
前言
正则表达式是很多前端同学的薄弱的知识点,很多同学基本上都还处于在实际开发中遇到就只能利用搜索引擎解决的初级阶段。但是正则表达式相关的知识点比较少,难就难在应用,只要把一些标准的模式记住之后,几乎就能够完成日常开发80%的需求,剩下的20%再借助搜索引擎,能够大大的提高我们的工作效率。
现代的开发工具大都支持使用正则表达式进行检索,掌握正则表达式尤其能在检索代码的时候释放出不容小觑的能量,大幅度的聚焦我们的检索范围,提高工作效率。
本文就向大家阐述一下正则表达式相关的知识点,并根据我7年以上的实际项目开发经验,结合一些例子向大家展示其实际开发中的用途。
正则表达式基础
这一小节是与JS无关的知识点,只要是任何一门支持正则表达式的语言都可以受用。
说白了,学习正则表达式,我们无非就是记忆一些正则匹配的标准范式,正则表达式的核心就是匹配范围+量词。
精准匹配:
- 简单的,遇到什么就是什么(除开正则表达式的元字符),比如
0,表示匹配0;正则表达式的元字符有很多个,如果我们确实要匹配那个字符(即要求正则表达式引擎把它当一个普通的字符处理),我们可以用\进行转义,比如,我们要匹配英文的问号,\?。 ^,表示匹配开头,比如我们在验证用户输入的时候,要求用户输入的第一个字符必须是数字,则需要使用正则表达式^\d,假设不加这个^,则用户在任意位置输入数字都能匹配了。$,表示匹配结尾,和^的效果类似,一般匹配开头和结尾的标识会用来做用户输入的验证。
范围匹配:
[pattern],一对方括号,表示范围,其中pattern(我撰文用pattern表示占位),可以是任何有意义的正则表达式模式范围。比如[0-9],表示匹配数字;比如[\dA-Za-z_],表示匹配数字,大小写字母和下划线;比如[a9'],表示匹配小写字母a,数字9,单引号’这三个字符中的任意一个。[^pattern],也是表示范围,不过其表示的是这个范围的反面,比如[^0-9],表示匹配非数字;表示匹配[^\dA-Za-z_],表示匹配除了数字,大小写字母,下划线以外的任意字符;比如[^a9'],表示匹配除了小写字母a,数字9,单引号’这三个字符以外的任意字符。[\u4e00-\u9fa5],表示匹配汉字。\d,表示匹配数字,等价于[0-9]\w,表示匹配包括下划线的任何单词字符。类似但不等价于[A-Za-z0-9_].,表示匹配除“\n”和”\r”之外的任何单个字符,一定要记住.是元字符,这是实际开发中相当容易写bug的一个场景,因为.匹配的范围特别的广,有些时候写错了恰好就能匹配的上某些测试用例。\s,匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。实际开发中,String.prototype.trim方法就可以使用这个元字符进行实现。\b,匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。这个范围在实际开发中的使用频率并不是那么高,作为了解即可。pattern|pattern,表示或,匹配|左边的的模式或者右边的模式之一即可,实际开发中需要注意一个问题,或,会存在一个或此或彼或两者的问题,因此在判断的时候,需要考虑一下字符串的长度,比如我们需要匹配一个Hex格式的颜色色值,一种表示方法,#c09,这个色值等价于#cc0099,如果我们用正则来编写匹配模式的话,可以写出#([a-fA-F\d]{3})|([a-fA-F\d]{6}),但是这个正则可以把#cc0099c09匹配。(我这个例子可能举的不是那么贴切,不过希望读者可以通过这个例子注意到这个或的问题)
