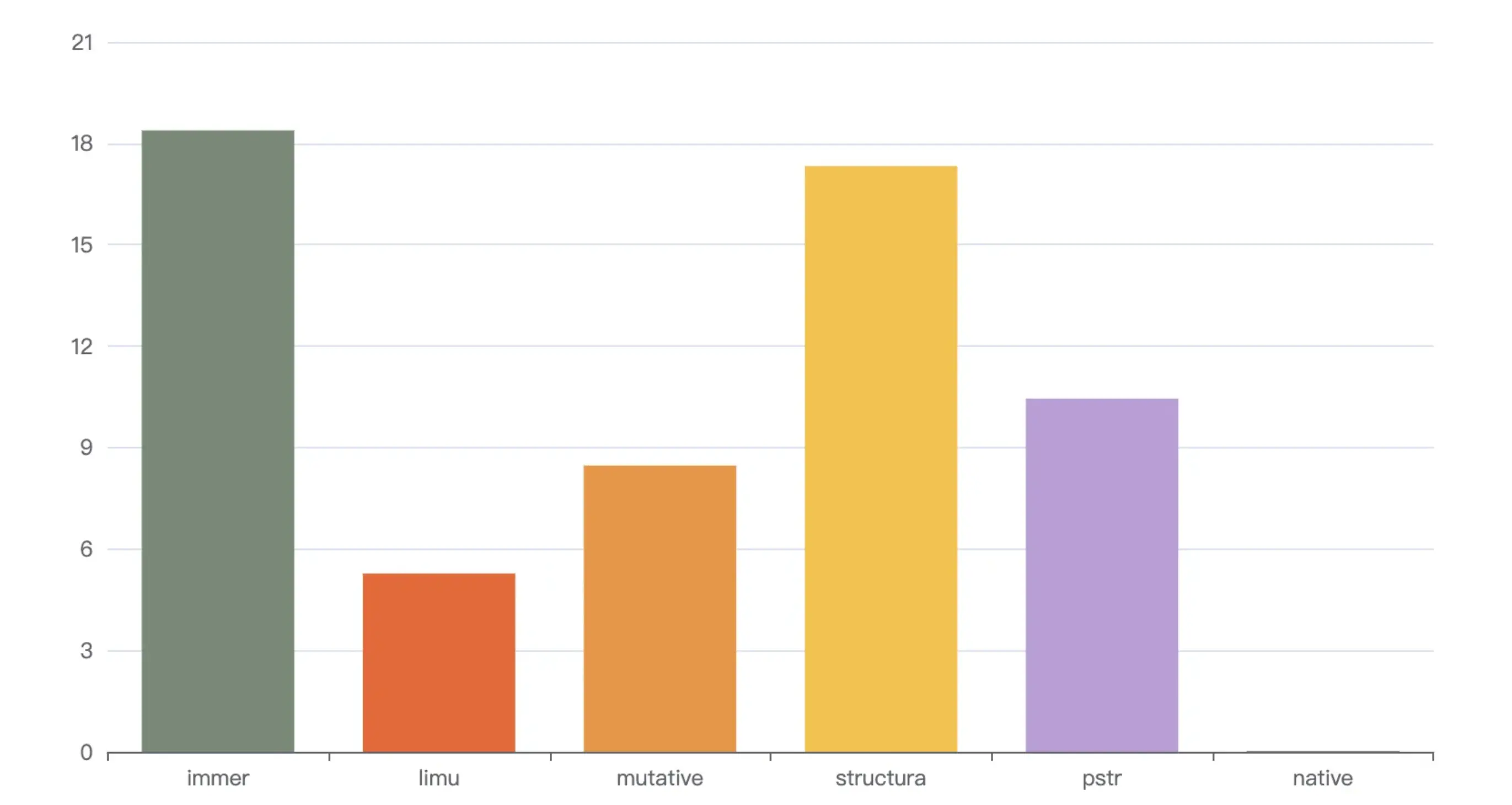
执行npm run s4,表示操作草稿数组,结果冻结,结果如下
loop: 1000, immer avg spend 58.359 ms
loop: 1000, limu avg spend 26.142 ms
loop: 1000, mutative avg spend 32.264 ms
loop: 1000, structura avg spend 74.851 ms
loop: 1000, pstr avg spend 32.481 ms
loop: 1000, native avg spend 0.481 ms
由于操作了1万长度的数组,时间相对上一组均提升了2到3倍,structura 和 immer 在此场景表现依然不如硬克隆pstr,limu表现最好,mutative次之。
