

node内置模块就相当于js数组中的那些方法,都是官方定义好的方法。node既然赋予了js后端的能力,那么它就可以和操作系统打交道,获取操作系统的信息,对文件资源实现增删改,其实node本质就是C/C++开发的,node并不是一门语言,它只是js代码的解析器,node就相当于浏览器的执行引擎,node对js进行解析,将其解析成可以操作得了服务器的代码,node封装了许多模块,js代码可以调动这些node模块
本期就介绍一些常用的内置模块,每个模块就相当于一个对象,会有很多属性
node中文网:nodejs.cn/api/v18/
global
node中的global就相当于浏览器的window,其实二者都是globalThis,也就是this。
console.log(globalThis === window) // 浏览器
console.log(globalThis === global) // node
因此你可以直接对这个对象挂属性,比如🌰
global.userInfo = {
name: '小黑子',
age: 18
}
console.log(Object.getOwnPropertyNames(global))
getOwnPropertyNames
这个方法可以查看一个对象的所有属性,之前讲深浅拷贝的时候提到过Obj.hasOwnProperty(key),这个东西是判断key值为对象的显示具有还是隐式具有
__filename
当前文件的绝对路径,只在CommonJS语法才有
__dirname
当前文件夹的绝对路径,只在CommonJS语法才有
process
进程,里面包含许多属性
process.argv
获取你输入的指令
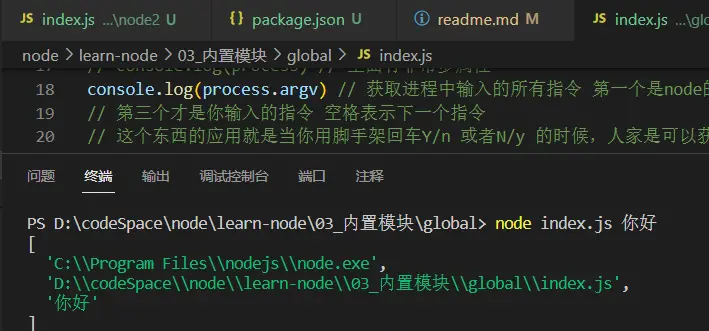

输出结果中第一个是node的路径,第二个是当前脚本的绝对路径,第三个才是输入的指令,当然你可以以空格的方式输入更多的指令,他都会给你输出出来,所以我们可以通过这个指令获取用户在终端输入的值,脚手架安装的时候会用到这个
process.cwd()
获取当前工作目录的绝对路径,类似dirname
所谓工作目录就是当前项目的根目录
process.env
NODE_ENV=production node index.js
这个操作可以用来做环境变量,开发环境如何,生产环境如何。打包项目的时候你不清楚现在是开发还是生产环境,production代表生产环境,dev代表开发环境,你可以在生产环境过滤掉无用的console.log调试
process.pid
代表进程的id
process.platform
读取当前的操作系统
process.arch
读取cpu
process.stdout
标准的输出流,可以进行数据的写入
process.stdout.write('hello')
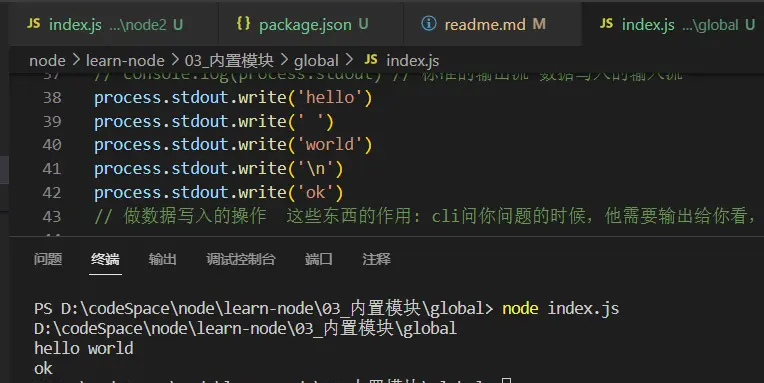
终端给你展示效果,脚手架问题展现给用户看就是用的这些交互操作
process.stdin
读取输入的数据流,你可以用这个监听一个data事件,获取用户输入的内容
process.stdout.write('Are you sure you want to do?')