实际开发中,我们掌握以上这些范围匹配模式即可。还有一些不常用的模式,有兴趣的读者可以直接查看正则表达式。
非获取范围匹配:
在某些时候,我们要求匹配的位置尽量精确,因此会对匹配的位置有一定的要求。
总结为4个字,前瞻后顾
(?:pattern),非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。这个匹配模式在实际开发中不常用。这个解释如果你觉得晦涩难懂的话,就看这个图吧。


(?=pattern),非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。这就是所谓的后顾。(?!pattern),非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。(?<=pattern),非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 这就是所谓的前瞻。(?<!pattern),非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等
量词:
之前我们所提到的范围,如果不加量词的话,都只能匹配一个字符。如果加上了量词,就表示匹配这个范围多少次。
- 通用范围,
{n},表示匹配前面的范围确定的n次,n为正整数。 {n,}表示匹配前面的范围至少n次,n为正整数。{n,m},表示匹配前面的范围至少n次,至多m次,n,m为正整数,m大于n,需要注意的是逗号前面没有空格。+,表示匹配前面的范围至少1次,等价于{1,}。*,表示匹配前面的范围任意次,等价于{0,}。?,表示匹配前面的范围最少0次,最多一次,等价于{0,1},这个符号一般我们会用来匹配用户输入的可选部分,比如匹配手机号码时,国家代码就是可选的,^(\+?86-)?1[3456789]\d{9}$,我们在输入的时候,既输入+86-13345671234,又可以输入86-13345671234,还可以输入13345671234。
分组
在正则表达式中,一个小括号表示一个组,分组有两种意义,一种就是我们在进行或的逻辑匹配的时候,我们可能需要匹配其中一个组即可。另外一种就是非常重要的用途了,我们需要利用正则表达式匹配到的结果,这个时候也需要分组。
比如,之前我们在说那个Hex色值匹配的例子,可能存在一个或此或彼或两者的问题,如果我们把正则表达式写成这样,就可以避免这个问题:(^#[a-fA-F\d]{3}$)|(^#[a-fA-F\d]{6}$),看起来写的啰嗦了,但是实际上我们是收窄了匹配的范围从而避免了问题。
比如,我们需要利用到匹配的结果,在快递单上打印的用户的手机号码加密,可以编写出这样的一个正则表达式用于替换,比如:
function protectTelephone(str) {
// 提取出前面3位数字和最后4位数字
return str.replace(/(1[3456789]\d)(\d{4})(\d{4})/, '$1****$3')
}
这个函数就会将11位的用户手机号替换成前三位数字+4个*+最后4位数字。
在这个场景,还可以利用到我们之前提到的非获取匹配,即前瞻后顾,在匹配到4位数字的时候,前面3位看起来要是电话号码的格式前3位,最后面的4位也必须是数字:
function protectTelephone(str) {