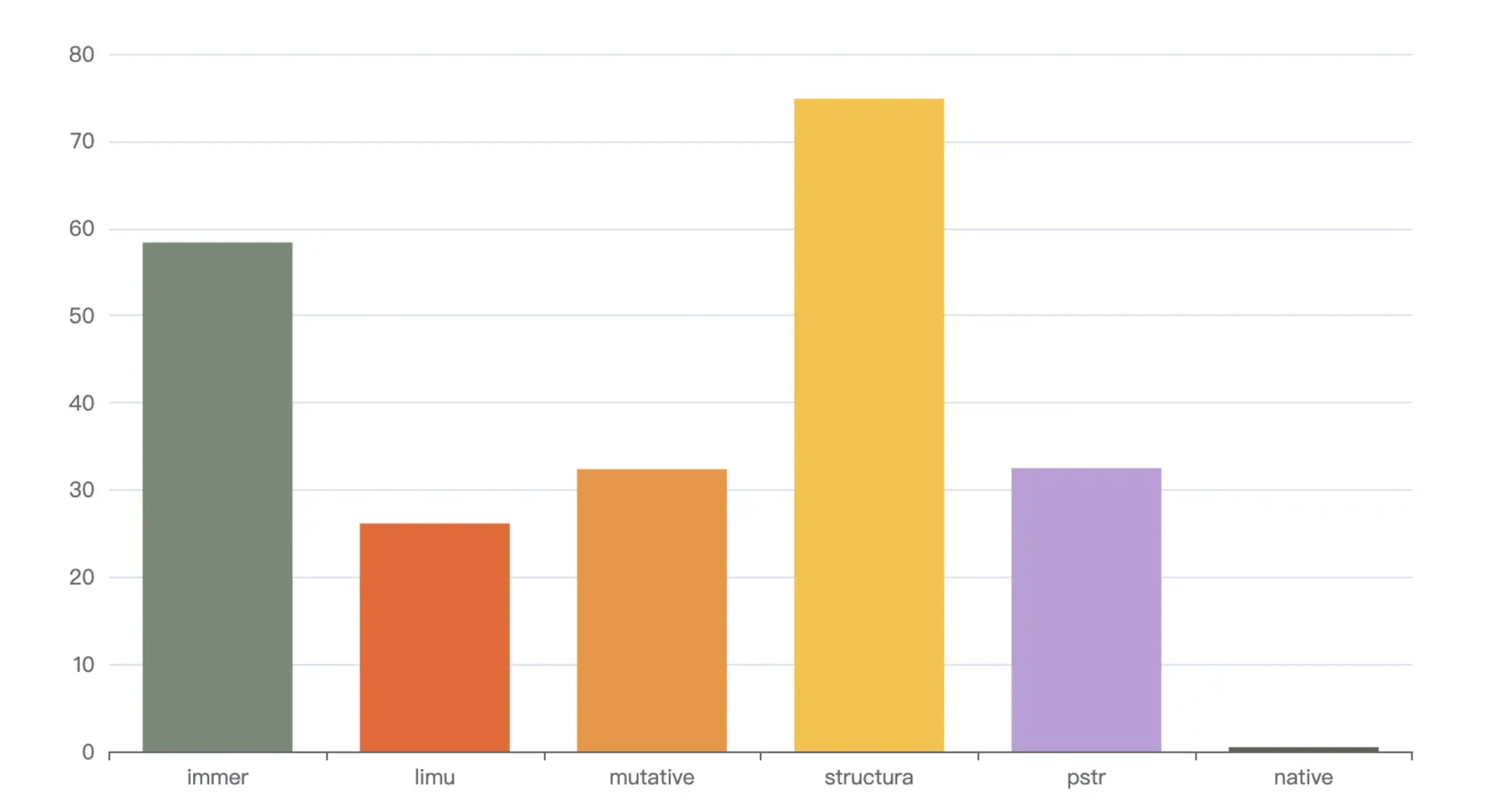
测试结论
经过上述多轮测试得出,不冻结场景下,limu、structura、mutative三者差距不大,均在10倍到30倍之间。
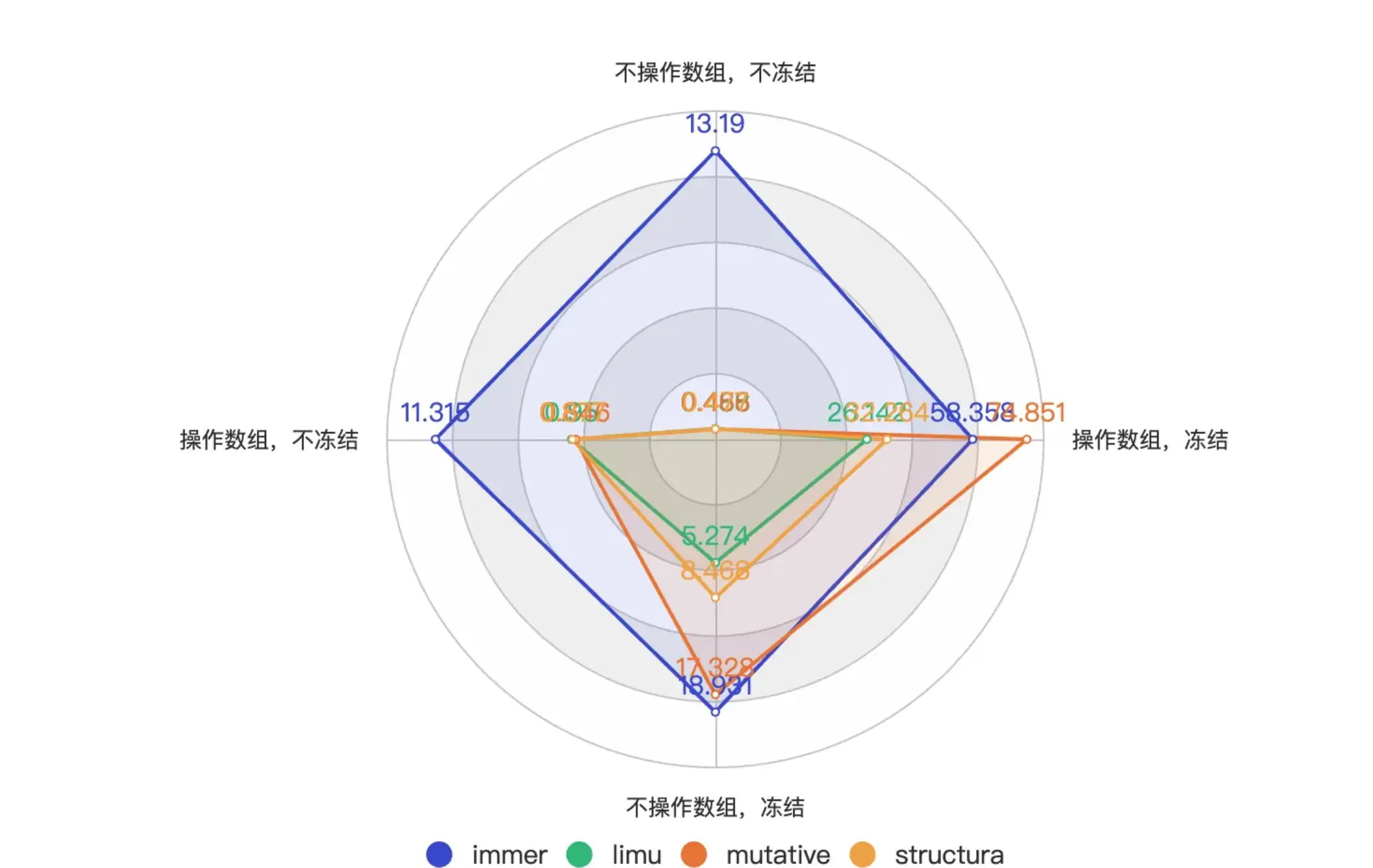
冻结场景下,limu表现最为优异,mutative次之,structura则表现还不如immer,展现为雷达图后性能表现如下
注:面积越小性能越好
结语
经过上述完整的优化细节披露以及测试结果汇总,limu在不冻结各种场景的性能测试结果已和structura、mutative平起平坐,在冻结场景领先structura、mutative1到2倍,现如今可宣称limu到达了不可变数据性能之。
除了性能优异以外,limu的数据是可实时查看的,深度展开后就是json而非Proxy,面向调试非常友好,如对性能有极致追求且不考虑非Proxy环境的兼容,limu将会是你的最佳选择,和immer保持了对等的api设计,如没有用到immer的applyPatches相关api,可实现无感平替。
one more thing
基于limu 打造的helux即将宣发,期望重定义react开发范式,全面提升react应用的DX&UX(开发体验、用户体验),欢迎提前关注与了解。

友链:
❤️ 你的小星星是我们开源最大的精神动力,欢迎关注以下项目:
limu 最快的不可变数据js操作库.
hel-micro 工具链无关的运行时模块联邦sdk.
helux 集atom、signal、依赖追踪为一体,支持细粒度响应更新的状态引擎
原文链接:https://juejin.cn/post/7320437823332450304 作者:幻魂