process.stdin.on('data', (data) => {
console.log(`用户输入了: ${data}`)
})
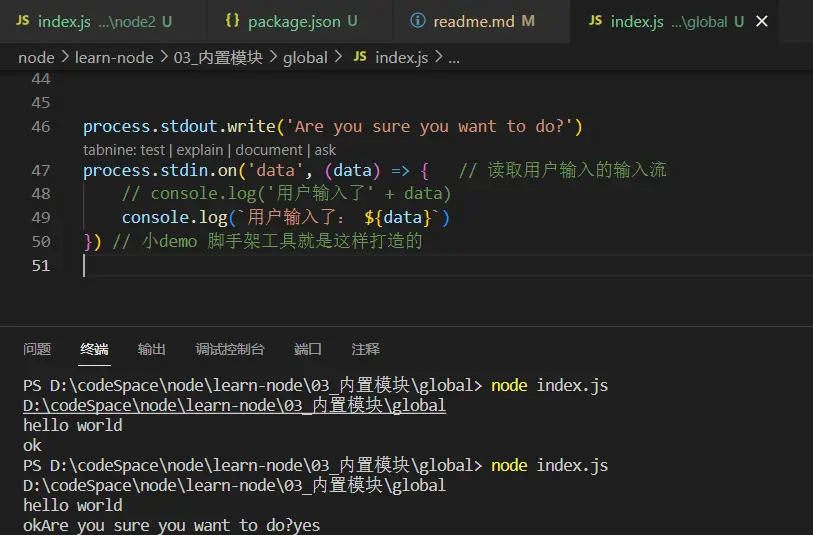
回答脚手架问题的时候就是用这个功能,读取到用户输入的内容
path
上期文章就介绍了node的模块化语法是CommonJS,下面的模块都需要先进行引入
const path = require('path') // path理解为某某路径下的一个东西,node是自带的
console.log(path) // path下有很多方法,都可以和操作系统交互
path.join()
将多个路径进行合并拼接
console.log(path.join('a', 'b', 'c')) // a\b\c
windows操作系统是反斜杠,Mac操作系统是斜杠进行拼接的
console.log(path.join(process.cwd(), 'model', 'index')) // d:\codeSpace\model\index
path.resolve()
直接拼接到当前工作区的绝对路径
console.log(path.resolve('a', 'b', 'c')) // d:\codeSpace\a\b\c
path.dirname()
返回路径中最终指向的路径的当前路径
console.log(path.dirname(process.cwd())) // d:\
console.log(path.dirname('a/b/c')) // a/b
path.basename()
返回路径中的文件名,第二个参数为删除的后缀
console.log(path.basename('a/b/c.js')) // c.js Mac需要'/a/b/c.js',多一个斜杠
返回当前带有后缀的文件名
console.log(path.basename(__filename)) // index.js
返回当前文件名
console.log(path.basename(__filename, '.js')) // index
path.extname()
获取文件的后缀或扩展名
console.log(path.extname(__filename)) // .js
一般上传文件限制文件格式就可以用这个方法
path.normalize()
规范路径
console.log(path.normalize('/a/\b/c.j')) // a\b\c.j
windows系统依旧是反斜杠。。
path.parse()
解析出当前文件的根目录,文件夹绝对目录,带有后缀的文件名,扩展名以及文件名
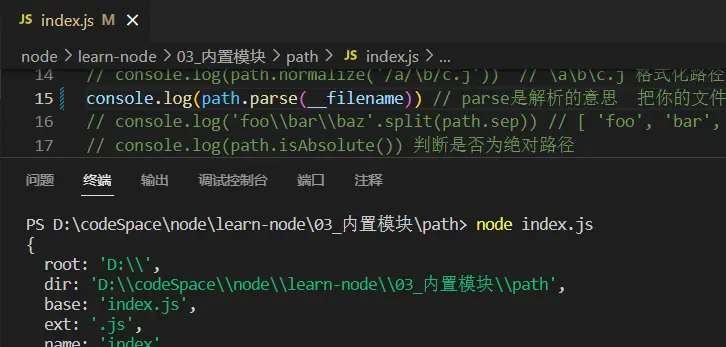
path.sep
就是代表斜杠,不过window是反斜杠,这是个属性
console.log('foo\bar\baz'.split(path.sep)) // [ 'foo', 'bar', 'baz' ]
这里写成两个\,是因为系统会把\b也读成一个值
path.isAbsolute()
判断路径是否为绝对路径
console.log(path.isAbsolute('D:\codeSpace\node\learn-node\03_内置模块\path')) // true
fs文件系统(File System)
操作文件或文件夹
它支持同步,异步两种调用方式,默认情况下一定是异步,因为它耗时执行
同样需要模块化引入
const fs = require('fs');
fs.readFileSync()