// 匹配4位数字,但是要求这个4位数字前面后面加起来要像是手机号码格式
return str.replace(/(?<=1[3456789]\d)\d{4}(?=\d{4})/, '****')
}
贪婪模式与非贪婪模式
正则表达式在匹配的时候,都是尽可能的多匹配。像之前我们提到的一个量词:+表示至少匹配一个模式1次,但是有些时候,我们需要它尽可能少的匹配,因此就可以在这种量词后面跟上一个?,比如/o+/来匹配字符串ooooooo,会直接从开头就给匹配到结束了,但是如果我们使用非贪婪模式来匹配的话/o+?/,仅仅只匹配到第一个o就结束了。
具有二意性的元字符
?,对于量词,表示匹配{0,1},对于量词后面的?,表示使用非贪婪模式。^,单独出现,表示匹配字符串的开头,如果出现在方括号内,表示取这个方括号表示的范围的反面,如[^\d]表示匹配非数字。
JS中的正则表达式
在JS中,正则表达式是一种特殊的对象,其有两种表达方式,一种叫做字面量的形式,用/正则表达式/[修饰符]来表示,另外一种可以使用JS表达式动态的创建正则表达式对象,即使用new RegExp(正则表达式,修饰符)的方式,使用动态创建正则表达式对象的方式需要注意的问题是需要注意转义字符,比如正常我们写/\d/,使用new的方式创建则需要写成new RegExp("\\d"),这是因为在字符串内\\才是真正表示\。
实际上,字面量形式的正则表达式还是会被JS引擎解析为RegExp的实例。比如:
const testExp = /\d/;
testExp instanceof RegExp // true
typeof testExp // 'object'
所以在实际的开发中,不是必须要动态的创建正则表达式对象时,尽量不要使用new的方式创建。
RegExp对象
构造函数
RegExp构造函数的第一个参数是正则表达式,需要注意一下转义字符即可。第二个参数表示正则表达式的标志,到ES6,已经支持dgimsuvy这些模式,我简单介绍一下常用的几个标识,i,标识忽略大小写,比如之前我们写的用于匹配Hex颜色色值的正则,可以简写成如下的方式:/(^#[a-f\d]{3}$)|(^#[a-f\d]{6}$)/i;m,表示多行匹配,实际开发中几乎不会用到;g,标志意味着正则表达式应该测试字符串中所有可能的匹配,这是很多新手开发者经常傻傻分不清的标识,g标示开启之后,RegExp.lastIndex属性将会生效,可能会出现一些意料之外的bug,我们在验证用户的输入的时候,是没有必要开启g的标识的,但是加上这个标识没有错的原因,是因为每次验证,我们都生成了一个正则表达式字面量,所以lastIndex实际上没有生效,因此看起来加不加效果也一样,一般我们在做替换的时候,如果需要尽可能多的替换到模式的话,需要开启g标识。
比如最开始我们提到的手机号码的场景,假设业务后端返回给我们的是一段富文本,我们在BFF服务器内需要将这段富文本里面的所有符合电话号码格式的内容都替换成加*的展示形式,就需要使用g标识:
function protectInfo(content) {
// 替换到所有的符合电话号码格式的数据
return str.replace(/(1[3456789]\d)(\d{4})(\d{4})/g, '$1****$3')
}
其余模式就不做解释了,有兴趣的同学可以直接参考阮一峰老师的网络博客:正则的扩展
RegExp.prototype.source
