

几乎每个现代数字产品都必须包含某种分页 API。该 API 的主要作用是从大表中逐块检索数据,以便您的前端应用程序不需要进行具有巨大负载的 API 调用。较小的有效负载会导致较短的延迟。
其次,分页 API 可以提供更好的用户体验。用户可以逐页查看数据,而不是等待加载整个数据集。这意味着页面加载速度更快,响应时间更短,使用户能够更快地获取并浏览数据。
另外,使用分页 API 还有助于优化资源利用。如果一次性返回所有数据,可能会导致服务器负载过高,增加服务器压力和响应时间。而分页 API 可以根据需要动态地加载数据,使服务器能够更有效地处理请求。
基于偏移量的分页
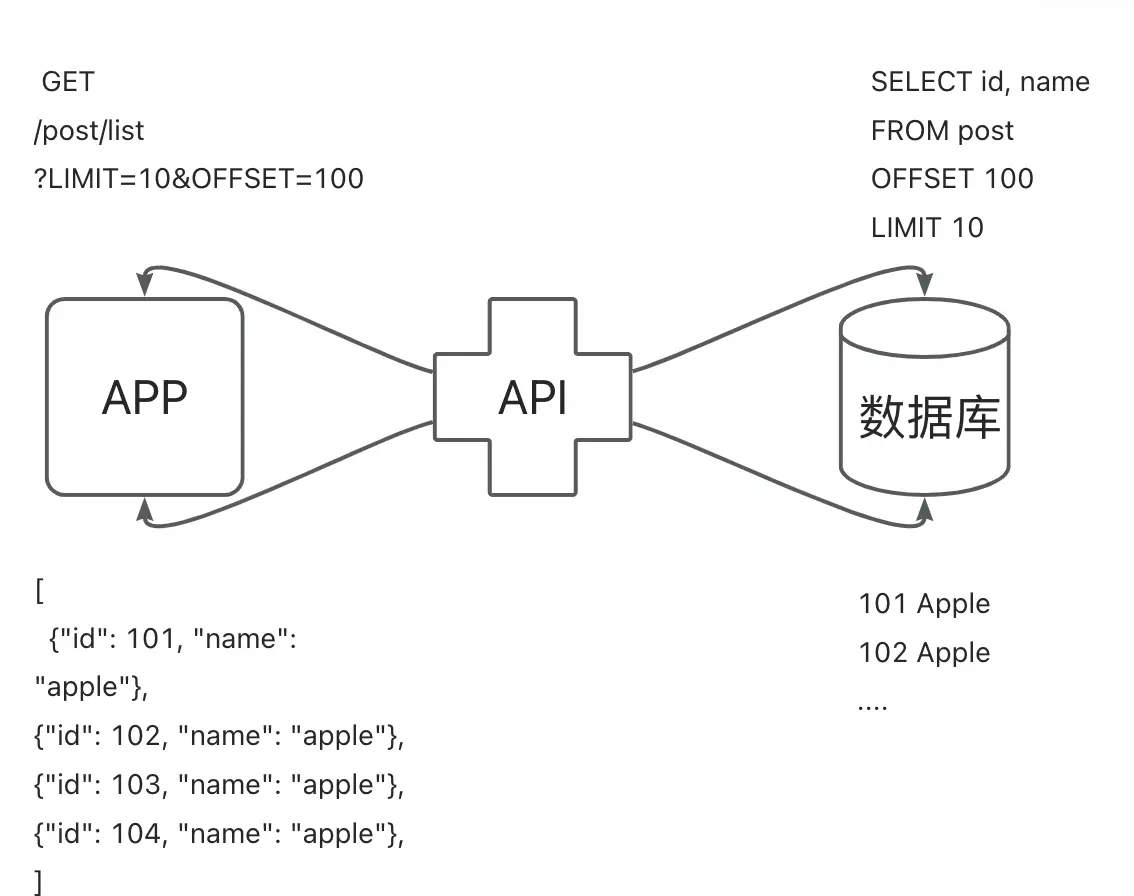

开发分页 API 的常用方法是基于偏移量。在这里,前端在 < 的 第 100 行 行之后请求 10 行 偏移值的增加而增加。 表。当表的尺寸很小时,这是无害的。但是,延迟随着文章条数的增多,就不尽然了。
为什么? 因为数据库(并非所有类型的数据库)实际上为此查询准备了offset+limit 行。因此,当偏移值变大时,数据库必须遍历offset+limit行数。
让我们做一个快速实验。 我准备了一个名为 post 的表,其中包含 mysql 数据库中的 110001 行。它有 3 列;即 id 、 name 和 created_at 。
现在让我们运行这个查询,
数据库响应:
限制(成本=1.74..1.91行=10宽度=27)(实际时间=0.552..0.554行=10循环=1)
->对产品进行顺序扫描(成本=0.00..1909.01行=110001宽度=27)(实际时间=0.541..0.548行=110个循环=1)
计划时间:1.231毫秒
执行时间:0.580 毫秒
在这里,我们可以看到数据库已经处理了110行,然后返回了10行10行 a> 来限制这一点。90000。现在,我们通过将偏移量增加到
限制(成本=1561.90..1562.08行=10宽度=27)(实际时间=10.275..10.277行=10循环=1)
->对产品进行顺序扫描(成本=0.00..1909.01行=110001宽度=27)(实际时间=0.425..6.666行=90010循环=1)
计划时间:1.070毫秒
执行时间:10.302 毫秒
现在,您可以看到它已读取90010行,仅返回10行10.302ms 。!执行时间也需要大量的
基于令牌的分页

在这种类型的分页中,API 在每个页面上向使用者发送 next_token。该令牌用于下一次 API 调用等。列或属性用于透视表中的数据。您可以选择任何符合要求的列。主要思想是,您必须提出条件和参数来帮助您浏览表格。常见的做法是,如果创建时间是唯一的,则选择行创建时间作为标记。在上图中, 表的created_at 列已用作令牌。您可以看到 API 已将 第 111 行 的 发送为 以及 10 个产品。但是,如果表变大,基于令牌的分页需要的延迟要少得多。post``created_at**next_token
为什么? 因为此查询使用查询中的条件过滤表,并从条件匹配的行开始扫描。简而言之,它只读取 limit 行数。
让我们在之前创建的 post 表上做一些实验。我们将查询与早期实验中完成的相同结果。请注意,正确的索引将带来更好的性能。我让事情变得简单。
让我们针对第 100 次 到 110 次 运行此查询行,
在这里,我们已经可以看到它的执行时间比以前少了。数据库已过滤掉并仅计算10行而不是110行 .
现在,让我们使用更大的令牌值来限制查询。此查询的目标是90000 到第 90010 行 行。
限制(成本=0.00..1.11行=10宽度=27)(实际时间=6.587..6.589行=10循环=1)
->对产品进行顺序扫描(成本=0.00..2184.01行=19735宽度=27)(实际时间=6.586..6.587行=10个循环=1)
= '1662535267497'::bigint)"
筛选器删除的行数:90000
规划时间:1.314 毫秒
执行时间:6.617毫秒
您注意到其中的巨大差异了吗?该查询的执行时间仅为6.617ms。数据库不必遍历 90000 行,而是过滤表并仅读取 10 必需的行。
概括
基于偏移量的分页的数据库查询必须读取 offset+limit 行数,另一方面,基于标记的查询只需要读取 limit 行数对条件进行额外处理的行数。
原文链接:https://juejin.cn/post/7332765584915398665 作者:糖墨夕