这是同步读取文件内容,sync表示同步,async表示异步
const syncData = fs.readFileSync('./data.txt', 'utf8')
console.log(syncData)
你也可以写成
const syncData = fs.readFileSync('./data.txt', {encoding: 'utf8'})
文本编码格式就是utf8,base64是图片编码格式,默认不知明编码格式打印就是一个buffer流。buffer也有length,toString()属性。还可以通过Buffer.isBuffer()判断是否为buffer流
fs.readdirSync()
读取文件夹,以数组的形式输出其子文件名
const info = fs.readdirSync('./test')
console.log(info) // [ 'avatar.jpg' ]
所以这个方法可以读取文件夹里所有的文件名
fs.mkdirSync()
创建一个文件夹,创建多层需要用上第二个参数,并给true
fs.mkdirSync('./test-dir/data/list', {recursive: true})
fs.rmdirSync()
删除一个文件夹,删除多层同样需要用上第二个参数,并给true
fs.rmdirSync('./test-dir', {recursive: true})
fs.readFile()
这里没有sync,读文件I/O流本身就是一个异步操作,所以一定是回调才能打印,回调中有两个参数err和res,读不到就是err,读到了就是res
透析js事件循环机制event-loop【拿捏面试】 – 掘金 (juejin.cn)这期文章讲解宏微任务时提到过
I/O流是个宏任务异步操作
const syncData = fs.readFile('./data.txt', {encoding: 'utf8'}, (err, res) => {
if(!err) {
console.log(res)
}
});
fs.promiss.readFile()
同样是读取文件,这个方法封装成了promiss,所以后面.then就可以解决异步
fs.promises.readFile('./data.txt', 'utf8').then(res => {
console.log(res)
})
当然官方给你另一种引入,这样也可以
const fs = require('fs/promises')
fs.readFile('./data.txt', {encoding: 'utf8'}).then(res => {
console.log(res)
})
fs.writeFileSync()
写入文件,第一个参数是文件url,第二个参数是文件中的内容。Sync是将异步变成同步
fs.writeFileSync('./target.txt', '大黑子')
当前目录就会生成target.txt文件,里面还会有你写入的内容
当然你也可以结合前面的读取文件,读完之后将文件写入其他路径
const img = fs.readFileSync('./avatar.jpg')
fs.writeFileSync('./pic/avatar2.jpg', img)
这里操作的img并没有指明编码格式,因此一定是buffer流格式。其实复制图片也就是复制图片的buffer流
fs.statSync()
读取文件的statement,各种信息,比如mtime创建时间,ctime更改时间,不过这个时间是国际标准时间