通过这个属性,我们可以拿到这个正则表达式对象的正则表达式内容,这个内容就是在上一节所提到的与平台无关的正则表达式内容。
标识符属性
通过RegExp.prototype.flags属性,我们可以拿到初始化正则表达式对象时第二个参数的内容,或者说正则表达式对象字面量上的修饰符,ES6目前已经支持的dgimsuvy这些模式,大部分都有对应的属性来获取是否添加某个标识符,对于常见的2个标识符,如RegExp.prototype.global可以获得这个正则表达式对象是否有g标识,RegExp.prototype.ignoreCase可以获得这个正则表达式对象是否有i标识,其它不常用的,感兴趣的同学可以参考MDN。
RegExp.prototype.lastIndex
先给大家看一个新手犯的错误:
const regExp = /1[3456789]\d{9}/g
regExp.test('13456788765') // true
regExp.test('13456788765') // false
regExp.test('13456788765') // true
regExp.test('13456788765') // false
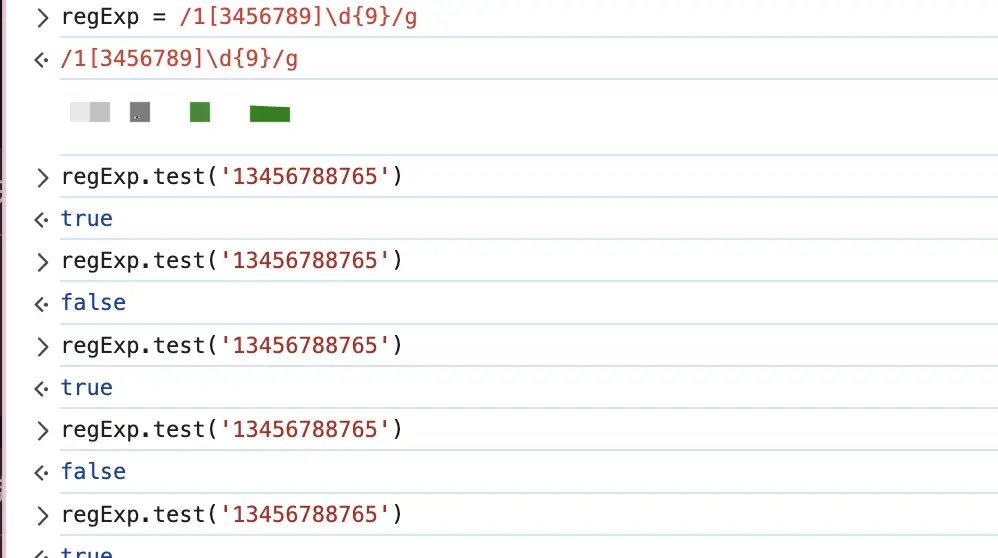
先给大家解释一下为什么会出现这样的情况,这是因为开启了全局匹配模式之后,RegExp的lastIndex属性生效了,当第一次匹配成功之后,lastIndex切到匹配成功的位置,下一次匹配的时候这个字符串就不再是从头开始匹配了,所以第二次就匹配失败了,匹配失败之后,lastIndex就会重置为0,所以就像初始化了一个正则表达式一样,再次进行匹配的时候,就会匹配成功。
但是如果把这个代码改写成这样,就不会错了:
/1[3456789]\d{9}/g.test('13456788765') // true
/1[3456789]\d{9}/g.test('13456788765') // true
/1[3456789]\d{9}/g.test('13456788765') // true
/1[3456789]\d{9}/g.test('13456788765') // true
这是因为每次都用了一个新的正则表达式来进行匹配,所以lastIndex并不会影响。
在实际开发中,在做用户输入验证的时候,一定不要添加全局匹配标识,只有在做字符串替换的时候才可能用到全局匹配标识。
RegExp.$1-RegExp.$9
这个是一个非标准的实现,但是大多数浏览器都实现了这组属性,不过仍然不推荐在生产环境中使用。
在正则表达式的章节我们介绍了分组,这里面的$1-$9,表示9个组,虽然正则表达式可以有无限的组,但是JS只支持匹配成功之后至多9个组的值记录下来。
你或许可能看到过这种代码:
// 假设标识匹配某个业务场景下的序列号
const regExp = /W([a-zA-Z]{26})#/
const content = 'some content read from database';
const flag = regExp.test(content);
if(flag) {
// 读取组进行一些操作
console.log(RegExp.$1)
}
以上的代码是不推荐的,实际上,我们拿到组的匹配值还是在字符串上进行操作,因此我们可以使用String.prototype.replace配合正则表达式完成相应的效果,但是这种方式是推荐在生产环境中使用的:
const regExp = /W([a-zA-Z]{26})#/
