

本节来聊聊前端分片上传、断点续传、秒传的功能实现。
写了个小案例:前端是React;后端是学了一天半的Nest.js😅,写的可能不是很好,实际感觉难点在后端,很多文件读写操作。
- 前端:Ys-OoO/react-music-recommendation (github.com) 具体分片功能实现在
src/utils/sliceUpload - 后端:Ys-OoO/nest-music-recommendation (github.com) 具体分片功能实现在
src/music/music.service.ts
这个小案例中包括了jwt认证、文件上传下载功能等,也实现了本节的重点分片上传、断点续传、秒传功能。
前言
如标题所见,本文要讲的是大文件的分片上传、断点续传和秒传三个功能,而实际上断点续传和秒传都是基于分片上传扩展的功能。
- 分片上传原理:客户端将选择的文件进行切分,每一个分片都单独发送请求到服务端;
- 断点续传 & 秒传原理:客户端发送请求询问服务端某文件的上传状态,服务端响应该文件已上传分片,客户端再将未上传分片上传即可;
- 如果没有需要上传的分片就是秒传;
- 如果有需要上传的分片就是断点续传;
- 每个文件要有自己唯一的标识,这个标识就是将整个文件进行MD5加密,这是一个Hash算法,将加密后的Hash值作为文件的唯一标识;
- 使用
spark-md5第三方工具库
- 使用
前端整体流程
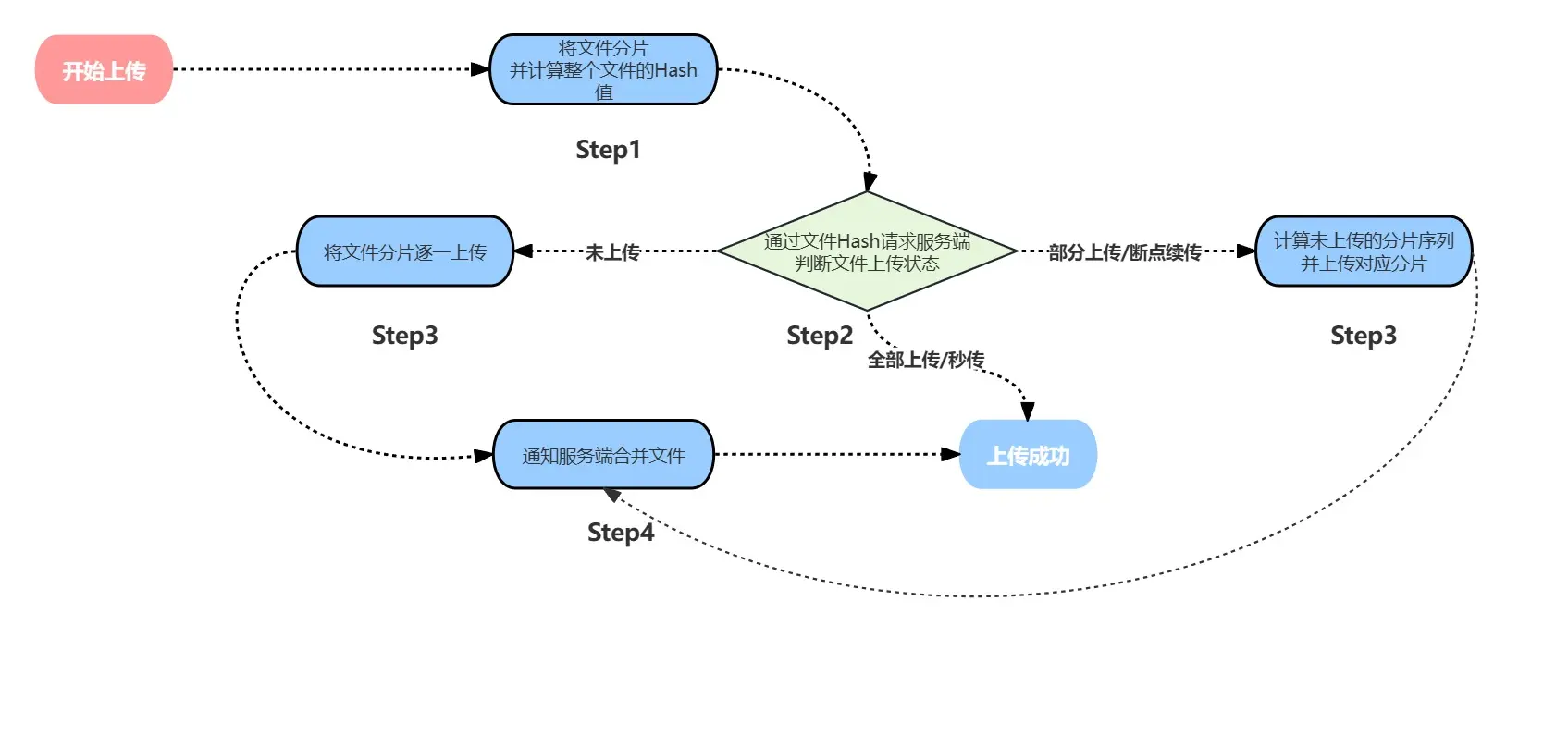
如下图所示是前端分片上传的整体流程:
- 第一步:将文件进行分片,并计算其Hash值(文件的唯一标识)
- 第二步:发送请求,询问服务端文件的上传状态
- 第三步:根据文件上传状态进行后续上传
- 文件已经上传过了
- 结束 — 秒传功能
- 文件存在,但分片不完整
- 将未上传的分片进行上传 — 断点续传功能
- 文件不存在
- 将所有分片上传
- 文件已经上传过了
- 第四步:文件分片全部上传后,发送请求通知服务端合并文件分片

前端详细流程
接下来就是最关键的实现部分了
分片上传入口
当我们选择一个要上传的文件后,点击上传触发上传回调函数,上传的回调函数需要如下参数:
/**
* @param {File} targetFile 目标上传文件
* @param {number} baseChunkSize 上传分块大小,单位Mb
* @param {string} uploadUrl 上传文件的后端接口地址
* @param {string} vertifyUrl 验证文件上传的接口地址
* @param {string} mergeUrl 请求进行文件合并的接口地址
* @param {Function} progress_cb 更新上传进度的回调函数
* @returns {Promise}
*/
接下来先给出大致代码思路然后逐一完善:
async function uploadFile(file, baseChunkSize, uploadUrl, vertifyUrl, mergeUrl, progress_cb) {
1. 将文件进行分片并计算Hash值
得到 allChunkList---所有分片 fileHash---文件的hash值
2. 通过fileHash请求服务端,判断文件上传状态
得到 neededFileList---待上传文件分片
3. 同步上传进度,针对不同文件上传状态调用 progress_cb
4. 发送上传请求
5. 发送文件合并请求
}
文件分片 & Hash计算
/**
* 将目标文件分片 并 计算文件Hash
* @param {File} targetFile 目标上传文件
* @param {number} baseChunkSize 上传分块大小,单位Mb
* @returns {chunkList:ArrayBuffer,fileHash:string}
*/
async function sliceFile(targetFile, baseChunkSize = 1) {
return new Promise((resolve, reject) => {
//初始化分片方法,兼容问题
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
//分片大小 baseChunkSize Mb
let chunkSize = baseChunkSize * 1024 * 1024;
//分片数
let targetChunkCount = targetFile && Math.ceil(targetFile.size / chunkSize);
//当前已执行分片数
let currentChunkCount = 0;
//当前以收集的分片
let chunkList = [];
//创建sparkMD5对象
let spark = new SparkMD5.ArrayBuffer();