浏览器缓存就是用得这个手段,比如一个大厂的服务器肯定在全国各个地方有分服务器,分服务器需要和总部服务器保持同步,就需要查看文件是否更改,更改就需要进行同步
fs.statSync('./avatar.jpg')
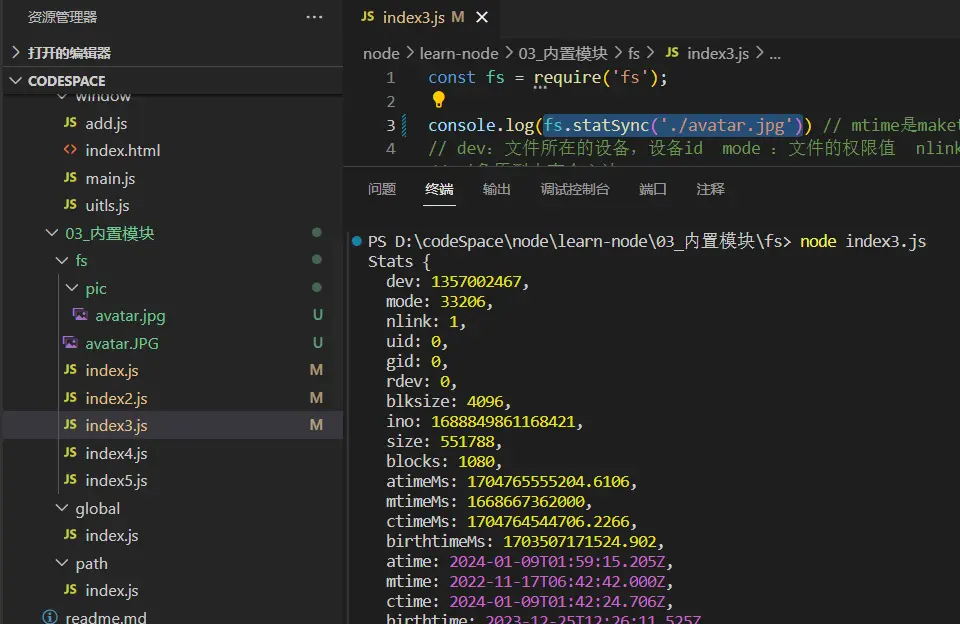
dev: 设备id;mode:文件的权限;nlink:文件总共有几个路径可以访问到它的地址;uid:用户所属的id;gid: group id文件所属哪个分组的……你还可以放到浏览器去看看它的原型,里面有个isDirectory()方法判断文件是否为文件夹,isFile()判断是否为文件
const info = fs.statSync('./pic')
console.log(info.isDirectory()) // true
console.log(info.isFile()) // false
fs.appendFileSync()
给指定文件添加内容,wirteFileSync会覆盖原有文件的内容
fs.appendFileSync('./data.txt', '\n大黑子')

fs.renameSync()
重命名文件,你也可以重名它的后缀
fs.renameSync('./data.txt', './data.md')
你也可以利用这个移动文件路径,不同上面的读取写入,读取写入是复制
fs.renameSync('./data.md', './pic/data.md')
fs.unlinkSync()
删除文件
fs.unlinkSync('./pic/data.md')
fs.rmSync()
这个方法还可以删除目录
fs.rmSync('pic', {recursive: true})
第二个参数表示是否删除文件夹中所有的文件
fs.watch()
监听文件夹下文件的变更,第三个参数是个回调,函数第一个参数是变更类型,第二个参数是变更的文件名
fs.watch('./', { recursive: true }, (eventType, filename) => {
console.log(`当前文件夹下${filename}文件变更为: ${eventType}`)
})
这个东西就可以去应用到报警器上,比如烟雾报警器,他会生成日志,fs.watch有变更就可以实时传给前端
util实用工具
util模块会提供一些辅助性的函数
记得先引入这个模块
const util = require('util');
util.inspcet()
将对象转成成字符串,JSON.stringify()也可以,但是它转成的字符串key是双引号引起来的
inspect还会有第二个参数,展开的深度
const obj = {
a: 1,
b: {
c: 2,
d: [3, 4, 5],
e: () => {
console.log(6)
}
}
}
console.log(JSON.stringify(obj)) // {"a":1,"b":{"c":2,"d":[3,4,5]}}
console.log(util.inspect(obj)) // { a: 1, b: { c: 2, d: [ 3, 4, 5 ], e: [Function: e] } }
console.log(util.inspect(obj, {depth: 1})) // { a: 1, b: { c: 2, d: [Array], e: [Function: e] } }
util.format()
以你想要的格式格式化字符串,第一个参数是占位符以及你想要的格式
console.log(util.format('%s:%s', 'foo', 'bar')) // foo:bar