let content = 'some content read from database';
content = content.replace(regExp, '$1')
如果你确实仅仅只需要拿到某个组,可以使用下一小节即将阐述的RegExp.prototype.exec方法。
RegExp.prototype.exec
exec() 方法在一个指定字符串中执行一个搜索匹配,它的效果是跟String.prototype.match相似的。
如果匹配失败,exec() 方法返回null,并将正则表达式的 lastIndex 重置为 0。
如果匹配成功,exec() 方法返回一个数组,并更新正则表达式的lastIndex 属性。完全匹配成功的文本将作为返回数组的第一项,从第二项起,后续每项都对应一个匹配的捕获组。数组还具有以下额外的属性:
使用这个方法,可以避免让我们使用RegExp.$1-$9的非标准属性。
比如,在之前提过的使用RegExp.$1的例子,我们可以用exec进行改写。
// 假设标识匹配某个业务场景下的序列号
const regExp = /W([a-zA-Z]{26})#/
const content = 'some content read from database';
const results = regExp.exec(content);
if(Array.isArray(results)) {
// 读取组进行一些操作
console.log(results[1])
}
实际开发中,我们还可以利用这个方法做很多神奇的事儿,以下是两个例子。
匹配所有的 HTML 标签及其属性:
const html = '<div id="container" class="wrapper">Hello <span style="color: red;">world</span>!</div>';
const tagRegex = /<(\w+)([^>]*)>/g;
let match;
while ((match = tagRegex.exec(html)) !== null) {
console.log(`标签: ${match[0]}`);
console.log(`标签名: ${match[1]}`);
console.log(`属性: ${match[2]}`);
}
从 CSS 样式表中提取所有的类名和对应的样式属性:
const css = '.container {width: 100%;} .wrapper {margin: 20px;}';
const classRegex = /\.(\w+)\s*\{([^}]*)\}/g;
let match;
while ((match = classRegex.exec(css)) !== null) {
console.log(`类名: ${match[1]}`);
console.log(`样式属性: ${match[2]}`);
}
序列化需要注意的问题
正则表达式对象在序列化的时候,会被序列化成一个普通的对象。如果我们需要将其真实的面目记录下来。
const testExp = /\d+/gi
JSON.stringify(testExp) // {}
正则表达式对象上的toString方法重写了Object.prototype.toString方法,因此,直接使用正则表达式对象的toString方法可以得到我们预期的结果,比如:
const testExp = /\d+/gi
testExp.toString() // /\d+/gi
不过,这个办法也不是100%能解决问题,这个值如果说直接反序列化的话,会出问题:
const testExp = /\d+/gi
const str = testExp.toString()
const parseExp = new RegExp(str) // /\/\d+\/gi/
它会将整个字符串算入到正则表达式的source里面去,所以,这种方式是不行的。
我们有两种变通的方式来处理,第一种方式是使用正则表达式来处理这类字符串:
// 假设用户输入的是一个合法的字符串
function parseExp(str) {
const flagExp = /\/([dgimsuvy]*)$/
const idx = str.search(flagExp);
const flagMark = str.substring(idx+1);
// 替换掉开头的/,再替换掉结尾的/+标识符
const expContent = str.replace(/^\//, '').replace(/\/([dgimsuvy]*)$/, '')
return new RegExp(expContent, flagMark);
}
第二种方式是使用eval,只不过问题就是在严格模式下不能使用eval。
// 假设用户输入的是一个合法的字符串
function parseExp(str) {
return eval('(' + str + ')')
}
和字符串方法配合使用
String.prototype.searchString.prototype.replaceString.prototype.splitString.prototype.match
String.prototype.search
search 方法用于在字符串中执行正则表达式的搜索,寻找匹配项。如果匹配成功,则返回正则表达式在字符串中首次匹配的索引;否则,返回 -1。
这个方法其实是有点儿类似于RegExp.prototype.test方法,因为test方法返回的是布尔值,而这个方法返回的是索引,我们可以根据索引就知道是否匹配成功了。
const paragraph = "I think Ruth's dog is cuter than your dog!";
const regex = /[^\w\s']/g;
console.log(paragraph.search(regex));
String.prototype.replace
replace() 方法返回一个新字符串,其中一个、多个或所有匹配的 pattern 被替换为 replacement。
pattern 可以是字符串或正则表达式对象,replacement 可以是字符串或一个在每次匹配时调用的函数。
如果 pattern 是字符串,则只会替换第一个匹配项。原始的字符串不会改变。
使用replace方法常常能实现类似像模板引擎的效果:
function render(template, data) {
return template.replace(/\{\{(\w+)\}\}/g, (match, key) => {
return data[key] !== undefined ? data[key] : match;
});
}
// 示例数据
const data = {
name: 'John',
age: 30,
city: 'New York'