//创建文件读取对象
let fileReader = new FileReader();
let fileHash = null;
//FilerReader onload事件
fileReader.onload = (e) => {
//当前读取的分块结果 ArrayBuffer
const curChunk = e.target.result;
//将当前分块追加到spark对象中
spark.append(curChunk);
currentChunkCount++;
chunkList.push(curChunk);
//判断分块是否全部读取成功
if (currentChunkCount >= targetChunkCount) {
//全部读取,获取文件hash
fileHash = spark.end();
resolve({ chunkList, fileHash });
} else {
loadNext();
}
};
//FilerReader onerror事件
fileReader.onerror = () => {
reject(null);
};
//读取下一个分块
const loadNext = () => {
//计算分片的起始位置和终止位置
const start = chunkSize * currentChunkCount;
let end = start + chunkSize;
if (end > targetFile.size) {
end = targetFile.size;
}
//读取文件,触发onLoad
fileReader.readAsArrayBuffer(blobSlice.call(targetFile, start, end));
};
loadNext();
});
}
分片上传入口完善
async function uploadFile(file, baseChunkSize, uploadUrl, vertifyUrl, mergeUrl, progress_cb) {
const { chunkList, fileHash } = await sliceFile(file, baseChunkSize);
//所有分片 ArrayBuffer[]
let allChunkList = chunkList;
//需要上传的分片序列 number[]
let neededChunkList = [];
//上传进度
let progress = 0;
//发送请求,获取文件上传状态
if (vertifyUrl) {
const { data } = await requestInstance.post(vertifyUrl, {
fileHash,
totalCount: allChunkList.length,
extname: '.' + file.name.split('.').pop(),
});
const { neededFileList, message } = data;
if (message) console.info(message);
//无待上传文件,秒传
if (!neededFileList.length) {
progress_cb(100);
return;
}
//部分上传成功,更新unUploadChunkList
neededChunkList = neededFileList;
}
//同步上传进度,断点续传情况下
progress = ((allChunkList.length - neededChunkList.length) / allChunkList.length) * 100;
//上传
if (allChunkList.length) {
const requestList = allChunkList.map(async (chunk, index) => {
if (neededChunkList.includes(index + 1)) {
const response = await uploadChunk(chunk, index + 1, fileHash, uploadUrl);
//更新进度
progress += Math.ceil(100 / allChunkList.length);
if (progress >= 100) progress = 100;
progress_cb(progress);
return response;
}
});
Promise.all(requestList).then(() => {
//发送请求,通知后端进行合并 //后缀名可通过其他方式获取,这里以.mp4为例
requestInstance.post(mergeUrl, { fileHash, extname: '.mp4' });
});
}
}