console.log(util.format('%d + %d = %d', 1, 1, 2)) // 1 + 1 = 2
console.log(util.format('hello %j', {name: 'world'})) // hello {"name":"world"}
util.types.isArrayBuffer()
判断数组流类型,util里面判断数据类型比原生js多得多,大家可以去官方文档看看,这里就放两个来展示
console.log(util.types.isArrayBuffer([])) // false
console.log(util.types.isDate(new Date())) // true
https
这是node最常用的内置模块,http和https两种,都是用于创建http服务器,后端开发必用模块,后端向前端应答请求
const https = require('https')
https.get()
相当于前端的ajax,这里是后端发请求,很多时候后端的数据也是请求过来的,请求成功会走一个回调,回调参数是请求成功的相应,然后用on去监听data事件
直接拿到数据会不完整,因此需要进行一个数据的积累拼接,最后用end事件触发监听结束,这个时候的数据才是完整的
https.get('https://api.juejin.cn/interact_api/v1/message/count?aid=2608&uuid=&spider=0', (res) => { // 掘金随便找的接口地址,拿不到数据
let content = ''
res.on('data', (chunk) => {
content += chunk
})
res.on('end', () => {
console.log(content)
})
})
当然你可以换个写法,第二个参数写成请求头,并且给他设置成json类型的数据,如果监听写在里面就用data,写在外面就用response
const req = https.get('https://api.juejin.cn/interact_api/v1/message/count?aid=2608&uuid=&spider=0', {
headers: {
'Content-Type': 'application/json'
}
})
req.on('response', res => {
let content = ''
res.on('data', (chunk) => {
content += chunk
})
res.on('end', () => {
console.log(content)
})
})
不过Content-Type是给后端看的,这是我们希望人家返回给我们的数据格式,人家也有可能不满足你的请求,就相当于一个口头交流
http还支持post,put,delete等,因为这些不常用,所以官方文档将这些方法都写成了request请求
https.request()
const https = require('https');
const url = new URL('https://api.juejin.cn/interact_api/v1/message/count?aid=2608&uuid=&spider=0')
const req = https.request(
{
method: 'POST',
port: 80, // 后端只有启动了服务才有端口号
hostname: url.hostname,
path: url.pathname + url.searchParams,
},