};
// 模板字符串
const template = 'Hello, my name is {{name}}. I am {{age}} years old. I live in {{city}}.';
// 渲染模板
const result = render(template, data);
console.log(result);
以上代码展示了replace方法第二个参数是函数的实际应用场景。
另外,在替换过程中,可以指定一些带有含义的字符串作为替换项
常用的就是$n,比如,在之前的例子中我们用于给用户的电话号码脱敏的场景,就使用到了:
function protectInfo(content) {
// 替换到所有的符合电话号码格式的数据
return str.replace(/(1[3456789]\d)(\d{4})(\d{4})/g, '$1****$3')
}
其它特殊替换模式在实际开发中几乎不怎么用到,读者对其有个了解即可。
String.prototype.split
split() 方法接受一个模式,通过搜索模式将源字符串分割成一个有序的子串列表,将这些子串放入一个数组,并返回该数组。
split方法接受的模式可以是普通字符串,也可以是正则表达式。
const text = 'apple,banana ;orange apple banana';
const words = text.split(/[\s,;]+/);
console.log(words); // ["apple", "banana", "orange", "apple", "banana"]
使用正则表达式进行字符串分割能够大大的提高我们分割字符串的便利性,往往能够解决很多棘手的问题。
但是,使用正则表达式进行分割,有可能存在把字符串截断的问题,解决这个问题可以使用ES6新引入的u标识。
以下是来自MDN的截图:
"😄😄".split(/(?:)/); // [ "\ud83d", "\ude04", "\ud83d", "\ude04" ]
"😄😄".split(""); // [ "\ud83d", "\ude04", "\ud83d", "\ude04" ]
以上两种写法是等价的。
String.prototype.match
match() 方法检索字符串与正则表达式对象进行匹配的结果。
match方法的参数接收一个正则表达式对象或者任何具有Symbol.match方法的对象。如果传入的参数不是RegExp对象的实例,并且没有Symbol.match方法,将尝试会使用new RegExp(regexp)将其隐式地转换为自动转化为RegExp对象。
正常在实际开发中,我们就传入一个正则表达式对象即可,对于match方法的参数的特点,作为了解即可。
match方法在有匹配时,返回一个Array,其内容取决于是否存在全局(g)标志,如果没有匹配,则返回null。
- 如果使用
g标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组。 - 如果没有使用
g标志,则只返回第一个完整匹配及其相关捕获组。在这种情况下,match()方法将返回与RegExp.prototype.exec()相同的结果(一个带有一些额外属性的数组)。
以下是不使用g标识符:
const str = "For more information, see Chapter 3.4.5.1";