在上传时我们调用了uploadChunk()方法,由于我们的请求不仅包含文件,还包含分片索引以及hash值,因此我们的请求体应该是formData,还有一点需要就是此时我们传入的chunk的类型是ArrayBuffer,而formData中文件的类型应该是Blob。 具体代码如下:
async function uploadChunk(chunk, index, fileHash, uploadUrl) {
let formData = new FormData();
//注意这里chunk在之前切片之后未ArrayBuffer,而formData接收的数据类型为 blob|string
formData.append('chunk', new Blob([chunk]));
formData.append('index', index);
formData.append('fileHash', fileHash);
return requestInstance.post(uploadUrl, formData);
}
前后端代码流程一览
可能你看完前面还是不是很了解分片上传到底是如何工作的,这里我先给出一个示例,方便你更好的理解文件在后端是怎么变化的;
示例:假设此时我们上传一个10Mb的文件,分片大小为5MB,那么前端将传输两个分片;
-
- 服务端接收到一个请求,请求包含分片文件,整个文件的hash,以及分片的索引
-
- 然后服务端将会创建一个文件夹,文件夹名为hash值;
-
- 然后将分片命名为
chunk-文件索引保存在文件夹中;
- 然后将分片命名为
- 上述三个步骤就是我们判断文件上传状态的依据,我们只需要知道文件的hash以及文件的总分块数就可以判断了;
现在你是不是清楚多了,实际上前端的逻辑并不复杂,但是整个过程涉及多个请求,这样我们就要搞清楚后端到底干了什么才能更清楚的理解!
现在给出一个代码流程图,你应该能更清楚的了解整个过程了:
优化
至此我们已经实现了文件分片上传、断点续传、秒传的功能,不过还可以优化;
要知道当文件非常大的时候,我们计算其Hash值是十分耗时的,为了解决Hash计算耗时问题,我们可以采取以下优化方案:
- 使用
Web Worker,不占用主线程资源,在后台线程中计算; - 不再Hash整个文件,而是采用一些其他策略;
Web Worker
./sliceUpload.js
async function uploadFile(file, baseChunkSize, uploadUrl, vertifyUrl, mergeUrl, progress_cb) {
//创建文件分片Worker
const sliceFileWorker = new Worker(new URL('./sliceFileWorker.js', import.meta.url), { type: 'module' });
//将文件以及分块大小通过postMessage发送给sliceFileWorker线程
sliceFileWorker.postMessage({ targetFile: file, baseChunkSize })、
//分片处理完之后触发onmessage事件
sliceFileWorker.onmessage = async (e) => {
//获取处理结果
const { chunkList, fileHash } = e.data;
//后续代码与之前一样
...
}
}
./sliceFileWorker.js
self.onmessage = async (e) => {
//获取文件以及分块大小传输
const { targetFile, baseChunkSize } = e.data;
//分片并计算Hash
const { chunkList, fileHash } = await sliceFile(targetFile, baseChunkSize);
//将计算结果通过postMessage发送给主线程
self.postMessage({ chunkList, fileHash });
}
async function sliceFile(targetFile, baseChunkSize = 1) {
//与之前一样
...
}
Hash策略
我们不一定非要Hash整个文件,可以采用以下策略:
- 仅Hash文件的第一个分片 + 中间分片的首尾n字节 + 最后一个分片

总结
文件的分片上传功能的注意点:
- 利用
FileReader.onload读取分片,利用spark-md5第三方库对文件进行hash计算 formData类型的请求体中,文件等二进制数据应以Blob类型传输Promise.all中获取请求进度可以使用回调来更新进度;- 后端代码编写时要正确的区分文件和文件夹的区别;
原文链接:https://juejin.cn/post/7324140839780433932 作者:Ys_OoO