res => {
let content = ''
res.on('data', (chunk) => {
content += chunk
})
res.on('end', () => {
console.log(content)
})
}
)
req.end()
通常我们不会用get,request发请求,写法麻烦,一般我们会用axios,fetch发请求,用fetch得话,node版本必须大于等于18
fetch()
当然这是原生js的东西,但是node发请求的两种我们一般不用,这里顺带过一遍
fetch('https://api.juejin.cn/interact_api/v1/message/count?aid=2608&uuid=&spider=0')
.then(res => res.json())
.then(data => {
console.log(data)
})
axios也非常好用,不仅支持window,还支持node。
axios
安装
npm init -y // 生成项目说明书package.json,里面记录了依赖
npm i axios // 生成node_modules
axios官方自己定义了一个get方法,它比fetch更强大。fetch只能在node中使用
const axios = require('axios')
axios.get('https://api.juejin.cn/interact_api/v1/message/count?aid=2608&uuid=&spider=0')
.then(res => {
console.log(res.data)
})
http
http方法比https更多
http.createServer()
创建一个服务,接受一个回调函数,回调函数有两个参数,分别为前端的请求和后端的响应
const http = require('http')
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/html')
console.log(req.url, req.method) // fafa GET fafa是自己随便拼接在3000后面的
res.end('<h1>Hello World</h1>') // 向前端输出
})
server.listen(3000, () => {
console.log('listening on port 3000')
})
这里模拟了一个后端项目,非常简短,功能就是向前端输出一段html代码
运行这个后端后,去访问localhost:3000
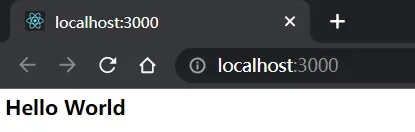
我们检查查看网络,刷新页面
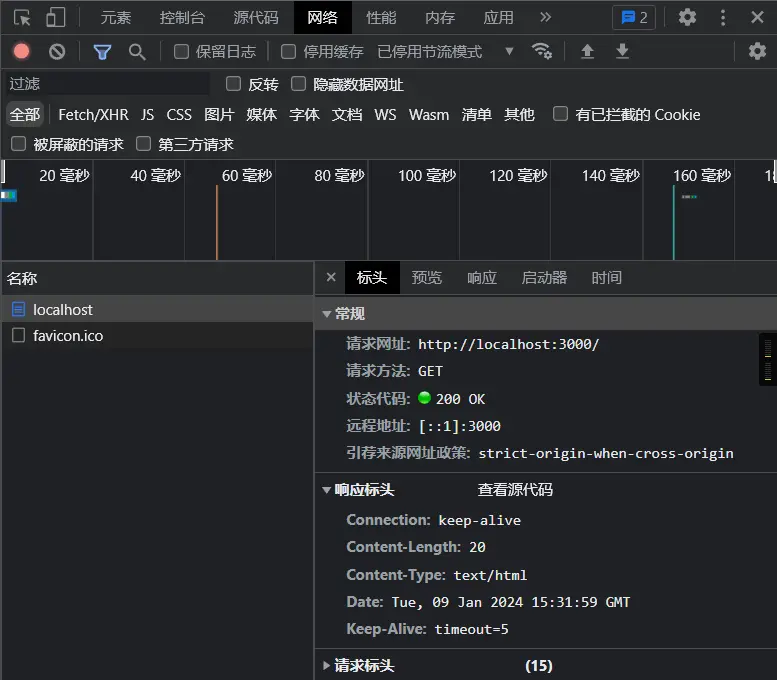
这里可以看到接口,请求头中有请求地址,请求方式,状态码……,后端响应的响应头,里面有自己设置的内容类型,Content-Type就是给浏览器看的,以何种方式去解析响应体,如果后端那里的格式设成application/json。那么页面就是直接输出html代码。状态码是上面后端写入的
favicon是浏览器自带的小图标请求,title那里的图标
但是这里的后端代码没有指名具体的url,所以url后面随便接东西都可以拿到后端的数据。所以我们肯定有必要去区分,首页拿到首页的数据,详情页拿到详情页的数据。req前端的请求是整个请求体,里面常用的属性就是req.url前端向哪个地址发请求,req.method前端以何种方式发请求
所以这里我们可以实现访问具体的路径去输出内容,也就是加个if判断