const re = /see (chapter \d+(\.\d)*)/i;
const found = str.match(re);
console.log(found);
// [
// 'see Chapter 3.4.5.1',
// 'Chapter 3.4.5.1',
// '.1',
// index: 22,
// input: 'For more information, see Chapter 3.4.5.1',
// groups: undefined
// ]
对于这种用法,我建议大家还是直接使用RegExp.prototype.exec,这种语义性不强的写法,代码的可读性不高。
使用g标识符就特别好理解了,即:匹配某个字符串符合某个模式的所有子串。
const str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
const regexp = /[A-E]/gi;
const matches = str.match(regexp);
console.log(matches);
// ['A', 'B', 'C', 'D', 'E', 'a', 'b', 'c', 'd', 'e']
实际开发中,match的用法主要是这种场景。
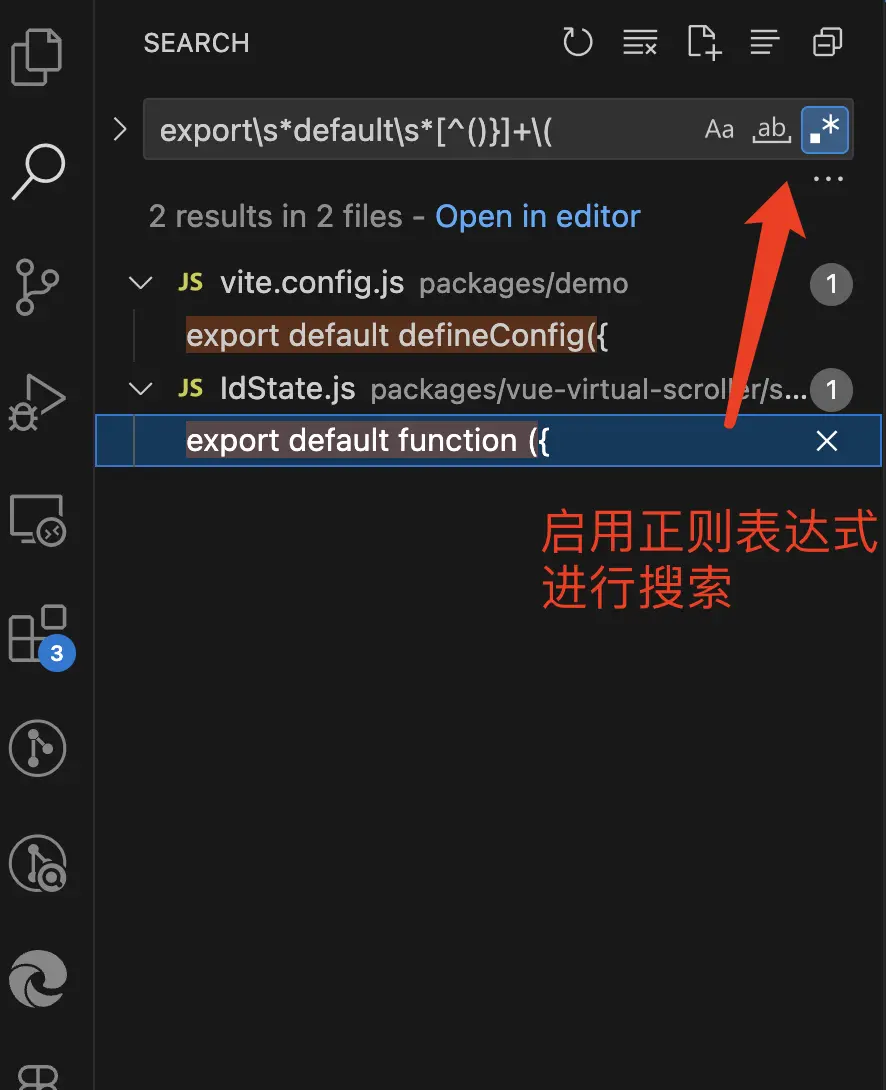
与编辑器配合使用
掌握了正则表达式,在实际开发中模糊搜索源代码,完成批量替换可谓是相当的🐂🍺。
本文就以为VSCode的使用方式向大家展示在编辑器中使用正则表达式进行模糊搜索和替换。
如果觉得这个例子不具备说服力,我们可以尝试搜索更复杂的例子,搜索项目中所有的<table>及其子标签,要求table标签必须具有class属性:
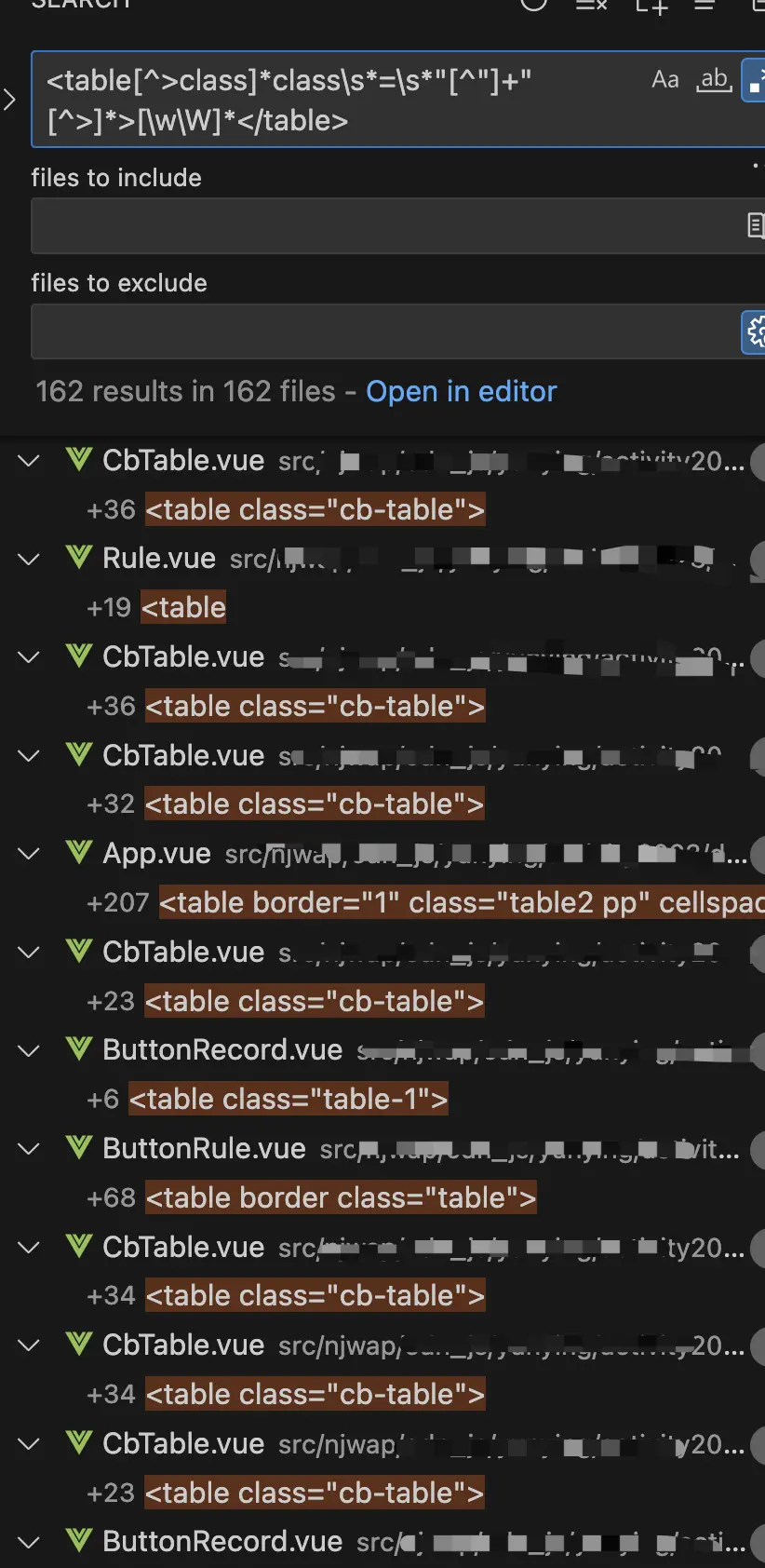
同样,在替换的时候仍然可以使用前面我们在String.prototype.replace方法小节提到的特殊字符替换。
比如,某天你暗恋了许久的小姐姐给你发一个csv文件,让你帮忙将一个文件里面的所有客户的电话号码替换成前文提到的将中间4位进行脱敏的形式。

(注:上面的电话号码是杜撰的)
你在短短的几分钟内就帮小姐姐搞定了,那爱情不就来了吗?哈哈哈。
总结
正则表达式的知识点比较简单,但是难点在于实际应用。
从我个人的成长体会来说,正则表达式的学习是一个循序渐进的过程,首先完全不会的时候肯定遇到一个业务场景就只能通过搜索引擎解决问题。当我们解决了对应的业务需求之后,一定要对这个正则表达式进行复盘,为什么它这样写可以解决我的问题,分析每个子模式匹配的内容是否符合我们的业务预期(比如有些时候把.当普通字符串用了,很多博客上的人给出的正则表达式不乏这种错误)。
在复盘完成之后,我们的技术积累自然也就提升了。在写正则表达式的时候,遇到分组的时候需要注意分组嵌套的问题。遇到或的逻辑时,一定需要注意或此或彼或两者的问题。
然后,我们需要知道在JS中正则表达式的一些坑点(比如lastIndex),以及序列化需要注意的问题。
最后,我们需要举一反三,能够在实际的开发中使用正则表达式在编辑器中进行文本的模糊检索和替换,能够大幅的提升我们的工作效率。
对于本文阐述的内容有任何疑问的同学可以在评论区留言或私信我。
如果大家喜欢我的文章,可以多多点赞收藏加关注,你们的认可是我最好的更新动力,😁。
原文链接:https://juejin.cn/post/7333986476029444106 作者:HsuYang