const server = http.createServer((req, res) => {
res.statusCode = 201
res.setHeader('Content-Type', 'text/html')
const { url } = req
if (url === '/home') {
res.end('<h1>home page</h1>') // 向前端输出
} else if (url === '/detail') {
res.end('<h1>detail page</h1>')
} else {
res.end('<h1>not found</h1>')
}
})
const { url } = req是对象的解构,这样url就是req.url了,if体内数据正常来讲就是后端向数据库拿到的数据
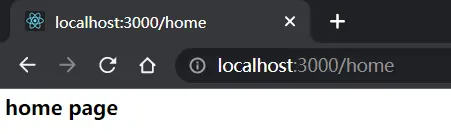
但是事实上有时候我们需要通过url传参,home页地址中接入参数?id=xxx。这个时候就需要解析if判断的地址
通过URL实例对象的searchParams方法
new URL(url, 'http://localhost').searchParams
这个方法返回的数据虽是个对象,但是key是字符串,因此我们需要用上Object.fromEntries()方法去去掉key的引号。
对于带参数的url,比如home页,只要url包含home或者以home开头就让后端发送home的数据
const query = Object.fromEntries(new URL(url, 'http://localhost').searchParams ) // URLSearchParams { 'id' => '123' } => { id: '123' }
if (url.startsWith('/home')) {
res.end('<h1>home page</h1>') // 向前端输出
} else if (url.startsWith('/detail')) {
res.end('<h1>detail page</h1>')
} else {
res.end('<h1>not found</h1>')
}
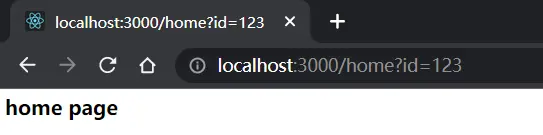
这样就解决了url传参输出内容失败的问题了,既然这里的query是个对象,里面有id这个属性,因此我们还可以进一步在if里面通过query.id去判断不同的用户id输入不同的home内容
如果项目接口太多,if-else也会非常多,因此这个写法比较low
在浏览器中输入url,浏览器帮我们把数据自动请求回来,这是浏览器自带的get请求。如果后端定义的是post请求,浏览器就无法就测试了,这个时候我们可以用postman这个应用来测了
我们换个栗子,这里我写了个json数据文件,所以if体内输出的数据就是后端读到文件内容
const http = require('http');
const fs = require('fs')
const server = http.createServer((req, res) => {
// res.setHeader('Content-Type', 'application/json', 'charset=utf8') 注释这个是为了安利一个浏览器插件
if (req.url.startsWith('/movie')) {
const data = fs.readFileSync('./data.json', 'utf8')
res.end(data)
}
})
server.listen(3000, () => {
console.log('listening on 3000 port')
})
这样,我们访问movie这个url就可以拿到后端传过来的数据了,因为后端没有定义数据类型,所以网页的中文会乱码,这里安利一个谷歌插件charset
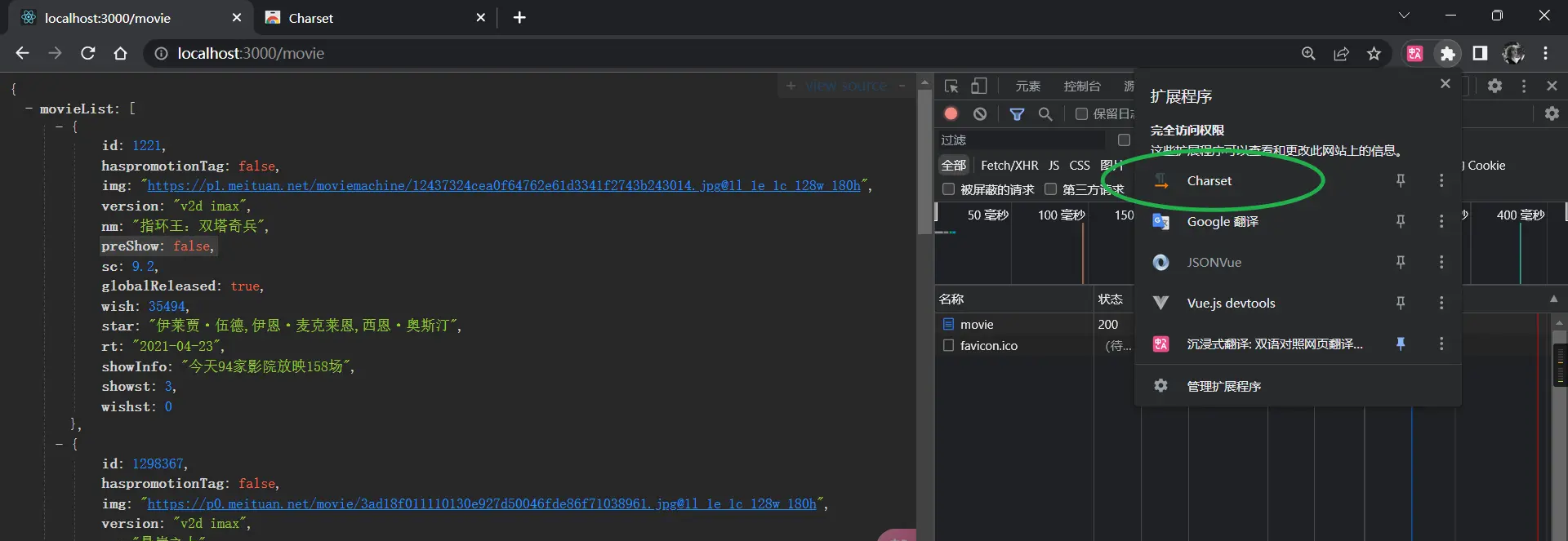
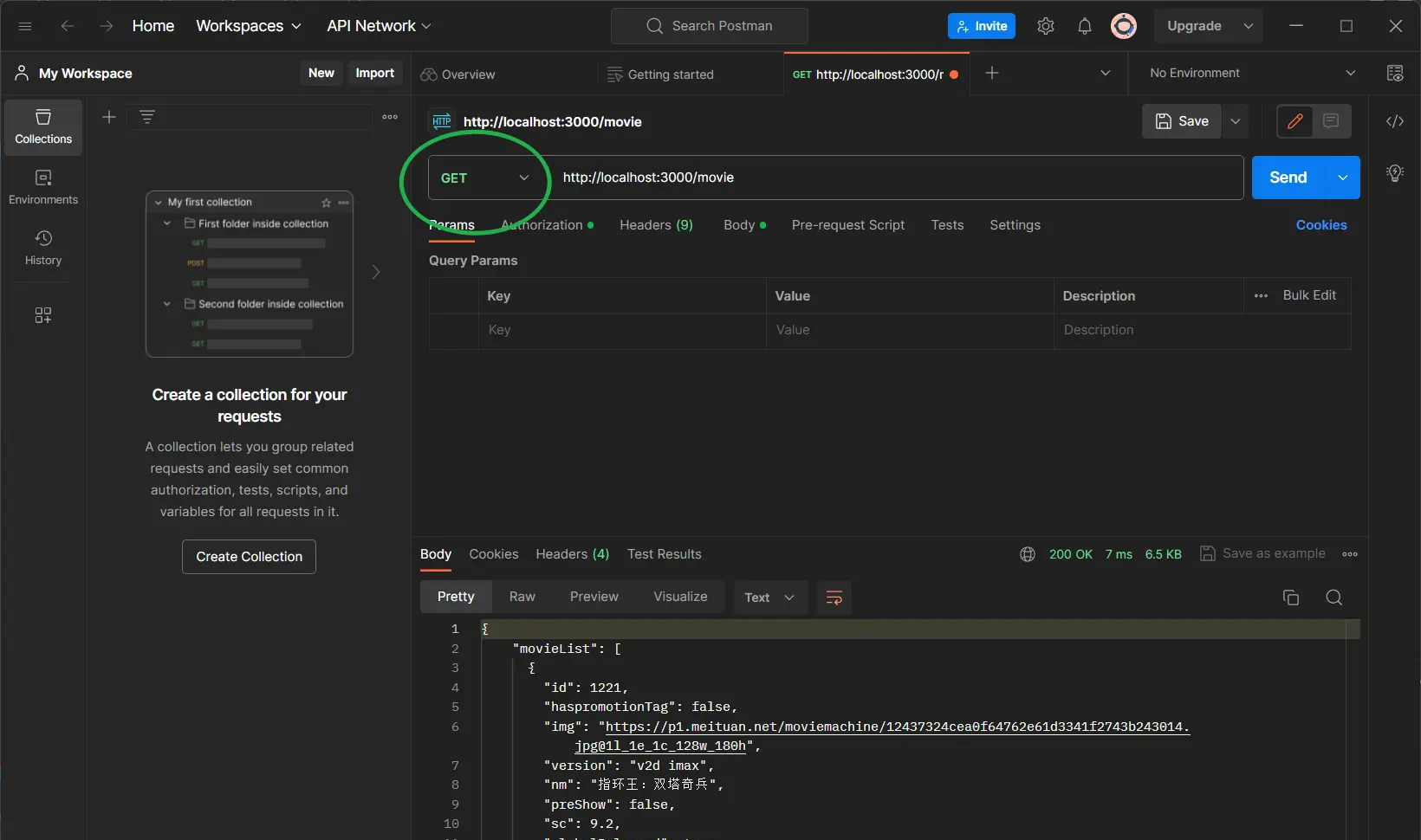
当然你也可以用postman去测试,你可以选择请求方式,这里因为没有后端没有限定请求方式,所以任意请求方式访问movie路径都可以拿到数据
child_process
子进程模块是node中的核心模块,js是单线程,但是可以通过创建子进程实现多个任务的并行处理
单线程是无法同时执行多个任务的,js执行碰到异步会先挂起,等到同步执行完毕再去执行异步,如果是多线程那么就是碰到异步代码会再开一个进程去执行异步。node可以实现在js的单一进程中创建子进程去实现多个任务的并行处理
所以处理请求高并发是node的一个优点,单进程处理同一时间发过来的成千上万的请求会很慢。
子进程你只需要着重掌握下面介绍这几个方法
同样记得先引入或者模块
const ChildProcess = require('child_process')
spawn和spawnSync
这个方法用于新建一个子进程去执行指令,接收的参数就是指令,比如Mac下的cwd就是拿到当前文件夹的绝对路径
const { spawn, spawnSync } = ChildProcess
const pwd = spawnSync('pwd')
console.log(pwd.stdout.toString())
同样分为同步和异步
下面再来看看node父子进程通讯
fork
这里以fork.js作为父进程,child.js作为子进程
fork.js
const fork = require('child_process').fork;
const child = fork('child.js') // 使用fork方法创建一个子进程
child.on('message', (msg) => { // 监听子进程发来的消息
console.log(`来自子进程的消息: ${msg}`);
})
child.send('hello from parent') // 向子进程发送一条消息
child.js
process.on('message', (msg) => {
console.log(`来自父进程的消息: ${msg}`);
process.send('hello from child') // 两份js实现数据传输,node父子通讯
})
运行node fork.js
来自父进程的消息: hello from parent
来自子进程的消息: hello from child
父进程先向子进程发消息,子进程再接收消息,并且向父进程返回这个消息,父进程又监听到了这个消息并且打印出来了。
最后
这些模块里面的各种方法,你肯定记不住,但是你需要先熟悉一遍,不记得没关系,要用的时候直接去文档中查找即可,过一遍至少清楚哪些功能会在哪个模块中出现,方便查找
另外有不懂之处欢迎在评论区留言,如果觉得文章对你学习有所帮助,还请”点赞+评论+收藏“一键三连,感谢支持!
本次学习代码已上传至本人GitHub学习仓库:github.com/DolphinFeng…
原文链接:https://juejin.cn/post/7322310004873379840 作者:Dolphin_海豚